【清华】2.0_实验12-回归分析
- 格式:pdf
- 大小:372.70 KB
- 文档页数:7

定量分析实验室项目课程介绍
1、回归分析(Linear Regression Analysis):
教师:Yu Xie(谢宇),美国密歇根大学社会学系教授。
时间:2007年7月16日至8月10日
课时:48学时。
课程内容:简介线性代数,以矩阵形式温习线性回归模型。
主要讲授线性回归在社会科学研究中的应用,并介绍通径分析、纵贯数据分析、对二分类因变量的logit 分析。
本课程将结合STATA统计软件的应用。
该课程为本实验室开设系列方法课程的必修课之一。
2、分层线性模型(Hierarchical Linear Model):
教师:Stephen Raudenbush,美国芝加哥大学社会学系教授
时间:2007年8月13日至8月31日
课时:48学时。
课程内容:介绍分层数据结构与分层模型的基本原理,通过大量纵贯数据和分层数据的分析实例来示范分层模型在社会科学研究中的应用。
课程从两层分析模型入手,然后扩展到三层模型(包括个体重复测量分析),并介绍对潜在变量和交互分组数据的分层分析。
本课程将结合HLM统计软件的应用。

回归分析实验案例数据引言:回归分析是一种常用的统计方法,用于探索一个或多个自变量对一个因变量的影响程度。
在实际应用中,回归分析有很多种,例如简单线性回归、多元线性回归、逻辑回归等。
本文将介绍一个回归分析实验案例,并分析其中的数据。
案例背景:一家汽车制造公司对汽车的油耗进行研究。
他们收集了一些汽车的相关数据,并希望通过回归分析来探究这些数据之间的关系。
数据收集:为了进行回归分析,他们收集了以下数据:1. 汽车型号:不同汽车型号的标识符。
2. 汽车价格:每辆汽车的价格,单位为美元。
3. 汽车速度:以每小时英里的速度来衡量。
4. 引擎大小:汽车引擎的容量大小,以升为单位。
5. 油耗:每加仑汽油行驶的英里数。
数据分析:通过对收集的数据进行回归分析,可以得出以下结论:1. 汽车价格与汽车引擎大小之间存在正相关关系。
即引擎越大,汽车价格越高。
2. 汽车速度与油耗之间呈现负相关。
即速度越高,油耗越大。
3. 汽车引擎大小与油耗之间存在正相关关系。
即引擎越大,油耗越大。
结论:基于以上分析结果,可以得出以下结论:1. 汽车价格受到引擎大小的影响,即引擎越大,汽车价格越高。
这一结论可以帮助汽车制造公司在制定价格策略时做出合理的决策。
2. 汽车速度与油耗之间呈现负相关。
这一结论可以帮助消费者在购买汽车时考虑速度对油耗的影响,从而选择更经济的汽车。
3. 汽车引擎大小与油耗之间存在正相关关系。
这一结论可以帮助汽车制造公司在设计引擎时考虑油耗因素,从而提高汽车的燃油效率。
总结:回归分析是一种有效的统计方法,可以用于探索数据间的关系。
通过对汽车制造公司收集的数据进行回归分析,我们发现了汽车价格、速度和引擎大小与油耗之间的关系。
这些分析结果对汽车制造公司制定价格策略、消费者购车以及提高燃油效率都具有重要的指导意义。
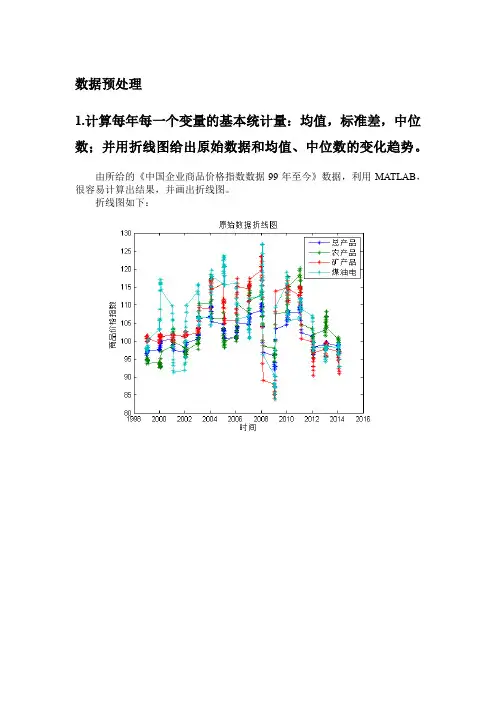
数据预处理1.计算每年每一个变量的基本统计量:均值,标准差,中位数;并用折线图给出原始数据和均值、中位数的变化趋势。
由所给的《中国企业商品价格指数数据99年至今》数据,利用MATLAB,很容易计算出结果,并画出折线图。
折线图如下:2.给出各变量按季节变化趋势;每年各变量频数直方图的变化趋势,可做动态图。
利用MATLAB作图如下:(此频数直方图是动态图)3. 按原始数据,指出被解释变量和每解释变量之间的关系,画图;利用MATLAB分别作图如下:从图中可以看出,随着农产品价格指数的增长,总指数有线性增长的趋势,所以总指数与农产品价格指数有线性关系。
从图中可以看出,随着矿产品价格指数的增长,总指数有线性增长的趋势,所以总指数与矿产品价格指数有线性关系。
从图中可以看出,随着煤油电价格指数的增长,总指数有线性增长的趋势,所以总指数与煤油电价格指数有线性关系。
4.按年平均数、中位数预处理数据,指出被解释变量和每个解释变量之间的关系,画图;利用MATLAB,分别作图如下:从图中可以看出,对于每个解释变量(各个价格指数中均值),随着其增长,被解释变量(总指数均值)都有线性增长的趋势,所以被解释变量与每个解释变量分别有线性关系。
从图中可以看出,对于每个解释变量(各个价格指数均中位数),随着其增长,被解释变量(总指数中位数)都有线性增长的趋势,所以被解释变量与每个解释变量分别有线性关系。
(本节MATLAB代码见附录一)一元回归分析 基本模型下面先从简单入手,由上节数据预处理第三问求解得出,总指数y 与农产品价格指数x 之间存在线性关系,所以,可以建立以下一元线性回归模型:y i = β0+β1x i +εi, i=1,2……,191各εi 独立同分布,其分布为N (0,σ2)由数据(xi ,yi )(i=1,2……,191)可获得β0、β1的估计ˆβ1ˆβ 称 01ˆˆˆx yββ=+ 为y 关于x 的回归方程,ˆβ,1ˆβ为回归系数,εi 是随机误差。


回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。

1.1回归分析的基本思想及其初步应用(第1课时)教案教材:人民教育出版社A版必修3授课教师:中卫市第一中学俞清华【教学目标】在《数学③(必修)》之后,学生已经学习了两个变量之间的相关关系,包括画散点图,最小二乘法求回归直线方程等内容.在人教A版选修1-2第一章第一节“回归分析的基本思想及其初步应用”这一节中进一步介绍回归分析的基本思想及其初步应用.这部分内容《教师用书》共计4课时,第一课时:介绍线性回归模型的数学表达式,解释随机误差项产生的原因,使学生能正确理解回归方程的预报结果;第二课时:从相关系数、相关指数和残差分析角度探讨回归模型的拟合效果,以及建立回归模型的基本步骤;第三课时:介绍两个变量非线性相关关系;第四课时:回归分析的应用. 本节课是第一课时的内容.1、知识与技能目标认识随机误差;2、过程与方法目标(1)会使用函数计算器求回归方程;(2)能正确理解回归方程的预报结果.3、情感、态度、价值观通过本节课的学习,加强数学与现实生活的联系,以科学的态度评价两个变量的相关性,理解处理问题的方法,形成严谨的治学态度和锲而不舍的求学精神.培养学生运用所学知识,解决实际问题的能力.教学中适当地利用学生合作与交流,使学生在学习的同时,体会与他人合作的重要性.【教学重点】随机误差e的认识【教学难点】随机误差的来源和对预报变量的影响【教学方法】启发式教学法【教学手段】多媒体辅助教学【教学流程】【教学过程设计】.几点注明:1、复习引入时教师做示范——提供5组身高与体重的数据,用Excel展示如何画散点图、用最小二乘法求线性回归方程.随机抽样并列表如下:2、计算机做散点图的步骤如下:(1)进入Excel软件操作界面,在A1,B1分别输入“身高”和“体重”,在A,B 列输入相应的数据.(2)点击“图表向导”图标,进入“图表类型”对话框,选择“标准类型”中的“XY散点图”,单击“下一步”.(3)在“图表向导”中的“图表数据源”对话框中,选择“系列”选项,单击“添加”按钮添加系列1,在“X值”栏中输入身高所在数据区域,在“Y值”栏中输入体重所在数据区域,单击“下一步”.(4)进入“图表向导”中的图表选项对话框,对图表的一些属性进行设置. (5)单击“完成”按钮.注:也可以直接使用我们提供的文件来给学生演示,相对节约课堂时间.3、学生使用函数计算器求回归方程的过程如下:MODE SHIFT CLR =1 13 , DT 165 49 ,DT17565, DT 165 58 , DT 157 51 , DT 170 53 SHIFT CLRSHIFTCLR2==1 (进入回归计算模式)(清除统计存储器)(输入五组数据)所以回归方程为 yˆ0.673x-56.79 (计算参数a) (计算参数b)(学生还会使用更先进的计算器)4、课堂使用的数据如下高二女生前15组数据列表:高二女生中间15组数据列表:高二女生后15组数据列表:课本P2例题1 女大学生8组数据列表:例1.1.1回归分析的基本思想及其初步应用(第1课时)教案说明教材:人民教育出版社A版必修3授课教师:中卫市第一中学俞清华1、设计理念《数学课程标准》明确指出:有效的数学学习活动不能单纯地模仿与记忆,动手实践、自主探索与合作交流,可以促进学生自主、全面、可持续的发展,是学生学习数学的重要方式.为使教学真正做到以学生为本,我对教材P2—P3的知识进行了适当地重组和加工,力求给学生提供研究、探讨的时间与空间,让学生充分经历“做数学”的过程,促使学生在自主中求知,在合作中获取,在探究中发展.2、授课内容的数学本质与教学目标定位回归分析,是一种从事物因果关系出发进行预测的方法.操作中,是在掌握大量观察数据的基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数表达式(称回归方程式),预测今后事物发展的趋势.然而,所建立的回归方程与样本点的分布之间还存在有差异,这一差异就是我们本节课学习的主要内容:随机变量.3、学习本课内容的基础以及应用本课内容安排在《数学3(必修)》之后,学生已经学习了两个变量之间的相关关系,包括画散点图,会利用最小二乘法求回归直线方程等内容.以此为基础,进一步讨论一元线性回归模型,分析产生模型中随机误差项的原因,从而让学生了解线性回归模型与函数模型之间的区别与联系,体会统计思维与确定性思维的区别与联系.通过本节课的学习,为后继课程了解偏差平方和分解思想和相关指数的含义、了解相关指数R2和模型拟合的效果之间的关系、了解残差图的作用,体会什么是回归分析、回归分的必要性,都起到铺垫作用.在本节课的教学中,学生使用了函数计算器,教师则利用电脑Excel表格完成对数据的整理,需要学生有一定的动手能力.4、学习本课内容时容易了解与容易误解的地方由于学生对必修3中的线性回归知识已经熟悉,会抽取样本、会画散点图、会利用最小二乘法求出线性回归方程,所以本节课学生容易了解:(1)从散点图看出,样本点呈条状分布,体重与身高具有线性相关关系,因此可以用线性回归方程来近似刻画它们之间的关系.(2)可以发现样本点并不完全落在回归方程上,有随机误差存在.(3)容易理解由一条回归方程预测到的身高172cm的女生体重不是都一样,它只是一个平均值.在学习过程中,相对不易理解的地方有:(1)对于随机误差的来源,学生是能够从样本的个体差异上来理解的,但是对于由用线性回归模型近似真实模型所引起的误差,学生理解还是有一定困难的.(2)随机误差对预报变量的影响,学生从感性上很好理解,当然是随机误差越小越好.但是从理性上认识,怎样从数据上刻画出随机误差是否变小了呢?学生还有困难.5、本节课的教法特点以及预期效果分析5.1 改造创新教师通过分析教材和学生认知规律,创造性地使用教材,做到既重视教材,更重视学生.具体说来有以下改造:(1)创设生活情景.利用学生的“体检经验”设置问题,既没有脱离课本例题1的相关内容,又能激发学生对数学的亲切感,引发学生看个究竟的冲动,兴趣盎然地投入学习.(2)充分体现随机观念.课本上仅仅希望利用8组数据就要学生体会到统计的思想和后继课程中回归分析的必要性,实在是为难学生了.在本课教学设计学生操作时强调“增多数据,加强比较”. 帮助学生体会“不同事件(如课本例1女大学生和高二女生)”,则统计结果不同、“同一事件(如都是高二女生),采样不同结果也不同”的基本事实.(3)教师的作用. 在这节课里,教师在学生操作结束后,利用更多数据的操作,形成一个与学生结果的对比,这一操作与展示为学生创造了新的思维增长点,引领学生进入更深层领悟.5.2 问题性本课教学以问题引导学习活动,通过恰时恰点地提出问题,提好问题,给学生提问的示范,使他们领悟发现和提出问题的艺术,引导他们更加主动和有兴趣地学,逐步培养学生的问题意识,孕育创新精神.例如,在“结果的分析”中的问题4、“预测出的体重值都不同,那么它还有参考价值吗?”目的是让学生充分认识随机误差e的来源和对预报变量的影响,而这一问题的提出,立刻吸引学生细细体会随机观念,同时激发出学生的好奇心,提升深入探求的欲望.5.3 合作、探究的学习方式本节课的合作学习体现在两个方面:除了体现在每个小组内部成员之间,还体现在整堂课的教学结构上.小组成员内部提倡“不同的人作不同的事”,面对不同分组,学生可以自主选择的不同工作,动手带动动脑,遇到小的问题,通过探讨和帮助,能做到“学生的问题由学生自己解决”,促进对某一问题更清晰的认识,还能感受到团结合作的好处与必要.同时,每个小组的劳动成果共同构成课堂教学需要的多条回归方程,组与组之间的合作推动整节课的比较与区分得以实现.5.4教学手段本课积极将数学课程与信息技术进行整合,采用多种技术手段,特点主要体现如下:(1)以PPT 为操作平台,界面活泼,操作简单,能有效支持多种其它技术;(2)教师用Excel图表展示,直观形象,节约时间,帮助学生顺利完成学习内容;(3)学生使用函数计算器动手操作,求出回归方程.本课预期:(1)学生可以很好地复习使用函数计算器求回归方程,虽然在要求学生自己操作前教师有一个示例,但是还是会有一少部分人不会使用,所以在教学前要有一定的思想准备,和必要措施.(2)在分析各个组的预测结果为什么有差异时,由于个体经验不同,对问题的挖掘深度产生不同,这时教师的启发引导可能会十分必要,不能完全由学生漫无目的的“讨论”,使学生活动流于形式.(3)“结果分析”前,由学生展示操作成果,这些结果已经够用来说明问题,教师不要急于参与.在“结果分析”的第4个问题中引入教师利用电脑求出的由45 组数据得到的回归方程,让学生再一次通过比较得到新的思考点——怎样知道自己模拟的回归方程身高变化对体重变化影响有多大呢?这样会使学生自然而然渴望进一步了解相关回归分析的知识,为后继课程做好伏笔.对于体现本节课承上启下的作用,可能更好一些.6 教学反思通过本节课的教学实践,我再次体会到什么是由“关注知识”转向“关注学生”,在教学过程中,注意到了由“给出知识”转向“引起活动”,由“完成教学任务”转向“促进学生发展”,课堂上的真正主人应该是学生.一堂好课,师生一定会有共同的、积极的情感体验.本节课的教学中,知识点均是学生通过探索“发现”的,学生充分经历了探索与发现的过程.教学中没有以练习为主,而是定位在知识形成过程的探索,注重数学的思想性,如统计思想、随机观念、函数思想、数形结合的思想方法等,引导学生体验数学中的理性精神,加强数学形式下的思考和推理。

可编辑修改精选全文完整版实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi ni i Y L X X X Y n E X Y E E ββ)] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==01010)()1(])1([βεβεβ=--+=--+=∑∑==i xxi ni i xx i ni E L X X X n L X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni i xx i n i X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑==222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 证明:(1)01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSE SSR )Y ˆY Y Y ˆn1i 2i i n1i 2i+=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章1.一个回归方程的复相关系数R=0.99,样本决定系数R2=0.9801,我们能2ˆ22-=∑neiσ判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。


双因素实验回归分析和方差分析的转化李晓燕新疆大学数学与系统科学学院,乌鲁木齐 (830046)E-mail: lieryan2008@摘 要:本文简要介绍了回归分析和方差分析的基本原理,并根据实际问题中的双因素无重复实验的具体实施情况分别采用回归分析法和方差分析法进行分析讨论。
对前者,首先对实验数据进行认真观测,研究自变量及结果变量的相关性和变化规律,给出假定的回归模型并对参数及其置信区间进行估计推断;对后者,双因素实验观测数据虽较多,但因素水平较少的情况下,就可以通过重新调整数据结构设置,使其变为正交实验设计模式,从而可单独对某因素进行显著性影响的评判,即方差分析。
从而得出同一问题在适当条件下两种方法的可实现性。
关键词:回归分析,方差分析,最小二乘原理,离差平方和,双因素中图分类号:O212.61. 引言在科学实践的许多问题中,常会遇到许多相互联系相互制约的变量,常见的变量之间的关系大致分为两类:确定性关系和非确定性关系。
确定性关系即函数关系,此关系大家较为熟悉;非确定性关系即相关关系。
相关关系是指两个相互关联的变量之间存在着一定的数量关系,而这种关系并不是完全确定的,当一个变量发生变化时,另一个变量也在一定范围内有规律的变化。
变量间存在相关关系的例子也很多。
例如,身高和体重的关系,总体来说,身高者体也重;在气候、种子、管理等条件基本相同时,施肥量和浇水量多些,亩产量则高些,但也不会无限制上涨,而是在某个范围内大体上满足这种关系。
回归分析就是研究某随机变量(因变量)与其它一个或多个普通变量(自变量)之间的数量关系,并建立其数学关系,称为回归方程。
如果所建立的方程是线性的,称作线性回归[1],否则称作非线性回归。
回归分析是解决这种非确定关系的有力工具。
方差分析也是数理统计的基本方法之一,是工农业生产和科学研究中分析数据的一种常用方法。
例如,在化工生产中,原料成分、原料剂量、催化剂和反应时间等因素都会对产品的质量和数量产生影响,但影响大小各有不同,要想找出对产品的质量和数量产生显著影响的因素就需要进行实验。


第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈ /2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
回归分析实验报告财政收入研究摘要本文是对财政收入与农业增加值、工业增加值、建筑业增加值、人口数、社会消费总额、受灾面积进行多元线性回归。
首先,根据所给数据,对数据进行标准化,然后进行相关性分析,初步确定各因素与财政收入的相关程度。
再运用逐步回归分析,确定了变量子集为工业增加值、人口数和社会消费总额。
之后,为了消除复共线性,用主成分估计对回归系数进行有偏估计,获得了模型的回归系数估计值。
最后,对所得结果作了分析,并给出了适当建议。
一、数据处理为了消除变量间的量纲关系,从而使数据具有可比性,运用spss对所给数据进行标准化。
二、相关性分析要对某地财政收入影响因素进行多元回归分析,首先要分析财政收入与各自变量的相关性,只有与财政收入有一定相关性的自变量才能对财政收入变动进行解释。
运用spss得到变量间的相关系数表如下:表一:由上表可知,财政收入与农业增加值、工业增加值、建筑业增加值、人口数、社会消费总额呈高度正相关,但与受灾面积相关程度不高。
由此表明所选取的大部分变量是可以用来解释财政收入变动的。
为进一步确定最优子集,下面用逐步回归法。
三、回归分析回归分析就是对具有相关关系的变量之间数量变化的一般关系进行测定,确定一个相关的数学表达式,以便于进行估计或预测的统计方法。
在此利用逐步回归法选定回归方程。
逐步回归思想:综合运用前进法和后退法,将变量一个一个引入,引入变量的条件是其偏回归平方和经检验是显著的。
同时,每引入一个新变量,对已入选方程的老变量逐个进行检验,将经检验认为不显著的变量剔除,以保证所得自变量子集中的每个变量都是显著的。
此过程经若干步直到不能再引入新变量为止。
运用spss得到逐步回归的输出结果:表二:回归系数表模型 非标准化系数标准化系数 t Sig. CollinearityStatistics B 标准误差BetaToleranceVIF1(Constant) -1.292E-16.029 .0001.000x5:社会消费总额.991 .029 .991 33.990.000 1.000 1.0002(Constant) -1.210E-16.024 .000 1.000x5:社会消费总额 2.649 .555 2.6494.776.000 .002 499.022 x2: 工业增加值-1.660 .555 -1.660 -2.992.007 .002 499.0223(Constant) -2.451E-17.017 .000 1.000x5:社会消费总额 4.021 .485 4.021 8.292.000 .001 783.048 x2: 工业增加值 -2.829 .460 -2.829 -6.147 .000 .001 705.453 x4: 人口数-.225.048-.225 -4.697.000.1317.663a. Dependent Variable: y: 财政收入由表二可知,模型三是最终模型,最终选入方程的自变量为:x2:工业增加值;x4:人口数;x5:社会消费总额。
清华大学五道口2020年经济计量学考博真题第一题概念题,随机变量的数学期望和方差问题20分第二题为证明最小二乘法估计量的无偏性,一致性和有效性。
分数45分第三题为联立方程组的识别与工具变量法计算问题,35分清华大学五道口2019年经济计量学考博真题名词解释1.经济变量2.解释变量3.被解释变量4.内生变量5.外生变量6.滞后变量简答题1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。
2.计量经济模型有哪些应用?3.简述建立与应用计量经济模型的主要步骤。
4.对计量经济模型的检验应从几个方面入手?清华大学五道口2018年经济计量学考博真题1.前定变量2.控制变量3.计量经济模型4.函数关系5.相关关系6.最小二乘法简答题1.计量经济学应用的数据是怎样进行分类的?2.在计量经济模型中,为什么会存在随机误差项?3.总体回归模型与样本回归模型的区别与联系。
4.试述回归分析与相关分析的联系和区别。
清华大学五道口2017年经济计量学考博真题名词解释1.高斯-马尔可夫定理2..总变量(总离差平方和)3.回归变差(回归平方和)4.剩余变差(残差平方和)问答题1.计量经济学应用的数据是怎样进行分类的?2.在计量经济模型中,为什么会存在随机误差项?清华大学五道口2016年经济计量学考博真题名词解释1.残差2.显著性检验3.回归变差4.剩余变差简答题1.简述BLUE的含义。
2.对于多元线性回归模型,为什么在进行了总体显著性F检验之后,还要对每个回归系数进行是否为0的t检验?清华大学五道口2015年经济计量学考博真题名词解释1.偏相关系数2.异方差性3.格德菲尔特-匡特检验简答题1.常见的非线性回归模型有几种情况?1、怀特检验2、戈里瑟检验和帕克检验3.修正的决定系数2R 及其作用。
清华大学五道口2012年经济计量学考博真题1、多重决定系数2、调整后的决定系数3.给定二元回归模型:01122t t t t y b b x b x u =+++,请叙述模型的古典假定。
实验9 乙酸乙酯皂化反应速率系数测定丛 乐 2005011007 生51实验日期:2007年12月8日星期六 提交报告日期:2007年12月22日星期六助教老师:曾光洪1 引言1.1实验目的1. 学习测定化学反应动力学参数的一种物理化学分析方法——电导法。
2. 了解二级反应的特点,学习反应动力学参数的求解方法,加深理解反应动力学特征。
3. 进一步认识电导测定的应用,熟练掌握电导率仪的使用方法。
1.2 实验原理反应速率与反应物浓度的二次方成正比的反应为二级反应,其速率方程式可以表示为22dc -=k c dt (1) 将(1)积分可得动力学方程:0c t 22c 0dc -=k dt c ⎰⎰ (2)2011-=k t c c (3) 式中:0c 为反应物的初始浓度;c 为t 时刻反应物的浓度;2k 为二级反应的反应速率常数。
将1/c 对t 作图应得到一条直线,直线的斜率即为2k 。
对于大多数反应,反应速率与温度的关系可以用阿累尼乌斯经验方程式来表示:a E ln k=lnA-RT(4) 式中:a E 为阿累尼乌斯活化能或反应活化能;A 为指前因子;k 为速率常数。
实验中若测得两个不同温度下的速率常数,就很容易得到21T a 21T 12k E T -T ln=k R T T ⎛⎫ ⎪⎝⎭(5) 由(5)就可以求出活化能a E 。
乙酸乙酯皂化反应是一个典型的二级反应,325325CH COOC H +NaOH CH COONa+C H OH →t=0时, 0c 0c 0 0t=t 时, 0c -x 0c -x x xt=∞时, 0 0 0x c → 0x c →设在时间t 内生成物的浓度为x ,则反应的动力学方程为220dx =k (c -x)dt(6) 2001x k =t c (c -x)(7) 本实验使用电导法测量皂化反应进程中电导率随时间的变化。
设0κ、t κ和κ∞分别代表时间为0、t 和∞(反应完毕)时溶液的电导率,则在稀溶液中有:010=A c κ20=A c κ∞t 102=A (c -x)+A x κ式中A 1和A 2是与温度、溶剂和电解质的性质有关的比例常数,由上面的三式可得0t 00-x=-c -κκκκ∞ (8) 将(8)式代入(7)式得: 0t 20t -1k =t c -κκκκ∞ (9) 整理上式得到t 20t 0=-k c (-)t+κκκκ∞ (10)以t κ对t (-)t κκ∞作图可得一直线,直线的斜率为20-k c ,由此可以得到反应速率系数2k 。
习题五1试检验不同日期生产的钢锭的平均重量有无显著差异?(α=0.05) 解 根据问题,因素A 表示日期,试验指标为钢锭重量,水平为5.假设样本观测值(1,2,3,4)ij y j =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .检验的问题:01251:,:i H H μμμμ===不全相等 .计算结果:表5.1 单因素方差分析表注释: 当=0.001表示非常显著,标记为 ‘***’,类似地,= 0.01,0.05,分别标记为 ‘**’ ,‘*’ .查表0.95(4,15) 3.06F =,因为0.953.9496(4,15)F F =>,或p = 0.02199<0.05, 所以拒绝0H ,认为不同日期生产的钢锭的平均重量有显著差异.2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验 试检验在四种不同催化剂下平均得率有无显著差异?(α=0.05)解根据问题,设因素A 表示催化剂,试验指标为化工产品的得率,水平为4 .假设样本观测值(1,2,...,)ij i y j n =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .其中样本容量不等,i n 分别取值为6,5,3,4 .检验的问题:012341:,:i H H μμμμμ===不全相等 .计算结果:表5.2 单因素方差分析表查表0.95(3,14) 3.34F =,因为0.952.4264(3,14)F F =<,或p = 0.1089 > 0.05,所以接受0H ,认为在四种不同催化剂下平均得率无显著差异 .3 试验某种钢的冲击值(kg ×m/cm2),影响该指标的因素有两个,一是含铜量A ,另试检验含铜量和试验温度是否会对钢的冲击值产生显著差异?(α=0.05) 解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用.设因素,A B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为12.假设样本观测值(1,2,3,1,2,3,4)ij y ij ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ=1,2,3,4j = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零;(2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; 计算结果:表5.3 双因素无重复试验的方差分析表查表0.95(2,6) 5.143F =,0.95(3,6) 4.757F =,显然计算值,A B F F 分别大于查表值,或p = 0.0005,0.0009 均显著小于0.05,所以拒绝1020,H H ,认为含铜量和试验温度都会对钢的冲击值产生显著影响作用.设每个工人在每台机器上的日产量都服从正态分布且方差相同 .试检验:(α=0.05)1)操作工之间的差异是否显著? 2)机器之间的差异是否显著?3)它们的交互作用是否显著?解 根据问题,这是一个双因素等重复(3次)试验的问题,要考虑交互作用.设因素,A B 分别表示为机器和操作,试验指标为日产量,水平为12. 假设样本观测值(1,2,3,1,2,3,4)ijk y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ= 1,2,3,4j =,1,2,3k = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;记ij γ为对应于交互作用A B ⨯的主效应; 检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; (3)30:ij H γ全部等于零,31:ij H γ不全等于零;计算结果:表5.4 双因素无重复试验的方差分析表查表0.95(3,24) 3.01F =,0.95(2,24) 3.4F =,0.95(6,24) 2.51F =,计算值 3.01,A F <3.4, 2.51B A B F F ⨯>>,或0.05A p >>,而,B A B p p ⨯均显著小于0.05,所以拒绝2030,H H ,接受10H ,认为操作工之间的差异显著,机器之间的差异不显著,它们之间的交互作用显著 . 5 某轴承厂为了提高轴承圈退火的质量,制定因素水平分级如下表所示因素 上升温度℃ 保温时间(h)出炉温度℃水平1 800 6 400 水平28208500试填好正交试验结果分析表并对试验结果进行直观分析和方差分析 .解 根据题意,这是一个3因素2水平的试验问题 .试验指标为硬度的合格率 .应选择正交表44(2)L 来安排试验,随机生成正交试验表如下:方差来源 自由度 平方和 均方 F 值 P 值 因素A 因素B 相互效应A ×B误差 总和3 2 6 24 352.750 27.167 73.5 41.333 144.750.917 13.583 12.250 1.7220.5323 7.8871 7.11290.6645 0.00233** 0.00192**由此可见第三号试验条件为:上升温度800℃、保温时间6h 、出炉温度500℃ . 直观分析需要计算K 值,计算结果如下:表5.6 计算表直观分析 由计算的K 值知,因素A 、B 、C 的极差分别为70,40,40,因此主次关系为A B C >=,B ,C 相当 .由于试验指标为硬度的合格率,应该是越大越好,所以各确定因素的水平分别是121,,A B C ,即最佳的水平组合是121A B C ,即最佳搭配为:上升温度800℃、保温时间8h 、出炉温度400℃.采用方差分析法,计算得下表:表5.7 方差分析表方差来源平方和 自由度均方差 F 值 A 1225 1 1225 1 B 400 1 400 0.33 C 400 1 400 0.33 误差 1225 1 1225 总和32504如果显著性检验水平取0.1α=,则查表得0.9(1,1)39.9F =,显然计算的F 值1,0.33A B C F F F ===均小于查表值,所以认为三个因素对结果影响都显著 .6问应选用哪张正交表安排试验,并写出第8号试验的条件;如果9组试验结果为(单位:kg/100m 2):62.925,57.075,51.6,55.05,58.05,56.55,63.225,50.7,54.45,试对该正交试验结果进行直观分析和方差分析.解 该问题属于3因素3水平的试验问题,试验指标为水稻产量 .根据题意应选择正交表49(3)L 来安排试验,随机生成正交表如下:由表可知,第8号试验的条件:品种(A 3)珍珠矮11号,插值密度(B 2)3.75棵/100m 2 ,施肥量(C 1)0.75kg/100m 2纯氨; 直观分析需要计算K 值,计算结果如下:表5.9 计算表同上题进行直观分析,得出K 值的大小关系为:111312212223333132,,K K K K K K K K K >>>>>>由直观分析看出:本例较好的水平搭配是:113A B C 采用方差分析法,计算得下表:表5.10 方差分析表方差来源平方和自由度 均方差F 值A 1.759 2 0.879 0.0223B 65.861 2 32.931 0.8361C 6.660 2 3.330 0.0845 误差78.776 239.388 39.3880.9(2,2)9F =,所以认为三个因素对结果影响都不显著.7 在阿魏酸的合成工艺考察中,为了提高产量,选取了原料配比A ,吡啶量B 和反应时间C 三个因素,它们各取了7个水平如下:原料配比A :1.0,1.4,1.8,2.2,2.6,3.0,3.4 吡啶量B :10,13,16,19,22,25,28 反应时间C :0.5,1.0,1.5,2.0,2.5,3.0,3.5试选用合适的均匀设计表安排试验,并写出第7号试验的条件;如果7组试验的结果(收率)为:0.33,0.336,0.294,0.476,0.209,0.451,0.482,试对该均匀试验结果进行直观分析并通过回归分析发现可能更好的工艺条件.解 根据题意选择均匀设计表47(7)U 来安排试验,有3个因素,根据使用表,实验安排如:表5.11 试验安排表6 6 5 4 0.4517 7 7 7 0.482 所以第7号实验的条件为:原配料比3.4,吡啶量28ml,反应时间3.5h.通过直观分析,最好的实验条件是:原配料比3.4,吡啶量28ml,反应时间3.5h. 通过回归分析,最合适的实验条件是:原配料比2.6,吡啶量16ml,反应时间0.5h.习题六1 从某中学高二女生中随机选取8名,测得其升高、体重如下:1 2 3 4 5 6 78身高(cm)160 159 160 157 169 162 165 154体重(kg)49 46 53 41 49 50 48 43在绝对距离下,试用最短距离法和离差平方和法对其进行聚类分析.解由R软件,用最短距离(左)和差离平方和法(右)对题目进行聚类分析如下图6.1,表6.1和表6.2:最短距离法离差平方和法图6.1 聚类树形图表6.1 聚类附表(最短距离法)步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 6 5.000 0 0 22 1 2 10.000 1 0 43 4 8 13.000 0 0 74 1 7 13.000 2 0 55 1 3 13.000 4 0 66 1 5 17.000 5 0 7表6.2 聚类附表(离差平方和法)2 已知五个变量的距离矩阵为03674012340444401592343331).;2);3)036034022020401000⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭试用最短距离法和最长距离法对这些变量进行聚类,并画出聚类图和二分树.解 针对距离矩阵1),采用两种方法计算如下. ①最短距离法的聚类步骤如下:12345036740159036020w w w w w ⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭a )将()236,1w w f h =合并为一类,,{}11456,,,,H w w w h =距离矩阵如下0743023060⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}()457457),,,2b w w h w w f h ==合并为一类,{}2167,,,H w h h =距离矩阵如下:034030⎛⎫ ⎪⎪ ⎪⎝⎭{}()()1681689),,3,3c w h h w h f h f h ===合并为一类,最后,,聚类图和树状图如图6.2:图6.2 聚类图(左)与树状图(右)②最长距离法与最短距离法类似,步骤如下: a )()236,1w w f h =合并为一类,{}11456,,,,H w w w h =距离矩阵如下0746025090⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭ {}(){}4574572167),,,2,,,b w w h w w f h H w h h ===合并为一类,距离矩阵如下:067090⎛⎫⎪⎪ ⎪⎝⎭{}()()1681689),,69c w h h w h f h f h ===合并为一类,最后,,,聚类图和树状图如图6.3:图6.3 聚类图(左)与树状图(右)(2)针对距离矩阵2)012340234034040⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭①最短距离法的聚类步骤如下 a )()216,1w w f h =合并为一类,{}13456,,,,0342043040H w w w h =⎛⎫⎪⎪ ⎪ ⎪⎝⎭距离矩阵如下{}()367367),,,2b w h h w h f h ==合并为一类,{}24567,,,,H w w h h =聚类矩阵如下:043040⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,聚类图和树状图如图6.4:图6.4 聚类图(左)与树状图(右)②由于本题数据的特殊性,最长距离法与最短距离法结果相同(略). (3)044440333022010⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭最短距离法的聚类步骤如下a ) ()456,1w w f h =合并为一类,{}11236,,,,H w w w h =距离矩阵如下0444033020⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}36736724567),,,2,,,,b w h h w h f h H w w h h ===合并为一类,距离矩阵如下:044030⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,,聚类图和树状图如图6.5:图6.5 聚类图(左)与树状图(右)由于本题数据的特殊性,最长距离法与最短距离法结果相同(略).3 在一项关于作物对土壤营养的反应的研究中,要测定土壤的总磷量和总氮量(占干物质重的百分比),今对10份土样测得数据如下:总氮量(%)0.63 1.19 2.30 1.29 0.73 0.52 0.33 0.61 0.47 0.66在绝对距离下,试用重心法对其进行聚类分析.解由R软件得到重心法聚类分析的结果如图6.6与表6.3:图6.6 聚类树形图表6.3 聚类过程记录表步骤聚类合并系数首次出现的阶段类别下一步组 1 组 2 组 1 组 21 1 8 .001 0 0 22 1 10 .002 1 0 43 6 9 .005 0 0 64 15 .010 2 0 75 2 4 .010 0 0 86 67 .027 3 0 77 1 6 .048 4 6 88 1 2 .459 7 5 99 1 3 2.572 8 0 0 4 1975年Dagnelie收集了11年的气象数据资料如下表变量年序x1x2x3x4其中:x 1—前一年11月12日的降水量;x 2—7月均温;x 3—7月降雨量;x 4—月日辐射,试对这四个气象因子进行主成分分析. 解 由R 软件分析得到如下表6.4,6.5:表6.4 各主成分的重要性:主成分1 主成分2 主成分3 主成分4 标准差 1.6103349 0.9890848 0.53407741 0.37854199 方差贡献率 0.6482947 0.2445722 0.07130967 0.03582351 累积贡献率0.64829470.89286680.964176491.00000000表6.5 因子荷载:主成分1 主成分2 主成分3 主成分4 X1 0.291 0.871 0.332 -0.214 X2 -0.506 0.425 -0.742 -0.111 X3 0.577 0.136 -0.418 0.688 X4-0.5710.2050.4040.685由于前两个主成分对应的累积贡献率已经达到89.287,因此选取主成分的数目为2.5 对某初中12岁的女生进行体检,测量其身高x 1、体重x 2、胸围x 3和坐高x 4,共测得58个样本,并算得1234(,,,)x x x x x ='的样本协方差为19.9410.5023.566.5919.7120.958.637.97 3.937.55S ⎛⎫ ⎪⎪= ⎪ ⎪ ⎪⎝⎭ 试进行样本主成分分析.解 首先计算样本的相关系数矩阵:10.484410.32240.887210.70330.59760.31251⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭设相关系数矩阵的特征值和特征向量分别为d 和v 阵,计算得到0.0546000 0 0.312600= 000.96470 000 2.6681d ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭即四个特征值依次为:2.6681,0.9647,0.3126,0.0546,前两个主成分的累计贡献率为:90.8471%,因此提取主成分为2.四个特征根相应的特征向量为0.06000.70600.5333 0.4620 0.7317 0.17430.34040.5642=0.60570.19320.60400.48060.30690.65870.48460.4870v -⎛⎫ ⎪-⎪ ⎪--- ⎪-⎝⎭ 因此,两个主成分的表达式为:112340.060.73170.60570.3069z x x x x =+-- 212340.7060.17430.19320.6587z x x x x =-+-+6 比较因子分析和主成分分析模型的异同,阐明两者的关系. 解(1)提取公因子的方法主要有主成分法和公因子法.若采取主成分法,则主成分分析和因子分析基本等价,该法从解释变量的变异的角度出发,尽量使变量的方差能被主成分解释;而公因子法主要从解释变量的相关性角度,尽量使变量的相关程度能被公因子解释,当因子分析目的重在确定结构时则用到该法.(2)主成分分析和因子分析都是在多个原始变量中通过他们之间的内部相关性来获得新的变量,达到既减少分析指标个数,又能概括原始指标主要信息的目的.但他们各有其特点:主成分分析是将n 个原始变量提取m 个支配原始变量的公因子,和1个特殊因子,各因子之间可以相关或不相关.(3)统用降维的方法,但差异也很明显:主成分分析把方差划分为不同的正交成分,而因子分析则把方差化分为不同的起因因子;因子分析中的特征值的计算只能从相关系数矩阵出发,且必须把主成分划分为因子.(4)因子分析提取的公因子比主成分分析提取的主成分更具有可解释性.(5)两者分析的实质及重点不同.主成分的数学模型为Y AX =,因子分析的数学模型为X AF ε=+.因而可知主成分分析是实际上是线性变换,无假设检验,而因子分析是统计模型,某些因子模型是可以得到假设检验的;主成分分析主要综合原始数据的信息,而因子分析重在解释原始变量之间的关系.(6)SPSS 数据的实现:两者都通过“analyze data reduction Factor···”过程实现,但主成分分析主要使用“descriptires ”,“extraction ”,“stores ”对话框,而因子分析处使用这些外,还可使用“rotaction ”对话框进行因子旋转.7 试对第4题的变量作因子分析,并将结果和上面的结果进行比较. 解 用SPSS 分析,计算结果如下表6.6-6.8:表6.6 反应压缩比情况表 提取方法: 主成分法计算的相关系数矩阵的特征值和方差贡献率:表6.7 方差解释度提取方法: 主成分法表6.8 主成分矩阵8 为研究某一树种的叶片形态,选取50片叶测量其长度x 1(mm )和宽度x 2(mm ),按样本数据求得其平均值和协方差矩阵为:129048134,92,4845x x S ⎛⎫=== ⎪⎝⎭求出相关系数阵R ,并由R 出发作因子分析;解1)求相关系数矩阵:904810.7303,48900.73031S R ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭ 2)用R 软件求R 的特征根及其相应的特征向量,软件输出结果如下:$values[1] 2.99393809 0.07273809 $vectors[,1] [,2] [1,] 0.7071068 -0.7071068 [2,] 0.7071068 0.7071068122.9939,0.0727,λλ∴==12(),()0.7071,0.7071-0.7071,0.7071T Tηη==3) 求载荷矩阵A :1.22350.19071.22350.1907A -⎛⎫= ⎪⎝⎭4)22121.5333, 1.5333,h h == 0.98810.154*0.98810.154A -⎛⎫= ⎪⎝⎭12121,1,0.3043,0.3043u u v v ===-=,222222000011112,0,()0.9074,20i i iii i i i i i A u B v C u v D u v =========-===∑∑∑∑9 1981年,生物学家Grogan 和Wirth 对两种蠓虫Af 和Apf 根据其触角长度x 1和翼长x 2进行了分类,分类的数据资料如下:Af 1 2 3 4 5 6 7 8 x 1 1.24 1.36 1.38 1.38 1.38 1.40 1.48 1.54 x 2 1.27 1.74 1.64 1.82 1.90 1.70 1.82 1.82 Apf 1 2 3 4 5 6 x 1 1.14 1.18 1.20 1.26 1.28 1.30 x 2 1.78 1.96 1.86 2.00 2.00 1.96 (1)试建立Af 和Apf 的Fisher 判别模型;(2)对样本(1.24,1.80),(1.28,1.84),(1.40,2.04)进行判别分类. 解 (1)建立Fisher 判别模型991122121111(,)(1.42,1.75),(,)(1.23,1.93)99T TT T i i i i i i x x y y μμ======∑∑120.08480.1490.01980.0218,0.1490.39120.02180.039A A ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭12120.0080.0130.0130.0332A A n n ⎛⎫+== ⎪+-⎝⎭∑()120.19,0.18Tμμ-=-,()()121 1.325,1.842T μμ+= 1345.05135.42135.4283.33--⎛⎫= ⎪-⎝⎭∑, 带入Fisher 判别函数 ()12345.05135.42[(,)(1.325,1.84)]0.19,0.18135.4283.33Tx x -⎛⎫-- ⎪-⎝⎭1291.301741.336944.534x x =--(2)把三个样本(1.24,1.80),(1.28,1.84),(1.4,2.04)带入模型,得到结果:三个样本均属于Apf 类.10 在两个玉米品种之间进行判别:137玉米G 1和甜玉米G 2,选取的两个变量是:x 1—玉米果穗长;x 2—玉米果穗直径,两个类的样本容量为n 1=n 2=40,实际算得两个类的样本均值和样本协方差为:121218.5625.348.120 4.4589.661 3.720,,,5.98 4.12 4.458 4.350 3.720 3.410x x S S ⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭试建立G 1,G 2的Bayes 类线性判别函数.解 因为已知两类的样本均值和样本协方差为:12(18.56,5.98),(25.34,4.12)T T x x ==,128.120 4.4589.661 3.720,4.458 4.350 3.720 3.410S S ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭可计算得到修正的公共协方差矩阵和逆矩阵12120.2280.1450.1450.0992A A n n ⎛⎫+== ⎪+-⎝⎭∑,15.6393.738.25147.38--⎛⎫= ⎪-⎝⎭∑()()()121216.78,1.86,21.95,5.052TTμμμμ-=-+= 带入Fisher 判别函数()112121(())()2T W x x μμμμ-=-+-∑ ()()12 5.6393.73[(,)21.95,5.05] 6.78,1.868.25147.38Tx x -⎛⎫=-- ⎪-⎝⎭1274.396.951141.29x x =-+-。
【清华】实验报告_液体饱和蒸气压测定_丛乐精品文档精品文档PAGE #实验4 液体饱和蒸气压的测定丛乐2005011007 生51实验日期:2007年11月24日星期六提交报告日期:2007年12月8日星期六助教老师:叶逢春1 引言1.1 实验目的1.运用克劳修斯-克拉贝龙方程,求出所测温度范围内平均摩尔气化焓及正常沸点。
2.掌握测定饱和蒸汽压的方法。
1.2 实验原理在通常温度下(距离临界温度较远时),纯液体与其蒸气达平衡时的蒸气压称为该温度下液体的饱和蒸气压,简称为蒸气压。
蒸发1 摩尔液体所吸收的热量称为该温度下液体的摩尔气化热。
液体的蒸气压与液体的本性及温度等因素有关。
随温度不同而变化,温度升高时,蒸气压增大;温度降低时,蒸气压降低,这主要与分子的动能有关。
当蒸气压等于外界压力时,液体便沸腾,此时的温度称为沸点,外压不同时,液体沸点将相应改变,当外压为? p?(101.325kPa)时,液体的沸点称为该液体的正常沸点。
液体的饱和蒸气压与温度的关系用克劳修斯(Clausius)-克拉贝龙(Clapeyron )方程式表示:式中,R 为摩尔气体常数;T 为热力学温度;ΔvapHm为在温度T 时纯液体的摩尔气化热。
假定ΔvapHm 与温度无关,或因温度变化范围较小,ΔvapHm可以近似作为常数,积分上式,得:A ln p BT或A ln p BT vapHm Rm式中:B——积分常数。
从上式可知:若将ln p对1/T 作图应得一直线,斜率m=-A vapHm / R由此可得vapHm Rm ,同时从图上可求出标准压力时的正常沸点。
2 实验操作2.1 实验药品、仪器型号及测试装置示意图1.仪器等压管1 支、稳压瓶1个、负压瓶1 个、恒温槽1 套、冷凝管1个、真空泵1 台、自耦调压变压器1 台(TDG1/250 型)、搅拌器 1 个、压力计1台(LZ-PI 型)、温度测量控制仪1 台(CK-1B 型)。
实验12回归分析
化工系分7陈龙2007011832
『实验目的』
1.了解回归分析的基本原理,掌握MATLAB 实现的方法;
2.练习用回归分析解决实际问题。
『实验内容』
一、题目1:
用切削机床加工时,为实时地调整机床需测定刀具的磨损速度,每隔一小时测量刀具的厚度得到以下数据,建立刀具厚度对于切削时间的回归模型,对模型和回归系数进行检验,并预测7.5h 和15h 后的刀具厚度,用(30)和(31)式两种办法计算预测区间,解释计算结果。
时间/h 012345678910刀具厚度/cm 30.6
29.1
28.4
28.1
28.0
27.7
27.5
27.2
27.0
26.8
26.5
【模型建立】
设时间为i x ,对应的刀具厚度为i y ,作出y-x 散点图观察:x=0:10;
y=[30.629.128.428.128.027.727.527.227.026.826.5]';plot(x,y,'+')
可以观察出,y-x 是可以建立线性回归模型的。
设x y 10ββ+=,下面用MATLAB 计算回归系数。
【模型求解】X=[ones(11,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);b,bint,s
rcoplot(r,rint)得到的结果为:b =29.5455
-0.3291
bint =28.976930.1140
-0.4252-0.2330s =0.869660.00180.0000
0.1985
观察到第一个数据的残差的置信区间不包含零点,是异常数据,应舍去。
x(1)=[];y(1)=[];
X=[ones(10,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);b,bint,s
rcoplot(r,rint)得到的结果为:
b=29.0533
-0.2588
bint=28.833429.2732
-0.2942-0.2233
s=0.9726283.55990.00000.0195
可见剩下的第一个数据的残差的置信区间仍不包含零点,还是不满足要求,应再剔除。
x(1)=[];
y(1)=[];
X=[ones(9,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);
b,bint,s
rcoplot(r,rint)
得到的结果为:
b=28.8667
-0.2333
bint=28.779628.9537
-0.2467-0.2200
s=0.995917150.00000.0019
可见去掉了前两个数据后,余下的9个数据没有异常情况,并且回归系数的置信区间小了,F 值大了,剩余方差小了,都对回归分析有利。
取第三次计算得到的b ,可以得到回归模型为x y 2333.08667.28-=。
下面作图检验该线性回归方程:
【模型应用】
用以上建立的模型,可以得到预测值:
1)当时间为7.5h 时,y(7.5)=28.8667-0.2333*7.5=27.1167;a1=tinv(1-0.05/2,7);x(1:2)=[];sxx=var(x)*8;
c1=a1*sqrt(s(4))*sqrt((7.5-mean(x))^2/sxx+1/9+1)
得到c1=0.1104,所以用(30)式算得的预测区间为[27.0063,27.2271];a2=norminv(0.975,0,1);c2=a2*s(4)
得到c2=0.0855,所以用(31)式算得的预测区间为[27.0311,27.2022]。
2)当时间为15h 时,y(15)=28.8667-0.2333*15=25.3667。
c3=a1*sqrt(s(4))*sqrt((15-mean(x))^2/sxx+1/9+1);
得到c3=0.1569,所以用(30)式算得的预测区间为[25.2098,25.5236];c4=c2=0.0855,所以用(31)式算得的预测区间为[25.2811,25.4522]。
【结果解释】
用(30)式与(31)式算的预测区间不大一样,后者是当n 较大且x0接近x 的平均值时的极限结果,因此不确定的范围会小一些,而前者则是在n 有限的情况下得到的,为了使结果准确,预测区间的范围就应该大一点。
----------------------------------------------------------------------------------------------------------------------
二、题目2:
电影院调查电视广告费用和报纸广告费用对每周收入的影响,得到下面的数据,建立回归模型并进行检验,诊断异常点的存在并进行处理。
每周收入9690959295959494电视广告费用 1.5 2.0 1.5 2.5 3.3 2.3 4.2 2.5报纸广告费用
5.0
2.0
4.0
2.5
3.0
3.5
2.5
3.0
【模型假设】
设电视广告费用为x1,报纸广告费用为x2,每周收入为y ,x1=[1.52.01.52.53.32.34.22.5]’x2=[5.02.04.02.53.03.52.53.0]’x=[x1,x2];
y=[9690959295959494]’;rstool(x,y,'linear',0.05)
在命令窗口中分别调整model ,依次对linear,purequadratic,interaction,quadratic 四种形式进行计算,比较剩余标准差,结果如下:
linear 0.6998,purequadratic 0.2497,interaction 0.4527,quadratic 0.1415。
因此对于全体数据,采用quadratic 模式,即包含线性项和完全二次项的形式是最佳的。
但是出于方便,先考虑剩余标准差最大的线性回归形式:22110x x y βββ++=。
之后再讨论
【模型求解】
X=[ones(8,1)x];
[b,bint,r,rint,s]=regress(y,X);
b,bint,s
rcoplot(r,rint)
结果如下:
b=83.2116
1.2985
2.3372
bint=78.805887.6174
0.4007 2.1962
1.4860 3.1883
s=0.908924.94080.00250.4897
很遗憾,第一组数据的残差区间未包含零点,舍弃该数据再做尝试。
x(1,:)=[];
y(1)=[];
X=[ones(7,1)x];
[b,bint,r,rint,s]=regress(y,X);
b,bint,s
rcoplot(r,rint)
b =81.4881
1.2877
2.9766
bint =78.787884.1883
0.7964 1.77902.3281 3.6250s =0.976884.38420.0005
0.1257
这样得到的残差区间均符合要求,因此可以采用线性模型
219766.22877.14181.81x x y ++=。
在去掉了第一组数据后,再用rstool 命令运算一遍,会发现linear,purequadratic,interaction,quadratic 四种形式依次输出的剩余标准差为0.3545,0.2648,0.1495,0.1600,于是最佳形式为interaction :21217369.05753.17137.03290.85x x x x y ++-=。