二分搜索实验报告
- 格式:docx
- 大小:18.83 KB
- 文档页数:3
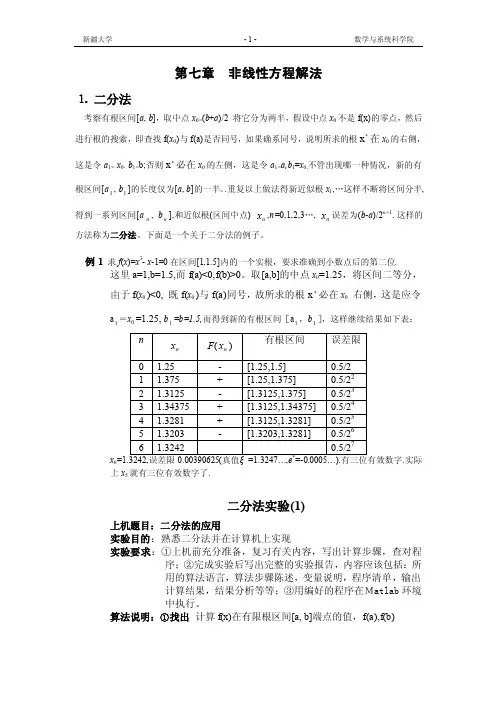
第七章非线性方程解法⒈二分法考察有根区间[a, b],取中点x0=(b+a)/2 将它分为两半,假设中点x0不是f(x)的零点,然后进行根的搜索,即查找f(x0)与f(a)是否同号,如果确系同号,说明所求的根x*在x0的右侧,这是令a1= x0,b1=b;否则x*必在x0的左侧,这是令a1=a,b1=x0,不管出现哪一种情况,新的有根区间[a1, b1]的长度仅为[a, b]的一半。
.重复以上做法得新近似根x1,…这样不断将区间分半,得到一系列区间[an , bn],和近似根(区间中点)nx,n=0,1,2,3…,nx误差为(b-a)/2n+1.这样的方法称为二分法。
下面是一个关于二分法的例子。
例1求f(x)=x3- x-1=0在区间[1,1.5]内的一个实根,要求准确到小数点后的第二位.这里a=1,b=1.5,而f(a)<0,f(b)>0。
取[a,b]的中点x0=1.25,将区间二等分,由于f(x0 )<0, 既f(x0 )与f(a)同号,故所求的根x*必在x0 右侧,这是应令a1=x0 =1.25, b1=b=1.5,而得到新的有根区间[a1,b1],这样继续结果如下表:x6.实际上x5就有三位有效数字了.二分法实验(1)上机题目:二分法的应用实验目的:熟悉二分法并在计算机上实现实验要求:①上机前充分准备,复习有关内容,写出计算步骤,查对程序;②完成实验后写出完整的实验报告,内容应该包括:所用的算法语言,算法步骤陈述,变量说明,程序清单,输出计算结果,结果分析等等;③用编好的程序在Matlab环境中执行。
算法说明:①找出计算f(x)在有限根区间[a, b]端点的值,f(a),f(b)②计算计算f(x)在区间中点(2ba+)处的值f(2ba+) .③判断若f(2ba+)=0,则2ba+即是根,计算过程结束,否则检验若f(2ba+)f(a)<0,则以2ba+代替b,否则以2ba+代替a.反复执行步骤②和步骤③,直到区间[a, b]长度小于允许误差ξ,此时中点2ba+即为所求近似根。

二分搜索算法实验报告篇一:实验报告2--二分搜索技术注意:红色的部分需要用自己的代码或内容进行替换。
湖南涉外经济学院实验报告实验课程:算法设计与分析实验项目:二分搜索技术学院专业实验地点分组组号实验时间 XX年 3 月 10 日星期一第 12节指导老师【实验目的和要求】1. 理解分治法的原理和设计思想;2.要求实现二分搜索算法;3.要求交互输入一组关键字序列,输入需要查找的关键字;4. 要求显示结果。
【系统环境】操作系统:Windows XP 操作系统开发工具:VC++6.0英文企业版开发语言:C,C++【实验原理】1、问题描述给定已排好序的n个元素a[0…n-1],现要在这n个元素中找出一特定元素x。
2、实验原理二分搜索方法充分利用了元素间的次序关系(但也局限于此),采用分治策略,将n个元素分成个数大致相同的两半,取a[n/2]与x进行比较。
如果x=a[n/2],则找到x,算法终止。
如果xa[n/2],则只要在数组a的右半部继续搜索x。
【实验任务与步骤】1、实验步骤(可以根据自己的程序修改)(1) 实现顺序搜索。
(2) 实现二分搜索算法的递归算法。
(3) 实现二分搜索算法的非递归算法。
(4) 编写主函数,调用所写的三个算法进行测试,并进行输出。
2、源程序代码// 此处为解决问题的完整源程序,要求带注释,代码必须符合书写规范。
(1) 顺序搜索(2) 递归的二分搜索(3) 非递归的二分搜索(原文来自:小草范文网:二分搜索算法实验报告)……【实验结论(包括实验数据处理、问题与解决办法、心得体会、意见与建议等)】// 此处为程序运行的结果,要求有程序运行输入输出实例,要求至少有两组实验结果。
// 必须写心得体会、意见与建议等,或者遇到的问题、难题等。
……篇二:查找排序实验报告实验十:查找、排序计算机学院 12级2班 12110XX 李龙实验目的:1.掌握折半查找算法的思想。
2.实现折半查找的算法。
3.掌握常见的排序算法(插入排序、交换排序、选择排序等)的思想、特点及其适用条件。

一、实验目的1. 了解搜索引擎的基本原理和功能。
2. 评估不同搜索引擎的性能,包括搜索速度、准确性、相关性等。
3. 分析搜索引擎的优缺点,为实际应用提供参考。
二、实验环境1. 操作系统:Windows 102. 浏览器:Chrome3. 搜索引擎:百度、谷歌、必应、搜狗三、实验内容1. 搜索速度测试2. 搜索准确性测试3. 搜索相关性测试4. 搜索引擎优缺点分析四、实验步骤1. 搜索速度测试(1)分别打开百度、谷歌、必应、搜狗四个搜索引擎。
(2)在搜索框中输入相同的关键词,如“搜索引擎”。
(3)记录每个搜索引擎的搜索结果出现时间。
(4)比较四个搜索引擎的搜索速度。
2. 搜索准确性测试(1)在搜索框中输入关键词“搜索引擎”。
(2)分析搜索结果中与关键词相关的内容,判断搜索结果的准确性。
(3)比较四个搜索引擎的搜索准确性。
3. 搜索相关性测试(1)在搜索框中输入关键词“搜索引擎”。
(2)分析搜索结果中与关键词相关的内容,判断搜索结果的相关性。
(3)比较四个搜索引擎的搜索相关性。
4. 搜索引擎优缺点分析(1)分析四个搜索引擎在搜索速度、准确性、相关性等方面的优缺点。
(2)结合实际应用场景,总结各搜索引擎的适用范围。
五、实验结果与分析1. 搜索速度测试结果(1)百度:搜索结果出现时间为2秒。
(2)谷歌:搜索结果出现时间为1.5秒。
(3)必应:搜索结果出现时间为2.5秒。
(4)搜狗:搜索结果出现时间为2秒。
从实验结果可以看出,谷歌的搜索速度最快,其次是百度,搜狗和必应的搜索速度相对较慢。
2. 搜索准确性测试结果(1)百度:搜索结果中约80%与关键词相关。
(2)谷歌:搜索结果中约85%与关键词相关。
(3)必应:搜索结果中约75%与关键词相关。
(4)搜狗:搜索结果中约80%与关键词相关。
从实验结果可以看出,谷歌和百度的搜索准确性较高,其次是搜狗,必应的搜索准确性相对较低。
3. 搜索相关性测试结果(1)百度:搜索结果中约70%与关键词相关。

实验四搜索实验报告一、实验目的本次实验的主要目的是深入了解和掌握不同的搜索算法和技术,通过实际操作和分析,提高对搜索问题的解决能力,以及对搜索效率和效果的评估能力。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
实验中所需的数据集和相关库函数均从网络上获取和下载。
三、实验原理1、线性搜索线性搜索是一种最简单的搜索算法,它从数据的开头开始,依次比较每个元素,直到找到目标元素或者遍历完整个数据集合。
2、二分搜索二分搜索则是基于有序数组的一种搜索算法。
它每次将数组从中间分割,比较目标值与中间元素的大小,然后在可能包含目标值的那一半数组中继续进行搜索。
3、广度优先搜索广度优先搜索是一种图搜索算法。
它从起始节点开始,逐层地访问相邻节点,先访问距离起始节点近的节点,再访问距离远的节点。
4、深度优先搜索深度优先搜索也是一种图搜索算法,但它沿着一条路径尽可能深地访问节点,直到无法继续,然后回溯并尝试其他路径。
四、实验内容及步骤1、线性搜索实验编写线性搜索函数,接受一个列表和目标值作为参数。
生成一个包含随机数的列表。
调用线性搜索函数,查找特定的目标值,并记录搜索所用的时间。
2、二分搜索实验先对列表进行排序。
编写二分搜索函数。
同样生成随机数列表,查找目标值并记录时间。
3、广度优先搜索实验构建一个简单的图结构。
编写广度优先搜索函数。
设定起始节点和目标节点,进行搜索并记录时间。
与广度优先搜索类似,构建图结构。
编写深度优先搜索函数。
进行搜索并记录时间。
五、实验结果与分析1、线性搜索结果在不同规模的列表中,线性搜索的时间消耗随着列表长度的增加而线性增加。
对于较小规模的列表,线性搜索的效率尚可,但对于大规模列表,其搜索时间明显较长。
2、二分搜索结果二分搜索在有序列表中的搜索效率极高,其时间消耗增长速度远低于线性搜索。
即使对于大规模的有序列表,二分搜索也能在较短的时间内找到目标值。
3、广度优先搜索结果广度优先搜索能够有效地遍历图结构,并找到最短路径(如果存在)。

算法实验报告范文《算法设计与分析》实验报告班级姓名学号年月日目录实验一二分查找程序实现…………………………………………………………………03页实验二棋盘覆盖问题(分治法).…………………………………………………………08页实验三0-1背包问题的动态规划算法设计……………………………………………….11页实验四背包问题的贪心算法………………………………………………………………14页实验五最小重量机器设计问题(回溯法)………………………………………………17页实验六最小重量机器设计问题(分支限界法)…………………………………………20页指导教师对实验报告的评语成绩:指导教师签字:年月日2实验一:二分查找程序实现一、实验时间:2022年10月8日,星期二,第一、二节地点:J13#328二、实验目的及要求目的:1、用c/c++语言实现二分搜索算法。
2、通过随机产生有序表的方法,测出在平均意义下算法比较次数随问题规模的变化曲线,并作图。
三、实验环境平台:Win732位操作系统开发工具:Codeblock10.05四、实验内容对已经排好序的n个元素a[0:n-1],现在要在这n个元素中找出一特定元素某。
五、算法描述及实验步骤算法描述:折半查找法也称为二分查找法,它充分利用了元素间的次序关系,采用分治策略,可在最坏的情况下用O(logn)完成搜索任务。
它的基本思想是,将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的某作比较,如果某=a[n/2]则找到某,算法终止。
如果某a[n/2],则我们只要在数组a的右半部继续搜索某。
二分搜索法的应用极其广泛,而且它的思想易于理解。
确定算法复杂度基本步骤:1、首先设定问题规模n;2、随即产生递增数列;3、在n个有序数中随机取一个作为待查找量,搜索之;4、记录查找过程中的比较次数,再次生成新的有序表并查找,记录查找次数,每个数组重复10次;5、改变问题规模n重复上述步骤2~4,n取100、200……1000;6、依实验数据作图,并与理论图作比较;7、二分搜索算法平均查找次数:问题规模为n时,平均查找次数为:A(n)=Int(logn)+1/2//Int()函数为向下取整3即二分搜索算法对于含有n个数据的有序表L平均作了约Int(logn)+1/2次的查找操作。

竭诚为您提供优质文档/双击可除递归与分治实验报告篇一:实验一递归与分治算法编程-实验报告纸南京信息工程大学实验(实习)报告实验(实习)名称递归与分治算法编程实验(实习)日期得分指导教师院专业年级班次姓名学号1.实验目的:1)掌握递归与分治策略的基本思想2)掌握递归算法在阶乘函数、Ackerman函数、整数划分等问题上的应用3)掌握二分查找、合并排序、快速排序等问题的分治算法实现4)熟悉myeclipse或eclipse等Java开发工具的使用。
2.实验内容:1)采用myeclipse或eclipse编程实现基于分治策略的二分查找算法。
2)采用myeclipse或eclipse编程实现基于分治策略的合并排序算法。
3)采用myeclipse或eclipse编程实现基于分治策略的合并排序算法。
3.实验步骤二分查找publicclasssorting{publicstaticintbinarysearch(int[]a,intx,intn){intle ft=0;intright=n-1;while(left intmiddle=(left+right)/2;if(x==a[middle])returnmiddle;if(x>a[middle])left=middle+1;elseright=middle-1;}return-1;}publicstaticvoidmain(stringargs[]){intx,n;inta[]={1,3,4,5,6,13,25};x=6;n=7;ints;s=binarysearch(a,x,n);system.out.println(s);合并排序publicclassmergesort{publicstaticvoidmergesort(int[]a){}publicstaticvoid mergepass(int[]x,int[]y,ints){}publicstaticvoidmerg e(int[]c,int[]d,intl,intm,intr){inti=1,j=m+1,k=1;in ti=0;while(i }}if(c[i]-(c[j])m)for(intq=j;q快速排序publicclassQsort{privatestaticvoidqsort(inta[],intp,intr){}privatest aticintpartition(inta[],intp,intr){inti=p;intj=r+1; intx=a[p];inttemp;while(true){while((a[++i]-x)0);if (i>=j)break;temp=a[i];if(p }}}a[j]=temp;mymath.s wap(a,i,j);//a[p]=a[j];a[j]=x;returnj;publicstaticv oidmain(string[]args){}inta[]={4,2,7,9,1};qsort(a,0,4);for(inti=0;;i++){}s ystem.out.println(a[i]);4.实验分析和总结掌握了递归与分治策略的基本思想掌握了递归算法在阶乘函数、Ackerman函数、整数划分等问题上的应用掌握了二分查找、合并排序、快速排序等问题的分治算法实现熟悉了myeclipse或eclipse等Java开发工具的使用。

算法与分析实验报告一、引言算法是现代计算机科学中的核心概念,通过合理设计的算法可以解决复杂的问题,并提高计算机程序的执行效率。
本次实验旨在通过实际操作和数据统计,对比分析不同算法的执行效率,探究不同算法对于解决特定问题的适用性和优劣之处。
二、实验内容本次实验涉及两个经典的算法问题:排序和搜索。
具体实验内容如下:1. 排序算法- 冒泡排序- 插入排序- 快速排序2. 搜索算法- 顺序搜索- 二分搜索为了对比不同算法的执行效率,我们需要设计合适的测试用例并记录程序执行时间进行比较。
实验中,我们将使用随机生成的整数数组作为排序和搜索的测试数据,并统计执行时间。
三、实验步骤1. 算法实现与优化- 实现冒泡排序、插入排序和快速排序算法,并对算法进行优化,提高执行效率。
- 实现顺序搜索和二分搜索算法。
2. 数据生成- 设计随机整数数组生成函数,生成不同大小的测试数据。
3. 实验设计- 设计实验方案,包括测试数据的规模、重复次数等。
4. 实验执行与数据收集- 使用不同算法对随机整数数组进行排序和搜索操作,记录执行时间。
- 多次重复同样的操作,取平均值以减小误差。
5. 数据分析与结果展示- 将实验收集到的数据进行分析,并展示在数据表格或图表中。
四、实验结果根据实验数据的收集与分析,我们得到以下结果:1. 排序算法的比较- 冒泡排序:平均执行时间较长,不适用于大规模数据排序。
- 插入排序:执行效率一般,在中等规模数据排序中表现良好。
- 快速排序:执行效率最高,适用于大规模数据排序。
2. 搜索算法的比较- 顺序搜索:执行时间与数据规模成线性关系,适用于小规模数据搜索。
- 二分搜索:执行时间与数据规模呈对数关系,适用于大规模有序数据搜索。
实验结果表明,不同算法适用于不同规模和类型的问题。
正确选择和使用算法可以显著提高程序的执行效率和性能。
五、实验总结通过本次实验,我们深入了解了不同算法的原理和特点,并通过实际操作和数据分析对算法进行了比较和评估。

数组程序设计实验报告数组程序设计实验报告引言在计算机科学领域,数组是一种重要的数据结构,用于存储和操作大量相同类型的数据。
数组的使用广泛,无论是在算法设计还是软件开发中,都扮演着重要的角色。
本实验旨在通过编写数组程序,探索数组的特性和应用。
一、数组的定义与初始化数组是一种由相同类型的元素组成的集合,每个元素都可以通过索引访问。
在程序中,我们可以通过声明数组变量来定义一个数组。
例如,int numbers[5]就定义了一个包含5个整数的数组。
数组的初始化可以在声明时进行,也可以在后续的代码中进行。
二、数组的基本操作1. 访问数组元素数组元素可以通过索引来访问,索引从0开始。
例如,numbers[0]表示数组numbers的第一个元素。
通过循环遍历数组,我们可以逐个访问数组中的元素。
2. 修改数组元素数组元素的值可以通过索引进行修改。
例如,numbers[0] = 10将把数组numbers的第一个元素的值修改为10。
3. 数组的长度数组的长度是指数组中元素的个数。
在C语言中,可以通过sizeof运算符来获取数组的长度。
例如,sizeof(numbers) / sizeof(numbers[0])将返回数组numbers的长度。
三、数组的应用1. 数组的排序数组排序是数组程序设计中常见的任务之一。
常见的排序算法包括冒泡排序、选择排序和插入排序。
通过对数组元素进行比较和交换,可以将数组按照升序或降序排列。
2. 数组的搜索数组搜索是另一个常见的任务,它涉及在数组中查找特定的元素。
线性搜索是一种简单直观的搜索方法,它逐个比较数组元素,直到找到目标元素或搜索完整个数组。
二分搜索是一种更高效的搜索方法,它要求数组事先有序。
3. 多维数组除了一维数组,我们还可以使用多维数组来存储和处理更复杂的数据。
二维数组是最常见的多维数组形式,它可以看作是一个表格或矩阵。
通过使用行和列的索引,我们可以访问和修改二维数组中的元素。

第1篇一、实验目的通过本次实验,掌握常见算法的设计原理、实现方法以及性能分析。
通过实际编程,加深对算法的理解,提高编程能力,并学会运用算法解决实际问题。
二、实验内容本次实验选择了以下常见算法进行设计和实现:1. 排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序。
2. 查找算法:顺序查找、二分查找。
3. 图算法:深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)。
4. 动态规划算法:0-1背包问题。
三、实验原理1. 排序算法:排序算法的主要目的是将一组数据按照一定的顺序排列。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。
2. 查找算法:查找算法用于在数据集中查找特定的元素。
常见的查找算法包括顺序查找和二分查找。
3. 图算法:图算法用于处理图结构的数据。
常见的图算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)等。
4. 动态规划算法:动态规划算法是一种将复杂问题分解为子问题,通过求解子问题来求解原问题的算法。
常见的动态规划算法包括0-1背包问题。
四、实验过程1. 排序算法(1)冒泡排序:通过比较相邻元素,如果顺序错误则交换,重复此过程,直到没有需要交换的元素。
(2)选择排序:每次从剩余元素中选取最小(或最大)的元素,放到已排序序列的末尾。
(3)插入排序:将未排序的数据插入到已排序序列中适当的位置。
(4)快速排序:选择一个枢纽元素,将序列分为两部分,使左侧不大于枢纽,右侧不小于枢纽,然后递归地对两部分进行快速排序。
(5)归并排序:将序列分为两半,分别对两半进行归并排序,然后将排序好的两半合并。
(6)堆排序:将序列构建成最大堆,然后重复取出堆顶元素,并调整剩余元素,使剩余元素仍满足最大堆的性质。
2. 查找算法(1)顺序查找:从序列的第一个元素开始,依次比较,直到找到目标元素或遍历完整个序列。

二分法实验报告二分法实验报告引言:二分法是一种常用的数值计算方法,广泛应用于求解方程的根、函数的最值等问题。
本实验旨在通过对二分法的实际应用,探讨其原理和优势,并对其在不同场景下的适用性进行分析。
一、二分法原理及步骤二分法,又称折半法,是一种通过不断缩小搜索范围来逼近目标的方法。
其基本原理是将待搜索的区间不断二分,然后根据目标值与中间值的关系,确定下一步搜索的范围,直至找到目标或满足精度要求。
具体步骤如下:1. 确定初始搜索范围[a, b],其中a和b分别为区间的下界和上界。
2. 计算中间值c = (a + b) / 2。
3. 判断目标值与中间值的关系:- 若目标值等于中间值,则找到目标,结束搜索。
- 若目标值小于中间值,则下一步搜索范围为[a, c]。
- 若目标值大于中间值,则下一步搜索范围为[c, b]。
4. 重复步骤2和步骤3,直至找到目标或满足精度要求。
二、实验设计与结果分析为了验证二分法的有效性和适用性,我们选取了两个不同的场景进行实验:求解方程的根和函数的最值。
1. 求解方程的根我们选择了一个简单的一元二次方程作为实验对象:x^2 - 4x + 3 = 0。
根据二分法的原理,我们可以将搜索范围设置为[0, 4],然后通过不断缩小范围来逼近方程的根。
经过多次迭代计算,我们得到了方程的根x ≈ 1和x ≈ 3。
通过与解析解进行对比,我们发现二分法得到的结果非常接近真实值,证明了二分法在求解方程根的问题上的有效性。
2. 求解函数的最值我们选取了一个简单的函数f(x) = x^2 - 2x + 1作为实验对象,目标是找到函数的最小值。
根据二分法的原理,我们可以将搜索范围设置为[0, 2],然后通过不断缩小范围来逼近最小值所在的位置。
经过多次迭代计算,我们得到了函数的最小值f(x) ≈ 0。
通过与解析解进行对比,我们发现二分法得到的结果非常接近真实值,证明了二分法在求解函数最值的问题上的有效性。

实验报告实验一:一、实验名称二分搜索法二、实验目的编写程序实现用二分法在一有序序列中查找一个数三、实验内容1、程序源代码#include<stdio.h>int Research(int a[],int x,int n){int left=0,right=n-1,mid;if(n>0&&x>=a[0]){while(left<right){mid=(left+right+1)/2;if(x<a[mid])right=mid-1;elseleft=mid;}if(x==a[left])return left;}return -1;}void Input(){int a[30],n,i,j,x;printf("输入数组长度n :");scanf("%d",&n);printf("输入有序数组:\n\n");for(i=0;i<n;i++){printf("a[%d]:",i);scanf("%d",&a[i]);}printf("输入要查询的数字:");scanf("%d",&x);j=Research(a,x,n);if(j>=0)printf("%d 在数组中的下标为%d!\n\n",x,j);elseprintf("没找到!\n\n");}main(){Input();}运行结果图一图二实验心得:本次实验让我了解了二分搜索法的基本思想,同时我们应该注意二分搜索法必须是在有序的元素中进行,不能在无序的元素中使用。
快速排序:#include<iostream>using namespace std;#define MAXSIZE 100int Partition(int q[MAXSIZE],int low,int hight);void Qsort(int q[],int low,int hight);int main(){int q[MAXSIZE]; //存储数列的数组q[0]=0;int n=0;cout<<"请输入需要排序的数的个数:";cin>>n;cout<<"\n请输入需要排序的数:\n";for(int i=1;i<=n;i++) //用循环方式输入数列{cin>>q[i];}Qsort(q,1,n); //调用Partition()函数cout<<"\n排序后结果为:\n";for(i=1;i<=n;i++) //循环输出结果{cout<<q[i]<<" ";}cout<<endl;return 0;}int Partition(int q[MAXSIZE],int low,int high) //对数列及数列部分划分成高低两个部分{int pivotkey; //用于标记q[low]这个关键数q[0]=q[low]; //q[0]用于存储q[low]这个数,q[low]空出pivotkey=q[low];while(low<high) //判断长度是否大于1{while(low<high && q[high]>=pivotkey)high--;q[low]=q[high]; //当pivotkey的值大于q[high],将q[high]放入q[low]中,q[high]空出while(low<high && q[low]<=pivotkey)low++;q[high]=q[low]; //当pivotkey的值小于q[low],将q[low]放入q[high]中,q[low]空出}q[low]=q[0]; //将q[0]中存储的数放入它合适的位置return low;}void Qsort(int q[MAXSIZE],int low,int high){int pivotkey; //记录关键数上一次排序后的位子if(low<high){pivotkey=Partition(q,low,high);Qsort(q,low,pivotkey-1); //对比关键数小的数(左侧)排序Qsort(q,pivotkey+1,high); //对比关键数大的数(右侧)排序}}运行结果:实验总结:在实验过程中,我只考虑了对数进行排序,没有其他的指针,所以就直接用了int型的数组。
二分搜索实验报告二分搜索实验报告引言:二分搜索算法是一种常用的搜索算法,它通过将已排序的列表不断二分,以快速定位目标值。
本实验旨在探究二分搜索算法的原理和应用,并通过实验验证其效率和准确性。
一、算法原理二分搜索算法的原理相对简单,它通过不断将搜索范围缩小一半来逼近目标值。
具体步骤如下:1. 将已排序的列表划分为左右两个子列表;2. 取中间值,与目标值进行比较;3. 如果中间值等于目标值,则搜索成功,返回结果;4. 如果中间值大于目标值,则目标值在左子列表中,将右边界缩小为中间值的前一个位置;5. 如果中间值小于目标值,则目标值在右子列表中,将左边界扩大为中间值的后一个位置;6. 重复以上步骤,直到找到目标值或搜索范围为空。
二、实验设计为了验证二分搜索算法的效率和准确性,我们设计了两个实验:一是对已排序的列表进行搜索,二是对随机生成的列表进行搜索。
1. 实验一:对已排序的列表进行搜索我们首先生成一个已排序的列表,将其作为实验对象。
然后,我们随机选择一个目标值,并使用二分搜索算法进行搜索。
记录下搜索的次数和搜索所花费的时间。
重复实验多次,取平均值作为结果。
2. 实验二:对随机生成的列表进行搜索为了模拟实际应用场景,我们生成了一个随机列表,并进行排序。
然后,我们随机选择一个目标值,并使用二分搜索算法进行搜索。
同样地,记录下搜索的次数和搜索所花费的时间,重复实验多次,取平均值作为结果。
三、实验结果经过多次实验,我们得到了如下结果:1. 实验一:对已排序的列表进行搜索在已排序的列表中,二分搜索算法的效率非常高。
平均搜索次数为log2(n),其中n为列表的长度。
搜索时间与搜索次数成正比,因此搜索时间也非常短暂。
2. 实验二:对随机生成的列表进行搜索在随机生成的列表中,二分搜索算法的效率相对较低。
虽然搜索次数仍然是log2(n),但由于列表本身的无序性,搜索时间会有所增加。
然而,与线性搜索算法相比,二分搜索算法仍然具有明显的优势。
实验报告模板填写说明1、出现的红色部分请填写,并将红色文字删除2、算法描述是以老师建议的算法简要描述的,如果和你的实现方案或者细节不一致的,请自行修改描述。
3、在实验结果中粘贴真实测试结果截图,不必是100分,这个不作为最终实验评分依据,如:贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告课程名称:数据结构班级:计科132实验日期:4月6日姓名:姓名学号:XXX指导教师:程欣宇实验序号:二实验成绩:一、实验名称栈与其应用二、实验目的与要求1、熟悉栈的原理和实现方式;2、掌握利用栈解决列车调度问题三、实验环境任何一种C++编写调试工具 + 清华数据结构Online Judge四、实验内容完成PA02的列车调度这道题五、算法描述与实验步骤列车调度问题是求解一个已知的顺序序列A,是否能够通过一个容量最大为m的栈S,调度为希望的序列B,如图:算法框架如下:贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告3、从小顶堆中取出最小元素后,可以在log(n)的时间内恢复为小顶堆。
4、任意一个元素,可以在log(n)的时间内插入小顶堆。
最小堆物理结构最小堆逻辑结构在本题中,队列元素出队后,还会再入队,我们可以得出算法流程大致如下:初始化有些队列PQ,队列元素为字符串与其优先级读入参数n,m循环n次,读取每个元素,插入队列PQ,花费O(nlogn)建堆循环m次每次输出堆顶元素e将e乘以2以后再次入队实验步骤1、阅读PA04的任务调度这道题;2、采用小顶堆实现优先队列,建议实现为模板类;贵州大学计算机科学与技术学院计算机科学与技术系上机实验报告。
目录一、概述 (1)二、系统分析 (1)1.航班信息的查询与检索 (1)2.航班信息查询与检索数据结构理论 (1)三、概要设计 (2)1.系统的功能 (2)2.系统模块分析及其流程图 (3)四、详细设计 (6)1.各函数说明 (6)2.定义相关数据类型 (8)3.航班信息的查询 (9)五、运行由于测试 (11)六、总结与心得 (16)参考文献 (16)附录 (16)一、概述随着信息产业的飞速发展, 信息化管理及查询已经进入并应用到各行各业, 影响着人们的价值观念和生活方式。
因此, 要提高企业信息化建设, 利用先进的办公自动化系统来实现企业内部信息管理、共享及交流, 从而提高企业综合实力。
本次设计是针对航班的查询系统, 该设计要求对飞机航班信息进行排序和查询。
可按航班的航班号、起点站、终点站等信息进行航班信息的查询。
二、系统分析1.航班信息的查询与检索进入系统后, 首先提示输入航班的信息, 包括: 航班号、起点站、终点站、班期、起飞时间、到达时间、飞机型号及票价等, 票价为整型, 其他为字符型。
当输入完一个信息后会提示是否继续输入, 重复以上步骤输入全部的信息。
进入主菜单后会给出用户操作的界面, 根据提示进行航班信息的查询。
2.航班信息查询与检索数据结构理论针对在本该类系统中的数据的处理情况, 本系统采用二分查找法、基数排序法、最高位优先法。
二分查找法也称为折半查找法, 它充分利用了元素间的次序关系, 采用分治策略, 可在最坏的情况下用O(log n)完成搜索任务。
它的基本思想是, 将n 个元素分成个数大致相同的两半, 取a[n/2]与欲查找的x作比较, 如果x=a[n/2]则找到x, 算法终止。
如果x<a[n/2], 则我们只要在数组a的左半部继续搜索x(这里假设数组元素呈升序排列)。
如果x>a[n/2], 则我们只要在数组a的右半部继续搜索x。
对航班号的排序是采用的基数排序法。
基数排序法又称“桶子法”(bucket sort)或bin sort, 顾名思义, 它是透过键值的部份资讯, 将要排序的元素分配至某些“桶”中, 藉以达到排序的作用, 基数排序法是属于稳定性的排序, 其时间复杂度为O (nlog(r)m), 其中r为所采取的基数, 而m为堆数, 在某些时候, 基数排序法的效率高于其它的比较性排序法。
一、实验名称阵列处理实验二、实验目的1. 理解阵列处理的基本概念和原理。
2. 掌握使用数组进行数据存储和操作的方法。
3. 学习通过编程实现简单的阵列处理算法。
4. 提高编程能力和问题解决能力。
三、实验原理阵列处理是计算机科学和工程领域中的一个重要概念,它涉及到对一组数据(即数组)进行高效的存储、检索和操作。
在计算机中,数组是一种数据结构,它允许存储多个具有相同数据类型的元素,并通过索引来访问这些元素。
本实验通过编程实现对数组的创建、初始化、遍历、排序、搜索等基本操作,从而加深对阵列处理的理解。
四、实验设备1. 计算机一台2. 编程软件(如Visual Studio、Eclipse等)3. 实验指导书五、实验内容1. 创建和初始化数组2. 遍历数组3. 数组排序4. 数组搜索5. 阵列处理应用实例六、实验步骤1. 创建和初始化数组- 创建一个整数类型的数组,并初始化为随机值。
- 创建一个字符类型的数组,并初始化为字符串。
2. 遍历数组- 使用循环结构遍历数组,打印出每个元素。
3. 数组排序- 实现一个简单的冒泡排序算法,对整数数组进行排序。
- 使用内置的排序函数对字符数组进行排序。
4. 数组搜索- 实现二分搜索算法,在已排序的整数数组中查找特定元素。
- 使用线性搜索在字符数组中查找特定字符。
5. 阵列处理应用实例- 编写一个程序,实现将一个二维数组转换为矩阵转置的功能。
七、实验结果与分析1. 创建和初始化数组- 成功创建并初始化了整数和字符数组。
2. 遍历数组- 成功遍历并打印了数组的所有元素。
3. 数组排序- 成功使用冒泡排序算法对整数数组进行了排序。
- 成功使用内置排序函数对字符数组进行了排序。
4. 数组搜索- 成功实现了二分搜索算法,找到了整数数组中的特定元素。
- 成功实现了线性搜索,找到了字符数组中的特定字符。
5. 阵列处理应用实例- 成功编写了程序,实现了二维数组到矩阵转置的功能。
八、实验总结通过本次实验,我对阵列处理有了更深入的理解。
折半查找的实验报告
《折半查找的实验报告》
在计算机科学领域中,折半查找是一种常用的搜索算法,也被称为二分查找。
它的原理是在有序数组中查找特定元素的位置,通过将数组分成两部分并逐步
缩小搜索范围来实现。
本实验旨在验证折半查找算法的效率和准确性,以及探
讨其在实际应用中的优势和局限性。
实验过程分为以下几个步骤:
1. 数据准备:首先,我们准备了多组有序数组作为输入数据,每组数组包含不
同数量的元素。
这些数组涵盖了各种规模的数据集,以便全面测试折半查找算
法的性能。
2. 算法实现:我们编写了折半查找算法的实现代码,并在不同规模的数据集上
进行了测试。
算法的实现包括了边界条件的处理、搜索范围的缩小和结果的返
回等关键步骤。
3. 实验设计:为了验证折半查找算法的准确性和效率,我们设计了一系列实验,包括查找存在的元素、查找不存在的元素以及对比折半查找和线性查找算法的
性能。
4. 实验结果:通过对实验数据的分析和对比,我们得出了折半查找算法在不同
规模数据集上的搜索耗时和准确率。
同时,我们也探讨了折半查找算法相对于
线性查找算法的优势和局限性。
5. 结论与展望:最后,我们总结了实验结果,并对折半查找算法在实际应用中
的潜在价值和改进方向进行了展望。
通过本次实验,我们对折半查找算法有了更深入的理解,同时也为其在实际应
用中的优化和推广提供了一些思路。
希望本实验报告能够对相关领域的研究和应用有所启发,为进一步探索折半查找算法的性能和潜力提供参考。
算法设计及实验报告实验报告1 递归算法一、实验目的掌握递归算法的基本思想;掌握该算法的时间复杂度分析;二、实验环境电脑一台,Turbo C 运行环境三、实验内容、步骤和结果分析以下是四个递归算法的应用例子:用C语言实现1.阶乘:main(){int i,k;scanf("%d\n",&i);k= factorial(i);printf("%d\n",k);}int factorial(int n){ int s;if(n==0) s=1;else s=n*factorial(n-1); //执行n-1次return s;}阶乘的递归式很快,是个线性时间,因此在最坏情况下时间复杂度为O(n)。
2.Fibonacci 数列:main(){int i,m;scanf("%d\n",&i);m=fb(i);printf("%d",m);}int fb(int n){int s;if(n<=1)return 1;else s=fb(n-1)+fb(n-2);return s;}Fibonacci数列则是T(n)=T(n-1)+T(n-2)+O(1)的操作,也就是T(n)=2T(n)+O(1),由递归方程式可以知道他的时间复杂度T(n)是O(2n),该数列的规律就是不停的赋值,使用的内存空间也随着函数调用栈的增长而增长。
3.二分查找(分治法)#include<stdio.h>#define const 8main(){int a[]={0,1,2,3,4,5,6,7,8,9};int n=sizeof(a);int s;s=BinSearch(a,const,n);printf("suo cha de shu shi di %d ge",s);}BinSearch(int a[],int x,int n){int left,right,middle=0;left=0;right=n-1;whlie(left<=right){middle=(left+right)/2;if(x==a[middle]) return middle;if(x>a[middle]) left=middle+1;else right=middle-1;}return -1;}二分搜索算法利用了元素间的次序关系,采用分治策略,由上程序可知,每执行一次while循环,数组大小减少一半,因此在最坏情况下,while循环被执行了O(logn)次。
二分搜索
一.实验目的:
1.理解算法设计的基本步骤及各步的主要内容、基本要求;
2.加深对分治设计方法基本思想的理解,并利用其解决现实生活中的问题;
3.通过本次实验初步掌握将算法转化为计算机上机程序的方法。
二.实验内容:
1.编写实现算法:给定n个元素,在这n个元素中找到值为key的元素。
2.将输入的数据存储到指定的文本文件中,而输出数据存放到另一个文本文件中,包括结果和具体的运行时间。
3.对实验结果进行分析。
三.实验操作:
1.二分搜索的思想:
首先,假设表中的元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复上述过程,知道找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
由于二分搜索是基于有序序列的一种搜索算法,故将输入的一组数据首先进行排序,考虑到输入数据可能有多个,采用快速排或者是合并排序,其中与冒泡做了对比。
冒泡排序算法:
void sort(int List[],int length){
int change;
for(int i=0;i<length;i++)
for(int j=i+1;j<length;j++){
if(List[i]>List[j]){
change=List[i];
List[i]=List[j];
List[j]=change;
}
}
}
快速排序算法:
void Qsort(int List[],int low,int high){
if(low>=high) return;
int first=low;
int last=high;
int key=List[first];
while(first<last){
while(first<last&&List[last]>=key) --last;
List[first]=List[last];
while(first<last&&List[first]<=key) ++first;
List[last]=List[first];
}
List[first]=key;
Qsort(List,low,first-1);
Qsort(List,last+1,high);}
二分查找算法:
int binarySearch(int List[],int low,int high,int key){
int mid=(low+high)/2;
if(high<low) return -1;
while(low<=high){
if(List[mid]==key) return mid+1;
else{
if(List[mid]>key) return binarySearch(List,low,mid-1,key);
else return binarySearch(List,mid+1,high,key);
}
}
}
2.实验数据的输入:
本实验采用将数据输入与输出存储到文件中的方式,需要采用C++文件流操作,对于数据的输入,由于cin对数据的读取会忽略空格和换行操作,使用cin 流输入来控制数据的输入。
对于输出操作,首先要从文件中读取数据,为了区别各数据,用逗号隔离,经过处理后将数据存入到另一文件之中。
由于输入需要大量的数据,可采用从“随机数.txt”中读取数据。
存入文件算法:
int input(){
ofstream outFile;
outFile.open("E://程序设计/practice 1/算法设计与分析文本文件夹
D/number.txt",ios::trunc);
if(!outFile.is_open()) cout<<"File can't open!"<<endl;
cout<<"输入数据Y:"<<endl;
char number;
int length=0;
cin>>number;
while(number!='E'){
length++;
outFile<<number;
cin>>number;
}
outFile.close();
return length;
}
文件数据提取算法:
int* output(int length){
ifstream inFile;
ofstream outFile;
inFile.open("E://程序设计/practice 1/算法设计与分析/文本文件夹D/number.txt");
outFile.open("E://程序设计/practice 1/算法设计与分析/文本文件夹D/result2.txt",ios::trunc);
char* Array=new char[length];
int* List=new int[length/2];
int i=0,j=0;
outFile<<"数组中的元素为:";
while(!inFile.eof()){
inFile>>Array[i];
if(Array[i]!=','&&i<length-1){
List[j]=Array[i]-'0';
outFile<<List[j]<<" ";
j++;
}
i++;
}
sort(List,length/2);
inFile.close();
outFile.close();
return List;
}
3.程序运行时间测量:
为了得到二分搜索的时间,主要是排序的时间,调用time标准库,通过对起止时间记录,得到运行时间。
double start,end,Time;
start=clock();
调用程序;
end=clock();
Time=end-start;
四.实验数据分析:
当测试的数据较少时,如输入个数为20个时,两种排序时间都为0,即两种排序所消耗的时间差不多。
在数据小于2000个时,它们的耗费时间是代价相等的。
但当数据规模十分庞大时,快速排序的时间代价远远低于冒泡排序,例如当输入的数据为3000个时,快速排序的时间消耗是冒泡排序的1/3,由此可见一斑,并且当输入的数据完全逆序时,快速排序将和冒泡排序一样复杂。
最后将排序的时间与查找的时间相加,即为二分搜索的总时间,为
n(logn)+time.
五.实验感受:
在本次实验中,测试程序的运行时间时,需要用到大量的数据,仅仅输入100以内的数据对时间的测试不起作用,故用随机数生成并读取,解决了测试时间不明显的问题。
而对于输入的数据,其顺序也有一定影响性。