源程序的预处理及词法分析程序设计
- 格式:docx
- 大小:14.28 KB
- 文档页数:6


程序编译的四个步骤程序编译通常涉及以下四个步骤:预处理、编译、汇编和链接。
1.预处理预处理是编译过程的第一步,它主要负责对源代码进行一些预处理操作。
预处理器工具通常被称为预处理程序,它会根据源代码文件中的预处理指令来修改源代码。
预处理指令位于源代码文件的开头,以“#”字符开头。
预处理指令主要包括宏定义、条件编译和包含文件等。
在预处理阶段,预处理器会执行以下操作:-展开宏定义:将代码中的宏定义替换为相应的代码片段。
-处理条件编译:根据条件编译指令的结果,决定是否包含或排除一些代码。
-处理包含文件:将文件中的包含文件指令替换为实际的文件内容。
预处理后的源代码通常会生成一个中间文件,供下一步编译使用。
2.编译编译是程序编译过程的第二个阶段。
在编译阶段,编译器将预处理生成的中间文件翻译成汇编语言。
编译器会按照源代码的语法规则,将源代码转换为汇编语言指令,生成目标文件(也称为汇编代码文件)。
编译器在编译过程中执行以下操作:-词法分析:将源代码分割为多个词法单元,如关键字、标识符和运算符等。
-语法分析:根据语言的语法规则,分析词法单元的组合,生成语法树。
-语义分析:检查语法树的语义正确性,进行类型检查等。
-优化:对生成的中间代码进行各种优化,以提高程序执行效率。
编译器输出的目标文件通常是汇编语言形式的代码,以便下一步汇编使用。
3.汇编汇编是编译过程的第三个阶段,它将编译器生成的汇编代码翻译成目标机器码。
汇编器(或称为汇编程序)将汇编代码中的指令和操作数翻译为目标机器指令的二进制表示。
汇编器在汇编过程中执行以下操作:-识别和解析汇编指令:将汇编代码中的汇编指令和操作数分割解析。
-确定存储器地址:根据符号的引用和定义,计算并分配存储器地址。
-生成目标机器指令:将汇编指令和操作数翻译为目标机器指令的二进制表示。
汇编器的输出是一个或多个目标文件,每个目标文件都包含可在目标机器上执行的二进制指令。
4.链接链接是编译的最后一个阶段,它将多个目标文件和库文件组合在一起,生成最终的可执行文件。
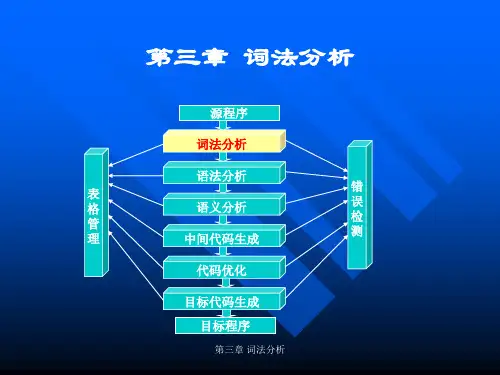

程序设计语言编译原理(第三版)第3章第3章词法分析任务:从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串。
§3.1§3.2§3.3§3.4对于词法分析器的要求词法分析器的设计正规表达式与有限自动机词法分析器的自动产生(LE某)—略1§3.1对于词法分析器的要求一.功能和输出形式二.接口设计§3.1对于词法分析器的要求一.功能和输出形式1.功能:输入源程序,输出单词符号2.单词符号的分类(1)关键字:由程序语言定义的具有固定意义的标识符,也称为保留字或基本字。
例如:Pacal语言中begin(2)标识符:用来表示各种名字。
endifwhile等。
如变量名、数组名、过程名等。
(3)常数:整型、实型、布尔型、文字型等例:100(5)界符:,;3.14159()true等ample(4)运算符:+、-、某、/3§3.1对于词法分析器的要求3.输出的单词符号形式二元式:(单词种别,单词符号的属性值)通常用“整数编码”“单词符号的特征或特性”单词符号的编码:标识符:一般统归为一种常数:常按整型、实型、布尔型等分类关键字:全体视为一种/一字一种运算符:一符一种界符:一符一种4§3.1对于词法分析器的要求例:考虑下述C++代码段:while(i>=j)i--;经词法分析器处理后,它将被转换为如下的单词符号序列:<while,-><(,-><id,指向i的符号表项的指针><>=,-><id,指向j的符号表项的指针><),-><id,指向i的符号表项的指针><--,-><;,->§3.1对于词法分析器的要求二.接口设计1.词法分析器作为独立的一遍词法分析字符流(源程序)单词序列(输出在一个中间文件上)2.词法分析器作为一个独立的子程序,但并不一定作为独立的一遍语法分析器单词(至少一个)调用(取下一个单词)词法分析器优点:使整个编译程序的结构更简洁、清晰和条理化.6§3.2词法分析器的设计一.输入和预处理二.单词符号的识别三.状态转换图及其实现§3.2词法分析器的设计一.输入、预处理1.预处理:剔掉空白符、跳格符、回车符、换行符、注解部分等.原因:编辑性字符除了出现在文字常数中之外,在别处的任何出现都无意义.#注解部分不是程序的必要组成部分,它的作用仅在于改善程序的易读性和易理解性.8§3.2词法分析器的设计2.预处理子程序:每当词法分析器调用时,就处理出一串确定长度(如120个字符)的输入字符,并将其装进词法分析器所确定的扫描缓冲区中。


简述汇编语言程序运行步骤汇编语言程序是一种低级语言,它直接操作计算机硬件资源。
了解汇编语言程序运行步骤对于理解计算机的底层工作原理以及编写高效的代码至关重要。
本文将简述汇编语言程序的运行步骤,以帮助读者对该过程有一个清晰的了解。
汇编语言程序的运行步骤可以大致分为如下几个环节:预处理、编译、汇编、链接和运行。
以下将详细描述每个步骤的功能和过程。
1. 预处理:在预处理环节,汇编语言程序会经过预处理器的处理。
预处理器主要负责处理宏定义、头文件包含、条件编译等指令,以生成一份经过预处理的源代码文件。
预处理环节的目标是去除源代码中的注释、展开宏定义、处理条件编译等操作,为后续步骤做准备。
2. 编译:编译是将预处理得到的源代码转化为汇编语言代码的过程。
编译器将预处理后的源代码进行词法分析、语法分析、语义分析等操作,生成相应的汇编语言代码。
编译器还会进行优化操作,以提高程序的执行效率。
3. 汇编:汇编是将编译得到的汇编语言代码转化为机器代码的过程。
在这一步骤中,汇编器将汇编语言代码转化为计算机可以理解和执行的二进制指令。
4. 链接:链接是将多个目标文件链接在一起,形成一个可执行文件的过程。
在这一步骤中,链接器将编译得到的目标文件与系统库文件进行链接,解析符号引用,生成最终的可执行文件。
链接的目标是生成一个包含所有必要信息的可执行文件,以便能够正确地执行程序。
5. 运行:运行是将可执行文件加载到计算机的内存中,并执行其中的指令。
在运行过程中,处理器按照指令的顺序执行程序,对数据进行相应的处理,最终得到程序的结果。
以上即为汇编语言程序的运行步骤。
通过对这些步骤的简要描述,读者可以对程序的整个运行过程有一个初步的了解。
深入理解每个步骤的原理和细节,对于编写高效的汇编语言程序至关重要。
因此,建议读者在掌握基本步骤的基础上,进一步学习汇编语言的相关知识,以提升自己的编程能力。
总结起来,汇编语言程序的运行步骤包括预处理、编译、汇编、链接和运行。

《编译原理词法分析器语法分析课程设计-《编译原理》课程设计院系信息科学与技术学院专业软件工程年级级学号 2723姓名林苾湲西南交通大学信息科学与技术学院12月目录课程设计1 词法分析器 (2)设计题目 (2)设计内容 (2)设计目的 (2)设计环境 (2)需求分析 (2)概要设计 (2)详细设计 (4)编程调试 (5)测试 (11)结束语 (13)课程设计2 赋值语句的解释程序设计 (14)设计题目 (14)设计内容 (14)设计目的 (14)设计环境 (14)需求分析 (15)概要设计 (16)详细设计 (16)编程调试 (24)测试 (24)结束语 (25)课程设计一词法分析器设计一、设计题目手工设计c语言的词法分析器(能够是c语言的子集)。
二、设计内容处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。
三、设计目的了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。
四、设计环境该课程设计包括的硬件和软件条件如下:.硬件(1)Intel Core Duo CPU P8700(2)内存4G.软件(1)Window 7 32位操作系统(2)Microsoft Visual Studio c#开发平台.编程语言C#语言五、需求分析.源程序的预处理:源程序中,存在许多编辑用的符号,她们对程序逻辑功能无任何影响。
例如:回车,换行,多余空白符,注释行等。
在词法分析之前,首先要先剔除掉这些符号,使得词法分析更为简单。
.单词符号的识别并判断单词的合法性:将每个单词符号进行不同类别的划分。
单词符号能够划分成5中。
(1)标识符:用户自己定义的名字,常量名,变量名和过程名。
(2)常数:各种类型的常数。
(3) 保留字(关键字):如if、else、while、int、float 等。
(4) 运算符:如+、-、*、<、>、=等。

#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char*rwtab[24]={"main","if","then","while","do","static","int","double","struct","break","else","long", "switch","case","typdef","char","return","const","float","short","continue","for","void","sizeof"};char *special[10]={"default"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 26:printf("( %d,%d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %s,%d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=25;for(n=0;n<10;n++)if(strcmp(token,special[n])==0){syn=39;break;}for(n=0;n<24;n++)if(strcmp(token,rwtab[n])==0)/*比较字符串token和rwtab是否相同*/{syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){while((ch>='0')&&(ch<='9')){sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=26;}else switch(ch){case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){syn=35;}else if(ch=='>'){syn=34;}else{syn=33;token[m++]=ch;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){syn=37;token[m++]=ch;}else{syn=36;p--;}break;case '+': syn=27;token[m++]=ch;break;case '-':syn=28;token[m++]=ch;break;case ':':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=32;token[m++]=ch;}else{ syn=31;p--;}break;case '=':syn=38;token[m++]=ch;break;case '*': syn=29;token[m++]=ch;break;case '/': syn=30;token[m++]=ch;break;case '(': syn=42;token[m++]=ch;break;case ')': syn=43;token[m++]=ch;break;case ';': syn=41;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}。

python编译的过程摘要:Python是一种广泛使用的高级编程语言,它的编译过程相对简单。
本文将详细介绍Python的编译过程,包括源代码处理、编译成字节码、执行引擎等步骤。
一、Python的编译过程Python的编译过程可以分为以下几个步骤:1. 源代码处理2. 编译成字节码3. 执行引擎下面我们详细了解一下每个步骤。
二、源代码处理1. 源代码文件Python的源代码文件通常以.py为扩展名。
在Windows系统中,源代码文件扩展名为.pyc。
源代码文件包含一系列Python语句,这些语句可以是一个简单的变量赋值,也可以是一个复杂的函数定义。
2. 预处理预处理阶段的主要任务是处理源代码中的宏定义、注释和包含文件。
预处理器会将所有的宏定义展开,将注释删除,并将包含文件的内容合并到主源文件中。
3. 语法检查预处理完成后,源代码将进入语法检查阶段。
Python的解释器会对源代码进行语法检查,确保源代码符合Python的语法规范。
如果源代码中存在语法错误,解释器将报告错误并终止编译过程。
三、编译成字节码1. 词法分析词法分析阶段将源代码分解成一系列的词法单元(tokens)。
词法单元是源代码中的最小单位,通常包括关键字、变量名、操作符等。
词法分析器会将源代码转换成一个词法单元的列表。
2. 语法分析语法分析阶段将词法单元列表转换成一个抽象语法树(abstract syntax tree, AST)。
抽象语法树表示了源代码的结构,包括变量声明、函数定义、表达式等。
语法分析器会根据Python的语法规则构建抽象语法树。
3. 语义分析语义分析阶段对抽象语法树进行语义检查,确保源代码中没有语法错误。
此外,语义分析器还会为抽象语法树中的每个语句分配一个运算符优先级。
4. 字节码生成字节码生成阶段将抽象语法树转换成字节码(bytecode)列表。
字节码是Python程序的执行指令,包括载入模块、调用函数、计算表达式等。

pdb编译-回复编译(pdb编译)是将高级别的源代码转化为低级别的目标代码的过程。
在计算机科学中,编译器扮演着重要的角色,它将程序员编写的源代码转换为计算机能够执行的机器码。
pdb编译器则是一种特定领域的编译器,它用于将Python代码转换为机器码,使得程序可以更高效地运行。
本文将分为六个主要步骤来解释pdb编译的过程:预处理、词法分析、语法分析、语义分析、代码生成和代码优化。
每个步骤将分别进行详细讨论,以帮助读者更好地理解pdb编译的工作原理。
第一步:预处理预处理是编译过程的第一步,它主要用于处理源代码中的包含指令和宏定义等预处理指令。
预处理器会根据这些指令进行相应的处理,例如展开宏定义、替换宏参数以及引入其他头文件等。
在Python中,由于其动态类型的特性,预处理过程相对较简单,主要包括注释的删除和行尾空白字符的删除。
第二步:词法分析词法分析是编译过程的第二步,其主要任务是将源代码转换为一个个的词法单元(token)。
词法单元是源代码中的最小、不可再分的语法单元,比如标识符、关键字、运算符、常量等。
词法分析器会扫描源代码并将每个词法单元存储为一个二元组(token type,token value)。
例如,在Python中,标识符‘x’会被词法分析器识别为(IDENTIFIER,'x')。
第三步:语法分析语法分析是编译过程的第三步,其主要任务是根据源代码的词法单元序列,判断是否符合语法规则,并生成抽象语法树(AST)。
语法规则描述了源代码中各个词法单元之间的关系,可以通过上下文无关文法(CFG)进行形式化表示。
语法分析器会根据CFG进行逐个词法单元的匹配,构建一棵语法树。
例如,在Python中,语法分析器会将语句“x = 1 + 2”解析为一个赋值表达式,左边是一个标识符节点“x”,右边是一个加法表达式节点,其中包括两个整数常量节点。
第四步:语义分析语义分析是编译过程的第四步,其主要任务是根据语法树对源代码的语义进行分析。

C语言文件的编译到执行的四个阶段C语言程序的编译到执行过程可以分为四个主要阶段:预处理、编译、汇编和链接。
1.预处理:在这个阶段,编译器会执行预处理指令,将源代码中的宏定义、条件编译和包含其他文件等操作进行处理。
预处理器会根据源代码中的宏定义替换相应的标识符,并去除注释。
预处理器还会将包含的其他文件插入到主文件中,并递归处理这些文件。
处理后的代码被称为预处理后的代码。
2.编译:在这个阶段,编译器将预处理后的代码转换成汇编代码。
汇编代码是一种低级的代码,使用符号来表示机器指令。
编译器会对源代码进行词法分析、语法分析和语义分析,生成相应的中间代码。
中间代码是一种与特定硬件无关的代码表示形式,便于后续阶段的处理。
3.汇编:在这个阶段,汇编器将中间代码转化为机器可以执行的指令。
汇编器会将汇编代码翻译成二进制形式的机器指令,并生成一个目标文件。
目标文件包含了机器指令的二进制表示以及相关的符号信息。
4.链接:在C语言中,程序通常由多个源文件组成,每个源文件都经过了预处理、编译和汇编阶段得到目标文件。
链接器的作用就是将这些目标文件合并成一个可执行文件。
链接器会解析目标文件中的符号引用,找到其对应的定义并进行连接。
链接器还会处理库文件,将使用到的函数和变量的定义从库文件中提取出来并添加到目标文件中。
最终,链接器生成一个可以直接执行的可执行文件。
以上是C语言程序从编译到执行的四个阶段。
每个阶段都有特定的任务,并负责不同层次的代码转换和处理。
通过这四个阶段,C语言程序可以从源代码转换为机器能够执行的指令,并最终被计算机执行。
高级语言的编译过程编译器是将高级语言代码转换为计算机能够理解的机器语言代码的程序。
编译器可以分为前端和后端两个部分。
前端负责将高级语言代码转换为中间代码,而后端将中间代码转换为目标机器语言代码。
下面将详细介绍高级语言的编译过程。
一、预处理器在编译过程中,首先需要进行预处理。
预处理器负责对源代码进行预处理,将源代码中的宏定义展开,去掉注释和空行,将头文件中的内容复制到源文件中等操作。
预处理后的文件被称为预处理文件。
二、词法分析器词法分析器的作用是将源代码转换为词法单元序列。
词法单元是组成程序的最小单元,也就是代码中的各种关键字、变量和符号等。
词法分析器通过扫描预处理文件中的字符流,将字符流分解成由词法单元组成的序列。
三、语法分析器语法分析器的作用是将词法单元序列转换为语法分析树。
语法分析树是由一系列节点组成的树状结构,节点表示语法单元,边表示语法关系。
语法分析器通过语法规则,对词法单元序列进行分析,并生成语法分析树。
四、语义分析器语义分析器的作用是对语法分析树进行语义分析。
语义分析器主要完成类型检查、符号表管理和语义错误检查等任务。
在语义分析过程中,需要对程序中的变量、函数、常量等进行处理,并检查语义错误。
五、中间代码生成器中间代码是一种介于源代码和目标代码之间的代码形式,它将高级语言代码转换为一种中间表示形式。
中间代码生成器的作用是将语法分析树转换为中间代码。
中间代码可以是一种类似于汇编语言的形式,也可以是一种高级语言形式。
六、代码优化器代码优化器的作用是对生成的中间代码进行优化,以提高程序的性能和效率。
代码优化器可以对中间代码进行多种优化,如常量折叠、循环展开、死代码消除等,以减少程序的执行时间和空间。
代码优化器是编译器中最复杂和最重要的部分之一。
七、目标代码生成器目标代码生成器的作用是将中间代码转换为目标机器语言代码。
目标代码生成器需要解决的主要问题是寄存器分配、指令选择和代码调度等。
目标代码生成器将中间代码翻译成目标机器的指令序列,并生成可执行的目标代码文件。
c语言的编译流程C语言是一种高级编程语言,被广泛用于系统软件、游戏开发、嵌入式系统等领域。
在使用C语言进行编程时,需要将代码转换为可执行文件,这个过程称为编译。
本文将介绍C语言的编译流程,以及编译过程的主要步骤。
1. 预处理(Preprocessing):编译过程的第一步是预处理,它由预处理器(Preprocessor)执行。
预处理器主要完成以下任务:- 处理以“#”开头的预处理指令,例如#include、#define、#ifdef 等。
- 将所有的#include指令替换为相应的头文件的内容。
-进行宏替换,将程序中的宏定义展开。
- 词法分析(Lexical Analysis):将代码分解为一个个的单词,称为记号(Token)。
- 语法分析(Syntax Analysis):根据语法规则组织单词,并创建语法树(Syntax Tree)。
- 语义分析(Semantic Analysis):对语法树进行分析,检查语义错误,并生成中间代码。
3. 汇编(Assembly):编译器生成的中间代码是与特定平台无关的,需要通过汇编器(Assembler)将其转换为可执行文件。
汇编器主要完成以下任务:-将汇编代码转换为机器码指令。
-将符号名称解析为地址,生成可重定位代码。
4. 链接(Linking):在C语言编程中,通常会使用多个源文件,这些文件中的函数和变量可能相互引用。
链接器(Linker)的作用是将这些文件中的符号引用和定义进行匹配,生成最终的可执行文件。
链接器主要完成以下任务:- 符号解析(Symbol Resolution):将符号引用与符号定义进行匹配。
- 地址重定位(Address Relocation):将代码中的相对地址转换为绝对地址。
- 符号合并(Symbol Merging):将多个源文件中同名的符号进行合并,以解决重复定义的问题。
-生成可执行文件,包括代码段、数据段等。
5. 加载(Loading):加载器(Loader)是操作系统提供的一部分,它将可执行文件加载到内存中,并执行程序。
头验一一、实验名称:词法分析器的设计二、实验目的:1词法分析器能够识别简单语言的单词符号2 ,识别出并输出简单语言的基本字•标示符.无符号整数•运算符.和界符三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
2、程序流程图(1)主程序验报告(2)扫描子程序3、各种单词符号对应的种别码单词符号种别码助记符内码值while 1 while -if 2 if -else 3 else -switch 4 switch -case 5 case -标识符6 id id在符号表中的位置常数7 num num在常数表中的位置+ 8 + -- 9 - -* 10 * -<= 11 relop LE< 11 relop LT== 11 relop EQ= 12 = -J 13J-五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[] 、token[] (均为字符串数组),c,s( char 型),i,j,k (int型),a[]用来存放输入的字符串,token[] 另一个则用来帮助识别单词符号,s 用来表示正在分析的字符。
字符串输入之后,逐个分析输入字符,判断其是否‘#',若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c) 、int letter(char c) 判断其是数字,字符还是算术符, 分别为用以判断数字或字符的情况,算术符的判断可以在switch 语句中进行,还要通过函数int lookup(char token[]) 来判断标识符和保留字。
2 实验词法分析器源程序:#include <stdio.h> #include <math.h> #include <string.h> int i,j,k;char c,s,a[20],token[20]={'0'};int letter(char s){if((s>=97)&&(s<=122)) return(1);else return(0);}int digit(char s){if((s>=48)&&(s<=57)) return(1);else return(0);void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){ if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else")==0) return(3);else if(strcmp(token,"switch")==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf("please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!='#');i=1;j=0;get();while(s!='#'){ memset(token,0,20); switch(s){case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':case 'l':case 'm':case 'n':case 'o':case 'p': case 'q': case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':case 'z':while(letter(s)||digit(s)) {token[j]=s;j=j+1;get();}retract();k=lookup(token); if(k==0)printf("(%d,%s)",6,token); else printf("(%d,-)",k); break; case '0': case '1':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':while(digit(s)){token[j]=s;j=j+1;get();}retract();printf("%d,%s",7,token); break;case '+':printf("('+',NULL)");break;case '-':printf("('-',null)");break;case '*':printf("('*',null)");break;case '<':get();if(s=='=') printf("(relop,LE)");else{retract();printf("(relop,LT)");}break;case '=':get();if(s=='=')printf("(relop,EQ)");else{retract();printf("('=',null)");}break;case ';':printf("(;,null)");break;case ' ':break; default:printf("!\n");}j=0;get();六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术。
c语言编译的正确过程以C语言编译的正确过程C语言是一种广泛应用于软件开发领域的高级编程语言,它具有语法简洁、执行效率高等特点,因此备受程序员的喜爱。
编译是将C 语言源代码转换为可执行文件的过程,本文将详细介绍C语言编译的正确过程。
1. 预处理在编译过程开始之前,C语言编译器会首先进行预处理。
预处理器会对源代码进行扫描,解析并处理以"#"开头的预处理指令,如宏定义、条件编译等。
预处理的主要目的是对源代码进行预处理,将所有预处理指令替换为实际代码。
2. 词法分析词法分析是编译器的下一个阶段。
在这个阶段,编译器会将源代码分解为一个个的词法单元,如关键字、标识符、运算符、常量等。
编译器会根据C语言的语法规则对每个词法单元进行解析和分类。
3. 语法分析语法分析是编译器的关键阶段之一。
在这个阶段,编译器会根据C 语言的语法规则,对词法单元进行语法分析,构建语法树。
语法树是一种树状结构,用于表示源代码的语法结构,便于后续的语义分析和代码生成。
4. 语义分析语义分析是编译器的另一个关键阶段。
在这个阶段,编译器会对语法树进行分析,检查语义错误和类型匹配等问题。
如果发现错误,编译器会生成相应的错误信息。
同时,编译器还会进行符号表的构建,用于记录变量、函数等符号的信息。
5. 代码生成代码生成是编译器的最后一个阶段。
在这个阶段,编译器会根据语义分析的结果,将语法树转换为目标平台的机器代码。
代码生成过程中,编译器会进行优化,以提高程序的执行效率。
优化包括常量折叠、循环展开、指令调度等技术。
6. 链接链接是将编译生成的目标文件与库文件进行合并,生成可执行文件的过程。
链接器会对目标文件进行符号解析和重定位,将各个模块的目标代码链接在一起,生成最终的可执行文件。
链接过程还包括对库文件的搜索和加载。
7. 运行编译生成可执行文件后,就可以运行程序了。
在运行过程中,操作系统会加载可执行文件到内存中,并按照指令进行执行。
程序编译的四个步骤程序的编译过程通常分为四个步骤:预处理、编译、汇编和链接。
第一步:预处理(Preprocessing)预处理是编译过程的第一个步骤。
在这一步骤中,预处理器将对源代码进行处理,以便于后续的编译。
预处理器通常会执行以下任务:1.去除注释:将源代码中的注释(单行、多行注释)删除,以便于后续的处理。
2.展开宏定义:替换源代码中的宏定义,在源代码中使用宏定义的地方,将其替换为宏定义的内容。
3.处理条件编译指令:根据条件编译指令的条件,决定哪些代码需要编译,哪些代码需要忽略。
4.处理头文件包含指令:将头文件包含指令替换为头文件的内容,以确保源代码中可以使用头文件中定义的函数、变量等。
编译是预处理之后的一步,编译器将对预处理后的文件进行处理。
编译器通常会执行以下任务:1. 词法分析(Lexical Analysis):将源代码分解成一个个的词素,如关键字、标识符、运算符等,并生成相应的记号。
2. 语法分析(Syntax Analysis):根据词法分析生成的记号,将其按照一定的文法规则进行组织,构建抽象语法树。
3. 语义分析(Semantic Analysis):对抽象语法树进行分析,检查程序是否存在语义错误,如类型不匹配、未定义的变量等。
4. 代码生成(Code Generation):根据语义分析的结果,将抽象语法树转化为目标机器的汇编代码。
第三步:汇编(Assembly)汇编是编译过程的第三步,将编译器生成的汇编代码转化为机器码。
汇编器(Assembler)会执行以下任务:1.识别指令和操作数:根据汇编代码的语法规则,识别出每个指令以及对应的操作数。
2.生成机器码:将汇编指令和操作数翻译成机器码表示形式。
3.符号解析:解析并处理所有的符号引用,如函数、变量等的引用。
第四步:链接(Linking)链接是编译过程的最后一步,将编译器生成的目标代码和其他库文件进行合并。
1.解析外部符号引用:将目标代码中引用的外部符号(函数、变量等)与其他目标代码或库文件中的定义进行匹配。
嵌入式编译的过程嵌入式编译是指将高级语言编写的程序转化为特定硬件平台上可执行的机器码的过程。
在嵌入式系统中,由于资源的有限性和特定的应用需求,编译过程需要考虑如何优化代码,以提高程序的性能和效率。
本文将详细介绍嵌入式编译的过程及其关键步骤。
一、预处理预处理是编译过程的第一步,它主要是对源代码进行一些预处理操作,比如宏替换、头文件包含、条件编译等。
预处理器会根据程序中的宏定义和条件语句进行相应的处理,生成一个经过处理的源代码文件。
二、词法分析词法分析是将预处理后的源代码文件进行分词,将源代码分解成一个个的词法单元。
词法分析器会识别出源代码中的关键字、标识符、运算符、常量等,并将其转化为编译器可识别的内部表示形式。
三、语法分析语法分析是将词法分析得到的词法单元按照语法规则进行组织和分析的过程。
语法分析器会根据编程语言的语法规则,将词法单元组织成语法树或抽象语法树。
在语法分析阶段,编译器会进行语法检查,确保程序的语法正确性。
四、语义分析语义分析是对语法树或抽象语法树进行分析和处理的过程。
在语义分析阶段,编译器会进行类型检查、符号表管理、语义错误检测等操作。
语义分析器会根据语义规则对程序进行分析,以确保程序的语义正确性。
五、中间代码生成中间代码生成是将经过语义分析的源代码转化为中间代码的过程。
中间代码是一种高级语言形式的代码,它不依赖于具体的硬件平台,而是以一种与机器无关的方式来表示源代码的执行逻辑。
中间代码生成器会根据源代码和语义信息生成相应的中间代码。
六、代码优化代码优化是对中间代码进行优化的过程,目的是提高程序的性能和效率。
代码优化器会根据特定的优化算法对中间代码进行分析和重组,以减少程序的执行时间和存储空间。
常见的代码优化技术包括常量折叠、循环优化、指令调度等。
七、代码生成代码生成是将优化后的中间代码转化为目标平台上的机器码的过程。
代码生成器会根据目标平台的指令集架构和寄存器分配策略,将中间代码转化为与目标平台相匹配的机器码。
//词法分析#include<iostream>#include<cstring>#include<cstdlib>#include<cstdio>using namespace std;void chu_li_1(FILE *p,FILE *q) //处理空格{char ch;if((p=fopen("输出文件.txt","r+"))==NULL) //shili3.txt为中转文件{cout<<"输出文件打开错误"<<endl;}if((q=fopen("中转文件.txt","w+"))==NULL) //保存处理后程序的文件{cout<<"中转文件打开错误"<<endl;}while(!feof(p)){ch=fgetc(p);if(ch!=32)fputc(ch,q); //保留一个空格else if(ch==32) //将多个空格删除{fputc(ch,q);while(1&&(ch!=EOF)){ch=fgetc(p);if(ch!=32) //空格结束{fputc(ch,q);break;}}}}fclose(p);fclose(q);}void chu_li_2(FILE *p,FILE *q) //处理换行{char ch;if((p=fopen("中转文件.txt","r+"))==NULL){cout<<"中转文件打开错误"<<endl;}if((q=fopen("输出文件.txt","w+"))==NULL){cout<<"输出文件打开错误"<<endl;}while((ch=fgetc(p))!=EOF){if(ch!='\n') //忽略换行符fputc(ch,q);}fclose(p);fclose(q);}void chu_li_3(FILE *p,FILE *q) //处理注释{char ch;if((p=fopen("输入文件.txt","r+"))==NULL) //程序输入文件{if((p=fopen("输入文件.txt","w+"))==NULL) //程序输入文件{cout<<"输入文件打开错误"<<endl;}}if((q=fopen("中转文件.txt","w+"))==NULL){cout<<"中转文件打开错误"<<endl;}while((ch=fgetc(p))!=EOF){if(ch==47) //程序中发现字符'/'{ch=fgetc(p);if(ch==42) //判断字符后'/'是否有字符'*'{while(1){ch=fgetc(p); //忽略注释内容if(ch==42) //直到有'*'出现{ch=fgetc(p);if(ch==47) //判断结束break;}}}else if(ch==47) //判断以"//"开头形式的注释{while((ch!='\n')&&((ch=fgetc(p))!=EOF))ch=fgetc(p);}else{fputc('/',q); //将不属于注释标示符的字符'/'写入文件fputc(ch,q); //}}elsefputc(ch,q);}fclose(p);fclose(q);}void Y_C_L(FILE *p,FILE *q) //预处理函数{chu_li_3(p,q); //处理注释chu_li_2(p,q); // 处理换行chu_li_1(p,q); //处理空格}void Fen_xi(){FILE *p,*q;char ch;int m,n=0;char letter[20000]="\0";char *rwtab[44]={"#","main","if","then","while","do","static","int"," double","struct","break","else","long","switch","case","typedef","char","return","const","float","short","continue","for","void","sizeof","ID","NUM","+","-","*","/",":",":=","<","<>","<=",">",">=","=","default","include",";","(",")"};if((p=fopen("中转文件.txt","r+"))==NULL)cout<<"中转文件打开错误"<<endl;if((q=fopen("输出文件.txt","w+"))==NULL)cout<<"输出文件打开错误"<<endl;fputs("Token",q);fputs("\t\t",q);fputs("Syn",q);fputc('\n',q);ch=fgetc(p);while(ch!=EOF){ m=1;letter[0]=ch;if(letter[0]<=57&&letter[0]>=48)//开头是数字{while(1&&ch!=EOF)//直到不是数字时为止{ch=fgetc(p);if(ch>=48&&ch<=57)letter[m++]=ch;elsebreak;}cout<<letter<<'\t'<<'\t'<<"26"<<endl;//输出读入的数字fputs(letter,q);fputs("\t\t",q);fputs("26",q);fputc('\n',q);for(int j=0;j<20000;j++)//将缓存数组清零letter[j]='\0';letter[0]=ch;}else if((letter[0]<='z'&&letter[0]>='a')||(letter[0]<='Z'&&letter[0]>='A'))//开头是字母{ int H=0;while(1&&!ch!=EOF)//直到不是字母或数字时为止{ch=fgetc(p);if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9'))letter[m++]=ch;elsebreak;}for(n=0;n<44;n++)//对初始表进行比较查看是否是关键字{if(strcmp(letter,rwtab[n])==0){cout<<letter<<'\t'<<'\t'<<n<<endl;fputs(letter,q);fputs("\t\t",q);fprintf(q,"%d",n);fputc('\n',q);H=1;}}if(H==0)//如果比较完时没有,该字符量就是一般字符串{cout<<letter<<'\t'<<"25"<<endl;fputs(letter,q);fputs("\t\t",q);fputs("25",q);fputc('\n',q);}for(int j=0;j<20000;j++)//将缓存数组清零letter[j]='\0';letter[0]=ch;}else if((letter[0]>=' '&&letter[0]<='/')||(letter[0]>=':'&&letter[0]<='?')){ int H=0;if(letter[0]==' '||letter[0]=='!'||letter[0]=='\"'||letter[0]=='$'||letter[0]=='%' ||letter[0]=='&'||letter[0]=='\''||letter[0]==','||letter[0]=='.'||letter[0]=='?') ch=fgetc(p);else{while(ch!=EOF){ch=fgetc(p);if(((ch>' '&&ch<='/')||(ch>=':'&&ch<'?'))&&(ch!=' '||ch!='!'||ch!='\"'||ch!='$'||ch!='%'||ch!='&'||ch!='\''||ch!=','||ch!='.'||ch!='?'))letter[m++]=ch;elsebreak;}for(n=0;n<44;n++)//对初始表进行比较查看是否是关键字{if(strcmp(letter,rwtab[n])==0){cout<<letter<<'\t'<<n<<endl;fputs(letter,q);fputs("\t\t",q);fprintf(q,"%d",n);fputc('\n',q);H=1;}}if(H==0)//如果比较完时没有,该字符量就是一般字符串{cout<<"sorry!字符"<<letter<<"不存在!"<<endl;fputs("sorry!字符",q);fputs(letter,q);fputs("不存在!",q);fputc('\n',q);}for(int j=0;j<20000;j++)//将缓存数组清零letter[j]='\0';letter[0]=ch;}}else{cout<<"sorry!字符"<<ch<<"非系统能识别的字符!"<<endl;fputs("sorry!字符",q);fputc(ch,q);fputs("非系统能识别的字符!",q);fputc('\n',q);ch=fgetc(p);}}fclose(p);fclose(q);}int main(){FILE *fp1,*fp2;Y_C_L(fp1,fp2); //预处理函数cout<<"Token"<<"\t\t"<<"Syn"<<endl;Fen_xi();//分析分类并输出system("pause");}。