SqlServer 使用存储过程实现插入或更新语句
- 格式:doc
- 大小:33.00 KB
- 文档页数:2

SQLServer Insert语句1. 概述在SQLServer数据库中,INSERT语句用于向表中插入新的数据行。
它是SQL语言中最基本和常用的操作之一。
INSERT语句可以将数据插入到已存在的表中,也可以通过创建新表的方式插入数据。
2. INSERT语句语法INSERT语句的基本语法如下:INSERT INTO 表名 (列1, 列2, 列3, ...)VALUES (值1, 值2, 值3, ...)其中,表名是要插入数据的表的名称,列1, 列2, 列3, ...是要插入数据的列的名称,值1, 值2, 值3, ...是要插入的具体数据值。
3. 插入单行数据要向表中插入单行数据,可以使用以下语法:INSERT INTO 表名 (列1, 列2, 列3, ...)VALUES (值1, 值2, 值3, ...)例如,要向名为students的表中插入一条学生记录,可以使用以下语句:INSERT INTO students (name, age, gender)VALUES ('张三', 20, '男')这将在students表中插入一行数据,包括姓名为张三,年龄为20,性别为男的学生信息。
4. 插入多行数据如果要向表中插入多行数据,可以使用单个INSERT语句多次执行,也可以使用INSERT语句的扩展语法。
4.1 多次执行INSERT语句可以多次执行INSERT语句来插入多行数据。
例如,要向students表中插入三条学生记录,可以使用以下语句:INSERT INTO students (name, age, gender)VALUES ('张三', 20, '男')INSERT INTO students (name, age, gender)VALUES ('李四', 22, '女')INSERT INTO students (name, age, gender)VALUES ('王五', 21, '男')这将分别插入三条学生记录到students表中。

sqlserver调用存储过程语句SQL Server是一种关系型数据库管理系统,它支持存储过程的调用。
存储过程是一组预定义的SQL语句,可以在数据库中存储和重复使用。
在SQL Server中,调用存储过程可以提高数据库的性能和安全性。
下面是SQL Server调用存储过程的语句。
1. 创建存储过程在SQL Server中,可以使用CREATE PROCEDURE语句创建存储过程。
例如,下面的语句创建了一个名为GetEmployee的存储过程,该存储过程返回Employee表中指定员工的信息。
CREATE PROCEDURE GetEmployee@EmployeeID intASSELECT * FROM Employee WHERE EmployeeID = @EmployeeID2. 调用存储过程在SQL Server中,可以使用EXECUTE语句或EXEC语句调用存储过程。
例如,下面的语句调用了GetEmployee存储过程,并传递了EXECUTE GetEmployee 1或者EXEC GetEmployee 13. 传递参数在调用存储过程时,可以传递参数。
在存储过程中,可以使用@符号定义参数。
例如,下面的语句创建了一个名为GetEmployeeByDepartment的存储过程,该存储过程返回指定部门的所有员工信息。
CREATE PROCEDURE GetEmployeeByDepartment@DepartmentID intASSELECT * FROM Employee WHERE DepartmentID =@DepartmentID在调用存储过程时,可以传递DepartmentID参数的值。
例如,下面的语句调用了GetEmployeeByDepartment存储过程,并传递了EXECUTE GetEmployeeByDepartment 2或者EXEC GetEmployeeByDepartment @DepartmentID = 24. 返回值在存储过程中,可以使用RETURN语句返回一个整数值。

SQLSERVER触发器触发INSERT,UPDATE,DELETE三种状态SQLSERVER触发器触发INSERT,UPDATE,DELETE三种状态来源:⼀个触发器内三种INSERT,UPDATE,DELETE状态CREATE TRIGGER tr_T_A ON T_A for INSERT,UPDATE,DELETE如IF exists (select * from inserted) and not exists (select * from deleted) 则为 INSERT如IF exists(select * from inserted ) and exists (select * from deleted) 则为 UPDATE如IF exists (select * from deleted) and not exists (select * from inserted)则为 DELETE插⼊操作(Insert):Inserted表有数据,Deleted表⽆数据删除操作(Delete):Inserted表⽆数据,Deleted表有数据更新操作(Update):Inserted表有数据(新数据),Deleted表有数据(旧数据)---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------SQL中触发器的使⽤原⽂地址:https:///feiquan/archive/2018/04/01/8685722.html创建触发器是特殊的存储过程,⾃动执⾏,⼀般不要有返回值类型: 1.后触发器(AFTER,FOR)先执⾏对应语句,后执⾏触发器中的语句 2.前触发器并没有真正的执⾏触发语句(insert,update,delete),⽽是执⾏触发后的语句 3.⾏级触发器(FOR EACH ROW)在SQL server 中不存在商品号为1的库存量:1.后触发器(实现不同表之间的约束)--实现在销售量不⼤于库存量时,每卖出n件商品,对应商品的库存要减n,若销售量⼤于库存量,则回滚此次操作IF EXISTS (SELECT *FROM sysobjects WHERE name='tr_SaleCommodity')DROP TRIGGER tr_SaleCommodityGOCREATE TRIGGER tr_SaleCommodityON OrderInfo FOR INSERT --FOR/AFTER为后触发器ASBEGINIF EXISTS (SELECT * FROM inserted I INNER JOIN CommodityInfo C ON modityId=modityIdWHERE I.Amount>C.Amount)BEGINROLLBACK --后触发器PRINT '商品的销售量⼤于商品的库存量'ENDELSEBEGINUPDATE CommodityInfoSET Amount=Amount-(SELECT Amount FROM inserted)WHERE CommodityId IN(SELECT CommodityId FROM inserted)ENDENDGO执⾏:INSERT INTO OrderInfo(UserId,CommodityId,Amount,PayMoney,PayWay,OrderTime,Confirm,SendGoods)VALUES('YOUYOU',1,10,600,'⽹上银⾏','2014-11-11 00:00:00.000',1,1)结果: 注意:1.上⼀⾏为销售记录,下⼀⾏为商品1的信息 2.卖出10个,库存量由48变为38 3.可以看出以上的销售记录中的Paymoney是不正确的,它的值应该是Amount*OutPrice=10*300,所以需要前触发器来约束2.前触发器(可以实现⾏级触发器功能)--实现了⽇期校验和⽀付⾦额的计算IF EXISTS(SELECT* FROM sysobjects WHERE name='tr_DateConfim')DROP TRIGGER tr_DateConfimGOCREATE TRIGGER tr_DateConfimON OrderInfo INSTEAD OF INSERT ,UPDATEASBEGINDECLARE @date datetimeSELECT @date=OrderTime FROM insertedIF @date BETWEEN '2012-1-1' AND '2015-1-1'BEGINDECLARE @UserId varchar(20) ,@CommodityId int,@Amount int,@PayMoney money,@PayWay varchar(20),@OrderTime datetime,@Confirm int,@SendGoods intSELECT @UserId=UserId,@CommodityId=CommodityId,@Amount=Amount,@PayWay=PayWay,@OrderTime=OrderTime,@Confirm=Confirm,@SendGoods=SendGoods FROM insertedDECLARE @outPrice moneySELECT @outPrice=OutPrice FROM CommodityInfo WHERE CommodityId=@CommodityIdSET @PayMoney=@outPrice*@AmountPRINT 'inserted 中的数据:'+CONVERT(varchar(20),@UserId)+' '+CONVERT(varchar(20),@CommodityId)+' '+CONVERT(varchar(20),@Amount)+' '+CONVERT(varchar(20),@PayMoney)+' '+CONVERT(varchar(20),@PayWay)+' '+CON INSERT INTO OrderInfo(UserId,CommodityId,Amount,PayMoney,PayWay,OrderTime,Confirm,SendGoods)SELECT UserId,CommodityId,Amount,@PayMoney,PayWay,OrderTime,Confirm,SendGoods FROM insertedENDELSEPRINT '你插⼊的数据中的时间只能在 2012-1-1 到 2015-1-1 中间'ENDGO执⾏:INSERT INTO OrderInfo(UserId,CommodityId,Amount,PayWay,OrderTime,Confirm,SendGoods)VALUES('YOUYOU',1,5,'⽹上银⾏','2013-1-11',1,1) 注意:这⾥插⼊时我并没有定义PayMoney,PayMoney是通过触发器来⾃动计算的结果:⽇期不正确:⽇期正确:打印信息对应:@UserId+' '+@CommodityId+' '+@Amount+' '+@PayMoney+' '+@PayWay+' '@OrderTime+' '@Confirm+' '+@SendGoods+' '@outPrice3.⾏级触发器(错误)执⾏结果:可以看出在SQL server中并不⽀持⾏级触发器。

SqlServer使用存储过程实现插入或更新语句SqlServer 使用存储过程实现插入或更新语句存储过程的功能非常强大,在某种程度上甚至可以替代业务逻辑层,接下来就一个小例子来说明,用存储过程插入或更新语句。
1、数据库表结构2、创建存储过程1Create proc[dbo].[sp_Insert_Student]2@No char(10),3@Name varchar(20),4@Sex char(2),5@Age int,6@rtn int output7as8declare9@tmpName varchar(20),10@tmpSex char(2),11@tmpAge int1213if exists(select*from Student where No=@No)14begin15select@tmpName=Name,@tmpSex=Sex,@tmpAge=Age from Student where No=@No16if ((@tmpName=@Name) and (@tmpSex=@Sex) and(@tmpAge=@Age))17begin18set@rtn=019end20else21begin22update Student set Name=@Name,Sex=@Sex,Age=@Agewhere No=@No23set@rtn=224end25end26else27begin28insert into Student values(@No,@Name,@Sex,@Age) 29set@rtn=130end3、调用存储过程1declare@rtn int2exec sp_Insert_Student '1101','张三','男',23,@rtn output34if@rtn=05print'已经存在相同的。
'6else if@rtn=17print'插入成功。

sqlsever insert语句SQL Server Insert语句是SQL Server关系型数据库管理系统中最常用的功能之一,用于将新数据插入到指定的数据库表中,其实现包含多个步骤。
一、准备插入数据在使用SQL Server Insert语句前,需要先准备好要插入的数据。
通常情况下,可以使用文本编辑器或数据表格编辑器来创建要插入的数据。
然后将数据保存为文件或表格式,以便将其传递给SQL Server。
二、连接数据库使用SQL Server Insert语句之前,需要先连接到目标数据库。
可以使用SQL Server Management Studio等工具来连接数据库,也可以使用代码来连接。
需要提供数据库名称、主机名、用户名和密码等必要信息来连接SQL Server数据库。
三、创建Insert语句创建Insert语句是将准备好的数据插入到数据库表中的关键步骤。
Insert语句的格式如下:INSERT INTO table_name (column1, column2,column3,...column_n) VALUES (value1, value2,value3,...value_n);其中,table_name是目标数据库表的名称,column1、column2、column3等是数据库表的列名,value1、value2、value3等是要插入的具体数据。
需要根据实际情况修改表名、列名和数据。
多个数据值之间使用逗号分隔。
例如,要将以下数据插入到名为“students”的数据库表中:名字年龄Tom 18Alice 20Mike 19可以使用以下SQL Server Insert语句:INSERT INTO students (name, age) VALUES ('Tom', 18),('Alice', 20), ('Mike', 19);其中,name和age是表的列名,'Tom'、18、'Alice'等是具体的数据值。

sqlserver存储过程循环写法⽤游标,和WHILE可以遍历您的查询中的每⼀条记录并将要求的字段传给变量进⾏相应的处理==================DECLARE@A1 VARCHAR(10),@A2 VARCHAR(10),@A3 INTDECLARE CURSOR YOUCURNAME FOR SELECT A1,A2,A3 FROM YOUTABLENAMEOPEN YOUCURNAMEfetch next from youcurname into @a1,@a2,@a3while @@fetch_status<>-1beginupdate … set …-a3 where ………您要执⾏的操作写在这⾥fetch next from youcurname into @a1,@a2,@a3endclose youcurnamedeallocate youcurname—————————————在应⽤程序开发的时候,我们经常可能会遇到下⾯的应⽤,我们会通过查询数据表的记录集,循环每⼀条记录,通过每⼀条的记录集对另⼀张表进⾏数据进⾏操作,如插⼊与更新,我们现在假设有⼀个这样的业务:⽼师为所在班级的学⽣选课,选的课程如有哲学、马克思主义政治经济学、XXX思想概论、*理论这些课,现在操作主要如下:1) 先要查询这些还没有毕业的这些学⽣的名单,毕业过后的⽆法进⾏选课;2) 在批量的选取学⽣的同时,还需要添加对应的某⼀门课程;3) 点添加后选课结束。
数据量少可能看不出⽤程序直接多次进⾏操作这种办法实现的弱点,因为它每次在操作数据库的时候,都存在着频繁的和数据库的I/O直接交互,这点性能的牺牲实属不应该,那我们就看下⾯的⽅法,通过存储过程的游标⽅法来实现:建⽴存储过程:Create PROCEDURE P_InsertSubject@SubjectId intASDECLARE rs CURSOR LOCAL SCROLL FORselect studentid from student where StudentGradu = 1OPEN rsFETCH NEXT FROM rs INTO @tempStudentIDWHILE @@FETCH_STATUS = 0BEGINInsert SelSubject values (@SubjectId,@tempStudentID)FETCH NEXT FROM rs INTO @tempStudentIDENDCLOSE rs使⽤游标对记录集循环进⾏处理的时候⼀般操作如以下⼏个步骤:1、把记录集传给游标;2、打开游标3、开始循环4、从游标中取值5、检查那⼀⾏被返回6、处理7、关闭循环8、关闭游标上⾯这种⽅法在性能上⾯⽆疑已经是提⾼很多了,但我们也想到,在存储过程编写的时候,有时候我们尽量少的避免使⽤游标来进⾏操作,所以我们还可以对上⾯的存储过程进⾏改造,使⽤下⾯的⽅法来实现:Create PROCEDURE P_InsertSubject@SubjectId intASdeclare @i int,@studentidDECLARE @tCanStudent TABLE(studentid int,FlagID TINYINT)BEGINinsert @tCanStudent select studentid,0 from student where StudentGradu = 1WHILE( @i>=1)BEGINSELECT @studentid='’SELECT TOP 1 @studentid = studentid FROM @tCanStudent WHERE flagID=0SET @i=@@ROWCOUNTIF @i<=0 GOTO Return_LabInsert SelSubject values (@SubjectId,@studentid)IF @@error=0UPDATE @tCanStudent SET flagID=1 WHERE studentid = @studentidReturn_Lab:ENDEndGO我们现在再来分析以上这个存储过程,它实现的⽅法是先把满⾜条件的记录集数据存放到⼀个表变量中,并且在这个表变量中增加⼀个FLAGID进⾏数据初始值为0的存放,然后去循环这个记录集,每循环⼀次,就把对应的FLAGID的值改成1,然后再根据循环来查找满⾜条件等于0的情况,可以看到,每循环⼀次,处理的记录集就会少⼀次,然后循环的往选好课程表⾥⾯插⼊,直到记录集的条数为0时停⽌循环,此时完成操作。

SqlServer通⽤存储过程的编写通⽤存储过程的编写对数据库的操作基本上就四种:Insert、Update、Delete和Select,⽽Update和Insert两种操作⼜可以作简单的合并,这样下来,基本上⼀个数据表对应三个存储过程便可以完成绝⼤多数的数据库操作。
存储过程命名规则:Operate_TableName。
⽐如表Order_Info对应三个存储过程:AddEdit_Order_Info、Delete_Order_Info、Search_Order_Info,下⾯先列出相关代码,然后作总体分析。
⼀、AddEdit_Order_Info/*************************************************************** Name : AddEdit_Order_Info** Creater : PPCoder Designed By PPCode Studio()** Create Date : 2004-9-6 8:30:17** Modifer : Rexsp** Modify Date : 2004-9-6 8:30:17** Description : AddEdit information for Order_Info**************************************************************/ALTER PROCEDURE dbo.AddEdit_Order_Info(@OrderStateID Int=-1,@OrderStateID_Min Int=-1,@OrderStateID_Max Int=-1,@OrderUserID Int=-1,@OrderUserID_Min Int=-1,@OrderUserID_Max Int=-1,@OrderID Int=-1,@OrderID_Min Int=-1,@OrderID_Max Int=-1,@ProductID Int=-1,@ProductID_Min Int=-1,@ProductID_Max Int=-1,@CustomizeID Int=-1,@CustomizeID_Min Int=-1,@CustomizeID_Max Int=-1,@OutID INT=0 OUTPUT)ASIF @OrderID=-1BEGININSERT INTO[Order_Info] ([OrderStateID],[OrderUserID],[ProductID],[CustomizeID])VALUES(@OrderStateID,@OrderUserID,@ProductID,@CustomizeID)Set @OutID = @@IDENTITYENDELSEBEGINDECLARE @strSQL NVARCHAR(1000)SET @strSQL ='UPDATE [Order_Info] SET @tmpOrderID = @tmpOrderID'IF @OrderStateID <>-1BEGINSET @strSQL = @strSQL +', [OrderStateID] = @tmpOrderStateID'ENDIF @OrderUserID <>-1BEGINSET @strSQL = @strSQL +', [OrderUserID] = @tmpOrderUserID'ENDIF @ProductID <>-1BEGINSET @strSQL = @strSQL +', [ProductID] = @tmpProductID'ENDIF @CustomizeID <>-1BEGINSET @strSQL = @strSQL +', [CustomizeID] = @tmpCustomizeID' ENDSET @strSQL = @strSQL +' WHERE [OrderID] = @tmpOrderID'BEGIN TRANEXECUTE sp_executesql @strSQL, N'@tmpOrderStateID INT,@tmpOrderUserID INT,@tmpOrderID INT,@tmpProductID INT,@tmpCustomizeID INT',@tmpOrderStateID=@OrderStateID,@tmpOrderUserID=@OrderUserID,@tmpOrderID=@OrderID,@tmpProductID=@ProductID,@tmpCustomizeID=@CustomizeIDSet @OutID = @OrderIDIF @@error!=0BEGINROLLBACKENDELSEBEGINCOMMITENDENDRETURN⼆、Delete_Order_Info/*************************************************************** Name : Delete_Order_Info** Creater : PPCoder Designed By PPCode Studio()** Create Date : 2004-9-6 8:30:17** Modifer : Rexsp** Modify Date : 2004-9-6 8:30:17** Description : Delete information for Order_Info**************************************************************/ALTER PROCEDURE dbo.Delete_Order_Info(@OrderStateID Int=-1,@OrderStateID_Min Int=-1,@OrderStateID_Max Int=-1,@OrderUserID Int=-1,@OrderUserID_Min Int=-1,@OrderUserID_Max Int=-1,@OrderID Int=-1,@OrderID_Min Int=-1,@OrderID_Max Int=-1,@ProductID Int=-1,@ProductID_Min Int=-1,@ProductID_Max Int=-1,@CustomizeID Int=-1,@CustomizeID_Min Int=-1,@CustomizeID_Max Int=-1,@OutID INT=0 OUTPUT)ASDECLARE @strSQL NVARCHAR(1000)SET @strSQL ='DELETE FROM [Order_Info] WHERE @tmpOrderID = @tmpOrderID ' IF @OrderStateID<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID = @tmpOrderStateID'ENDIF @OrderStateID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID_Min = @tmpOrderStateID_Min' ENDIF @OrderStateID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID_Max = @tmpOrderStateID_Max' ENDIF @OrderUserID<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID = @tmpOrderUserID'ENDIF @OrderUserID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID_Min = @tmpOrderUserID_Min' ENDIF @OrderUserID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID_Max = @tmpOrderUserID_Max' ENDIF @OrderID<>-1BEGINSET @strSQL = @strSQL +' AND OrderID = @tmpOrderID'ENDIF @OrderID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderID_Min = @tmpOrderID_Min'ENDIF @OrderID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderID_Max = @tmpOrderID_Max'ENDIF @ProductID<>-1BEGINSET @strSQL = @strSQL +' AND ProductID = @tmpProductID'ENDIF @ProductID_Min<>-1BEGINSET @strSQL = @strSQL +' AND ProductID_Min = @tmpProductID_Min'ENDIF @ProductID_Max<>-1BEGINSET @strSQL = @strSQL +' AND ProductID_Max = @tmpProductID_Max'ENDIF @CustomizeID<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID = @tmpCustomizeID'ENDIF @CustomizeID_Min<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID_Min = @tmpCustomizeID_Min' ENDIF @CustomizeID_Max<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID_Max = @tmpCustomizeID_Max'ENDBEGIN TRANEXECUTE sp_executesql @strSQL, N'@tmpOrderStateID INT,@tmpOrderUserID INT,@tmpOrderID INT,@tmpProductID INT,@tmpCustomizeID INT',@tmpOrderStateID=@OrderStateID,@tmpOrderUserID=@OrderUserID,@tmpOrderID=@OrderID,@tmpProductID=@ProductID,@tmpCustomizeID=@CustomizeIDSet @OutID = @OrderIDIF @@error!=0BEGINROLLBACKENDELSEBEGINCOMMITENDRETURN三、 Search_Order_Info/*************************************************************** Name : Search_Order_Info** Creater : PPCoder Designed By PPCode Studio()** Create Date : 2004-9-6 8:30:17** Modifer : Rexsp** Modify Date : 2004-9-6 8:30:17** Description : Search information for Order_Info**************************************************************/ALTER PROCEDURE dbo.Search_Order_Info(@OrderStateID Int=-1,@OrderStateID_Min Int=-1,@OrderStateID_Max Int=-1,@OrderUserID Int=-1,@OrderUserID_Min Int=-1,@OrderUserID_Max Int=-1,@OrderID Int=-1,@OrderID_Min Int=-1,@OrderID_Max Int=-1,@ProductID Int=-1,@ProductID_Min Int=-1,@ProductID_Max Int=-1,@CustomizeID Int=-1,@CustomizeID_Min Int=-1,@CustomizeID_Max Int=-1,@ReturnCount INT=-1,@OutID INT=0 OUTPUT)ASDECLARE @strSQL NVARCHAR(1000)IF @ReturnCount<>-1BEGINSET @strSQL ='SELECT TOP '+@ReturnCount+' * FROM [Order_Info] WHERE @tmpOrderID = @tmpOrderID 'ENDELSEBEGINSET @strSQL ='SELECT * FROM [Order_Info] WHERE @tmpOrderID = @tmpOrderID ' ENDIF @OrderStateID<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID = @tmpOrderStateID'ENDIF @OrderStateID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID_Min = @tmpOrderStateID_Min' ENDIF @OrderStateID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderStateID_Max = @tmpOrderStateID_Max' ENDIF @OrderUserID<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID = @tmpOrderUserID'ENDIF @OrderUserID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID_Min = @tmpOrderUserID_Min'ENDIF @OrderUserID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderUserID_Max = @tmpOrderUserID_Max' ENDIF @OrderID<>-1BEGINSET @strSQL = @strSQL +' AND OrderID = @tmpOrderID'ENDIF @OrderID_Min<>-1BEGINSET @strSQL = @strSQL +' AND OrderID_Min = @tmpOrderID_Min'ENDIF @OrderID_Max<>-1BEGINSET @strSQL = @strSQL +' AND OrderID_Max = @tmpOrderID_Max'ENDIF @ProductID<>-1BEGINSET @strSQL = @strSQL +' AND ProductID = @tmpProductID'ENDIF @ProductID_Min<>-1BEGINSET @strSQL = @strSQL +' AND ProductID_Min = @tmpProductID_Min'ENDIF @ProductID_Max<>-1BEGINSET @strSQL = @strSQL +' AND ProductID_Max = @tmpProductID_Max'ENDIF @CustomizeID<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID = @tmpCustomizeID'ENDIF @CustomizeID_Min<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID_Min = @tmpCustomizeID_Min'ENDIF @CustomizeID_Max<>-1BEGINSET @strSQL = @strSQL +' AND CustomizeID_Max = @tmpCustomizeID_Max'ENDBEGIN TRANEXECUTE sp_executesql @strSQL, N'@tmpOrderStateID INT,@tmpOrderUserID INT,@tmpOrderID INT,@tmpProductID INT,@tmpCustomizeID INT',@tmpOrderStateID=@OrderStateID,@tmpOrderUserID=@OrderUserID,@tmpOrderID=@OrderID,@tmpProductID=@ProductID,@tmpCustomizeID=@CustomizeIDSet @OutID = @OrderIDIF @@error!=0BEGINROLLBACKENDELSEBEGINCOMMITEND分析:1、三个存储过程的⼊参基本上相同,只有Search_Order_Info多了⼀个@ReturnCount⽤来控制搜索信息的条数的。

sqlserver存储过程举例SQL Server存储过程是一段预先编译好的SQL代码,能够被多次执行。
它可以接受输入参数并返回输出参数,还可以执行逻辑判断和循环等复杂操作。
下面我列举了10个例子来展示SQL Server存储过程的使用。
1. 创建新的存储过程:```sqlCREATE PROCEDURE sp_CreateNewEmployee@FirstName NVARCHAR(50),@LastName NVARCHAR(50),@Salary FLOATASBEGININSERT INTO Employees (FirstName, LastName, Salary)VALUES (@FirstName, @LastName, @Salary)END```这个存储过程用于向Employees表中插入新的员工记录。
2. 更新存储过程:```sqlCREATE PROCEDURE sp_UpdateEmployeeSalary@EmployeeID INT,@NewSalary FLOATASBEGINUPDATE EmployeesSET Salary = @NewSalaryWHERE EmployeeID = @EmployeeID END```这个存储过程用于更新指定员工的薪水。
3. 删除存储过程:```sqlCREATE PROCEDURE sp_DeleteEmployee @EmployeeID INTASBEGINDELETE FROM EmployeesWHERE EmployeeID = @EmployeeID END```这个存储过程用于删除指定员工的记录。
4. 查询存储过程:```sqlCREATE PROCEDURE sp_GetEmployeeByID@EmployeeID INTASBEGINSELECT * FROM EmployeesWHERE EmployeeID = @EmployeeIDEND```这个存储过程用于根据员工ID查询员工信息。

sqlserver select 中使用存储过程SQL Server中使用存储过程是一种提高数据库性能和代码重用性的技术。
在查询中使用存储过程可以将一组SQL语句封装在一个单元中,并且可以将参数传递给存储过程。
下面是一些关于在SQL Server中使用存储过程的详细信息。
1. 存储过程的定义和使用:在SQL Server中创建和使用存储过程非常简单。
可以使用CREATE PROCEDURE语句创建存储过程,并使用EXECUTE或EXEC语句执行存储过程。
存储过程可以包含输入参数、输出参数和返回值。
以下是一个简单的存储过程的示例:CREATE PROCEDURE GetCustomersByCity@City VARCHAR(255)ASBEGINSELECT * FROM Customers WHERE City = @CityEND在上面的示例中,我们创建了一个名为GetCustomersByCity的存储过程,它接收一个City参数,并在Customers表中选择所有匹配该城市的客户。
下面是如何执行该存储过程的示例:EXEC GetCustomersByCity 'London'通过执行上面的语句,存储过程将返回所有位于伦敦的客户。
2. 存储过程的优点:使用存储过程有以下几个优点:- 提高性能:存储过程在服务器端执行,减少了网络传输量,提高了查询的执行速度。
此外,存储过程还可以进行查询优化和索引优化,进一步提高查询性能。
- 代码重用:可以将一些常用的查询逻辑封装在存储过程中,在不同的应用程序中重复使用。
这样可以减少代码量,提高开发效率。
- 安全性:存储过程可以设置权限,只有有权限的用户才能执行存储过程。
这样可以提高数据的安全性。
- 数据一致性:存储过程可以执行一系列的操作,保证数据的一致性。
例如,在一个存储过程中可以同时更新多个表,保证数据的完整性。
3. 存储过程参数的使用:存储过程可以接收输入参数、输出参数和返回值。
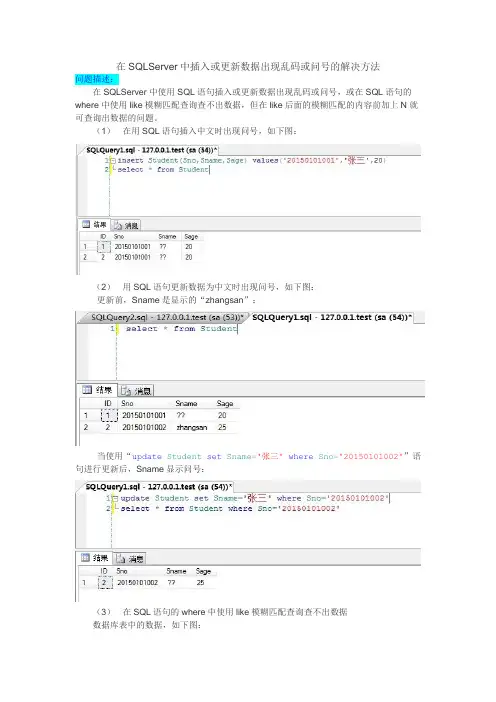
在SQLServer中插入或更新数据出现乱码或问号的解决方法问题描述:在SQLServer中使用SQL语句插入或更新数据出现乱码或问号,或在SQL语句的where中使用like模糊匹配查询查不出数据,但在like后面的模糊匹配的内容前加上N就可查询出数据的问题。
(1)在用SQL语句插入中文时出现问号,如下图:(2)用SQL语句更新数据为中文时出现问号,如下图:更新前,Sname是显示的“zhangsan”:当使用“update Student set Sname='张三'where Sno='20150101002'”语句进行更新后,Sname显示问号:(3)在SQL语句的where中使用like模糊匹配查询查不出数据数据库表中的数据,如下图:使用like模糊匹配查询查不出数据,如下图:但在like后面的模糊匹配的内容前加上N就可查询出数据,如下图:问题产生的原因:由于数据库属性的排序规则设置不正确。
解决方法:方法一:手动修改(设置数据库的排序规则)具体步骤:选中要修改的数据库-->右键-->属性-->弹出数据库属性对话框-->选项-->把排序规则设置成:Chinese_PRC_90_CI_AS-->确定。
(1)选中要修改的数据库→右键→属性:(2)弹出数据库属性对话框→选项→把排序规则设置成:Chinese_PRC_90_CI_AS→确定注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:方法二:使用SQL语句修改在查询分析器中输入下面的SQL语句执行即可:USE masterGOALTER DATABASE数据库名COLLATE排序规则如要修改test数据库的排序规则,则可:USE masterGOALTER DATABASE test COLLATE Chinese_PRC_90_CI_AS注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:当在修改数据库排序规则时要修改的数据库被使用从而导致排序规则修改失败时的处理方法:重启数据库服务:选中数据库服务器→右键→重新启动即可:排序规则术语:什么是排序规则呢?排序规则是根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。

关于sql server存储过程中单个或批量数据的增加、删除、修改操作方法举个简单的例子:T_MYTEST表中有两个字段ID NV ARCHAR(50),NAME NV ARCHAR(50)界面参数设置:ArrayList ParaSet = new ArrayList();ArrayList ParaValue = new ArrayList();ArrayList ParaKeyName = new ArrayList();ArrayList SelectRowList = new ArrayList();GetSelectItemInf(ref SelectRowList); //获得grid选择的行foreach (Infragistics.Win.UltraWinGrid.UltraGridRow row in SelectRowList) {ParaKeyName.Add("NULL");//用来记录操作的记录条数//注意参数名称和值成对添加ParaSet.Add("EDITTYPE"); //操作类型ParaValue.Add("ADD");ParaSet.Add("ID");//IDParaValue.Add(row.Cells["ID"].Value.ToString());ParaSet.Add("NAME");//NAMEParaValue.Add(row.Cells["ID"].Value.ToString());}int ParamCount = ParaKeyName.Count; //操作次数string ParamName = string.Empty; //参数名称string ParamValue = string.Empty; //参数值for (int a = 0; a < ParaSet.Count; a++){//参数之间用▲分隔ParamName = ParamName + ParaSet[a].ToString().Replace("▲", "") + "▲"; ParamValue = ParamValue + ParaValue[a].ToString().Replace("▲", "") + "▲"; }//设置参数(@ParamCount, @ParamName, @ParamValue ,@ExeOutInf),//然后再调用存储过程(我这就不写了)//删除、修改也类型可以是单条或批量数据库存储过程如下:ALTER PROCEDURE [dbo].[sp_name]@ForCount INT,--总循环次数@ParamName NVARCHAR(MAX),--名称@ParamValue NVARCHAR(MAX),--值@ExeOutInf NVARCHAR(100)OUT--返回值ASBEGINSET NOCOUNT ON;DECLARE @EditType NVARCHAR(100);--记录操作类型DECLARE @ForNum INT;--记录循环次数SET @ForNum = 1;--设置初始值--定义表所有列参数DECLARE @L_id NVARCHAR(50);--编号DECLARE @L_name NVARCHAR(50);--名称DECLARE @L_FLOG INT;--纪录是否存在标志位--求所有参数的总长度DECLARE @TotalNameCount INT;--记录总数DECLARE @PosFlog INT;--记录字符串中'▲'的位置DECLARE @VarName NVARCHAR(MAX);--记录操作字符串SET @TotalNameCount = 0;--设置初始值为0SET @PosFlog = 1;--设置初始值为1SET @VarName = @ParamName;--设置初始值为传进来的参数@ParamName--循环获取参数总个数WHILE(@PosFlog > 0)BEGINSET @PosFlog =PATINDEX('%▲%',@VarName);IF(@PosFlog > 1)BEGINSET @TotalNameCount = @TotalNameCount + 1;SET @VarName =SUBSTRING(@VarName ,@PosFlog +1,LEN(@VarName));END;END;DECLARE @RecordParamLength INT;--单条纪录的长度SET @RecordParamLength = @TotalNameCount/@ForCount;DECLARE @VarRecordParamLength INT;--单条记录循环变量DECLARE @ColumnName NVARCHAR(MAX);--列名BEGIN TRAN OperateTran;--开始事务WHILE(@ForNum <= @ForCount)--循环BEGINSET @VarRecordParamLength = 0;--初始化SET @ForNum = @ForNum + 1;--下一次循环--循环取单条记录的所有参数WHILE(@VarRecordParamLength < @RecordParamLength)BEGINSET @VarRecordParamLength = @VarRecordParamLength + 1;SET @ColumnName =SUBSTRING(@ParamName,0,PATINDEX('%▲%',@ParamName));--获取各个参数的对应的值IF(@ColumnName ='EDITTYPE')BEGINSET @EditType =SUBSTRING(@ParamValue ,1 ,PATINDEX('%▲%',@ParamValue)- 1)END;IF(@ColumnName ='ID')BEGINSET @L_id =SUBSTRING(@ParamValue ,1 ,PATINDEX('%▲%',@ParamValue)- 1);END;IF(@ColumnName ='NAME')BEGINSET @L_name =SUBSTRING(@ParamValue ,1 ,PATINDEX('%▲%',@ParamValue)- 1);END;SET @ParamName =SUBSTRING(@ParamName ,PATINDEX('%▲%',@ParamName)+1,LEN(@ParamName));SET @ParamValue =SUBSTRING(@ParamValue ,PATINDEX('%▲%',@ParamValue)+1,LEN(@ParamValue));END;--添加IF(@EditType ='ADD')BEGINSET @L_FLOG =(SELECT COUNT(*)FROM T_MYTESTWHERE ID = @L_ID);IF(@L_FLOG ='1')BEGINSET @ExeOutInf ='对不起,该记录信息已经存在.';END;ELSEBEGININSERT INTO T_MYTEST(id,name)VALUES(@L_id,@L_name);SET @ExeOutInf ='NEWID:'+'ID;'+ @L_ID;END;END;--修改IF(@EditType ='EDIT')BEGINSET @L_FLOG =(SELECT COUNT(*)FROM T_MYTESTWHERE ID = @L_ID);IF(@L_FLOG ='0')BEGINSET @ExeOutInf ='对不起,该记录信息不存在,不能进行修改.';END;ELSEBEGINUPDATE T_MYTESTSET id = @L_id,name= @L_nameWHERE id = @L_id;END;END;--删除IF(@EditType ='DEL')BEGINSET @L_FLOG =(SELECT COUNT(*)FROM T_MYTESTWHERE ID = @L_ID);IF(@L_FLOG ='0')BEGINSET @ExeOutInf ='对不起,该记录信息不存在,不能进行删除.';END;ELSEBEGINDELETE T_MYTESTWHERE id = @L_id;END;END;END;IF(@@Error> 0)--如果事务有错误,返回,表示为不成功BEGINROLLBACK TRAN OperateTran;return'0';ENDELSE--否则执行事务,返回,表示成功BEGINCOMMIT TRAN;return'1';ENDEND总结:用这种方法编写存储过程的一点好处:1、增加、删除、修改方法放在同一个存储过程中;2、可以进行单个或批量数据增加、删除、修改操作;3、客户端调用存储过程方法统一,都是@ParamCount, @ParamName,@ParamValue ,@ExeOutInf四个参数,可以把它分离出一个方法。
SQLSERVER存储过程基本语法⼀、定义变量--简单赋值declare@a intset@a=5print@a--使⽤select语句赋值declare@user1nvarchar(50)select@user1='张三'print@user1declare@user2nvarchar(50)select@user2= Name from ST_User where ID=1print@user2--使⽤update语句赋值declare@user3nvarchar(50)update ST_User set@user3= Name where ID=1print@user3⼆、表、临时表、表变量--创建临时表1create table #DU_User1([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL);--向临时表1插⼊⼀条记录insert into #DU_User1 (ID,Oid,[Login],Rtx,Name,[Password],State) values (100,2,'LS','0000','临时','321','特殊');--从ST_User查询数据,填充⾄新⽣成的临时表select*into #DU_User2 from ST_User where ID<8--查询并联合两临时表select*from #DU_User2 where ID<3union select*from #DU_User1--删除两临时表drop table #DU_User1drop table #DU_User2--创建临时表CREATE TABLE #t([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL,)--将查询结果集(多条数据)插⼊临时表insert into #t select*from ST_User--不能这样插⼊--select * into #t from dbo.ST_User--添加⼀列,为int型⾃增长⼦段alter table #t add[myid]int NOT NULL IDENTITY(1,1)--添加⼀列,默认填充全球唯⼀标识alter table #t add[myid1]uniqueidentifier NOT NULL default(newid())select*from #tdrop table #t--给查询结果集增加⾃增长列--⽆主键时:select IDENTITY(int,1,1)as ID, Name,[Login],[Password]into #t from ST_Userselect*from #t--有主键时:select (select SUM(1) from ST_User where ID<= a.ID) as myID,*from ST_User a order by myID--定义表变量declare@t table(id int not null,msg nvarchar(50) null)insert into@t values(1,'1')insert into@t values(2,'2')select*from@t三、循环--while循环计算1到100的和declare@a intdeclare@sum intset@a=1set@sum=0while@a<=100beginset@sum+=@aset@a+=1endprint@sum四、条件语句--if,else条件分⽀if(1+1=2)beginprint'对'endelsebeginprint'错'end--when then条件分⽀declare@today intdeclare@week nvarchar(3)set@today=3set@week=casewhen@today=1then'星期⼀'when@today=2then'星期⼆'when@today=3then'星期三'when@today=4then'星期四'when@today=5then'星期五'when@today=6then'星期六'when@today=7then'星期⽇'else'值错误'endprint@week五、游标declare@ID intdeclare@Oid intdeclare@Login varchar(50)--定义⼀个游标declare user_cur cursor for select ID,Oid,[Login]from ST_User --打开游标open user_curwhile@@fetch_status=0begin--读取游标fetch next from user_cur into@ID,@Oid,@Loginprint@ID--print @Loginendclose user_cur--摧毁游标deallocate user_cur六、触发器 触发器中的临时表: Inserted 存放进⾏insert和update 操作后的数据 Deleted 存放进⾏delete 和update操作前的数据--创建触发器Create trigger User_OnUpdateOn ST_Userfor UpdateAsdeclare@msg nvarchar(50)--@msg记录修改情况select@msg= N'姓名从“'+ + N'”修改为“'+ +'”'from Inserted,Deleted --插⼊⽇志表insert into[LOG](MSG)values(@msg)--删除触发器drop trigger User_OnUpdate七、存储过程--创建带output参数的存储过程CREATE PROCEDURE PR_Sum@a int,@b int,@sum int outputASBEGINset@sum=@a+@bEND--创建Return返回值存储过程CREATE PROCEDURE PR_Sum2@a int,@b intASBEGINReturn@a+@bEND--执⾏存储过程获取output型返回值declare@mysum intexecute PR_Sum 1,2,@mysum outputprint@mysum--执⾏存储过程获取Return型返回值declare@mysum2intexecute@mysum2= PR_Sum2 1,2print@mysum2⼋、⾃定义函数 函数的分类: 1)标量值函数 2)表值函数 a:内联表值函数 b:多语句表值函数 3)系统函数--新建标量值函数create function FUNC_Sum1(@a int,@b int)returns intasbeginreturn@a+@bend--新建内联表值函数create function FUNC_UserTab_1(@myId int)returns tableasreturn (select*from ST_User where ID<@myId)--新建多语句表值函数create function FUNC_UserTab_2(@myId int)returns@t table([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL)asbegininsert into@t select*from ST_User where ID<@myIdreturnend--调⽤表值函数select*from dbo.FUNC_UserTab_1(15)--调⽤标量值函数declare@s intset@s=dbo.FUNC_Sum1(100,50)print@s--删除标量值函数drop function FUNC_Sum1谈谈⾃定义函数与存储过程的区别:⼀、⾃定义函数: 1. 可以返回表变量 2. 限制颇多,包括 不能使⽤output参数; 不能⽤临时表; 函数内部的操作不能影响到外部环境; 不能通过select返回结果集; 不能update,delete,数据库表; 3. 必须return ⼀个标量值或表变量 ⾃定义函数⼀般⽤在复⽤度⾼,功能简单单⼀,争对性强的地⽅。
sqlserver存储过程调用语法SQL Server存储过程调用语法存储过程是SQL Server数据库中一种重要的对象,它是一组预编译的SQL语句集合,可以被多次调用和执行。
通过存储过程,可以提高数据库的性能,降低网络传输的开销,并且可以实现复杂的业务逻辑。
在SQL Server中,调用存储过程可以使用以下语法:EXECUTE [数据库名].[模式名].存储过程名 [参数1, 参数2, ...]其中,EXECUTE关键字用于执行存储过程,数据库名和模式名是可选的,如果存储过程在当前数据库中,可以省略这两部分。
存储过程名是需要调用的存储过程的名称。
参数1, 参数2, ...是可选的输入参数,用于向存储过程传递数值或数据。
在调用存储过程时,可以按照以下几种方式传递参数:1. 位置传参:按照存储过程定义中参数的位置依次传递参数值,参数之间用逗号分隔。
例如:EXECUTE 存储过程名参数值1, 参数值2, ...2. 关键字传参:按照存储过程定义中参数的名称和对应的参数值进行传参,参数之间用逗号分隔。
例如:EXECUTE 存储过程名 @参数名1 = 参数值1, @参数名2 = 参数值2, ...3. 混合传参:可以同时使用位置传参和关键字传参的方式进行调用。
例如:EXECUTE 存储过程名参数值1, @参数名2 = 参数值2, ...在调用存储过程时,还可以使用OUTPUT关键字来获取存储过程的输出参数值。
输出参数必须在存储过程定义中使用OUTPUT关键字进行声明,例如:CREATE PROCEDURE 存储过程名@输入参数1 数据类型,@输出参数1 数据类型 OUTPUTASBEGIN-- 存储过程的逻辑代码SET @输出参数1 = ...END在调用存储过程时,可以使用以下语法获取输出参数的值:DECLARE @输出参数1 数据类型EXECUTE 存储过程名参数1, @输出参数1 = @输出参数1 OUTPUT在实际应用中,存储过程的调用可以嵌套在其他的SQL语句或事务中。
sqlserver update语句
更新是数据库管理中一种重要的运算操作,它指的是将既有数据库中重用或不能重用的数据进行变更,即更新或修改数据库内容,也可称为修改运算。
对SQL Server来说,要更新数据,首先要明确要更新的数据,包括它们的表名,字段名,新值等,不同的更新操作可以通过两种更新语句“UPDATE”和“SET”来实现。
一般的SQL Server更新语句的形式如下:
UPDATE 表名
SET 字段名1 = 新值1,字段名2= 新值2,…
WHERE 条件表达式
例如:
对于需要更新多个字段可以采用:
如果更新的值也是表中的字段,可以直接在SET子句中将新字段的值设置成指定的字段的当前值。
如果要更新多个表,则可以使用UPDATE语句的多表形式:
除了这种使用UPDATE语句来更新数据库的方法外,SQL Server还提供另外两种更新操作的方法:数据结构更新和系统函数更新。
1、数据结构更新
使用数据结构更新,就是在UPDATE语句中使用系统函数或存储过程,将表的结构以及表的内容一并更新,而不仅仅针对其中某些字段。
使用ALTER TABLE语句可以更改表结构,然后利用系统函数或存储过程可以将表中已有的内容更新成所需要的新内容。
2、系统函数更新
系统函数更新是在SQL Server中使用某些特定函数,将表的内容更新为新的内容的方法。
上面的UPDATE语句说明了当条件表达式满足时,就会更新字段名1,它会将字段名1中的“old”替换成“new”。
实验六SQL server 数据插入、更新与删除【实验目的】
1.掌握INSERT、UPDA TE、DELETE命令的用法。
2.理解执行数据插入、更新、删除命令时,数据库实体完整性对操作的影响。
3.理解执行数据插入、更新、删除命令时,数据库参照完整性对操作的影响。
【实验学时】
建议2学时
【实验环境配置】
1.SQLSERVER环境
【实验原理】
SQL 语言中的INSERT、UPDA TE、DELETE语句语法
【实验步骤】
1、创建数据库test_db,并且根据表1所示,创建student表、sc表和course表。
2、执行INSERT语句,为student表、course表和SC表分别添加3条记录,注意添加信息
的次序和数据库完整性的影响。
(注意保存INSERT语句的SQL语句,以便执行UPDA TE 语句和DELETE语句)
3、执行UPDATE语句,更改SC表新添加的记录中关于学生和课程的信息。
4、执行DELETE语句,删除student表、course表的任意一条记录,注意数据库完整性的
影响。
student 表数据
sc表数据
course表数据。
sql server 存储过程语法SQL Server 存储过程是一种预编译的、可复用的存储对象,其中包含一组可由应用程序调用的 T-SQL 语句。
存储过程可以接受输入参数和输出参数,并能够对相关表进行插入、更新、删除等操作。
下面是 SQL Server 存储过程的语法和使用方法,以及相应的案例。
1.语法:```sqlCREATE [ OR ALTER ] PROCEDURE procedure_name[ @parameter [ data type ] [ = default ] [ OUT | OUTPUT | INOUT ] ] ASBEGIN-- T-SQL statement(s)ENDGO```2.使用方法:1. 创建存储过程:使用 CREATE PROCEDURE 创建存储过程,设置存储过程名称、输入参数、输出参数和 T-SQL 语句等。
2. 执行存储过程:通过 EXECUTE 或 EXEC 命令执行存储过程,并传递相关的参数。
3. 删除存储过程:使用 DROP PROCEDURE 删除存储过程。
3.案例:假设有一张 Students 表,包含学生的名字、学号和成绩等信息。
现在需要创建一个存储过程,根据输入的学号查询对应学生的成绩,并返回查询结果。
下面是存储过程的实现代码:```sqlCREATE PROCEDURE Proc_GetStudentScore@student_id INT,@score INT OUTASBEGINSELECT @score = Score FROM Students WHERE StudentID = @student_id;END```在上面的代码中,存储过程 Proc_GetStudentScore 包含一个输入参数@student_id 和一个输出参数@score。
T-SQL 语句通过查询 Students 表,获取指定学号的学生成绩,并将结果存储在 @score 参数中。