应用抽样技术(第二版)李金昌课后习题
- 格式:docx
- 大小:2.46 MB
- 文档页数:21

应用抽样技术练习题一、选择题1. 下列哪种抽样方法属于非概率抽样?A. 简单随机抽样B. 分层抽样C. 方便抽样D. 系统抽样2. 在简单随机抽样中,每个个体被抽中的概率是:A. 不相等B. 相等C. 逐渐增大D. 逐渐减小A. 总体标准差B. 抽样误差C. 置信水平A. 确定总体B. 划分层次C. 确定各层样本量5. 系统抽样中,抽样间隔的计算公式是:A. N/nB. N/(n+1)C. n/ND. (N1)/n二、填空题1. 抽样技术分为两大类:______抽样和______抽样。
2. 在______抽样中,每个个体被抽中的概率是相等的。
3. 抽样误差的大小与样本量成______比,与总体标准差成______比。
4. 在分层抽样中,各层的样本量应与各层的______成比例。
5. 系统抽样的第一步是确定______。
三、简答题1. 简述简单随机抽样的步骤。
2. 何为抽样误差?它受哪些因素影响?3. 简述分层抽样的优点。
4. 系统抽样与简单随机抽样有何区别?5. 如何确定样本量?四、计算题1. 某企业有员工1000人,采用简单随机抽样方法抽取50人进行调查。
计算每个员工被抽中的概率。
2. 某地区居民收入总体标准差为500元,要求抽样误差不超过50元,置信水平为95%。
计算所需样本量。
3. 某学校有学生2000人,分为四个年级,每个年级人数分别为400、450、500和650人。
现采用分层抽样方法抽取200人进行调查,求每个年级应抽取的样本量。
4. 某生产线共有1000个产品,采用系统抽样方法抽取100个产品进行质量检验。
计算抽样间隔。
5. 某企业对员工满意度进行调查,总体标准差为10%,要求抽样误差不超过2%,置信水平为90%。
计算所需样本量。
五、判断题1. 在抽样调查中,总体的大小对于抽样误差没有影响。
()2. 非概率抽样不能提供总体参数的估计。
()3. 在系统抽样中,第一个样本单元可以随机选择。

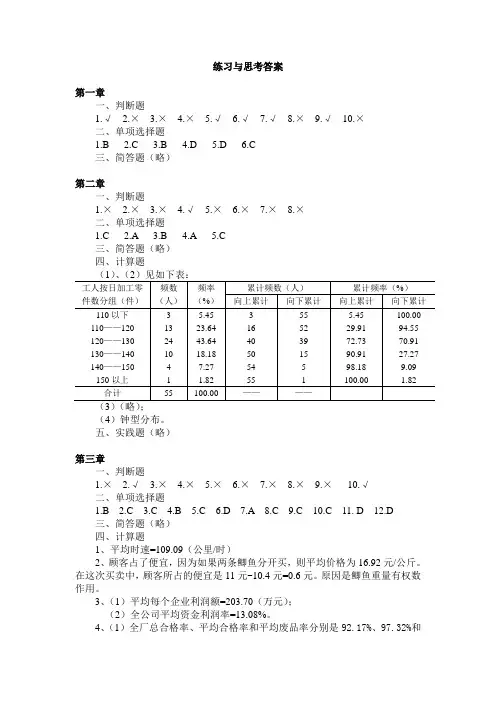
练习与思考答案第一章一、判断题1.√2.×3.×4.×5.√6.√7.√8.×9.√10.×二、单项选择题1.B2.C3.B4.D5.D6.C三、简答题(略)第二章一、判断题1.×2.×3.×4.√5.×6.×7.×8.×二、单项选择题1.C2.A3.B4.A5.C三、简答题(略)四、计算题(4)钟型分布。
五、实践题(略)第三章一、判断题1.×2.√3.×4.×5.×6.×7.×8.×9.×10.√二、单项选择题1.B2.C3.C4.B5.C6.D7.A8.C9.C 10.C 11. D 12.D三、简答题(略)四、计算题1、平均时速=109.09(公里/时)2、顾客占了便宜,因为如果两条鲫鱼分开买,则平均价格为16.92元/公斤。
在这次买卖中,顾客所占的便宜是11元-10.4元=0.6元。
原因是鲫鱼重量有权数作用。
3、(1)平均每个企业利润额=203.70(万元);(2)全公司平均资金利润率=13.08%。
4、(1)全厂总合格率、平均合格率和平均废品率分别是92.17%、97.32%和2.68%;(采用几何平均法)(2)全厂总合格率、平均合格率和平均废品率分别是97.31%、97.31%和2.69%;(采用调和平均法)(3)全厂总合格率、平均合格率和平均废品率分别是97.38%、97.38%和2.62%。
(采用算术平均法)5、(1)算术平均数x =76.3043;四分位数L Q =70.6818,M Q =75.9091和U Q =82.5;众数o m =75.38;(2)全距R=50;平均差 A.D.=7.03;四分位差d Q =11.82,异众比率r V =51.11%;方差2s =89.60;标准差s =9.4659;(3)偏度系数(1)k S =0.0977,(2)k S =0.1154,(3)k S =0.0454; (4)峰度系数β=2.95;(5)12.41%12.5%s s V V ==乙甲;。
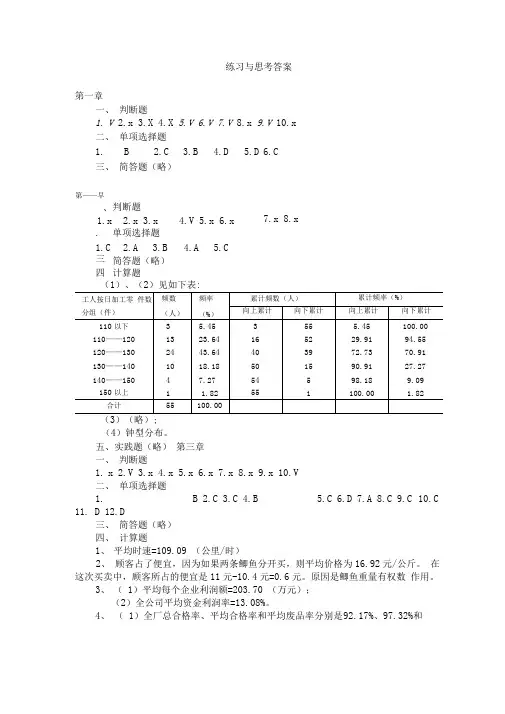
练习与思考答案第一章一、 判断题1. V2.x3.X4.X5.V6.V7.V8.x9.V 10.x 二、 单项选择题1. B2.C3.B4.D5.D6.C三、 简答题(略)(1)、(2)见如下表:(3)(略); (4)钟型分布。
五、实践题(略) 第三章 一、 判断题1. x2.V3.x4.x5.x6.x7.x8.x9.x 10.V二、 单项选择题1.B 2.C 3.C 4.B 5.C 6.D 7.A 8.C 9.C 10.C11. D 12.D三、 简答题(略) 四、 计算题1、 平均时速=109.09 (公里/时)2、 顾客占了便宜,因为如果两条鲫鱼分开买,则平均价格为16.92元/公斤。
在这次买卖中,顾客所占的便宜是11元-10.4元=0.6元。
原因是鲫鱼重量有权数 作用。
3、 ( 1)平均每个企业利润额=203.70 (万元);(2)全公司平均资金利润率=13.08%。
4、 ( 1)全厂总合格率、平均合格率和平均废品率分别是 92.17%、97.32%和第——早、判断题1.x2.x3.x4.V5.x6.x . _____ 单项选择题1.C2.A3.B4.A5.C三、 简答题(略) 四计算题7.x 8.x2.68%;(采用几何平均法)(2)全厂总合格率、平均合格率和平均废品率分别是 97.31%、97.31%和 2.69%;(采用调和平均法)(3)全厂总合格率、平均合格率和平均废品率分别是 97.38%、97.38%和2.62%。
(采用算术平均法)5、( 1)算术平均数 x =76.3043 ;四分位数 Q L =70.6818,Q M =75.9091 和 Q =82.5;众数 m 。
=75.38 ;(2)全距 R=50;平均差 A.D.=7.03 ;四分位差 Q d =11.82,异众比率V r =51.11%;方差 s 2=89.60 ;标准差 s = 9.4659 ;偏度系数 S k 1)=0.0977,S k 2)=0.1154,戏)=0.0454 ;乂甲二12.41%; V 乙 =12.5%。

抽样技术课后习题答案第⼆章习题2.1判断下列抽样⽅法是否是等概的:(1)总体编号1~64,在0~99中产⽣随机数r ,若0或r>64则舍弃重抽。
(2)总体编号1~64,在0~99中产⽣随机数r ,r 处以64的余数作为抽中的数,若余数为0则抽中64.(3)总体20000~21000,从1~1000中产⽣随机数r 。
然后⽤19999作为被抽选的数。
解析:等概抽样属于概率抽样,概率抽样具有⼀些⼏个特点:第⼀,按照⼀定的概率以随机原则抽取样本。
第⼆,每个单元被抽中的概率是已知的,或者是可以计算的。
第三,当⽤样本对总体⽬标进⾏估计时,要考虑到该样本被抽中的概率。
因此(1)中只有1~64是可能被抽中的,故不是等概的。
(2)不是等概的【原因】(3)是等概的。
2.2抽样理论和数理统计中关于样本均值y 的定义和性质有哪些不同?解析:抽样理论和数理统计中关于样本均值的定义和性质的不同抽样理论概率统计定义 ∑==ni i y n y 11∑==ni iy n y 11性质1.期望()()()()Y C P E NN C N C ===∑∑==n n1i n i 1i i i 1y y y2.⽅差()()()[]()iiP y E y y V n N21∑=-==()()[]n NC i iiC y E y n N121∑=- ()21S nf -=1.期望()??=∑=n i i y n E y E 11()∑==ni y E 1i n 1[]µµ==n n12.⽅差()[]2µ-=i y E y V211-=∑=n i i y n E µ()ny n 122i σµ=-=E2.3为了合理调配电⼒资源,某市欲了解50000户居民的⽇⽤电量,从中简单随机抽取了300户进⾏,现得到其⽇⽤电平均值=y 9.5(千⽡时),=2s 206.试估计该市居民⽤电量的95%置信区间。


《抽样技术(第二版)金勇进等编著》习题解答第二章2.22.3 解:已知2ˆ9.5,206,50000,300500009.5475000y s N n Y Ny ====∴==⨯=, 222211300/50000ˆ()50000206500000.6825170636666730041308.19128,80964.05491f v YN s n --∴==⨯⨯=⨯===所以居民日用电量的95%的置信区间为 ˆˆ[[47500080964.05491,47500080964.05491] [394035.9451,555964.0549]YY -+=-+=相对误差为ˆd Y Y r Y-=2.4 解:ˆ0.35Pp == , 11200/1000010000()(1)0.35(10.35)0.0011512009999f N V p P P n N --=-=⨯⨯⨯-=-0.03339=∴P 的95%置信区间为:[[0.35 1.960.03339,0.35 1.960.03339][0.2846,0.4154]p p -+=-⨯+⨯=2.5 解:已知200,20N n ==,根据已知数据计算得:2144.5,826.0526,() 6.096915y s v y ==∴== ∴Y 的95%置信区间为:[[144.5 1.96 6.096915,144.5 1.96 6.096915][132.55,156.45]y y -+=-⨯+⨯=2.6 解:已知2ˆ1120,25600,350,503501120392000y S N n Y Ny ====∴==⨯=,2221150/350ˆ()350256003840000506196.773,12145.68f V YN S n --∴==⨯⨯===∴ˆY的95%置信区间为:ˆˆ[[379854.3,404145.7]Y Y -+= 2.7 解:已知21000,2,68,10.95N d S α===-=,222022221000 1.966861.3010002 1.9668Nt S n Nd t S ⨯⨯∴===+⨯+⨯0161.387.571430.7n n r === 样本量最终为88个家庭。

第一章1.1 答:理论上,若要根据调查数据进行统计推断,则需使用概率抽样。
在实际情形中,对概率抽样与非概率抽样的选择基于对调查目的与调查条件的权衡。
按照L. Kish 的说法,适用概率抽样的场合:(1)“当随机化〖即概率抽样〗既简单又重要时,忽视它就等于轻率和无知”;(2)“只有在某一具体研究领域中由于观察到抽选偏差,发现随机性的假设系错误后〖即随机性假设不成立〗,某些研究人员才显示出对概率抽样发生兴趣……在大多数物理学和化学实验中,样本的选择看来并不需要特别注意,在生物学里,随机与不随机兼而有之。
另一个极端是社会科学,事物特征的分布往往与随机分布相去甚远,也正是在这些领域,概率抽样最为需要,也是最为发展的”;(3)“随机化的概率抽样并不是一个教条而是一种策略,特别是对抽样数目大的场合更是如此”。
〖请再次注意由个人随意写下一些数字的例子〗适用非概率抽样的场合:(1)“比较大的挑战是在很多场合实行随机化的花费很大,这时它的价值必须与它的高费用相权衡,而且常常还要与减少对测量和实验变量的控制相权衡〖指调查方法与试验方法的选择〗。
因此,在很多现场操作中作业人员在下列三种情况下,尽量避免使用概率抽样: 第一,如果元素是一致的,那抽样就不重要了,例如,所有重量为一个单位的氢原子都可以认为是一样的;第二,虽然缺乏一致性,但如果预测的变量是可以度量且能够控制的话,抽样仍然可以避免,例如,在对个人进行抽选时对性别的控制是容易的;第三,如果不能控制的变量在总体中是随机分布的,那么对于任何选样设计,都可以提供一个随机样本。
”(2)“很多卓有成就的科学(天文学、物理学和化学)的巨大进步过去和现在都没有用概率抽样,在这些科学的研究里,统计推断是根据对总体有着适当的、自动的和自然的随机化这一主观判断而作出的……科学研究里充满了根据总体天然随机化的假定而获得成功的例子。
”1.2 答(1)(2)(3)皆否。
理由:判断一抽样是否为概率抽样,乃判断其是否为一给定之(),,S P U ,即:是否有确定之有限总体U ,所有可能样本的集合{}S s =是否确定,每个样本的选取概率{}P p =是否确定。


统计学简答题第一章1.统计的含义与本质是什么?含义:1、统计工作:调查研究。
资料收集、整理和分析。
2、统计资料:工作成果。
包括统计数据和分析报告。
3、统计学:研究如何搜集、整理、分析数据资料的一门方法论科学。
本质:就是关于为何统计,统计什么和如何统计的思想。
2.什么是统计学?有哪些性质?统计学是关于如何收集、整理和分析统计数据的科学。
统计学就其研究对象而言,具有数量性、总体性和差异性的特点;就其学科范畴而言,具有方法型、层次性和通用性的特点;就其研究方式而言,具有描述性和推断性的特点。
3.统计学数据可分为哪几种类型,不同类型数据各有什么特点?(1)按照所采用的计量尺度可分为分类数据、顺序数据和数值型数据。
特点:分类数据说明的是事物的品质特征,用文字表述,结果均表现为类别。
数值型数据说明现象的数量特征,用数值表现。
分类数据:数据表现为类别,各类别之间是平等的并列关系,无法区分优劣或大小,各类别之间的顺序可以任意改变;顺序数据:数据表现为类别,各类别之间可以比较顺序,比分类数据精确;数值型数据:数据表现为具体的数值,可以进行加减乘除运算。
(2)按收集方法可分为观测的数据和实验的数据。
特点:观测数据:数据是在没有对事物进行人为控制的条件下得到的,实验数据:数据是在实验中控制实验对象而收集到的。
(3)按照被描述的对象和时间的关系可分为截面数据和时间序列数据。
,特点:截面数据:描述的是现象在某一时刻的变化情况时间序列数据:描述的是现象随时间而变化的情况。
4.如何正确理解描述统计与推断统计的关系?描述统计和推断统计是统计方法的两个组成部分。
描述统计是整个统计学的基础,推断统计则是现代统计学的主要内容。
描述统计对资料的数量特征及其分布规律进行测定和描述;而统计推断是指通过抽样等方式进行样本估计总体特征的过程,包括参数估计和假设检验两项内容。
推断统计是和假设检验联系在一起的,这只是简单的描述现象,并没有进行假设,再利用数据检验,得出推断的结果。

第一章1.1判断题:(1)对;(2)对;(3)对;(4)对;(5)错;(6)错;(7)错;(8) 错;(9)错;(10)对•;(11)对。
1.2试分析以下几种抽样属于何种抽样(概率或非概率):(1)概率抽样;(2)非概率抽样;(3)非概率抽样;(4)非概率抽样;(5)非概率抽样;(6)非概率抽样。
1.3选择题:(1) c; (2) c; (3) b; (4) co第二章2.1判断题:(1)错;(2)错;(3)对;(4)错;(5)错;(6)错;(7)错;(8) 错;(9)对;(10)对;(11)错;(12)错;(13)错。
2.3选择题:(2)期望为5,方差为4/3(3)抽样标准误=I,= 1.155(4)抽样极限误差= 1.96*1.155 = 2.263(5)置信区间=(5.67-2.263, 5.67+2.263) = (3.407, 7.933)。
若区间两端只考虑抽样分布的可能性取值,则可得该抽样分布作为离散分布的置信区间为[3,7]第三章3.1判断题是否为等概率抽样:(1)是;(2)否;(3)是;(4)否。
3.2p = — == 0.267 n 30 m=g=°°g30-1⑴歹=土£匕=5.5『=§£(匕_区)2=6.2552 =-^—y(K-r)2 =8.33 N-\- 1(2)样本:(2,5) (2,6) (2,9) (5,6) (5,9) (6,9)此=空(3.5 + 4 + 5.5 + 5.5 + 7 + 7.5)= 5.5 8何)=?Z(4.5 + 8 + 24.5 + 0.5 + 84-4.5) = 8.333.3⑴ £叫=1682 Yy,.2 =118266 上£ =上四登= 0.03276 乙’n 30y = 1682/30 = 56.0672 1 -.2 1 fv -2) H8266-30x50.067A2s =—>()',—)') =—7 L H ~ny = ------------------------------ —— ------------ = 826.271 〃一1旨)30-1*时=上匚2 =0.03276x826.271 = 27.07 nse(项)=0(顼)=5.203△ =,x se(项)=1.96 x 5.203 = 10.19895%置信度下置信区间为(56.067-10.198, 56.067+10.198) = (45.869,66.265). 因此,对该校学生某月的人均购书支出额的估计为56.07 (元),由于置信度95% 对应的『= 1.96,所以,可以以95%的把握说该学生该月的人均购书支出额大约在45.87〜66.27元之间。
第二章2.1判断题:(1)错;(2)错;(3)对;(4)错;(5)错;(6)错;(7)错;(8)错;(9)对;(10)对;(11)错;(12)错;(13)错。
2.3选择题:(1)b ;(2)b ;(3)d ;(4)c ;(5)c 。
2.7(1)抽样分布:(2)期望为5,方差为4/3 (3)抽样标准误 = √4/3 = 1.155 (4)抽样极限误差 = 1.96*1.155 = 2.263(5)置信区间 = (5.67-2.263, 5.67+2.263) =(3.407, 7.933)。
若区间两端只考虑抽样分布的可能性取值,则可得该抽样分布作为离散分布的置信区间为[3, 7]第三章3.1 判断题是否为等概率抽样:(1)是;(2)否;(3)是;(4)否。
3.2 (1)5.51==∑i Y NY 25.6)(122=-=∑Y Y Ni σ 33.8)(1122=--=∑Y Y N S i (2)样本:(2, 5) (2, 6) (2, 9) (5, 6) (5, 9) (6, 9)()()5.55.775.55.545.361=+++++=∑y E ()∑=+++++=33.8)5.485.05.2485.4(612s E3.3(1) 1682=∑i y 1182662=∑i y03276.0301750/3011=-=-n f 760.5630/1682==y127.8261302^067.503011826611)(11212212=-⨯-=⎪⎭⎫ ⎝⎛--=--=∑∑==y n y n y y n s n i in i i ()07.27271.82603276.012=⨯=-=s nf y v ()203.5)(==y v y se198.10203.596.1)(=⨯=⨯=∆y se t95%置信度下置信区间为(56.067-10.198, 56.067+10.198)=(45.869, 66.265). 因此,对该校学生某月的人均购书支出额的估计为56.07(元),由于置信度95%对应的96.1=t ,所以,可以以95%的把握说该学生该月的人均购书支出额大约在45.87~66.27元之间。