编译原理(第二版)PL0源代码(C语言版)
- 格式:pdf
- 大小:507.84 KB
- 文档页数:33

/*PL/0编译程序(C语言版)*编译和运行环境:*Visual C++*WinXP/7*利用方式:*运行后输入PL/0源程序文件名*回答是不是将虚拟机代码写入文件*回答是不是将符号表写入文件*执行成功会产生四个文件(词法分析结果.txt符号表.txt虚拟代码.txt源程序和地址.txt)*/#include <>#include""#include"string"#define stacksize 500xt","w");fa1=fopen("源程序和地址.txt","w");xt","w");fas=fopen("符号表.txt","w");addset(nxtlev,declbegsys,statbegsys,symnum);nxtlev[period]=true;if(-1==block(0,0,nxtlev)){n\n");fprintf(cifa,"源程序显现错误,请检查!!!");fprintf(fa1,"源程序显现错误,请检查!!!");fprintf(fa,"源程序显现错误,请检查!!!");fprintf(fas,"源程序显现错误,请检查!!!");}fclose(fa);fclose(fa1);fclose(fas);}fclose(fin);}else{printf("Can't open file!\n");}fclose(cifa);]=period;ssym['#']=neq;ssym[';']=semicolon;strcpy(&(word[0][0]),"begin");\n\n" );fprintf(fa1,"\t\t程序结尾丢了句号“.”\n");break;case 10:printf("\t\t语句之间漏了“;”\n" );fprintf(fa1,"\t\t语句之间漏了“;”\n");break;case 11:printf("\t\t标识符拼写错误或未说明\n" );fprintf(fa1,"\t\t标识符拼写错误或未说明\n");break;case 12:printf("\t\t赋值语句中,赋值号左部标识符属性应是变量\n" );fprintf(fa1,"\t\t赋值语句中,赋值号左部标识符属性应是变量\n");break;case 13:printf("\t\t赋值语句左部标识符后应是复制号“:=”\n" );fprintf(fa1,"\t\t赋值语句左部标识符后应是复制号“:=”\n");break;case 14:printf("\t\tcall后应为标识符\n" );fprintf(fa1,"\t\tcall后应为标识符\n");break;case 15:printf("\t\tcall后标识符属性应为进程\n" );fprintf(fa1,"\t\tcall后标识符属性应为进程\n");break;case 16:printf("\t\t条件语句中丢了then\n" );fprintf(fa1,"\t\t条件语句中丢了then\n");break;case 17:printf("\t\t丢了“end”或“;”\n" );fprintf(fa1,"\t\t丢了“end”或“;”\n");break;case 18:printf("\t\twhile型循环语句中丢了“do”\n" ); fprintf(fa1,"\t\twhile型循环语句中丢了“do”\n");break;case 19:printf("\t\t语句后的符号不正确\n" );fprintf(fa1,"\t\t语句后的符号不正确\n" );break;case 20:printf("\t\t应为关系运算符\n" );fprintf(fa1,"\t\t应为关系运算符\n");break;case 21:printf("\t\t表达式内标示符属性不能是进程\n" ); fprintf(fa1,"\t\t表达式内标示符属性不能是进程\n");break;case 22:printf("\t\t表达式漏掉了右括号\n" );fprintf(fa1,"\t\t表达式漏掉了右括号\n");break;case 23:printf("\t\t因子后的非法符号\n" );fprintf(fa1,"\t\t因子后的非法符号\n");break;case 24:printf("\t\t表达式的开始符不能是此符号\n" );fprintf(fa1,"\t\t表达式的开始符不能是此符号\n");break;case 25:printf("\t\t标识符越界\n" );fprintf(fa1,"\t\t标识符越界\n");break;case 26:printf("\t\t非法字符\n" );fprintf(fa1,"\t\t非法字符\n");break;case 31:printf("\t\t数越界\n");fprintf(fa1,"\t\t数越界\n");break;case 32:printf("\t\tread语句括号中的标识符不是变量\n" );fprintf(fa1,"\t\tread语句括号中的标识符不是变量\n");break;case 33:printf("\t\twrite()或read()中应为完整表达式\n" );fprintf(fa1,"\t\twrite()或read()中应为完整表达式\n");break;default:printf("\t\t显现未知错误\n" );fprintf(fa1,"\t\t显现未知错误\n");}err++;}:break;default :error(26);}if(sym!=period){t\tperiod\n");}}}}}}return 0;}=x;code[cx].l=y;code[cx].a=z;cx++;return 0;}dr=cx;gendo(jmp,0,0);if(lev>levmax){dr].a=cx;dr=cx;ize=dx;cx0=cx;gendo(inte,0,dx);ind){case constant:fprintf(fas,"%d const %s ",i,table[i].name);fprintf(fas,"val=%d\n",table[i].val);break;case variable:fprintf(fas,"%d var %s ",i,table[i].name);fprintf(fas,"lev=%daddr=%d\n",table[i].level,table[i].adr);break;case procedur:fprintf(fas,"%d proc %s ",i,table[i].name);fprintf(fas,"lev=%daddr=%dsize=%d\n", table[i].level,table[i].adr,table[i].size);break;}}}memcpy(nxtlev,fsys,sizeof(bool)*symnum);ame,id);table[(* ptx)].kind=k;switch(k){case constant:if(num>amax){error(31);num=0;}table[(*ptx)].val=num;break;case variable:table[(*ptx)].level=lev;table[(*ptx)].adr=(*pdx);(*pdx)++;break;case procedur:table[(*ptx)].level=lev;break;}}ame,idt);i=tx;ame,idt)!=0){i--;}return i;}],code[i].l,code[i],a);}}}ind!=variable){error(12);i=0;}else{getsymdo;if(sym==becomes){getsymdo;printf("该语句为赋值语句。


编译原理第二版课后习答案编译原理是计算机科学领域中的一门重要学科,它主要研究程序的自动翻译技术,将高级语言编写的程序转换为机器能够执行的低级语言。
编译原理的基本概念和技术是计算机专业学生必须学会的知识之一,而编译原理第二版课后习题则是帮助学生更好地理解课程内容和提高编译器开发能力的重要资源。
本篇文章将对编译原理第二版课后习题进行分析和总结,并提供一些参考答案和解决问题的思路。
一、词法分析词法分析是编译器的第一步,它主要将输入的字符流转换为有意义的词法单元,例如关键字、标识符、常量和运算符等。
在词法分析过程中,我们需要编写一个词法分析程序来处理输入的字符流。
以下是几道词法分析相关的习题:1. 如何使用正则表达式来表示浮点数?答案:[+|-]?(\d+\.\d+|\d+\.|\.\d+)([e|E][+|-]?\d+)?这个正则表达式可以匹配所有的浮点数,包括正负小数、整数和指数形式的浮点数。
2. 什么是语素?举例说明。
答案:语素是构成单词的最小承载语义的单位,例如单词“man”,它由两个语素“ma”和“n”组成。
“ma”表示男性,“n”表示名词。
3. 采用有限状态自动机(Finite State Automata)实现词法分析的优点是什么?答案:采用有限状态自动机(Finite State Automata)实现词法分析的优点是运行速度快,消耗内存小,易于编写和调试,具有可读性。
二、语法分析语法分析是编译器的第二步,它主要检查词法分析生成的词法单元是否符合语法规则。
在语法分析过程中,我们需要编写一个语法分析器来处理词法单元序列。
以下是几道语法分析相关的习题:1. 什么是上下文无关文法?答案:上下文无关文法(Context-Free Grammar, CFG)是一种形式语言,它的语法规则不依赖于上下文,只考虑规则左边的非终结符号。
EBNF是一种常见的上下文无关文法。
2. LR分析表有什么作用?答案:LR分析表是一种自动机,它的作用是给定一个输入符号串,判断其是否符合某个文法规则,并生成语法树。

编译原理第二版答案
编译原理是计算机科学中非常重要的一个领域,它涉及到编程语言的设计、编
译器的构建以及程序的执行过程。
《编译原理(第二版)》是一本经典的教材,它系统地介绍了编译原理的基本概念、理论和实践,对于理解编译原理具有重要的指导意义。
在学习这本教材的过程中,很多同学都会遇到一些问题,尤其是对于习题的答案。
本文将对《编译原理(第二版)》中的习题答案进行详细解析,希望能够帮助大家更好地理解和掌握编译原理的知识。
1. 介绍编译原理的基本概念和原理,包括词法分析、语法分析、语义分析、中
间代码生成、代码优化和目标代码生成等内容。
2. 解析《编译原理(第二版)》中的习题答案,包括对于词法分析、语法分析、语义分析等各个方面的习题进行逐一分析和解答。
3. 提供一些编译原理相关的案例分析,帮助读者更好地理解编译原理的理论和
实践。
4. 总结编译原理学习中的常见问题和解决方法,为读者提供一些学习建议和学
习技巧。
5. 展望编译原理的未来发展方向,介绍一些最新的研究成果和应用领域,为读
者打开编译原理的新视野。
通过本文的阅读,读者将能够全面了解《编译原理(第二版)》中的习题答案,深入理解编译原理的基本概念和原理,掌握编译原理的核心知识和技术,为今后的学习和工作打下坚实的基础。
希望本文能够对大家的学习和研究有所帮助,欢迎大家阅读和参考。

一、题目:简单PL0编译程序及其扩展表示多行表达式的<表达式序列>文法如下:<表达式序列>-> <表达式> ↙<表达式序列> |<表达式>↙↙<表达式> -> [<变量>=] [+|-]<项>{(+|-)<项>}<项> -> <因子>{(* | /)<因子>}<因子> -> <无符号实数>|<变量>|<标准函数>‘(’<表达式>‘)’|‘(’ <表达式>‘)’<标准函数> -> sin | cos | tan | exp其中的变量无需定义且其作用域为第一次赋值处至最后。
递归下降方式设计其编译程序,生成PL/0栈式指令代码,然后解释执行。
二、编译技术,主要数据结构及算法Class:MyPL0int getch();void error(int n);int gen(string function,int lev,string a);int factor();int term();int expression();void listcode();void interpret();void GetFile();void start();void Check(int i);void run(string str);Class:Code主要数据结构:数组,栈,链表三、测试本程序的测试源程序在test.txt中:a=1+2*3-4/(2*3) //检测是否实现基本文法b=sin2+cos6+tan10 //检测是否扩展标准函数(本组没能实现exp)c=9*(3+ //检测出错纠察—缺少右括号d=x+3 //检测变量无定义e=48*+33 //检测表达式非法用于测试的源代码用户也可以自己定义四、遗留问题及思考没有解决exp的识别和计算,有待考究追加通过对书后标准程序的改造和学习,本小组加深了PL0编译程序的执行过程,了解到栈式目标代码的具体生成过程,。

pl0编译原理编译原理是计算机科学中的一门重要课程,它研究的是如何将高级语言转化为机器语言的过程。
在编译原理中,pl0是一种简单的编程语言,它的设计目标是为了教学和研究目的而产生的。
本文将介绍pl0编译原理的基本概念和主要过程。
一、pl0编译原理的基本概念1.1 什么是pl0编程语言pl0是一种结构化的过程性编程语言,它的语法规则简单明了,易于学习和理解。
pl0支持基本的数据类型和控制结构,包括整型、实型、布尔型等。
1.2 pl0编译器的作用pl0编译器的主要作用是将pl0源代码转化为目标代码,使计算机能够理解和执行这些代码。
编译器的工作包括词法分析、语法分析、语义分析、中间代码生成和目标代码生成等。
1.3 pl0编译过程的主要阶段pl0编译过程主要包括词法分析、语法分析、语义分析和代码生成等阶段。
在词法分析阶段,编译器将源代码分解成一个个的词法单元;在语法分析阶段,编译器将词法单元按照语法规则组织成一个抽象语法树;在语义分析阶段,编译器对抽象语法树进行语义检查和类型推导;最后,在代码生成阶段,编译器将抽象语法树转化为目标代码。
二、pl0编译原理的主要过程2.1 词法分析词法分析是编译过程的第一步,它将源代码分解成一个个的词法单元。
在pl0编译器中,常见的词法单元包括关键字、标识符、常量、运算符和界符等。
编译器通过正则表达式和有限自动机等技术来实现词法分析。
2.2 语法分析语法分析是编译过程的第二步,它将词法单元按照语法规则组织成一个抽象语法树。
在pl0编译器中,常见的语法规则包括表达式、语句、函数和过程等。
编译器通过上下文无关文法和递归下降等技术来实现语法分析。
2.3 语义分析语义分析是编译过程的第三步,它对抽象语法树进行语义检查和类型推导。
在pl0编译器中,常见的语义检查包括变量声明检查、类型匹配检查和作用域检查等。
编译器通过符号表和类型推导等技术来实现语义分析。
2.4 代码生成代码生成是编译过程的最后一步,它将抽象语法树转化为目标代码。

第1 章引论第1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。


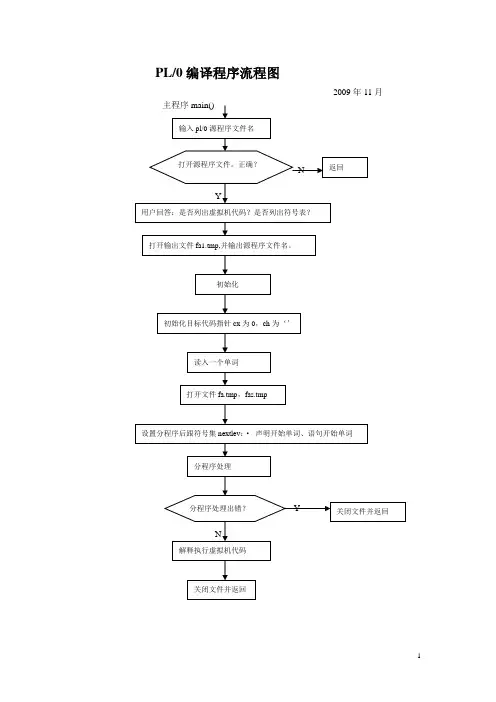
编译原理实验报告******************************************************************************* ******************************************************************************* PL0语言功能简单、结构清晰、可读性强,而又具备了一般高级程序设计语言的必须部分,因而PL0语言的编译程序能充分体现一个高级语言编译程序实现的基本方法和技术。
PL/0语言文法的EBNF表示如下:<程序>::=<分程序>.<分程序> ::=[<常量说明>][<变量说明>][<过程说明>]<语句><常量说明> ::=CONST<常量定义>{,<常量定义>};<常量定义> ::=<标识符>=<无符号整数><无符号整数> ::= <数字>{<数字>}<变量说明> ::=V AR <标识符>{, <标识符>};<标识符> ::=<字母>{<字母>|<数字>}<过程说明> ::=<过程首部><分程序>{; <过程说明> };<过程首部> ::=PROCEDURE <标识符>;<语句> ::=<赋值语句>|<条件语句>|<当循环语句>|<过程调用语句>|<复合语句>|<读语句><写语句>|<空><赋值语句> ::=<标识符>:=<表达式><复合语句> ::=BEGIN <语句> {;<语句> }END<条件语句> ::= <表达式> <关系运算符> <表达式> |ODD<表达式><表达式> ::= [+|-]<项>{<加法运算符> <项>}<项> ::= <因子>{<乘法运算符> <因子>}<因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’<加法运算符> ::= +|-<乘法运算符> ::= *|/<关系运算符> ::= =|#|<|<=|>|>=<条件语句> ::= IF <条件> THEN <语句><过程调用语句> ::= CALL 标识符<当循环语句> ::= WHILE <条件> DO <语句><读语句> ::= READ‘(’<标识符>{,<标识符>}‘)’<写语句> ::= WRITE‘(’<表达式>{,<表达式>}‘)’<字母> ::= a|b|…|X|Y|Z<数字> ::= 0|1|…|8|9【预处理】对于一个pl0文法首先应该进行一定的预处理,提取左公因式,消除左递归(直接或间接),接着就可以根据所得的文法进行编写代码。

《编译原理》课程实验报告题目PL/0编译程序的C语言扩充专业化学工程与工艺班级学号姓名任课教师华东理工大学信息学院一.实验题目PL/0编译程序的C语言扩充二.实验目的在分析理解PL/0编译程序的基础上,对其词法分析程序、语法分析程序和语义处理程序进行部分修改扩充。
三.实验内容在PL/0语言的基础上增加对整型一维数组的支持、扩充IF-THEN-ELSE条件语句、增加REPEAT 语句、支持带参数的过程和增加注释等,如下所示:(1)整型一维数组,数组的定义格式为:VAR<数组标识名>(<下界>:<上界>)其中上界和下界可以是整数或者常量标识名。
访问数组元素的时候,数组下表是整型的表达式,包括整数、常量或者变量和他们的组合。
(2)扩充条件语句,格式为:<条件语句> ::= EF<条件>THEN<语句> [ELSE<语句>](3)增加REPEAT语句,格式为:<复合语句> ::= REPEAT<语句>UNTL<条件>四.实验过程(1)PL/0编译程序的C语言源代码输入(2)运行PL/0编译程序的C语言源代码,调试运行PL/0编译程序(3)对PL/0编译程序进行功能扩充(4)PL/0编译程序功能扩充部分的分析与设计(5)对PL/0编译程序进行功能扩充,即编写代码(6)进行PL/0编译程序功能扩充部分的运行调试(7)完成实验报告总结五.PL/0编译程序的功能扩充程序说明(1)扩充赋值运算:+=,-=.此功能扩充只需在语句分析里面进行增加如下程序:if(SYM==BECOMES||SYM==PLUSBECOMES||SYM==MINUSBECOMES){if (SYM==BECOMES){GetSym();EXPRESSION(FSYS,LEV,TX);}elseif(SYM==PLUSBECOMES||SYM==MINUSBECOMES){GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);if(SYM==PLUSBECOMES){GetSym();FACTOR(FSYS,LEV,TX);GEN(OPR,0,2);}elseif(SYM==MINUSBECOMES){GetSym();FACTOR(FSYS,LEV,TX);GEN(OPR,0,3);}}if (i!=0)GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);}(2)扩充FOR TO和FOR DOWNTO语句,此功能的关键是如何判断条件是否成立,并如何进行程序跳转.在这里用到了几条指令,和地址回填技术.扩充程序如下:case FORSYM:GetSym();if(SYM!=IDENT)Error(31); //FOR后面要标识符i=POSITION(ID,TX);if (i==0) Error(11);elseif (TABLE[i].KIND!=VARIABLE) { /*ASSIGNMENT TO NON-VARIABLE*/Error(12); //变量}GetSym();if(SYM!=BECOMES)Error(13);GetSym();EXPRESSION(SymSetUnion(SymSetNew(TOSYM,DOWNTOSYM,DOSYM),FSYS),LEV,TX);//表达式if(SYM==DOWNTOSYM)CX1=CX;GetSym();GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);//保存结果至变量单元GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);//重新调入栈顶EXPRESSION(SymSetAdd(DOSYM,FSYS),LEV,TX);//表达式GEN(OPR,0,11);//判断运算CX2=CX;GEN(JPC,0,0);//如果栈顶非真跳转GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);///重新调入栈顶GEN(LIT,0,1) ;//送1到栈顶GEN(OPR,0,3); //减运算if(SYM==DOSYM){GetSym();STATEMENT(FSYS,LEV,TX);}GEN(JMP,0,CX1);CODE[CX2].A=CX;}else if(SYM==TOSYM){CX1=CX;GetSym();GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); //保存结果至变量单元GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); /重新调入栈顶EXPRESSION(SymSetAdd(DOSYM,FSYS),LEV,TX);//表达式分析GEN(OPR,0,13);//判断运算CX2=CX;GEN(JPC,0,0);//如果栈顶非真跳转GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);GEN(LIT,0,1);GEN(OPR,0,2);if(SYM==DOSYM){GetSym();STATEMENT(FSYS,LEV,TX);}GEN(JMP,0,CX1);CODE[CX2].A=CX;//回填地址}else Error(35);break;(3) 增加条件语句的ELSE子ELSE语句的语法语义分析程序:case IFSYM:GetSym();CONDITION(SymSetUnion(SymSetNew(THENSYM,DOSYM),FSYS),LEV,TX);if (SYM==THENSYM) GetSym();else Error(16);CX1=CX; GEN(JPC,0,0);STATEMENT(FSYS,LEV,TX);CX2=CX; GEN(JMP,0,CX+1);CODE[CX1].A=CX;if (SYM==SEMICOLON) GetSym();if(SYM==ELSESYM){GetSym();STATEMENT(FSYS,LEV,TX);CODE[CX2].A=CX;} //add the statement of ELSEelse STATEMENT(FSYS,LEV,TX);break;(4)修改单词:不等号# 改为 <>if (CH=='<'){GetCh();if (CH=='=') { SYM=LEQ; GetCh(); }elseif(CH=='>') { SYM=NEQ; GetCh(); }else SYM=LSS;六.实验设计思想1.设计说明PL/0语言是Pascal语言的一个子集,这里分析的PL/0的编译程序包括了对PL/0语言源程序进行分析处理、编译生成类PCODE代码,并在虚拟机上解释运行生成的类PCODE代码的功能。
《编译原理》实验报告———编写编译程序实现多行表达式的<表达式序列>的文法语言的编译执行组长:组员:一、实验项目名称:有表示多行表达式的<表达式序列>文法如下:<表达式序列>-> <表达式> ↙<表达式序列> |<表达式>↙↙<表达式> -> [<变量>=] [+|-]<项>{(+|-)<项>}<项> -> <因子>{(* | /)<因子>}<因子> -> <无符号实数>|<变量>|<标准函数>…(‟<表达式>…)‟|…(‟ <表达式>…)‟<标准函数> -> sin | cos | tan | exp其中的变量无需定义且其作用域为第一次赋值处至最后。
试按递归下降方式设计其编译程序,生成PL/0栈式指令代码,然后解释执行。
二、实验要求:·将编译和解释执行分成完全独立的两个阶段;·对栈式指令进行适当扩充,使之能处理标准函数的调用;·剔除本题目不需要的PL/0栈式指令,并说明理由;·简化PL/0运行栈,使之满足本题目要求既可;·注意<表达式>定义中的可选项[变量=]引起的歧义性:如a=1+2与a+2,前一个a属于<表达式>,而后一个a属于<项>,思考如何解决;·以“表达式↙目标码序列↙结果↙”方式输出运行结果;·设计一个测试,使之能充分测试你的实现;·对正确列出的目标码、执行并按适当方式演示运行栈的变化,计算出值;对错误的指出其出错位置和错误性质三、设计概述:·实现平台:VC++6.0·运行平台:xindows xp四、结构设计说明:结构图:五、具体实现过程:1、词法分析(斯琴)词法分析子程序名为getsym,功能是从源程序中读出一个单词符号,把它的信息放入全局变量sym,值放入id中,语法分析需要单词时,直接从变量中获得。
编译原理课程设计学院计算机学院专业计算机科学与技术班级学号姓名指导教师20 年月日一、课程设计要求基本内容(成绩范围:“中”、“及格”或“不及格”)(1)扩充赋值运算:*= 和/=扩充语句(Pascal的FOR语句):①FOR <变量>:=<表达式> TO <表达式> DO <语句>②FOR <变量>:=<表达式> DOWNTO <表达式> DO <语句>其中,语句①的循环变量的步长为2,语句②的循环变量的步长为-2。
(3)增加运算:++ 和--。
选做内容(成绩评定范围扩大到:“优”和“良”)(1)增加类型:①字符类型;②实数类型。
(2)扩充函数:①有返回值和返回语句;②有参数函数。
(3)增加一维数组类型(可增加指令)。
(4)其他典型语言设施。
二、概述目标:实现PL0某些特定语句实现语言:C语言实现工具平台:VS201运行平台:WIN7三、结构设计说明与功能块描述PL/0编译程序的结构图PL/0编译程序的总体流程图四、主要成分描述1、符号表编译程序里用了一个枚举类型enum symbol,然后定义了enum symbol sym来存放当前的符号,前面讲过,主程序定义了一个以字符为元素的一维数组word,称保留字表,这个保留字表也存放在符号表里,为了识别当前的符号是属于哪些保留字;还有标识符,拼数,拼符合词等的符号名都存放在符号表里,当sym存放当前的符号时,我们可以判断它是属于哪类的符号,然后加以处理。
在运行的过程中,主程序中又定义了一个名字表,也就是符号表,来专门存放变量、常量和过程名的各个属性,里面的属性包括name,kind,val/level,adr,size,我们来举一个PL/0语言过程说明部分的片段:Const a=35,b=49;Var c,d,e;Procedure p;Var g;当遇到标识符的引用时就调用position函数,根据当前sym的符号类型来查table表,看是否有过正确的定义,若已有,则从表中取相应的有关信息,供代码的生成用。
实验一PL0编译程序编译原理上机实验一1.软件准备(1)、pl/0编译程序:pl0 .exe(2)、pl/0编译程序源代码程序(PASCAL程序):pl0.pas(或pl0pl0.pas)(3)、pl/0程序实例(文本文件):text.pl0, text1.pl0, test2.pl0, … text9.pl0共10个例子2.实验要求:(1)阅读pl/0源程序实例(text.pl0,test1.pl0,………text9.pl0共10个例子)理解每个PL0程序的功能;熟悉并掌握pl/0语言相关规则。
(2)用pl/0编译程序,对提供的10个例子逐一进行编译并运行。
熟悉pl/0编译程序使用操作方法。
通过理解每个实例程序的功能,编程思想,进一步理解PL/0语言的语法及其语义;提高阅读程序的能力,应用程序设计语言的编程能力;增强程序语言语法、语义意识。
(3)用pl/0语言编写以下程序,进一步熟悉PL/0语言:a、由三角形的三条边长计算三角形面积。
b、编写一个PL0过程,计算以a为直径的圆的面积。
用主程序确定圆的直径,输出计算结果。
c、编写递归程序,计算n!。
d、计算1000之内的所有素数,并输出结果。
求出1000之内所有素数之和。
(要求编写3个以上的pl/0过程实现)3.文件(软件)使用说明(1)、打开文件目录“PL0编译…”,运行PL/0编译程序(pl0.exe),按提示要求输入PL0源程序文件名(如test1.pl0),┉(2)、打开Fa2.txt文件,可看到当前经过编译并运行后的pl/0程序的目标代码及其执行结果。
(3)、打开out1.txt或out2.txt、┉或out9.txt文件,可看到各个pl/0程序实例的编译、运行、操作过程结果。
4.提交实验报告及要求(1)、简述test4.pl0 …test7.pl0各程序语法含义,执行结果。
(2)、提交实验要求编写的4个PL/0源程序及其执行结果。
(3)、简写本次实验的收获与体会。
课程: 编译原理理解PL/0编译程序原理实验报告系专业班级姓名学号指导教师1.实验目的1. 学习使用教学辅助软件THPL0CAI2. 掌握PL/0源程序的编译和解释过程2.实验平台Windows + THPL0CAI3.实验内容目录:pl0演示1.运行THPL0CAI 程序1) 选择0 - Static Link 方式进入2) 选择Open/Create a source file 打开一个PL/0源程序, 如Test2.pl0 const a=10;var b,c;procedure p;var k;beginc:=b+10;end;beginread(b);while b#0 dobegincall p;write(2*c);read(b)endend.2.按F9键开始单步编译Test2.pl0 程序1) 观察符号表的构造过程Table.dat 窗口2) 观察目标代码的构造过程Code.dat 窗口3. 按F9键开始单步执行编译Test2.pl0 生成的代码1) 观察运行栈的变化过程Stack.dat 窗口2) 观察数据的输入输出Result.dat 窗口4.实验报告给出编译过程中符号表的建立过程,1.选定编译内容test22.按空格键进行编译3.得出的符号表table.dat给出运行过程中运行栈的变化过程,只给出部分说明即可。
1.F9开始运行栈2.输入2,给变量赋值3.输入3,给变量赋值,得出结果4.输入0,结束运行栈5.思考题1) 理解编译和解释的含义,目标代码是按何种方式执行的?PL/0编译程序所产生的目标代码是一个假想栈式计算机的汇编语言,可称为类PCODE指令代码,它不依赖任何具体计算机,其指令集极为简单,指令格式也很单纯,其格式如下:f l a其中f代表功能码,l表示层次差,也就是变量或过程被引用的分程序与说明该变量或过程的分程序之间的层次差。
a的含意对不同的指令有所区别,对存取指令表示位移量,而对其它的指令则分别有不同的含义,见下面对每条指令的解释说明。