hae 常用正则
- 格式:docx
- 大小:36.43 KB
- 文档页数:1

python 正则表达式规则正则表达式是一种强大的文本匹配工具,可以用于搜索、替换和验证字符串。
在Python中,可以使用re模块来操作正则表达式。
本文将详细介绍正则表达式的各种规则及其用法。
一、元字符在正则表达式中,元字符是具有特殊含义的字符。
常用的元字符包括:. * + ? ^ $ \ | ( ) [ ] { }。
1.点号(.):匹配任意字符,除了换行符。
2.星号(*):匹配前一个字符0次或多次。
3.加号(+):匹配前一个字符1次或多次。
4.问号(?):匹配前一个字符0次或1次。
5.脱字符(^):匹配字符串的开头。
6.美元符号($):匹配字符串的结尾。
7.反斜杠(\):用于转义特殊字符。
8.竖线(|):用于表示“或”关系。
9.圆括号(()):用于分组。
10.方括号([]):用于指定字符集合。
11.花括号({}):用于指定数量。
二、常用模式1.匹配数字:\d可以匹配一个数字。
2.匹配字母:\w可以匹配一个字母或数字。
3.匹配空白字符:\s可以匹配一个空格、制表符、换行符等。
4.匹配任意字符:.可以匹配除换行符外的任意字符。
5.匹配多个字符:使用[]指定字符集合,如[A-Za-z0-9]可以匹配一个字母或数字。
6.匹配重复字符:使用*、+或{}指定重复次数,如\d{3}可以匹配3个数字。
7.匹配起始和结尾:使用^和$指定起始和结尾,如^\d表示以数字开头。
三、常用函数在re模块中,常用的函数包括:match、search、findall、finditer、sub和split。
1.match函数:从字符串的开头匹配模式,如果匹配成功返回一个匹配对象,否则返回None。
2.search函数:在字符串中搜索匹配模式,如果匹配成功返回一个匹配对象,否则返回None。
3.findall函数:返回所有匹配的结果,以列表形式返回。
4.finditer函数:返回所有匹配的结果,以迭代器形式返回。
5.sub函数:替换匹配的字符串。

python正则表达式举例正则表达式是一种强大的文本匹配工具,可以用于在字符串中查找特定模式的文本。
在Python中,我们可以使用re模块来实现正则表达式的匹配操作。
下面是一些常见的正则表达式的用法举例:1. 匹配数字:可以使用\d来匹配一个数字。
例如,使用正则表达式\d+可以匹配一个或多个数字。
pythonimport res = "apple 123 orange 456"pattern = r"\d+"result = re.findall(pattern, s)print(result) # 输出['123', '456']2. 匹配单词:可以使用\w来匹配一个单词字符(包括字母、数字和下划线)。
例如,使用正则表达式\w+可以匹配一个或多个单词。
pythonimport res = "I have 2 cats and 3 dogs."pattern = r"\w+"result = re.findall(pattern, s)print(result) # 输出['I', 'have', '2', 'cats', 'and', '3', 'dogs']3. 匹配邮箱:可以使用\w+@\w+\.\w+来匹配一个邮箱地址。
pythonimport res = "My email address is abc123@yahoo."pattern = r"\w+@\w+\.\w+"result = re.findall(pattern, s)print(result) # 输出['abc123@yahoo']4. 匹配电话号码:可以使用\d{3}-\d{4}-\d{4}来匹配一个电话号码。

yyyymmdd hhmmss 的正则表达式-回复如何使用正则表达式来匹配"yyyymmdd hhmmss"格式的字符串。
一、介绍正则表达式是一种强大的模式匹配工具,它可以在文本中搜索、替换和提取数据。
使用正则表达式可以快速有效地处理各种模式的字符串。
本文将详细介绍如何使用正则表达式来匹配"yyyymmdd hhmmss"格式的字符串。
二、基本规则在使用正则表达式匹配目标字符串之前,我们需要了解一些正则表达式的基本规则:1. 字符匹配:“.”表示匹配任意单个字符。
2. 重复匹配:“*”表示匹配前一个字符的零个或多个重复;“+”表示匹配前一个字符的一个或多个重复;“?”表示匹配前一个字符的零个或一个重复。
3. 字符集合:“[...]”表示匹配方括号中的任意一个字符。
4. 范围匹配:“[a-z]”表示匹配任意一个小写字母;“[0-9]”表示匹配任意一个数字。
5. 逻辑匹配:“”表示逻辑或,匹配符号前面或后面的任意一个表达式。
6. 强制匹配位置:“^”表示匹配行首;“”表示匹配行尾。
三、正则表达式根据上述基本规则,我们可以构建一个正则表达式来匹配"yyyymmdd hhmmss"格式的字符串:\[2\d{3}(0[1-9] 1[0-2])([0-2]\d 3[0-1]) ([01]\d 2[0-3])([0-5]\d){2}\]四、解析让我们一步一步解析这个正则表达式,以便更好地理解它的含义:1. \[2\d{3}:以2开头的四位数字表示年份,如2000-2999。
2. (0[1-9] 1[0-2]):表示月份,可以是01-09或10-12。
3. ([0-2]\d 3[0-1]):表示日期,可以是01-09、10-29、30或31。
4. ([01]\d 2[0-3]):表示小时,可以是00-09、10-19、20-23。
5. ([0-5]\d){2}:表示分和秒,可以是00-59的两位数字。

正则表达式(Regular Expression)是一种用于匹配字符串的强大工具。
它通过使用特定的符号和字符来描述和匹配一系列字符串,能够满足我们在处理文本时的各种需求。
在这篇文章中,我们将深入探讨20个常用的单字母正则表达式,并通过实例来展示它们的使用方法。
1. \b在正则表达式中,\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
2. \d\d表示任意一个数字字符。
它可以用来匹配任何数字,例如\d+可以匹配一个或多个数字字符。
3. \w\w表示任意一个字母、数字或下划线字符。
它可以用来匹配单词字符,例如\w+可以匹配一个或多个单词字符。
4. \s\s表示任意一个空白字符,包括空格、制表符、换行符等。
它可以用来匹配空白字符,例如\s+可以匹配一个或多个空白字符。
5. \.\.表示匹配任意一个字符,包括标点符号和空格等。
它可以用来匹配任意字符,例如\.可以匹配任意一个字符。
6. \A\A表示匹配字符串的开始。
它可以用来确保匹配发生在字符串的开头。
7. \Z\Z表示匹配字符串的结束。
它可以用来确保匹配发生在字符串的结尾。
8. \b\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
9. \D\D表示任意一个非数字字符。
它可以用来匹配任何非数字字符。
10. \W\W表示任意一个非单词字符。
它可以用来匹配任何非单词字符。
11. \S\S表示任意一个非空白字符。
它可以用来匹配任何非空白字符。
12. \[\[表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
13. \]\]表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
14. \(\(表示匹配左括号。
它可以用来匹配包含在左括号内的字符。
15. \)\)表示匹配右括号。
它可以用来匹配包含在右括号内的字符。
16. \{\{表示匹配左花括号。
它可以用来匹配包含在左花括号内的字符。
17. \}\}表示匹配右花括号。

最常用的十七种正则表达式表达式基础一个正则表达式就是由普通字符(例如字符a 到z)以及特殊字符(称为元字符)组成的文字模式。
该模式描述在查找文字主体时待匹配的一个或多个字符串。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
如:下表是元字符及其在正则表达式上下文中的行为的一个完整列表:下面看几个例子:"^The":表示所有以"The"开始的字符串("There","The cat"等);"of despair$":表示所以以"of despair"结尾的字符串;"^abc$":表示开始和结尾都是"abc"的字符串——呵呵,只有"abc"自己了;"notice":表示任何包含"notice"的字符串。
'*','+'和'?'这三个符号,表示一个或一序列字符重复出现的次数。
它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。
下面是几个例子:"ab*":表示一个字符串有一个a后面跟着零个或若干个b。
("a", "ab", "abbb",……);"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多;"ab?":表示一个字符串有一个a后面跟着零个或者一个b;"a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。
也可以使用范围,用大括号括起,用以表示重复次数的范围。
"ab{2}":表示一个字符串有一个a跟着2个b("abb");"ab{2,}":表示一个字符串有一个a跟着至少2个b;"ab{3,5}":表示一个字符串有一个a跟着3到5个b。
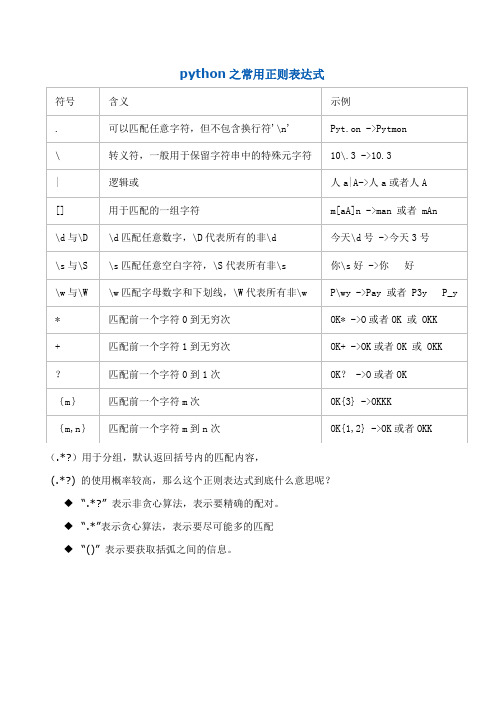
python之常用正则表达式(.*?)用于分组,默认返回括号内的匹配内容,(.*?) 的使用概率较高,那么这个正则表达式到底什么意思呢?◆“.*?” 表示非贪心算法,表示要精确的配对。
◆“.*”表示贪心算法,表示要尽可能多的匹配◆“()” 表示要获取括弧之间的信息。
基于正则表达式完成字符串的查询,替换和分割操作,这些操作都需要导入re模块,并使用如下几个函数。
1.匹配查询函数findall(pattern, string, flags=0)findall 函数可以对指定的字符串进行遍历匹配,获取字符串中所有匹配的子串,并返回一个列表结果。
该函数的参数含义如下:pattern:指定需要匹配的正则表达式。
string:指定待处理的字符flags:指定匹配模式,常用的值可以是re.I、re.M、re.S和re.X。
1)re.I的模式是让正则表达式对大小写不敏感;2)re.M的模式是让正则表达式可以多行匹配;3)re.S的模式指明正则符号.可以匹配任意字符,包括换行符\n;4)re.X模式允许正则表达式写得更详细,如多行表示、忽略空白字符、加入注释等。
2.匹配替换函数sub(pattern, repl, string, count=0, flags=0)sub函数的功能是替换,类似于字符串的replace方法,该函数根据正则表达式把满足匹配的内容替换为repl。
该函数的参数含义如下:1)pattern:同findall函数中的pattern。
2)repl:指定替换成的新值。
3)string:同findall函数中的string。
4)count:用于指定最多替换的次数,默认为全部替换。
5)flags:同findall函数中的flags。
3.匹配分割函数split(pattern, string, maxsplit=0, flags=0)split函数是将字符串按照指定的正则表达式分隔开,类似于字符串的split方法。
python正则的用法Python正则表达式是一种强大的工具,用于匹配、查找和替换字符串中的模式。
它可以帮助我们在文本处理和数据挖掘中快速、准确地找到我们想要的信息。
下面是一些常用的Python正则表达式的用法:1. re.match(pattern, string):尝试从字符串的起始位置匹配模式,如果匹配成功,则返回一个匹配对象;如果匹配失败,则返回None。
2. re.search(pattern, string):在字符串中搜索匹配模式的位置,如果匹配成功,则返回一个匹配对象;如果匹配失败,则返回None。
3. re.findall(pattern, string):在字符串中找到所有匹配模式的子串,并返回一个包含所有匹配对象的列表。
4. re.split(pattern, string):将字符串按照匹配模式进行分割,并返回一个包含分割后的子串的列表。
5. re.sub(pattern, repl, string):在字符串中找到匹配模式的子串,并使用repl替换它们。
正则表达式中的一些常用的元字符和符号:1. ():用于定义一个子组,可以使用\1、\2等引用它们。
2. []:表示一个字符集合,匹配其中的任意一个字符。
例如,[abc]匹配'a'、'b'或'c'。
3. \:用于转义特殊字符。
例如,\.表示匹配点号字符。
4. ^:匹配字符串的起始位置。
5. $:匹配字符串的结束位置。
6. *:表示前一个字符可以出现0次或多次。
例如,a*b可以匹配'b'、'ab'、'aab'等。
7. +:表示前一个字符可以出现1次或多次。
例如,a+b可以匹配'ab'、'aab'、'aaab'等。
8. ?:表示前一个字符可以出现0次或1次。
例如,a?b可以匹配'b'和'ab'。
burp hae 正则正则(也称为正则表达式)是一种用于模式匹配和处理字符串的工具。
它由一系列字符和特殊符号组成,可以用来识别和匹配符合特定模式的文本。
正则表达式可以用来实现很多功能,比如验证邮箱或手机号码的格式、从文本中提取特定的信息、检查密码的强度等等。
它的强大之处在于可以根据需要自定义所需匹配的模式。
正则表达式的基本元素包括普通字符和特殊字符。
普通字符表示它本身,例如字母和数字。
特殊字符用来表示特定的意义或操作,比如通配符、重复次数和位置。
通配符是常用的正则表达式元素之一。
例如, "." 代表任意一个字符,"[]" 表示指定字符集合中的一个字符,"[abc]" 表示可以是字母 a、b 或 c 中的任意一个,"[^abc]" 表示可以是不是字母 a、b 或 c 中的任意一个字符。
重复次数是用来指定一个模式的重复次数的。
例如,"*" 表示前面的模式可以重复零次或更多次,"+" 表示前面的模式可以重复一次或更多次,"?" 表示前面的模式可以重复零次或一次。
位置元素用来指定字符串的位置。
例如,"^" 表示字符串的开头,"$" 表示字符串的结尾。
除了这些基本元素以外,正则表达式还有很多其他的特殊字符和用法,如分组、反向引用、贪婪匹配和非贪婪匹配等等。
使用正则表达式时,可以使用各种编程语言或工具来实现。
不同的语言或工具对于正则表达式的支持程度和语法细节可能会有所不同,但基本的概念和规则都是相似的。
总的来说,正则表达式是一种强大而灵活的工具,可以在文本处理的各种场景中发挥作用。
通过学习和掌握正则表达式的语法和用法,可以大大提高字符串处理的效率和准确性。
hae 常用正则【最新版】目录1.正则表达式的概念和作用2.常用正则表达式元字符及其功能3.常用正则表达式函数及其应用4.示例:使用 Python 实现常用正则表达式的匹配正文一、正则表达式的概念和作用正则表达式(Regular Expression,简称 regex)是一种强大的文本处理工具,它可以用来检查文本是否符合某种模式、提取文本中的特定信息等。
正则表达式广泛应用于各种编程语言和文本处理场景,如验证用户输入、过滤网页内容、数据提取等。
二、常用正则表达式元字符及其功能1.`.`:匹配任意字符(除了换行符)2.`*`:匹配前面的字符 0 次或多次3.`+`:匹配前面的字符 1 次或多次4.`?`:匹配前面的字符 0 次或 1 次5.`{n}`:匹配前面的字符 n 次6.`{n,}`:匹配前面的字符 n 次或多次7.`{n,m}`:匹配前面的字符 n 到 m 次8.`[abc]`:匹配方括号内的任意一个字符(a、b 或 c)9.`[^abc]`:匹配除方括号内字符以外的任意字符10.`(pattern)`:捕获括号内的模式,并将其存储以供以后引用11.`|`:表示或(or),匹配两个模式之一三、常用正则表达式函数及其应用1.`re.search(pattern, string)`:在字符串中查找与模式匹配的子串2.`re.findall(pattern, string)`:在字符串中查找所有与模式匹配的子串3.`re.sub(pattern, repl, string)`:用指定的替换字符串替换字符串中的所有匹配子串4.`pile(pattern)`:编译正则表达式,提高匹配效率四、示例:使用 Python 实现常用正则表达式的匹配```pythonimport re# 示例文本text = "I have 3 cats and 2 dogs."# 提取数字um = re.search(r"d+", text)if num:print("数字:", num.group())else:print("未找到数字")# 提取所有动物名称animal = re.findall(r"[a-zA-Z]+", text)print("动物名称:", animal)# 替换所有数字为对应的汉字ew_text = re.sub(r"d+", "一", text)print("替换数字后的文本:", new_text)```通过以上示例,我们可以看到正则表达式在文本处理中的强大功能。
最全常⽤正则表达式⼤全⼀、校验数字的表达式1. 数字:^[0-9]*$2. n位的数字:^\d{n}$3. ⾄少n位的数字:^\d{n,}$4. m-n位的数字:^\d{m,n}$5. 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6. ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7. 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8. 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9. 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10. 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11. ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12. ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13. ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14. ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15. ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16. ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17. 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18. 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19. 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1. 汉字:^[\u4e00-\u9fa5]{0,}$2. 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3. 长度为3-20的所有字符:^.{3,20}$4. 由26个英⽂字母组成的字符串:^[A-Za-z]+$5. 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6. 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7. 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8. 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9. 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10. 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11. 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+ 12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1. Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2. 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?4. ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5. 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6. 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7. ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8. 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9. 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10. 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11. 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12. ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13. ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14. ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15. 钱的输⼊格式:16. 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17. 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18. 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19. 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20. 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21. 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22. 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24. 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25. xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26. 中⽂字符的正则表达式:[\u4e00-\u9fa5]27. 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28. 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29. HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30. ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31. 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32. 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)33. IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤)34. IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))。