计量经济学的三种检验
- 格式:ppt
- 大小:370.00 KB
- 文档页数:144


E v i e w s计量经济学三大检验作业1我们有1978-2007年我国财政收入,国内生产总值,财政支出和商品零售价格指数的年度数据。
请用Eview 进行回归分析。
(1) 根据回归结果分析模型的经济意义(包含模型的显著性,拟合优度,系数的显著性,系数的经济意义)建立模型,做OLS 估计,得结果图一,列表如下:43283175.57898859.0003271.0558.6399X X X Y ++--=∧)0636.20)(065848.0)(012559.0)(836.2132(SE )882456.2)(65061.13)(260476.0-)(000492.3-(t =997046.02=R 996705.02=R 845.2924=F模型整体显著性较高(F 检验十分显著),可决系数2R 和调整的可决系数较大,即样本回归方程对样本观测值拟合较好。
t 检验显示2X 的系数不显著(p 值>0.05,不能拒绝β=0的原假设),3X 和4X 的系数显著(p值<0.05,拒绝β=0的原假设)。
从模型的经济意义来看,财政支出、商品零售价格指数与财政收入成正相关,国内生产总值与财政收入成负相关,不符合客观经济规律,可能与模型变量的选取有关。
考虑对模型进行对数变换,结果为图二。
432ln 128427.1ln 631090.0ln 448496.0946444.6ln X X X Y +++-=∧)610249.0)(160929.0)(141418.0)(853146.2(SE)849127.1)(921549.3)(171412.3)(434662.2(t -=987673.02=R 986251.02=R 3969.694=F对数变换后模型整体显著性较高(F 检验十分显著,p 值=0.00<<0.05),可决系数2R 和调整的可决系数略有下降,模型可解释98.63%的因变量变化。

所有计量经济学检验方法
1、回归分析:回归分析是用来确定两个变量之间相关关系的一种统计方法,它能够推断出一个变量对另一个变量的影响程度。
常用的回归检验包括偏直斜率检验、R平方检验、Durbin-Watson检验、自相关检验、Box-Cox检验等。
2、主成分分析:主成分分析(PCA)是一种统计分析方法,用于消除随机变量之间的相关性,从而简化数据分析过程。
常用的方法有二元主成分分析(BPCA)、多元主成分分析(MPCA)
3、因子分析:因子分析是一种统计学方法,用于确定从多个离散观测变量中提取的隐含变量。
常用的因子分析检验包括KMO检验、Bartlett 统计量检验、条件双侧门限统计量检验等。
4、多元分析:多元分析是一种统计学方法,用于探索随机变量之间的关系,常用的多元分析检验包括多元弹性网络(MANOVA)、多元回归(MR)以及结构方程模型(SEM)。
5、聚类分析:聚类分析是一种用于探索研究数据中的结构和特征的统计学方法。
它主要是将数据集分组,以便对数据集中的每组信息单独进行分析。
常用的聚类分析检验有K均值聚类、层次聚类、嵌套聚类等。
6、特征选择:特征选择是一种数据分析技术,用于从大量可能的特征中,选择有效的特征变量。


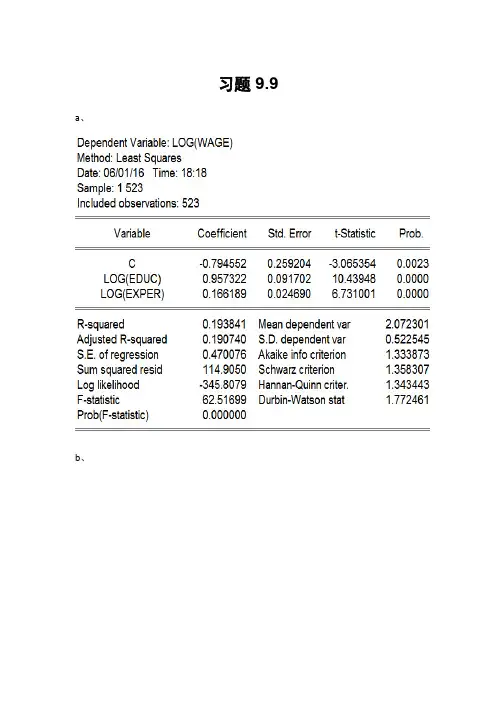
习题9.9 a、b、两者均可能存在异方差。
C、帕克检验三种帕克检验的p值都大于0.05,因此不拒绝原假设,即没有证据表明自变量系数为0;实质上帕克检验表明的是残差的平方并不体现出所假定的变化模式,残差的平方仍然可能存在其他形式的变化模型。
所以尚不能肯定一定不存在异方差。
格莱泽检验模型:ln(ei 2)=B1+B2ln(ln(educ))+vi格莱泽检验的第三种形式:残差的绝对值和1/educ显著相关,可能存在异方差问题。
怀特检验P=0.0004,拒绝原假设,即可能存在异方差问题。
帕克检验和格莱泽检验对异方差的形式要做出特殊的假定,要对不同的函数形式进行多次尝试,即便是自变量的系数不显著,也不態断定一定不存在异方差问题,因为可能是假定的函数形式不正确。
而怀特一般异方差检验采用了最为全面的函数形式,建议采用怀特一般异方差检验。
d、使用加权最小二乘法,选择权重是首要解决的问题。
权重选择得不恰当,异方差问题仍然会存在。
事实上,加权最小二乘法在使用过程中,需要经过多次尝试,多次检验,才可能找到一个合适的权重,因此在运用中这是比较不方便的。
本题样本容量为523,是个大样本,适合用怀特异方差校正。
其结果如下:e、选择不存在异方差的模型,即双对数模型。
因为异方差的存在会导致OLS估计量不再有效,其方差通常也会出现有偏性,在这种情况下,常用的假设检验都不再可靠,有可能出现错误的结论。
f、不能,因为两个模型的因变量形式不同。
习题9.28a、回归结果表明:小轿车的最高时速每提高1个百分点,耗油量平均下降1.27个百分点;马力每提高1个百分点,耗油量平均上升0.39个百分点;车重每提高1个百分点,耗油量平均下降1.90个百分点。
b、因为这是关于轿车耗油量的截面数据,因此预计存在异方差问题。
c、p值近似等于0,则拒绝原假设,即可能存在异方差问题。
d、校正后的值与OLS的结果比较发现:两者的估计系数的值是相同的,但是他们的方差和标准误差是不同的。


所有计量经济学检验方法(全)计量经济学所有检验方法一、拟合优度检验 可决系数TSSRSSTSS ESS R -==12 TSS 为总离差平方和,ESS为回归平方和,RSS 为残差平方和该统计量用来测量样本回归线对样本观测值的拟合优度。
该统计量越接近于1,模型的拟合优度越高。
调整的可决系数)1/()1/(12----=n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。
将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。
二、方程的显著性检验(F 检验)方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。
原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1:βj 不全为0 统计量)1/(/--=k n RSS kESS F 服从自由度为(k , n-k-1)的F分布,给定显著性水平α,可得到临界值Fα(k,n-k-1),由样本求出统计量F的数值,通过F>Fα(k,n-k-1)或F≤Fα(k,n-k-1)来拒绝或接受原假设H,以判定原方程总体上的线性关系是否显著成立。
三、变量的显著性检验(t检验)对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。
原假设与备择假设:H0:βi=0 (i=1,2…k);H1:βi≠0给定显著性水平α,可得到临界值tα/2(n-k-1),由样本求出统计量t的数值,通过|t|> tα/2(n-k-1) 或|t|≤tα/2(n-k-1)来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。
四、参数的置信区间参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
统计量)1(~1ˆˆˆ----'--=k n t k n c S t iiii iiie e βββββ在(1-α)的置信水平下βi 的置信区间是( , ) ββααββi i t s t s ii-⨯+⨯22,其中,t α/2为显著性水平为α、自由度为n-k-1的临界值。


所有计量经济学检验方法1. OLS回归分析:OLS(Ordinary Least Squares)是一种常用的回归分析方法,它通过最小二乘估计来计算自变量对因变量的影响。
OLS回归分析可用于检验两个或多个变量之间的关系。
2.t检验:t检验用于检验样本均值与总体均值之间的差异是否显著。
在计量经济学中,常常用t检验来检测回归系数的显著性,即判断自变量对因变量的影响是否显著。
3.F检验:F检验用于检验回归模型的整体显著性。
通过F检验可以判断回归模型中自变量的组合对因变量的影响是否显著。
4.残差分析:残差分析用于检验回归模型的拟合优度。
它通过对回归模型的残差进行统计分析,判断残差是否符合正态分布、是否存在异方差等,并据此评估回归模型的合理性。
5.雅克-贝拉检验:雅克-贝拉检验用于检验时间序列数据的自相关性。
自相关性是指时间序列数据中的随机误差项之间存在相关性,为了使回归模型的估计结果有效,需要排除自相关性的影响。
6. ARIMA模型:ARIMA(Autoregressive Integrated Moving Average)模型是一种常用的时间序列分析模型,用于分析和预测时间序列数据。
ARIMA模型可以用于检验时间序列数据的平稳性和趋势。
7. Granger因果检验:Granger因果检验用于检验两个时间序列变量之间的因果关系。
通过检验一个变量的过去值对另一个变量的当前值的预测能力,可以判断两个变量之间是否存在因果关系。
8.卡方检验:卡方检验用于检验两个或多个分类变量之间是否存在显著差异。
在计量经济学中,卡方检验常用于检验变量之间的相关性和拟合优度。
9.随机效应模型和固定效应模型:随机效应模型和固定效应模型是面板数据分析中常用的方法。
它们通过考虑个体特征对经济现象的影响,帮助研究人员解决面板数据中存在的个体特征和时间特征之间的内生性问题。
10.引导变量法:引导变量法用于解决因果关系中的内生性问题。
通过引入其他变量作为工具变量,可以将内生性引起的估计偏误消除或减小。

计量经济学中的统计检验引言统计检验是计量经济学中的重要方法之一,用于判断经济模型的有效性、变量之间的关系是否显著以及对经济政策效果的评估等。
本文将介绍计量经济学中常用的统计检验方法,包括基本原理、应用场景和使用步骤等内容。
一、单样本 t 检验单样本 t 检验用于检验一个样本的平均值是否显著不同于一个已知的理论值。
该检验基于 t 分布,可以对样本的平均值进行显著性检验。
使用步骤1.提出假设:首先,我们需要提出一个原假设和一个备择假设。
原假设通常为“样本均值等于理论值”,备择假设为“样本均值不等于理论值”。
2.计算 t 统计量:通过计算样本均值、样本标准差和样本容量,可以计算得到 t 统计量。
t 统计量的计算公式为:$$t = \\frac{\\bar{X}-\\mu}{s/\\sqrt{n}}$$3.其中,$\\bar{X}$ 是样本均值,$\\mu$ 是理论值,s是样本标准差,n是样本容量。
4.设定显著性水平:我们需要设定一个显著性水平,通常为0.05 或 0.01。
5.判断结果:根据 t 统计量和显著性水平,查找 t 分布表或使用统计软件得到 p 值。
如果 p 值小于显著性水平,则拒绝原假设,认为样本均值与理论值显著不同。
应用场景单样本 t 检验适用于以下场景: - 检验某一种产品的平均销售量是否达到预期水平; - 检验某一种投资组合的年化收益率是否显著高于市场平均收益率; - 检验某种药物的剂量是否显著高于安全水平。
二、双样本 t 检验双样本 t 检验用于比较两个样本均值之间是否存在显著差异。
通过比较两个样本的均值差异是否显著,我们可以判断两个样本是否来自同一总体。
使用步骤1.提出假设:与单样本 t 检验类似,我们需要提出原假设和备择假设。
原假设通常为“两个样本的均值相等”,备择假设为“两个样本的均值不相等”。
2.计算 t 统计量:通过计算两个样本的均值、标准差和样本容量,可以计算得到 t 统计量。
一、名词解释第一章1、计量经济学:计量经济学是以经济理论和经济数据的事实为依据,运用数学、统计学的方法,借助计算机为辅助工具,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
2、虚拟变量数据:虚拟变量数据是人为构造的,通常取值为1或0的,用来表征政策等定性事实的数据。
3、计量经济学检验:计量经济学检验主要是检验模型是否符合计量经济方法的基本假定。
4、政策评价:政策评价是利用计量经济模型对各种可供选择的政策方案的实施后果进行模拟测算,从而对各种政策方案做出评价第二章1、回归平方和:回归平方和用ESS 表示,是被解释变量的样本估计值与其平均值的离差平方和。
2、拟和优度检验:拟和优度检验指检验模型对样本观测值的拟合程度,用2R 表示,该值越接近1,模型对样本观测值拟合得越好。
3、相关关系:当一个或若干个变量X 取一定数值时,与之相对应的另一个变量Y 的值虽然不确定,但却按某种规律在一定范围内变化,变量之间的这种关系,称为不确定性的统计关系或相关关系,可表示为Y=f(X ,u),其中u 为随机变量。
4、高斯-马尔科夫定理:在古典假定条件下,O LS 估计式是其总体参数的最佳线性无偏估计式。
第三章1、偏回归系数:在多元线性回归模型中,回归系数j (j=1,2,……,k )表示的是当控制其他解释变量不变的条件下,第j 个解释变量的单位变动对被解释变量平均值的影响,这样的回归系数称为偏回归系数。
2、多重可决系数:“回归平方和”与“总离差平方和”的比值,用2R 表示。
3、修正的可决系数:用自由度修正多重可决系数2R 中的残差平方和与回归平方和。
4、回归方程的显著性检验(F 检验):对模型中被解释变量与所有解释变量之间的线性关系在总体上是否显著做出推断。
5、回归参数的显著性检验(t 检验):当其他解释变量不变时,某个回归系数对应的解释变量是否对被解释变量有显著影响做出推断。
6、无多重共线性假定:假定各解释变量之间不存在线性关系,或者说各解释变量的观测值之间线性无关,在此条件下,解释变量观测值矩阵X 列满秩Rank(X)=k ,此时,方阵X`X 满秩, Rank(X`X)=k从而X`X 可逆,(X`X) 存在。
计量经济学简答题1.简述计量经济学中的检验包括哪些内容?(1)t 检验:回归模型中变量的显著性检验;(2)F 检验:方程总体线性的显著性检验;受约束的回归检验;多重共线性检验(判定系数检验法和逐步回归法检验法);异方差性检验(G-Q 检验)(3)卡方检验:异方差性的检验(White 检验)、拉格朗日乘数(LM )检验(4)拟合优度检验:检验模型对样本观测值的拟合程度,一元线性回归模型中看可决系数R 2统计量的值,多元回归模型中看调整的R 2统计量的值。
其值越接近1,说明模型的拟合优度较高。
(5)异方差性的检验:图示检验法、White 检验、布罗施-帕甘(B-P )检验(F 统计量或LM统计量)、戈里瑟(Gleiser )检验。
(6)序列相关性的检验:图示法、回归检验法、D.W.检验法、拉格朗日乘数(LM )检验(7)时间序列的平稳性检验:单位根检验(DF 检验、ADF 检验)2.计量经济学研究的对象是什么?计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量经学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究。
3.应用计量经济学方法,研究客观经济现象的步骤是什么?(1)陈述理论(或假设);(2)建立计量经济模型;(3)收集数据;(4)估计参数;(5)假设检验;(6)预测和政策分析。
4.多元线性回归模型的经典的基本假定有哪些?(1)回归模型是正确设定的;(2)解释变量X 1,X 2...X K 在所抽取的样本中具有变异性,且X j 之间不存在严格线性相关性(无完全多重共线性);(3)随机干扰项具有条件零均值性:()0...|2,1=K i X X X E μ;(4)随机干扰项具有条件同方差及不序列相关性:()221...,|ar σμ=K i X X X V ,()0...,|,21=K j i X X X Cov μμ;(5)随机干扰项满足正态分布:()221,0~...,|σμN X X X K i 。
计量经济学所有检验分布,给定显著性水平α,可得到临界值Fα(k,n-k-1),由样本求出统计量F的数值,通过F>Fα(k,n-k-1)或F≤Fα(k,n-k-1)来拒绝或接受,以判定原方程总体上的线性关系是否原假设H显著成立。
三、变量的显著性检验(t检验)对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。
=0 (i=1,2…k);原假设与备择假设:H0:βiH1:β≠0i给定显著性水平α,可得到临界值tα/2(n-k-1),由样本求出统计量t的数值,通过|t|> tα/2(n-k-1) 或|t|≤tα(n-k-1)/2来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。
四、参数的置信区间参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
统计量)1(~1ˆˆˆ----'--=k n t k n c S t iiii iiie e βββββ在(1-α)的置信水平下βi的置信区间是( , ) ββααββi i t s t s ii-⨯+⨯22,其中,t α/2为显著性水平为α、自由度为n-k-1的临界值。
五、异方差检验1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程:iji i X f e ε+=)(~2 或iji i X f e ε+=)(|~|选择关于变量X 的不同的函数形式,对方程进行估计并进行显著性检验,如果存在某一种函数形式,使得方程显著成立,则说明原模型存在异方差性。
如: 帕克检验常用的函数形式:ie X Xf jiji εασ2)(=或ijiiX e εασ++=ln ln )~ln(22若α在统计上是显著的,表明存在异方差性。
Glejser 检验类似于帕克检验。
Glejser 建议:在从OLS 回归取得误差项后,使用e i 的绝对值与被认为密切相关的解释变量再做LS 估计,并使用如右的多种函数形式。
计量经济学重点(简答题)一、什么是计量经济学?计量经济学,又称经济计量学,它是以一定的经济理论和实际统计资料为依据,运用数学、统计学和计算机技术,通过建立计量经济学模型,定量分析经济变量之间的随机因果关系。
理解定义注意以下几个问题:1)理论基础:经济学、数学、统计学2)计量经济学是对实际经济现象的数量分析。
3)计量经济学研究的是经济变量之间的随机关系而非确定性关系。
4)计量经济学是一门经济学科,而非应用数学。
二、计量经济学的研究的步骤是什么?1)理论模型的设计A.理论或假说的陈述;B.理论的数学模型的设定;C.理论的计量经济模型的设定。
i.把模型中不重要的变量放进随机误差项中;ii.拟定待估参数的理论期望值。
2)获取数据数据来源:网络、统计年鉴、报纸、杂志数据类别:时间序列数据、截面数据、混合数据、虚变量数据。
数据要求:完整性、准确性、可比性、一致性i.完整性:模型中包含的所有变量都必须得到相同容量的样本观察值。
ii.准确性:统计数据或调查数据本身是准确的。
iii.可比性:数据口径问题。
iv.一致性:指母体与样本的一致性。
3)模型的参数估计:普通最小二乘法。
4)模型的检验:经济学检验;统计学检验;计量经济学检验;模型的预测检验。
5)模型的应用:结构分析;经济预测;政策评价;经济理论的检验与发展。
三、简述统计数据的类别?时间序列数据、截面数据、混合数据、虚变量数据。
1)时间序列数据:按时间先后排列收集的数据。
采纳时间序列数据的注意事项:A.所选择的样本区间的经济行为一致性问题。
B.样本数据在不同样本点之间的可比性问题。
C.样本数据过于集中的问题。
不能反映经济变量间的结构关系,应增大观察区间。
D.模型的随机误差项序列相关问题。
2)截面数据:又称横向数据,是一批发生在同一时间截面上的调查数据。
研究某时点上的变化情况。
采纳截面数据的注意事项:A.样本与母体的一致性问题。
B.随机误差项的异方差问题。
3)混合数据:也称面板数据,既有时间序列数据,又有截面数据。
计量经济学协整检验方法协整检验(cointegration test)是计量经济学中用于检验变量之间是否存在长期稳定的均衡关系的方法。
它的主要目的是确定变量之间的长期关系,即是否存在一个稳定的均衡关系,从而可以进行有效的经济分析和预测。
本文将介绍几种常用的协整检验方法。
1. 单位根检验方法(Unit root test)单位根检验用于检验时间序列数据是否具有非平稳性。
一般来说,如果变量是非平稳的,那么它们之间就不可能存在长期稳定的均衡关系。
常用的单位根检验方法有ADF检验(Augmented Dickey-Fuller test)和KPSS检验(Kwiatkowski–Phillips–Schmidt–Shin test)等。
ADF检验是一种参数统计方法,可以用来检验变量是否是单位根过程,从而判断是否存在协整关系;KPSS检验则是一种非参数统计方法,用于检验变量是否是平稳的。
2. Johansen协整检验方法(Johansen cointegration test)Johansen协整检验方法是一种常用的多变量协整检验方法,可以同时检验多个变量之间的协整关系。
该方法基于向量自回归模型(vector autoregressive model,VAR),通过对向量误差修正模型(vectorerror correction model,VECM)的估计,检验向量自回归参数的协整关系。
Johansen协整检验方法具有较强的参数估计效率和较好的统计性质,被广泛应用于实证研究中。
3. Engle-Granger两步法(Engle-Granger two-step method)Engle-Granger两步法是一种常用的两步骤协整检验方法。
首先,通过对变量进行单位根检验,确定哪些变量是非平稳的;然后,对非平稳变量进行协整关系的估计和检验。
该方法的优点是简单易行,适用于小样本情况,但它的估计效率相对较低。
4. 引导回归法(Bootstrap method)引导回归法是一种非参数的协整检验方法,用于解决传统统计方法在小样本情况下可能存在的偏误和低功效问题。
作业1我们有1978-2007年我国财政收入,国内生产总值,财政支出和商品零售价格指数的年度数据。
请用Eview 进展回归分析。
(1) 根据回归结果分析模型的经济意义〔包含模型的显著性,拟合优度,系数的显著性,系数的经济意义〕建立模型,做OLS 估计,得结果图一,列表如下:43283175.57898859.0003271.0558.6399X X X Y ++--=∧)0636.20)(065848.0)(012559.0)(836.2132(SE )882456.2)(65061.13)(260476.0-)(000492.3-(t =997046.02=R 996705.02=R 845.2924=F模型整体显著性较高〔F 检验十分显著〕,可决系数2R 和调整的可决系数较大,即样本回归方程对样本观测值拟合较好。
t 检验显示2X 的系数不显著〔p 值>0.05,不能拒绝β=0的原假设〕,3X 和4X 的系数显著〔p 值<0.05,拒绝β=0的原假设〕。
从模型的经济意义来看,财政支出、商品零售价格指数与财政收入成正相关,国内生产总值与财政收入成负相关,不符合客观经济规律,可能与模型变量的选取有关。
考虑对模型进展对数变换,结果为图二。
432ln 128427.1ln 631090.0ln 448496.0946444.6ln X X X Y +++-=∧)610249.0)(160929.0)(141418.0)(853146.2(SE)849127.1)(921549.3)(171412.3)(434662.2(t -=987673.02=R 986251.02=R 3969.694=F对数变换后模型整体显著性较高〔F 检验十分显著,p 值=0.00<<0.05〕,可决系数2R 和调整的可决系数略有下降,模型可解释98.63%的因变量变化。
t 检验显示4ln X 的系数不显著〔p 值=0.0758>0.05,不能拒绝β=0的原假设〕,2ln X 和3ln X 的系数显著〔p 值<0.05,拒绝β=0的原假设〕。