中国科学院大学数据库新技术期末复习(提纲+答案整理)
- 格式:pdf
- 大小:623.79 KB
- 文档页数:14

数据科学期末考试试题和答案本文档提供了一份数据科学期末考试的试题和答案。
试题
1. 什么是数据科学?
2. 数据科学的主要应用领域有哪些?
3. 数据科学的主要技术工具有哪些?
4. 请解释数据清洗的概念和重要性。
5. 请解释数据可视化的概念和重要性。
答案
1. 数据科学是通过收集、分析和解释数据来研究和理解现实世界的科学领域。
它结合了统计学、计算机科学和领域知识,旨在发现数据中隐藏的模式、趋势和见解。
2. 数据科学的主要应用领域包括金融、医疗、营销、社交媒体分析等。
它在各个领域都能提供决策支持和洞察力。
3. 数据科学的主要技术工具包括编程语言(如Python和R)、数据存储和处理工具(如SQL和Hadoop)、机器研究和统计分析
工具(如Scikit-Learn和TensorFlow)等。
4. 数据清洗是将原始数据转化为可靠、一致且易于分析的格式
的过程。
它包括处理缺失值、异常值、重复值以及数据格式转换等。
数据清洗的重要性在于确保数据质量、准确性和可靠性,以便后续
的数据分析和建模。
5. 数据可视化是将数据以可视化形式呈现的过程,通过图表、
图形和可视化工具展示数据的特征、关系和趋势。
数据可视化的重
要性在于提供直观的数据理解和传达,帮助决策者快速洞察数据,
发现模式和趋势,支持数据驱动的决策和沟通。
以上是试题和答案的简要内容,希望对您的期末考试有所帮助。
祝您顺利通过考试!。

域信息检索与利用实用技巧任课老师:李玲试题专用纸1、简答题:您在学习和研究过程中遇到下列问题时,常用哪些方法来解决?(10题,3分/小题,共30分)(1)查找期刊时,您常用的方法?答: 中文期刊一般用:中国知网、万方数据库、维普数据库等;外文期刊一般用:ACM、IEEE、Elsevier ScienceDirect、SpringerLink、ScienceOnline 、Taylor & Francis Online Journals 、Cambridge Journal等;可通过国科大图书馆进入上述网站首页,输入所需检索的期刊信息,如期刊名称、作者、发表年份等信息进行查询。
(2)查找中国科学院学位论文时,您常用的方法?答: 进入“中国科学院大学”首页→点击右下方“图书馆”→点击进入“中科院学位论文数据库”→进入检索界面,输入所需检索的论文信息,如:论文名称、作者、指导老师等。
(3)查找各国专利以及专利的被引用情况时, 您常用的方法?答:进入国家知识产权局官网“”,输入所需检索专利的发明名称、申请号、申请人(三者至少必填其一)进行检索,查看专利被引用情况。
(4)查找SCI期刊的影响因子,您常用的方法?答:通过国科大图书馆点击“ISI-SCIE”进入web of science平台查询界面,输入期刊的关键词、作者等信息,可通过“AND”进行多个关键词组合以缩小查询范围。
(5)查找标准文献时,有哪些注意事项?答:合理选择标准数据库(如中文期刊会议类检索工具选用CNKI、维普、万方等,查询专利选用国家知识产权局等数据库);注意文献的发表时间(如利用CNKI科技类期刊数据库查询只能查询1994年之后发表的文献,维普中文科技期刊库可查询1984年之后发表的文献)使用多个精确的关键字组合,以减小检索范围。
(6)文献管理时,您常用的方法?答:使用EndNote文献管理工具,进行分类管理方便后期查询。
域信息检索与利用实用技巧任课老师:李玲试题专用纸(7)获取无法直接下载的文献全文时,您常用的方法?答:可通过文献传递,向有权限的人求助;或通过查询Researchgate,付费网站获取;也可以邮件联系文献作者求助。

【21秋】数据库原理及应用开发学习通超星期末考试章节答案2024年1.恒参信道的特性改善可以采用分集接收的方法。
答案:错2.随机过程的频谱特性能用它的傅里叶变换表达式来表示答案:错3.随参信道对信号传输的影响可以采用均衡技术来加以改善。
答案:错4.当信道带宽B趋近于无穷大,信道容量C趋近于无穷大()答案:错5.由于DSB信号的调制制度增益是SSB的一倍,所以抗噪声性能比SSB好一倍。
()答案:错6.恒参信道的特性是可以通过线性网络来补偿的。
()答案:对7.出现概率越大的消息,其所含的信息量越大。
()答案:错8.如果随机过程x(t)是广义平稳的,那么它一定具有严格平稳的特点答案:错9.表示随机实验结果的一个变量叫随机变量答案:对10.平稳随机过程的自相关函数具有任意的形状答案:错11.白噪声是根据其概率密度函数的特点定义的答案:错12.按照能量区分,确知信号可分为能量信号和功率信号答案:对13.码元传输速率与信息传输速率在数值上是相等的。
()答案:错14.对于n维高斯过程,各统计样本之间的不相关特性与统计独立有如下关系答案:不相关不一定统计独立15.平稳随机过程协方差函数C(τ)可以利用相关函数R(τ)和均值m来表示,具体情况如下答案:R(τ)-m^216.高斯白噪声通常是指噪声的什么量服从高斯分布()答案:幅值17.如果随机过程x(t)是广义平稳的,那么它一定具有()特点答案:均值是常数18.以下关于随机过程的描述错误的是()答案:广义平稳的高斯随机过程一定是严平稳的19.一个均值为零的平稳高斯窄带噪声,它的包络一维分布服从(),如果再加上正弦波后包络一维分布服从()答案:瑞利分布;莱斯分布20.实能量信号的频谱密度和实功率信号的频谱有一个共同的特性,即其负频谱和正频谱的模(),相位()。
答案:偶对称;奇对称21.以下属于模拟信号是()答案:PAM信号22.已知4进制数字信号的传码率为400波特,转换为2进制数字信号的传输速率为______。

2022年中国科学技术大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、下列说法不正确的是()。
A.图的遍历是从给定的源点出发每个顶点仅被访问一次B.遍历的基本方法有两种:深度遍历和广度遍历C.图的深度遍历不适用于有向图D.图的深度遍历是一个递归过程2、设有一个10阶的对称矩阵A,采用压缩存储方式,以行序为主存储, a11为第一元素,其存储地址为1,每个元素占一个地址空间,则a85的地址为()。
A.13B.33C.18D.403、以下与数据的存储结构无关的术语是()。
A.循环队列B.链表C.哈希表D.栈4、下面关于串的叙述中,不正确的是()。
A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储5、已知串S='aaab',其next数组值为()。
A.0123B.1123C.1231D.12116、下列关于无向连通图特性的叙述中,正确的是()。
Ⅰ.所有的顶点的度之和为偶数Ⅱ.边数大于顶点个数减1 Ⅲ.至少有一个顶点的度为1A.只有Ⅰ B.只有Ⅱ C.Ⅰ和Ⅱ D.Ⅰ和Ⅲ7、已知关键字序列5,8,12,19,28,20,15,22是小根堆(最小堆),插入关键字3,调整后的小根堆是()。
A.3,5,12,8,28,20,15,22,19B.3,5,12,19,20,15,22,8,28C.3,8,12,5,20,15,22,28,19D.3,12,5,8,28,20,15,22,198、一个具有1025个结点的二叉树的高h为()。
A.11B.10C.11至1025之间D.10至1024之间9、每个结点的度或者为0或者为2的二叉树称为正则二叉树。
n个结点的正则二叉树中有()个叶子。
A.log2nB.(n-1)/2C.log2n+1D.(n+1)/210、下面关于B和B+树的叙述中,不正确的是()A.B树和B+树都是平衡的多叉树B.B树和B+树都可用于文件的索引结构C.B树和B+树都能有效地支持顺序检索D.B树和B+树都能有效地支持随机检索二、填空题11、以下程序的功能是实现带附加头结点的单链表数据结点逆序连接,请填空完善之。

(本大题共9小题,每空1分,共10分)请在每小题的空格中填上正确答案。
错填、不填均无分。
1. 关系数据模型由关系数据结构、关系操作和关系完整性约束三部分组成。
2. 一般情况下,当对关系R和S使用自然连接时,要求R和S含有一个或多个共有的属性3. 在Student表的Sname列上建立一个唯一索引的SQL语句为:CREATE UNIQUE INDEX Stusname ON student(Sname)4. SELECT语句查询条件中的谓词“!=ALL”与运算符 NOT IN 等价5. 关系模式R(A,B,C,D)中,存在函数依赖关系{A→B,A→C,A→D,(B,C)→A},则侯选码是 A和(B,C) ,R∈ AB NF。
6. 分E-R图之间的冲突主要有属性冲突、命名冲突、结构冲突三种。
7. 事物是DBMS的基本单位,是用户定义的一个数据库操作序列。
8. 存在一个等待事务集{T0,T1,…,T n},其中T0正等待被T1锁住的数据项,T1正等待被T2锁住的数据项,T n-1正等待被T n锁住的数据项,且T n正等待被T0锁住的数据项,这种情形称为死锁。
9. 可串行性是并发事务正确性的准则。
三、简答题(第1、3题3分,第2题4分,共10分)1.试述关系模型的参照完整性规则?答:参照完整性规则:若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:取空值(F的每个属性值均为空值)或者等于S中某个元组的主码值。
2.试述视图的作用?(1)视图能够简化用户的操作。
(1分)(2)视图使用户能以多种角度看待同一数据。
(1分)(3)视图对重构数据库提供了一定程度的逻辑独立性。
(1分)(4)视图能够对机密数据提供安全保护。
(1分)3. 登记日志文件时必须遵循什么原则?登记日志文件时必须遵循两条原则:(1)登记的次序严格按并发事务执行的时间次序。

中科院机器学习题库new整理表姓名:职业工种:申请级别:受理机构:填报日期:A4打印/ 修订/ 内容可编辑信息技术会考复习(十五)【学习目标】让学生复习数据管理技术上机内容。
【任务导航】通过让学生自主学习来复习这部分内容。
【学习过程】一、教师点评上周数据管理技术上机系统操作的内容。
二.学生自主运行练习上机系统。
针对上次考试系统考得不好的学生进行分层次辅导,指出其经常出错的地方,如数据库的名字打错、保存路径出错、数据表名打错等问题。
三、分析部分上机选择题第 1题:(分值: 2)如图所示为某学校行政管理结构,该图描述的数据模型是A.面向对象模型B.关系模型C.网状模型D.层次模型第 2题:(分值: 2)在“参赛选手”数据表中,有关参赛选手的信息如下:“选手编号、姓名、性别、出生年月、学校名称、比赛成绩”其中“姓名”和“出生年月”的数据类型可以分别定义为A.日期型和文本型B.文本型和日期型C.数字型和数字型D.数字型和日期型第 3题:(分值: 2)如图所示的“读者信息”表中,可以选作关键字字段是A.读者身份B.姓名C.性别D.借书证号第 4题:(分值: 2)在信息世界中,实体集之间的联系有三种:一对一联系、一对多联系和A.多对多联系B.单对单联系C.逻辑联系D.数据联系第 5题:(分值: 2)下列关于数据库系统主要特点的叙述,错误的是A.数据具有较高的独立性B.数据共享C.实现数据冗余D.数据结构化第 6题:(分值: 2)关系数据库的二维表(关系)必须满足的条件是①表中每一列的数据类型必须相同②表中不允许有重复的字段③表中不应有内容完全相同的行④行和列排列顺序是无关紧要的⑤表中每一个字段可以是简单的数据项, 也可以是组合的数据项A.①②③⑤B.①②③④C.②③④⑤D.①③④⑤第 7题:(分值: 2)下列属于现实世界术语的是A.字段B.对象C.关键字D.记录第 8题:(分值: 2)下列关于数据库管理系统的叙述,正确的是A.数据库管理系统具有对数据库中数据资源进行统一管理和控制的功能B.数据库管理系统是数据库的统称C.数据库管理系统具有对任何信息资源管理和控制的能力D.数据库管理系统对普通用户来说具有不可操作性第 9题:(分值: 2)如图所示的“厦门至上海南”表中,属于字段名是A.厦门、福州南B.福州南、12:47C.站名、动车组车次D.D3204、宁德第 10题:(分值: 2)如图所示的E-R图,对应的二维表是A.B.C.D.第 11题:(分值: 2)在数据库技术发展过程中,最常用的数据模型有层次模型、网状模型和A.分支模型B.关系模型C.独立模型D.系统模型第 12题:(分值: 2)下列关于数据管理技术的叙述,正确的是A.数据管理技术是指图书管理技术B.数据管理技术是指对存储在计算机中的文件进行管理的专门技术C.数据管理技术是指保存批量数据的技术D.数据管理技术是指对数据的收集、分类、组织、存储等与数据管理活动有关的技术第 13题:(分值: 2)在信息世界,实体集之间的联系有三种。

2021年国开电大《大数据技术》期末测验试题及答案1、当前大数据技术的基础是由(C)首先提出的。
A:微软B:百度C:谷歌D:阿里巴巴2、大数据的起源是(C)。
A:金融B:电信C:互联网D:公共管理3、根据不同的业务需求来建立数据模型,抽取最有意义的向量,决定选取哪种方法的数据分析角色人员是(C)。
A:数据管理人员B:数据分析员C:研究科学家D:软件开发工程师4、(D)反映数据的精细化程度,越细化的数据,价值越高。
A:规模B:活性C:关联度D:颗粒度5、数据清洗的方法不包括(D)。
A:缺失值处理B:噪声数据清除C:一致性检查D:重复数据记录处理6、智能健康手环的应用开发,体现了(D)的数据采集技术的应用。
A:统计报表B:网络爬虫C:API接口D:传感器7、下列关于数据重组的说法中,错误的是(A)。
A:数据重组是数据的重新生产和重新采集B:数据重组能够使数据焕发新的光芒C:数据重组实现的关键在于多源数据融合和数据集成D:数据重组有利于实现新颖的数据模式创新8、智慧城市的构建,不包含(C)。
A:数字城市B:物联网C:联网监控D:云计算9、大数据的最显著特征是(A)。
A:数据规模大B:数据类型多样C:数据处理速度快D:数据价值密度高10、美国海军军官莫里通过对前人航海日志的分析,绘制了新的航海路线图,标明了大风与洋流可能发生的地点。
这体现了大数据分析理念中的(B)。
A:在数据基础上倾向于全体数据而不是抽样数据B:在分析方法上更注重相关分析而不是因果分析C:在分析效果上更追究效率而不是绝对精确D:在数据规模上强调相对数据而不是绝对数据11、下列关于舍恩伯格对大数据特点的说法中,错误的是(D)。
A:数据规模大B:数据类型多样C:数据处理速度快D:数据价值密度高12、当前社会中,最为突出的大数据环境是(A)。
A:互联网B:物联网C:综合国力D:自然资源13、在数据生命周期管理实践中,(B)是执行方法。
A:数据存储和备份规范B:数据管理和维护C:数据价值发觉和利用D:数据应用开发和管理14、下列关于网络用户行为的说法中,错误的是(C)。

数据科学复习题集及答案数据科学作为一门涵盖统计学、机器学习、数据挖掘等多个领域的综合学科,通过运用数学方法和计算机科学技术,从数据中发现新的信息和知识,并为决策提供支持。
为了帮助学习者更好地掌握数据科学的知识,本文整理了一系列数据科学复习题集及其详细答案,供大家参考。
第一部分:数据预处理问题一:请解释数据清洗的概念,并列举常见的数据清洗方法。
答案:数据清洗是指对原始数据进行处理,去除异常值或缺失值,修正数据格式或数据类型等操作,以提高数据的质量和准确性。
常见的数据清洗方法包括删除缺失值、替换异常值、去重,以及将数据转化为一致的格式等。
问题二:请说明特征选择的意义以及常用的特征选择方法。
答案:特征选择是指从数据集中选择对目标变量有显著影响的特征,以提高模型的准确性和解释性。
特征选择的意义在于减少维度、降低计算成本,并增强模型的泛化能力。
常用的特征选择方法包括过滤法(如相关系数、方差选择)、包装法(如递归特征消除)和嵌入法(如L1正则化)等。
第二部分:统计学基础问题三:请解释均值、中位数和众数的概念,以及它们在统计分析中的应用。
答案:均值指的是一组数据的平均值,通过将所有数据相加再除以数据的数量得到。
中位数是将一组数据按照大小顺序排列后,处于中间位置的数值。
众数是一组数据中出现次数最多的数值。
在统计分析中,均值可以用于描述数据的平均水平,中位数则可以描述数据的中心趋势,而众数则常用于描述数据的类型或最常见的特征。
问题四:请解释相关系数的概念。
并说明相关系数的取值范围及其含义。
答案:相关系数是衡量两个变量之间相关程度的指标,其取值范围为-1到1。
当相关系数为正值时,表示两个变量呈正相关,即随着一个变量的增加,另一个变量也会增加。
当相关系数为负值时,表示两个变量呈负相关,即随着一个变量的增加,另一个变量会减少。
当相关系数接近于0时,表示两个变量之间没有线性相关关系。
第三部分:机器学习算法问题五:请解释什么是监督学习和无监督学习,并举例说明其应用场景。
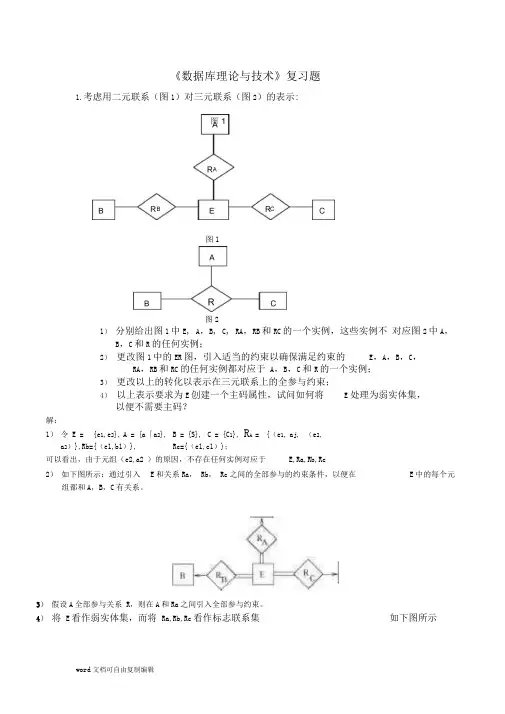
《数据库理论与技术》复习题1.考虑用二元联系(图1)对三元联系(图2)的表示:1) 分别给出图1中E , A ,B , C , RA ,RB 和RC 的一个实例,这些实例不 对应图2中A ,B ,C 和R 的任何实例;2) 更改图1中的ER 图,引入适当的约束以确保满足约束的 E ,A ,B ,C ,RA ,RB 和RC 的任何实例都对应于 A ,B ,C 和R 的一个实例;3) 更改以上的转化以表示在三元联系上的全参与约束; 4) 以上表示要求为E 创建一个主码属性,试问如何将E 处理为弱实体集,以便不需要主码?解:1) 令 E = {e 1, e 2}, A = {a 「a 2}, B = {S}, C = {C 1}, R A = {(e 1, aj, (e 2,a 2)},Rb={(e1,b1)},Rc={(e1,c1)};可以看出,由于元组(e2,a2 )的原因,不存在任何实例对应于E,Ra,Rb,Rc2) 如下图所示:通过引入 E 和关系Ra , Rb , Rc 之间的全部参与的约束条件,以便在E 中的每个元组都和A ,B ,C 有关系。
3) 假设A 全部参与关系 R ,则在A 和Ra 之间引入全部参与约束。
4) 将 E 看作弱实体集,而将 Ra,Rb,Rc 看作标志联系集 如下图所示图1图22. Suppose that we are using extendable hashing on a file that contains records with the followi ngsearch-key values:2, 3, 5, 7, 11, 17, 19, 23, 29, 31,35,271)Show the exte ndable hash structure for this file if the hash fun cti on is h(x) = x mod 8and buckets can hold three records.2.解:(1)(一点疑惑:这道题用的不是书中的用高位extendable hash?只有凭感觉做了,不一定正确,拉链法扩展,超出24后乘2 rehash)(若是按书上的,先mod 8得到hash值,取高位二进制…最多111,即directory depth 最大为3) Bucket 号0:1:[17,]2:[2]3: [3,11,19] -> [35,27]4:5:[5,29]6:7:[7,23,31](2)只注明了修改的行a.Bucket3 : [3,19,35] -> [27]b.Bucket7 : [7,23,31] -> [15]c.Bucket7 : [7,23,15]d.Bucket1 : [17,25]答案类似下面:hurkpt0T234567 record376(11117456511620iQ50464H7I7(15242H5I572222轴81475069752)Show how the extendable hash structure of part 1) changes as theresult of each of the following steps: a. Delete 11. b. I nsert 15. c. Delete 31. d. I nsert 25.2 3and h3, where hi(x) = ((x +x )*i) mod m . 3.答:(1)(2)直接套hash 函数(3)套公式:任何一位k 个hash 后还是为0的概率:p=(1-1.0/m)误判率:f = (1-p)k1) Show the Bloom filter bits following each of the following six elements insertions in order: 2013, 2010,2007, 2004, 2001, 19982) For the Bloom filter obtained after part 1), find one value that is not among the six in serted values,but is a false positive.3) Compute the probability of a false positive f.3.Suppose thatBloom filter usesm=32 bits, and 3 hash functions h1, h2,Insert 2369, 37&DInsert 3943Q6)i») After inserting 2013 巾1(2013) ■ 14, h2(2OJ3) ■ 28, h3(2(113) - 10):Bits set: 10, 14, 28After inserting 2010 - 12. 112(2010)= 24, h3(2010| = 4):Bits set:4, 10, 12, 14, 24,28After inserting 2007 (hl(2007)= 24^ h2(2()07 \ —16, hl(2010) —8):Bits set: 4, 8, JO, 12, 14> 16, 24, 28After inserting 30(J4 (hl(2lJ<J4| - 16. h2(2004\ = 0, h3^20(J4) = 161:4 一Bits set: 0* 4* 8t 10, IX 14. 16#24, 28AHrr inserting 2()01 (hU2D01) - l£ h2(20Ol) ■札h3(2OO|) w 22):BUi set: 0, 4, 8, 10, IX 】4»J8, 22, 24, 2SAHcr in^rling 3998 ihl{l99»r- 28. h2(i99S)- 24, h3(iyvS) - 20):Bits act: 0. 4.礼10, 12, 14, 16. 18, 20, 22, 24, 28b) 3^( K) will be LI fuJ.se posit since oJl of il 爺hibsh will niuip Io I he Jirrolh hil which hus alirudybeen sei by 2004.4.假设用Bloom filter存放集合S(其中元素个数为34亿),hash函数个数为8, 允许的错误率最大为0.001,那么该Bloom filter的位数m最小应为多少?4.解:M = n*1.44*log 2(1.0/f)5.The key-value store uses quorums for consistency. The total number of replicas, N, for a key, is fixed -however, N may be differe nt for differe nt keys. Each read has to access at least r replicas (and retur ns if all of them agree), while each write has to write to at least w replicas.For each of the following design choices, say whether it (by itself) does or does not guarantee strong consistency, i.e., one copyserializability?a.w=3, r=1b.w = 2N/3c.叶w = Nd.w = Ne.r + w > N/2f.r + w > 3N/2g.r + w > 3N/2, w > 2N/3Q7) a) No. Nodcit caii be in the order of hundreds^ iind since write is only being applied to J mode陥there cun behcminl er Moling writes which vitd 皿c oiic copy ^cri Lili/ability.b| No. Since l he re id is only on cine replies ilicn we can have a rc^i on a M Jc replica thM'爲pjil of the 2N/J nodes chosen for wrilcs.c | No. Writes can equal >□ 1 in here | J.c, r=Nl :i. Thu齢there can be noninlrrscch iig writes which which violulc<^nc ctvn vscri al izahi]i I v.~ 書# "- ——一■—th SiiiLC wriles arc applied It? all of I he noik 备iiny rc«id ^ill get the ] Jjlii.c| No, SimiLkr la C, sclting w« 1 result in noninlcrsccting writes which violate one ccpyscriali^abilily-f t Yes. w > N/2 in thi^ ca^cr. because otherwise, r > N which dues noi ni^kc sense,R匸詔乐& writes will intcrsecl inihis ease and so does writes & wriies.we arcg) YtSu Wrhe^ will nu*l intcrscvt in this and 0皿疋r+w > 3N/2, rcihJs mid wriics will intcfscxl for sure. SoB guaranteed k) gel the data.N越大,同一个数据的备份越多,系统相对也就越不容易丢失数据。

数据库原理及应用复习指南(附答案)数据库原理及应用复习指南一、考试形式:闭卷统考二、考试题型●单项选择题(本题10小题;每小题2分,共20分)●填空题(本题10空 ,每空1分,共10分)●简答题(本题4小题,每小题6分,共24分)●设计题(本题6小题,每小题4分,共24分)●综合题(本题3小题,共22分 )三、重点难点第1章绪论●掌握数据库、数据库管理系统、数据库系统的概念与关系●了解数据管理技术的产生与发展、理解数据库系统的特点●掌握数据模型的组成要素;掌握数据模型分类;几个基本术语,特别是关系模型中码的含义。
●掌握数据库系统的三级模式结构与两级映像,书28页的图1.16 第2章关系数据库●理解关系的概念;关系中的主属性、非主属性的含义;关系的性质,关系模式的形式化表示。
●掌握关系模型的组成要素;结合S-C,理解关系的三种完整性约束;●掌握关系代数的含义;传统的集合运算、专门的关系运算中的选择、投影、连接(包括外连接)、除(难点)。
●根据给出的语义描述,写出关系代数表达式;或根据关系代数表达式写结果;简单的代数表达式与SQL语句之间的转换。
第3章关系数据库标准语言SQL●理解SQL的特点;●掌握定义修改和删除数据库、表、索引的方法;●重点掌握数据查询的方法。
●掌握数据更新的方法。
●掌握视图的概念、作用,视图与表的区别;掌握定义、修改、删除、查询、更新视图的方法●重点复习书上的所有例题、书后的作业、补充的实验练习。
第4章数据库安全性●掌握数据库安全性的基本概念,了解计算机及信息安全技术的两种安全标准●掌握数据库安全性控制方法,特别是授权与回收●了解数据库中角色的概念●了解视图机制和审计、数据加密第5章数据库完整性●掌握数据库完整性的基本概念●掌握三种完整性定义及其检查方法与违约处理●掌握触发器和存储过程的定义和使用第6章关系数据理论●掌握关系数据理论问题的提出;●掌握函数依赖、平凡与非平凡函数依赖、完全和部分函数依赖、传递函数依赖的基本概念;多值依赖的概念;●理解1NF、2NF、3NF、BCNF、4NF;●重视书189页的图6.8●理解Armstrong公理系统的3条规则●掌握计算属性集关于函数依赖集的闭包的方法(算法6.1)●掌握求最小函数依赖集的方法(定义6.15)●掌握分解到2NF\3NF\BCNF的算法。

第一套题客观题单选题(共12题,共36分)1. 利用SQL语言所建立的视图在数据库中属于()。
A 实表B 虚表C 索引D 字段参考答案:B;考生答案:B;试题分数:3;考生得分:32. 下面属于Access数据库中所含操作对象的是()。
A 文件B 宏C 索引D 视图参考答案:B;考生答案:B;试题分数:3;考生得分:33. 设一个关系为R(A,B,C,D,E),它的最小函数依赖集为FD={A→B,A→C,B→D,D→E},则该关系的候选码为()。
A AB BC CD D参考答案:A;考生答案:A;试题分数:3;考生得分:34. 在文件系统中,存取数据的基本单位是()。
A 记录B 数据项C 二进制位D 字节参考答案:A;考生答案:A;试题分数:3;考生得分:35.在Access中,如果只想显示表中符合条件的记录,可以使用的方法是()。
A 筛选B 删除C 冻结D 隐藏参考答案:A;考生答案:D;试题分数:3;考生得分:06.在Access中,若利用宏打开一个查询,则选择的宏操作命令是()。
A OpenTableB OpenQueryC OpenFormD OpenReport参考答案:B;考生答案:B;试题分数:3;考生得分:37. 在利用计算机进行数据处理的四个发展阶段中,第三个发展阶段是()。
A 人工管理B 文件系统C 数据库系统D 分布式数据库系统参考答案:C;考生答案:C;试题分数:3;考生得分:38. 设两个关系中分别包含有m和n个属性,它们具有同一个公共属性,当对它们进行等值连接时,运算结果的关系中包含的属性个数为()。
A m*nB m+n-1C m+nD m+n+1参考答案:C;考生答案:B;试题分数:3;考生得分:09.在SQL的查询语句中,group by选项实现的功能是()。
A 选择B 求和C 排序D 分组统计参考答案:D;考生答案:D;试题分数:3;考生得分:310.在报表设计视图中,若需要在报表每一页的顶部都打印出相关信息,则该信息应设置在()。
2021年中国科学技术大学数据科学与大数据技术专业《计算机组成原理》科目期末试卷B(有答案)一、选择题1、下列存储器中,在工作期间需要周期性刷新的是()。
A. SRAMB. SDRAMC.ROMD. FLASH2、一个存储器的容量假定为M×N,若要使用I×k的芯片(I<M,k<N),需要在字和位方向上同时扩展,此时共需要()个存储芯片。
A.M×NB.(M/I)×(N/k)C.M/I×M/ID.M/I×N/k3、串行运算器结构简单,其运算规律是()。
A.由低位到高位先行进行进位运算B.由低位到高位先行进行借位运算C.由低位到高位逐位运算D.由高位到低位逐位运算4、float 型数据常用IEEE754单精度浮点格式表示。
假设两个float型变量x和y分别存放在32位寄存器fl和f2中,若(fl)=CC900000H,(f2)=BOC00000H,则x和y 之间的关系为()。
A.x<y且符号相同B.x<y符号不同C.x>y且符号相同D.x>y且符号不同5、假设在网络中传送采用偶校验码,当收到的数据位为10101010时,则可以得出结论()A.传送过程中未出错B.出现偶数位错C.出现奇数位错D.未出错或出现偶数位错6、在下面描述的PCI总线的基本概念中,不正确的表述是()。
A.PCI总线支持即插即用B.PCI总线可对传输信息进行奇偶校验C.系统中允许有多条PCI总线D.PCI设备一定是主设备7、关于同步控制说法正确的是()。
A.采用握手信号B.由统一时序电路控制的方式C.允许速度差别较大的设备一起接入工作D.B和C8、计算机硬件能够直接执行的是()。
1.机器语言程序IⅡ.汇编语言程序Ⅲ.硬件描述语言程序入A.仅IB.仅I、ⅡC.仅I、ⅢD. I、Ⅱ 、Ⅲ9、在计算机系统中,作为硬件与应用软件之间的界面是()。
试题一一、单项选择题(本大题共20小题,每小题2分,共40分) 在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。
错选、多选 或未选均无分。
1.数据库系统的核心是(B)A •数据库B •数据库管理系统C .数据模型D .软件工具2. 下列四项中,不属于数据库系统的特点的是( C ) A •数据结构化 B •数据由DBMS 统一管理和控制 C .数据冗余度大D .数据独立性高3. 概念模型是现实世界的第一层抽象,这一类模型中最著名的模型是 (D ) A •层次模型 B •关系模型 C .网状模型D •实体-联系模型4.数据的物理独立性是指( C )A •数据库与数据库管理系统相互独立B •用户程序与数据库管理系统相互独立C •用户的应用程序与存储在磁盘上数据库中的数据是相互独立的D •应用程序与数据库中数据的逻辑结构是相互独立的5・要保证数据库的逻辑数据独立性,需要修改的是(A )A •模式与外模式之间的映象B •模式与内模式之间的映象C .模式D •三级模式6・关系数据模型的基本数据结构是( D )A.树B .图C .索引D .关系7・ 有一名为“列车运营”实体,含有:车次、日期、实际发车时间、实际抵达 时间、情况摘要等属性,该实体主码是( C )A.车次 B .日期 C .车次+日期D .车次+情况摘要8.己知关系R 和S , R A S 等价于(B )A. ( R-S)-S C. (S-R)-R9. 学校数据库中有学生和宿舍两个关系:学生(学号,姓名)和 宿舍(楼名,房间号,床位号,学号)假设有的学生不住宿,床位也可能空闲。
如果要列出所有学生住宿和宿舍分 配的情况,包括没有住宿的学生和空闲的床位,则应执行( A )A.全外联接 C.右外联接10. 用下面的T-SQL 语句建立一个基本表:CREATE TABLE Student (Sno CHAR (4) PRIMARY KEY,Sname CHAR (8) NOT NULL, Sex CHAR ( 2), Age INT )可以插入到表中的元组是( D )D. '5021','刘祥',NULL , NULL11. 把对关系SPJ 的属性QTY 的修改权授予用户李勇的 T-SQL 语句是( CA. GRANT QTY ON SPJ TO '李勇’B. GRANT UPDA TE(QTY) ON SPJ TO '李勇'C. GRANT UPDA TE (QTY) ON SPJ TO 李勇D. GRANT UPDA TE ON SPJ (QTY) TO 李勇13•关系规范化中的插入操作异常是指A •不该删除的数据被删除 C .应该删除的数据未被删除14•在关系数据库设计中,设计关系模式是数据库设计中( A )阶段的任务A .逻辑设计B •物理设计C .需求分析D •概念设计B. S-(S-R) D. S-(R-S)B.左外联接 D.自然联接A. '5021','刘祥',男,21B. NULL ,'刘祥',NULL ,21 C. '5021', NULL ,男,21 (D )B .不该插入的数据被插入 D .应该插入的数据未被插入15. 在E-R 模型中,如果有 3个不同的实体型,3个m:n 联系,根据E-R 模型转 换为关系模型的规则,转换后关系的数目为( C )。
数据库原理与应用复习提纲与参考答案 考试题型:一.单项选择题二.填空题:三.判断题: 四.简答题五.关系代数和SQL 语言六.码的求解、范式判断、规范化:七.绘制E-R 图、转换为关系模式、确定关系的码八.调度问题:确定是否为可串行化调度复习提纲---教材分章节题库目录:第一部分 基本概念(ch1绪论)第二部分 关系数据库(ch2)第三部分 SQL 语言(ch3)第四部分 数据库安全性(ch4)第五部分 数据库完整性(ch5)第六部分 关系数据理论及数据库设计(ch6ch7)第七部分 并发控制及数据库恢复(ch10)关注平时做过的:习题实验二、三、四基本概念题综合技能题综合技能题答题步骤总结:五.关系代数查询答题步骤1、确定条件的列名与查询的列名,来自哪些关系,来自单个关系用单关系选择投影查询;来自多个关系用连接,再选择投影;如果有所有的、至少、包含等字样考虑用除运算SQL语言查询答题步骤2、确定条件的列名与查询的列名,来自哪些表,来自单个表用单表查询,用select确定列用where确定行;来自多个表用连接或子查询,要查询的列来自单个表可使用子查询(也可用连接查询),否则只能用连接查询;如果有所有的、至少、包含等字样考虑用Exists存在性子查询;如果有统计信息用分组查询,用having筛选满足分组条件的组,注意select中的列有2种,分组列与聚合函数列,没有第三种列。
六.码的求解、范式判断、规范化答题步骤码的求解步骤将依赖集的属性分成左右两边,则有1)只出现在左边的肯定是码的属性之一2)只出现在右边的肯定不是码的属性3)两边都不出现的肯定是码的属性之一;再看选出的属性能否构,如果是码,则选出的属性就是唯一的码;如果不是码,则将其与依赖集左边属性一一结合,尝试是否为码(即能否决定其他全部属性)范式判断区分非主属性,主属性;再确定有无部分依赖、传递依赖等做出判断规范化将范式按1NF→2NF→3NF→BCNF逐步分解(不严格推敲时将依赖集的每个依赖左右两边组成一个关系即可得分解)七.绘制E-R图、转换为关系模式、确定关系的码答题步骤确定实体、联系、联系类型(1:1或1:n或m:n);转换为关系模式;确定每个关系的码八.调度问题:确定是否为可串行化调度答题步骤先确定初值、再计算2个事务的串行结果、再计算事务的并行处理结果,比较结果:若与其中任何一个串行结果相同则为可串行化调度,否则为不可串行化调度数据库原理与应用复习提纲题库参考答案第一部分基本概念主要内容:1、数据、数据库、数据库管理系统、数据库系统基本概念2、数据管理技术的发展阶段3、数据库系统的特点4、数据模型的组成要素5、概念模型的描述6、关系数据模型的三要素7、数据库系统的三级模式两级映像、数据独立性练习题一、选择题1 数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
2022年中国科学技术大学数据科学与大数据技术专业《计算机网络》科目期末试卷B(有答案)一、选择题1、在n个结点的星形拓扑结构中,有()条物理链路。
A.n-lB.nC.n×(n-1)D.n×(n+l)/22、当一台计算机从FTP服务器下载文件时,在该FTP服务器上对数据进行封装的5个转换步骤是()。
A.数据、报文、IP分组、数据帧、比特流B.数据、IP分组、报文、数据帧、比特流C.报文、数据、数据帧、IP分组、比特流D.比特流、IP分组、报文、数据帧、数据3、在因特网中,IP分组的传输需要经过源主机和中间路由器到达目的主机,通常()。
A.源主机和中间路由器都知道IP分组到达目的主机需要经过的完整路径B.源主机知道IP分组到达日的主机需要经过的完整路径,而中间路由器不知道C.源主机不知道IP分组到达目的主机需要经过的完整路径,而中间路由器知道D.源主机和中间路由器都不知道IP分组到达目的主机需要经过的完整路径4、路由器的路由选择部分,包括了()。
A.路由选择处理器B.路由选择协议C.路由表D.以上都是5、PPP中的LCP帧起到的作用是()。
A.在建立状态阶段协商数据链路协议的选项B.配置网络层协议C.检查数据链路层的错误,并通知错误信息D.安全控制,保护通信双方的数据安全6、对于无序接收的滑动窗口协议,若序号位数为n,则发送窗口最大尺寸为()A.2n -1B.2nC.2n-1D.2n-17、一个UDP用户数据报的数据字段为8192B。
在链路层要使用以太网来传输,那么应该分成()IP数据片。
A.3个B.4个C.5个D.6个8、下面信息中()包含在TCP首部中而不包含在UDP首部中。
A.目标端口号B.序号C.源端口号D.校验号9、传输层中的套接字是()。
A.IP地址加端口B.使得传输层独立的APIC.允许多个应用共享网络连接的APID.使得远端过程的功能就像在本地一样10、FTP客户机发起对FTP服务器的连接建立的第一阶段建立()A.控制传输连接B.数据连接C.会话连接D.控制连接11、在TCP/IP协议簇中,应用层的各种服务是建立在传输层提供服务的基础上的。
数据与技术期末考试卷答案一、选择题1. 数据库管理系统(DBMS)的主要功能是:A. 存储数据B. 管理数据C. 访问数据D. 以上都是答案:D2. 在关系数据库中,表之间的关系可以是:A. 一对一B. 一对多C. 多对多D. 所有选项答案:D3. SQL语言用于:A. 数据查询B. 数据更新C. 数据定义D. 所有选项答案:D4. 数据挖掘的目的是:A. 发现数据中的模式B. 预测未来趋势C. 辅助决策制定D. 所有选项答案:D5. 大数据分析的核心技术包括:A. 分布式计算B. 机器学习C. 数据存储D. 所有选项答案:D二、简答题1. 请简述数据清洗的重要性。
答:数据清洗是确保数据质量的关键步骤,它包括去除重复数据、纠正错误数据、处理缺失值等。
数据清洗可以提高数据分析的准确性,减少错误结论的风险,是数据科学项目成功的关键。
2. 什么是数据仓库,它与数据库有何不同?答:数据仓库是一个面向主题的、集成的、时变的数据集合,用于支持管理决策。
与数据库不同,数据仓库通常用于存储历史数据,支持复杂的查询和分析,而不是日常事务处理。
三、计算题1. 假设有一个学生成绩数据库,包含学生ID、姓名、课程ID和成绩。
请编写SQL查询语句,找出所有数学课成绩低于60分的学生名单。
答:SELECT 姓名 FROM 学生成绩表 WHERE 课程ID = '数学' AND 成绩 < 60;四、论述题1. 论述大数据时代下,数据隐私保护的重要性及其挑战。
答:在大数据时代,数据隐私保护变得尤为重要。
数据隐私保护不仅关系到个人权益,也是企业社会责任的体现。
随着数据量的激增,数据泄露的风险也随之增大,这给数据隐私保护带来了新的挑战。
企业需要采取更先进的技术和管理措施来保护用户数据,同时,法律法规也需要不断更新以适应新的技术环境。
五、案例分析题1. 某电商平台希望通过数据分析提升用户体验。
请分析可能的数据分析方向,并提出具体的分析方法。