《经济预测与决策》实验报告
- 格式:doc
- 大小:376.00 KB
- 文档页数:14

企业预测与决策实训报告一、引言随着市场竞争的日益激烈,企业面临着各种各样的挑战与风险。
为了在这个竞争激烈的环境中保持竞争优势,企业需要准确地预测未来的趋势,并做出相应的决策。
本次实训旨在通过对企业数据的分析和模型建立,为企业提供科学的决策依据。
二、数据分析在实训中,我们首先对企业的历史数据进行了分析。
我们通过统计分析的方法,了解了企业销售额、利润、成本等指标的变化趋势,并进行了可视化展示。
通过对数据的分析,我们了解到企业销售额在过去几个季度逐渐下降,但利润仍有保持稳定的趋势。
这意味着企业在管理成本方面还存在一定的问题。
三、预测模型建立为了进一步预测未来的趋势并做出合理的决策,我们建立了一套预测模型。
我们选择了时间序列分析中的ARIMA模型作为预测模型。
通过对历史数据进行拟合,并使用相关统计指标对模型的拟合效果进行评估,我们得到了一个较为准确的预测模型。
四、未来趋势预测基于我们建立的模型,我们对未来的销售额进行了预测。
根据预测结果,我们发现未来几个季度的销售额仍有下降的趋势。
这表明企业需要采取措施来提升销售额,以保持竞争力和利润。
五、决策建议基于我们对数据的分析和预测结果,我们给出了以下几点决策建议:1. 加大市场推广力度:通过增加市场推广投入,扩大企业知名度,提高产品销售额。
2. 优化产品定价策略:根据市场需求和竞争情况,合理定价以提高销售额和利润。
3. 优化供应链管理:通过优化供应链管理,减少成本,提高盈利能力。
4. 加强人力资源培养:提高员工的专业素质和服务水平,为企业发展提供人才支持。
六、总结通过本次实训,我们充分认识到企业预测与决策的重要性。
通过对历史数据的分析和模型的建立,我们能够更加准确地预测未来的趋势,并做出科学合理的决策。
我们的决策建议将帮助企业更好地应对竞争和风险,保持竞争优势,并实现可持续发展。


经济预测与决策仿真实验报告一、实验背景在当今复杂多变的经济环境中,准确的经济预测和明智的决策对于企业、政府和个人都至关重要。
经济预测能够帮助我们提前洞察市场趋势,把握机遇,规避风险;而决策则是基于预测结果,选择最优的行动方案,以实现既定的目标。
为了深入理解和掌握经济预测与决策的方法和技巧,我们进行了本次仿真实验。
二、实验目的本次实验的主要目的是:1、熟悉并运用常见的经济预测方法,如时间序列分析、回归分析等,对经济数据进行预测。
2、通过建立决策模型,综合考虑各种因素,制定最优的经济决策方案。
3、培养对经济数据的敏感度和分析能力,提高解决实际经济问题的能力。
三、实验数据与方法(一)实验数据我们选取了某地区过去五年的经济数据,包括 GDP 增长率、物价指数、失业率、进出口贸易额等指标。
这些数据来源于政府统计部门和相关的经济研究报告。
(二)实验方法1、时间序列分析使用移动平均法和指数平滑法对 GDP 增长率进行预测,观察其短期和中期的趋势变化。
2、回归分析建立多元线性回归模型,以物价指数、失业率等作为自变量,GDP 增长率作为因变量,分析各因素对经济增长的影响。
3、决策树分析构建决策树模型,针对企业的投资决策问题,考虑市场需求、竞争状况、成本等因素,确定最优的投资方案。
四、实验过程与结果(一)时间序列分析1、移动平均法分别计算了 3 期和 5 期移动平均值,并绘制出趋势线。
结果显示,3 期移动平均对短期波动的反应较为灵敏,但中期趋势不够平滑;5 期移动平均则在平滑中期趋势方面表现较好,但对短期变化的捕捉相对滞后。
2、指数平滑法通过调整平滑系数α的值,进行多次预测。
当α取值较大时,预测结果对近期数据的权重较大,能够更快地反映最新的变化;当α取值较小时,预测结果更趋于稳定,但对短期变化的响应较慢。
(二)回归分析经过数据处理和模型拟合,得到回归方程如下:GDP 增长率= 05×物价指数 02×失业率+ 03×进出口贸易额+常量通过对回归系数的分析,发现物价指数对GDP 增长率有正向影响,失业率有负向影响,进出口贸易额也有正向影响。

一、实习背景随着我国经济的快速发展,经济决策在企业管理、政策制定等方面扮演着越来越重要的角色。
为了更好地培养具备实际操作能力和决策思维的人才,我国高校积极开展经济决策仿真实验。
本次实习,我有幸参加了由我国某知名高校举办的宏微观经济学决策仿真实验,通过实际操作和数据分析,提升了自己的经济决策能力。
二、实习目的1. 理解宏微观经济学基本理论,为实际经济决策奠定理论基础。
2. 掌握经济决策仿真实验的基本方法,提高实际操作能力。
3. 培养团队协作精神,提高沟通协调能力。
4. 了解当前经济形势,提高对我国经济政策的认识。
三、实习内容1. 宏微观经济学基本理论学习在实习过程中,我们首先学习了宏微观经济学的基本理论,包括供求理论、生产理论、市场结构、宏观经济政策等。
通过学习,我们对经济学的基本概念、原理和方法有了更深入的了解。
2. 经济决策仿真实验操作本次实习主要采用某知名经济决策仿真实验平台,通过模拟真实经济环境,让我们在实际操作中锻炼决策能力。
实验内容包括:(1)产品供给与需求数字化决策实验:通过调整价格、产量等参数,观察市场供求关系变化,掌握价格与产量之间的关系。
(2)不同市场结构下厂商最优智能生产行为实验:分析不同市场结构下厂商的生产成本、收益和利润,寻找最优生产策略。
(3)市场失灵及厂商数字博弈实验:模拟市场失灵情况,分析厂商在非完全竞争市场中的竞争策略。
(4)宏观经济指标智能统计及一般均衡实验:运用统计学方法,分析宏观经济指标变化,预测经济走势。
(5)经济周期及经济增长的数字化模拟实验:模拟经济周期波动,分析经济增长的驱动因素。
(6)财政政策和货币政策工具应用实验:分析财政政策和货币政策对经济的影响,掌握政策调控手段。
3. 团队协作与沟通在实习过程中,我们分为若干小组进行实验操作。
在实验过程中,我们积极交流、分享经验,共同解决问题。
通过团队协作,我们提高了沟通协调能力,培养了团队精神。
四、实习成果1. 理论知识方面:通过实习,我对宏微观经济学的基本理论有了更深入的理解,为今后的经济决策提供了理论支持。

实验报告实验名称:预测与决策技术应用课程实验指导教师:实验日期:实验地点:班级:学号:姓名:实验成绩:实验1 德尔菲预测法【实验题目】某公司为实现某个目标,初步选定了a,b,c,d,e,f 六个工程,由于实际情况的限制,需要从六项中选三项。
为慎重起见,公司共聘请了100位公司内外的专家,请他们选出他们认为最重要的三项工程,并对这三项工程进行排序,专家的意见统计结果如下表。
如果你是最后的决策者,请根据专家给出的意见,做出最合理的决定。
专家意见表排序 1 2 3 a 30 10 20 b 10 10 40 c 16 10 20 d 10 15 0 e 14 46 10 f 20 9 10【实验环境】• Excel【实验目的】• 掌握利用德尔菲法进行定性预测的方法 【实验步骤及结果】本实验中,要求选择3个项目进行排序,则可以按每位专家是同等的预测能力来看待,并规定其专家评选的排在第1位的项目给3分,第2位的项目给2分,第3位的项目给1分,没选上的其余项目给0分。
在本实验中,1T =3分,2T =2分,3T =1分。
上表中,对征询表作出回答的专家人数N=100人:赞成a 项排第1位的专家有30人(即a,1N =30),赞成a 项排第2位的专家有10人(a,2N =10),赞成a 排第3位的有20人(a,3N =20)。
所以,a 项目的总得分为:3*30+2*10+1*20=130分。
同理可以分别计算出:b 项目的总得分为:3*10+2*10+1*40=90分;c 项目的总得分为:3*16+2*10+1*20=88分;d 项目的总得分为:3*10+2*15+1*0=60分;e 项目的总得分为:3*14+2*46+1*10=144分;f 项目的总得分为:3*20+2*9+1*10=88分。
由此,绘制下表。
并从总分按高到低排序,得到前三个项目是e、a、b。
专家意见表排序第1位第2位第3位得分\分排序分值\分 3 2 1工程a 30 10 20 130 2b 10 10 40 90 3c 16 10 20 88 4d 10 15 0 60 6e 14 46 10 144 1f 20 9 10 88 4该方法用统计方法综合专家们的意见,定量表示预测结果。

学生实验报告实验课程名称经济预测与决策上机实验报告开课实验室学院年级专业班学生姓名学号开课时间至学年第学期经济预测与决策实验报告实验一实验名称:一元线性回归预测上机实验。
实验目的:通过实验掌握一元线性回归预测的数学模型、参数估计方法、误差分析和检验,掌握一元线性回归的点预测和区间预测。
实验内容:1.对下表所给数据,用Excel直接计算一元线性回归模型的参数估计、可决系数、相关系数、标准差、F统计量和斜率系数的t统计量。
2.分析模型的优劣,α=0.05,作F检验和t检验3.若2011年月人均可支配收入x0=5000元,预测该商品的销售量,并给出置信度为95%的区间预测。
4.用Excel中的数据分析直接进行回归,写出问题1中的参数和指标,对α=0.10,作F检验和t检验写出实验报告:1、用Excel直接计算,得:R^2和r都很小,模型较差。
⑵当α=0.05,作F检验和t检验F统计量=3.934182154<4.6,故方程不显著;t统计量=1.983477288<2.15,故方程不显著。
⑶若2011年月人均可支配收入x0=5000元,该商品的销售量为7427.06288,并给出置信度为95%的预测区间为【5688.49337,9165.63239】当α=0.10,作F检验和t检验:F统计量=3.934182154>3.10,故方程显著;t统计量=1.983477288>1.76,故方程显著。
经济预测与决策实验报告实验二实验名称:多元线性回归预测上机实验。
实验目的:通过实验掌握多元线性回归预测的数学模型、参数估计方法、误差分析和检验,掌握多元线性回归的点预测和区间预测。
实验内容:1.对下表所给数据,用Excel中的数据分析直接进行回归。
2.写出该二元线性回归模型。
3.写出可决系数、相关系数、标准差,简单判别该预测模型的优劣。
4.写出F统计量和斜率系数的t统计量,α=0.10,作F检验和t检验。

一、实习背景随着我国经济的快速发展,经济决策在企业发展中扮演着越来越重要的角色。
为了更好地了解经济决策的过程和方法,提高自己的实际操作能力,我在实习期间选择了经济决策方向,为期一个月。
二、实习内容1. 实习单位简介实习单位是一家知名的企业,主要从事生产、销售、研发和售后服务。
公司业务范围广泛,涉及多个行业,具有丰富的市场经验和强大的研发实力。
2. 实习岗位及职责我在实习期间担任经济决策助理,主要负责以下工作:(1)收集和整理市场信息,分析行业发展趋势,为决策层提供参考依据;(2)协助部门负责人制定年度经营计划和预算;(3)跟踪项目进度,分析项目风险,提出风险应对措施;(4)参与项目评估,提出项目建议书,为决策层提供决策支持。
3. 实习过程(1)市场调研与行业分析在实习期间,我深入了解了公司所属行业的市场状况,包括竞争对手、市场份额、行业政策等。
通过对市场信息的收集和分析,为决策层提供了有针对性的建议。
(2)经营计划与预算编制在部门负责人的指导下,我参与了公司年度经营计划和预算的编制工作。
通过分析历史数据和行业趋势,制定出合理的经营目标和预算方案。
(3)项目评估与建议在实习期间,我参与了多个项目的评估工作。
通过对项目可行性、风险、收益等方面的分析,提出了项目建议书,为决策层提供了决策支持。
三、实习收获1. 提升了经济决策能力:通过实习,我掌握了经济决策的基本流程和方法,提高了自己的经济决策能力。
2. 增强了团队合作意识:在实习过程中,我学会了与团队成员沟通、协作,共同完成工作任务。
3. 拓宽了知识面:实习期间,我了解了多个行业的发展趋势和市场需求,拓宽了自己的知识面。
4. 提高了实际操作能力:通过实习,我将所学知识运用到实际工作中,提高了自己的实际操作能力。
四、总结通过本次经济决策实习,我对经济决策有了更深入的了解,提高了自己的实际操作能力。
在今后的工作中,我将继续努力学习,为我国经济发展贡献自己的力量。

《经济预测与决策》期末考试玉溪师范学院理学院数学系学生课题调查分析报告课题:关于玉溪师范学院大学生网络使用状况及影响情况调查报告学院:理学院组长:***(20100111**)组员:***(20100111**)***(20100111**)***(20100111**)***(20100111**)***(20100111**)班级:10数学一班立项时间:2012年11月23日目录一、封面 (1)二、目录 (2)三、课题研究基本材料 (3)四、调查小组成员基本情况介绍 (4)五、小组分工与合作 (5)六、小组合作完成记录 (6)七、问卷调查样本 (7)八、问卷调查分析总结报告 (8)九、大学生上网现状概述 (10)十、大学生网络使用情况 (14)十一、大学生使用网络的影响分析 (17)十二、大学生网络管理、教育和使用建议 (24)十三、课题总结报告 (28)玉溪师范学院非标准试卷评卷表一、课题研究基本材料院(系):数学系2012 —2013 学年第一学期一.课程信息课程名称经济预测与决策任课教师杨亚非课题关于玉溪师范学院大学生网络使用状况及影响情况调查报告考试方式□设计□论文□调研报告□分析报告□实验报告□其他二.学生信息姓名学号专业职务联系电话*** 20100111** 数学与应用数学组长******* 20100111** 数学与应用数学调查员******* 20100111** 数学与应用数学分析员******* 20100111** 数学与应用数学统计员******* 20100111** 数学与应用数学整理员****三.评语(根据评定标准,结合学生的论文、设计、报告等,写出评语)成绩评定课程名称经济预测与决策概论课程类型公共必修课组织人*** 性别女职务组长学校玉溪师范学院专业数学与应用数学研究方向预测与决策联系电话****目前,大学校园先后开设了校园网络以方便大学生的学习和生活。

经济预测与决策德尔菲法应用案例某公司研制出一种新兴产品〜现在市场上还没有相似产品出现〜因此没有历史数据可以获得。
公司需要对可能的销售量做出预测〜以决定产量。
于是〜该公司成立专家小组〜并聘请业务经理、市场专家和销售人员等8位专家〜预测全年可能的销售量。
8 位专家提出个人判断〜经过三次反馈得到结果〜如下表所示。
专家第一次判断第二次判断第三次判断编号最低最可最高最最可最高最最可最高销售能销售低能销低能销售量销售量销销售售量销销售量 1 500 750 900 600 750 900 550 750 900 量售量售量2 200 450 600 300 500 650 400 500 650 量量3 400 600 800 500 700 800 500 700 8004 750 900 1500 600 750 1500 500 600 12505 100 200 350 220 400 500 300 500 600专家第一次判断第二次判断第三次判断编号最低最可最高最低最可最高最低最可最高销售能销售销售能销销能销售6 300 500 750 300 500 750 300 600 750 量销售量量销售售量售量销7 250 300 400 250 400 500 400 500 600 量量量8 260 300 500 350 400 600 370 410 610平均345 500 725 390 550 775 415 570 770 数解答: 在预测时〜最终一次判断是综合前几次的反馈做出的〜因此〜在预测时一般以最后一次判断为主。
如果按照8 位专家第三次判断的平均值计算〜则预测这个新产品的平均销售量为:415570770,,,585() 千件3 加权平均预测:将最可能销售量、最低销售量和最高销售量分别按0.50 、0.20 和0.30 的概率加权平均〜则预测平均销售量为:5700.504150.207700.30599() ,,,,,, 千件中位数预测: 用中位数计算〜可将第三次判断按预测值高低排列如下:最低销售量:300 370 400 500 550最可能销售量:410 500 600 700 750最高销售量:600 610 650 750 800 900 1250中间项的计算公式为:n1,(n), 项数2最低销售量的中位数为第三项〜即400。
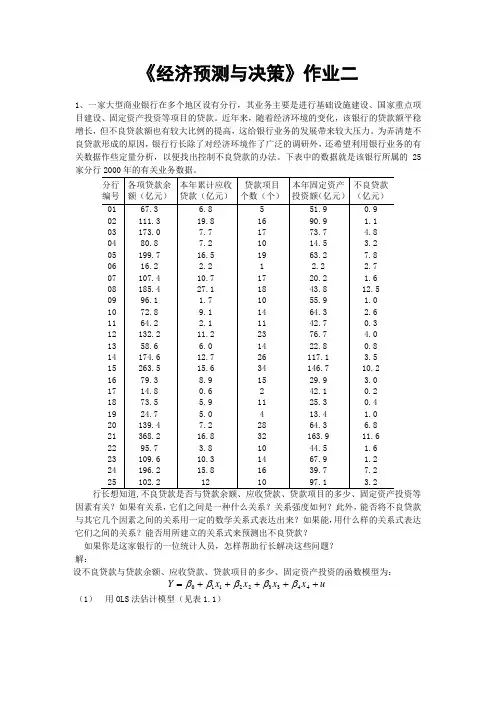
《经济预测与决策》作业二1、一家大型商业银行在多个地区设有分行,其业务主要是进行基础设施建设、国家重点项目建设、固定资产投资等项目的贷款。
近年来,随着经济环境的变化,该银行的贷款额平稳增长,但不良贷款额也有较大比例的提高,这给银行业务的发展带来较大压力。
为弄清楚不良贷款形成的原因,银行行长除了对经济环境作了广泛的调研外,还希望利用银行业务的有关数据作些定量分析,以便找出控制不良贷款的办法。
下表中的数据就是该银行所属的25家分行2000年的有关业务数据。
分行编号 各项贷款余额(亿元) 本年累计应收 贷款(亿元) 贷款项目 个数(个) 本年固定资产投资额(亿元) 不良贷款 (亿元)01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 67.3 111.3 173.0 80.8 199.7 16.2 107.4 185.4 96.1 72.8 64.2 132.2 58.6 174.6 263.5 79.3 14.8 73.5 24.7 139.4 368.2 95.7 109.6 196.2 102.2 6.8 19.8 7.7 7.2 16.5 2.2 10.7 27.1 1.7 9.1 2.1 11.2 6.0 12.7 15.6 8.9 0.6 5.9 5.0 7.2 16.8 3.8 10.3 15.8 12 5 16 17 10 19 1 17 18 10 14 11 23 14 26 34 15 2 11 4 28 32 10 14 16 10 51.9 90.9 73.7 14.5 63.2 2.2 20.2 43.8 55.9 64.3 42.7 76.7 22.8 117.1 146.7 29.9 42.1 25.3 13.4 64.3 163.9 44.5 67.9 39.7 97.1 0.9 1.1 4.8 3.2 7.8 2.7 1.6 12.5 1.0 2.6 0.3 4.0 0.8 3.5 10.2 3.0 0.2 0.4 1.0 6.8 11.6 1.6 1.2 7.2 3.2行长想知道,不良贷款是否与贷款余额、应收贷款、贷款项目的多少、固定资产投资等因素有关?如果有关系,它们之间是一种什么关系?关系强度如何?此外,能否将不良贷款与其它几个因素之间的关系用一定的数学关系式表达出来?如果能,用什么样的关系式表达它们之间的关系?能否用所建立的关系式来预测出不良贷款?如果你是这家银行的一位统计人员,怎样帮助行长解决这些问题? 解:设不良贷款与贷款余额、应收贷款、贷款项目的多少、固定资产投资的函数模型为:u x x x x Y +++++=443322110βββββ (1) 用OLS 法估计模型(见表1.1)SUMMARY OUTPUT回归统计Multiple R 0.890225 R Square 0.792501 Adjusted R Square 0.748817 标准误差 1.823038 观测值 24 方差分析df SS MSFSignificance F回归分析 4 241.1737 60.29342 18.14171 2.77033E-06 残差 19 63.14591 3.323469 总计 23 304.3196Coeffi cients 标准 误差 t StatP-valueLower 95%Upper 95%Intercept -0.9769 0.832391 -1.17361 0.255054 -2.719115908 0.765312 67.3 0.040107 0.010699 3.748725 0.001360.0177140250.06256.8 0.148507 0.080791 1.838166 0.081725 -0.020590104 0.317603 5 0.00942 0.088843 0.106032 0.916669 -0.176529738 0.19537 51.9-0.02859 0.015736-1.81697 0.08503-0.061529223 0.004344(表1.1)=Yˆ-0.9769+0.040107x1+0.148507x2+0.00942x3-0.02859x4 (-1.1736) (3.7487) (1.8381) (0.1060) (-1.8169)=2R 0.7925, =2R 0.7488, F=18.1417可见,2R 比较大,而且F=18.1417> ,故认为不良贷款与上述解释变量总体线性关系显著。

南京工业大学经济与管理学院经济预测与决策方法分析实验报告2014年11月15日关于我国城镇居民可支配收入预测方法的选择与分析摘要 (3)一经济预测的概述及作用 (3)1.1 经济预测的概述 (3)1.2 经济预测的作用 (3)二预测的分类和程序 (3)2.1 预测的分类 (3)2.2 预测的程序 (4)三预测模型的设立 (5)3.1模型 (5)3.2 应用 (6)四结论 (11)摘要本文通过对我国2001-2010年城镇居民可支配收入情况的分析,分别利用经济预测中的二次指数平滑法和二次移动平均法,对之后年份居民可支配收入进行预测,学习了解在预测过程中需要注意的相关情况,对不同的预测方法进行分析对比,找出符合实际的预测方法进行科学预测;对于一个经济预测问题, 不同预测模型揭示的经济信息会有所不同。
关键词:可支配收入二次指数平滑法二次移动平均法一经济预测的概述及作用1.1 经济预测的概述经济预测,是指以准确的点差统计资料和经济信息为依据,从经济现象的历史、现状和规律性出发,运用科学的方法,对经济现象未来发展前景的测定。
1.2 经济预测的作用(1)经济预测是经济决策科学化的工具(2)经济预测是编制计划、预见计划执行情况,加强国家计划指导的依据。
(3)经济预测是企业改善经营管理的手段(4)经济预测可以推动统计工作的发展二预测的分类和程序2.1 预测的分类(1)按预测设计的范围不同,可分为宏观经济预测和微观经济预测;(2)按预测的时间长短不同,可分为长期经济预测、中期经济预测、短期经济预测和近期经济预测;(3)按预测方法的性质不同,可分为定性经济预测和定量经济预测;(4)按经济的时态不同,可分为静态经济预测和动态经济预测。
2.2 预测的程序2.2.1 确定预测目的,制定预测计划这是经济预测首先要解决的问题。
确定预测目的,就是从决策与管理的需要出发,紧密联系实际需要与可能,确定预测要解决的问题。
预测计划是根据预测目的制定的预测方案,包括预测的内容、项目、预测所需要的资料,准备选用的预测方法,预测的进程和完成时间,编制预测的预算,调配力量,组织实施等。
经济预测模型实验报告一、引言经济的不确定性是市场中的一个重要特征,针对这种不确定性,经济学家们一直致力于发展各种经济预测模型,希望通过分析数据和趋势来预测未来的经济走势。
本实验旨在通过建立一个经济预测模型来分析特定经济指标,并根据模型的结果进行未来趋势的预测。
二、实验方法1. 数据收集:首先,我们收集了过去几年的经济数据,包括GDP增长率、通货膨胀率、失业率等指标。
2. 模型建立:接着,我们选择了适合这些经济指标的经济预测模型,并进行了参数的估计和模型的拟合。
3. 模型评估:在模型建立完成后,我们对模型进行了评估,包括残差分析、预测误差分析等。
4. 未来预测:最后,我们利用建立的模型对未来几年的经济走势进行了预测。
三、实验结果我们建立的经济预测模型表现出较高的拟合度,并且在历史数据上的预测准确率也较高。
根据我们的模型,未来几年的GDP增长率将保持稳定增长,通货膨胀率可能会略有波动,失业率也将保持在一个相对低水平。
四、实验结论通过这次实验,我们验证了经济预测模型在分析和预测经济走势中的重要性。
经济预测模型可以帮助政府、企业等各方更好地制定经济政策和商业决策,降低不确定性带来的风险,推动经济的稳定和持续发展。
五、展望未来,我们将进一步完善经济预测模型,提高其预测准确性和实用性。
同时,我们也将尝试引入更多更全面的经济指标,以便更好地把握经济的全貌和发展趋势。
总结:本次经济预测模型实验为我们提供了一次难得的学习机会,我们通过实践掌握了建立和评估经济预测模型的方法,对经济预测有了更深入的理解。
希望我们的实验结果对经济学领域的研究和实践有所帮助,为经济的稳定和可持续发展做出贡献。
经济预测和决策方法分析论文本论文旨在介绍经济预测和决策方法的重要性和背景,并提出论文的目的和结构。
经济预测和决策方法在现代经济学和企业管理中扮演着至关重要的角色。
在不确定的经济环境中,预测经济趋势和做出明智的决策是企业和政府机构取得成功的关键。
准确的经济预测可以帮助企业规划生产和销售策略,政府机构制定合理的政策措施。
而科学的决策方法则可以帮助决策者在多样化的选择中做出最优的决策。
本论文将首先介绍经济预测的基本概念和方法,并分析其在不同领域的应用。
其次,我们将探讨决策方法论的基本原理和技巧,并分析其在经济决策中的具体应用。
最后,我们将对现有的经济预测和决策方法进行综合评估,并提出一些改进和发展的建议。
通过对经济预测和决策方法的分析和研究,本论文旨在为企业管理者、政府机构和经济学研究人员提供有益的指导和启示,帮助他们更好地应对经济环境的挑战并做出明智的决策。
同时,本论文也希望能够促进对经济预测和决策方法的进一步研究,推动其方法的改进和应用的拓展。
希望通过本论文的研究,能够提高经济预测和决策的准确性和效果,为经济发展和管理提供更为科学的支持。
接下来的章节将依次介绍经济预测的基本方法、决策方法论的原理和技巧,并分析其在实际中的应用。
最后,本论文将对目前的经济预测和决策方法进行评估,并提出改进和发展的建议。
希望通过这些内容的阐述,读者能够加深对经济预测和决策的理解,并从中获得有益的启示。
注:以上内容仅为提纲,请在各章节中扩写具体内容。
本论文旨在介绍不同的经济预测方法,并讨论它们的优点和局限性。
以下是几种常见的经济预测方法:时间序列分析:时间序列分析是一种常用的经济预测方法,它基于历史数据分析未来的趋势和模式。
通过观察历史数据的变化,我们可以识别出周期性、趋势性和季节性的模式,并进行预测。
时间序列分析的优点在于它能够捕捉到历史数据中的关键特征,并用于预测未来的趋势。
然而,它的局限性在于对未来可能出现的突发事件或外部因素进行预测比较困难。
经济预测与决策论文引言经济预测与决策是现代经济学的重要研究领域之一。
通过预测未来的经济发展趋势和制定相应的决策策略,可以帮助政府、企业和个人做出更明智的决策,提高经济效益和社会福利。
本论文将探讨经济预测与决策的相关理论和方法,并以实证研究为基础,验证其实际应用的有效性。
经济预测的意义经济预测对于各个经济主体具有重要意义。
首先,对于政府来说,经济预测有助于制定长期和短期的经济政策。
政府可以通过预测经济增长、通胀率、失业率等指标,为未来的政策制定提供参考依据。
其次,对于企业来说,经济预测有助于制定市场营销和生产计划。
通过对需求、供应、价格等因素进行预测,企业可以制定合理的生产和销售策略,以最大限度地满足市场需求。
最后,对于个人来说,经济预测有助于个人财务规划和投资决策。
通过对收入、支出、通胀率等因素进行预测,个人可以合理规划自己的财务安排和投资组合,实现财务目标。
经济预测的方法经济预测的方法主要包括定性和定量两种。
定性预测主要通过专家判断、民意调查等方式进行,主观因素较多,其结果往往具有较大的不确定性。
而定量预测主要通过统计模型、时间序列分析等方式进行,对经济数据进行量化分析,结果更加客观和可靠。
在定量预测方法中,常用的包括回归分析、VAR 模型、ARIMA模型等。
这些方法在不同的经济预测问题中具有各自的优势和适用范围。
决策与风险管理经济决策涉及到风险管理的问题。
在经济不确定性的背景下,决策者需要考虑到风险和回报之间的权衡,以最大化利润或效益。
为此,需要运用决策论的相关理论和方法。
决策论主要包括风险偏好、风险评估、决策准则等内容。
通过运用决策论的方法,可以帮助决策者在面对不确定性和风险时做出最佳的决策。
实证研究:经济预测与决策的案例分析为了验证经济预测与决策的有效性,本论文将以某国家的经济预测与决策为案例进行分析。
首先,我们将收集该国过去的经济数据,并通过时间序列分析等方法预测未来的经济发展趋势。
接着,我们将制定相应的经济政策和决策策略,以应对未来可能出现的经济变化。
经济决策实习报告一、实习背景与目的随着我国经济的快速发展,市场竞争日趋激烈,企业面临的决策问题也日益复杂。
为了提高自己的实践能力和决策分析能力,我选择了经济决策实习,以便更好地将理论知识与实际工作相结合。
本次实习在XX有限公司进行,实习期间,我参与了公司的一系列经济决策活动,对企业的运营管理和决策过程有了更深入的了解。
二、实习内容与过程1. 市场调研在实习过程中,我参与了公司对新产品的市场调研。
通过查阅相关资料、收集数据和分析市场趋势,我们得出了新产品市场的潜在需求、竞争态势和市场规模等关键信息。
这些信息为后续的产品定价、市场营销策略和投资决策提供了重要依据。
2. 财务分析我参与了公司某一项目的财务分析。
通过对项目的投资成本、预期收益、现金流量和风险评估等进行详细计算和分析,我们得出了该项目是否值得投资的意见。
此外,我还学习了如何利用财务指标评价公司的经营状况和盈利能力。
3. 定价策略在实习过程中,我参与了公司产品的定价策略制定。
我们根据市场需求、成本结构和竞争对手定价等因素,采用成本加成法、市场需求定价法和竞争导向定价法等方法,制定了合理的产品价格。
同时,我还学会了如何根据市场变化和公司战略调整定价策略。
4. 投资决策我参与了公司一项投资项目的决策讨论。
在项目评估阶段,我们进行了项目可行性研究,包括市场前景分析、技术可行性分析、财务可行性分析等。
根据评估结果,公司最终决定是否投资该项目。
这个过程让我深刻理解了投资决策的重要性和复杂性。
三、实习收获与反思1. 实践能力提高通过实习,我将所学理论知识应用于实际工作中,提高了自己的实践能力。
我学会了如何收集和分析市场数据、如何进行财务分析、如何制定定价策略和投资决策等。
这些经验对我今后的工作具有很大的指导意义。
2. 团队协作能力增强在实习过程中,我与同事们共同承担工作任务,学会了沟通协调、合作共赢。
我认识到,团队协作是企业成功的关键,只有团结一致,才能克服困难,实现企业目标。
预测与决策上机实验报告学院:经济与管理学院学号:***********姓名:***实验一:移动平均法一、实验目的Part A:一次移动平均法1熟悉数据文件的建立;2熟悉时间序列数据散点图的绘制及其一次移动平均法适用条件的判断;3熟悉应用一次移动平均法进行相应预测;4熟悉一次移动平均法预测精度的分析及其最优移动步长N的确定。
Part B:二次移动平均法1根据时间序列数据散点图,熟悉二次移动平均法适用条件的判断;2熟悉应用二次移动平均法进行相应预测;3熟悉二次移动平均法预测精度的分析及其最优移动步长N的确定;。
二、实验内容及实验过程Part A问题描述:某汽油批发商在过去12周的汽油销售量统计数据如表1所示。
油销售量。
(2)取移动步长N=3,采用一次移动平均法进行预测,并分析其预测精度。
(3)如何选择合适的移动步长,使预测精度较高?实验过程:步骤1:新建Excel文档,输入本问题数据。
步骤2:绘制散点图。
点击Excel【插入】菜单下的【图表】子菜单。
在“图表类型”栏选择“XY散点图”,点击[下一步]按钮。
步骤3:选择预测模型。
从该汽油批发商在过去12周汽油销售量散点图可以看出,汽油销售量基本在20千加仑上下波动,无长期变化趋势,无季节影响,因而可以使用一次移动平均法进行相应预测。
步骤4:计算一次移动平均值和预测值。
方法1:公式法1)选择步长为3,在单元格“C4”中输入“=(B2+B3+B4)/3”或者插入函数AVERAGE,即“=AVERAGE(B2:B4)”,如图。
2)回车,并将单元格“C4”的内容复制到单元格区域“C5:C13”(选中单元格“C4”,按下Ctrl键,拖动鼠标至C13),并将单元格区域C4:C13的内容复制到D5:D14区域(在单元格D5,输入“= C4”,并将其内容复制到区域D6:D14),预测值结果如图。
方法2:一次移动平均预测模块法1)点击Excel【工具】菜单下面的子菜单【数据分析】,打开“数据分析”对话框,从“分析工具”列表中选择“移动平均”,如图,点击[确定]按钮。
实验一一元线性回归预测一、实验目的通过实验掌握一元线性回归预测的数学模型、参数估计方法、误差分析和检验,掌握一元线性回归的点预测和区间预测。
二、实验内容1.对下表所给数据,用Excel直接计算一元线性回归模型的参数估计、可决系数、标准差、t统计量。
2.分析模型的优劣,α=0.05,作他检验。
3.若2011年月人均可支配收入x0=5000元,预测该商品的销售量,并给出置信度为95%的区间预测。
1999 7690 86832000 8010 93172001 8550 96752002 8420 75422003 8600 70842004 8900 86122005 9260 9119三、实验步骤1.用excel做回归于测四、实验结果1.有上图可知,一元线性回归模型的参数估计a为5807.16,b为0.32、可决系数为0.219、标准差为808.64、t统计量为1.98.2.可决系数越大,回归方程就拟合得越好,相反越差,由题意知,可决系数较小,所以拟合得不好由查表得Fα=4.60,tα=2.15,又由上图可知,F检验:F=3.93< Fα=4.60,故回归方程不显著。
T检验:t=1.98 <tα=2.15,故回归方程不显著。
3.利用excel求出y的实测值和预测值之间的差,然后计算出残差平方和Q.yi-yi^ (yi-yi^)2-798.33782 637343.2748-237.41459 56365.68754-18.52737 343.2634391990.83947 981762.8553514.40536 264612.8744-394.8297 155890.492541.17505 292870.4347324.85847 105533.0255-1049.85621 1102198.062384.42911 147785.7406914.75519 836777.05761097.80545 1205176.806-993.07702 986201.9677-1509.3936 2278269.04-78.5879 6176.058026311.77894 97206.107439154512.747y=a+bx,a=5807.157,b=0.323981,当x=5000时,y=7427.063故,Q=9154512.747,再由公式σ2=Q/(n-2)易知,σ2=653893.7676σ=808.63698135,由P(y^-2δ<y<y^+2δ)=95%得,区间预测为(5809.788917,9044.336842)。
五、实验小结由此实验使我更加清楚如何利用excel处理一元回归预测的相关问题。
知道了怎样计算回归方程的显著性检验,和进行经济预测。
实验二多元线性回归预测一、实验目的通过实验掌握多元线性回归预测的数学模型、参数估计方法、误差分析和检验,掌握多元线性回归的点预测和区间预测。
二、实验内容1.对下表所给数据,用Excel中的数据分析直接进行回归。
2.写出该二元线性回归模型。
3.写出复可决系数、复相关系数、标准差,简单判别该预测模型的优劣。
4.写出F统计量和斜率系数的t统计量,α=0.10,作F检验和t检验。
5.若劳动量为25人工小时,木材耗用量为30m3,预测总成本,并给出置信度为95%的总成本的区间预测。
三、实验步骤1. 对下表所给数据,用Excel 中的数据分析直接进行回归。
2.由表得出b 0,b 1,b 2,回归方程为:y^= b 0+b 1x1+b 2x2.3.复相关系数公式:∑∑==∧∧--=ni ini iy yy y R 1212)()(复可决系数公式:∑∑==∧∧--=n i ini iy y y yR 1212)()(4.由公式F=(U/p)/(Q/(n-p-1)),iiy i i C S b t ∧=5.yi-y^(yi-y^)2-0.039019476 0.00152252 -0.11208865 0.012563865 -0.096709201 0.00935267 -0.100537273 0.010107743 0.148690396 0.022108834 0.064069846 0.004104945 0.135594359 0.01838583Q 0.078146407 (Sy)2 0.019536602 Sy0.14由公式SY=(Q/(n-p-1))0.5计算可以得区间估计(y0-2sy,yo+2sy)四、实验结果1.图1.2.由图1 易知, b0=-1.395634654b1=0.746138348b2=0.676964406故回归方程为y=-1.3956+0.7461x1+0.6770x23. 由图1易知复可决系数为0.720905689、复相关系数为0.849061652、标准差为0.139773394。
可决系数越大,回归方程就拟合得越好,相反越差,由题意知,可决系数较大,所以拟合得好。
4.由图1 易知,F =5.166036439 t1=1.478908596 ,t2=2.497437669F 检验:通过查表知,Fα(2,7-2-1)=6.94故 F < Fα,故回归方程不显著。
t检验:通过查表易知 tα=2.13t1< tα,故x1对y无显著影响,应该删除该因素。
t2 > tα,故x2对y有显著影响,。
5.Sy=0.14,又置信度为95%,故总成本的预测区间为(37.28675621,37.84675621)五、实验小结通过多元回归预测的相关实验,使我学会了利用excel计算多元回归方程的复可决系数、复相关系数、标准差,并简单判别该预测模型的优劣。
和如何查表计算F检验,t检验,以及求解预测区间。
实验三非线性回归预测一、实验目的通过实验掌握非线性回归预测的数学模型、参数估计方法、误差分析和检验,掌握非线性回归的点预测和区间预测。
二、实验内容:1.对下表所给数据,在Excel中作xy散点图,观察xy的数据适合哪几类曲线?2.根据表中的数据分别计算二次曲线模型和幂函数模型的参数,并并判断哪一个模型准确性更高。
3.若2011年的销售量为500千吨,预测当年的利润。
三、实验步骤1.在Excel中作xy散点图,观察xy的数据。
2.数学模式为幂函数形式为,y=ax b两边同时取对数,lg y=lg a+blg x可化非线性为线性回归问题求解,其回归方程为 y’=A+Bx’二次函数属多项式模式,其形式为,y=a0+a1x1+a2x2+…+a p x pR越大其模型准确性更高。
4.有方程y=ax b ,求出a、b后,将x=500代入方程求y。
或者,可化非线性为线性回归问题求解,其回归方程为y’=A+Bx’,然后利用该方程求解。
四、实验结果1.散点图如下,适合幂函数模型和二次函数模。
2. 幂函数模型如下,化为线性回归方程为,由图可知R12=0.9972二次函数模型如下,由图可知R22=0.9942R12> R22,所以幂函数模型的准确性更高。
4.由散点图可得公式 y=0.0294x1.7502,将x=500代入得y=1372.67故2011年利润为1372.67万元。
若不用散点图的公式进行计算,可y=ax b两边同时取对数,lg y=lg a+blg x,然后化非线性为线性回归问题求解,其回归方程为y’=A+Bx’。
x' y'1.477121 1.0791811.778151 1.4771211.954243 1.8450982.079181 2.0413932.130334 2.1760912.255273 2.3424232.322219 2.505152.40654 2.6532132.431364 2.6901962.477121 2.7323942.518514 2.8129132.537819 2.903092.591065 2.9595182.607455 2.9822712.6532133.041393其回归为,SUMMARY OUTPUT回归统计Multiple R 0.998606757 R Square 0.997215454 Adjusted RSquare0.997001258 标准误差0.032195623 观测值15 方差分析df SS MS F SignificanceF回归分析 1 4.825826009 4.825826 4655.625 5.35E-18 残差13 0.013475256 0.001037总计14 4.839301265Coefficients 标准误差t Stat P-value Lower 95% Uppe 95%Intercept -1.530967787 0.05844182 -26.1964 1.23E-12 -1.65722 -1.40 X Variable 1 1.730176297 0.025357204 68.23214 5.35E-18 1.675395 1.784所以有y= -1.530967787+ 1.730176297x因为x=500,所以x’= 2.69897,代入该方程得,y’= 3.138726所以 y= 1376.341298故有2011年利润为1376.341298万元。
五、实验小结通过该实验使我更加了解了散点图的使用,如何利用散点图进行可线性化的非线性回归预测。
实验五移动平均预测和指数平滑预测一、实验目的通过实验掌握移动平均预测、一次指数平滑预测和二次指数平滑预测的计算公式和预测方法。
二、实验内容1.在一个图中同时画出原始数据、一次指数平滑值、二次指数平滑值的折线图,观察数据的特征。
2.取不同的整数N=4和5和计算一次移动平均Mt,计算平均绝对误差,比较和评价哪一种方法预测的效果更好?3.取常数α=0.3,用二次指数平滑平均预测法预测未来3个月每月的yt。
三、实验步骤1.根据简单指数平滑公式,本月平滑值=a*上月实际值+(1-a)*上月预测值,在这里取a=0.3,然后根据题意作图。
2. 根据公式预测值=(y n+y n-1+…+y n-N+1)/N ,计算出滑动平均预测值,然后再根据公式平均绝对误差=Q/n ,计算出所有的平均绝对误差,然后比较,较小的那一个方法更有效。
3. 二次预测=a*上月预测+(1-a)*上月预测的预测,预测公式y t(T)=[2+aT/(1-a)]*上月预测值 - [1+aT/(1-a)]*上月预测的预测。
四、实验结果1.2.N=4,平均绝对误差较小,所以效果更好。
3. 得到未来三个月每月的y t 分别为36.67 37.93 39.20五、实验小结掌握如何利用excel求数据的一次指数平滑预测和二次指数平滑预测,和当N取不同值是如何比较哪种方法预测的效果更好。