第七章--图的深度优先遍历
- 格式:ppt
- 大小:1.27 MB
- 文档页数:9

深度优先遍历的算法深度优先遍历(Depth-First Search,DFS)是一种用来遍历或树或图的算法。
它以一个起始节点开始,沿着路径尽可能深地,直到到达最深处或无法继续为止,然后回溯到上一个节点,继续其他路径。
DFS通过栈来实现,每次访问一个节点时,将其标记为已访问,并将其相邻的未访问节点压入栈中。
然后从栈中弹出节点,重复这个过程,直到栈为空为止。
1.创建一个栈,用来存储待访问的节点。
2.将起始节点标记为已访问,并将其压入栈中。
3.当栈不为空时,执行以下步骤:-弹出栈顶节点,并输出该节点的值。
-将该节点的未访问的相邻节点标记为已访问,并将其压入栈中。
4.重复步骤3,直到栈为空为止。
-深度优先遍历是一种先序遍历,即先访问节点本身,然后访问其子节点。
-深度优先遍历可以用来求解连通图、查找路径等问题。
-深度优先遍历的时间复杂度为O(V+E),其中V为节点数,E为边数。
1.求解连通图:深度优先遍历可以用来判断一个图是否连通,即从一个节点是否能够访问到所有其他节点。
2.查找路径:深度优先遍历可以找到两个节点之间的路径。
当遇到目标节点时,即可停止遍历,返回路径结果。
3.拓扑排序:深度优先遍历可以进行拓扑排序,即将有依赖关系的任务按一定的顺序排列。
深度优先遍历的实现可以通过递归或迭代方式来完成。
递归方式更加简洁,但在处理大规模图时可能导致栈溢出。
迭代方式则可以采用栈来避免栈溢出问题。
无论是递归方式还是迭代方式,其核心思想都是通过访问节点的相邻节点来进行深入,直至遍历完整个图或树的节点。
总而言之,深度优先遍历是一种常用的图遍历算法,它以一种深入优先的方式遍历路径。
在实际应用中,深度优先遍历可以用来求解连通图、查找路径和拓扑排序等问题,是图算法中的重要工具之一。
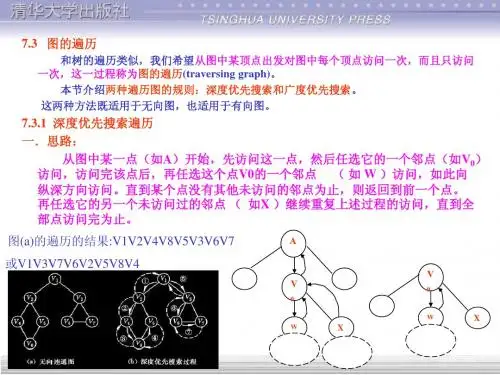

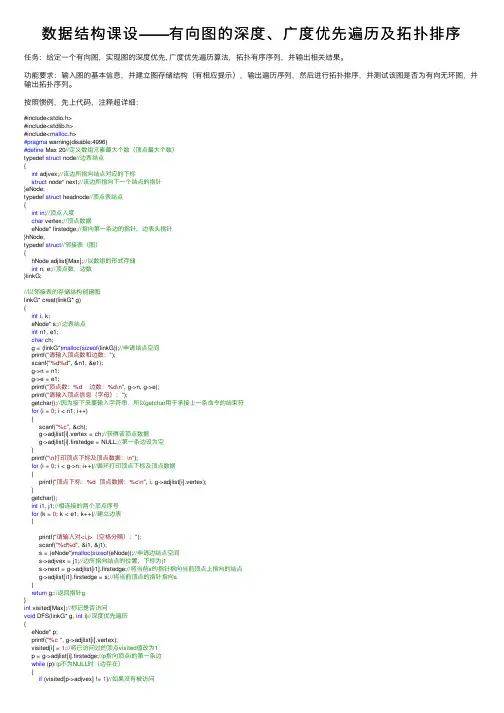
数据结构课设——有向图的深度、⼴度优先遍历及拓扑排序任务:给定⼀个有向图,实现图的深度优先, ⼴度优先遍历算法,拓扑有序序列,并输出相关结果。
功能要求:输⼊图的基本信息,并建⽴图存储结构(有相应提⽰),输出遍历序列,然后进⾏拓扑排序,并测试该图是否为有向⽆环图,并输出拓扑序列。
按照惯例,先上代码,注释超详细:#include<stdio.h>#include<stdlib.h>#include<malloc.h>#pragma warning(disable:4996)#define Max 20//定义数组元素最⼤个数(顶点最⼤个数)typedef struct node//边表结点{int adjvex;//该边所指向结点对应的下标struct node* next;//该边所指向下⼀个结点的指针}eNode;typedef struct headnode//顶点表结点{int in;//顶点⼊度char vertex;//顶点数据eNode* firstedge;//指向第⼀条边的指针,边表头指针}hNode;typedef struct//邻接表(图){hNode adjlist[Max];//以数组的形式存储int n, e;//顶点数,边数}linkG;//以邻接表的存储结构创建图linkG* creat(linkG* g){int i, k;eNode* s;//边表结点int n1, e1;char ch;g = (linkG*)malloc(sizeof(linkG));//申请结点空间printf("请输⼊顶点数和边数:");scanf("%d%d", &n1, &e1);g->n = n1;g->e = e1;printf("顶点数:%d 边数:%d\n", g->n, g->e);printf("请输⼊顶点信息(字母):");getchar();//因为接下来要输⼊字符串,所以getchar⽤于承接上⼀条命令的结束符for (i = 0; i < n1; i++){scanf("%c", &ch);g->adjlist[i].vertex = ch;//获得该顶点数据g->adjlist[i].firstedge = NULL;//第⼀条边设为空}printf("\n打印顶点下标及顶点数据:\n");for (i = 0; i < g->n; i++)//循环打印顶点下标及顶点数据{printf("顶点下标:%d 顶点数据:%c\n", i, g->adjlist[i].vertex);}getchar();int i1, j1;//相连接的两个顶点序号for (k = 0; k < e1; k++)//建⽴边表{printf("请输⼊对<i,j>(空格分隔):");scanf("%d%d", &i1, &j1);s = (eNode*)malloc(sizeof(eNode));//申请边结点空间s->adjvex = j1;//边所指向结点的位置,下标为j1s->next = g->adjlist[i1].firstedge;//将当前s的指针指向当前顶点上指向的结点g->adjlist[i1].firstedge = s;//将当前顶点的指针指向s}return g;//返回指针g}int visited[Max];//标记是否访问void DFS(linkG* g, int i)//深度优先遍历{eNode* p;printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已访问过的顶点visited值改为1p = g->adjlist[i].firstedge;//p指向顶点i的第⼀条边while (p)//p不为NULL时(边存在){if (visited[p->adjvex] != 1)//如果没有被访问DFS(g, p->adjvex);//递归}p = p->next;//p指向下⼀个结点}}void DFSTravel(linkG* g)//遍历⾮连通图{int i;printf("深度优先遍历;\n");//printf("%d\n",g->n);for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问{DFS(g, i);//调⽤DFS函数}}}void BFS(linkG* g, int i)//⼴度优先遍历{int j;eNode* p;int q[Max], front = 0, rear = 0;//建⽴顺序队列⽤来存储,并初始化printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已经访问过的改成1rear = (rear + 1) % Max;//普通顺序队列的话,这⾥是rear++q[rear] = i;//当前顶点(下标)队尾进队while (front != rear)//队列⾮空{front = (front + 1) % Max;//循环队列,顶点出队j = q[front];p = g->adjlist[j].firstedge;//p指向出队顶点j的第⼀条边while (p != NULL){if (visited[p->adjvex] == 0)//如果未被访问{printf("%c ", g->adjlist[p->adjvex].vertex);visited[p->adjvex] = 1;//将该顶点标记数组值改为1rear = (rear + 1) % Max;//循环队列q[rear] = p->adjvex;//该顶点进队}p = p->next;//指向下⼀个结点}}}void BFSTravel(linkG* g)//遍历⾮连通图{int i;printf("⼴度优先遍历:\n");for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问过{BFS(g, i);//调⽤BFS函数}}}//因为拓扑排序要求⼊度为0,所以需要先求出每个顶点的⼊度void inDegree(linkG* g)//求图顶点⼊度{eNode* p;int i;for (i = 0; i < g->n; i++)//循环将顶点⼊度初始化为0{g->adjlist[i].in = 0;}for (i = 0; i < g->n; i++)//循环每个顶点{p = g->adjlist[i].firstedge;//获取第i个链表第1个边结点指针while (p != NULL)///当p不为空(边存在){g->adjlist[p->adjvex].in++;//该边终点结点⼊度+1p = p->next;//p指向下⼀个边结点}printf("顶点%c的⼊度为:%d\n", g->adjlist[i].vertex, g->adjlist[i].in);}void topo_sort(linkG *g)//拓扑排序{eNode* p;int i, k, gettop;int top = 0;//⽤于栈指针的下标索引int count = 0;//⽤于统计输出顶点的个数int* stack=(int *)malloc(g->n*sizeof(int));//⽤于存储⼊度为0的顶点for (i=0;i<g->n;i++)//第⼀次搜索⼊度为0的顶点{if (g->adjlist[i].in==0){stack[++top] = i;//将⼊度为0的顶点进栈}}while (top!=0)//当栈不为空时{gettop = stack[top--];//出栈,并保存栈顶元素(下标)printf("%c ",g->adjlist[gettop].vertex);count++;//统计顶点//接下来是将邻接点的⼊度减⼀,并判断该点⼊度是否为0p = g->adjlist[gettop].firstedge;//p指向该顶点的第⼀条边的指针while (p)//当p不为空时{k = p->adjvex;//相连接的顶点(下标)g->adjlist[k].in--;//该顶点⼊度减⼀if (g->adjlist[k].in==0){stack[++top] = k;//如果⼊度为0,则进栈}p = p->next;//指向下⼀条边}}if (count<g->n)//如果输出的顶点数少于总顶点数,则表⽰有环{printf("\n有回路!\n");}free(stack);//释放空间}void menu()//菜单{system("cls");//清屏函数printf("************************************************\n");printf("* 1.建⽴图 *\n");printf("* 2.深度优先遍历 *\n");printf("* 3.⼴度优先遍历 *\n");printf("* 4.求出顶点⼊度 *\n");printf("* 5.拓扑排序 *\n");printf("* 6.退出 *\n");printf("************************************************\n");}int main(){linkG* g = NULL;int c;while (1){menu();printf("请选择:");scanf("%d", &c);switch (c){case1:g = creat(g); system("pause");break;case2:DFSTravel(g); system("pause");break;case3:BFSTravel(g); system("pause");break;case4:inDegree(g); system("pause");break;case5:topo_sort(g); system("pause");break;case6:exit(0);break;}}return0;}实验⽤图:运⾏结果:关于深度优先遍历 a.从图中某个顶点v 出发,访问v 。


算法设计:深度优先遍历和广度优先遍历实现深度优先遍历过程1、图的遍历和树的遍历类似,图的遍历也是从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。
它是许多图的算法的基础。
深度优先遍历和广度优先遍历是最为重要的两种遍历图的方法。
它们对无向图和有向图均适用。
注意:以下假定遍历过程中访问顶点的操作是简单地输出顶点。
2、布尔向量visited[0..n-1]的设置图中任一顶点都可能和其它顶点相邻接。
在访问了某顶点之后,又可能顺着某条回路又回到了该顶点。
为了避免重复访问同一个顶点,必须记住每个已访问的顶点。
为此,可设一布尔向量visited[0..n-1],其初值为假,一旦访问了顶点Vi之后,便将visited[i]置为真。
--------------------------深度优先遍历(Depth-First Traversal)1.图的深度优先遍历的递归定义假设给定图G的初态是所有顶点均未曾访问过。
在G中任选一顶点v为初始出发点(源点),则深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。
若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。
若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。
图的深度优先遍历类似于树的前序遍历。
采用的搜索方法的特点是尽可能先对纵深方向进行搜索。
这种搜索方法称为深度优先搜索(Depth-First Search)。
相应地,用此方法遍历图就很自然地称之为图的深度优先遍历。
2、深度优先搜索的过程设x是当前被访问顶点,在对x做过访问标记后,选择一条从x出发的未检测过的边(x,y)。
若发现顶点y已访问过,则重新选择另一条从x出发的未检测过的边,否则沿边(x,y)到达未曾访问过的y,对y访问并将其标记为已访问过;然后从y开始搜索,直到搜索完从y出发的所有路径,即访问完所有从y出发可达的顶点之后,才回溯到顶点x,并且再选择一条从x出发的未检测过的边。

一、单选题C01、在一个图中,所有顶点的度数之和等于图的边数的倍。
A)1/2 B)1 C)2 D)4B02、在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A)1/2 B)1 C)2 D)4B03、有8个结点的无向图最多有条边。
A)14 B)28 C)56 D)112C04、有8个结点的无向连通图最少有条边。
A)5 B)6 C)7 D)8C05、有8个结点的有向完全图有条边。
A)14 B)28 C)56 D)112B06、用邻接表表示图进行广度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A07、用邻接表表示图进行深度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A08、一个含n个顶点和e条弧的有向图以邻接矩阵表示法为存储结构,则计算该有向图中某个顶点出度的时间复杂度为。
A)O(n) B)O(e) C)O(n+e) D)O(n2)C09、已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是。
A)0 2 4 3 1 5 6 B)0 1 3 6 5 4 2 C)0 1 3 4 2 5 6 D)0 3 6 1 5 4 2B10、已知图的邻接矩阵同上题,根据算法,则从顶点0出发,按广度优先遍历的结点序列是。
A)0 2 4 3 6 5 1 B)0 1 2 3 4 6 5 C)0 4 2 3 1 5 6 D)0 1 3 4 2 5 6D11、已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是。
A)0 1 3 2 B)0 2 3 1 C)0 3 2 1 D)0 1 2 3A12、已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是。
A)0 3 2 1 B)0 1 2 3 C)0 1 3 2 D)0 3 1 2A13、图的深度优先遍历类似于二叉树的。
A)先序遍历 B)中序遍历 C)后序遍历 D)层次遍历D14、图的广度优先遍历类似于二叉树的。

7_1对于图题7.1(P235)的无向图,给出:(1)表示该图的邻接矩阵。
(2)表示该图的邻接表。
(3)图中每个顶点的度。
解:(1)邻接矩阵:0111000100110010010101110111010100100110010001110(2)邻接表:1:2----3----4----NULL;2: 1----4----5----NULL;3: 1----4----6----NULL;4: 1----2----3----5----6----7----NULL;5: 2----4----7----NULL;6: 3----4----7----NULL;7: 4----5----6----NULL;(3)图中每个顶点的度分别为:3,3,3,6,3,3,3。
7_2对于图题7.1的无向图,给出:(1)从顶点1出发,按深度优先搜索法遍历图时所得到的顶点序(2)从顶点1出发,按广度优先法搜索法遍历图时所得到的顶点序列。
(1)DFS法:存储结构:本题采用邻接表作为图的存储结构,邻接表中的各个链表的结点形式由类型L_NODE规定,而各个链表的头指针存放在数组head中。
数组e中的元素e[0],e[1],…..,e[m-1]给出图中的m条边,e中结点形式由类型E_NODE规定。
visit[i]数组用来表示顶点i是否被访问过。
遍历前置visit各元素为0,若顶点i被访问过,则置visit[i]为1.算法分析:首先访问出发顶点v.接着,选择一个与v相邻接且未被访问过的的顶点w访问之,再从w 开始进行深度优先搜索。
每当到达一个其所有相邻接的顶点都被访问过的顶点,就从最后访问的顶点开始,依次退回到尚有邻接顶点未曾访问过的顶点u,并从u开始进行深度优先搜索。
这个过程进行到所有顶点都被访问过,或从任何一个已访问过的顶点出发,再也无法到达未曾访问过的顶点,则搜索过程就结束。
另一方面,先建立一个相应的具有n个顶点,m条边的无向图的邻接表。

第七章 图一、单选题( C )1. 在一个图中,所有顶点的度数之和等于图的边数的 倍。
A .1/2 B. 1 C. 2 D. 42. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的( B )倍。
A .1/2 B. 1 C. 2 D. 4 (B )3. 有8个结点的无向图最多有 条边。
A .14 B. 28 C. 56 D. 112 ( A )一个n 个顶点的连通无向图,其边的个数至少为( )。
A .n-1B .nC .n+1D .nlogn ; ( C )5. 有8个结点的有向完全图有 条边。
A .14 B. 28 C. 56 D. 112 (B )6. 用邻接表表示图进行广度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图 ( A )7. 用邻接表表示图进行深度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图8. 下面关于求关键路径的说法不正确的是( C )。
A .求关键路径是以拓扑排序为基础的B .一个事件的最早开始时间同以该事件为尾的弧的活动最早开始时间相同C .一个事件的最迟开始时间为以该事件为尾的弧的活动最迟开始时间与该活动的持续时间的差D .关键活动一定位于关键路径上9. 已知图的邻接矩阵如下,根据算法思想,则从顶点0出发,按深度优先遍历的结点序列是( D )A . 0 2 4 3 1 5 6 B. 0 1 3 5 6 4 2 C. 0 4 2 3 1 6 5 D. 0 ⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡01000111011000010110101100110010001100100110111101 3 42 5 610、设数据结构A=(D,R),其中D={1,2,3,4},R={r},r={<1,2>,<2,3>,<3,4>,<4,1>,<4,2>},则数据结构A是(C )。


浅析深度优先和⼴度优先遍历实现过程、区别及使⽤场景⼀、什么是深度/⼴度优先遍历? 深度优先遍历简称DFS(Depth First Search),⼴度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种⽅式。
这两种遍历⽅式有什么不同呢?我们来举个栗⼦: 我们来到⼀个游乐场,游乐场⾥有11个景点。
我们从景点0开始,要玩遍游乐场的所有景点,可以有什么样的游玩次序呢?1、深度优先遍历 第⼀种是⼀头扎到底的玩法。
我们选择⼀条⽀路,尽可能不断地深⼊,如果遇到死路就往回退,回退过程中如果遇到没探索过的⽀路,就进⼊该⽀路继续深⼊。
在图中,我们⾸先选择景点1的这条路,继续深⼊到景点7、景点8,终于发现⾛不动了: 于是,我们退回到景点7,然后探索景点10,⼜⾛到了死胡同。
于是,退回到景点1,探索景点9: 按照这个思路,我们再退回到景点0,后续依次探索景点2、3、5、4、发现相邻的都玩过了,再回退到3,再接着玩6,终于玩遍了整个游乐场: 具体次序如下图,景点旁边的数字代表探索次序。
当然还可以有别的排法。
像这样先深⼊探索,⾛到头再回退寻找其他出路的遍历⽅式,就叫做深度优先遍历(DFS)。
这⽅式看起来很像⼆叉树的前序遍历。
没错,其实⼆叉树的前序、中序、后序遍历,本质上也可以认为是深度优先遍历。
2、⼴度优先遍历 除了像深度优先遍历这样⼀头扎到底的玩法以外,我们还有另⼀种玩法:⾸先把起点相邻的⼏个景点玩遍,然后去玩距离起点稍远⼀些(隔⼀层)的景点,然后再去玩距离起点更远⼀些(隔两层)的景点… 在图中,我们⾸先探索景点0的相邻景点1、2、3、4: 接着,我们探索与景点0相隔⼀层的景点7、9、5、6: 最后,我们探索与景点0相隔两层的景点8、10: 像这样⼀层⼀层由内⽽外的遍历⽅式,就叫做⼴度优先遍历(BFS)。
这⽅式看起来很像⼆叉树的层序遍历。
没错,其实⼆叉树的层序遍历,本质上也可以认为是⼴度优先遍历。
数据结构考试题库含答案数据结构考试题库含答案Document serial number【KKGB-LBS98YT-BS8CB-BSUT-BST108】数据结构习题集含答案目录选择题第一章绪论1.数据结构这门学科是针对什么问题而产生的(A )A、针对非数值计算的程序设计问题B、针对数值计算的程序设计问题C、数值计算与非数值计算的问题都针对D、两者都不针对2.数据结构这门学科的研究内容下面选项最准确的是(D )A、研究数据对象和数据之间的关系B、研究数据对象C、研究数据对象和数据的操作D、研究数据对象、数据之间的关系和操作3.某班级的学生成绩表中查得张三同学的各科成绩记录,其中数据结构考了90分,那么下面关于数据对象、数据元素、数据项描述正确的是(C )A、某班级的学生成绩表是数据元素,90分是数据项B、某班级的学生成绩表是数据对象,90分是数据元素C、某班级的学生成绩表是数据对象,90分是数据项D、某班级的学生成绩表是数据元素,90分是数据元素4.*数据结构是指(A )。
A、数据元素的组织形式B、数据类型C、数据存储结构D、数据定义5.数据在计算机存储器内表示时,物理地址与逻辑地址不相同,称之为(C )。
A、存储结构B、逻辑结构C、链式存储结构D、顺序存储结构6.算法分析的目的是(C )A、找出数据的合理性B、研究算法中的输入和输出关系C、分析算法效率以求改进D、分析算法的易懂性和文档型性7.算法分析的主要方法(A )。
A、空间复杂度和时间复杂度B、正确性和简明性C、可读性和文档性D、数据复杂性和程序复杂性8.计算机内部处理的基本单元是(B )A、数据B、数据元素C、数据项D、数据库9.数据在计算机内有链式和顺序两种存储方式,在存储空间使用的灵活性上,链式存储比顺序存储要(B )。
A、低B、高C、相同D、不好说10.算法的时间复杂度取决于( C )A 、问题的规模B、待处理数据的初始状态C、问题的规模和待处理数据的初始状态D、不好说11.数据结构既研究数据的逻辑结构,又研究物理结构,这种观点(B )。
第7章图二.判断题部分答案解释如下。
2. 不一定是连通图,可能有若干连通分量 11. 对称矩阵可存储上(下)三角矩阵14.只有有向完全图的邻接矩阵是对称的 16. 邻接矩阵中元素值可以存储权值21. 只有无向连通图才有生成树 22. 最小生成树不唯一,但最小生成树上权值之和相等26. 是自由树,即根结点不确定35. 对有向无环图,拓扑排序成功;否则,图中有环,不能说算法不适合。
42. AOV网是用顶点代表活动,弧表示活动间的优先关系的有向图,叫顶点表示活动的网。
45. 能求出关键路径的AOE网一定是有向无环图46. 只有该关键活动为各关键路径所共有,且减少它尚不能改变关键路径的前提下,才可缩短工期。
48.按着定义,AOE网中关键路径是从“源点”到“汇点”路径长度最长的路径。
自然,关键路径上活动的时间延长多少,整个工程的时间也就随之延长多少。
三.填空题1.有n个顶点,n-1条边的无向连通图2.有向图的极大强连通子图3. 生成树9. 2(n-1) 10. N-1 11. n-1 12. n 13. N-1 14. n15. N16. 3 17. 2(N-1) 18. 度出度 19. 第I列非零元素个数 20.n 2e21.(1)查找顶点的邻接点的过程 (2)O(n+e) (3)O(n+e) (4)访问顶点的顺序不同 (5)队列和栈22. 深度优先 23.宽度优先遍历 24.队列25.因未给出存储结构,答案不唯一。
本题按邻接表存储结构,邻接点按字典序排列。
25题(1) 25题(2) 26.普里姆(prim )算法和克鲁斯卡尔(Kruskal )算法 27.克鲁斯卡尔28.边稠密 边稀疏 29. O(eloge ) 边稀疏 30.O(n 2) O(eloge) 31.(1)(V i ,V j )边上的权值 都大的数 (2)1 负值 (3)为负 边32.(1)n-1 (2)普里姆 (3)最小生成树 33.不存在环 34.递增 负值 35.16036.O(n 2) 37. 50,经过中间顶点④ 38. 75 39.O(n+e )40.(1)活动 (2)活动间的优先关系 (3)事件 (4)活动 边上的权代表活动持续时间41.关键路径 42.(1)某项活动以自己为先决条件 (2)荒谬 (3)死循环 43.(1)零 (2)V k 度减1,若V k 入度己减到零,则V k 顶点入栈 (3)环44.(1)p<>nil (2)visited[v]=true (3)p=g[v].firstarc (4)p=p^.nextarc45.(1)g[0].vexdata=v (2)g[j].firstin (3)g[j].firstin (4)g[i].firstout (5)g[i].firstout (6)p^.vexj (7)g[i].firstout (8)p:=p^.nexti (9)p<>nil (10)p^.vexj=j(11)firstadj(g,v 0) (12)not visited[w] (13)nextadj(g,v 0,w)46.(1)0 (2)j (3)i (4)0 (5)indegree[i]==0 (6)[vex][i] (7)k==1 (8)indegree[i]==047.(1)p^.link:=ch[u ].head (2)ch[u ].head:=p (3)top<>0 (4)j:=top (5)top:=ch[j].count(6)t:=t^.link48.(1)V1 V4 V3 V6 V2 V5(尽管图以邻接表为存储结构,但因没规定邻接点的排列,所以结果是不唯一的。