Meta 分析及stata命令
- 格式:ppt
- 大小:497.00 KB
- 文档页数:12
1 定量资料两组比较的meta分析2 定性资料两组比较的meta分析实例:分类资料的meta分析为了探讨用Aspirin预防心肌梗塞(myocardial infarction,MI)后死亡的发生。
美国在1976——1988年问进行了7个关于Aspirin预防MI后死亡的研究,详细结果见表1,其中6项研究的结果表明Aspirin组及安慰剂组的MI后死亡率的差别无统计学意义。
只有1项结果表明Aspirin预防MI后死亡有效并且差别有统计学意义。
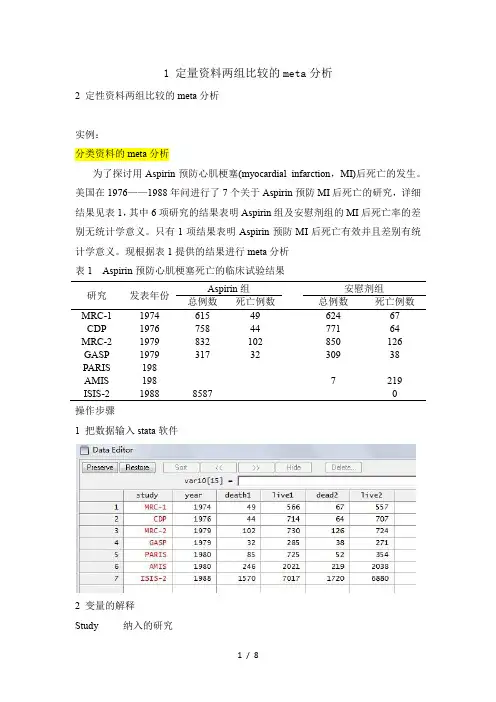
现根据表1提供的结果进行meta分析表1 Aspirin预防心肌梗塞死亡的临床试验结果研究发表年份Aspirin组安慰剂组总例数死亡例数总例数死亡例数MRC-119746154962467 CDP19767584477164 MRC-21979832102850126 GASP19793173230938 PARIS198AMIS1987219 ISIS-2198885870操作步骤1 把数据输入stata软件2 变量的解释Study 纳入的研究Year 年份Death1 Aspirin组的死亡人数Live1 Aspirin组的存活人数Death2 安慰剂组的死亡人数Live2 安慰剂组的死亡人数3 进行meta分析metan death1 live1 dead2 live2, or label(namevar=study, yearvar=year)结果:以上结果分成两部分(1)meta分析的合并统计量合并OR值OR=0.897,95%的可信区间(0.841,0.957)(2)给出异质性检验的结果只要异质性检验的P值不小于0.10(或者I-squared小于50%)就可以认为不存在异质性,可以用应固定效应模型(stata默认的情况)。
如果质性检验的P值小于等于0.10(或者I-squared大于50%),则不同的组间存在异质性,应该应用随机效应模型随机效应模型的命令如下:metan death1 live1 dead2 live2, or label(namevar=study, yearvar=year) random在运行meta分析命令的同时stata输出森林图,如下:由输出的合并结果和漏斗图可以得出,合并的OR值为0.90,95%可信区间为(0.84,0.96)4 发表偏倚的检验,命令如下:(1) gen logor=log(_ES)(2)gen selogor=_selogES(3)metabias logor selogor,graph(begg)输出结果如下:发表偏倚主要看begg检验的结果,由上图可以看到发表偏倚假设检验的z值为1.20,p值为0.230>0.05,可以认为没有发表偏倚。


Meta分析在医学研究中,绝大多数的医学现象都呈一定的随机性,因此医学研究的结果都受随机抽样误差影响而有所差异。
所以对于同一研究问题的多个研究结果往往不全相同,有些研究的结论甚至相反。
因此如何从结果不一的同类研究中综合出一个较为可靠的结论是医学研究中常常需要面临的问题。
Meta分析就是研究如何综合同类研究结果的一种统计分析方法。
Meta分析就是把相同研究问题的多个研究结果视为一个多中心研究的结果,运用多中心研究的统计方法进行综合分析。
Meta统计分析可以分为确定性模型分析方法和随机模型分析方法。
较常用的确定性模型Meta分析有Mantel-Haeszel统计方法(仅适用于效应指标为OR)和General-Variance-Based统计方法。
然而所有的确定性模型统计方法都要求Meta分析中的各个研究的总体效应指标(如:两组均数的差值等)是相等的,并称为齐性的(Homogeneity),而随机模型对效应指标没有齐性要求。
因此Meta分析可以采用下列分析策略:1)如果各个研究的效应指标是齐性的,则选用确定性模型统计方法:●效应指标为OR,则采用Mantel-Haeszel统计方法●效应指标为两个均数的差值、两个率的差值、回归系数、对数RR等近似服从正态分布的效应指标,则采用General-Variacne-Based方法进行Meta统计分析。
2)如果各个研究的效应指标不满足齐性条件或者研究背景无法用确定性模型进行解释的,则采用随机模型进行Meta 统计分析。
为了使读者较容易地掌握Meta 分析方法,以下将结合STATA软件的Meta 分析操作命令,通过实例介绍Meta 分析步骤和软件操作以及相应的统计分析结果解释,然后对Meta 分析中所涉及的统计公式进行分类汇总小结。
确定性模型的Meta 分析方法例1:为了研究Aspirin 预防心肌梗塞(MI)后死亡的发生,美国在1976年-1988年间进行了7个关于Aspirin 预防MI 后死亡的研究,其结果见表1,其中6次研究的结果表明Aspirin 组与安慰剂组的MI 后死亡率的差别无统计意义,只有一个研究的结果表明Aspirin 在预防MI 后死亡有效并且差别有统计意义。

《Stata在Meta分析中的应用》篇一一、引言Meta分析是一种统计技术,用于整合来自多个独立研究的结论,以提供更全面、更准确的结论。
随着科研工作的深入,Meta 分析在各个研究领域中扮演着越来越重要的角色。
Stata作为一种强大的统计分析软件,在Meta分析中发挥着重要作用。
本文将详细介绍Stata在Meta分析中的应用。
二、Stata软件简介Stata是一款功能强大的统计分析软件,广泛应用于数据管理、统计分析、数据可视化等领域。
其丰富的功能和强大的计算能力使得它在Meta分析中成为首选工具。
Stata提供了丰富的Meta分析命令和程序,使得用户可以方便地进行Meta分析。
三、Stata在Meta分析中的应用1. 数据管理Stata具有强大的数据管理功能,可以方便地导入、导出、清洗和整理Meta分析所需的数据。
用户可以将多个研究的数据整合到一个数据集中,然后使用Stata进行数据清洗和整理,以确保数据的准确性和一致性。
2. 描述性分析Stata可以进行描述性分析,包括计算各研究的效应量、标准误、置信区间等。
这些描述性分析的结果可以为后续的Meta分析提供基础。
3. 固定效应模型和随机效应模型Stata支持固定效应模型和随机效应模型两种Meta分析模型。
用户可以根据研究需求选择合适的模型。
固定效应模型假设各研究间的效应量是固定的,而随机效应模型则考虑了各研究间的异质性。
4. 亚组分析和元回归分析Stata还支持亚组分析和元回归分析等更复杂的Meta分析方法。
亚组分析可以根据某些特征将研究分为不同的亚组,然后分别进行Meta分析。
元回归分析则可以探讨效应量与其他变量之间的关系。
5. 结果可视化Stata提供了丰富的图形功能,可以将Meta分析的结果以图表的形式展示出来。
例如,可以使用森林图展示各研究的效应量及其置信区间,以便更直观地了解各研究的结果和总体结果。
四、案例分析以某项关于药物治疗糖尿病的研究为例,我们将介绍如何使用Stata进行Meta分析。

生物医学发展迅速,科学工作者常需综合评价针对某一科学问题的不同研究证据。
如何归纳和综合分析这些分散的研究证据,提升对问题的认识水平,已成为生物医学研究的重要步骤[1]。
荟萃(Meta )分析就是定量综合分析多个同类研究效应的方法[2]。
近十年,Meta 分析在生物医学领域应用日益广泛,有关文献迅速增多,2001年前共有169篇中文论文发表,而在2001-2009期间就有2115篇。
已发表的Meta 分析多针对设有对照的研究类型,国内文献未见针对无对照的研究类型如横断面研究,国外亦少见。
横断面研究等没有设对照的研究是人群研究的基础,也是揭示暴露与疾病关系不可或缺的。
生物医学工作者掌握针对无对照的研究类型的Meta 分析方法和计算机实现步骤是必要的。
本文旨在介绍二分类无对照资料的Meta 分析方法及其在Stata 软件中的操作步骤。
无对照二分类资料的Meta 分析方法及Stata 实现王佩鑫a ,b,李宏田b ,c,刘建蒙b ,c(北京大学a.公共卫生学院;b.生育健康研究所;c.卫生部生育健康重点实验室,北京100191)[摘要]目的介绍无对照二分类资料Meta 分析方法及在Stata 软件中的操作步骤。
方法首先介绍3种数据类型无对照二分类资料Meta 分析的原理及方法,再用Stata 软件对3个实例数据进行Meta 分析。
结果无对照二分类资料Meta 分析的关键是选择服从正态分布或可转化为正态分布的指标。
3个实例数据经正态转换后进行Meta 分析,结果与原文一致。
结论Stata 软件可实现无对照二分类资料(含患病率、发病密度和比值)的Meta 分析,操作简单,实用性强。
[关键词]二分类变量;无对照;Stata ;Meta 分析[中图分类号]R195.1[文献标识码]A [文章编号]1671-5144(2012)01-0052-04Meta-Analysis of Non-Comparative Binary Outcomes andIts Solution by StataWANG Pei-xin a ,b ,LI Hong-tian b ,c ,LIU Jian-meng b ,c(a.School of Public Health ;b.Institute of Reproductive and Child Health ;c.Ministry of Health Key Laboratory of Reproductive Health ,Peking University ,Beijing 100191,China )Abstract :ObjectiveTo introduce the method of meta-analysis for non-comparative binary outcomes and its realization in Stata.MethodsWe first introduced principles and methods of meta-analysis for three types of non-comparative binary outcomes ,and then replicated results of three published meta-analyses in Stata.ResultsThe keypoint of doing these meta-analyses was to choose the effect size indices which were of normal distribution or could be transformed into normal distribution.The replicated results were consistent with the original literatures.Conclusions Meta-analyses for three types of binary outcomes ,including prevalence ,incidence density ,and odds ,could be done in Stata conveniently.Key words :binary ;non-comparative ;Stata ;meta-analysis[基金项目]国家自然科学基金资助项目(81072372)[作者简介]王佩鑫(1986-),男,河北馆陶人,在读硕士研究生,研究方向为妇女儿童保健。

手把手教你用Stata进行Meta分析Meta简明教程(7)Meta简明教程目录1. 认识一下meta方法! | Meta简明教程(1)2. 一文初步学会Meta文献检索| Meta简明教程(2)3. 如何搞定“文献筛选” | Meta简明教程(3)4.Meta分析文献质量评价 | Meta简明教程(4)5.Meta分析数据提取| Meta简明教程(5)6.一文学会revman软件| Meta简明教程(6)Meta简明教程(7)上一期介绍了Revman 软件对二分类数据、连续型数据、诊断性试验数据、生存-时间数据进行meta分析,本期将利用Stata对以上数据进行meta分析。
大家可以到本公众号下载Stata软件(重磅推荐:分类最全的统计分析相关软件,了解一下?请关注、收藏以备用)Stata12.0 界面一、二分类数据分析数据形式例:研究阿司匹林(aspirin)预防心肌梗死(MI)7个临床随机对照试验,观察死亡率,数据提取如下:操作步骤1.构建数据1)启动Stata 12.0 软件后,可以直接点击工具栏中DataEditor (edit)按钮。
也可在在菜单栏中点击Data→Data Editor→ DataEditor (edit),出现以下界面。
2)点击变量名位置,依次输入研究名称(research),阿司匹林组死亡数(a),阿司匹林组存活数(b),安慰剂组死亡数(c),安慰剂组存活数(d)3)录入数据:在变量值区域输入数据2. 数据分析1)导入meta模块:在Command窗口中进行编程,首先需要在Stata中安装meta 模块:在Command窗口输入“ssc install metan”,选中点回车。
结果窗口中出现下面的结果,说明已经安装了meta模块。
2)输入meta分析代码:在Command窗口输入“Command窗口输入“metan a b c d, or fixed”,点回车,完成结果分析。


Stata软件在诊断性研究的meta分析中的命令在诊断性研究的meta分析中可以计算合并阳性似然比、合并阴性似然比、诊断OR值、ROC值、SROC曲线、HSROC-bivariate meta-analysis等。
Stata进行诊断研究meta分析时的起始命令:*Variable codes: tp=true positives; fp=false positives; tn=true negatives;fn=false negatives*add .5 to all zero cellsgen zero=0replace zero=1 if tp==0|fp==0|fn==0|tn==0replace tp=tp+.5 if zero==1replace fp=fp+.5 if zero==1replace fn=fn+.5 if zero==1replace tn=tn+.5 if zero==1gen tpr= tp/(tp+fn)gen fpr=fp/(fp+tn)gen logittpr=ln(tp/fn)gen logitfpr=ln(fp/tn)gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)gr7 logittpr logitfprspearman logittpr logitfpr1.1 合并阳性似然比命令:metan tp fn fp tn, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR+, Random Effects)2.2 合并阴性似然比命令:metan fn tp tn fp, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR-, Random Effects)2.3 合并诊断OR值命令:metan tp fn fp tn, or random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary Diagnostic Odds Ratio, Random Effects)2.4 ROC值命令:gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)2.5 SROC曲线命令:gen sum= logittpr+ logitfprgen diff= logittpr- logitfprregress diff sumpredict yhatgr7 diff yhat sum, ylab(3,4,5,6,7,8) xlab(-4,-3,-2,-1,0,1,2) c(.l) s(oi)gen tse=1/(1+(1/(exp(_cons/1-_b)*(fpr/spec)^1+_b/1-_b)))(constant and b are derived from the above regression model)*plot SROC curve (generic)gr7 se tse fpr, ysize(6) xsize(6) noaxis xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1)ylab(0(.1)1) s(Oi) c(.s) l1(Sensitivity) b2(1-Specificity) ti(Summary ROC Curve) key1(" ")key2(" ")2.6 HSROC-bivariate meta-analysis命令:metandi tp fp fn tn, plot (基于SROC命令)2.7 发表偏倚命令:gen or=(tp*tn)/(fp*fn)gen lnor=ln(or)gen selnor=(1/tp)+(1/fp)+(1/fn)+(1/tn)*Begg and Egger test for publication bias with Begg's funnel plot: metabias lnor selnor, graph(begg)*Begg and Egger tests for subgroups (eg. Covariate=1)metabias lnor selnor if covariate==1, graph(begg)。

Meta回归stata结果解读在统计学中,meta回归分析是一种用于结合多个独立研究结果的方法,以产生一个综合的估计值。
这种方法可以帮助研究者更准确地评估一个特定效应的大小和方向,并且可以提供对这个效应的整体理解。
在本文中,我们将介绍meta回归分析的基本概念,并对使用Stata软件进行meta回归分析的结果进行解读。
1. 概念在研究领域,通常会有多个独立的研究对同一个问题或效应进行研究,并且产生了不同的估计值。
meta回归分析的主要目的就是将这些独立研究的结果进行合并,得出综合的效应估计。
这样做的好处是可以增加研究结果的统计功效,并且可以提供更准确的估计。
2. Stata软件进行meta回归分析利用Stata软件进行meta回归分析可以帮助研究者更方便地进行数据处理和结果解读。
我们需要将已有的研究结果数据导入Stata软件中,然后使用meta命令进行meta回归分析。
在得到结果后,我们可以对各个参数进行解读,并得出综合的效应值和其置信区间。
3. 结果解读在meta回归分析的结果中,我们通常会看到各个研究的效应值、加权效应值、置信区间等参数。
在解读这些结果时,我们需要重点关注综合的效应值和其置信区间。
如果置信区间包含0,说明综合效应值可能不显著;而如果置信区间不包含0,说明综合效应值可能是显著的。
我们还需要关注异质性检验的结果,以确定研究结果是否存在显著的异质性。
4. 个人观点个人对meta回归分析的理解是,这种方法可以帮助研究者更全面地评估一个效应的大小和方向,尤其是当存在多个独立研究时。
利用Stata软件进行meta回归分析,可以更加方便地进行数据处理和结果解读,为研究者提供了一个强大的工具。
总结在本文中,我们介绍了meta回归分析的基本概念,并介绍了利用Stata软件进行meta回归分析的方法和结果解读。
通过对结果的解读,我们可以更全面地评估一个效应的大小和方向,从而得出对研究问题的更深入理解。
使用stata进行meta分析的详细具体过程和方法meta, stata最近使用stata 8进行meta分析,之前已经使用refman 5进行了初步处理,但是refman 的漏斗图只能粗略看是否对称,无法定量,据说stata可以进行发表性偏倚定量评价,所以自己摸索stata中的meta分析方法,在DXY中学习了不少战友的帖子(zhangdog战友),都感觉不是很系统,有的还有些问题。
结合自己的体会,写个详细的总结,希望对像我一样的初学者有所帮助,尤其对很多非统计学专业的人员有用,当然我也不是统计学专业的,问题再所难免,共同学习,还望战友指点。
1.stata的安装,建议下载8.0的版本,有战友反映9.0和10.0的版本好象有些问题,反正基本功能有了,meta分析的菜单在8.0以后版本都有了,所以不必追求最新的。
我是在上下载的。
baidu,google上都能找到。
2.原始数据的录入,这是应用stata进行分析的基础。
(1)命令窗口输入:Input no study event1 total1 event0 total0: |( g; m- [2 `; b3 `(分别表示纳入研究序号,名称,暴露组或处理组例数,总例数,对照组例数,对照组总例数,因为我是用refman中导出数据,这后4项可以直接输出),作用是产生变量。
然后可以逐行输入数据,以end命令结束,我建议初学者跳到下面的输入更简单。
* s# ?- w; d: B6 v$ L- j(2)点Data——Data editor(或ctrl+7快捷键),可以直接录入数据,可以直接复制,粘贴数据。
输完后点击preserve保存退出Data editor 窗口。
6 z7 T5 M3 H5 ~%第一步(1)也可以省略,进入第二步后,先输入数据,然后双击自动产生的变量var1,var2....进行变量名称的修改,个人感觉这样快捷。
1 Deng SL 2004 31 114 8 100* Z4 U' m+ R$ i4 i8 V( P&2 Ding HF 2006 19 25 5 8^3 h2 l* t6 W9 ?" \$ _" o- S3 Fang ZL 2002 35 36 20 35+ C& ?* ^) Q3 y! l R, F' F14 Ito K 2006 36 40 31 40@5 ?* E& [!5 Kao JH 2003 81 127 4 35m/ y4 w2 R. y: h4 ~5 a6 Yuen MF 2004 60 66 101 1351 V3 [0 M& Y4 ~. B. x- a. B% l*完毕在命令窗输入list命令查看数据。
Meta分析软件操作教程,最全合集!“实用meta分析”为大家介绍了meta分析常用软件:Stata、RevMan、R、Meta-DiSc的相关操作,由于内容比较分散,不利于重复学习,我们特意整理成一个合集,只要收藏或转发一次,就不用担心以后找不到教程了!Meta分析教程——Stata篇Meta分析教程,Stata系列(1):数据录入一分钟学会Stata-合并单个率的森林图一分钟学会Stata-连续型变量的森林图一分钟学会Stata-二分类变量的森林图一分钟学会Stata-合并效应值的森林图一分钟学会Stata-亚组分析一分钟学会Stata之:二分类变量的发表偏倚检验一分钟学会Stata之:连续型变量的发表偏倚检验一分钟学会Meta分析-高清漏斗图的制作一分钟学会Meta分析之:Stata森林图的编辑剪补法在Stata中的实现和结果解读多图讲解Stata的发表偏倚检验技术贴:发表偏倚检验--harbord法发表偏倚检验--harbord法一分钟学会Stata:诊断试验的Meta分析(1)一分钟学会Stata:诊断试验的Meta分析(2)Stata操作的常见问题,你解决了吗?Meta分析教程——RevMan篇Meta分析软件之:Review Manager 5.2RevMan 5.2简易教程-新建系统评价RevMan 5.2 简易教程 2 纳入研究的添加RevMan 5.2 简易教程 3 Cochrane质量评价1 RevMan 5.2 简易教程 3 Cochrane质量评价2 RevMan5.2 简易教程4 增加比较和结局指标RevMan 5.2简易教程5 二分类数据分析RevMan5.2 简易教程6 连续性数据分析RevMan5.2 简易教程7 敏感性分析RevMan5.2 简易教程8 发表偏倚检验RevMan5.2 简易教程9 诊断性试验Meta分析RevMan5.2 简易教程10 HR P计算CIRevMan如何改变森林图中研究的次序Endnote的文献导入RevMan?So easy!利用SPSS和RevMan实现有序数据的Meta分析(1) 利用SPSS和RevMan实现有序数据的Meta分析(2) RevMan软件:率的Meta分析的实现(1) RevMan软件:率的Meta分析的实现(2) RevMan软件:率的Meta分析的实现(3) RevMan生成文献筛选流程图RevMan-诊断性试验的质量评价Meta分析教程——R软件篇R软件中数据的输入R软件系列: 第二讲二分类数据的Meta分析(1)R软件系列:实现二分类数据的Meta分析(2)R软件系列:实现连续数据的Meta分析R软件系列:实现单个率的Meta分析(1)R软件系列:实现单个率的Meta分析(2)R软件系列:实现相关系数的Meta分析R软件系列:实现效应值的Meta分析R软件系列:实现Meta回归分析R软件系列:实现累积Meta分析R软件系列:森林图的编辑R软件--Galbraith图、L’Abbe图和Baujat图的绘制R软件读取RevMan中的数据进行Meta分析(1)R软件读取RevMan中的数据进行Meta分析(2)一分钟学会meta分析之:R软件实现剪补法技术贴-附加轮廓线漏斗图的绘制在R软件中的实现Meta分析教程——Meta-DiSc篇Meta-disc入门学习-软件下载和安装Meta-disc入门学习之数据录入Meta-disc评估非阈值效应Meta-disc评估阈值效应诊断性meta分析:如何用Meta-DiSc评价异质性Meta-Disc四步法快速做出森林图Meta-Disc 如何输出高清图片的秘密Meta-disc如何进行meta回归分析Meta-disc之亚组分析今天的分享就到这了,实用meta分析致力于为大家提供更多精彩内容,除了meta分析,以下哪个栏目对你最有吸引力呢?一起投票吧!。
用stata进行单个率meta分析程序总结第一篇:用stata进行单个率meta分析程序总结用stata进行单个率meta分析程序总结感谢版主对我的方法进行验证,这里整理一下方面大家研究谷歌的程序(标红部分,分批录入stata12.0.可得到结果。
)clearinput study cases total 20 1000 40 5000 30 1500 25 3300 end gen p =.gen se =.// get proportions and std errors forv i =1(1)4 {cii total[`i'] cases[`i']qui replace p = r(mean)in `i'qui replace se = r(se)in `i' }// get the inverse variance-weighted proportion// use the official Stata-vwls-commandgen cons =1vwls p cons, sd(se)// use the user written-metan-command// for fixed-effects meta-analysismetan p se, nograph fixed// for random-effects meta-analysismetan p se, nograph random我的数据,用谷歌方法运行的命令:clearinput study cases total451 2 86 202 3 24 97 401 2502 endgen p =.gen se =.forv i =1(1)4 {cii total[`i'] cases[`i']qui replace p = r(mean)in `i'qui replace se = r(se)in `i' } gen cons =1vwls p cons, sd(se)metan p se, nograph fixed metan p se, nograph random我自已编的程序结果见贴子中的图片:录入格式,r n clear input study r n 1 0.831 154 2 0.828 134 3 0.88 100 endgenerate ser=sqrt(r*(1-r)/n)metan r ser, fixed label(namevar=study)metan r ser, random label(namevar=study)metafunnel r ser第二篇:meta分析资源大总结经过一段时间对meta的分析和了解,自己虽算不上精通meta分析,但自己还是觉得自己对meta分析产生了一定的兴趣!现在将我获得的各种资源汇总如下!与大家一起分享,一起进步!(一)meta分析的选题原则首先,选定的题目要有争议性!如果关于某项研究,大家的结论都是一致的,那没有再做meta分析的必要了!其次,选定的题目要有原始文献作支撑!俗话说,巧妇难为无米之脆!meta分析质量的好坏,关键还是取决于有无高质量的原始研究作为强大的后盾力量!再者,所选题目要具有创新!创新是论文是否发表的很重要的决定性因素!meta分析不像其他原始研究~我在美国做可能是A结果,我在中国做可能就是B结果!这两个研究是不同的因为研究的地域、人群等不同!但meta分析是针对目前所有发表或者未发表的研究报告进行二次研究!我理解的创新就是要在前人的工作基础上,结合自己的体会和阅读文献的感悟,提出一个合理,科学的问题!最后,所选题目要有意义!所有科学研究的终极目标是促进人类更好的发展!对于meta分析(无论是干预性研究的meta或者是诊断性试验的meta,etc),必须明确你的研究目的是什么?!这样做有什么意义!(二)meta分析的经典之作~唐茂芝、董佳毅八篇SR(声明:这八篇SR著作权属原作者所有!这里仅仅是分享而已,不带有任何其他目的!)我刚开始学习meta分析的时候,我导师就要求我们先看一下这八篇SR!最初看的有点吃力!但是后面慢慢就习惯了!下面是这八篇SR,与大家分享一下!(三)关于meta分析理论入门的PPT(特别适用于刚入门的战友们!)下面是我刚接触meta是看的PP他,也一并传上来,给初学meta 的战友们打气加油!(四)meta分析的证据分级和检索策略众所周知,不同原始文献的证据级别是不一样的!小弟整理了目前有关分级的标准!传上来与大家一起学习!另外,我也把三大数据库的检索使用方法一并传上来!(这些资料均来自互联网!版权属原作者所有!发帖者仅为交流学习之用,无其他意图!)(五)meta分析的圭臬毫无疑问,要做好meta分析,Cochrane HanbooK 是每个人必读的经典之作!下面我把5.0和5.1都上传上来!另外,还上创一个介绍meta分析的英文文献!(六)关于meta研究论文的写作指导一片好的meta分析,无论是文章结构还是语言表达,都十分完美!那有没有一个meta分析写作的固定模版呢!?答案是肯定的!下面我上传SR写作的模版和报告规范!呵呵,暂时就整理出这些啦!本来是想把Endnote和Stata一起传上来的,但是这两个文件有点大!所以各位战友如有需要,在园子里搜索一下吧!谢谢大家了!上面有什么不对的,请大家不吝赐教哈!我们一起学习,一起进步!祝大家国庆节快乐!第三篇:循证医学-meta分析入门总结一、选题和立题(一)形成需要解决的临床问题:系统评价可以解决下列临床问题:1.病因学和危险因素研究;2.治疗手段的有效性研究;3.诊断方法评价;4.预后估计;5.病人费用和效益分析等。
stata network meta analysis heterogeneity 在Stata中进行网络Meta分析时,需要考虑异质性的问题。
异质性指的是不同的研究或治疗组之间存在的差异,它可能由许多因素引起,如患者的基线特征、治疗方法或研究的执行方式等。
在进行网络Meta分析时,我们需要估计这种异质性并恰当地处理它,以确保结果的准确性和可靠性。
在Stata中进行网络Meta分析时,可以使用`netgraph`命令生成网络图,以可视化不同治疗之间的比较关系。
然后,可以使用`netreg`命令进行网络Meta分析,该命令可以估计不同治疗之间的效果,并考虑异质性的影响。
要处理异质性,可以考虑以下方法:
1. 使用随机效应模型:随机效应模型可以考虑到不同研究或治疗组之间的变异,并提供一个估计的异质性范围。
2. 计算I²统计量:I²统计量是一个量化异质性的常用方法,它可以告诉我们不同研究或治疗组之间的变异程度。
3. 敏感性分析:敏感性分析可以检查异质性对结果的影响,并确定哪些因素可能导致异质性。
总之,在进行网络Meta分析时,需要考虑异质性的问题,并采取适当的方法来处理它。
这可以帮助我们获得更准确和可靠的结果,并为临床决策提供更有力的支持。