编译原理第八章作业
- 格式:ppt
- 大小:85.00 KB
- 文档页数:4

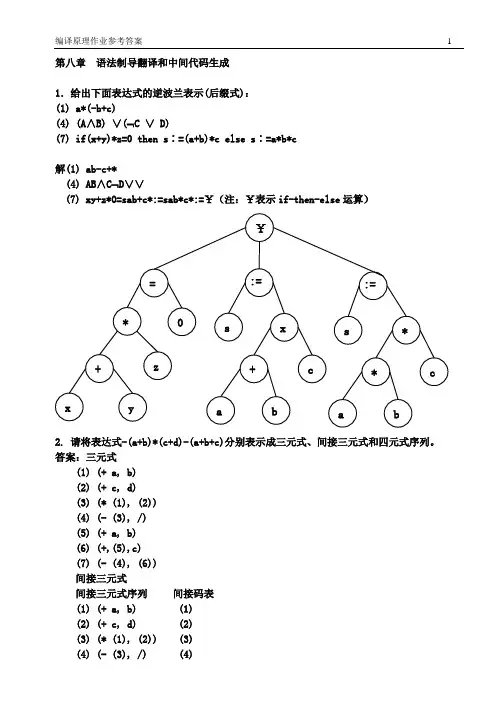
第八章 语法制导翻译和中间代码生成1.给出下面表达式的逆波兰表示(后缀式): (1) a*(-b+c)(4) (A ∧B) ∨(⌝C ∨ D)(7) if(x+y)*z=0 then s ∶=(a+b)*c else s ∶=a*b*c解(1) ab-c+*(4) AB ∧C ⌝D ∨∨(7) xy+z*0=sab+c*:=sab*c*:=¥(注:¥表示if-then-else 运算)2. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
答案:三元式(1) (+ a, b) (2) (+ c, d)(3) (* (1), (2)) (4) (- (3), /) (5) (+ a, b)(6) (+,(5),c) (7) (- (4), (6)) 间接三元式间接三元式序列 间接码表 (1) (+ a, b) (1) (2) (+ c, d) (2) (3) (* (1), (2)) (3) (4) (- (3), /) (4)¥= :=*:=+ xyzs +cxa bs* c*a b(5) (- (4), (1)) (1)(6) (- (4), (5)) (5)(6)四元式(1) (+, a, b, t1) (2) (+, c, d, t2) (3) (*, t1, t2, t3) (4) (-, t3, /, t4)(5) (+, a, b, t5) (6) (+, t5, c, t6) (6) (-, t4, t6, t7)3. 采用语法制导翻译思想,表达式E 的"值"的描述如下: 产生式 语义动作(0) S ′→E {print E.VAL}(1) E →E1+E2 {E.VAL ∶=E1.VAL+E2.VAL} (2) E →E1*E2 {E.VAL ∶=E1.VAL*E2.VAL} (3) E →(E1) {E.VAL ∶=E1.VAL} (4) E →n {E.VAL ∶=n.LEXVAL}如果采用LR 分析法,给出表达式(5 * 4 + 8) * 2的语法树并在各结点注明语义值VAL 。
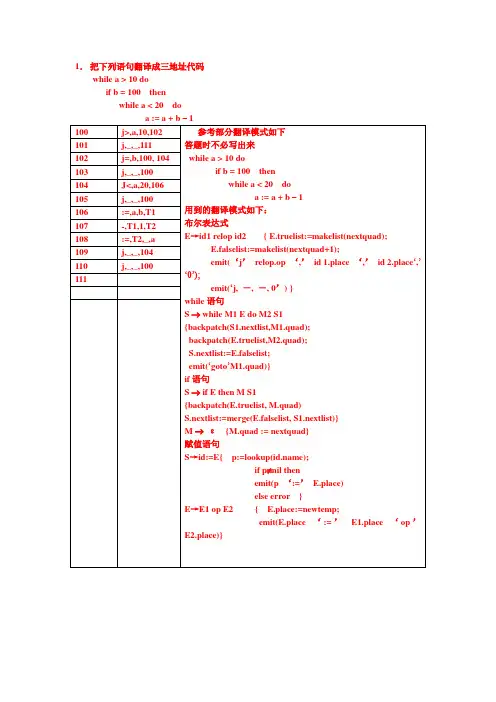


1、已知文法:A → aAd|aAb|ξ判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串 #ab# 给出分析过程。
解:(0) A’→ A(1)A → aAd(2) A → aAb(3) A →ξ构造该文法的活前缀DFA:由上图可知该文法是SLR(1)文法。
构造SLR(1)的分析表:3、考虑文法:S →AS|b A→SA|aFollow(A) = first(S) = {b}+first(A)= {a,b}(1)列出这个文法的所有LR(0)项目(2)按(1)列出的项目构造识别这个文法活前缀的NFA,把这个NFA确定化为DFA,说明这个DFA的所有状态全体构成这个文法的LR(0)规范族。
(3)这个文法是SLR的吗?若是,构造出它的SLR分析表。
(4)这个文法是LALR或LR(1)的吗?解:(0)S’→S (1)S→AS (2)S→b (3)A→SA (4)A→a(1)列出所有LR(0)项目:S’→·S S→·b A→·a S’→ S· S→b· A→a·S →·AS A→·SAS →A·S A→S·AS →AS· A→SA·(3)构造该文法的活前缀NFA:由上可知:I1 I3 I5 中存在着移进和归约冲突在I1中含项目:S’→ S·归约项 Follow(S’)={#}A →·a 移进项 Follow(S’)∩{a}=∮S →·b 移进项 Follow(S’)∩{b}=∮在I3中含项目:A →SA·归约项 Follow(A)={a,b}S →·b 移进项 Follow(A) ∩ {b}≠∮A →·a 移进项 Follow(A) ∩ {a}≠∮在I5中含项目:S →AS·归约项 Follow(S)={#,a,b}A →·a 移进项 Follow(S) ∩ {a}≠∮S →·b 移进项 Follow(S) ∩ {b }≠∮由此可知,I3、I5的移进与归约冲突不能解决,所以这个文法不是SLR (1)文法。


第一章练习题(绪论)一、选择题1.编译程序是一种常用的软件。
A) 应用B) 系统C) 实时系统D) 分布式系统2.编译程序生成的目标代码程序是可执行程序。
A) 一定B) 不一定3.编译程序的大多数时间是花在上。
A) 词法分析B) 语法分析C) 出错处理D) 表格管理4.将编译程序分成若干“遍”将。
A)提高编译程序的执行效率;B)使编译程序的结构更加清晰,提高目标程序质量;C)充分利用内存空间,提高机器的执行效率。
5.编译程序各个阶段都涉及到的工作有。
A) 词法分析B) 语法分析C) 语义分析D) 表格管理6.词法分析的主要功能是。
A) 识别字符串B) 识别语句C) 识别单词D) 识别标识符7.若某程序设计语言允许标识符先使用后说明,则其编译程序就必须。
A) 多遍扫描B) 一遍扫描8.编译方式与解释方式的根本区别在于。
A) 执行速度的快慢B) 是否生成目标代码C) 是否语义分析9.多遍编译与一遍编译的主要区别在于。
A)多遍编译是编译的五大部分重复多遍执行,而一遍编译是五大部分只执行一遍;B)一遍编译是对源程序分析一遍就立即执行,而多遍编译是对源程序重复多遍分析再执行;C)多遍编译要生成目标代码才执行,而一遍编译不生成目标代码直接分析执行;D)多遍编译是五大部分依次独立完成,一遍编译是五大部分交叉调用执行完成。
10.编译程序分成“前端”和“后端”的好处是A)便于移植B)便于功能的扩充C)便于减少工作量D)以上均正确第二章练习题(文法与语言)一、选择题1.文法 G 产生的 (1) 的全体是该文法描述的语言。
A.句型B. 终结符集C. 非终结符集D. 句子2.若文法 G 定义的语言是无限集,则文法必然是 (2) A递归的 B 上下文无关的 C 二义性的 D 无二义性的3. Chomsky 定义的四种形式语言文法中, 0 型文法又称为(A)文法;1 型文法又称为(C)文法;2 型语言可由(G) 识别。
A 短语结构文法B 上下文无关文法C 上下文有关文法D 正规文法E 图灵机F 有限自动机G 下推自动机4.一个文法所描述的语言是(A);描述一个语言的文法是(B)。



第一章练习题(绪论)一、选择题1.编译程序是一种常用的软件。
A) 应用B) 系统C) 实时系统D) 分布式系统2.编译程序生成的目标代码程序是可执行程序。
A) 一定B) 不一定3.编译程序的大多数时间是花在上。
A) 词法分析B) 语法分析C) 出错处理D) 表格管理4.将编译程序分成若干“遍”将。
A)提高编译程序的执行效率;B)使编译程序的结构更加清晰,提高目标程序质量;C)充分利用内存空间,提高机器的执行效率。
5.编译程序各个阶段都涉及到的工作有。
A) 词法分析B) 语法分析C) 语义分析D) 表格管理6.词法分析的主要功能是。
A) 识别字符串B) 识别语句C) 识别单词D) 识别标识符7.若某程序设计语言允许标识符先使用后说明,则其编译程序就必须。
A) 多遍扫描B) 一遍扫描8.编译方式与解释方式的根本区别在于。
A) 执行速度的快慢B) 是否生成目标代码C) 是否语义分析9.多遍编译与一遍编译的主要区别在于。
A)多遍编译是编译的五大部分重复多遍执行,而一遍编译是五大部分只执行一遍;B)一遍编译是对源程序分析一遍就立即执行,而多遍编译是对源程序重复多遍分析再执行;C)多遍编译要生成目标代码才执行,而一遍编译不生成目标代码直接分析执行;D)多遍编译是五大部分依次独立完成,一遍编译是五大部分交叉调用执行完成。
10.编译程序分成“前端”和“后端”的好处是A)便于移植B)便于功能的扩充C)便于减少工作量D)以上均正确第二章练习题(文法与语言)一、选择题1.文法 G 产生的 (1) 的全体是该文法描述的语言。
A.句型B. 终结符集C. 非终结符集D. 句子2.若文法 G 定义的语言是无限集,则文法必然是 (2) A递归的 B 上下文无关的 C 二义性的 D 无二义性的3. Chomsky 定义的四种形式语言文法中, 0 型文法又称为(A)文法;1 型文法又称为(C)文法;2 型语言可由(G) 识别。
A 短语结构文法B 上下文无关文法C 上下文有关文法D 正规文法E 图灵机F 有限自动机G 下推自动机4.一个文法所描述的语言是(A);描述一个语言的文法是(B)。
编译原理8参考答案编译原理8参考答案编译原理是计算机科学中的一门重要课程,它研究的是将高级语言转化为机器语言的过程。
在编译原理的学习过程中,学生们经常会遇到各种难题,而参考答案则是帮助他们解决这些问题的有力工具。
下面是一些编译原理8的参考答案,希望能对学习者有所帮助。
1. 什么是编译器?编译器是一种将高级语言转化为机器语言的程序。
它负责将源代码进行词法分析、语法分析、语义分析等一系列处理,最终生成可执行的目标代码。
2. 请简述编译器的工作原理。
编译器的工作原理主要包括以下几个步骤:- 词法分析:将源代码分解为一个个的词法单元。
- 语法分析:根据语法规则将词法单元组织成语法树。
- 语义分析:对语法树进行类型检查、语义检查等操作。
- 中间代码生成:将语法树转化为中间代码,比如三地址码、四元式等。
- 代码优化:对中间代码进行优化,提高程序的执行效率。
- 目标代码生成:将优化后的中间代码转化为目标机器代码。
- 目标代码优化:对目标机器代码进行优化,进一步提高执行效率。
3. 什么是词法分析?词法分析是编译器的第一步,它将源代码分解为一个个的词法单元。
词法单元包括关键字、标识符、运算符、常量等。
词法分析器通常使用正则表达式、有限自动机等方法进行实现。
4. 什么是语法分析?语法分析是编译器的第二步,它根据语法规则将词法单元组织成语法树。
语法分析器通常使用上下文无关文法和语法分析算法(如LL(1)、LR(1)等)进行实现。
5. 什么是语义分析?语义分析是编译器的第三步,它对语法树进行类型检查、语义检查等操作。
语义分析器通常使用符号表、类型检查规则等进行实现。
6. 什么是中间代码生成?中间代码生成是编译器的第四步,它将语法树转化为中间代码。
中间代码是一种介于源代码和目标代码之间的抽象表示形式,可以是三地址码、四元式、虚拟机指令等。
7. 什么是代码优化?代码优化是编译器的第五步,它对中间代码进行优化,提高程序的执行效率。
第八章习题答案2、请将算术表达式翻-(a+b)*(c+d)+(a+b+c)翻译为:(1)四元式(2)三元式(3)间接三元式答:(2)三元式(3)间接三元式间接码表:三元式:4、修改图8.5中计算声明语句中的名字的类型及相对对峙的翻译方案,以允许在一个声明中可以同时声明多个变量名。
答:翻译方案如下:P->{ offset:= 0 } DD-> D;DD->LL->id,L1 {L.type = L1.type;L.width = L1.width;enter(id,name,L.type,offset;Offset:= offset +L.width}L->:T{ L.type = T.type;L.width = T.width;}T->integer { T.type = integer; T.width:= 4 }T->real { T.type= real; T.width:= 8 }T-> array[num] of T1 { T.type:= array(num.val, T1.type);T.width:= num.val X T1.width }T->^T1 {T.type:=pointer(T1.type); T.width : = 4 }7、利用8.11的翻译方案,将下面的赋值语句翻译成三地址代码:A[i,j] = B[i,j] + C[A[k,l]]+D[i+j]答:令:域宽为wA的维数为:da1,da2, 不变部分为na, B的维数为db1,db2, 不变部分nbC的维数为dc,不变部分ncD的维数为dd,不变部分nd,t1 := i*db1t1:= t1+jt2:= B-nbt3:=w*t1t4:=t2[t3]xb = t4;t1 := k*da1t1:= t1+lt2:= A-nat3:=w*t1t4:=t2[t3]xa = t4;t1:=xa;t2:=C-nc;t3:=w*t1t4:=t2[t3]xca:=t4t1:=i+j;t2:=D-nd;t3:=w*t1;t4:=t2[t3];xd=t4;t5:=xb+xca;t6:=t5+xd;t1 := i*da1t1:= t1+jt2:= A-nat3:=w*t1t2[t3]:=t6。