神经网络(RBF)讲课
- 格式:pptx
- 大小:936.49 KB
- 文档页数:27

RBF神经网络概述1 RBF神经网络的基本原理2 RBF神经网络的网络结构3 RBF神经网络的优点1 RBF神经网络的基本原理人工神经网络以其独特的信息处理能力在许多领域得到了成功的应用。
它不仅具有强大的非线性映射能力,而且具有自适应、自学习和容错性等,能够从大量的历史数据中进行聚类和学习,进而找到某些行为变化的规律。
径向基函数(RBF)神经网络是一种新颖有效的前馈式神经网络,它具有最佳逼近和全局最优的性能,同时训练方法快速易行,不存在局部最优问题,这些优点使得RBF网络在非线性时间序列预测中得到了广泛的应用。
1985年,Powell提出了多变量插值的径向基函数(Radial-Basis Function, RBF)方法。
1988年,Broomhead和Lowe首先将RBF应用于神经网络设计,构成了径向基函数神经网络,即RBF神经网络。
用径向基函数(RBF)作为隐单元的“基”构成隐含层空间,对输入矢量进行一次变换,将低维的模式输入数据变换到高维空间内,通过对隐单元输出的加权求和得到输出,这就是RBF网络的基本思想。
2 RBF神经网络的网络结构RBF网络是一种三层前向网络:第一层为输入层,由信号源节点组成。
第二层为隐含层,隐单元的变换函数是一种局部分布的非负非线性函数,他对中心点径向对称且衰减。
隐含层的单元数由所描述问题的需要确定。
第三层为输出层,网络的输出是隐单元输出的线性加权。
RBF网络的输入空间到隐含层空间的变换是非线性的,而从隐含层空间到输出层空间的变换是线性。
不失一般性,假定输出层只有一个隐单元,令网络的训练样本对为,其中为训练样本的输入,为训练样本的期望输出,对应的实际输出为;基函数为第个隐单元的输出为基函数的中心;为第个隐单元与输出单元之间的权值。
单输出的RBF网络的拓扑图如图1所示:图1RBF网络的拓扑图当网络输入训练样本时,网络的实际输出为:(1)通常使用的RBF有:高斯函数、多二次函数(multiquadric function)、逆多二次函数、薄板样条函数等。
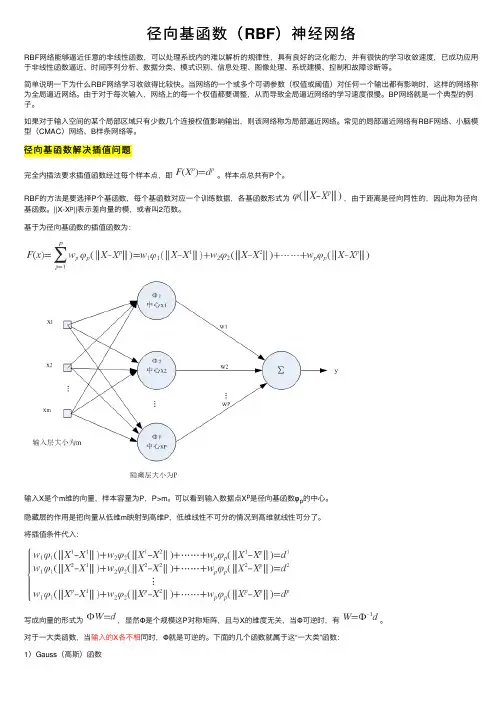
径向基函数(RBF)神经⽹络RBF⽹络能够逼近任意的⾮线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能⼒,并有很快的学习收敛速度,已成功应⽤于⾮线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
简单说明⼀下为什么RBF⽹络学习收敛得⽐较快。
当⽹络的⼀个或多个可调参数(权值或阈值)对任何⼀个输出都有影响时,这样的⽹络称为全局逼近⽹络。
由于对于每次输⼊,⽹络上的每⼀个权值都要调整,从⽽导致全局逼近⽹络的学习速度很慢。
BP⽹络就是⼀个典型的例⼦。
如果对于输⼊空间的某个局部区域只有少数⼏个连接权值影响输出,则该⽹络称为局部逼近⽹络。
常见的局部逼近⽹络有RBF⽹络、⼩脑模型(CMAC)⽹络、B样条⽹络等。
径向基函数解决插值问题完全内插法要求插值函数经过每个样本点,即。
样本点总共有P个。
RBF的⽅法是要选择P个基函数,每个基函数对应⼀个训练数据,各基函数形式为,由于距离是径向同性的,因此称为径向基函数。
||X-X p||表⽰差向量的模,或者叫2范数。
基于为径向基函数的插值函数为:输⼊X是个m维的向量,样本容量为P,P>m。
可以看到输⼊数据点X p是径向基函数φp的中⼼。
隐藏层的作⽤是把向量从低维m映射到⾼维P,低维线性不可分的情况到⾼维就线性可分了。
将插值条件代⼊:写成向量的形式为,显然Φ是个规模这P对称矩阵,且与X的维度⽆关,当Φ可逆时,有。
对于⼀⼤类函数,当输⼊的X各不相同时,Φ就是可逆的。
下⾯的⼏个函数就属于这“⼀⼤类”函数:1)Gauss(⾼斯)函数2)Reflected Sigmoidal(反常S型)函数3)Inverse multiquadrics(拟多⼆次)函数σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越⼩,宽度越窄,函数越具有选择性。
完全内插存在⼀些问题:1)插值曲⾯必须经过所有样本点,当样本中包含噪声时,神经⽹络将拟合出⼀个错误的曲⾯,从⽽使泛化能⼒下降。





RBF(径向基)神经⽹络 只要模型是⼀层⼀层的,并使⽤AD/BP算法,就能称作 BP神经⽹络。
RBF 神经⽹络是其中⼀个特例。
本⽂主要包括以下内容:什么是径向基函数RBF神经⽹络RBF神经⽹络的学习问题RBF神经⽹络与BP神经⽹络的区别RBF神经⽹络与SVM的区别为什么⾼斯核函数就是映射到⾼维区间前馈⽹络、递归⽹络和反馈⽹络完全内插法⼀、什么是径向基函数 1985年,Powell提出了多变量插值的径向基函数(RBF)⽅法。
径向基函数是⼀个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意⼀点c的距离,c点称为中⼼点,也就是Φ(x,c)=Φ(‖x-c‖)。
任意⼀个满⾜Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数,标准的⼀般使⽤欧⽒距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。
最常⽤的径向基函数是⾼斯核函数 ,形式为 k(||x-xc||)=exp{- ||x-xc||^2/(2*σ)^2) } 其中x_c为核函数中⼼,σ为函数的宽度参数 , 控制了函数的径向作⽤范围。
⼆、RBF神经⽹络 RBF神将⽹络是⼀种三层神经⽹络,其包括输⼊层、隐层、输出层。
从输⼊空间到隐层空间的变换是⾮线性的,⽽从隐层空间到输出层空间变换是线性的。
流图如下: RBF⽹络的基本思想是:⽤RBF作为隐单元的“基”构成隐含层空间,这样就可以将输⼊⽮量直接映射到隐空间,⽽不需要通过权连接。
当RBF的中⼼点确定以后,这种映射关系也就确定了。
⽽隐含层空间到输出空间的映射是线性的,即⽹络的输出是隐单元输出的线性加权和,此处的权即为⽹络可调参数。
其中,隐含层的作⽤是把向量从低维度的p映射到⾼维度的h,这样低维度线性不可分的情况到⾼维度就可以变得线性可分了,主要就是核函数的思想。
这样,⽹络由输⼊到输出的映射是⾮线性的,⽽⽹络输出对可调参数⽽⾔却⼜是线性的。
⽹络的权就可由线性⽅程组直接解出,从⽽⼤⼤加快学习速度并避免局部极⼩问题。



神经网络控制RBF神经网络是一种模拟人脑处理信息的计算模型,可以通过学习数据来预测和控制各种系统。
在控制领域,神经网络已经被广泛应用,很多控制问题可以通过神经网络来实现优化控制。
而基于类RBF(径向基函数)神经网络的控制方法也得到广泛的研究和应用,该方法是一种自适应控制方法,可以处理非线性系统,具有一定的理论和实际应用价值。
1. RBF神经网络控制方法RBF神经网络是一种前馈神经网络,由输入层、隐层和输出层组成。
其中,输入层接受外界输入,隐层包含一组RBF神经元,其作用是将输入空间划分为若干子空间,并将每个子空间映射到一个神经元上。
输出层是线性层,负责将隐层输出进行线性组合,输出控制信号。
在控制系统中,RBF神经元用于计算控制信号,从而实现控制目标。
RBF神经网络的训练包括两个阶段:聚类和权重调整。
聚类过程将输入空间划分成若干个类别,并计算出每个类别的中心和半径。
聚类算法的目标是使得同一类别内的样本距离聚类中心最小,不同类别之间距离最大。
常用的聚类算法包括k-means算法和LVQ算法。
权重调整过程将隐层神经元的权重调整到最优状态,以便将隐层输出映射到目标输出。
在实际控制中,RBF神经网络控制方法应用较为广泛,可以替代PID控制器等传统控制方法,具有良好的鲁棒性、自适应能力和较好的控制性能。
2. 基于RBF神经网络的控制方法RBF神经网络控制方法广泛应用于各种领域的控制任务,特别是在非线性系统控制中具有重要的应用价值。
基于RBF神经网络的控制方法主要包括以下两种:(1)虚拟控制策略:将系统建模为线性结构和非线性结构两部分,其中线性结构可以采用传统的控制方法进行控制,而非线性结构则采用基于RBF神经网络的控制方法进行控制。
虚拟控制策略的优点是可以将传统控制和RBF神经网络控制各自的优势融合起来,减小系统的复杂度和计算量。
(2)基于反馈线性化的控制策略:利用反馈线性化的方法将非线性系统变为一个可控的线性系统,从而可以采用传统线性控制方法进行控制。

课程目录⏹第一课MATLAB入门基础⏹第二课MATLAB进阶与提高⏹第三课BP神经网络⏹第四课RBF、GRNN和PNN神经网络⏹第五课竞争神经网络与SOM神经网络⏹第六课支持向量机(Support Vector Machine, SVM)⏹第七课极限学习机(Extreme Learning Machine, ELM)⏹第八课决策树与随机森林⏹第九课遗传算法(Genetic Algorithm, GA)⏹第十课粒子群优化(Particle Swarm Optimization, PSO)算法⏹第十一课蚁群算法(Ant Colony Algorithm, ACA)⏹第十二课模拟退火算法(Simulated Annealing, SA)⏹第十三课降维与特征选择RBF 神经网络概述• A radial basis function network is an artificial neural network that uses radial basis functions as activation functions.•It is a linear combination of radial basis functions.输入层隐含层输出层1,1IW 1b 2,1LW 2b p 1n 1a 2n 2a y =1R ⨯1S R⨯11S ⨯21S S ⨯21S ⨯2S 1S R 11,11()a radbas IW p b =-212,12()a purelin LW ab =+dist ∙*11S ⨯11S ⨯11S ⨯21S ⨯21S ⨯Problem•Assume that each case in the training set has two predictor variables, x and y.•Also assume that the target variable has two categories, positive which is denoted by a square and negative which is denoted by a dash.•suppose we are trying to predict the value of a new case represented by the triangle withpredictor values x=6, y=5.1.•Should we predict the target as positive or negative?• A generalized regression neural network (GRNN) is often used for function approximation. •It has a radial basis layer and a special linear layer.•It is similar to the radial basis network, but has a slightly different second layer.•The first layer is just like that for newrbe networks. It has as many neurons as there are input/ target vectors in P. The first-layer weights are set to P'. The bias b1 is set to a column vector of 0.8326/SPREAD.•The second layer also has as many neurons as input/target vectors, but here LW{2,1} is set to T.•Suppose you have an input vector p close to p i, one of the input vectors among the input vector/target pairs. This input p produces a layer 1 a i output close to 1. This leads to a layer 2 output close to t i.•Here the nprod box shown below (code function normprod) produces S2 elements in vector n2. Each element is the dot product of a row of LW2,1 and the input vector a1, all normalized by the sum of the elements of a1.• A larger spread leads to a large area around the input vector where layer 1 neurons will respond with significant outputs.•If spread is small, the radial basis function is very steep, so that the neuron with the weight vector closest to the input will have a much larger output than other neurons.•If spread becomes larger, the radial basis function's slope becomes smoother and several neurons can respond to an input vector. The network then acts as if it is taking a weighted average between target vectors whose design input vectors are closest to the new input vector.•The first-layer input weights, IW1,1 (net.IW{1,1}), are set to the transpose of the matrix formed from the Q training pairs, P'.•The second-layer weights, LW1,2 (net.LW{2,1}), are set to the matrix T of target vectors. Each vector has a1 only in the row associated with that particular class of input, and 0's elsewhere. (Use function ind2vecto create the proper vectors.)•newrbe–Design exact radial basis network–net = newrbe(P,T,spread)•newgrnn–Design generalized regression neural network–net = newgrnn(P,T,spread)•newpnn–Design probabilistic neural network–net = newpnn(P,T,spread)•cputime–Elapsed CPU time•round(ceil、fix、floor)–Round to nearest integer–Y = round(X)•length(size)– Length of vector– n = length(X)•find–Find indices and values of nonzero elements–[row,col] = find(X, ...)•.* ./ .\ .^ …… vs * / \ ^ ……– Multiplication (.*) right division (./) left division (.\) power (.^)–matrix multiplication (*) matrix right division (/) matrix left division (\) matrix power (^)案例分析RBF——近红外光谱汽油辛烷值预测GRNN、PNN——鸢尾花种类识别炼数成金逆向收费式网络课程⏹Dataguru(炼数成金)是专业数据分析网站,提供教育,媒体,内容,社区,出版,数据分析业务等服务。
RBF神经⽹络RBF神经⽹络RBF神经⽹络通常只有三层,即输⼊层、中间层和输出层。
其中中间层主要计算输⼊x和样本⽮量c(记忆样本)之间的欧式距离的Radial Basis Function (RBF)的值,输出层对其做⼀个线性的组合。
径向基函数:RBF神经⽹络的训练可以分为两个阶段:第⼀阶段为⽆监督学习,从样本数据中选择记忆样本/中⼼点;可以使⽤聚类算法,也可以选择随机给定的⽅式。
第⼆阶段为监督学习,主要计算样本经过RBF转换后,和输出之间的关系/权重;可以使⽤BP算法计算、也可以使⽤简单的数学公式计算。
1. 随机初始化中⼼点2. 计算RBF中的激活函数值,每个中⼼点到样本的距离3. 计算权重,原函数:Y=GW4. W = G^-1YRBF⽹络能够逼近任意⾮线性的函数(因为使⽤的是⼀个局部的激活函数。
在中⼼点附近有最⼤的反应;越接近中⼼点则反应最⼤,远离反应成指数递减;就相当于每个神经元都对应不同的感知域)。
可以处理系统内难以解析的规律性,具有很好的泛化能⼒,并且具有较快的学习速度。
有很快的学习收敛速度,已成功应⽤于⾮线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
当⽹络的⼀个或多个可调参数(权值或阈值)对任何⼀个输出都有影响时,这样的⽹络称为全局逼近⽹络。
由于对于每次输⼊,⽹络上的每⼀个权值都要调整,从⽽导致全局逼近⽹络的学习速度很慢,⽐如BP⽹络。
如果对于输⼊空间的某个局部区域只有少数⼏个连接权值影响输出,则该⽹络称为局部逼近⽹络,⽐如RBF⽹络。
RBF和BP神经⽹络的对⽐BP神经⽹络(使⽤Sigmoid激活函数)是全局逼近;RBF神经⽹络(使⽤径向基函数作为激活函数)是局部逼近;相同点:1. RBF神经⽹络中对于权重的求解也可以使⽤BP算法求解。
不同点:1. 中间神经元类型不同(RBF:径向基函数;BP:Sigmoid函数)2. ⽹络层次数量不同(RBF:3层;BP:不限制)3. 运⾏速度的区别(RBF:快;BP:慢)简单的RBF神经⽹络代码实现# norm求模,pinv求逆from scipy.linalg import norm, pinvimport numpy as npfrom matplotlib import pyplot as pltimport matplotlib as mplmpl.rcParams["font.sans-serif"] = ["SimHei"]np.random.seed(28)class RBF:"""RBF径向基神经⽹络"""def__init__(self, input_dim, num_centers, out_dim):"""初始化函数:param input_dim: 输⼊维度数⽬:param num_centers: 中间的核数⽬:param out_dim:输出维度数⽬"""self.input_dim = input_dimself.out_dim = out_dimself.num_centers = num_centersself.centers = [np.random.uniform(-1, 1, input_dim) for i in range(num_centers)] self.beta = 8self.W = np.random.random((self.num_centers, self.out_dim))def _basisfunc(self, c, d):return np.exp(-self.beta * norm(c - d) ** 2)def _calcAct(self, X):G = np.zeros((X.shape[0], self.num_centers), float)for ci, c in enumerate(self.centers):for xi, x in enumerate(X):G[xi, ci] = self._basisfunc(c, x)return Gdef train(self, X, Y):"""进⾏模型训练:param X: 矩阵,x的维度必须是给定的n * input_dim:param Y: 列的向量组合,要求维度必须是n * 1:return:"""# 随机初始化中⼼点rnd_idx = np.random.permutation(X.shape[0])[:self.num_centers]self.centers = [X[i, :] for i in rnd_idx]# 相当于计算RBF中的激活函数值G = self._calcAct(X)# 计算权重==> Y=GW ==> W = G^-1Yself.W = np.dot(pinv(G), Y)def test(self, X):""" x的维度必须是给定的n * input_dim"""G = self._calcAct(X)Y = np.dot(G, self.W)return Y测试上⾯的代码:# 构造数据n = 100x = np.linspace(-1, 1, n).reshape(n, 1)y = np.sin(3 * (x + 0.5) ** 3 - 1)# RBF神经⽹络rbf = RBF(1, 20, 1)rbf.train(x, y)z = rbf.test(x)plt.figure(figsize=(12, 8))plt.plot(x, y, 'ko',label="原始值")plt.plot(x, z, 'r-', linewidth=2,label="预测值")plt.legend()plt.xlim(-1.2, 1.2)plt.show()效果图⽚:RBF训练RBF函数中⼼,扩展常数,输出权值都应该采⽤监督学习算法进⾏训练,经历⼀个误差修正学习的过程,与BP⽹络的学习原理⼀样.同样采⽤梯度下降爱法,定义⽬标函数为:ei为输⼊第i个样本时候的误差。
RBF神经网络:原理详解和MATLAB实现——2020年2月2日目录RBF神经网络:原理详解和MATLAB实现 (1)一、径向基函数RBF (2)定义(Radial basis function——一种距离) (2)如何理解径向基函数与神经网络? (2)应用 (3)二、RBF神经网络的基本思想(从函数到函数的映射) (3)三、RBF神经网络模型 (3)(一)RBF神经网络神经元结构 (3)(二)高斯核函数 (6)四、基于高斯核的RBF神经网络拓扑结构 (7)五、RBF网络的学习算法 (9)(一)算法需要求解的参数 (9)0.确定输入向量 (9)1.径向基函数的中心(隐含层中心点) (9)2.方差(sigma) (10)3.初始化隐含层至输出层的连接权值 (10)4.初始化宽度向量 (12)(二)计算隐含层第j 个神经元的输出值zj (12)(三)计算输出层神经元的输出 (13)(四)权重参数的迭代计算 (13)六、RBF神经网络算法的MATLAB实现 (14)七、RBF神经网络学习算法的范例 (15)(一)简例 (15)(二)预测汽油辛烷值 (15)八、参考资料 (19)一、径向基函数RBF定义(Radial basis function——一种距离)径向基函数是一个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意一点c的距离,c点称为中心点,也就是Φ(x,c)=Φ(‖x-c‖)。
任意一个满足Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数。
标准的一般使用欧氏距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。
在神经网络结构中,可以作为全连接层和ReLU层的主要函数。
如何理解径向基函数与神经网络?一些径向函数代表性的用到近似给定的函数,这种近似可以被解释成一个简单的神经网络。
径向基函数在支持向量机中也被用做核函数。
常见的径向基函数有:高斯函数,二次函数,逆二次函数等。