数据挖掘原理与SPSSClementine应用宝典支持向量机
- 格式:ppt
- 大小:1.56 MB
- 文档页数:5



数据挖掘领域的十大经典算法原理及应用数据挖掘是指从大量的数据中发现关联规则、分类模型、聚类模型等有用的信息的过程。
以下是数据挖掘领域的十大经典算法原理及应用:1. 决策树算法(Decision Tree)决策树是一种基于树形结构的分类模型,它通过构建树来将输入数据集划分为不同的类别。
决策树算法在金融风险评估、医疗诊断等领域有广泛应用。
2. 支持向量机算法(Support Vector Machine,SVM)支持向量机是一种二分类模型,其目标是在高维空间中找到一个最优的超平面,将不同类别的样本分离开来。
SVM在图像识别、文本分类等领域有广泛应用。
3. 神经网络算法(Neural Network)神经网络模拟人脑的工作原理,通过连接众多的神经元来完成学习和预测任务。
神经网络在图像处理、自然语言处理等领域有广泛应用。
4. 朴素贝叶斯算法(Naive Bayes)朴素贝叶斯算法是一种基于贝叶斯定理的统计分类方法,它假设所有特征之间相互独立,并通过计算后验概率来进行分类。
朴素贝叶斯在垃圾邮件过滤、文本分类等领域有广泛应用。
5. K均值聚类算法(K-means Clustering)K均值聚类是一种无监督学习算法,它通过将样本分成K个簇来实现数据的聚类。
K均值聚类在市场细分、客户群体分析等领域有广泛应用。
6. Apriori算法Apriori算法是一种频繁项集挖掘算法,它可以找出数据集中项之间的关联关系。
Apriori算法在购物篮分析、推荐系统等领域有广泛应用。
7. PageRank算法PageRank算法是一种用于网页排序的算法,它通过计算网页之间的链接关系来确定网页的重要性。
PageRank算法在引擎领域有广泛应用。
8. 随机森林算法(Random Forest)随机森林是一种集成学习算法,它通过构建多个决策树,并通过投票方式来进行分类或回归。
随机森林在金融风险评估、信用评分等领域有广泛应用。
9. AdaBoost算法AdaBoost是一种迭代的强学习算法,它通过调整样本权重来训练多个弱分类器,并通过加权投票方式来进行分类。

目录SPSS Clementine 数据挖掘入门(1) (2)客户端基本界面 (3)项目区 (3)工具栏 (3)源工具(Sources) (3)记录操作(Record Ops)和字段操作(Field Ops) (4)图形(Graphs) (4)输出(Output) (4)模型(Model) (4)数据流设计区 (4)管理区 (5)Outputs (5)Models (5)SPSS Clementine 数据挖掘入门(2) (6)1.定义数据源 (7)2.理解数据 (8)3.准备数据 (9)4.建模 (14)5.模型评估 (15)6.部署模型 (17)SPSS Clementine 数据挖掘入门(3) (18)分类 (21)决策树 (21)Naïve Bayes (24)神经网络 (26)回归 (27)聚类 (28)序列聚类 (31)关联 (32)SPSS Clementine 数据挖掘入门(1)SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
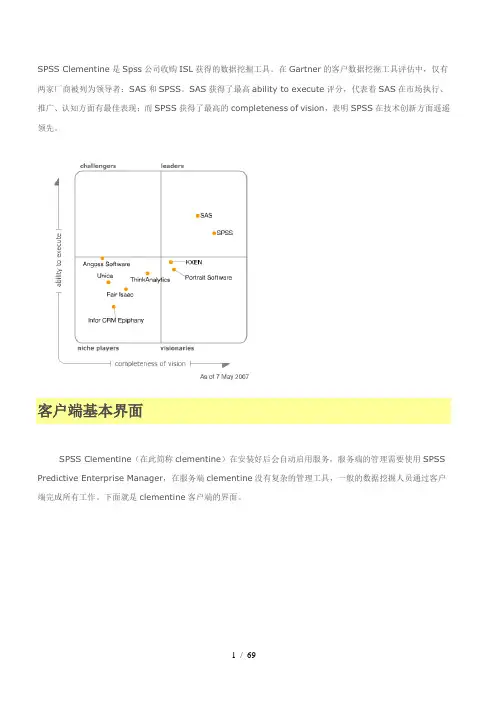
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面 ^_’项目区顾名思义,是对项目的管理,提供了两种视图。

支持向量机在数据挖掘中的应用数据挖掘已经成为了当今IT领域中最热门的技术之一,在大数据时代,它的应用越来越广泛。
支持向量机(Support Vector Machine,SVM)作为一种高效、精准的分类算法,在数据挖掘中发挥了重要的作用。
本文将重点介绍SVM在数据挖掘中的应用。
一、什么是支持向量机支持向量机是一种基于统计学习理论的二分类模型。
与逻辑回归、朴素贝叶斯、决策树等分类算法不同,支持向量机可以处理高维空间和非线性问题,且具有较高的准确性。
从本质上来说,SVM利用支持向量的概念,寻找最优的超平面来分类数据点。
支持向量是指与分离超平面最近的数据点,他们决定了分离超平面的位置和方向。
最优超平面是指能最好地分离两类数据点的平面。
SVM可以分为线性SVM和非线性SVM两种类型。
线性SVM通常可以处理线性可分问题,即可以找到一条直线把两类数据点分开。
非线性SVM则可以处理非线性可分问题,通过使用核函数将输入空间映射到高维空间进行处理。
二、SVM在数据挖掘中的应用1. 图像分类在计算机视觉领域中,SVM被广泛用于图像分类。
图像由像素组成,每个像素都有相应的特征值。
数据挖掘可以在这些特征值上进行分类,而SVM能够在高维特征空间中精确分类。
通过SVM对图像进行分类,可以实现图像检索、图像识别等应用。
2. 文本分类在文本挖掘中,SVM也是一种非常有效的分类算法。
文本通常具有高维度、稀疏性,因此与图像处理中类似,SVM也可以应用于文本特征的提取和分类。
通过SVM对文本进行分类,可以实现情感分析、垃圾邮件过滤等应用。
3. 生物信息学在生物信息学领域中,SVM可应用于基因表达数据、DNA特征分类等任务。
因为生物信息学需要分类问题解决各种不同性质的数据,而SVM能够比较好地处理高维、复杂、非线性数据,因此在生物信息学中应用广泛。
4. 金融风险预测在金融领域中,SVM可以用于风险评估、欺诈检测等领域。
以信用卡欺诈检测为例,信用卡欺诈的数据是非常稀疏的,而SVM能够通过对这些数据进行特征工程和分类,识别和预测欺诈行为。

SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:)。


支持向量机算法在数据挖掘中的应用研究随着机器学习和数据挖掘的快速发展,越来越多的算法被提出来并成功地应用到各个领域。
其中,支持向量机(Support Vector Machine,SVM)算法是非常常见的一个。
支持向量机算法起源于1990年代,它是一种基于统计学习理论的非线性监督学习算法。
它最初的目的是解决分类问题,但后来又成功应用于回归问题和异常检测等领域。
支持向量机算法最鲜明的特点是:通过寻找一个最优超平面来将数据分成两类,这个超平面是能够使得不同类别的数据点之间的最大间隔最小的平面。
如果数据不能被一个超平面完美分开,那么可以通过引入核函数,将数据映射到一个高维空间,使得它们可以被一个超平面分开。
这个算法在数据挖掘领域的应用非常广泛。
下面我将从预测分析、文本分类、图像识别和异常检测几个方面来谈谈我对支持向量机算法在数据挖掘中应用的一些思考。
一、预测分析支持向量机算法的应用已经从分类问题扩展到了回归问题。
在预测分析领域,支持向量机算法可以应用于多元回归、时间序列预测等方面。
在多元回归问题中,通常涉及到多变量之间的复杂关系。
通过支持向量机算法,我们可以将所有变量之间的非线性关系都考虑进去,找到一个能够最大程度地解释数据的模型。
相对于其他算法,支持向量机算法具有更好的稳定性和预测精度,因为它不会受数据的噪声和异常值的影响。
二、文本分类在文本分类方面,支持向量机算法在众多的算法中也是非常适合的一种。
支持向量机算法的优点在于:一方面,它可以将文本映射到高维空间,从而能够克服文本特点本身造成的线性可分性不强的局限性。
另一方面,支持向量机算法在分类时具有较高的准确率和处理速度。
在文本分类的应用中,常常要考虑到的是怎么表示文本内容。
除了传统的“one-hot编码”之外,还可以使用tf-idf(tf: term frequency,表示某个词在文本中出现的频率;idf: inverse document frequency,表示该词在所有文档中出现的频率)来表示文本的特征。


支持向量机在数据挖掘中的应用分析随着数据时代的到来,数据挖掘越来越成为人们关注的焦点,而在数据挖掘算法中,支持向量机(Support Vector Machine, SVM)是一种广泛应用的机器学习算法。
本文将从支持向量机的定义、原理,以及它在数据挖掘中的应用等多个方面进行分析。
一、支持向量机的定义与原理支持向量机,也称为最大间隔分类器(Maximum Margin Classifier),是一种二分类模型,它的基本思想是在特征空间中寻找一个最优的超平面,使得能够将不同类别的样本分开,并且距离最近的样本点与该超平面之间的距离(即间隔)最大化。
支持向量机的决策边界是通过训练集中的少数支持向量点来决定的。
与许多其他机器学习算法相比,支持向量机的性能优势在于:1.具备较好的泛化性能支持向量机通过最大化间隔来学习分类器,这意味着它更加关注于训练数据中与决策边界最靠近的样本点,可以有效地避免过拟合的问题。
因此,在未知数据的预测问题中,支持向量机具有较好的泛化性能。
2.可以处理高维数据支持向量机最初被设计用于处理二维空间中不可分的数据,但是随着它的发展,支持向量机可以处理高维数据,因为超平面可以在高维空间中更加明显地分割样本点。
二、支持向量机在数据挖掘中的应用1.文本分类支持向量机在文本分类中具有较好的性能。
在传统的文本分类中,传统的方法通常是将文本转化为向量表示,然后使用分类算法来对向量进行分类。
支持向量机的优势在于可以从高维度的向量中发现并且分类文本。
例如,在垃圾邮件分类中,支持向量机可以自动地区分垃圾邮件和正常邮件,从而有效地避免了垃圾邮件的困扰。
2.图像识别支持向量机在图像识别中也有较好的应用。
在人脸识别中,支持向量机可以从图像中提取特征,然后学习并区分人脸特征。
其分类器的准确性比传统的分类器要高很多。
此外,在鉴别其他物体时,支持向量机的分类器也能够以较高的精度识别出该物体。
3.医学诊断支持向量机在医学诊断中也有广泛的应用前景。
支持向量机在数据挖掘问题中的应用研究Ⅰ、引言随着社会发展和科技进步,我们所拥有的数据量越来越庞大,逐渐进入了“大数据”的时代。
如何从这些庞大的数据中,挖掘出对我们有价值的信息成为了人们关注的重点。
数据挖掘是一种重要的信息处理方式,支持向量机(Support Vector Machine,简称SVM)则是其重要的工具之一。
SVM是由Vapnik等人于1990年提出的一种学习模型,能解决分类和回归问题。
自提出后,SVM得到了广泛的研究和应用。
本文将从SVM的基本原理、算法流程以及其在数据挖掘等领域的应用等方面进行系统的介绍和分析。
Ⅱ、支持向量机的基本原理1、间隔和支持向量SVM是一种二分类问题的模型,将数据点根据其所处的特征空间进行标记。
如图1所示,红点为正例,蓝点为负例,用一条直线来分割它们。
图1 SVM模型图示当然,这个分割线有很多种可能。
我们如何选择最好的呢?其实,SVM是建立在间隔最大化的基础上的。
也就是说,我们想要找到一个最优解,使得分类的边界线离各个类别的样本都尽可能的远,同时也不能跨越样本的数据点。
我们定义距离这条边的最近的点为“支持向量”,如图2所示。
图2 支持向量示意图2、核函数在实际情况中,我们的分类问题可能并不是线性可分的。
这时,我们需要引入核函数的概念。
核函数可以将原本不可分的问题转化为更高维度的特征空间,在这个特征空间中就可以方便地完成分类。
核函数有多种选择,如线性核、多项式核、高斯核等。
其中,高斯核函数常常被用作非线性SVM。
3、SVM的数学表述SVM 的优化问题可以表示如下:$$\min_{w,b} \frac{1}{2}||w||^2$$$$s.t. \quad y_i(w^T\phi(x_i)+b) \geq 1,i=1,2,...,n$$其中,$w$ 为特征向量,$b$ 为偏置量,$y_i$ 表示 $x_i$ 的类别标记,$\phi$ 表示特征映射函数,$||w||^2$ 表示 $w$ 的二范数。
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:/esestt/archive/2007/06/03/769411.html)。
数据挖掘中的支持向量机算法原理解析数据挖掘是一门利用统计学、机器学习和数据库技术来发现模式、关系和趋势的学科。
而支持向量机(Support Vector Machine,SVM)是数据挖掘中一种常用的分类算法。
本文将深入探讨SVM算法的原理及其在数据挖掘中的应用。
一、SVM算法的基本原理SVM算法是一种监督学习算法,其基本原理是通过将数据映射到高维空间,构建一个最优的超平面来实现分类。
在SVM中,我们将数据看作是一个n维空间中的点,每个点都有一个对应的标签。
我们的目标是找到一个超平面,将不同类别的数据点分开,并使得超平面到最近数据点的距离最大化。
在SVM中,我们首先将数据映射到高维空间,然后通过寻找一个最优的超平面来实现分类。
这个最优的超平面被称为分离超平面,它可以将不同类别的数据点完全分开。
为了找到最优的分离超平面,我们需要解决一个优化问题,即最大化间隔。
二、SVM算法的优化问题在SVM中,我们的目标是找到一个最优的超平面,使得超平面到最近数据点的距离最大化。
这个最优化问题可以通过求解一个凸二次规划问题来实现。
具体来说,我们需要最小化一个目标函数,同时满足一些约束条件。
目标函数可以表示为:min 1/2 * ||w||^2,其中w是超平面的法向量。
约束条件可以表示为:yi(w·xi + b) ≥ 1,其中xi是数据点的特征向量,yi是数据点的标签,b是超平面的偏置。
通过求解这个凸二次规划问题,我们可以得到最优的超平面,从而实现数据的分类。
三、SVM算法的核函数在实际应用中,数据往往不是线性可分的,这时候就需要引入核函数来处理非线性问题。
核函数可以将数据从原始空间映射到一个更高维的空间,使得数据在新空间中线性可分。
常用的核函数有线性核函数、多项式核函数和径向基函数(RBF)核函数。
线性核函数适用于线性可分的数据,多项式核函数适用于多项式可分的数据,而RBF核函数适用于非线性可分的数据。