聚类分析与判别分析区别
- 格式:docx
- 大小:115.23 KB
- 文档页数:33


「聚类分析与判别分析」聚类分析和判别分析是数据挖掘和统计学中常用的两种分析方法。
聚类分析是一种无监督学习方法,通过对数据进行聚类,将相似的样本归为一类,不同的样本归入不同的类别。
判别分析是一种有监督学习方法,通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
本文将对聚类分析和判别分析进行详细介绍。
聚类分析是一种数据探索技术,其目标是在没有任何先验知识的情况下,将相似的样本聚集在一起,形成互相区别较大的样本群。
聚类算法根据样本的特征,将样本分为若干个簇。
常见的聚类算法有层次聚类、k-means聚类和密度聚类。
层次聚类是一种自下而上或自上而下的层次聚合方法,通过测量样本间的距离或相似性,不断合并或分裂簇,最终形成一个聚类树状结构。
k-means聚类将样本划分为k个簇,通过优化目标函数最小化每个样本点与其所在簇中心点的距离来确定簇中心。
密度聚类基于样本点的密度来判断是否属于同一簇,通过划定一个密度阈值来确定簇的分界。
聚类分析在很多领域中都有广泛的应用,例如市场分割、医学研究和社交网络分析。
在市场分割中,聚类分析可以将消费者按照其购买行为和偏好进行分组,有助于企业制定更精准的营销策略。
在医学研究中,聚类分析可以将不同患者分为不同的亚型,有助于个性化的治疗和药物开发。
在社交网络分析中,聚类分析可以将用户按照其兴趣和行为进行分组,有助于推荐系统和社交媒体分析。
相比之下,判别分析是一种有监督学习方法,其目标是通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
判别分析的目标是找到一个决策边界,使得同一类别内的样本尽可能接近,不同类别之间的样本尽可能远离。
常见的判别分析算法有线性判别分析(LDA)和逻辑回归(Logistic Regression)。
LDA是一种经典的线性分类方法,它通过对数据进行投影,使得同类样本在投影空间中的方差最小,不同类样本的中心距离最大。
逻辑回归是一种常用的分类算法,通过构建一个概率模型,将未知样本划分为不同的类别。


聚类分析、判别分析、主成分分析、因子分析主成分分析与因子分析的区别1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。
2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。
3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。
4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。
5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。
6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS 根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。
7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。
当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。
1 、聚类分析基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。
目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。


判别分析与聚类分析判别分析与聚类分析是数据分析领域中常用的两种分析方法。
它们都在大量数据的基础上通过统计方法进行数据分类和归纳,从而帮助分析师或决策者提取有用信息并作出相应决策。
一、判别分析:判别分析是一种有监督学习的方法,常用于分类问题。
它通过寻找最佳的分类边界,将不同类别的样本数据分开。
判别分析可以帮助我们理解和解释不同变量之间的关系,并利用这些关系进行预测和决策。
判别分析的基本原理是根据已知分类的数据样本,建立一个判别函数,用来判断未知样本属于哪个分类。
常见的判别分析方法包括线性判别分析(LDA)和二次判别分析(QDA)。
线性判别分析假设各类别样本的协方差矩阵相同,而二次判别分析则放宽了这个假设。
判别分析的应用广泛,比如在医学领域可以通过患者的各种特征数据(如生理指标、疾病症状等)来预测患者是否患有某种疾病;在金融领域可以用来判断客户是否会违约等。
二、聚类分析:聚类分析是一种无监督学习的方法,常用于对数据进行分类和归纳。
相对于判别分析,聚类分析不需要预先知道样本的分类,而是根据数据之间的相似性进行聚类。
聚类分析的基本思想是将具有相似特征的个体归为一类,不同类别之间的个体则具有明显的差异。
聚类分析可以帮助我们发现数据中的潜在结构,识别相似的群组,并进一步进行深入分析。
常见的聚类分析方法包括层次聚类分析(HCA)和k-means聚类分析等。
层次聚类分析基于样本间的相似性,通过逐步合并或分割样本来构建聚类树。
而k-means聚类分析则是通过设定k个初始聚类中心,迭代更新样本的分类,直至达到最优状态。
聚类分析在市场细分、社交网络分析、图像处理等领域具有广泛应用。
例如,可以将客户按照他们的消费喜好进行分组,以便为不同群体提供有针对性的营销活动。
总结:判别分析和聚类分析是两种常用的数据分析方法。
判别分析适用于已知分类的问题,通过建立判别函数对未知样本进行分类;聚类分析适用于未知分类的问题,通过数据的相似性进行样本聚类。


聚类分析聚类分析和判别分析有相似的作用,都是起到分类的作用。
但是,判别分析是已知分类然后总结出判别规则,是一种有指导的学习;而聚类分析则是有了一批样本,不知道它们的分类,甚至连分成几类也不知道,希望用某种方法把观测进行合理的分类,使得同一类的观测比较接近,不同类的观测相差较多,这是无指导的学习。
所以,聚类分析依赖于对观测间的接近程度(距离)或相似程度的理解,定义不同的距离量度和相似性量度就可以产生不同的聚类结果。
SAS/STAT中提供了谱系聚类、快速聚类、变量聚类等聚类过程。
谱系聚类方法介绍谱系聚类是一种逐次合并类的方法,最后得到一个聚类的二叉树聚类图。
其想法是,对于个观测,先计算其两两的距离得到一个距离矩阵,然后把离得最近的两个观测合并为一类,于是我们现在只剩了个类(每个单独的未合并的观测作为一个类)。
计算这个类两两之间的距离,找到离得最近的两个类将其合并,就只剩下了个类……直到剩下两个类,把它们合并为一个类为止。
当然,真的合并成一个类就失去了聚类的意义,所以上面的聚类过程应该在某个类水平数(即未合并的类数)停下来,最终的类就取这些未合并的类。
决定聚类个数是一个很复杂的问题。
设观测个数为,变量个数为,为在某一聚类水平上的类的个数,为第个观测,是当前(水平)的第类,为中的观测个数,为均值向量,为类中的均值向量(中心),为欧氏长度,为总离差平方和,为类的类内离差平方和,为聚类水平对应的各类的类内离差平方和的总和。
假设某一步聚类把类和类合并为下一水平的类,则定义为合并导致的类内离差平方和的增量。
用代表两个观测之间的距离或非相似性测度,为第水平的类和类之间的距离或非相似性测度。
进行谱系聚类时,类间距离可以直接计算,也可以从上一聚类水平的距离递推得到。
观测间的距离可以用欧氏距离或欧氏距离的平方,如果用其它距离或非相似性测度得到了一个观测间的距离矩阵也可以作为谱系聚类方法的输入。
根据类间距离的计算方法的不同,有多种不同的聚类方法。


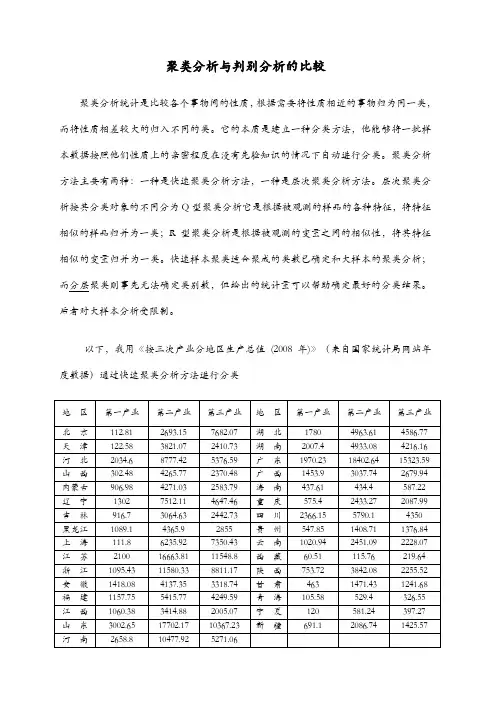
聚类分析与判别分析的比较聚类分析统计是比较各个事物间的性质,根据需要将性质相近的事物归为同一类,而将性质相差较大的归入不同的类。
它的本质是建立一种分类方法,他能够将一批样本数据按照他们性质上的亲密程度在没有先验知识的情况下自动进行分类。
聚类分析方法主要有两种:一种是快速聚类分析方法,一种是层次聚类分析方法。
层次聚类分析按其分类对象的不同分为Q型聚类分析它是根据被观测的样品的各种特征,将特征相似的样品归并为一类;R型聚类分析是根据被观测的变量之间的相似性,将其特征相似的变量归并为一类。
快速样本聚类适合聚成的类数已确定和大样本的聚类分析;而分层聚类则事先无法确定类别数,但给出的统计量可以帮助确定最好的分类结果。
后者对大样本分析受限制。
以下,我用《按三次产业分地区生产总值(2008年)》(来自国家统计局网站年度数据)通过快速聚类分析方法进行分类结果分析:从输出结果可以看出,当样本层次聚类分析成3个类时,样本的类归属情况:第一类包括7个省:北京、上海、安徽、福建、湖南、湖北、四川;第二类包含17个省:天津、山西、内蒙古、吉林、黑龙江、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆;第三类包含4省:河北、辽宁、浙江、河南;第四类包含3个省:江苏、山东、广东判别分析是另一种处理分类分体的统计方法。
它是先根据已知类别的事物的性质,建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。
判别分析的内容十分丰富,按照已知分类的多少,分成两组判别喝多组判别;按照判别方法分为逐步判别和序贯判别;按照判别则分为距离判别、贝叶斯判别和费歇判别等。
通过聚类分析我们已经知道以上31个省的分类情况,现在将福建、江西、山东、河南四个省的聚类结果删除掉。
然后进行判别分析。
得出结果如上图,福建,江西,山东,河南四省的判别结果与之前分类结果一样。
典型判别式函数系数函数1 2 3第一产业.000 .002 .001第二产业.001 -.001 .000第三产业.000 .001 .000(常量) -3.744 -1.017 -.516非标准化系数由此图得出三个函数(X1,X2,X3分别为第一产业、第二产业、第三产业)D1=-3.744+0.001X2D2==1.017+0.002X1-0.001X2+0.001X3D3=-0.516+0.001X1通过聚类分析和判别分析,我们得到了31省的分类结果。
聚类分析、判别分析、主成分分析、因子分析主成分分析与因子分析的区别1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。
2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。
3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。
4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。
5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。
6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。
7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。
当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。
1 、聚类分析基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。
目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。
判别分析(Discriminant Analysis)一、概述:判别问题又称识别问题,或者归类问题。
判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。
根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。
所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。
训练样本的要求:类别明确,测量指标完整准确。
一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。
判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。
半定量指标界于二者之间,可根据不同情况分别采用以上方法。
类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。
如何来表征相同属性、相同的特征指标呢?同一类别的个体之间距离小,不同总体的样本之间距离大。
距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距绝对距离马氏距离:(Manhattan distance)设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为(,)X与总体(类别)A的距离D X Y=(,)为D X A=明考斯基距离(Minkowski distance):明科夫斯基距离欧几里德距离(欧氏距离)二、Fisher两类判别一、训练样本的测量值A类训练样本编号 1x 2xm x1 11A x 12A x 1A m x 221A x22A x2A m xA n1A An x 2A An xA An m x 均数1A x2A xAm xB 类训练样本编号 1x 2x m x1 11B x 12B x 1B m x 221B x22B x2B m xB n1B Bn x 2B Bn x B Bn m x 均数1B x2B xBm x二、建立判别函数(Discriminant Analysis Function)为:1122m m Y C X C X C X =+++其中:1C 、2C 和m C 为判别系数(Discriminant Coefficient ) 可解如下方程组得判别系数。
第五章 聚类分析5.1 判别分析和聚类分析有何区别?答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
5.2 试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造?答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p 维空间的n 个点。
点之间的距离即可代表样品间的相似度。
常用的距离为(一)闵可夫斯基距离:1/1()()pq qij ikjk k d q XX ==-∑q 取不同值,分为(1)绝对距离(1q =) (2)欧氏距离(2q =) 21/21(2)()pij ikjk k d XX ==-∑(3)切比雪夫距离(q =∞)1()max ij ik jk k pd X X ≤≤∞=-(二)马氏距离(三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。
将变量看作p 维空间的向量,一般用 (一)夹角余弦(二)相关系数5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jkij k ik jkX X d L p X X =-=+∑cos pikjkijXX θ=∑()()piki jk j ij XX X X r --=∑式应遵循哪些原则?答: 设d ij 表示样品X i 及X j 之间距离,用D ij 表示类G i 及G j 之间的距离。