(完整版)python+xpath笔记
- 格式:doc
- 大小:16.98 KB
- 文档页数:3

py xpath用法XPath(XML Path Language)是一种用于在XML文档中定位节点的语言。
在Python中,我们可以使用lxml库来使用XPath来解析和定位XML文档中的节点。
首先,我们需要安装lxml库。
可以使用pip命令来安装lxml 库:pip install lxml.一旦安装了lxml库,我们就可以开始使用XPath来解析XML文档。
下面是一个简单的例子来说明如何使用XPath:python.from lxml import etree.# 假设我们有一个XML文档如下:# <bookstore>。
# <book category="COOKING">。
# <title lang="en">Everyday Italian</title>。
# <author>Giada De Laurentiis</author>。
# <year>2005</year>。
# <price>30.00</price>。
# </book>。
# <book category="CHILDREN">。
# <title lang="en">Harry Potter</title>。
# <author>J.K. Rowling</author>。
# <year>2005</year>。
# <price>29.99</price>。
# </book>。
# </bookstore>。
# 解析XML文档。
tree = etree.parse('books.xml')。

Python快速掌握Python爬⾍XPath语法1.什么是XPath?xpath是⼀门在XML和HTML⽂档中查找信息的语⾔,可⽤来在XML和HTML⽂档中对元素和属性进⾏遍历,XPath 通过使⽤路径表达式来选取 XML ⽂档中的节点或者节点集。
这些路径表达式和在常规的电脑⽂件系统中看到的表达式⾮常相似。
2.XPath语法想要学好xpath,⾸先要搞明⽩html⽂档中的节点。
以上是在⽹上随便找的⼀段html的⽂本,可以观察得到,div的标签下是ul标签,⽽ul标签下是li标签,于是发现html的标签是⼀级⼀级如树状的。
Xpath正是通过这样的⽅式去寻找。
以⽣活中举例,要确定⼀个⼈的位置,⾸先确定他在中国,然后确定他在某个省份,哪座城市,那个⼩区,最后找到他。
同级标签可以⽤li[1],li[2],li[3]的⽅式获取3.lxml库简单介绍⼀下lxml库,接下来会⽤到它lxml是⼀个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML 数据。
lxml和正则⼀样,也是⽤C实现的,是⼀款⾼性能的PythonHTML/XML解析器,可以利⽤之前学习的XPath语法,来快速的定位特定元素以及节点信息。
4.实际案例随便爬取⼀个⽹站,找到找到⽹站的html⽂本,如下图要找到title和href,仔细观察可以得到路径分别是//div[@id="resultList"]/div[@class="el"]/p/span/a/@title//div[@id="resultList"]/div[@class="el"]/p/span/a/@href运⾏如下:5.总结Xpath,是在爬⾍中常见的提取数据的⽅式之⼀,相⽐于正则,它更加简单⼀些,便于操作,xpath的难点在于准确的确定数据所在的位置。

python中⽤xpath匹配⽂本段落内容的技巧content = item.xpath('//div[@class="content"]/span')[0].xpath('string(.)')content = item.xpath('//div[@class="content"]/span//text()')两种匹配规则,都能匹配到图中的⽂本段落内容:第⼀种匹配到的结果是:"content":"\n\n\n⼩⼉⼦5岁天⽣戏精在⾼铁站,⼀对夫妻带⼀男孩也5岁左右,⼩男孩坐地上耍赖,⼩夫妻与⼩男孩全程英语交流,坐他们对⾯的⼩⼉⼦看的云⾥雾⾥,突然转过头跟我说,“妈妈,他们说的话我也会。
”正在我惊讶之际,这⼩⼦⼀⾸“ABCDEFG……”好吧~\n\n"第⼆种匹配到的结果是:"content":["\n\n\n⼩⼉⼦5岁天⽣戏精", "在⾼铁站,⼀对夫妻带⼀男孩也5岁左右,⼩男孩坐地上耍赖,⼩夫妻与⼩男孩全程英语交流,坐他们对⾯的⼩⼉⼦看的云⾥雾⾥,突然转过头跟我说,“妈妈,他们说的话我也会。
”", "正在我惊讶之际,这⼩⼦⼀⾸“ABCDEFG……”", "好吧~\n\n"]第⼀种匹配规则得到的content,内容中的<br/>⾃动忽略,得到包含全部字符内容的整串,但是原本⽤换⾏符断句处没有逗号,产⽣的内容阅读起来可能不连贯。
第⼆种匹配规则得到的content,也将忽略内容中的<br/>,同时会以<br/>为间隔,将⽂本内容⽤逗号切开,最终得到⼀个字符串列表。
在对⽂本内容要求⽐较精确的情况下,可以将第⼆种规则匹配后的结果,⽤ "\n".join() 来对字符串列表进⾏处理,不会出现不连贯情况。

python爬⾍之xpath的基本使⽤详解⼀、简介XPath 是⼀门在 XML ⽂档中查找信息的语⾔。
XPath 可⽤来在 XML ⽂档中对元素和属性进⾏遍历。
XPath 是 W3C XSLT 标准的主要元素,并且XQuery 和 XPointer 都构建于 XPath 表达之上。
⼆、安装pip3 install lxml三、使⽤1、导⼊from lxml import etree2、基本使⽤from lxml import etreewb_data = """<div><ul><li class="item-0"><a href="link1.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >first item</a></li><li class="item-1"><a href="link2.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >second item</a></li> <li class="item-inactive"><a href="link3.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >third item</a></li><li class="item-1"><a href="link4.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >fourth item</a></li><li class="item-0"><a href="link5.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >fifth item</a></ul></div>"""html = etree.HTML(wb_data)print(html)result = etree.tostring(html)print(result.decode("utf-8"))从下⾯的结果来看,我们打印机html其实就是⼀个python对象,etree.tostring(html)则是不全⾥html的基本写法,补全了缺胳膊少腿的标签。

Python xpath写法一、概述XPath(XML Path Language)是一门在 XML 文档中查找信息的语言,可以用来在 XML 文档中对元素和属性进行定位。
在 Python 中,使用 XPath 可以很方便地对 XML 或 HTML 文档进行解析和提取信息。
本文将介绍 Python 中使用 XPath 的写法,帮助读者更好地理解和应用这一技术。
二、导入相关库在使用 Python 进行 XPath 解析之前,需要导入相关的库。
通常情况下,我们会使用lxml 库进行XPath 解析。
在代码中需要先导入该库。
``` pythonfrom lxml import etree```三、XPath 基本写法在使用 Python 进行 XPath 解析时,需要掌握一些基本的写法规则。
下面将介绍几种常用的 XPath 写法。
1. 选取节点要选取节点,可以使用路径表达式。
路径表达式(Path Expression)用于选取 XML 文档中的节点或者节点集。
要选取 XML 文档中的所有<book> 节点,可以使用以下写法:``` pythonxpath = '//book'```2. 选取子节点如果要选取某个节点的子节点,可以使用斜杠(/)。
要选取 XML 文档中 <book> 节点的所有 <title> 子节点,可以使用以下写法:``` pythonxpath = '//book/title'```3. 选取父节点要选取某个节点的父节点,可以使用两个点(..)。
要选取 <title> 节点的父节点 <book>,可以使用以下写法:``` pythonxpath = '//title/..'```4. 选取指定属性的节点如果要选取具有指定属性的节点,可以使用方括号。
要选取所有带有category 属性的 <book> 节点,可以使用以下写法:``` pythonxpath = '//book[category]'```5. 选取指定条件的节点XPath 还支持使用谓语(Predicates)来选取满足指定条件的节点。

常用的XPath表达式一些常用的XPath表达式:/catalog/cd/price如果XPath的开头是一个斜线(/)代表这是绝对路径。
如果开头是两个斜线(//)表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。
以下的语法会选出文件中所有叫做cd的元素(在树中的任何层级都会被选出来)://cd选择未知的元素使用星号(Wildcards,*)可以选择未知的元素。
下面这个语法会选出/catalog/cd 的所有子元素:/catalog/cd/*以下的语法会选出所有catalog的子元素中,包含有price作为子元素的元素。
/catalog/*/price以下的语法会选出有两层父节点,叫做price的所有元素。
/*/*/price以下的语法会选择出文件中的所有元素。
//*要注意的是,想要存取不分层级的元素,XPath语法必须以两个斜线开头(//),想要存取未知元素才用星号(*),星号只能代表未知名称的元素,不能代表未知层级的元素。
选择分支使用中括号可以选择分支。
以下的语法从catalog的子元素中取出第一个叫做cd的元素。
XPath的定义中没有第0元素这种东西。
/catalog/cd[1]以下语法选择catalog中的最后一个cd元素:(XPathj并没有定义first() 这种函式喔,用上例的[1]就可以取出第一个元素。
/catalog/cd[last()]以下语法选出含有price子元素的所有/catalog/cd元素。
/catalog/cd[price]以下语法选出price元素的值等于10.90的所有/catalog/cd元素/catalog/cd[price=10.90]以下语法选出price元素的值等于10.90的所有/catalog/cd元素的price元素/catalog/cd[price=10.90]/price选择一个以上的路径使用Or操作数( ¦)就可以选择一个以上的路径。

python爬虫xpath用法Python是一种广泛应用于网络爬虫开发的编程语言。
在Python 中,XPath是一种非常强大的工具,用于在HTML或XML文档中定位和提取特定的内容。
XPath是一种基于路径表达式的查询语言,通过使用不同的节点和操作符,可以轻松地从网页中获取所需的数据。
使用XPath进行网页数据提取的步骤如下:步骤1:安装必要的库在进行XPath网页数据提取之前,需要先确保安装了相关的库。
使用pip命令安装"lxml"库,该库提供了XPath解析器和相关功能。
步骤2:导入必要的模块在Python脚本中,需要导入"lxml"库中的相关模块,以便于使用XPath功能。
导入的模块通常包括"lxml.etree"和"requests",其中"lxml.etree"用于解析和提取HTML或XML文档,"requests"用于发送HTTP请求并获取网页内容。
步骤3:发送HTTP请求并获取网页内容使用"requests"库发送HTTP请求,并获取网页内容。
可以使用"get"方法发送GET请求,并将返回的响应保存在一个变量中。
步骤4:解析网页内容使用"lxml.etree"模块中的"HTML"方法解析网页内容。
将获取到的网页内容作为参数传递给"HTML"方法,并将返回的解析树保存在一个变量中。
步骤5:使用XPath表达式提取数据使用XPath表达式定位和提取所需的数据。
在"lxml.etree"模块中,可以使用"xpath"方法,并将XPath表达式作为参数传递给该方法。
步骤6:处理提取的数据根据需求,对提取的数据进行进一步的处理和整理。

Python爬⾍之Xpath语法XPath 是⼀门在 XML ⽂档中查找信息的语⾔。
XPath ⽤于在 XML ⽂档中通过元素和属性进⾏导航。
XPath 含有超过 100 个内建的函数。
这些函数⽤于字符串值、数值、⽇期和时间⽐较、节点和 QName 处理、序列处理、逻辑值等等。
XPath 是 W3C 标准,XPath 于 1999 年 11 ⽉ 16 ⽇成为 W3C 标准。
XPath 被设计为供 XSLT、XPointer 以及其他 XML 解析软件使⽤。
在XPath 中,有七种类型的节点:元素、属性、⽂本、命名空间、处理指令、注释以及⽂档节点(或称为根节点)。
XML ⽂档是被作为节点树来对待的。
树的根被称为⽂档节点或者根节点。
⼀、选取节点常⽤的路径表达式:表达式描述实例nodename选取nodename节点的所有⼦节点xpath(‘//div’)选取了div节点的所有⼦节点/从根节点选取xpath(‘/div’)从根节点上选取div节点xpath(‘//div’)选取所有的div节点//选取所有的当前节点,不考虑他们的位置.选取当前节点xpath(‘./div’)选取当前节点下的div节点..选取当前节点的⽗节点xpath(‘..’)回到上⼀个节点@选取属性xpath(’//@calss’)选取所有的class属性⼆、谓词:被嵌在⽅括号内,⽤来查找某个特定的节点或包含某个制定的值的节点表达式结果xpath(‘/body/div[1]’)选取body下的第⼀个div节点xpath(‘/body/div[last()]’)选取body下最后⼀个div节点xpath(‘/body/div[last()-1]’)选取body下倒数第⼆个div节点xpath(‘/body/div[positon()<3]’)选取body下前两个div节点xpath(‘/body/div[@class]’)选取body下带有class属性的div节点xpath(‘/body/div[@class=”main”]’)选取body下class属性为main的div节点xpath(‘/body/div[price>35.00]’)选取body下price元素值⼤于35的div节点三、通配符:Xpath通过通配符来选取未知的XML元素表达式结果xpath(’/div/*’)选取div下的所有⼦节点xpath(‘/div[@*]’)选取所有带属性的div节点四、取多个路径:使⽤“ | 运算符可以选取多个路径表达式结果xpath(‘//div|//table’)选取所有的div和table节点五、Xpath轴:轴可以定义相对于当前节点的节点集轴名称表达式描述ancestor xpath(‘./ancestor::*’)选取当前节点的所有先辈节点(⽗、祖⽗)ancestor-or-self xpath(‘./ancestor-or-self::*’)选取当前节点的所有先辈节点以及节点本⾝attribute xpath(‘./attribute::*’)选取当前节点的所有属性child xpath(‘./child::*’)返回当前节点的所有⼦节点descendant xpath(‘./descendant::*’)返回当前节点的所有后代节点(⼦节点、孙节点)following xpath(‘./following::*’)选取⽂档中当前节点结束标签后的所有节点following-xpath(‘./following-sibing::*’)选取当前节点之后的兄弟节点sibingparent xpath(‘./parent::*’)选取当前节点的⽗节点preceding xpath(‘./preceding::*’)选取⽂档中当前节点开始标签前的所有节点preceding xpath(‘./preceding::*’)点preceding-sibling xpath(‘./preceding-sibling::*’)选取当前节点之前的兄弟节点self xpath(‘./self::*’)选取当前节点六、功能函数:使⽤功能函数能够更好的进⾏模糊搜索函数⽤法解释starts-with xpath(‘//div[starts-with(@id,”ma”)]‘)选取id值以ma开头的div节点contains xpath(‘//div[contains(@id,”ma”)]‘)选取id值包含ma的div节点and xpath(‘//div[contains(@id,”ma”) andcontains(@id,”in”)]‘)选取id值包含ma和in的div节点text()xpath(‘//div[contains(text(),”ma”)]‘)选取节点⽂本包含ma的div节点七、常⽤函数:1、精确定位(1)contains(str1,str2)⽤来判断str1是否包含str2例1://*[contains(@class,'c-summaryc-row ')]选择@class值中包含c-summary c-row的节点例2://div[contains(.//text(),'价格')]选择text()中包含价格的div节点(2)position()选择当前的第⼏个节点例1://*[@class='result'][position()=1]选择@class='result'的第⼀个节点例2://*[@class='result'][position()<=2]选择@class='result'的前两个节点(3)last()选择当前的倒数第⼏个节点例1://*[@class='result'][last()]选择@class='result'的最后⼀个节点例2://*[@class='result'][last()-1]选择@class='result'的倒数第⼆个节点(4)following-sibling 选取当前节点之后的所有同级节点例1://div[@class='result']/following-sibling::div选择@class='result'的div节点后所有同级div节点找到多个节点时可通过position确定第⼏个如://div[@class='result']/following-sibling::div[position()=1](5)preceding-sibling 选取当前节点之前的所有同级节点使⽤⽅法同following-sibling2、过滤信息(1)substring-before(str1,str2)⽤于返回字符串str1中位于第⼀个str2之前的部分例⼦:substring-before(.//*[@class='c-more_link']/text(),'条')返回.//*[@class='c-more_link']/text()中第⼀个'条'前⾯的部分,如果不存在'条',则返回空值(2)substring-after(str1,str2)跟substring-before类似,返回字符串str1中位于第⼀个str2之后的部分例1:substring-after(.//*[@class='c-more_link']/text(),'条')返回.//*[@class='c-more_link']/text()中第⼀个’条’后⾯的部分,如果不存在'条',则返回空值例2:substring-after(substring-before(.//*[@class='c-more_link']/text(),'新闻'),'条')返回.//*[@class='c-more_link']/text()中第⼀个'新闻'前⾯与第⼀个'条'后⾯之间的部分(3)normalize-space()⽤来将⼀个字符串的头部和尾部的空⽩字符删除,如果字符串中间含有多个连续的空⽩字符,将⽤⼀个空格来代替例⼦:normalize-space(.//*[contains(@class,'c-summaryc-row ')])(4)translate(string,str1,str2)假如string中的字符在str1中有出现,那么替换为str1对应str2的同⼀位置的字符,假如str2这个位置取不到字符则删除string的该字符例⼦:translate('12:30','03','54')结果:'12:45'3、拼接信息(1)concat()函数⽤于串连多个字符串例⼦:concat('',.//*[@class='c-more_link']/@href)。
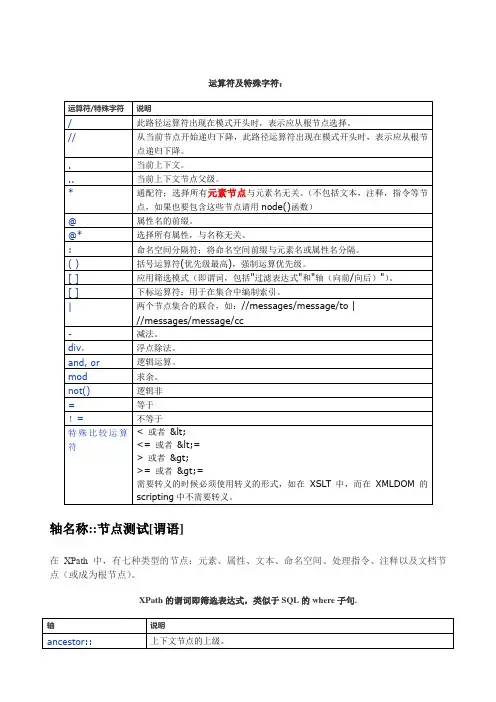
运算符及特殊字符:运算符/特殊字符 说明/ // . .. * @ @* : () [] [] | div, and, or mod not() = !=此路径运算符出现在模式开头时,表示应从根节点选择。
从当前节点开始递归下降,此路径运算符出现在模式开头时,表示应从根节 点递归下降。
当前上下文。
当前上下文节点父级。
通配符;选择所有元素节点与元素名无关。
(不包括文本,注释,指令等节 点,如果也要包含这些节点请用 node()函数) 属性名的前缀。
选择所有属性,与名称无关。
命名空间分隔符;将命名空间前缀与元素名或属性名分隔。
括号运算符(优先级最高),强制运算优先级。
应用筛选模式(即谓词,包括"过滤表达式"和"轴(向前/向后)") 。
下标运算符;用于在集合中编制索引。
两个节点集合的联合,如://messages/message/to | //messages/message/cc 减法。
浮点除法。
逻辑运算。
求余。
逻辑非 等于不等于 特 殊 比 较 运 算 < 或者 < <= 或者 <= 符 > 或者 > >= 或者 >= 需要转义的时候必须使用转义的形式,如在 XSLT 中,而在 XMLDOM 的 scripting 中不需要转义。
轴名称::节点测试[谓语]在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节 点(或成为根节点) 。
XPath 的谓词即筛选表达式,类似于 SQL 的 where 子句.轴 说明ancestor::上下文节点的上级。
上 下 文 节点 的 上 级由 上下 文 节 点的 父 级 以及 父级 的 父 级等 组 成; 因 此, ancestor:: 轴总是包括根节点,除非上下文节点就是根节点。
ancestor-or-self:: attribute:: child:: 上下文节点及其上级。

经常在工作中会使用到XPath的相关知识,但每次总会在一些关键的地方不记得或不太清楚,所以免不了每次总要查一些零碎的知识,感觉即很烦又浪费时间,所以对XPath归纳及总结一下。
在这篇文章中你将能学习到:•XPath简介•XPath 路径表达式详解•XPath在DOM,XSLT及XQuery中的应用XPath简介XPath是W3C的一个标准。
它最主要的目的是为了在XML1.0或X ML1.1文档节点树中定位节点所设计。
目前有XPath1.0和XPath2. 0两个版本。
其中Xpath1.0是1999年成为W3C标准,而XPath 2.0标准的确立是在2007年。
W3C关于XPath的英文详细文档请见:/TR/xpath20/。
XPath是一种表达式语言,它的返回值可能是节点,节点集合,原子值,以及节点和原子值的混合等。
XPath2.0是XPath1.0的超集。
它是对XPath1.0的扩展,它可以支持更加丰富的数据类型,并且X Path2.0保持了对XPath1.0的相对很好的向后兼容性,几乎所有的XPath2.0的返回结果都可以和XPath1.0保持一样。
另外XPath2. 0也是XSLT2.0和XQuery1.0的用于查询定位节点的主表达式语言。
XQuery1.0是对XPath2.0的扩展。
关于在XSLT和XQuery中使用XPath表达式定位节点的知识在后面的实例中会有所介绍。
在学习XPath之前你应该对XML的节点,元素,属性,原子值(文本),处理指令,注释,根节点(文档节点),命名空间以及对节点间的关系如:父(Parent),子(Children),兄弟(Sibling),先辈(Ancestor),后代(Descendant)等概念有所了解。
这里不在说明。
XPath路径表达式在本小节下面的内容中你将可以学习到:•路径表达式语法•相对/绝对路径•表达式上下文•谓词(筛选表达式)及轴的概念•运算符及特殊字符•常用表达式实例•函数及说明这里给出一个实例Xml文件。

在深入探讨 Python XPath 基本语法之前,我们首先需要了解什么是XPath。
XPath(XML Path Language)是一种用来在 XML 文档中定位节点的语言,同时也适用于 HTML 和 XHTML 文档。
Python 中的 XPath 主要用于解析 XML 或 HTML 文件,获取特定节点或元素的信息。
接下来,我们将深入探讨 Python 中 XPath 的基本语法,以便更好地理解和应用它。
1. XPath 基本语法XPath 语法非常灵活,可以根据不同的需求来定位和选择节点。
在Python 中,我们可以使用 lxml 库来实现 XPath 的解析和定位。
下面是 Python 中 XPath 的基本语法:1) 选择节点要选择节点,可以使用节点名称,例如:```//book```这表示选取文档中的所有 `<book>` 节点。
2) 路径表达式路径表达式用于选取 XML 文档中的节点或者节点集。
可以通过 `/` 或`//` 来指定路径。
例如:```/catalog/book/title```这表示选取 `<catalog>` 下的所有 `<book>` 下的 `<title>` 节点。
3) 谓语谓语用于查找满足条件的节点。
选取第二个 `<book>` 节点:```/catalog/book[2]```或者选取价格大于 30 的 `<book>` 节点:```/catalog/book[price>30]```4) 通配符通配符 `*` 用于选取所有元素节点或者匹配所有节点。
例如:```//* 选取文档中的所有节点//@class 选取名为 class 的所有属性```2. Python 中的实践在 Python 中,我们可以使用 lxml 库来实现对 XML 或 HTML 文档的解析和 XPath 定位。
Xpath语法详解1.简介XPath是⼀门在XML和HTML⽂档中查找信息的语⾔,可以⽤来在XML和HTML⽂档中对元素和属性进⾏遍历XPath的安装Chrome插件XPath Helper点Chrome浏览器右上⾓:更多⼯具-----扩展程序-----⾕歌商店--------勾选XPath Helper(需要FQ)2.语法详解#1.选取节点'''/ 如果是在最前⾯,代表从根节点选取,否则选择某节点下的某个节点.只查询⼦⼀辈的节点/html 查询到⼀个结果/div 查询到0个结果,因为根节点以下只有⼀个html⼦节点/html/body 查询到1个结果// 查询所有⼦孙节点//head/script//div. 选取当前节点.. 选取当前节点的⽗节点@ 选取属性//div[@id] 选择所有带有id属性的div元素<div id="sidebar" class="sidebar" data-lg-tj-track-code="index_navigation" data-lg-tj-track-type="1">'''#2.谓语'''谓语是⽤来查找某个特定的节点或者包含某个指定的值的节点,被嵌在⽅括号中。
//body/div[1] body下的第⼀个div元素//body/div[last()] body下的最后⼀个div元素//body/div[position()<3] body下的位置⼩于3的元素//div[@id] div下带id属性的元素<div id="sidebar" class="sidebar" data-lg-tj-track-code="index_navigation" data-lg-tj-track-type="1">//input[@id="serverTime"] input下id="serverTime"的元素模糊匹配//div[contains(@class,'f1')] div的class属性带有f1的通配符 *//body/* body下⾯所有的元素//div[@*] 只要有⽤属性的div元素//div[@id='footer'] //div 带有id='footer'属性的div下的所有div元素//div[@class='job_bt'] //dd[@class='job-advantage']运算符//div[@class='job_detail'] and @id='job_tent'//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
python的xpath方法Python的XPath方法XPath(XML Path Language)是一种在XML文档中定位节点的语言。
在Python中,我们可以使用XPath方法来解析XML文档,并通过指定XPath表达式来提取我们需要的数据。
在Python中,我们可以使用lxml库来实现XPath方法。
首先,我们需要安装lxml库,可以使用以下命令来安装:```pip install lxml```安装完成后,我们就可以开始使用XPath方法了。
1. 导入库我们需要导入lxml库和requests库(用于发送HTTP请求获取XML文档):```import requestsfrom lxml import etree```2. 发送HTTP请求获取XML文档使用requests库发送HTTP请求获取XML文档:```response = requests.get(url)xml_doc = response.content```3. 创建XPath解析对象使用lxml库的etree模块创建XPath解析对象:```xml_tree = etree.XML(xml_doc)xpath_parser = etree.XPathEvaluator(xml_tree)```4. 使用XPath表达式提取数据我们可以通过XPath表达式来提取我们需要的数据。
以下是一些常用的XPath表达式示例:- 提取所有的节点:```nodes = xpath_parser('//node')```- 提取指定节点的文本内容:```text = xpath_parser('//node/text()')```- 提取指定节点的属性值:```attribute = xpath_parser('//node/@attribute') ```- 提取符合条件的第一个节点:```node = xpath_parser('//node[condition][1]') ```- 提取符合条件的所有节点:```nodes = xpath_parser('//node[condition]')```- 提取符合条件的节点的文本内容:```text = xpath_parser('//node[condition]/text()')```- 提取符合条件的节点的属性值:```attribute = xpath_parser('//node[condition]/@attribute') ```5. 处理提取到的数据我们可以使用循环来处理提取到的数据,例如打印出文本内容:```for t in text:print(t)```或者保存到文件中:```with open('output.txt', 'w') as f:for t in text:f.write(t + '\n')```这样,我们就可以使用Python的XPath方法来解析XML文档并提取我们需要的数据了。
W3school:Xpath 基础学习XPath 基础学习目录1.XPath 概述 .................................................................................................................. 2 . 1.1 什么是 XPath? ....................................................................................................... 2 1.2 XPath 路径表达式 .............................................................................................. 21.3 XPath 标准函数 ..................................................................................................... 2 2.XPath 术语 ................................................................................................................. 2 . 3.XPath 语法 ................................................................................................................. 4 . 2.1 选取节点................................................................................................................... 4 2.2 谓语(Predicates) .............................................................................................. 5 2.3 选取未知节点........................................................................................................... 6 2.4 选取若干路径........................................................................................................... 6 4.XPath Axes(坐标轴) ........................................................................................... 7 . (坐标轴) 位置路径表达式 ............................................................................................................... 7 5.XPath 运算符 ............................................................................................................. 9 . 6. XML 实例文档 ............................................................................................................. 10 节点选取 ......................................................................................................................... 11 选取所有的 book 节点 ............................................................................................... 11 选取第一个 book 节点 ............................................................................................... 11 选取 price ..................................................................................................................... 11 选取价格高于 35 的 price 价格 .............................................................................. 12 选取价格高于 35 的 title 节点 ................................................................................ 121W3school:Xpath 基础学习1.XPath 概述 . 1.1 什么是 XPath?XPath 是一门在 XML 文档中查找信息的语言,用于在 XML 文档中通过元素和属性进行导航。
《深入理解Python中的XPath表达式语法》1. 引言在Python编程中,XPath(XML Path Language)是一种用于在XML文档中定位节点的语言,它广泛用于解析和提取XML数据。
在本文中,将深度探讨Python中的XPath表达式语法,帮助读者更全面、深入地理解这一主题。
2. XPath表达式基础XPath表达式是一种用于在XML文档中选取节点或者节点集的语法。
在Python中,我们可以使用lxml库来实现XPath表达式的解析和应用。
以下是一些常用的基础XPath表达式语法:2.1 节点选择在XPath中,节点选择是最基本的操作之一。
通过节点选择,我们可以定位和选取XML文档中的特定节点。
在Python中,可以使用"/"符号来表示节点选择操作。
`/bookstore/book`表示选取根节点下的所有book节点。
2.2 路径表达式路径表达式是XPath中的核心概念,它描述了节点之间的层级关系和路径。
在Python中,路径表达式可以使用"/"和"//"来表示。
"/"表示子节点,"//"表示后代节点。
`/bookstore//book`表示选取根节点下的所有book节点,包括子节点和后代节点中的book节点。
3. 深入理解XPath表达式语法在Python中,XPath表达式语法非常灵活,可以满足各种复杂的节点选择和路径表达需求。
在实际应用中,我们可以使用一些特殊的语法来实现更精确的节点选择和路径表达。
3.1 谓词谓词是XPath中用于过滤节点的重要概念。
在Python中,我们可以使用"[]"来添加谓词,对节点进行条件筛选。
`/bookstore/book[1]`表示选取根节点下的第一个book节点。
3.2 选取属性在XPath中,除了选取节点外,还可以选取节点的属性。
XPath学习总结一.学习XPath的先决条件1.为什么要用XPath为了使一个XML文档变得更加有用,它的内容常常需要呈现其他格式。
可能我们需要把它的内容加载到一个web页、一份时事通讯或其他的打印出版物;可能文档需要升级到一个它所符合的更新的DTD版本,或者通过使用其他的XML 词汇传送给商业伙伴;或者可能数据需要变为可利用的,以便加载到一个与XML 无关的电子数据表或遗产数据库。
产生所有这些XML的内容为基础的表单变化的普遍接受的标准是“可扩展样式表语言转换(Extensible Stylesheet Language Transformations,XSLT)”。
XSLT与XML路径语言(XML Path Language)一致,用于定位一个XML文档的特定部分,让我们能够在几乎任何的目标环境中,容易地再利用我们的文档内容。
Xpath采用类似于文件路径的表达式,与Dom相比可以快速定位xml文档中的内容,Dom需要迭代查找节点,效率低下。
2.节点和节点类型首先明确一下,节点和元素不是一个概念,在xml标准中没有节点的定义,是在dom中按树型结构来组织xml文档,才引入了节点的概念。
在DOM中节点和元素不是等价的。
“元素”是指一对标记(tag)及其内部包含的字符串值的总和,例如下面这就是一个元素:<Country>China</Country>但是它却不是一个节点,而是两个。
第一个节点是节点,它的值是null;第二个节点是一个文本节点(节点名是#text),它的值是"China\n"。
文本节点是节点的子节点。
一个节点是一个XML文档的一个离散的逻辑部件,一个节点可以在他们的范围内包含其他的相同或不同节点类型的节点。
例如,如下是一个表示雇员信息的XML文本:二.XPath(XML Path Language)标准XPath是在1999年11月16日和XSLT一起成为正式标准的。
python使⽤xpath获取页⾯元素的使⽤关于python 使⽤xpath获取⽹页信息的⽅法?1、xpath的使⽤⽅法?XPath 使⽤路径表达式来选取 XML ⽂档中的节点或节点集。
节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
常⽤路径表达式含义表达式描述/从根节点选取(取⼦节点)//选择的当前节点选择⽂档中的节点.选取当前节点。
…选取当前节点的⽗节点。
@选取属性*表⽰任意内容(通配符)|运算符可以选取多个路径常⽤功能函数函数⽤法解释startswith()xpath(‘//div[starts-with(@id,”ma”)]‘)#选取id值以ma开头的div节点contains()xpath(‘//div[contains(@id,”ma”)]‘)#选取id值包含ma的div节点and()xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘)#选取id值包含ma的div节点text()_.xpath('./div/div[4]/a/em/text()')#选取em标签下⽂本内容备注:1、html中当相同层次存在多个标签例如div,它们的顺序是从1开始,不是02、浏览器中使⽤开发者⼯具可以快速获取节点信息2、实例:#!/usr/bin/python3# -*- coding: utf-8 -*-# @Time : 2021/9/7 9:35# @Author : Sun# @Email : 8009@# @File : sun_test.py# @Software: PyCharmimport requestsfrom lxml import etreedef get_web_content():try:url = "htpps://***keyword=%E6%97%A0%E9%92%A2%E5%9C%88&wq=%E6%97%A0%E""9%92%A2%E5%9C%88&ev=1_68131%5E&pvid=afbf41410b164c1b91d""abdf18ae8ab5c&page=5&s=116&click=0 "header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/75.0.3770.100 Safari/537.36 "}response = requests.request(method="Get", url=url, headers=header)result = response.textreturn resultexcept TimeoutError as e:return Nonedef parsing():result = get_web_content()if result is not None:html = etree.HTML(result)# 先获取⼀个⼤的节点,包含了想要获取的所有信息ii = html.xpath('//*[@id="J_goodsList"]/ul/li')for _ in ii:# 采⽤循环,依次从⼤节点中获取⼩的节点内容# ''.join() 将列表中的内容拼接成⼀个字符串infoResult = {# @href 表⽰:获取属性为href的内容'href': "https:" + _.xpath('./div/div[1]/a/@href')[0],'title': ''.join(_.xpath('./div/div[2]/div/ul/li/a/@title')),# text()表⽰获取节点i⾥⾯的⽂本信息'price': _.xpath('./div/div[3]/strong/i/text()')[0],'info': ''.join(_.xpath('./div/div[4]/a/em/text()')).strip(),'province': _.xpath('./div/div[9]/@data-province')[0]}print(infoResult)else:raise Exception("Failed to get page information, please check!")return Noneif __name__ == '__main__':parsing()结果图⽚:到此这篇关于python使⽤xpath获取页⾯元素的使⽤的⽂章就介绍到这了,更多相关python xpath获取页⾯元素内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。