SPSS国家经济发展水平区域划分分析方法
- 格式:doc
- 大小:593.00 KB
- 文档页数:12

SPSS分析方法在国家经济发展水平区域划分中的应用10数计系《2》班:陈东东学号:1006111002摘要:本文运用数理统计方法对中国经济发展水平进行评价和区域划分。
首先采用各项统计指标建立指标体系,运用SPSS软件进行聚类分析,对我国的27个省和直辖市进行研究,分析各自的经济发展特点。
根据已有信息,利用判别分析的方法来建立判别函数,并对选择的对象进行回报判别,用回报率说明了方法的合理性;再对我国的另外4个省和直辖市进行判别归类,宏观分析验证通过Fisher判别建立的线性判别函数的正确性。
《1》问题概述:随着中国经济的发展和社会的进步,人民的生活水平日益提高,城镇居民的生活水平更是上了一个大台阶.由于改革开放以来,城镇的投资的加大和企业的增加,近年来各地城镇家庭收入逐年递增。
城镇家庭的收入增加,必然会导致家庭消费支出总额的增加和家庭消费支出结构的变化。
从最近几年的统计数据可以看出:城镇地区对吃穿等基本生活资料的消费呈下降趋势,而对于文化教育及医疗保健的支出消费逐年递增。
从城镇家庭收支的变化情况可以看出整个国家的经济增长状况,以小见大,为决策提供一定的依据。
聚类和判别都是分类学的基本方法,而分类学是人类认识世界的基础学科。
平时我们对事物的认识都需要对其进行分类。
为了研究现阶段的全国经济发展各时间段的差异,我们需要对时期的经济指标进行分类,以便更好的做出下一步的经济策略。
聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
判别分析则先根据已知的类别的事物的性质,利用某种技术建立函数式,然后对未知类型的新事物进行判断,将其归为已知的类别中。
聚类分析事先并不知道对象的类别的面貌,甚至连共有几个类别也不确定。
判别分析事先知道已知的对象的类别和类别数。
本文以2010年国家统计年鉴上公布的全国各地区城镇居民家庭平均每人全年消费性支出(2009年)作为数据源,将聚类分析和判别分析的原理运用到各个时期经济发展水平分类的研究上,对此问题进行统计分析。

全国地区经济发展水平的聚类和实例判别分析摘要:针对我国各省(直辖)市的2009年度经济数据,选取9个经济指标进行系统聚类分析,得到我国3类不同的地区经济类型;利用实例进行判别分析, 结合实际情况分析结果。
聚类结果为制订有针对性的地区经济发展战略提供依据。
关键词:SPSS;聚类分析;判别分析;区域经济。
1.引言由于传统的生产力布局造成的经济发展起点不同,加上地域、资源、技术和政策等条件的差异,各个地区的经济发展水平高低不齐。
因此,对各地区经济发展水平进行分类、比较和研究,总结出有助于经济发展的优势和阻碍经济发展的劣势,有针对性地制订地区经济发展战略,对促进国民经济协调发展有重要意义[1]。
聚类分析和判别分析是是进行以上分析的两个重要的方法。
1.1聚类分析定义。
聚类分析又称群分析、点群分析。
根据研究对象特征对研究对象进行分类的一种多元分析技术,把性质相近的个体归为一类,使得同一类中的个体都具有高度的同质性,不同类之间的个体具有高度的异质性。
聚类分析的基本思想。
我们所研究的样品或指标(变量)之间存在程度不同的相似性(亲疏关系),于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量作为划分类型的依据,把一些相似程度较大的样品(或指标)聚合为一类,把另外一些相似程度较大的样品(或指标)又聚合为另一类;关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有的样品(或指标)聚合完毕。
1.2判别分析定义。
判别分析是一种进行统计判别和分组的技术手段。
根据一定量案例的一个分组变量和相应的其他多元变量的已知信息,确定分组与其他多元变量之间的数量关系,建立判别函数,然后便可以利用这一数量关系对其他未知分组类型所属的案例进行判别分组。
判别分析的基本思想。
对已知分类的数据建立由数值指标构成的分类规则即判别函数,然后把这样的规则应用到未知分类的样本去分类。
本文针对我国各省(直辖)市的2009年度经济数据, 考虑到数据的可得性和来源的权威性,选取9个经济指标进行系统聚类分析,得到我国3类不同的地区经济类型;并利用实例进行判别分析,以确认聚类效果。

基于SPSS因子分析的全国各省市经济发展水平摘要随着经济的发展,传统的三大经济地带分类已不能满足现状。
虽然我国各地经济发展取得较大进展,但东西部之间贫富差距急剧扩大,因此缩小地区间差距,实现各地区协调发展有着重要的政治、经济、社会意义。
本文通过选取除港、澳、台之外的31个省市为样本,基于能够综合反映经济状况的多个指标,采用SPSS的因子分析的方法,选取了对社会发展状况影响较大的几个指标,对我国除台湾、香港、澳门在外的31个省市自治区的社会发展状况进行了分析与比较。
通过因子分析的方法可以从不同角度了解各省的人均GDP分布差异,从而体现出我国的综合经济实力,便于我们去寻找一些省市的特点和规律,从而了解各地发展优势所在和劣势所在,为了进一步更好地去改善和改革提供了一点可供参考的价值,也在此提出来一些看法和建议。
关键词:中国各省市;发展状况,因子分析引言改革开放以来,中国经济迅速发展。
中国作为世界经济的重要组成部分、近年来在经济建设中取得重大成就,但省内部却存在由北至南经济发展不平衡的现象,如何客观、定量的对全国各地区经济差异做出评价,提出有效解决国内经济发展不平衡的政策建议,促进全国全面经济协调发展,是目前有待解决的问题。
虽然我国的国民收入在全世界名列前茅,总体水平非常可观,面对我国十三亿的庞大人口,平均下来就是一个非常小的数目了,人均水平在世界中排在了后面。
比如一些贫富差距,卫生医疗方面,教育的投入方面投入不均,导致了诸多的问题。
本文通过利用因子分析方法对全国31个地区进行城市综合竞争力评价,讨论省市经济发展的特点,针对国内区域经济发展不平衡的问题,找出原因,并且利用所学知识,对全国区域经济协调发展提出政策建议。
改革开放以来,经济的快速发展带动力我国社会各方面的快速发展,但是由于我国国土辽阔,各地区所处自然环境、所拥有的自然资源不尽相同,各地区的经济发展的基础也不尽相同,因此我国各省市的社会发展状况也出现了较大的差异。

全国各地区经济发展状况的综合分析摘要:本文以2010年中国统计年鉴的数据为来源,通过对各省市、自治区、直辖市等地区多项经济指标进行因子分析。
随着社会经济的快速发展和社会主义建设的不断推进,我国经济社会得到了又好又快的发展,人民生活水平也得到了很大的提高,但是,由于我国各省市的经济背景、社会背景和环境背景等都存在着这样或那样的差异,从而导致了各地区生产总值、生活消费水平也参差不齐。
为了客观的了解我国各地区的经济发展状况,本文运用spss软件中的各种分析方法对我国各地区的经济发展状况情况进行科学的分析,并进行分类,并为各地区经济发展规划与决策提出了相应的政策建议。
关键词:全国各地区经济发展状况 spss 聚类分析因子分析引言改革开放以来,全国各地区的经济发展很快,人民生活水平有了很大的提高。
但是不同区域之间人民的生活水平存在很大差异,各地区生产总值也不相同,这也是各地区经济发展不平衡的比表现。
随着社会经济的快速发展和社会主义建设的不断推进,我国经济社会得到了又好又快的发展,人民生活水平也得到了很大的提高,但是,由于我国各省市的经济背景、社会背景和环境背景等都存在着这样或那样的差异,从而导致了各地区生产总值、生活消费水平也参差不齐。
一、数据来源和模型变量的选择说明1、下表是要进行处理的31个省市的全国各地区经济发展状况的原始数据,数据来源于《2010中国统计年鉴》。
表12、变量选择和说明地区生产总值:x1居民消费水平:x2固定资产投资:x3职工平均工资:x4居民消费价格指数:x5商品零售价格指数:x6货物周转量:x7工业总产值:x8二、数据处理3.1 聚类分析聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为Q型聚类和R型聚类,Q型聚类是对样品进行分类处理,R型聚类是对变量进行分类处理。
全国31个省市的全国各地区经济发展状况样品分别对8个变量的观测数据如表1所示,在SPSS中利用系统聚类法对其进行样品聚类分析。
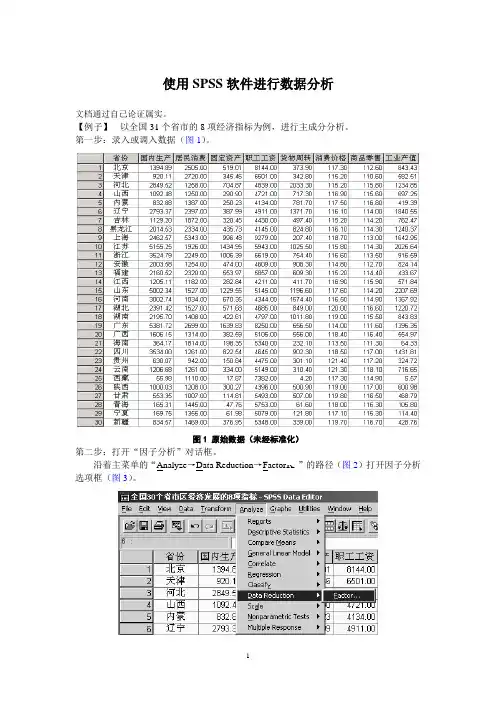
使用SPSS软件进行数据分析文档通过自己论证属实。
【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。

区域经济发展水平(一)江苏省旅游业发展现状近年来,江苏省旅游业的发展可谓突飞猛进,旅游总收入从2001年的744.1亿元增长到2023的2826.90亿元,短短7年之中旅游总收入增加近3倍。
全省旅游增加值从2001年的296.2亿元增加到了2023年的1249.50亿元,增长幅度之大有目共睹。
到2023年为止,全省旅游生产总值已经占到生产总值的4.9%。
2023年,全省各类旅游景区接待游客3.2亿人次,同比增长15.5%,年游客接待量100万人次以上的景区达到了68个。
旅游度假区经营管理取得新进展,2023年全省7个部级、省级旅游度假区共接待游客2137.5万人次,同比增长7.2%:实现营业收入46.2亿元,同比下降10.7%:招商项目203个,合同金额67.7亿元,其中外资5.6亿元。
2023年,全省公路、铁路、水路、航空等各种运输方式完成旅客运输量187240.54万人次,比上年增长16%:旅客周转量1596.06亿人,公里,比上年增长16.8%。
(二)江苏省旅游业发展存在的主要问题据2023年江苏省旅游业年度报告提供的统计数据,国内旅游收入全省排名第1、第2的苏州(570.34亿元)和南京(526.03亿元),分别是排名倒数第1、第2的宿迁(17.99亿元)和盐城(56.01亿元)的31.7倍和9.4倍:旅游外汇收入位于全省第1、第2的苏州(88916.27万美元)和南京(80763.71万美元)是位于全省末1、2位的宿迁(1188.18万美元)和淮安(2229.57万美元)的74.8倍和36.2倍。
从以上两组数据的对比不难发现,在江苏省旅游快速发展的背后,存在着巨大的区域发展不平衡性。
研究和协调这种旅游区域发展的不平衡性显然具有很强的现实意义。
二、江苏省旅游经济发展水平区域差异研究(一)江苏省旅游经济发展水平差异定量研究区域旅游经济的测度必须基于一定的指标,而且所选取的指标必须能反映各个区域旅游经济的整体状况,从经济角度研究旅游,可选取的指标主要有旅游外汇收入、国内旅游收入及旅游总收入等。

基于SPSS因子分析在地区经济发展综合评价中的应用一、研究背景与研究意义地区经济是国民经济的基础层次,任何国家的地区经济发展失衡都会使其面临严峻的挑战。
而我国各地区由于各种原因,经济发展水平有较大差异,尽管我国地区经济发展的不平衡通常是地区经济快速发展的特征之一,但缩小和规避内部差异是地区经济一体化和地区可持续发展的关键。
促进地区经济的发展,需要对经济能力、稳定的专业化生产力和地区经济目标的新机遇有充分的理解。
这一认识是规划加强地区经济发展和竞争力必备的基础要素,这些因素包括:人力资源、技术和创新、基础设施、管理、经营环境和市场定位。
导致地区发展不平衡的因素是多样化的,所以有必要用定量化的方法来进行评价并提出对策,从而正确选择重点投资区、实施重点地带(或城市)开发布局和带动战略。
这是促进我国经济持续发展、进一步缩小地区差异的重要途径之一,而对各地区经济进行综合评价是实现这一目标的科学参考和基本工作。
本文通过对《中国统计年鉴2007》中的我国各地区主要指标统计数据为依据,从地区经济实力水平、地区经济实力水平、产业结构、地区对外开放水平、地区文化教育和卫生水平、高等教育水平;、地区交通水平以及映地区环境保护水平等几个方面选取了28个指标,来反映我国地区经济发展水平的并应用因子分析方法对这些指标进行降维分析。
二、问题提出与变量选取由于地区经济复合系统结构非常复杂,单靠一个或几个指标往往难以客观评估一个地区的经济发展水平,所以需要建立指标体系来描述系统的发展状况。
指标太少或过于简单不能反映可持续发展的内涵,指标过少会对评估结果的精度产生影响,指标过多和过于复杂则不利于评估工作的开展。
本文从衡量地区发展的各类指标中选取了28个指标,如表错误!文档中没有指定样式的文字。
-1所示。
表错误!文档中没有指定样式的文字。
-1 变量符号及含义序号变量符号变量含义1 X1人均GDP(元)2 X2固定资本形成总额(亿元)3 X3工业企业单位个数(个)4 X4第一产业生产总值占比5 X5第三产业生产总值占比6 X6地方财政收入(万元)7 X7财政支出(万元)8 X8人均粮食占有量(公斤)9 X9居民消费支出(亿元)10 X10平均货币工资(元)11 X11总人口(万人)12 X12城镇人口比例13 X13各地区国际旅游外汇收入(亿美元)14 X14入境旅游人数(万人次)15 X15外商投资企业年底注册登记投资总额(亿美元)16 X16高等学校数(所)17 X17每十万人口在校生数(人)18 X18普通高等学校教职工数(人)19 X19各地区图书馆数(个)20 X20图书馆总藏量(千册)21 X21卫生机构数(个)22 X22铁路营业里程(公里)23 X23交通运输业客运量(万人)24 X24交通运输业货运量(万吨)25 X25邮电业务总量(亿元)26 X26城市人口密度(人每平方公里)27 X27生活垃圾无害化处理率(%)28 X28工业废水排放达标量(万吨)这里指标X2-X12主要是反映地区经济实力水平,X3-X5其中反映了产业结构;X13- X15主要是反映地区对外开放水平;X16-X21主要是反映地区文化教育和卫生水平,其中X16和X18反映了高等教育水平;X22-X25主要是反映地区交通邮电水平,从属于X5;X26-X28主要是反映地区环境保护水平。

<<SPSS统计分析软件>> 课程设计报告SPSS在经济中的应用分析摘要经济发展,是整个人类社会追求的目标之一。
在宏观经济理论中,经济的发展主要受到消费,投资,政府购买的影响。
在经济理论中,我们通常用GDP来描述经济的发展,同时GDP也会受到价格水平的影响。
衡量价格水平,我们一般用居民消费价格指数,商品零售价格指数来描述;投资一般用固定资产投资和工业总产值来衡量。
本文通过我国近20年的国内生产总值和影响国内生产总值的一些重要指标,如居民消费水平,财政支出,工业总产值,商品零售价格指数,居民消费价格指数,城镇居民收入,农村居民收入,能源消费总量等数据,利用SPSS软件提供的对各个影响因素的描述性统计分析,各个影响因素之间的相关性分析,回归分析,因子分析等方法对数据进行了深入的分析,并就分析结果所反映的问题给出了一些针对性的建议。
【关键词】经济发展描述统计相关性分析回归分析因子分析引言中国作为世界上的发展中国家,其经济实力及综合国力水平在近几十年的时间里都得到了长足的发展。
经济实力的不断攀升,以及经济增长速度的持续加速,令中国经济已成为世界各国所关注的焦点。
我国经济持续高速增长带来了社会财富的迅速增加,目前人均国内生产总值(GDP)迈过3000美元大关,已步入中等收入国家的行列。
那么影响GDP快速增长的原因有哪些?我国经济的迅速发展中是否还存在一些问题呢?是我们需要进一步探讨和研究的。
随着我国改革开放的实践和经济理论的发展,实证方法和数据分析成为了经济研究中的重要方面。
大量经验证据的分析和运用对于经济理论的发展和决策的支持都具有重要的意义。
而经济实证研究离不开现代统计分析方法的运用,SPSS作为统计分析工具,理论严谨、内容丰富,具有数据管理、统计分析、趋势研究、制表绘图、文字处理等功能。
为经济管理研究提供了有力的工具。
而因子分析,回归分析等方法是经济管理研究中常用的分析方法。

论文题目:基于各省市GDP、财政收入及财政支出数据的SPSS分析姓名:学号:班级:内容摘要:本文首先通过国家统计局官方网站收集了我国大陆31省市2010-2013年GDP、各省常年居住人口数、财政收入、社会保障与就业支出、交通运输支出、医疗卫生支出、教育支出等数据;而后根据要求对数据进行适当的处理,并选择了SPSS作为工具进行分析。
这其中既有东中西三个地区的地区生产总值之间的分布类型检验,又有关于GDP与各省常年居住人口数、财政收入、社会保障与就业支出、交通运输支出、医疗卫生支出、教育支出的相关性分析,以及各省GDP的方差分析。
根据分析的结果对我国GDP水平进行适当的探讨以及给出一些经济发展规划的建议。
1、题目要回答的问题自1978年改革开放以来,我国经济飞速发展,国内生产总值日趋上升,虽然经历了1997金融风暴和2008金融危机,但是我国经济发展前景一片大好,2011年,我国经济创造奇迹,GDP总量超过日本,一跃成为世界第二大经济体。
国内生产总值(简称GDP)是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。
它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。
一个国家或地区的经济究竟处于增长抑或衰退阶段,从这个数字的变化便可以观察到。
中共十八大报告指出中国现代化步入转型攻坚阶段,要继续坚持经济转型。
同时由于我国自身的一些发展条件限制,我国经济发展速度逐渐放缓,因而对我国GDP水平的研究就显得尤为必要。
由于对GDP的研究是一个非常复杂和庞大的过程,在这里,我们仅对以下几个问题做研究:1、分布类型检验①、正态分布检验采用假设检验方法对地区生产总值进行分布特征的检验,检验31个省市区的数据是否服从正态分布。
H0: 31个省市区的地区生产总值样本来自于一个正态分布的总体。
H1: 31个省市区的地区生产总值样本并非来自于一个正态分布总体。


基于SPSS的经济发展评价指标主成分分析姬艳曼;刘莹【摘要】The traditional principal component analysis needs to calculate manually processed data, so it ’s a heavy and complex job. In order to solve the above problem, this paper uses SPSS software for processing, it can automatically obtain standardized data and use economic data in 11 provinces from the country data in 2010 as the basis for experimental verification. Through the establishment of a comprehensive, scientific evaluation index system, this paper obtains comprehensive evaluation values of provinces. The results show that principal component of economic development based on SPSS evaluation analysis has feasibility and prospects, thereby providing supports for the formulation of policies.%传统的主成分分析法,要手动处理计算数据,工作量大且工作复杂。
为了解决以上问题,文章采用SPSS软件进行处理,可以自动得到标准化数据,并以国家数据网2010年11个省市的经济数据为基础,进行实验验证,通过建立一套完整、科学的评价指标体系,计算出各省市的综合评价值。
利用SPSS统计分析软件对B经济区进行区城市中心性测度利用SPSS统计分析软件对B经济区进行区城市中心性测度杨扬目录引言 (1)一、中国B经济区城市中心性测度..................................... 错误!未定义书签。
(一)因子分析法 (2)(二)城市中心性指标体系的构建 (3)(三)B经济区各城市中心性得分 (3)1. 相关系数矩阵分析 (3)2. 主成分提取分析 (4)3. 主成分载荷值及其指标归纳 (4)4. B经济区各城市中心性综合分析 (5)(四)结果分析 (6)1. 整体表现“一强多弱” (6)2. 经济的外向度和外资的整体拉动作用有待提高 (6)3. 人才队伍短缺,教育体制有待改善 (6)4. 制造业的发展分布严重不均衡,产业结构需要进一步优化 (6)三、提高B经济区各城市中心性的对策建议 (7)(一)以点带面,重点推进,协调发展 (7)1. 着力推动B经济区港城一体化 (7)2. 做好B经济区城市群的发展规划 (7)(二)改善投资环境,加大对外经济建设 (7)1. 改善外商投资融资环境 (7)2. 发展与周边国家地区经贸合作, 增强招商引资吸引力 (7)(三)完善教育体制,加强人才开发与队伍建设 (8)1. 加强教师培训,规范教学管理 (8)2. 建立统一开放的人才市场体系 (8)(四)增强城市产业支撑能力,优化产业结构 (8)1. 推动城市产业结构升级 (8)2. 优化城市产业空间布局 (8)参考文献 (9)1附录 (9)引言中心城市是指处于区域中心位置、具有带动区域发展功能的首位城市。
一般而言,中心城市是区域政治、经济、文化的中心,具有主导、协调、服务示范等功能。
其中协调与服务作用是主要的,城市越大,这种作用越明显。
随着市场经济的发展、工业化和城镇化的大规模推进,这种地域空间的结构、功能和地理尺度在集聚与扩散机制的交互作用下不断发生演进,从而出现了从城乡对立向城乡融合的转变、从各城镇独立发展向相互依赖发展的转变,进而在一些地理环境条件优越的地区形成了工业化和城镇化水平较高、城镇密集且相互联系密切的中心城市群。
摘要因子分析是利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。
它的基本思想是根据相关性大小把原始变量分组,使得同组之间变量相关性较高,不同组之间的变量的相关性则较低。
学会应用SPSS软件进行相关的因子分析,并将所学的知识结合SPSS对数据进行处理,可以更好地解决实际问题。
K均值法是非谱系聚类法的一种,非谱系聚类法是把样品聚类成K个类的集合,类的个数K可以预先给定,或者在聚类过程中确定,这种聚类方法在计算机计算过程中无须确定距离,也无须存储数据。
所以,K均值聚类可以应用于较大的数据组,它的思想是把每个样品聚集到其最近形心(均值)类中。
第三产业是一个国家国民经济中的重要组成部分,目前第三产业在世界各国得到了迅速的发展,已经成为发达国家的重要经济支柱,我国自从改革开发以来,第三产业得到了长足发展。
在发达国家,第三产业占国民经济的比重非常大,影响第三产业的因素有很多,本文试着通过对交通运输仓储和邮政业、批发和零售业、住宿和餐饮业、金融业、房地产业和其他的增加值指数的聚类分析和因子分析,探讨国家第三产业的发展情况。
关键词:spss;第三产业;聚类;因子分析目录1引言 (1)2数据来源 (1)3实验原理 (2)3.1因子分析的方法原理 (2)3.2聚类分析的思想原理 (2)4数据处理 (3)4.1因子分析的数据处理 (3)4.2聚类分析的数据处理 (8)5结果分析 (10)5.1因子分析的结果分析 (10)5.2聚类分析的结果分析 (11)附录 (12)参考文献 (15)1引言第三产业,又称第三次产业是指除第一、二产业以外的其他行业,是不生产物质产品的行业,即服务业。
第三产业一词首先是英国经济学家、新西兰奥塔哥大学教授费希尔1935年在《安全与进步的冲突》一书中首先提出来的。
第三产业主要包括流通、生产生活服务等部门。
第三产业的发展水平是衡量一个国家经济社会发展程度的重要标志。
SPSS数据分析专业:教育技术学姓名:刘耀博学号:0812100043一、我国城镇居民现状城市作为区域的中心,是一定地域内的经济聚集体。
城市和区域相互依存,彼此推动。
在市场经济条件下,相对一般城市而言,中心城市具有更为重要的作用。
中心城市的作用可以概括为若干“中心”,如商品流通中心、交通运输中心、金融服务中心、信息交流中心、科教文化中心等等,中心城市通过这样的“中心”对区域发展起带动作用。
今后我国经济发展离不开中心城市带动,完善区域性中心城市功能,加强中心城市对我国区域经济的组织和调控作用,实现二元经济向一元经济转化,是今后相当长一段时期内,推进我国城市化进程,加快中国经济增长的一个中心环节。
二、我国区域划级结构及趋势的统计分析下图是出自《中国统计年鉴—2009》这一资料性年刊,它系统收录了全国和各省、自治区、直辖市2008年经济、社会各方面的统计数据,以及近三十年和其他重要历史年份的全国主要统计数据。
此年鉴正文内容分为24个篇章,本文选取其中的第一篇章-综合,用以探究我国全国行政区在县级及低级市分布的差别。
一、原始数据二、 统计分析方法一:频数分析分析:有上述图表可得1、了解地级区划数在我国各个地理区域中的分布状况。
2、了解地级区划数落在12-16区间内的次数以及频率,其中14最多,百分比达15.6%,即在一个省中,地级区划数在14个的居多。
3、统计量全部有效,对被调查状况有所了解。
方法二:参数检验分析:由上述图表可以得出以下结论:1、95%的置信区间中地级区划数的数值范围是0.1688-41.4562。
2、p 大于a ,所以不能拒绝零假设,认为单个样本检验量与14没有显著差异。
14落在95%的置信区间内也证明了这一点。
方法三:相关分析分析:由上述图标可得1、 市辖区在一个省内的个数均值在53.4375,而县级市在一个省内的平均数量在22.9375个。
2、 县辖区与县级市的简单相关系数为0.995,它们的相关系数检验的概率p 值接近于0.因此,档显著性水平a 为0.05或0.01时,都应拒绝相关系数检验的零假设,认为两个总体存在线性关系。
SPSS分析方法在国家经济发展水平区域划分中的应用10数计系《2》班:陈东东学号:1006111002摘要:本文运用数理统计方法对中国经济发展水平进行评价和区域划分。
首先采用各项统计指标建立指标体系,运用SPSS软件进行聚类分析,对我国的27个省和直辖市进行研究,分析各自的经济发展特点。
根据已有信息,利用判别分析的方法来建立判别函数,并对选择的对象进行回报判别,用回报率说明了方法的合理性;再对我国的另外4个省和直辖市进行判别归类,宏观分析验证通过Fisher判别建立的线性判别函数的正确性。
《1》问题概述:随着中国经济的发展和社会的进步,人民的生活水平日益提高,城镇居民的生活水平更是上了一个大台阶.由于改革开放以来,城镇的投资的加大和企业的增加,近年来各地城镇家庭收入逐年递增。
城镇家庭的收入增加,必然会导致家庭消费支出总额的增加和家庭消费支出结构的变化。
从最近几年的统计数据可以看出:城镇地区对吃穿等基本生活资料的消费呈下降趋势,而对于文化教育及医疗保健的支出消费逐年递增。
从城镇家庭收支的变化情况可以看出整个国家的经济增长状况,以小见大,为决策提供一定的依据。
聚类和判别都是分类学的基本方法,而分类学是人类认识世界的基础学科。
平时我们对事物的认识都需要对其进行分类。
为了研究现阶段的全国经济发展各时间段的差异,我们需要对时期的经济指标进行分类,以便更好的做出下一步的经济策略。
聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
判别分析则先根据已知的类别的事物的性质,利用某种技术建立函数式,然后对未知类型的新事物进行判断,将其归为已知的类别中。
聚类分析事先并不知道对象的类别的面貌,甚至连共有几个类别也不确定。
判别分析事先知道已知的对象的类别和类别数。
本文以2010年国家统计年鉴上公布的全国各地区城镇居民家庭平均每人全年消费性支出(2009年)作为数据源,将聚类分析和判别分析的原理运用到各个时期经济发展水平分类的研究上,对此问题进行统计分析。
《2》模型的建立和聚类分析:本文采用《中国统计年鉴( 2010)》中的“中国各地区城镇居民家庭平均每人全年消费性支出(2009年)”的七项数据,即:食品、衣着、居住、家庭设备用品及服务、医疗保健、交通和通信、教育文化娱乐服务,运用SPSS19采用聚类分析方法,对全国城镇居民的消费结构进行了地区差异的分析。
表1.1 中国各地区城镇居民家庭平均每人全年消费性支出(单位:元)地区食品衣着居住家庭设备用品及服务医疗保健交通和通信教育文化娱乐服务全国4478.54 1284.20 1228.91 786.94 856.41 1682.57 1472.76 北京5936.11 1795.68 1290.22 1225.68 1389.45 2767.85 2654.98 天津5404.53 1362.56 1505.70 911.92 1273.38 1968.37 1740.85 河北3250.77 1190.19 1142.83 628.49 971.29 1151.15 982.21 山西3071.93 1162.00 1319.45 563.82 789.92 1095.77 1070.60 内蒙古3772.63 1857.19 1246.21 797.77 992.73 1557.03 1504.36 吉林3637.32 1419.12 1394.94 543.69 1120.44 1305.45 1028.06 黑龙江3397.41 1403.72 1026.77 547.87 978.79 922.77 956.85 上海7344.83 1593.08 1913.22 1365.39 1002.14 3498.65 3138.98 江苏4773.67 1297.95 1148.85 923.32 808.37 1721.87 1968.03 浙江5604.72 1614.66 1485.90 828.96 984.62 3290.63 2295.32 安徽4051.40 1080.06 1219.83 589.73 716.87 1013.38 1225.36 福建5336.36 1171.88 1394.91 859.06 591.50 1993.77 1504.96 江西3881.56 1053.01 935.44 761.85 550.25 1145.16 1066.94 山东3954.34 1548.75 1280.04 885.04 885.16 1719.68 1332.97 河南3272.75 1270.74 1004.37 684.79 875.52 1033.99 1048.14 湖北4160.51 1210.32 999.49 759.24 694.61 953.69 1208.46 湖南4174.55 1146.25 1074.69 798.40 784.66 1233.82 1207.72 广西4129.55 855.60 1021.11 754.79 538.17 1598.68 1111.13 四川4391.73 1178.38 973.02 679.16 648.31 1416.49 1150.73 贵州3755.61 1012.14 747.57 589.35 535.43 983.13 1146.35 云南4460.58 1102.14 943.67 393.22 708.78 1587.19 798.69 西藏4581.60 1086.42 689.76 356.86 352.31 1062.83 465.84陕西3988.57 1209.96 1018.23 683.51 863.36 1071.48 1430.22 甘肃3359.30 1169.70 801.21 559.06 746.77 894.35 1025.47青海3548.85 1043.40 790.50 505.32 701.37 975.91 889.32 宁夏3432.23 1260.58 1128.12 636.88 921.86 1363.63 1075.88 新疆3386.33 1357.05 856.78 552.50 684.01 1198.65 855.53参考表1.1中全国城镇居民平均每人全年消费性支出的数据,将我国经济发展区域划分为3类,即经济一般发达地区、比较发达地区、发达地区。
在应用SPSS软件采用系统聚类方法进行聚类时,将聚类数定义为3,运行SPSS软件,输出结果如下:表1.2 案例处理摘要(a)上表是样品的处理概要,从中可以看出27个样品的数据全都有效,均用于系统聚类分析过程。
表1.3系统聚类过程表阶群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 9 23 .323 0 0 52 5 11 .452 0 0 53 8 16 .614 0 0 114 7 14 .681 0 0 95 5 9 .697 2 1 86 15 19 .703 0 0 107 12 20 .826 0 0 148 5 10 1.050 5 0 139 7 21 1.070 4 0 1210 15 18 1.218 6 0 1911 8 13 1.292 3 0 1412 7 17 1.338 9 0 1513 4 5 1.449 0 8 1514 8 12 1.822 11 7 1715 4 7 1.910 13 12 1716 25 26 2.342 0 0 2117 4 8 2.457 15 14 1818 4 24 3.087 17 0 1919 4 15 3.446 18 10 2220 6 22 5.162 0 0 2221 25 27 6.989 16 0 2522 4 6 7.145 19 20 2523 2 3 9.025 0 0 2424 1 2 12.236 0 23 2625 4 25 12.437 22 21 2626 1 4 46.995 24 25 0上表是样品的凝聚进度,从中可以看出系统聚类分析过程中的每一步。
由于有27个样品,所以总共进行了26步,并在每一步中给出了凝聚过程中两类之间的相关系数。
阶(Stage)表示聚类的先后顺序群集组合(Cluster Combined)表示在某步中合并的个案,合并后用第一项的个案号表示生成的新类。
系数(Coefficients)为相似系数。
据聚类分析的基本原理,个案之间的亲密程度最高即相似系数最接近于1,最先合并。
因此该列中的系数与第一列的聚类步骤相对应,系数从小到大。
首次出现的阶聚集(Stage Cluster First Appears)表示新类首次出现的步骤。
对应于各聚类步骤参与合并的两项中,如果有一个是新生成的类,则在对应的列中显示出该新类在哪一步中第一次生成。
下一阶(Next Stage)为新类下一次出现的步骤,表示对应步骤生成的新类将在第几步与其它个案或新类合并。
表1.4群集成员上表表明聚类成员,给出了每一个样品为所分三类中哪一类的成员,即系统聚类分析的最终结果。
聚类分析结论:对聚类结果的类别间距离进行方差分析,方差分析表明,类别间距离差异的概率值均<0.1,即聚类效果好。
这样,原有27类(即原有的27个省区分组)聚合成3类,第一类含有3个地区,第二类含3有个地区,第三类含有21个地区。
总结得出:第一类:3个地区北京市、浙江省、上海市;第二类:3个地区天津市、福建省、江苏省;第三类:21个地区河南省、甘肃省等其它地区。
这与我们直观上得出的结论并比较吻合,第一类的北京为中国政治经济文化中心,浙江和上海为沿海经济迅速发展区,地处经济发达地区;第二类的天津市、福建和江苏省也都属于经济较发达地区,故经济入选较为发达类型;而第三类的河南省、甘肃省等其它地区则同属于经济一般发达类型。
这个结果从一个侧面反映出了我国经济发展的水平和结构。
经济水平有了较大的提高,但经济重心仍然集中在几个发达的主要省市,如北京、上海等。
中国实行改革开放政策以来.经济有了突飞猛进的增长.特别是城镇经济的迅速发展,但经济发展不平衡的问题也一直伴随着.《3》模型的判别分析根据聚类分析的结果,将各地区共分为3类,编号分别为1,2和3。
在SPSS中添加新的一列资源分类来表示类别,将这27个已分类的地区作为“训练样本”,用7组预测变量来建立判别准则来对27个地区进行判别分析;同时根据所建立的判别准则判别辽宁、广东、海南、重庆4个省区,即“待判样本”属于哪一类经济发展区域;原始数据如下表2.1所示:表2.1分类后的数据序号地区食品衣着居住家庭设备医疗保健交通通信教育文化聚类1 北京4560.52 1442.42 977.47 1322.36 2173.26 2514.76 1212.89 12 上海5248.95 1026.87 877.59 762.92 2332.83 2431.74 1435.72 13 浙江4393.40 1383.63 615.45 852.27 2492.01 1946.15 1229.25 14 福建3854.26 784.71 525.65 513.61 1232.70 1321.33 1233.49 25 江苏3462.66 886.82 647.52 600.69 1203.45 1467.36 997.53 26 天津3680.22 864.89 634.39 1049.33 1092.87 1452.17 1368.20 27 安徽3091.28 869.55 336.99 441.42 788.25 869.23 694.17 38 甘肃2408.37 854.00 403.80 562.74 703.07 1034.42 716.35 39 广西2857.40 477.67 360.62 401.06 785.01 850.90 826.86 310 贵州2649.02 832.74 446.53 329.77 775.07 938.37 627.23 311 河北2492.26 849.58 460.27 737.43 875.43 827.72 864.92 312 河南2215.32 919.31 431.02 520.57 762.08 847.12 737.00 313 黑龙江2215.68 971.44 319.37 634.30 665.01 843.94 755.32 314 湖北2868.39 877.01 401.22 517.19 763.14 997.74 752.56 315 湖南2850.94 868.23 513.63 632.52 965.09 1182.18 871.70 316 吉林2457.21 907.61 318.65 671.44 815.02 890.22 984.95 317 江西2636.93 725.72 451.32 357.03 600.16 894.58 742.93 318 内蒙古2323.55 1168.93 464.55 555.00 928.48 1052.65 802.26 319 宁夏2444.98 874.39 480.70 578.75 774.57 846.72 890.97 320 青海2366.42 724.96 420.31 542.93 753.07 793.72 653.04 321 山东2711.65 1091.22 526.29 624.06 1175.57 1201.97 838.17 322 山西2252.50 1016.69 441.82 589.97 825.18 1007.92 830.38 323 陕西2588.91 768.47 478.58 612.30 824.46 1280.14 746.59 324 四川2838.22 754.93 505.83 449.87 1009.35 976.33 728.43 325 西藏3107.90 734.83 211.10 221.70 694.21 359.34 612.67 326 新疆2386.97 953.03 364.11 472.35 765.72 819.72 698.66 327 云南3102.46 745.08 335.14 600.08 1076.93 754.69 585.35 328 广东6225.22 1064.33 1814.00 1052.57 925.62 2979.88 2168.88 待判别29 海南4507.81 581.66 1000.32 585.72 604.15 1548.76 961.95 待判别30 辽宁4680.85 1338.84 1293.00 607.51 1018.44 1493.17 1283.68 待判别31 重庆4576.23 1503.49 1120.60 1043.06 982.73 1189.03 1351.90 待判别2.1SPSS软件分析后的结果如下:表2.2 特征值从表中可以看出SPSS给出了两个判别函数,它们的特征值分别为23.382和1.099。