编译原理第二章(1)
- 格式:ppt
- 大小:651.50 KB
- 文档页数:74


第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
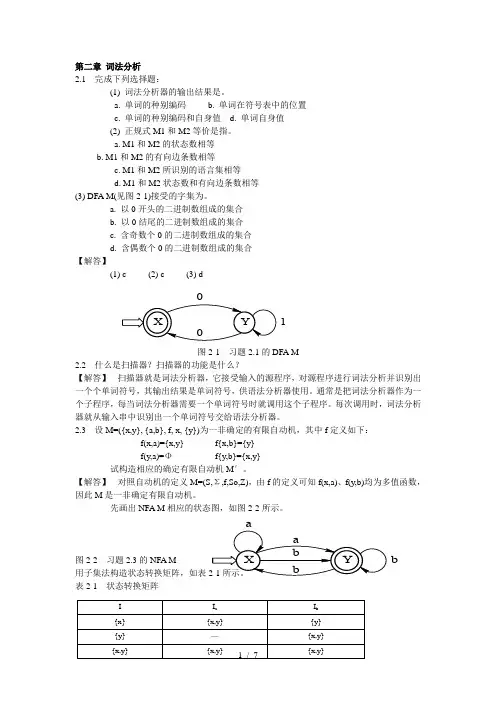
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。



第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiE EFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2.文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D……D3.已知文法G[S]:Sf dAB Af aA|a B|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法? [答案]正规式是daa*b* ;相应的正规文法为(由自动机化简来):G[S]:S —dA A —a|aB B —aB|a|b|bC C —bC|b也可为(观察得来):G[S]:S —dA A —a|aA|aB B —bB| &4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}5.给出语言{a n b n c1 n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A-> B ,A € Vn ,B€( VnU Vt) *,注意关键问题是保证a n b n的成立,即“ a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。


第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。


1.构造正规式的DFA。
(1)1(0|1)*101状态转换表:化简后得:(2)(a|b)*(aa|bb)(a|b)*化简后得;2.将下图确定化和最小化。
⇒解: 首先取A=ε-CLOSURE({0})={0},NFA确定化后的状态矩阵为:NFA确定化后的DFA为:⇒将A,B 合并得:⇒3.构造一个DFA,它接受∑={0,1}上所有满足如下条件的字符串,每个1都有0直接跟在后边。
解:按题意相应的正规表达式是0*(0 | 10)*0*构造相应的DFA,首先构造NFA为DFA为4.给出NFA等价的正规式R。
方法一:首先将状态图转化为得0,1消去其余结点NFA等价的正规式为(0|1)*11方法二:NFA→右线性文法→正规式A→0A|1A|1BB→1CC→εA=0A+1A+1BB=1A=0A+1A+11A=(0+1)*11→(0|1)*115.试证明正规式(a|b )*与正规式(a *|b *)*是等价的。
证明: (1)正规式(a|b)*的NFA 为=>其最简DFA 为(2)正规式(a*|b*)*的 NFA 为: 其最简化DFA 为:DFA由于这两个正规式的最小DFA 相同,所以正规式(a|b)*等价于正规式(a*|b*)*。
6.设字母表∑={a,b},给出∑上的正规式R=b*ab(b|ab)*。
(1)试构造状态最小化的DFA M,使得L(M)=L(R)。
(2)求右线性文法G,使L(G)=L(M)。
解: (1)构造NFA:(2)将其化为DFA,转换矩阵为:再将其最小化得:(2)对应的右线性文法G=({X,W,Y},{a,b},P,X)P: X→aW|bX W→b Y|b y→a W|bY|b3.8文法G[〈单词〉]为:〈单词〉-〉〈标识符〉|〈整数〉〈标识符〉-〉〈标识符〉〈字母〉|〈标识符〉〈数字〉|〈字母〉〈整数〉-〉〈数字〉|〈整数〉〈数字〉〈字母〉-〉A|B|C〈数字〉|->1|2|3(1)改写文法G为G’,使L(G’)=L(G)。
《编译原理》西北工业大学第三版课后答案第一章习题解答1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处置加工而得的另一种语言(目标语言)的程序。
翻译程序就是将某种语言翻译成另一种语言的程序的泛称。
编译程序与解释程序均为翻译程序,但二者工作方法相同。
解释程序的特点就是并不先将高级语言程序全部翻译成机器代码,而是每初始化一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并继续执行之,然后再初始化下一条语句稳步展开表述、继续执行,如此反反复复。
即边表述边继续执行,译者税金的指令序列并不留存。
编译程序的特点就是先将高级语言程序翻译成机器语言程序,将其留存至选定的空间中,在用户须要时再继续执行之。
即先译者、后继续执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表中管理程序、错误检查处理程序共同组成。
3.解:c语言的关键字有:autobreakcasecharconstcontinuedefaultdodoubleelseenumexternfloatforgotoifintlongregisterreturnshortsignedsiz eofstaticstructswitchtypedefunionunsignedvoidvolatilewhile。
上述关键字在c语言中均为保留字。
4.解:c语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用作函数(定义与调用)及表达式运算(发生改变运算顺序)。
c语言中并无end关键字。
逗号在c语言中被视作分隔符和运算符,做为优先级最高的运算符,运算结果为逗号表达式最右侧子表达式的值(例如:(a,b,c,d)的值d)。
5.略第二章习题解答1.(1)请问:26*26=676(2)请问:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}求解:对应文法为g(s)=({s},{a,b},{s→ε|asb},s)(2){anbmcp|n,m,p≥0}解:对应文法为g(s)=({s,x,y},{a,b,c},{s→as|x,x→bx|y,y→cy|ε},s)(3){an#bn|n≥0}∪{cn#dn|n≥0}求解:对应文法为g(s)=({s,x,y},{a,b,c,d,#},{s→x,s→y,x→axb|#,y→cyd|#},s)(4){w#wr#|w?{0,1}*,wr是w的逆序排列}求解:g(s)=({s,w,r},{0,1,#},{s→w#,w→0w0|1w1|#},s)(5)任何不是以0起头的所有奇整数所共同组成的子集解:g(s)=({s,a,b,i,j},{-,0,1,2,3,4,5,6,7,8,9},{s→j|ibj,b→0b|ib|e,i→j|2|4|6|8,jà1|3|5|7|9},s)(6)所有偶数个0和偶数个1所组成的符号串集合求解:对应文法为s→0a|1b|e,a→0s|1cb→0c|1sc→1a|0b3.描述语言特点(1)s→10s0s→aaa→baa→a求解:本文法形成的语言集为:l(g)={(10)nabma0n|n,m≥0}。
第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。
现代编译原理--第⼆章(语法分析之LR(1)) (转载请表明出处)前⾯已经介绍过LL(1),以及如何使⽤LL(1)⽂法。
但是LL(K)⽂法要求在看到K个字母的情况下必须做出预测,这相⽐于LR(K)⽂法⽽⾔就逊⾊很多。
LR(K)⽂法的定义是:从左⾄右分析,最右推导,超前查看K个单词。
先看⼀个例⼦,来对LR⽂法有个⼤致的印象。
以上就是使⽤LR⽂法对源码进⾏分析的例⼦。
注意到在LR⽂法中只有三个动作:移进,规约和接受,这三个动作也是通过查表来得到的。
任何时候如果都是唯⼀确定这三个动作中的⼀个,我们就能让LR⽂法正确的运⾏。
为了更好的理解LR(K)⽂法,我们先介绍以下最简单的LR(0)⽂法。
因为动作是根据表来确定,所以,表的构建依然是我们构建的重点,先来看看⼀个表的最终形式: ⾸先要说明的是,构建这张表的时候,我们使⽤到了状态机,⾏标就代表状态。
列标由两部分组成,分别是终结符,和⾮终结符。
s代表移进,r代表规约,g代表跳转,a代表接受,他们后⾯跟着的数字,除了r以外,都是状态的标号,只有r后⾯的数字指的时规约到第⼏个产⽣式。
所有空的地⽅都代表出现错误。
可见在⾮终结符下只有跳转。
为了构建这个表,我们⾸先构建状态机。
我们从⼀个基本的⽂法开始,⽂法如下: 我们向产⽣式中添加⼀个点,形成这种形式,称为项。
这个点的位置告诉我们当前在状态是什么。
点每移动⼀次,我们跳转⼀个状态。
点前⾯的字符串表⽰我们已经读取的历史,点后⾯的字符串表⽰我们希望得到的。
也就是这种表达⽅式,既可以展望未来,也可以回顾过去。
上⾯这个起始项中,我们希望得下⼀次得到⼀个S⾮终结符,可以看出1和2产⽣式是S的等价形式,如果我们得到1和2产⽣式的右部,我们就相当于得到了⾮终结符S,所以,我们的起始状态为: 我们称第⼀个产⽣式为核⼼项,其他为普通项。
这个状态我们称为状态1,所有的状态都是由这个状态中每个项的点的移动得到的。
例如,状态1吃掉⼀个终结符x时,状态1的第⼆个项中的点要向右移动⼀位。