统计学案例集
- 格式:doc
- 大小:1.06 MB
- 文档页数:47
![[经管营销]统计学案例](https://uimg.taocdn.com/cc1f97b4294ac850ad02de80d4d8d15abe2300bc.webp)
案例一高露洁——棕榄公司纽约州,纽约市高露洁——棕榄(Colgate-Palmolive)公司。
1806年在纽约开业,是一家经营香皂和蜡烛的小商店,今天,高露洁——棕榄公司的产品全世界可见,公司已在55个国家实现跨国经营,1996年年销售额超过87亿美元。
除了著名的传统的产品香皂、清洁剂、牙膏外,公司还兼营软皂、Mennen、宠物食品和其他产品。
高露洁——棕榄公司在对其家用洗涤产品的质量保证程序中利用统计学。
一个焦点是客户对盒装清洁剂的数量的满意度。
每一类尺寸的盒子都填充相同重量的清洁剂,但是清洁剂的容量受其清洁粉的密度影响。
例如,如果粉的密度偏大,达到盒的指定重量就需要少一些清洁剂,结果,当消费者打开盒子时,盒子显然未充满。
为了控制清洁剂重量这一难题,要对粉的密度的可接受范围加以限制。
定期抽取统计样本,测量每一样本的密度。
然后把汇总数据提供给经营人员,以便在需要把密度保持在期望的质量规格尺寸时采取正确的行动。
在一周的期间采集的150个样本的密度的频数分布,密度水平高于0.40是不可接受的。
频数分布中所有的密度小于或等于0.40表明经营符合其质量标准,从而使清洁剂产品生产质量令人满意。
[思考题]试利用150个样本的频数分布表做出直方图。
案例二中国玩具市场调查报告随着我国经济的发展,我国城乡居民的消费支出中,玩具类支出尽管难以与食品、服装等消费品的数额相提并论,然而却始终保持着一个不断增长的良好势头。
据有关专家预测,我国玩具市场逐渐从温而不热的季节性、节日性的特定销售态势中走出。
但国内玩具市场的潜力有多大,热点在何处呢?中国社会调查事务所对城乡玩具市场进行了一系列调查,范围为北京、天津、上海、广州、南京、武汉、长沙、青岛、沈阳等23个城市及其周边近郊、农村。
调查内容有:1.性别:男性占48.2%;女性占51.8%;2.年龄:15岁以下占24.4%;16岁~25岁占40.4%;26岁~50岁占15.4%;51岁以上占19.8%;3.文化程度:小学及小学以下占6.5%;初中(含技校)占17.2%;高中(含中专)占35.6%;大专占19.5%;本科占15.4%;本科以上占5.8%;4.职业:管理人员占29.7%;工人占25.5%;科技人员占12.3%;教师占7.8%;服务员占5.8%;学生占5.5%;个体户占4.5%;农民占3.0%;司机占1.2%;军人占1.2%;推销员占1.0%;其他占2.5%;5.月收入:0收入的占5.9%;500元以下占7.6%;501元~1 000元占34.8%;1 001元~1 500元占27.4%;1 501元~2 000元占15%;2 001元~2 500元占5.6%;2 501元以上占3.7%。
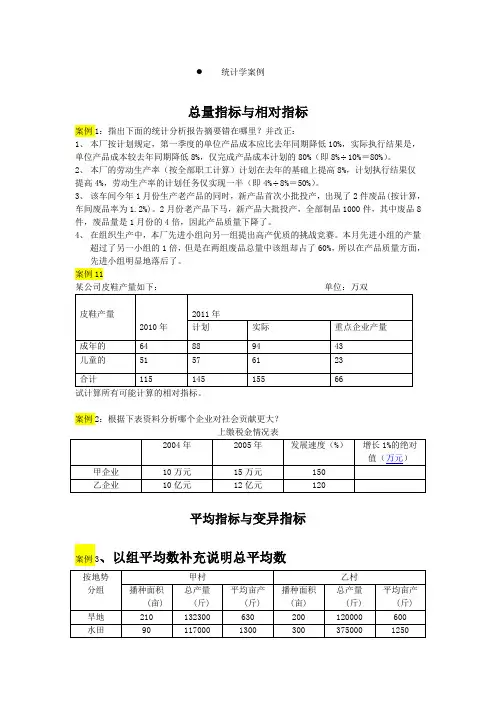
统计学案例总量指标与相对指标案例1:指出下面的统计分析报告摘要错在哪里?并改正:1、本厂按计划规定,第一季度的单位产品成本应比去年同期降低10%,实际执行结果是,单位产品成本较去年同期降低8%,仅完成产品成本计划的80%(即8%÷10%=80%)。
2、本厂的劳动生产率(按全部职工计算)计划在去年的基础上提高8%,计划执行结果仅提高4%,劳动生产率的计划任务仅实现一半(即4%÷8%=50%)。
3、该车间今年1月份生产老产品的同时,新产品首次小批投产,出现了2件废品(按计算,车间废品率为1.2%)。
2月份老产品下马,新产品大批投产,全部制品1000件,其中废品8件,废品量是1月份的4倍,因此产品质量下降了。
4、在组织生产中,本厂先进小组向另一组提出高产优质的挑战竞赛。
本月先进小组的产量超过了另一小组的1倍,但是在两组废品总量中该组却占了60%,所以在产品质量方面,先进小组明显地落后了。
案例11试计算所有可能计算的相对指标。
案例2:根据下表资料分析哪个企业对社会贡献更大?平均指标与变异指标案例3、以组平均数补充说明总平均数案例4:某单位有10个人,其中1人月工资为10万元,9人每人月工资为1000元。
该单位职工月平均工资为10900元。
即:)(109001091000100000元=⨯+你认为这个平均数有代表性吗?如果缺乏代表性应如何改正?案例5:以下是各单位统计分析报告的摘录1、 本局所属30个工厂,本月完成生产计划的情况是不一致的。
完成计划90%的有3个,完成96%的有5个,完成102%的有10个,完成110%的有8个,完成120%的有4个。
平均全局生产计划完成程度为104.33%。
即:304%1208%11010%1025%963%90⨯+⨯+⨯+⨯+⨯=104.33%2、 本厂开展增产节约运动以后,产品成本月月下降,取得显著的成绩,根据财务部门的报告,1 月份开支总成本15000元,平均单位产品成本为15元,2月份开支总成本25000元,平均单位产品成本下降为10元,3月份开支总成本45000元,平均单位产品成本仅8元。



《统计学》案例——相关回归分析案例一质量控制中的简单线性回归分析1、问题的提出某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。
2、数据的收集目标值确定之后,我们收集了某年某季度的回流温度与液化气收率的30组数据(如上表),进行简单直线回归分析。
3.方法的确立设线性回归模型为εββ++=x y 10,估计回归方程为x b b y10ˆ+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。
因此,建立描述y 与x 之间关系的模型时,首选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最小二乘估计值b 0=21.263和b 1=-0.229,于是最小二乘直线为x y229.0263.21ˆ-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。
(3)残差分析为了判别简单线性模型的假定是否有效,作出残差图,进行残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建立回归模型所依赖的假定是恰当的。
误差项的估计值s=0.388。
(4)回归模型检验 a.显著性检验在90%的显著水平下,进行t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。
由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化气收率与回流温度之间存在线性关系。
b.拟合度检验判定系数r 2=0.792。

《统计学》案例——综合分析关于居民月收入和居民金融资产影响因素关系的调查1、问题的提出改革开放以来。
中国居民家庭财富的效量不断增长。
居民储蓄存款持续稳定的增加。
从1978年的210.6亿元一路攀升,到2008年已达217885.4亿元。
在三十年的时间里增加了一千多倍。
与此同时,经济的货币化程度大大提高,金融市场特别是资本市场得到发展,使得居民金融资产选择的空同逐步扩大,导致了家庭金融资产多样化。
影响家庭金融资产组合的主要因素家庭金融资产选择主要受三类因素的影响:l、家庭内部因素(收入水平以及家庭财务状况;家庭的特征:成员的性别、年龄、婚姻状况、受教育程度、职业、健康状况、以及家庭人口数等;家庭成员的风险厌恶程度;住房所有权)。
2、金融资产特性随着资本市场的发展。
3、经济金融环境。
这些影响因素对居民金融资产的影响程度到底孰重孰轻呢?2、数据的收集为确定各类因素对居民金融资产的大小影响,有效地解居民关于金融资产和有关因素的现状,做了以下调查。
随机抽取了64户温州居民代表,以下为64位家庭各行业月收入和家庭金融资产(各种储蓄、有价证券、手存现金等)资料。
表1温州64位家庭各行业月收入和家庭金融资产信息表表1是一个样本总体,由随机抽取的64户居民家庭组成,总体则是温州市的全体居民家庭。
从这64户家庭中所调查登记的月收入和金融资产的具体数据是标志值。
3、方法的确定3.1.按标志对数据分组对这64户的调查资料进行整理,按月收入和金融资产两标志进行分组。
对于按月收入进行分组整理的结果见表2。
表2.按月收入分组(元)户数月收入(元)金融资产(万元)甲(1)(2)(3)500以下 3 1466 2.95500-1000 6 4125 8.931000-1500 13 16556 33.43表2中的各组和总体的“户数”是单位总量,各组和总体的“月收入”、“金融资产”是标志总量,它们是反映总体综合数量特征的指标。
对原始数据进行因果依存关系分组,见表3。

统计学案例案例一我国高等教育国际竞争力的分析研究一、教学目的1、明确对高等教育国际竞争力进行研究的意义及方法;2、学会根据研究的问题,正确、科学地设置对该问题进行评价的统计指标;3、掌握统计数据的收集与整理的方法,认识到统计数据在统计分析中的重要性;4、在综合掌握各种统计分析方法的基础上,根据所提问题的性质,能选择合适的统计分析方法;5、明确指标无量纲化的意义,掌握无量纲化的一般方法;6、掌握统计分析中权数的确定方法,明确模糊综合评价法在统计分析中应用;7、学会根据统计资料,对所研究的问题进行分析研究,并提供有情况、有分析、有对策的分析研究报告。
二、背景材料我国高等教育国际竞争力的分析研究经济全球化趋势及知识经济浪潮使包括人才在内的资源竞争更加激烈,信息共享程度更高,我国高等教育面临严峻的考验和挑战,对现代大学教育提出了新的要求和使命。
研究我国高等教育国际竞争力,科学发展我国的高等教育,应站在全球化高度,优化资源配置,增强创新能力,提高高等教育的竞争力,把握机遇,谋划未来,深化改革,提高教学质量,增强其国际竞争力。
因此,进行高等教育国际竞争力的研究,保持我国高等教育的可持续发展,具有非常重要的理论意义和现实意义。
一、高等教育国际竞争力的基本理论1、竞争、竞争力及高等教育国际竞争力的基本涵义“竞争系个人(或集团)间的角逐;凡两方或多方力图取得并非各方均能获得的某些东西时,就会有竞争,竞争与人类历史同样悠久。
”竞争是市场经济的基本法则,它不仅是经济学家和生物学家研究的对象,也是教育学家常常思考的问题。
从理论上讲,竞争力具有相对与绝对两种含义:绝对竞争力指个人、单位或国家在竞争日趋激烈的条件下其持续发展的能力,它很难用一个准确的计量单位来衡量。
而相对竞争力指个人、单位或国家其持续发展的能力在相互比较中所处的位置,一般可通过比较排名来相对体现。
从统计学的角度来说,绝对竞争力采用的是定距尺度,而相对竞争力采用的是定序尺度。

《统计学》案例——描述性分析大学毕业生的表现1、问题的提出某大学是一所综合性大学,有三个附属学院,分别是商贸学院、生物学院和医学院。
近期高校管理层为了了解社会对本校学生的满意程度,以此促进本校教学改革,其中进行了一项对本校的毕业生调查,随机抽取了48名毕业生组成样本,要求他们所在的工作单位对其工作表现、专业水平和外语水平三个方面的表现进行评分,评分由0到10,分值越大表明满意程度越高。
2、数据的收集表:48名毕业生工作表现、专业水平和外语水平评分资料表表:三个学院的48名毕业生的工作表现、专业水平和外语水平评分汇总表校管理层希望在调查分析报告中阐述以下几个问题:(1)用人单位对该校毕业生哪个方面最为满意? 哪个方面最不满意?应在哪些方面做出教学改革?(2)用人单位对该校毕业生哪个方面的满意程度差别最大?什么原因产生?(3)社会对三个学院的毕业生的满意程度是否一致?能否提出提高社会对该校毕业生的满意程度的建议?2、方法的确定将数据输入计算机,我们用Excel中的数据分析功能实现对数据的描述。
输出结果如下图表。
表:48名毕业生的评分统计汇总表表7 三个学院的48名毕业生的评分统计汇总表图24、结果分析从图可看出,随机抽取48名毕业生是由附属商贸学院、生物学院和医学院毕业生组成,各学院毕业生人数分别是17人、17人和14人,分别占样本的35.4%、35.4%和29.2%,可见各学院抽取毕业生人数大致相同,样本具有一定代表性。
从表可看出:①用人单位对某大学毕业生的工作表现评估分最高,而外语水平评估分最低。
工作表现平均评估分为8.04分,外语水平平均评估分为5.08分,两者平均评估分相差2.96分,由此可见用人单位最满意该校毕业生的工作表现,最不满意毕业生的外语水平,这反映出某大学注意培养学生社会实践能力,也反映出毕业生适应能力较强。
从用人单位对毕业生外语水平评分普遍偏低看,反映出该校的外语教学方面存在严重问题,今后需要在外语教学方面加大力度全面改革。

统计学应用于市场调查的案例分析在当今竞争激烈的市场环境中,市场调查是企业制定决策和开展营销活动的重要工具之一。
而统计学作为一门科学的研究方法,可以为市场调查提供有力的支持和指导。
本文将以几个实际案例为例,探讨统计学在市场调查中的应用。
案例一:产品定价策略一家电子产品公司希望了解消费者对其新产品的价格敏感度,以制定合理的定价策略。
为此,他们进行了一项市场调查,并运用统计学方法对收集到的数据进行分析。
首先,他们设计了一个问卷调查,询问受访者对不同价格水平的产品的购买意愿。
然后,他们利用统计学中的描述性统计方法,如平均数、中位数和标准差,对数据进行了整理和概括。
通过这些统计指标,他们得出了受访者对产品价格的整体接受程度。
接下来,他们运用回归分析方法,将受访者的购买意愿与其个人特征进行关联分析。
例如,他们考察了受访者的年龄、收入水平和教育程度对价格敏感度的影响。
通过回归分析,他们得出了不同人群对产品价格的敏感程度,为公司制定差异化的定价策略提供了依据。
案例二:广告推广效果评估一家服装品牌公司在推出新产品后,希望评估其广告推广的效果。
他们通过统计学方法进行市场调查,以了解广告对消费者购买意愿的影响。
首先,他们设计了实验组和对照组,实验组观看了广告,对照组则没有。
然后,他们对两组消费者的购买意愿进行统计分析。
通过比较实验组和对照组的购买意愿差异,他们可以得出广告对购买意愿的影响程度。
此外,他们还运用统计学中的假设检验方法,对实验结果的可靠性进行评估。
通过计算置信区间和p值,他们可以判断广告推广效果是否显著。
如果p值小于设定的显著性水平,他们就可以得出广告对购买意愿的确实有显著影响的结论。
案例三:市场细分分析一家汽车制造商希望了解不同消费者群体的购车偏好,以制定精准的市场细分策略。
他们进行了一项市场调查,并利用统计学方法对数据进行分析。
首先,他们收集了消费者的购车偏好数据,如品牌偏好、车型偏好和价格偏好等。
然后,他们利用聚类分析方法,将消费者划分为不同的群体。

统计学基础案例话说咱班上次进行了一场超级重要的考试,那这个考试成绩啊,就特别适合拿来做统计学的例子呢。
平均分这个概念就很关键。
老师把全班同学的成绩加起来,再除以总人数,得到的那个数字就是平均分啦。
比如说,咱们班50个人,所有成绩加起来是3500分,那平均分就是3500除以50等于70分。
这平均分就像一个基准线,能大概让我们知道这个班级整体考得怎么样。
要是平均分是90分,哇塞,那说明咱班整体是学霸班啊;要是只有50分,那就得好好反省反省啦。
然后就是中位数。
把所有同学的成绩按照从低到高或者从高到低的顺序排好。
如果总人数是奇数呢,正中间的那个成绩就是中位数;要是总人数是偶数,中间两个数的平均值就是中位数。
比如说咱班成绩排好序后,第25和26名同学成绩分别是72和74分,那中位数就是(72 + 74)÷ 2 = 73分。
中位数的好处是,它不太受那些特别高或者特别低的极端分数影响。
就像有个同学考了100分,另一个考了20分,这时候平均分可能会被拉低或者拉高,但中位数还是比较稳定地反映中间水平。
众数也很有趣呢。
众数就是在这些成绩里出现次数最多的那个分数。
比如说,70分有10个人考到了,其他分数都没有这么多人相同,那70分就是众数。
众数可以让我们知道哪个分数段是最“热门”的,可能这个分数对应的知识点是大家掌握得最好或者最不好的呢。
通过分析这些统计学的指标,老师就能对咱班的学习情况有个全面的了解,知道教学效果怎么样,哪里需要改进,我们自己也能清楚自己在班级里的水平大概处于什么位置呢。
咱学校图书馆那可是知识的大宝库啊,管理员叔叔阿姨们就经常做一些统计学的工作呢。
先说说每个月的借书总量。
这就好比是一个大盘子,能看出这个月图书馆的人气。
比如说10月份总共借出去了5000本书,这数字就代表了大家对知识的渴望程度。
要是哪个月借书量突然大增,可能是快考试了,同学们都来借书复习;要是借书量骤减,也许是因为学校举办了很多课外活动,大家都顾不上看书啦。
《统计学》案例——抽样推断分析案例一机票预售数量的统计研究1.问题的提出联合航空公司新开辟甲城——乙城之间的航线,选用75座位小飞机,每周一、三、五通航。
通航2个月后发现,座位订满飞机起飞时,经常出现顾客因故未能登机现象,公司考虑多售机票以提高上座率,不知是否可行。
于是想了解如下3个问题:(1)预订78张机票,出现75人以上登机的概率。
(2)每张机票价格200元,当出现75人以上登机时,对未能登机者按票价加倍补偿,应否多预售机票?(3)预售机票多少张时,平均收益最大?2.数据的收集前20个航班缺席人数统计如下表所示。
3、方法的确定泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。
根据所收集的信息,了解数据的概率分布特征,用泊松分布进行近似分析。
(1)平均缺席人数的频率航班缺席人数的算术平均数∑∑=fxf x =6 平均每个人缺席的频率p=6/75=0.08 (2)预订78张机票,出现75人以上登机的概率 即缺席2、1、0人的概率P(x=2,1,0)=P(x ≤2)=0.054(上式为n=78,p=0.08,μ=np=6.24的泊松分布近似计算。
)4.结果分析(1)多预售机票的可行性分析多预售机票,当出现75人以上登机时,对未能登机者按票价加倍补偿,会产生机会成本;但若登机人数少于75人,可以避免机会损失。
所以预售多少机票,应从机会成本和机会损失两方面考虑。
在一定范围内多预售机票可以减少成本,因此应考虑多预售机票。
(2) 计算最佳预售机票数量总成本Z=机会成本C+机会损失S 当预订机票数一定时,总成本Z=∑P(x)(C+S)其中,x=0,1,2,3,…表示缺席的人数P(x)表示缺席x 人的概率,P(x)=P(X ≤x)-P(X ≤x-1)可以通过泊松分布查表得出。
将预售机票成本数据表示如图5.4。
不难看出,N=75时,总成本最高,随着的增大,总成本逐渐降低,当N=81时,总成本最小,随着的继续增大,总成本开始逐渐上升。
统计学精品课程建设小组二○○六年十一月【案例一】全国电视观众抽样调查抽样方案一、调查目的、范围和对象1.1 调查目的准确获取全国电视观众群体规模、构成以及分布情况;获取这些观众的收视习惯,对电视频道和栏目的选择倾向、收视人数、收视率与喜爱程度,为改进电视频道和栏目、开展电视观众行为研究提供新的依据。
1.2 调查范围全国31个省、自治区、直辖市(港澳台除外)中所有电视信号覆盖区域。
1.3 调查对象全国城乡家庭户中的13岁以上可视居民以及4-12岁的儿童。
包括有户籍的正式住户也包括所有临时的或其他的住户,只要已在本居(村)委会内居住满6个月或预计居住6个月以上,都包括在内。
不包括住在军营内的现役军人、集体户及无固定住所的人口。
二、抽样方案设计的原则与特点2.1 设计原则抽样设计按照科学、效率、便利的原则。
首先,作为一项全国性抽样调查,整体方案必须是严格的概率抽样,要求样本对全国及某些指定的城市或地区有代表性。
其次,抽样方案必须保证有较高的效率,即在相同样本量的条件下,方案设计应使调查精度尽可能高,也即目标量估计的抽样误差尽可能小。
第三,方案必须有较强的可操作性,不仅便于具体抽样的实施,也要求便于后期的数据处理。
2.2 需要考虑的具体问题、特殊要求及相应的处理方法2.2.1 城乡区分城市与农村的电视观众的收视习惯与爱好有很大的区别。
理所当然地应分别研究,以便于对比。
最方便的处理是将他们作为两个研究域进行独立抽样,但代价是,这样做的样本点数量较大,调查的地域较为分散,相应的费用也就较高。
另一种处理方式是在第一阶抽样中不考虑区分城乡,统一抽取抽样单元(例如区、县),在其后的抽样中再区分城、乡。
这样做的优点是样本点相对集中,但数据处理较为复杂。
综合考虑各种因素,本方案采用第二种处理方式。
在样本区、县中,以居委会的数据代表城市;以村委会的数据代表农村。
2.2.2 抽样方案的类型与抽样单元的确定全国性抽样必须采用多阶抽样,而多阶抽样中设计的关键是各阶抽样单元的选择,其中尤以第一阶抽样单元最为重要。
案例2-1 Gulf Real Estate Properties公司Gulf Real Estate Properties有限责任公司是佛罗里达西南部的一家房地产公司。
企业在广告中称自己是“真正的地产专家”。
公司通过搜集有关地点、定价、售价和每套售出花费天数,对房屋的销售进行监督。
如果房屋位于墨西哥湾,则称之为“看得见海湾的房屋”;如果房屋位于墨西哥湾附件的其他海湾或者高尔夫球场,则称之为“看不见海湾的房屋”。
来自佛罗里达州那不勒斯的多元列表服务的样本数据,给出了最近售出的40套看得见海湾的房屋和18套看不见海湾的房屋的数据。
数据见GulfProp.xls,价格以千美元计。
管理报告1.对看得见海湾的房屋,求售价的总体均值以及售出中花费天数的总体均值的95%置信区间,并解释你的结论。
2.对看不见海湾的房屋,求售价的总体均值以及售出中花费天数的总体均值的95%置信区间,并解释你的结论。
3.假定分公司的经理要求在40000美元的边际误差下对看得见海湾的房屋售价的均值进行估计,在15000美元的边际误差下对看不见海湾的房屋售价的均值进行估计。
取置信度为95%,则应选取多大的样本容量。
解答:利用Excel软件求得一些数据如图1、图2:图1:看得见海湾图2:看不见海湾1.首先对看得见海湾的房间,根据题意,易知这是属于σ未知的情况,售价的总体均值1454.2X=,出售天数的总体均值2106X=, 则售价的95%置信区间为:[] 2211454.2 2.023 2.023392.65,515.79 S SX t X tαα⎡⎡-+=-+=⎢⎢⎣⎣售出中花费天数的均值的95%置信区间为:[] 2222106 2.023 2.02389.30,122.70 S SX t X tαα⎡⎡-+=-+=⎢⎢⎣⎣2. 对于看不见海湾的房间,依旧是σ未知的情况,售价的总体均值1203.2X=,售出天数的总体均值2135.0X=所以售价的总体均值的95%置信区间为:[] 2211203.2 2.11 2.11225.016,172,943X t X tαα⎡⎡-+=-+=⎢⎢⎣⎣售出天数的总体均值的95%置信区间为:[] 2222135 2.11 2.1197.057,172.943 X t X tαα⎡⎡-+=-+=⎢⎢⎣⎣3.对于看的见海湾的房间要求边际误差为40千美元,所以得出240Stα=,得到:2222211222.023192.5954040t Snα⨯===,其中0.05α=对于看不见海湾的房间要求边际误差为15千美元,所以得到:215 St α=,得到2222222222.1143.8939 1515t Snα⨯===,其中0.05α=所以,看得见海湾的房间应选取的样本容量为95,看不见海湾的房间应选取的样本容量为39。
统计学教学案例集统计学精品课建设小组2004年11月【案例一】全国电视观众抽样调查抽样方案一、调查目的、范围和对象1.1 调查目的准确获取全国电视观众群体规模、构成以及分布情况;获取这些观众的收视习惯,对电视频道和栏目的选择倾向、收视人数、收视率与喜爱程度,为改进电视频道和栏目、开展电视观众行为研究提供新的依据。
1.2 调查范围全国31个省、自治区、直辖市(港澳台除外)中所有电视信号覆盖区域。
1.3 调查对象全国城乡家庭户中的13岁以上可视居民以及4-12岁的儿童。
包括有户籍的正式住户也包括所有临时的或其他的住户,只要已在本居(村)委会内居住满6个月或预计居住6个月以上,都包括在内。
不包括住在军营内的现役军人、集体户及无固定住所的人口。
二、抽样方案设计的原则与特点2.1 设计原则抽样设计按照科学、效率、便利的原则。
首先,作为一项全国性抽样调查,整体方案必须是严格的概率抽样,要求样本对全国及某些指定的城市或地区有代表性。
其次,抽样方案必须保证有较高的效率,即在相同样本量的条件下,方案设计应使调查精度尽可能高,也即目标量估计的抽样误差尽可能小。
第三,方案必须有较强的可操作性,不仅便于具体抽样的实施,也要求便于后期的数据处理。
2.2 需要考虑的具体问题、特殊要求及相应的处理方法2.2.1 城乡区分城市与农村的电视观众的收视习惯与爱好有很大的区别。
理所当然地应分别研究,以便于对比。
最方便的处理是将他们作为两个研究域进行独立抽样,但代价是,这样做的样本点数量较大,调查的地域较为分散,相应的费用也就较高。
另一种处理方式是在第一阶抽样中不考虑区分城乡,统一抽取抽样单元(例如区、县),在其后的抽样中再区分城、乡。
这样做的优点是样本点相对集中,但数据处理较为复杂。
综合考虑各种因素,本方案采用第二种处理方式。
在样本区、县中,以居委会的数据代表城市;以村委会的数据代表农村。
2.2.2 抽样方案的类型与抽样单元的确定全国性抽样必须采用多阶抽样,而多阶抽样中设计的关键是各阶抽样单元的选择,其中尤以第一阶抽样单元最为重要。
本项调查除个别直辖市及城市外,不要求对省、自治区进行推断,从而可不考虑样本对省的代表性。
在这种情况下,选择区、县作为初级抽样单元最为适宜。
因为全国区、县的总数量很大,区、县样本量也会比较大,因而第一阶的抽样误差比较小。
另外对区、县的分层也可分得更为精细。
本抽样方案采用分层五阶抽样。
各阶抽样单元确定为:第一阶抽样:区(地级市以上城市的市辖区)、县(包括县级市等);第二阶抽样:街道、乡、镇;第三阶抽样:居委会、村委会;第四阶抽样:家庭户;第五阶抽样:个人。
为提高抽样效率,减少抽样误差, 在第一阶抽样中对区、县采用按地域及类别分层。
在每一层内前三阶抽样均采用按与人口成正比的不等概率系统抽样(PPS系统抽样),而第四阶抽样采用等概率系统抽样,即等距抽样,第五阶抽样采用简单随机抽样。
2.2.3 自我代表层的设立根据要求,本次调查需要对北京、上海两个直辖市以及广州、成都、长沙与西安四个省会城市进行独立分析,因而在处理上将这些城市(包括下辖的所有区、县)每个都作为单独的一层处理。
为方便起见,以下把这样的层称为自我代表层。
考虑到在这样处理后,全国其他区县在分层中的一些具体问题以及各地的特殊情况,将天津市也作为自我代表层处理。
另外,鉴于西藏情况特殊,所属区县与其它省(自治区)的差别很大,因此也将它作为自我代表层处理。
这样自我代表层共有8个,包括以下城市与地区:北京市、天津市、上海市;广州市、成都市、长沙市、西安市;西藏自治区。
三、样本区、县的抽选方法3.1 全国区、县的调查总体根据2001年的全国行政区划资料,全国(港澳台除外)共有787个市辖区,此外有5个地级市(湖州、东莞、中山、三亚、嘉峪关)不设市辖区,若将它们每个都视同一个市辖区,则共有792个区;全国共有1674个县(包括自治县及旗、自治旗、特区与林区等)、400个县级市,县级行政单位的总数为2074个,这中间包括福建省的金门县,不能进行调查,因此除金门县以外的所有2865个区、县(792个区及2073个县)构成此次调查的调查总体。
3.2区、县分层为便于调查后的资料分类汇总及提高精度,应将全国区、县进行分层。
分层可以按多种标识进行,从理论而言,分层标识应选取与调查指标相关程度较高的那些变量。
在本次调查中也就是应选取与观众收视行为、习惯与爱好等密切相关的变量。
关于这方面已有一些相应的研究结果,例如观众的年龄、性别、文化程度、职业、居住地的生活习惯与气候等。
不过注意到我们不可能按观众的个体来分类,只能按观众居住的区、县来分类。
而对于区、县,许多表示人口特征(除人口总数)及经济文化发展指标(除所在省的人文发展指数及县的人均GPT)的资料都无法得到,经过多方研究,我们对区县的分层按以下两种标识进行。
(1)地域我国幅员广大,各地经济、社会、文化与气候的地域差异极大,而所有这些因素都与电视观众的收视行为密切相关。
我们首先将所有县按所在省(自治区、直辖市)的地理位置分成3大层13个子层,[各省括号内的数字为它们的人文发展指数(Human Development Index,简称HDI),在全国的排位,参见附表]。
地域分层如表1:表1 全国区、县的地域分层需要说明的是以上划分的层,还考虑了其他一些因素,各省按联合国制定的标准计算的人文发展指数仅是考虑因素之一。
例如,按人文发展指数,广西(第19位)实际上可划在第二大层(中部地区),但考虑到国家西部大开发的范围将广西划入西部地区,我们的划分与它一致,这样便于资料的汇总发布。
又如海南,根据人文发展指数(第13位)放在第一大层稍为勉强,但是根据它的地理位置以及它以旅游为主业,就观众行为而言,与广东、福建划在一子层内是合理的。
(2)区、县类别同一大层的各市辖区与所隶属的城市的规模、在城市中的地理位置(市区或郊区)和居民成分构成(非农业人口占总人口的比例)有较大差异,各县也因经济文化发达程度有较大差异。
我们将各大层中所有的区、县除已划为自我代表层的以外,(如下称抽样总体)分成以下5类,每类组成1个小层:一类区,二类区,县级市,一类县,二类县。
全国抽样总体中所有区县共分成11×5=55个小层。
其中区的划分标准为区中非农业人口占总人口的比例,比例高于标准的为一类区,比例低于标准的为二类区;县的划分标准为人均国内生产总值,高的为一类县,低的为二类县。
区县划分类别的标准在三大层中各不相同,具体标准如下:区类别的划分标准:东部地区与中部地区:非农人口在总人口中的比例大于或等于80%为一类区,小于80%为二类区;西部地区:非农人口在总人口中的比例大于或等于70%为一类区,小于70%为二类区。
县类别的划分标准:东部地区:人均GDP在5000元以上为一类县;5000元以下为二类县。
中部地区:人均GDP在4000元以上为一类县;4000元以下为二类县。
西部地区:人均GDP在3000元以上为一类县;3000元以下为二类县。
3.3自我代表层的区、县情况根据最新行政区划,自我代表层中的7个城市所辖的区、县构成情况如表1。
表2 自我代表城市的辖区、县构成西藏自治区包括1个地级市(拉萨市,下辖一个城关区)、一个县级市(日喀则市)及71个县。
3.4 抽样总体区县情况按3.2划分标准,全国除自我代表层以外的抽样总体各小层的区、县数及人口在(抽样总体)总人口中的比例如表3与表4所示。
表3 抽样总体中各小层的区县数表4 抽样总体各小层人口占总人口的比例(%)3.5 区、县的抽样方法及样本量抽样总体中各层(指小层,下同)内对区、县的抽样采用按人口的PPS系统抽样,样本量一般为2;少数人口较多的小层样本量定为3。
样本量的具体分配见表5。
样本区、县总量为121个。
表5 各小层的区县样本量的分配四、抽样总体中样本区、县内的抽样方法4.1 样本区内的抽样每个一类样本区内采用街道(镇)、居委会、家庭户及个人的4阶抽样;每个二类样本区内采用街道(乡、镇)、居(村)委会、家庭户及个人的4阶抽样,样本量皆为90。
具体方法如下。
4.1.1 对街道(乡、镇)的抽样样本区内对街道(乡、镇)抽样采用按人口的PPS系统抽样,每个样本区抽3个街道(乡、镇),其中一类区不抽乡。
4.1.2 对居委会的抽样样本街道、镇(乡)内对居(村)委会的抽样采用按人口的PPS系统抽样,每个样本街道、镇、乡各抽2个居(村)委会(其中一类区不抽村委会)。
为操作方便,这里的人口数也可用户数。
4.1.3 对家庭户的抽样样本居(村)委会内对家庭户的抽样采用随机起点的等概率系统抽样,即等距抽样。
每个居(村)委会固定抽取15户。
在抽样时,必须首先清点居(村)委会管辖范围内的实际家庭户数,且规定排列的顺序。
4.1.4 样本户内具体调查对象的确定对每个被抽中的样本户,在13岁以上(含13岁)的成员中,完全随机地确定一名为具体调查对象。
为确保家庭成员中的每一个这样的成员都有相等的概率被抽中,采用二维随机表来确定。
表 6 确定户内调查对象的二维随机表4.2 样本县(县级市)内的抽样每个样本县内采用乡(镇)、村(居)委会、家庭户及个人的4阶抽样,样本量为60。
具体方法如下。
4.2.1 对乡、镇的抽样确定县城所在的镇(城关镇)为必调查镇,对其余乡(镇)采用按人口的PPS系统抽样,再抽2个乡(镇),每个样本县共调查3个乡(镇)。
4.2.2 对村(居)委会的抽样在每个城关镇中用按人口PPS抽样抽取2个样本居(村)委会。
对其它两个样本乡、镇内,也用同样的方法抽2个村委会。
为操作方便,这里的人口数也可用户数。
4.2.3 对家庭户的抽样样本村(居)内对家庭户的抽样与样本居委会内对家庭户的抽样完全相同,仍采用随机起点的等概率系统抽样,即等距抽样。
每个村(居)固定抽取10户。
4.2.4 具体调查对象的确定在样本户中确定具体对象的方法与4.1.4中情形完全相同,即用二维随机表来确定。
4.3 儿童样本的确定在城乡每个样本户中,除抽取一位13岁以上的观众作为调查对象外,如果还有4-12岁的儿童,则需要抽取1位进行儿童观众的调查。
如果符合年龄的条件多于1位,则仍按二维随机表的方法确定。
对于自我代表的7个城市中,为保证儿童的样本量,对每个样本户,调查所有满足年龄的儿童。
五、自我代表层中的抽样方法5.1 自我代表城市的抽样方法每个需要进行推断的城市皆作为自我代表层,在层内也进行分层抽样,层的划分标准与其它子层中的区、县标准基本相同。
只不过不再对县分类,且将县级市(仅长沙市有一个)也作为一般县处理。
这样每个城市皆分为一类区、二类区及县三层。
考虑到上海市浦东新区的特殊性(既包括完全城市化的市区,也包含相当广泛的农村),将该区作为自我代表层处理。