分布式文件系统概况及FastDFS介绍_余 庆
- 格式:ppt
- 大小:449.50 KB
- 文档页数:33


fastdfs原理FastDFS是一种分布式文件系统,用于存储大规模文件的分布式存储系统。
它由跟踪服务器(tracker server)和存储服务器(storage server)组成,能够提供高性能、高可靠性和可扩展性的文件存储服务。
FastDFS的工作原理是将大文件切分成多个小文件,然后分别存储到不同的存储服务器中,同时跟踪服务器记录了每个小文件所在的存储服务器的地址和文件名。
当用户上传文件时,跟踪服务器会选择一个存储服务器,并将文件传输到该服务器上,并返回文件的地址供用户访问。
当用户需要下载文件时,跟踪服务器会根据文件的地址找到对应的存储服务器,并将文件传输给用户。
FastDFS采用了一些优化策略来提高系统性能和可靠性。
首先,它采用了分布式存储的方式,将大文件切分成小文件存储在多个存储服务器上,这样可以提高文件的读写速度。
其次,FastDFS使用了冗余存储的方式来提高系统的可靠性,即将同一文件的多个副本存储在不同的存储服务器上,当某个存储服务器发生故障时,可以通过其他存储服务器提供文件访问服务,保证系统的可用性。
此外,FastDFS还提供了文件上传和下载的负载均衡策略,可以根据服务器的负载情况选择最优的存储服务器进行文件的上传和下载。
FastDFS的设计理念是简单、易用和高效。
它采用了轻量级的协议来实现文件的上传和下载,减少了系统的复杂性和开销。
同时,FastDFS提供了丰富的客户端接口和工具,方便用户进行文件的管理和操作。
总的来说,FastDFS是一种高性能、高可靠性和可扩展性的分布式文件存储系统。
它通过将大文件切分成小文件存储在多个存储服务器上,并采用冗余存储和负载均衡等策略,提供了快速、可靠的文件存储和访问服务。
FastDFS的设计理念简单易用,同时提供了丰富的客户端接口和工具,方便用户进行文件的管理和操作。

FastDFS介绍2011年2月26日21:21FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。
它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。
准确地讲,Google FS以及FastDFS、mogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS的设计理念FastDFS是为互联网应用量身定做的分布式文件系统,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标。
和现有的类Google FS分布式文件系统相比,FastDFS的架构和设计理念有其独到之处,主要体现在轻量级、分组方式和对等结构三个方面。
轻量级FastDFS只有两个角色:Tracker server和Storage server。
Tracker server作为中心结点,其主要作用是负载均衡和调度。
Tracker server在内存中记录分组和Storage server的状态等信息,不记录文件索引信息,占用的内存量很少。
另外,客户端(应用)和Storage server访问Tracker server时,Tracker server扫描内存中的分组和Storage server信息,然后给出应答。
由此可以看出Tracker server非常轻量化,不会成为系统瓶颈。
FastDFS中的Storage server在其他文件系统中通常称作Trunk server或Data server。
Storage server直接利用OS的文件系统存储文件。
FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应。
众所周知,大多数网站都需要存储用户上传的文件,如图片、视频、电子文档等。
出于降低带宽和存储成本的考虑,网站通常都会限制用户上传的文件大小,例如图片文件不能超过5MB、视频文件不能超过100MB等。


FastDFS的介绍FastDFS的介绍FastDFSFastDFS是由国⼈余庆所开发,其项⽬地址:https:///happyfish100FastDFS是⼀个轻量级的开源分布式⽂件系统,主要解决了⼤容量的⽂件存储和⾼并发访问的问题,⽂件存取时实现了负载均衡。
FastDFS是⼀款类Google FS的开源分布式⽂件系统,它⽤纯C语⾔实现,⽀持Linux、FreeBSD、AIX等UNIX系统。
FastDFS只能通过专有API对⽂件进⾏存取访问,不⽀持POSIX接⼝⽅式,不能mount使⽤。
准确地讲,Google FS以及FastDFS、mogileFS、 HDFS、TFS等类Google FS都不是系统级的分布式⽂件系统,⽽是应⽤级的分布式⽂件存储服务。
FastDFS的特性1》分组存储,灵活简洁、对等结构,不存在单点2》⽂件ID由FastDFS⽣成,作为⽂件访问凭证,FastDFS不需要传统的name server3》和流⾏的web server⽆缝衔接,FastDFS已提供apache和nginx扩展模块4》⼤、中、⼩⽂件均可以很好⽀持,⽀持海量⼩⽂件存储5》⽀持多块磁盘,⽀持单盘数据恢复6》⽀持相同⽂件内容只保存⼀份,节省存储空间7》存储服务器上可以保存⽂件附加属性8》下载⽂件⽀持多线程⽅式,⽀持断点续传FastDFS架构图FastDFS架构解读只有两个⾓⾊,tracker server和storage server,不需要存储⽂件索引信息所有服务器都是对等的,不存在Master-Slave关系存储服务器采⽤分组⽅式,同组内存储服务器上的⽂件完全相同(RAID 1)不同组的storage server之间不会相互通信由storage server主动向tracker server报告状态信息,tracker server之间通常不会相互通信系统架构-上传⽂件流程图1》client询问tracker上传到的storage;2》tracker返回⼀台可⽤的storage;3》client直接和storage通信完成⽂件上传,storage返回⽂件ID。

分布式文件系统FastDFS详解目录为什么要使用分布式文件系统 (3)单机时代 (3)独立文件服务器 (3)分布式文件系统 (4)FastDFS (4)什么是FastDFS (4)FastDFS相关概念 (5)上传机制 (8)下载机制 (11)同步时间管理 (12)精巧的文件ID-FID (14)为什么要使用分布式文件系统单机时代初创时期由于时间紧迫,在各种资源有限的情况下,通常就直接在项目目录下建立静态文件夹,用于用户存放项目中的文件资源。
如果按不同类型再细分,可以在项目目录下再建立不同的子目录来区分。
例如:resources\static\file、resources\static\img等。
优点:这样做比较便利,项目直接引用就行,实现起来也简单,无需任何复杂技术,保存数据库记录和访问起来也很方便。
缺点:如果只是后台系统的使用一般也不会有什么问题,但是作为一个前端网站使用的话就会存在弊端。
一方面,文件和代码耦合在一起,文件越多存放越混乱;另一方面,如果流量比较大,静态文件访问会占据一定的资源,影响正常业务进行,不利于网站快速发展。
独立文件服务器随着公司业务不断发展,将代码和文件放在同一服务器的弊端就会越来越明显。
为了解决上面的问题引入独立图片服务器,工作流程如下:项目上传文件时,首先通过ftp或者ssh将文件上传到图片服务器的某个目录下,再通过ngnix或者apache来访问此目录下的文件,返回一个独立域名的图片URL地址,前端使用文件时就通过这个URL地址读取。
优点:图片访问是很消耗服务器资源的(因为会涉及到操作系统的上下文切换和磁盘I/O操作),分离出来后,Web/App服务器可以更专注发挥动态处理的能力;独立存储,更方便做扩容、容灾和数据迁移;方便做图片访问请求的负载均衡,方便应用各种缓存策略(HTTP Header、Proxy C ache等),也更加方便迁移到CDN。
缺点:单机存在性能瓶颈,容灾、垂直扩展性稍差分布式文件系统通过独立文件服务器可以解决一些问题,如果某天存储文件的那台服务突然down了怎么办?可能你会说,定时将文件系统备份,这台down机的时候,迅速切换到另一台就OK了,但是这样处理需要人工来干预。

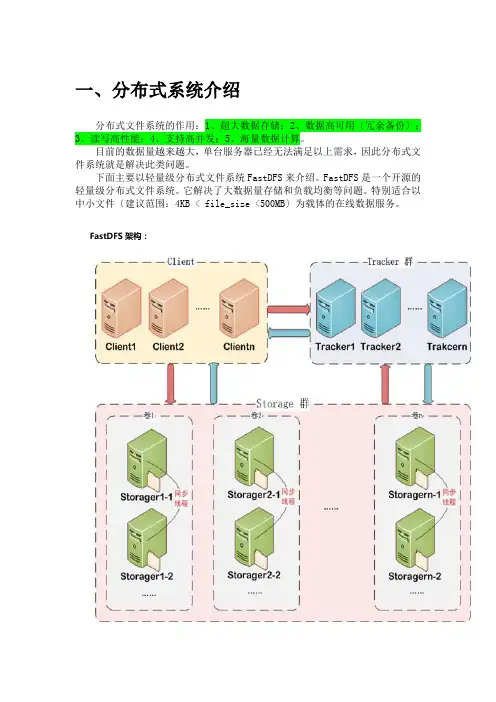
一、分布式系统介绍分布式文件系统的作用:1、超大数据存储;2、数据高可用〔冗余备份〕;3、读写高性能;4、支持高并发;5、海量数据计算。
目前的数据量越来越大,单台服务器已经无法满足以上需求,因此分布式文件系统就是解决此类问题。
下面主要以轻量级分布式文件系统FastDFS来介绍。
FastDFS是一个开源的轻量级分布式文件系统。
它解决了大数据量存储和负载均衡等问题。
特别适合以中小文件〔建议范围:4KB < file_size <500MB〕为载体的在线数据服务。
FastDFS架构:FastDFS服务端有三个角色:跟踪服务器〔tracker server〕、存储服务器〔stora ge server〕、客户端〔client〕:•tracker server:跟踪服务器,主要做调度工作,起负载均衡的作用。
在内存中记录集群中所有存储组和存储服务器的状态信息,是客户端和数据服务器交互的枢纽。
相比GFS中的master更为精简,不记录文件索引信息,占用的内存量很少。
跟踪器和存储节点都可以由一台或多台服务器构成。
跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。
其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
•storage server:存储服务器〔又称:存储节点或数据服务器〕,文件和文件属性〔m eta data〕都保存到存储服务器上。
Storage server直接利用OS的文件系统调用管理文件。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的metadata进行管理。
所谓文件的meta data就是文件的相关属性,以键值对〔key valuepair〕方式表示,如:width=1024,其中的key为width,value为1024。
文件metadata是文件属性列表,可以包含多个键值对。
为了支持大容量,存储节点〔服务器〕采用了分卷〔或分组〕的组织方式。

fastdfs 原理FastDFS是一个开源的分布式文件系统,其设计目标是高性能、高可靠、易扩展。
它主要用于解决大规模文件存储和文件访问问题,广泛应用于互联网领域中的图片、音视频等大文件存储和访问场景。
FastDFS的原理可以分为两个部分:存储部分和访问部分。
存储部分是FastDFS的核心,它由一组存储服务器组成,每个存储服务器独立运行,可以扩展到数百台服务器。
存储服务器之间通过心跳检测和状态同步来保证数据的一致性。
文件在存储服务器上以文件ID的形式存储,文件ID由文件内容的哈希值和存储服务器的标识组成,通过哈希算法可以将文件均匀地分布到不同的存储服务器上,实现负载均衡。
存储服务器采用多副本的方式来提高数据的可靠性,每个文件在存储服务器上都有多个副本,当其中一个存储服务器出现故障时,可以通过其他副本来提供服务。
访问部分是FastDFS的客户端,它负责将文件上传到存储服务器,并提供文件下载和删除等功能。
客户端通过Tracker服务器来获取存储服务器的地址信息,Tracker服务器维护了存储服务器的状态信息和文件的元数据信息,通过一致性哈希算法可以快速定位到存储服务器。
客户端上传文件时,首先向Tracker服务器发送请求,获取可用的存储服务器地址,然后将文件分成多个小块,并将每个小块上传到不同的存储服务器上,最后将文件的元数据信息保存到Tracker服务器上。
客户端下载文件时,先通过Tracker服务器获取存储服务器地址,然后根据文件ID找到对应的存储服务器,并从存储服务器上下载文件。
FastDFS的优点主要体现在以下几个方面:1. 高性能:FastDFS采用了分布式存储和负载均衡的机制,可以将文件均匀地分布到不同的存储服务器上,有效地提高了文件的访问速度和并发处理能力。
2. 高可靠性:FastDFS采用多副本的方式来存储文件,当某个存储服务器出现故障时,可以通过其他副本来提供服务,保证了数据的可靠性和高可用性。

01.分布式存储之FastDFS简介及部署分布式存储简介现代的互联⽹已经进⼊⼤数据时代,每天都有数以万计的数据产⽣,这些数据的规模轻轻松松地可以达到⼏P的级别,传统的的单机存储早已捉襟见肘,根本⽆法满⾜⼤数据对存储系统的要求。
这时,各种分布式系统才应运⽽⽣。
其实分布式的概念,早在很多年前,就有⼈提出和进⾏相关研究,但是由于当时的⽹络数据很少,分布式⽆⽤武之地,⼀直不温不⽕,⼀⾄到⼤数据时代的来临,才陆陆续续被⼈们应⽤到⼯程实践中。
概念分布式存储系统,是将数据分散存储在多台独⽴的设备上。
传统的⽹络存储系统采⽤集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满⾜⼤规模存储应⽤的需要。
分布式⽹络存储系统采⽤可扩展的系统结构,利⽤多台存储服务器分担存储负荷,利⽤位置服务器定位存储信息,它不但提⾼了系统的可靠性、可⽤性和存取效率,还易于扩展。
特性可扩展分布式存储系统可以扩展到⼏百台甚⾄⼏千台的集群规模,⽽且随着集群规模的增长,系统整体性能表现为线性增长。
低成本分布式存储系统的⾃动容错、⾃动负载均衡机制使其可以构建在普通的PC机之上。
另外,线性扩展能⼒也使得增加、减少机器⾮常⽅便,可以实现⾃动运维。
⾼性能⽆论针对整个集群还是单台服务器,都要求分布式存储系统具备⾼性能易⽤分布式存储系统需要能够提供易⽤的对外接⼝,另外,也要求具备完善的监控、运维⼯具,并能够⽂玩与其他系统集成.技术难点分布式存储系统的挑战主要在于数据、状态信息的持久化,要求在⾃动迁移、⾃动容错、并发读写的过程中保证数据的⼀致性。
分布式存储涉及的技术主要来⾃两个领域:分布式系统以及数据库。
数据分布如何将数据分布到多台服务器才能保证数据分布均匀?数据分布到多台服务器后如何实现跨服务器读写操作?分布式系统区别于传统单机系统在于能够将数据分布到多个节点,并在多个节点之间实现负载均衡。
分布式存储系统的⼀个基本要求就是透明性,包括数据分布透明性,数据迁移透明性,数据复制透明性还有数据故障透明性。

经典分布式文件系统全介绍随着云计算和大数据的快速发展,分布式文件系统成为构建大规模分布式存储系统的基础技术。
本文将对经典分布式文件系统进行全面介绍,包括定义、架构、特点、应用等方面。
一、定义:分布式文件系统(Distributed File System,简称DFS)是一种在多台计算机上共享存储资源的文件系统,它将多台计算机的存储组织起来,形成一个单一的文件系统。
用户可以通过网络访问这个文件系统,进行文件的存储和管理。
二、架构:1.文件元数据存储:用于存储文件的元数据信息,如文件名、大小、权限、创建时间等。
2.数据存储:用于存储文件的实际数据块,可以采用多种存储介质,如硬盘、闪存等。
3.元数据管理:负责管理文件元数据的创建、读取、更新和删除操作,保证文件系统的一致性。
4.数据管理:负责数据的分块、传输和备份,保证数据的可靠性和高效性。
5.客户端接口:提供用户访问分布式文件系统的接口,包括文件的读取、写入、删除等操作。
三、特点:1.可扩展性:分布式文件系统可以轻松地扩展存储容量和性能,通过增加存储服务器和负载均衡技术实现。
2.高效性:分布式文件系统能够并行处理多个文件和数据块的读写操作,提高文件的访问速度。
3.可靠性:分布式文件系统具备数据冗余和容错机制,可以保证数据的可靠性和持久性。
4.数据一致性:分布式文件系统能够保证并发访问下的数据一致性,并提供一致的文件视图。
5.安全性:分布式文件系统提供了权限控制和身份认证机制,可以保护文件系统中的数据安全。
四、应用:1.云存储:分布式文件系统是云存储的核心技术,可以提供大规模的存储空间和高可用性的数据访问。
2.大数据处理:分布式文件系统可以作为大数据处理平台的基础设施,支持海量数据的存储和分析。
3.视频监控:分布式文件系统能够扩展存储容量和带宽,满足视频监控系统对大容量、高并发的存储需求。
4.分布式数据库:分布式文件系统提供可靠的数据存储和访问接口,可以作为分布式数据库的存储层。
FastDFS分布式⽂件系统详解什么是⽂件系统 ⽂件系统是操作系统⽤于在磁盘或分区上组织⽂件的⽅法和数据结构。
磁盘空间是什么样的我们并不清楚,但⽂件系统可以给我们呈现⼀个⾮常清晰的表象,我们可以创建、删除、修改和复制这些⽂件,⽽实现这些功能的软件就是⽂件系统。
操作系统中负责管理和存储⽂件信息的软件被称为⽂件管理系统,简称⽂件系统。
⽂件系统是操作系统的⼀个重要组成部分,通过对操作系统所管理的存储空间的抽象,向⽤户提供统⼀的、对象化的访问接⼝,屏蔽对物理设备的直接操作和资源管理。
也就是说,⽂件系统解决了普通⽤户使⽤磁盘存储数据的问题。
⽂件系统的发展史 根据计算环境和所提供功能的不同,⽂件系统可划分为以下⼏种。
单机⽂件系统 特点:⽤于操作系统和应⽤程序的本地存储。
缺点:数据⽆法在多台机器之间共享。
代表:EXT2、EXT3、EXT4、NTFS、FAT、FAT32、XFS、JFS 等等。
⽹络⽂件系统 特点:基于现有以太⽹架构,实现不同服务器之间传统⽂件系统的数据共享。
缺点:两台服务器不能同时访问修改,性能有限。
代表:NFS、CIFS 等等,⽐如下图 Windows 主机之间进⾏⽹络⽂件共享就是通过微软公司⾃⼰的 CIFS 服务实现的。
分布式⽂件系统 数据量越来越多,在⼀个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不⽅便管理和维护,因此迫切需要⼀种系统来管理多台机器上的⽂件,这就是分布式⽂件管理系统。
分布式⽂件系统(Distributed File System)是⼀种允许⽂件通过⽹络在多台主机上共享的⽂件系统,可以让多机器上的多⽤户进⾏⽂件分享和存储。
在这样的⽂件系统中,客户端并⾮直接访问底层的数据存储区块,⽽是通过⽹络,以特定的通信协议和服务器沟通。
DFS 为分布在⽹络上任意位置的资源提供⼀个逻辑上的树形⽂件系统结构,让⽤户访问分布在⽹络上的共享⽂件更加简便。
所有⾼层次的⽂件系统都是以低层次的传统⽂件系统为基础,实现了更⾼级的功能。
Java ⾼级架构之FastDFS 分布式⽂件集群详解FastDFS 简介FastDFS 是⼀款开源的轻量级分布式⽂件系统,使⽤C 实现,⽀持Linux 、BSD 等unix-like 操作系统。
值得注意的是,fastdfs 并不是通⽤的⽂件系统,只能通过专⽤的API 访问。
fastdfs 为互联⽹应⽤量⾝定做,解决了⼤容量⽂件存储的问题,fastdfs 追求⾼性能和⾼扩展性。
fastdfs 的主要概念:tracker-server :跟踪服务器。
⽤于跟踪⽂件,主要起调度作⽤。
在内存中记录了所有存储组和存储服务器的状态信息,是客户端和数据存储的主要枢纽。
相⽐GFS 更为精简,因为不记录⽂件索引。
storage-server: 存储服务器。
⽤于存储⽂件。
直接使⽤操作系统的⽂件系统来管理和组织⽂件。
group: 组,卷。
多个服务器存在⼀个组中,在⼀个组中的服务器存储的⽂件是完全相同的,并且同⼀个组的服务器地位是对等的。
对于⽂件的操作可以在任意⼀个组中的服务器上进⾏。
metadata:元数据。
以键值对的⽅式存储,⽤于存储⽂件的相关信息。
各⼤存储系统的对⽐话说没有对⽐就没有伤害,fastdfs 也不是万能的,需要根据业务来选择适合的存储系统。
存储系统适合存储的⽂件类型⽂件分布情况系统性能复杂度FUSE(⽤户⽂件系统)POSIX()备份机制通讯协议接⼝社区情况实现语⾔FastDFS4KB ⾄500MB将⼩⽂件合并存储很⾼简单不⽀持不⽀持组内冗余备份HTTP API国内⽤户C TFS所有⽂件⼩⽂件合并以块组织分⽚-复杂不⽀持不⽀持块存储多份,主辅灾备HTTPAPI 少C++MFS⼤于64K分⽚存储Master 节点占⽤内存较⾼-⽀持⽀持多点备份,动态冗余使⽤FUSE 挂载较多Perl HDFS ⼤⽂件⼤⽂件分⽚块存储-简单⽀持⽀持多副本原⽣API 较多Java Ceph 对象⼤⽂件OSD ⼀主多从-复杂⽀持⽀持多副本原⽣API较少C++MogileFS海量⼩图⽚-⾼复杂⽀持不⽀持动态冗余原⽣API ⽂档少Perl ClusterFS ⼤⽂件--简单⽀持⽀持--多CFastDFS 客户端与服务器端交互原理FastDFS+Nginx整合架构图安装FastDFSmkdir /sourcecd /sourceyum install -y gcc gcc-c++ make cmake wget libeventwget https:///happyfish100/libfastcommon/archive/V1.0.35.tar.gz wget https:///happyfish100/fastdfs/archive/V5.10.tar.gztar -zxvf V1.0.35.tar.gztar -zxvf V5.10.tar.gzcd libfastcommon-1.0.35./make.sh./make.sh installln -s /usr/lib64/libfastcommon.so /usr/local/lib/libfastcommon.socd ../cd fastdfs-5.10/./make.sh./make.sh installcd ../rm -rf libfastcommon-1.0.35rm -rf fastdfs-5.10cp /etc/fdfs/tracker.conf.sample /etc/fdfs/tracker.confcp /etc/fdfs/storage.conf.sample /etc/fdfs/storage.confcp /etc/fdfs/client.conf.sample /etc/fdfs/client.confmkdir -p /data/fdfs/trackermkdir -p /data/fdfs/storageln -s /usr/bin/stop.sh /usr/local/bin/stop.shln -s /usr/bin/restart.sh /usr/local/bin/restart.sh修改配置⽂件修改跟踪器配置⽂件:base_path=/data/fdfs/tracker修改存储器配置⽂件:base_path=/data/fdfs/storagestore_path0=/data/fdfs/storagetracker_server=192.168.80.3:22122修改客户端配置⽂件:base_path=/data/fdfs/clienttracker_server=192.168.80.3:22122启动/etc/init.d/fdfs_trackerd start/etc/init.d/fdfs_storaged startnetstat -tunlap | grep :22122tcp 0 0 0.0.0.0:22122 0.0.0.0:* LISTEN 7247/fdfs_trackerdtcp 0 0 192.168.80.3:22122 192.168.80.3:39318 ESTABLISHED 7247/fdfs_trackerdtcp 0 0 192.168.80.3:39318 192.168.80.3:22122 ESTABLISHED 7444/fdfs_storaged启动后要查看状态, 出现active (exited)字样可以尝试重启服务。
FastDFS的原理及详解FastDFS是⼀个以C语⾔开发的开源的轻量级分布式⽂件系统,它对⽂件进⾏管理,功能包括:⽂件存储、⽂件同步、⽂件访问(⽂件上传、⽂件下载)等,解决了⼤容量存储和负载均衡的问题。
特别适合以中⼩⽂件(建议范围:4KB < file_size <500MB),如相册⽹站、视频⽹站等等。
FastDFS为互联⽹量⾝定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重⾼可⽤、⾼性能等指标,使⽤FastDFS很容易搭建⼀套⾼性能的⽂件服务器集群提供⽂件上传、下载等服务。
FastDFS原理FastDFS由跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)构成。
Tracker server追踪服务器主要作⽤是负载均衡和资源调度。
追踪服务器负责接收客户端的请求,选择合适的组合storage server,tracker server与storage server之间也会⽤⼼跳机制来检测对⽅是否活着。
Tracker需要管理的信息也都放在内存中,并且⾥⾯所有的Tracker都是对等的(每个节点地位相等),很容易扩展。
客户端访问集群的时候会随机分配⼀个Tracker来和客户端交互。
Storage server储存服务器实际存储数据,分成若⼲个组(group),实际traker就是管理的storage中的组,⽽组内机器中则存储数据,group可以隔离不同应⽤的数据,不同的应⽤的数据放在不同group⾥⾯。
优点:海量的存储:主从型分布式存储,存储空间⽅便拓展,且集群的实现也使系统不存在单点故障问题,⽤户不会因为服务器宕机⽽⽆法访问⽂件资源。
fastDFS对⽂件内容做hash处理,避免出现重复⽂件,然后fastDFS结合Nginx集成,提供⽹站效率。
客户端Client主要是上传下载数据的服务器,也就是我们⾃⼰的项⽬所部署在的服务器。
FastDFS分布式⽂件系统及源码解析记录⼀次本⼈学习FastDFS-分布式⽂件系统的学习过程,希望能帮助到有需要的⼈.⾸选得对此技术有个⼤概的了解,可以参考 ,其实⼤致看下图知道⼀下就⾏了.然后我们就直接开装了,⽹上有⼀⼤堆的安装教程这⾥也就不做介绍了,可以直接百度,如果有需要可以直接⽤我的百度⽹盘的链接:https:///s/1Y07hC2tiDy_E18ZAD4YKvg提取码:j5d0装完测通以后就开始撸JAVA代码,经过我⼀番研究发现了⼀位⼤佬,封装了⼀个⼯具jar包⼗分好⽤,maven⾥引⼊<dependency><groupId>com.github.tobato</groupId><artifactId>fastdfs-client</artifactId><version>1.26.5</version></dependency>具体的demo已经介绍可以参考引⼊了⼤佬jar包后⽤起来⼗分爽只要改⼀下trackerList的地址换成⾃⼰的就⾏了然后调具体的api即可使⽤我发现⼗分⽅便都没有做bean的配置就可以⽤了,研究了⼀番发现如下:接下来我就开始看改jar包的源码了,我们可以直接在IDE⾥下载,下载后源码可以看到中⽂注释,⼗分的爽⾸先可以看⼀下,包结构以及各个类的继承关系,这⾥推荐使⽤IDE看,对着类名按Ctrl+h就可以看到该类的上下结构或者使⽤Ctrl+Alt+Shift+U可以看到更详细的关系层次图.开始⼀步步分析源码,客户端API接⼝为FastFileStorageClient,该类是⼀个接⼝,最终的实现类为DefaultFastFileStorageClient下⾯我们来分析⼀下这个类,该类实现了接⼝FastFileStorageClient,FastFileStorageClient包含了⼀写上传下载⽂件等API,该接⼝继承了GenerateStorageClient说明这是在根接⼝上扩展⼀些APi接⼝.FastFileStorageClient继承了类DefaultGenerateStorageClient,该类是基本存储客户端操作实现,也就是说基础的存储功能⽤这个类就⾏了,下⾯我们来分析⼀下这个类.就找⼀个uploadFile()⽅法来说⼀下,其它的也是换汤不换药的,理解整体思路就⾏了.看到⾸先从trackClient这个类⾥取获取trackServer帮我们根据其⾃⾝算法帮我们计算出的存储节点信息.Debug发现,其实调⽤的是 DefaultTrackerClient然后从TrackerConnectionManager这个类中去执⾏对应的命令,作者把执⾏的操作⽤command做接⼝,各个操作就是最终command的实现类,这样程序的扩展性维护性就会很⾼咯,这⾥new Command对象就是把⾃定义的request和response包装⼀下即可(因为不同的command中的request和response不⼀样,所以就需要放到不同的类,不然⽤AbstractFdfsCommand这个公共类就⾏了)接着进⼊execute⽅法了,哦豁⼀看,执⾏交易,啥交易,py的那种吗,嘿嘿⽪⼀下⾸先该⽅法是获取连接,先找到yml⾥的trackServer地址,trackerLocator.getTrackerAddress(); trackerLocator这个类也是⼀层套⼀层,⼤家可以⾃⼰去看⼀下⽤了@PostConstruct注解,SpringBoot启动时候就会去执⾏⼀层⼀层的构造函数获取到连接(该链接还⽤连接池,作者⾃⼰写的⼀个连接池FdfsConnectionPool,每次获取连接的时候就池⼦⾥获取就⾏了)和地址以后就可以可以去执⾏具体操作了,最终会定位再AbstractFdfsCommand这个抽象类上去执⾏execute,与其说是抽象类,倒不如说是⼀个公共command执⾏类,所以继承该抽象类的execute⽅法都在它这⾥我们终于快看到头,send和receive这两个⽅法才是最底层的操作,send顾名思义就是发送,把command⾥的⼀些请求信息会发送给StorageServer(StorageServer的地址是被trackServer找到的,也就是我们客户端只需要trackServer的地址就⾏了,它会负责帮我们去找负责存储StorageServer的地址,然后帮助我们之间与其通讯,建⽴Socket通讯),好了,我们已经把请求发送给fastDFS服务端,接着它会告诉我们哪个存储节点我们可以去⽤,也就是receive⽅法中获得这些信息,最终⼀层层的返回给上级,接着我们就可以把⽂件变成Byte数组,还是之前的套路,最终到send和receive⽅法,send的时候会把⽂件写⼊到存储的⽂件节点上,最后receive⽅法可以返回路径信息等(这⾥就有⼀个疑问,为什么不⽤netty这种nio,不是好⼀点吗???有没有⼤佬能告诉我)⼀套基本的⽂件上传就完成了,api接⼝⼤致都是封装成具体的command,然后获取连接,执⾏⽅法command,最终就是send和receive⽅法.好了,⼤致的分析,⽐较通俗,也是⾃⼰的⼀些看法见解,如果有不对的地⽅,还请指正,⼯具包我在csdn上购买的,花了1块5呢 ,送给你们了!!!哈哈哈。
分布式FastDFS集群部署FastDFSFastDFS的作者余庆在其上是这样描述的:“FastDFS is an open source high performance distributed file system. It's major functions include: file storing, file syncing and file accessing (file uploading and file downloading), and it can resolve the high capacity and load balancing problem. FastDFS should meet the requirement of the website whose service based on files such as photo sharing site and video sharing site” ,意思说,FastDFS是⼀个开源的⾼性能分布式⽂件系统。
其主要功能包括:⽂件存储、⽂件同步和⽂件访问(⽂件上传和⽂件下载),它可以解决⾼容量和负载平衡问题。
FastDFS应满⾜基于照⽚共享站点和视频共享站点等⽂件的⽹站的服务要求。
FastDFS 有两个⾓⾊:跟踪器(Tracker)和存储器(Storage)。
Tracker 负责⽂件访问的调度和负载平衡。
Storage 存储⽂件及其功能是⽂件管理,包括:⽂件存储、⽂件同步、提供⽂件访问接⼝。
它还管理元数据,这些元数据是表⽰为⽂件的键值对的属性。
Tracker 和 Storage 节点都可以由⼀台或多台服务器构成。
这些服务器均可以随时增加或下线⽽不会影响线上服务,当然各个节点集群⾄少需要⼀台服务 Running。
注意,其中 Tracker 集群中的所有服务器都是对等的(P2P),可以根据服务器的压⼒情况随时增加或减少。
(⼀)FastDFS⾼可⽤集群架构学习---简介1、什么是FastDFS FastDFS 是余庆⽼师⽤c语⾔编写的⼀筐开源的分布式⽂件系统,充分考虑了冗余备份,负载均衡,线性扩容等机制,并注重⾼可⽤、⾼性能等指标,使⽤FastDFS可以很容易搭建⼀套⾼性能的⽂件服务器集群提供⽂件上传下载. FastDFS 实现了软件⽅式的RAID,可以使⽤廉价的IDE硬盘进⾏存储⽀持存储服务器在线扩容⽀持相同内容的⽂件只保存⼀份,节约磁盘空间; FastDFS 只能通过Client API访问,不⽀持POSIX访问⽅式; FastDFS 特别适合⼤中型⽹站使⽤,⽤来存储资源⽂件(如:图⽚、⽂档、⾳频、视频等等)。
2、FastDFS 的框架结构 FastDFS 系统有三个⾓⾊:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server: 跟踪服务器,主要做调度⼯作,起到均衡的作⽤;负责管理所有的storage server和group,每个storage在启动后会连接 Tracker,告知⾃⼰所属 group 等信息,并保持周期性⼼跳。
多个Tracker之间是对等关系,不存在单点故障。
Storage Server: 存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,组内的所有Storage Server之间是平等关系,会相互连接进⾏⽂件同步,从⽽保证组内的所有Storage Server的⽂件内容⼀致,所以建议group内的多个storage尽量配置相同,以免造成存储空间的浪费,不同组之间的Storage Server之间不会相互通信。
group内每个storage的存储依赖于本地⽂件系统,storage可配置多个数据存储⽬录,⽐如有10块磁盘,分别挂载在/data/disk1-/data/disk10,则可将这10个⽬录都配置为storage的数据存储⽬录。