计量资料的统计推断
- 格式:ppt
- 大小:1.09 MB
- 文档页数:100

统计描述与统计推断统计的主要工作就是对统计数据进行统计描述和统计推断。
统计描述是统计分析的最基本内容,是指应用统计指标、统计表、统计图等方法,对资料的数量特征及其分布规律进行测定和描述;而统计推断是指通过抽样等方式进行样本估计总体特征的过程,包括参数估计和假设检验两项内容。
(一)统计描述1.计量资料的统计描述计量资料的统计描述主要通过编制频数分布表、计算集中趋势指标和离散趁势指标以及统计图表来进行。
(1)集中趋势。
指频数表中频数分布表现为频数向某一位置集中的趋势。
集中趋势的描述指标:1)算术平均数。
直接法:x为观察值,n为个数加权法又称频数表法,适用于频数表资料,当观察例数较多时用。
f为各组段的频数。
2)几何平均数(geometric mean)。
几何平均数用符号G表示。
用于反映一组经对数转换后呈对称分布的变量值在数学上的平均水平。
直接法:加权法又称频数表法,当观察例数n较大时,可先编制频数分布表,用此法算几何平均数:3)百分位数(percentile )与中位数(median )。
百分位数是一种位置坐标,用符号x P 表示常用的百分位数有 2.5P 、5P 、50P 、75P 、95P 、97.5P 等,其中25P 、50P 、75P 又称为四分位数。
百分位数常用于描述一组观察值在某百分位置上的水平,多个百分位结合使用,可更全面地描述资料的分布特征。
中位数是一个特定的百分位数即50P ,用符号M 表示。
把一组观察值按从小到大(或从大到小)的次序排列,位置居于最中央的那个数据就是中位数。
中位数也是反映频数分布集中位置的统计指标,但它只由所处中间位置的部分变量值计算所得,不能反映所有数值的变化,故中位数缺乏敏感性。
中位数理论上可以用于任何分布类型的资料,但实践中常用于偏态分布资料和分布两端无确定值的资料。
其计算方法有直接法和频数表法两种。
直接法:当观察例数n 不大时,此法常用,先将观察值按大小次序排列,选用下列公式求M 。


《计量资料的统计推断》的复习思考题1.什么是统计推断?统计推断包括哪两方面内容?2.什么样的分布是t分布?对称分布、正态分布、t分布和标准正态分布有何区别和联系?3.什么是标准误?标准差和标准误有什么区别和联系?4.什么是总体均数的可信区间?某指标的95%正常值范围和95%可信区间有何区别何联系?5.显著性检验的目的意义是什么?基本原理是什么?前提条件有哪些?6.什么情况下可认为具有可比性?举例说明日常生活中常犯的没有可比性时进行比较的错误。
7.显著性检验的一般步骤有哪些?8.显著性检验时,假设有几种?哪几种?如何假设?9.假设检验时,如何选择进行单侧或双侧检验?10.什么是检验水准/显著性水平?一般是多少?如何根据实际情况来确定检验水准?11.假设检验时的“P值”是什么?举例说明。
12.统计学结论和实际意义有何异同?13.什么情况下应该作u/z检验?什么情况下应该作t检验?14.举例说明成组设计和配对设计有何区别。
15.有人说,“只要是比较两个均数,都可以作t检验。
”你认为这种说法对吗?为什么?16.什么是I类错误?什么是II类错误?为什么显著性检验时会犯这两类错误?这两类错误各有什么特点?相互之间有什么关系?17.什么是把握度?科学研究时如何才能使把握度达到一定的水平?18.为什么说统计学结论是概率性的,既不绝对肯定,也不绝对否定?19.随机抽取某品种2月龄苗猪25头,测得其平均体重为20kg,标准差为3kg。
试估计该品种2月龄苗猪的体重。
20.随机测得100听某批某种罐头净重量平均为344.0g,标准差为4.43g。
试估计该批该种罐头的净重量和正常值范围。
21.某鱼场按常规方法所育鲢鱼苗一月龄的平均体长为7.25cm,标准差为1.58cm。
为提高鱼苗质量,现采用一新方法进行育苗,一月龄时随机抽取100尾进行测量,测得其平均体长为7.65cm。
试问新方法能否使一月龄鲢鱼苗体长更长?22.某名优绿茶含水量标准为不超过5.5%。

计量资料的统计学方法
首先,计量资料的统计学方法包括描述统计和推断统计。
描述
统计用于总结和展示数据的特征,包括均值、中位数、标准差、频
数分布等。
这些统计量可以帮助我们了解数据的集中趋势、离散程
度和分布形态。
推断统计则用于从样本数据中推断总体的特征,包
括参数估计和假设检验。
参数估计可以帮助我们对总体参数(如均值、比例)进行估计,而假设检验则可以帮助我们对总体参数的假
设进行检验。
其次,计量资料的统计学方法还包括回归分析和方差分析。
回
归分析用于研究自变量和因变量之间的关系,可以帮助我们预测因
变量的取值。
常见的回归分析包括简单线性回归和多元线性回归。
方差分析则用于比较多个总体均值是否相等,可以帮助我们判断不
同组别之间的差异是否显著。
此外,计量资料的统计学方法还包括相关分析和时间序列分析。
相关分析用于研究两个变量之间的相关关系,可以帮助我们了解它
们之间的相关性强弱和方向。
时间序列分析则用于研究时间序列数
据的特征和规律,包括趋势、季节性和周期性等,可以帮助我们进
行未来的预测和规划。
综上所述,计量资料的统计学方法涵盖了描述统计、推断统计、回归分析、方差分析、相关分析和时间序列分析等多个方面,可以
帮助我们全面深入地理解和解释数据的特征和规律。
在实际应用中,研究者可以根据具体问题的特点和要求选择合适的统计方法进行分
析和解释。

医学统计学笔记一、绪论及基本概念1. 资料类型①计量资料(定量资料、数值变量资料):连续型、离散型②计数资料(定性资料、无序分类变量、名义变量):二分类、多分类③等级资料(半定量资料、有序分类变量)信息量:计量资料>等级资料>计数资料2.误差类型①过失误差:可避免②系统误差:具有明确的方向性,可避免③随机误差:分为随机测量误差和随机抽样误差,没有固定的大小和方向,不可避免3.核心概念参数:u、σ;固定的常数,总体的统计指标,参数大小客观存在,但往往未知。
统计量:X̅,S,P;样本的统计指标,参数附近波动的随机变量。
概率为参数,频率为统计量。
4.医学统计工作的基本步骤:设计、收集资料、整理资料、分析资料二、计量资料的统计描述1.集中趋势的描述a.算术均数,简称均数(mean):主要适用于对称分布或偏度不大的资料,尤其适合正态分布资料。
不能用于开口型资料。
u(总体均数),X(样本均数)。
b.几何均数(geometric mean,G):适用于经对数转换后呈对称分布。
观察值不能为0 、不能同时有正有负。
同一资料算得的几何均数小于算术均数。
c.中位数(median, M)和百分位数(precentile, Px):适用于各种分布类型资料。
当计量资料适合计算均数或几何均数时,不宜用中位数表示其平均水平。
用频数表法计算百分位数时,组距不一定要相等。
P x=L x+i x(n∗x%−∑f L)f xL x:第x百分位数所在组段的下限i x:第x百分位数所在组段的组距f x:第x百分位数所在组段的频数∑f L:第x百分位数所在组段上一组段累计频数d.调和均数(harmonic mean,H):适用于表达呈极严重的正偏态分布资料的平均水平。
计算方法为求倒数的均值后再取其倒数。
SPSS:在Transform中输入公式。
2.离散(dispersion)趋势的描述a.极差(range,R):也称为全距。
b.四分位数间距(quartile range,Q):即统计图中箱子的高度,常用于偏态资料离散度的描述,多与M 合用。

计量资料和计数资料的统计方法计量资料和计数资料是统计学中常见的两种数据类型,它们在统计分析中有着不同的处理方法和应用场景。
本文将分别介绍计量资料和计数资料的统计方法,并探讨其在实际问题中的应用。
一、计量资料的统计方法计量资料是指可以用数值表示的数据,例如身高、体重、温度等。
统计学中常用的计量资料分析方法有描述统计和推断统计。
1. 描述统计描述统计是对收集到的数据进行总结和描述的方法。
常用的描述统计量有平均值、中位数、众数、标准差、方差等。
平均值是计量资料最常用的描述统计量,它可以反映数据的集中趋势。
中位数和众数则可以反映数据的位置和分布情况。
标准差和方差则可以衡量数据的离散程度。
2. 推断统计推断统计是基于样本数据对总体进行推断的方法。
在推断统计中,常用的统计分析方法有假设检验和置信区间估计。
假设检验用于验证关于总体的某个参数的假设,例如总体均值是否等于某个特定值。
置信区间估计则可以给出总体参数的一个区间估计,例如总体均值的置信区间。
二、计数资料的统计方法计数资料是指不连续的、以计数形式出现的数据,例如人数、次数、事件发生次数等。
计数资料的统计方法主要包括频数分布、列联表分析和卡方检验。
1. 频数分布频数分布是计数资料最常用的分析方法之一,它将数据按照不同的取值进行分类,并统计每个类别的频数。
通过频数分布可以直观地了解数据的分布情况和特征。
2. 列联表分析列联表分析是用于分析两个或多个分类变量之间关系的方法。
通过构建列联表可以清晰地展示不同变量之间的交叉频数,并计算各个格子的期望频数和卡方值。
列联表分析可以帮助我们判断两个变量之间是否存在相关性。
3. 卡方检验卡方检验是用于检验两个或多个分类变量之间是否存在显著差异的统计方法。
卡方检验基于计数资料的频数分布和列联表,通过计算观察频数与期望频数的差异,并进行假设检验来判断变量之间是否独立。
三、计量资料和计数资料的应用计量资料和计数资料在实际问题中具有广泛的应用。

正保远程教育旗下品牌网站 美国纽交所上市公司(NYSE:DL)
自考365 中国权威专业的自考辅导网站
官方网站: 高等教育自学考试辅导《护理学研究》第八章第二节讲义1
量性研究资料的统计学分析方法
一、计量资料的统计学分析方法
二、计数资料的统计学分析方法
三、等级资料常用的统计学分析方法
四、统计表和统计图
量性研究资料的统计分析包括两个方面:
①统计描述:即描述数据的分布规律和特征,常用均数、标准差、中位数、率、构成比等统计指标,以及统计表、统计图等进行描述。
②统计推断:即由样本信息推断总体特征,常用t 检验、方差分析、χ2检验、秩和检验等比较组间有无差异,以及相关分析、回归分析等探讨变量之间的关联性。
统计学分析方法的选择取决于研究目的、科研设计类型和资料类型。
计量资料的统计学分析方法
(一)统计描述
正态分布:均数±标准差
偏态分布:中位数、四分位数间距
1.均数。

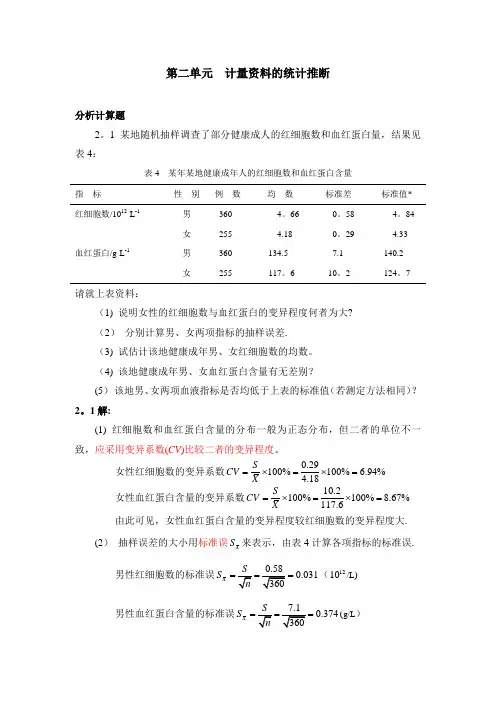
第二单元 计量资料的统计推断分析计算题2。
1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4:表4 某年某地健康成年人的红细胞数和血红蛋白含量指 标性 别 例 数 均 数 标准差 标准值* 红细胞数/1012·L -1 男 360 4。
66 0。
58 4。
84女 255 4.18 0。
29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2女255117。
610。
2124。
7请就上表资料:(1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差. (3) 试估计该地健康成年男、女红细胞数的均数。
(4) 该地健康成年男、女血红蛋白含量有无差别?(5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2。
1解:(1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。
女性红细胞数的变异系数0.29100%100% 6.94%4.18S CV X =⨯=⨯= 女性血红蛋白含量的变异系数10.2100%100%8.67%117.6S CV X =⨯=⨯= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大. (2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误.男性红细胞数的标准误0.031X S ===(1210/L ) 男性血红蛋白含量的标准误0.374X S ===(g/L )女性红细胞数的标准误0.018X S ===(1210/L )女性血红蛋白含量的标准误0.639X S ===(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数.样本含量均超过100,可视为大样本.σ未知,但n 足够大 ,故总体均数的区间估计按(/2/2X X X u S X u S αα-+ , )计算。

医学统计学计量资料的统计推断主要内容:标准误t 分布总体均数的估计假设检验均数的 t检验、u 检验、方差分析几个重要概念的回顾:计量资料:总体:样本:统计量:参数:统计推断:参数估计、假设检验第一节均数的抽样误差与总体均数的估计欲了解某地2000年正常成年男性血清总胆固醇的平均水平,随机抽取该地200名正常成年男性作为样本。
由于存在个体差异,抽得的样本均数不太可能恰好等于总体均数。
一、均数的抽样误差与标准误一、均数的抽样误差与标准误抽样误差:由于抽样引起的样本统计量与总体参数之间的差异X数理统计推理和中心极限定理表明:1、从正态总体N(??,??2)中,随机抽取例数为n的样本,样本均数??X 也服从正态分布;即使从偏态总体抽样,当n足够大时??X也近似正态分布。
2、从均数为??,标准差为??的正态或偏态总体中抽取例数为n的样本,样本均数??X的总体均数也为??,标准差为X标准误含义:样本均数的标准差计算:(标准误的估计值)注意: X 、S??X均为样本均数的标准误标准误意义:反映抽样误差的大小。
标准误越小,抽样误差越小,用样本均数估计总体均数的可靠性越大。
标准误用途:衡量抽样误差大小估计总体均数可信区间用于假设检验二 t 分布对正态变量样本均数??X做正态变换(u变换):X 常未知而用S??X估计,则为t变换:二、 t 分布t值的分布即为t分布t 分布的曲线:与??有关t分布与标准正态分布的比较1、二者都是单峰分布,以0为中心左右对称2、t分布的峰部较矮而尾部翘得较高说明远侧的t值个数相对较多即尾部面积(概率P值)较大。
当ν逐渐增大时,t分布逐渐逼近标准正态分布,当ν→??时,t分布完全成为标准正态分布t 界值表(附表9-1 )t??/2,??:表示自由度为??,双侧概率P为??时t的界值t分布曲线下面积的规律:中间95%的t值:- t0.05/2,?? ?? t0.05/2,??中间99%的t值:- t0.01/2,?? ?? t0.01/2,??单尾概率:一侧尾部面积双尾概率:双侧尾部面积(1) 自由度(ν)一定时,p与t成反比;(2) 概率(p)一定时,ν与t成反比;三总体均数的估计统计推断:用样本信息推论总体特征。
6 计量资料的统计推断-t检验t检验是以t分布为理论依据的假设检验方法,常用于正态总体小样本资料的均数比较,t检验统计量有三个不同的形式,适用于单因素设计的三种不同类型:①单个样本的均数与已知总体均数比较的检验,适用于单组设计,给出一组服从正态分布的定量观测数据和一个标准值(总体均值)的资料。
②配对t检验,适用于配对设计。
③成组t检验,适用于完全随机设计的两均数比较。
SPSS中使用菜单Analyze →Compore Means作t检验,Compore Means的下拉菜单如表6-1所示。
表6-1 Compore Means下拉菜单Means…分层计算…One-Sample T Test…单样本t检验…Independent-Samples T Test…独立样本t检验…Paired-Sample T Test…配对t检验…One-Way ANOV A…单因素方差分析…6.1 计量资料的分层计算Means过程可以对计量资料分层计算均数、标准差等统计量,同时可对第一层分组进行方差分析和线性趋势检验。
例6-1某学校测得不同年级、不同性别的12名学生的身高(cm),数据见表6-2。
试用SPSS的Means过程分别计算不同年级、不同性别学生身高的均数和标准差。
表6-2 12名学生的身高(cm)解年级:1=“初一”、2=“高一”,性别:1=“男”、2=“女”。
选择Analyze→Compare Means→Means命令,弹出Means对话框,如图6-2。
在变量列表中选中身高,送入Dependent(因变量)框中;选中年级,送入Independent(自变量),确定第一层依年级分组,单击Next按钮,选中性别,送入Independent,确定第二层依性别分组;单击OK。
输出结果如图6-3所示。
在Means对话框单击Options(选项)按钮,弹出Means:Options对话框,可以选择要计算的统计量,默认Mean、Number of cases、Standard Deviation;在Statisti cs for First Layer中,可对第一层分组作方差分析(Anova table and eta)和线性趋势检验(Test for linearity)。