管理统计学第四章未分组中位数
- 格式:ppt
- 大小:59.00 KB
- 文档页数:1

第四章一.思考题1、一组数据的分布特征可以从哪几个方面进行测度?答:可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
2、怎样理解平均数在统计学中的地位?答:平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础。
从统计学思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
3、简述四分位数的计算方法。
答:四分位数是一组数据排序后处于25%和75%位子上的值。
四分位数是通过3个点将全部数据等分成4分,其中每部分包含25%的数据。
中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值和处在75%位置上的数值。
它是根据为分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数据就是四分位数。
4、对于比率数据的平均数为什么采用几何平均?答:几何平均数是适用于特殊数据的一种平均数,主要适用于计算平均比率。
当所掌握的变量值本身是比率的形式时,采用几何平均法计算平均比率更为合理。
5、简述众数、中位数、平均数的特点和应用场合。
答:众数是数据中出现次数次数最多的变量值。
主要应用于分类数据。
中位数是一组数据排序后处于中间位置的变量值,其适用于顺序数据。
平均数也称均值,它是一组数据相加后除以数据个数的结果,是集中去世的主要测量值,它适用于数值型数据。
6、简述异众比率、四分位差、方差、标准差的使用场合。
答:异众比率主要适合测度分类数据的离散程度,对于顺序数据以及数值型数据也可以计算异众比率。
四分位差主要用于测度顺序数据的离散程度。
方差和标准差适用于测度数值型数据的离散程度。
7、标准分数有哪些用途?答:首先是比较不同单位和不同质数据的位置。
其次是和正态分布结合起来,求得概率和标准分值之间的对应关系。
还有就是在假设检验和估计中应用。

统计学各章计算题公式及解题方法第四章数据的概括性度量1.组距式数值型数据众数的计算:确定众数组后代入公式计算:下限公式:;上限公式:,其中,L为众数所在组下限,U为众数所在组上限,为众数所在组次数与前一组次数之差,为众数所在组次数与后一组次数之差,d为众数所在组组距2.中位数位置的确定:未分组数据为;组距分组数据为3.未分组数据中位数计算公式:4.单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组-对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5.组距式数列的中位数计算公式:下限公式:;上限公式:,其中,为中位数所在组的频数,为中位数所在组前一组的累积频数,为中位数所在组后一组的累积频数6.四分位数位置的确定:未分组数据:;组距分组数据:7.简单均值:8.加权均值:,其中,为各组组中值统计学各章计算题公式及解题方法9.几何均值(用于计算平均发展速度):10.四分位差(用于衡量中位数的代表性):11.异众比率(用于衡量众数的代表性):12.极差:未分组数据:;组距分组数据:13.平均差(离散程度):未分组数据:;组距分组数据:14.总体方差:未分组数据:;分组数据:15.总体标准差:未分组数据:;分组数据:16.样本方差:未分组数据:;分组数据:17.样本标准差:未分组数据:;分组数据:18.标准分数:19.离散系数:第七章参数估计1.的估计值:置信水平α90%0.1 0。
05 1.65495% 0。
05 0.025 1.9699% 0.01 0。
005 2。
58统计学各章计算题公式及解题方法2.不同情况下总体均值的区间估计:总体分布样本量σ已知σ未知大样本(n≥30)正态分布小样本(n<30)非正态分布大样本(n≥30)其中,查p448 ,查找时需查n—1的数值3.大样本总体比例的区间估计:4.总体方差在置信水平下的置信区间为:5.估计总体均值的样本量:,其中,E为估计误差6.重复抽样或无限总体抽样条件下的样本量:,其中π为总体比例第八章假设检验1.总体均值的检验(已知或未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设双侧检验左侧检验右侧检验假设形式已知统计量未知拒绝域值决策,拒绝2.总体均值检验(未知,小样本,总体正态分布)假设双侧检验左侧检验右侧检验统计学各章计算题公式及解题方法假设形式已知统计量未知拒绝域值决策,拒绝注:已知的拒绝域同大样本3.一个总体比例的检验(两类结果,总体服从二项分布,可用正态分布近似)(其中为假设的总体比例)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝4.总体方差的检验(检验)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝5.统计量的参考数值0.1 0。

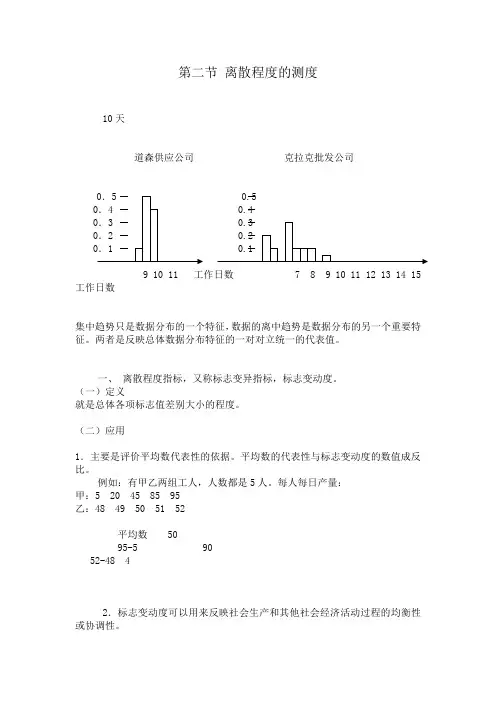
第二节离散程度的测度10天道森供应公司克拉克批发公司5 0.54 0.49 10 11 工作日数 7 8 9 10 11 12 13 14 15 工作日数集中趋势只是数据分布的一个特征,数据的离中趋势是数据分布的另一个重要特征。
两者是反映总体数据分布特征的一对对立统一的代表值。
一、离散程度指标,又称标志变异指标,标志变动度。
(一)定义就是总体各项标志值差别大小的程度。
(二)应用1.主要是评价平均数代表性的依据。
平均数的代表性与标志变动度的数值成反比。
例如:有甲乙两组工人,人数都是5人。
每人每日产量:甲:5 20 45 85 95乙:48 49 50 51 52平均数 5095-59052-48 42.标志变动度可以用来反映社会生产和其他社会经济活动过程的均衡性或协调性。
标志变动度小,就说明生产或经济活动各阶段变动幅度小,是均衡的协调的,反之,就是不均衡,不协调的。
二、测量标志变动度的主要方法(一)异众比率——分类数据,顺序数据,数值型数据1 定义:异众比率,即非众数组的频数占总频数的比率。
2 公式:Vr=(∑fi —fm)/ ∑fi =1—fm/ ∑fi∑fi变量值的总频数,fm众数组的频数。
3作用:主要用于衡量众数对一组数据的代表程度。
异众比率越大,说明非众数组的频数占总频数的比重越大,众数的代表性就越差;反之,异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。
4 适用范围:测定分类数据(也可以是顺序数据,数值型数据)的离散程度饮料品牌频数可口可乐 15旭日升 11百事可乐 9汇源果汁 6露露 9合计 50异众比率解:Vr=(∑fi —fm)/ ∑fi=1—fm/ ∑fi=(50—15)/50=35/50=0.7=70%(二)四分位差——顺序数据数值型数据1 定义:上四分位数和下四分位数之差。
2 公式: Qd=Qu—Ql3 作用:反映了中间50%数据的离散程度。
其数值越小,说明中间的数据越集中,数值越大,说明中间的数据越分散。



标题:深度解析统计学中的中位数和众数计算方法一、引言统计学是一门研究数据收集、整理、分析和解释的学科,而中位数和众数是其中两个重要的统计量。
它们能够有效地描述数据的集中趋势和分布特征,对于深入理解分析数据至关重要。
本文将从中位数和众数的概念入手,逐步介绍它们的计算方法及其在实际中的应用,帮助读者更好地理解和运用这两个统计指标。
二、中位数的计算方法中位数是按顺序排列的一组数据中间那个数,如果数据个数是奇数,则中位数就是中间那个数;如果数据个数是偶数,则中位数是中间两个数的平均数。
以一组数据{3, 5, 7, 9, 11}为例,计算其中位数的步骤如下:1. 将数据按升序排列:3, 5, 7, 9, 112. 计算中位数:由于数据的个数是奇数,因此中位数为排在中间的那个数,即中位数为7。
三、众数的计算方法众数是一组数据中出现次数最多的数值。
如果所有数值都只出现一次,那么该组数据没有众数。
以一组数据{1, 2, 3, 3, 4, 4, 4, 5, 6, 6}为例,计算众数的步骤如下:1. 计算每个数值出现的次数:1(1次), 2(1次), 3(2次), 4(3次), 5(1次),6(2次)2. 找出出现次数最多的数值:4该组数据的众数为4。
四、中位数和众数的应用中位数和众数在实际中有着广泛的应用,尤其在描述数据分布和集中趋势上非常有用。
在金融领域,中位数常被用来描述收入水平和财富分配的均衡度,而众数则常用来描述商品的热销程度和市场需求。
在医学研究中,中位数和众数可以帮助医生更好地了解病人的生理指标和疾病流行情况。
在教育领域,中位数和众数可以用来评估学生的成绩和学习能力。
中位数和众数作为统计学中的重要概念,无处不在地影响着我们的日常生活。
五、个人观点和总结在统计学中,中位数和众数作为数据的重要概括性统计量,能够很好地反映数据的分布和集中趋势。
尤其是在处理偏态分布和异常值较多的数据时,中位数和众数的稳健性使其比平均数更具有优势。

第四章统计综合指标(一)(一)填空题1、总量指标是反映社会经济现象的统计指标,其表现形式为绝对数。
2、总量指标按其反映总体的内容不同,分为总体的标志总量和总体单位总量;按其反映的时间状况不同,分为时期结构和时点结构.反映总体在某一时刻(瞬间)上状况的总量指标称为时点结构,反映总体在一段时期内活动过程的总量指标称为时期结构.3、相对指标的数值有两种表现形式,一是有名数,二是无名数.4、某企业中,女职工人数与男职工人数之比为1:3,即女职工占25%,则1:3属于比例相对数,25%属于结构相对数。
(二)单项选择题(在每小题备选答案中,选出一个正确答案)1、银行系统的年末储蓄存款余额是( D )A。
时期指标并且是实物指标 B。
时点指标并且是实物指标C。
时期指标并且是价值指标 D. 时点指标并且是价值指标2、某企业计划规定本年产值比上年增长4%,实际增长6%,则该企业产值计划完成程度为( B )A、150%B、101。
9%C、66。
7%D、无法计算3、总量指标具有的一个显著特点是( A )A。
指标数值的大小随总体范围的扩大而增加B. 指标数值的大小随总体范围的扩大而减少C. 指标数值的大小随总体范围的减少而增加D。
指标数值的大小随总体范围的大小没有直接联系4、在出生婴儿中,男性占53%,女性占47%,这是( D )A、比例相对指标B、强度相对指标C、比较相对指标D、结构相对指标5、我国1998年国民经济增长(即国内生产总值为)7.8% ,该指标是( C )A. 结构相对指标 B。
比例相对指标 C. 动态相对指标 D。
比较相对指标6、某商店某年第一季度的商品销售额计划为去年同期的110%,实际执行的结果,销售额比去年同期增长24.3%,则该商店的商品销售计划完成程度的算式为( B )A. 124。
3%÷210% B。
124。
3%÷110%C。
210%÷124。
3 D. 条件不够,无法计算7、下面属于时点指标的是( A )A. 商品库存量 B。


统计学各章计算题公式及解题⽅法统计学各章计算题公式及解题⽅法第四章数据的概括性度量1. 组距式数值型数据众数的计算:确定众数组后代⼊公式计算:下限公式:M 0=L +?11+?2×d ;上限公式:M 0=U ??21+?2×d ,其中,L 为众数所在组下限,U 为众数所在组上限,?1为众数所在组次数与前⼀组次数之差,?2为众数所在组次数与后⼀组次数之差,d 为众数所在组组距 2. 中位数位置的确定:未分组数据为n+1 2;组距分组数据为n 23. 未分组数据中位数计算公式:M e ={x (n+12) ,n 为奇数12(x n 2+x n 2+1),n 为偶数4. 单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组—对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5. 组距式数列的中位数计算公式:下限公式:M e =L +n2S m1f m×d ;上限公式:M e =U ?n2+S m+1f m×d ,其中,f m 为中位数所在组的频数,s m?1为中位数所在组前⼀组的累积频数,s m+1为中位数所在组后⼀组的累积频数6. 四分位数位置的确定:未分组数据:{下四分位数:Q L =n+14上四分位数:Q U =3(n+1)4;组距分组数据:{下四分位数:Q L =n4上四分位数:Q U =3n 4 7. 简单均值:x?=x 1+x 2+?+x nn=∑x in i=1n8. 加权均值:x?=M 1f 1+M 2f 2+?+M k f kf 1+f 2+?+f k=∑M i f ik i=1n=∑M i k i=1fin,其中,M 1,M 2…M k 为各组组中值9. ⼏何均值(⽤于计算平均发展速度):x?=√x 1×x 2×…×x n n =√∏x i n i=1n10. 四分位差(⽤于衡量中位数的代表性):Q D =Q U ?Q L 11. 异众⽐率(⽤于衡量众数的代表性):V r =∑f i ?f m ∑f i=1?fm ∑fi12. 极差:未分组数据:R =max (x i )?min (x i );组距分组数据:R =最⾼组上限?最低组下限13. 平均差(离散程度):未分组数据:M d =∑|x i ?x?|n i=1n;组距分组数据:M d =∑|M i ?x?|k i=1?f in14. 总体⽅差:未分组数据:σ2=∑(x i ?µ)2N i=1N;分组数据:σ2=∑(M i ?µ)2k i=1?f iN15. 总体标准差:未分组数据:σ=√∑(x i ?µ)2N i=1N;分组数据:σ=√∑(M i ?µ)2k i=1?f iN16.样本⽅差:未分组数据:s n?12=∑(x?x?)2n i=1n?1;分组数据:s n?12=∑(M i ?x?)2?f ik i=1n?117. 样本标准差:未分组数据:s n?1=√∑(x?x?) 2n i=1n?1;分组数据:s n?1=√∑(M i ?x?)2?f ik i=1n?118. 标准分数:z i =x i ?x?s19. 离散系数:v s =s x?第七章参数估计1. Z α2的估计值:其中,t α2查p448 ,查找时需查n-1的数值3. ⼤样本总体⽐例的区间估计:p ±z α2√p (1?p )n4. 总体⽅差σ2在1?α置信⽔平下的置信区间为:(n?1)s 2χα/22≤σ2≤(n?1)s 2χ1?α/225. 估计总体均值的样本量:n =(Z α/2)2σ2E 2,其中,E 为估计误差6. 重复抽样或⽆限总体抽样条件下的样本量:n =(Z α/2)2π(1?π)E ,其中π为总体⽐例第⼋章假设检验1. 总体均值的检验(σ2已知或σ2未知的⼤样本)[总体服从正态分布,不服从正态分布的⽤正态分布近似]3.⼀个总体⽐例的检验(两类结果,总体服从⼆项分布,可⽤正态分布近似)(其中π0为1.期望频数的分布(假定⾏变量和列变量是独⽴的)⼀个实际频数f ij的期望频数e ij,是总频数的个数n乘以该实际频数f ij落⼊第i⾏和第j列的概率,即:e ij=n·(r in )?(e jn)=r i c jn2. χ2统计量(⽤于检验列联表中变量间拟合优度和独⽴性;⽤于测定两个分类变量之间的相关程度χ2=∑∑(f ij ?e ij )2eijcj=1r i=1,⾃由度为(r ?1)(c ?1),f ij 为列联表中第i ⾏第j列的实际频数,e ij 为列联表中第i ⾏第j 列的期望频数1) 检验多个⽐例是否相等检验的步骤提出假设H 0:?1 = ?2 = … = ?j ;H 1: ? 1 , ?2 , …,?j 不全相等;计算检验的统计量;进⾏决策:根据显着性⽔平?和⾃由度(r -1)(c -1)查出临界值??2,若?2>??2,拒绝H 0;若?22) 利⽤样本数据检验总体⽐例是否等于某个数值检验的步骤提出假设H 0:?1 = ,?2 = ,… ;H 1:原假设的等式中⾄少有⼀个不成⽴;计算检验的统计量;进⾏决:根据显着性⽔平?和⾃由度(r -1)(c -1)查出临界值??2;若?2 >??2,拒绝H 0;若?23) 检验列联表中的⾏变量与列变量之间是否独⽴检验的步骤提出假设H 0:⾏变量与列变量独⽴;H 1:⾏变量与列变量不独⽴;计算检验的统计量;进⾏决策:根据显着性⽔平?和⾃由度(r -1)(c -1)查出临界值??2,若?22,拒绝H 0;若?2系数的值在0~1之间φ=√χ2n ,其中,n 为实际频数总个数,即样本容量4. 列联相关系数(C 系数)⽤于测度⼤于2?2列联表中数据的相关程度C =√χ2χ2+n,其中,C 的取值范围是 0≤C <1;C = 0表明列联表中的两个变量独⽴;C 的数值⼤⼩取决于列联表的⾏数和列数,并随⾏数和列数的增⼤⽽增⼤;根据不同⾏和列的列联表计算的列联系数不便于⽐较 5. V 相关系数V =√χ2n min[(r?1),(c?1)],其中,V 的取值范围是 0≤V ≤1; V = 0表明列联表中的两个变量独⽴;V=1表明列联表中的两个变量完全相关;不同⾏和列的列联表计算的列联系数不便于⽐较;当列联表中有⼀维为2,min[(r-1),(c-1)]=1,此时V=φ第⼗章⽅差分析1. 单因素⽅差分析的要点:1) 建⽴假设的表述⽅法:H 0:µ1=µ2=?=µk ,⾃变量对因变量没有显着影响 H 1:µ1,µ2,…,µk 不全相等,⾃变量对因变量有显着影响2) 决策:i. 根据给定的显着性⽔平α,在F 分布表中查找与第⼀⾃由度df 1=k ?1、第⼆⾃由df 2=n ?k 相应的临界值 F αii. 若F> F α,则拒绝原假设H 0,表明均值之间的差异是显着的,所检验的因素对观察值有显着影响iii.若F< F α,则不拒绝原假设H0,不能认为所检验的因素对观察值有显着影响3)单因素⽅差分析表的结构:2.⽅差分析中的多重⽐较(步骤):采⽤Fisher提出的最⼩显着差异⽅法,简写为LSD1)提出假设:H0:µi=µj(第i个总体的均值等于第j个总体的均值)H0:µi≠µj(第i个总体的均值不等于第j个总体的均值)2)计算检验统计量:x?i?x?j3)计算LSD:LSD=tα2√MSE(1n i+1n j)4)决策:若|x?i?x?j|>LSD,则拒绝H0;若|x?i?x?j|3.双因素⽅差分析:1)⽆交互作⽤的双因素⽅差分析表结构:2)有交互作⽤的双因素⽅差分析表结构:4.关系强度测量:变量间关系的强度⽤⾃变量平⽅和(SSA)及残差平⽅和(SSE)占总平⽅和(SST)的⽐例⼤⼩来反映,根据R 2平⽅根R 进⾏判断R 2=SSA (组间平⽅和)SST (总平⽅和)第⼗⼀章⼀元线性回归1. 样本的相关系数:r =∑()()∑()2∑()2=∑∑∑∑2(∑)2∑2(∑)22. 相关系数的显着性检验步骤:1) 提出假设:H 0:ρ=0;H 1:ρ≠0 2) 计算检验统计量:t =|r |√n?2 1?r 2~t (n ?2)3) 确定α并决策:|t |>t α2,拒绝H 0;|t |,不拒绝H 03. ⼀元回归模型:y =β0+β1x+?4. ⼀元线性回归⽅程形式:E (y )=β0+β1x ,其中β0是直线⽅程在y 轴上的截距,是当x =0时,y 的期望值;β1是直线的斜率,称为回归系数,表⽰当x 每变动⼀个单位时y 的平均变动值5. ⼀元线性回归中,估计的回归⽅程:y ?=β0+β?1x ,其中β?0是估计的回归直线在y 轴上的截距,β?1是直线的斜率,它表⽰对于⼀个给定的x 的值,y ?是y 的估计值,表⽰当x 每变动⼀个单位时y 的平均变动值6. 根据最⼩⼆乘法求β0以及β?1的公式: {β?1=n ∑x i y i ?(∑x i n i=1)(∑y i n i=1)n i=1n ∑x i 2n i=1?(∑x in i=1)2β?0=y ??β1x?7. 误差平⽅和之间的关系:∑(y i ?y ?)2=n i=1∑(y ?i ?y ?)2+∑(y i ?yi )2n i=1n i=1,即:SST(总平⽅和)=SSR(回归平⽅和)+SSE (残差平⽅和) 8. 判定系数(回归平⽅和占离差平⽅和的⽐例):R 2=SSR SST=∑(yi y )2n i=1∑(y i y)2n i=1=1∑(y i ?y ?i )2n i=1∑(yi y )2n i=19. 估计标准误差(实际观察值与回归估计值离差平⽅和的均⽅根):s y =√∑(y i ?yi )2n i=1n2=√SSEn?2=√MSE10. 线性关系的显着性检验:1) 提出假设:H 0:β1=0,线性关系不显着;H 1:β1≠0,有线性关系 2) 计算检验统计量:F =SSR 1?SSE n?2?=MSR MSE ~F (1,n ?2)3) 确定显着性⽔平α,并根据分⼦⾃由度1和分母⾃由度n-2找出临界值F α4) 决策:若F >F α,拒绝H 0;F1) 提出假设:H 0:β1=0,线性关系不显着;H 1:β1≠0,有线性关系 2) 计算检验统计量:t =β1s β1~t (n 2)3) 确定显着性⽔平α并决策:若|t |>t α2?,拒绝H 0;|t |y ?0±t α2?(n ?2)s y √1n +(x 0?x?)2∑(x i ?x?)2ni=1 其中,s y 为估计标准误差,(n ?2)为t α2?的⾃由度13. 预测区间估计:y 0在1?α置信⽔平下的预测区间:y ?0±t α2?(n ?2)s y √1+1n +(x 0?x?)2∑(x i ?x?)2ni=1 14. 回归分析表的结构:15. ⼏点说明:1) 判定系数R 2测度了回归直线对观测数据的拟合程度,若所有观测点都落在直线上,残差平⽅和SSE=0,R 2=1,拟合是完全的2) 在⼀元线性回归中,相关系数r 实际上是判定系数R 2的平⽅根3) 相关系数r 与回归系数β1是同号的第⼗三章时间序列预测和分析1. 环⽐增长率:报告期增长率与前⼀期⽔平之⽐减1:G i =Y iY i?1?1 (i =1,2,Λ,n)2. 定基增长率:报告期⽔平与某⼀固定时期⽔平之⽐减1G i =Yi Y 01 (i =1,2,Λ,n),其中, Y 0表⽰⽤于对⽐的固定基期的观察值3. 平均增长率:序列中各逐期环⽐值(也称环⽐发展速度) 的⼏何平均数减1后的结果(描述现象在整个观察期内平均增长变化的程度)G=√Y 1Y 0×Y 2Y 1×Λ×Yn Y n?1n ?1=√Y n Y 0n ?1,G ?表⽰平均增长率,n 为环⽐值的个数 1) 当时间序列中的观察值出现0或负数时,不宜计算增长率2) 在有些情况下,不宜单纯就增长率论增长率,要注意增长率与绝对⽔平的结合分析4. 时间序列预测的步骤:1) 确定时间序列所包含的成分,也就是确定时间序列的类型 2) 找出适合此类时间序列的预测⽅法3) 对可能的预测⽅法进⾏评估,以确定最佳预测⽅案 4) 利⽤最佳预测⽅案进⾏预测5. 均⽅误差:通过平⽅消去正负号后计算的平均误差,⽤MSE 表⽰MSE =∑(Yi ?F i )2n i=1n,其中Y i 为观测值,F i 为预测值6. 简单平均法:根据过去已有的t 期观察值来预测下⼀期数值。
《统计学原理》第四章综合指标(2)第四章综合指标第⼀节总量指标⼀、总量指标的意义总量指标:反映社会经济现象在⼀定时间、地点、条件下的总规模或总⽔平。
其表现形式是绝对数,是⼀个有名数。
总量指标的作⽤:1、是从数量上认识社会经济现象的起点。
2、是制定政策、编制计划、实⾏社会经济管理的基本依据。
3、是计算相对指标、平均指标以及其他各种分析指标的基础。
⼆、总量指标的种类1、总量指标按其反映的内容不同分为数量标志值的总和总体标志总量:各单位含的单位数总体单位总量:总体包2、总量指标按其反映的时间状况不同分为?时点指标时期指标3、总量指标按其采⽤的计量单位不同分为??劳动量指标价值指标实物指标三、总量指标的计算第⼆节相对指标⼀、相对指标的概念和作⽤相对指标(统计相对数):是两个有联系的指标数值对⽐的结果。
相对指标的特点:把两个对⽐的具体数值抽象化,以集中反映事物之间的数量关系。
⼆、相对指标的表现形式相对指标的表现形式千分数百分数成数倍数、系数⽆名数有名数三、常⽤的相对指标1、计划完成相对指标%100?=计划任务数实际完成数例、某企业产量计划规定本⽉的产量要达到200万吨,实际达到220万吨,问该企业的产量计划完成情况如何?解:计划完成百分⽐%100?=计划任务数实际完成数%110%100200220=?=例、某企业成本计划规定甲产品的单位成本要降到50元/件,实际降到48元/件,问该企业的成本计划完成情况如何?解:计划完成百分⽐%100?=计划任务数实际完成数%96%1005048=?=例、某企业产值计划规定本年的产值要⽐上年增长10%,实际增长15%,问该企业的产值计划完成情况如何?计划完成百分⽐%100?=计划任务数实际完成数%5.104%100%101%151=?++=注意:计划完成相对指标的评价:收⼊收益性质的指标(⼀般规定应达到的最低限额),计划完成百分⽐⼤于100%为超额完成计划,⼩于100%为没有完成计划;成本费⽤性质的指标(⼀般规定应达到的最⾼限额),计划完成百分⽐⼩于100%为超额完成计划,⼤于100%为没有完成计划。
公式一1. 众数【MODE 】(1) 未分组数据或单变量值分组数据众数的计算未分组数据或单变量值分组数据的众数就是出现次数最多的变量值。
(2) 组距分组数据众数的计算对于组距分组数据,先找出出现次数最多的变量值所在组,即为众数所在组,再根据下面的公式计算计算众数的近似值。
下限公式: 1012M =L++i ∆⨯∆∆ 式中:0M 表示众数;L 表示众数的下线;1∆表示众数组次数与上一组次数之差;2∆表示众数组次数与下一组次数之差;i 表示众数组的组距。
上限公式:2012M =U-+i ∆⨯∆∆ 式中:U 表示众数组的上限。
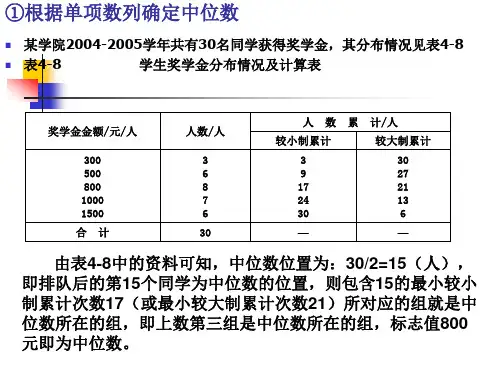
2.中位数【MEDIAN 】(1)未分组数据中中位数的计算根据未分组数据计算中位数时,要先对数据进行排序,然后确定中位数的位置。
设一组数据按从小到大排序后为12N X X X ,,…,,中位数e M ,为则有:e N+M =X1()2当N 为奇数e N N +1221M =X +X 2⎛⎫⎛⎫ ⎪ ⎪⎝⎭⎝⎭⎧⎫⎪⎪⎨⎬⎪⎪⎩⎭当N 为偶数(2)分组数据中位数的计算分组数据中位数的计算时,要先根据公式N / 2 确定中位数的位置,并确定中位数所在的组,然后采用下面的公式计算中位数的近似值:N=1m-1e m-S 2M =L+ii fd f ⨯∑式中:e M 表示中位数;L 表示中位数所在组的下限;m-1S 表示中位数所在组以下各组的累计次数;m f 表示中位数所在组的次数;d 表示中位数所在组的组距。
3.均值的计算【A VERAGE 】(1)未经分组均值的计算未经分组数据均值的计算公式为: 112n ++==nii x x x x x n n=∑…(2)分组数据均值计算分组数据均值的计算公式为: 11221121+++==+ki ik k i k kii x f xf x f x f xf f f f==+∑∑+4.几何平均数【GEOMEAN 】几何平均数是N 个变量值乘积的N 次方根,计算公式为:式中:G 表示几何平均数;∏表示连乘符号。