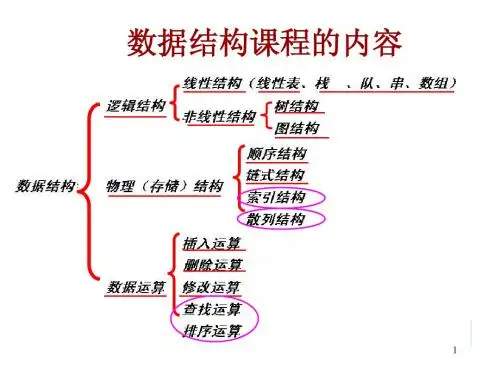
顺序查找
- 格式:doc
- 大小:29.50 KB
- 文档页数:5

一判断题1.顺序查找法适用于存储结构为顺序或链接存储的线行表。
2.一个广义表可以为其他广义表所共享。
3.快速排序是选择排序的算法。
4.完全二叉树的某结点若无左子树,则它必是叶子结点。
5.最小代价生成树是唯一的。
6.哈希表的结点中只包含数据元素自身的信息,不包含任何指针。
7.存放在磁盘,磁带上的文件,即可意识顺序文件,也可以是索引文件。
8.折半查找法的查找速度一定比顺序查找法快。
二选择题1.将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是()。
A. nB. 2n-1C. 2nD. n-12.在文件"局部有序"或文件长度较小的情况下,最佳内部排序的方法是()。
A. 直接插入排序B.气泡排序C. 简单选择排序D. 快速排序3.高度为K的二叉树最的结点数为()。
A. 24.一个栈的输入序列是12345,则占的不可能的输出序列是()A.54321B. 45321C.43512D.123455.ISAM文件和V ASM文件属于()A索引非顺序文件 B. 索引顺序文件 C. 顺序文件 D. 散列文件6. 任何一棵二叉树的叶子结点在先序,中序和后序遍历序列中的相对次序()A. 不发生变化B. 发生变化C. 不能确定D. 以上都不对7.已知某二叉树的后序遍历序列是dabec, 中序遍历序列是debac , 它的前序遍历是()。
A. acbedB. decabC. deabcD.cedba三.填空题1.将下图二叉树按中序线索化,结点的右指针指向(),Y的左指针指向()B DC X EY2.一棵树T中,包括一个度为1的结点,两个度为2的结点,三个度为3的结点,四各度为4的结点和若干叶子结点,则T的叶结点数为()3.抽象数据类型的定义仅取决与它的一组(),而与()无关,即不论其内部结构如何变化,只要它的()不变,都不影响其外部使用。
4.VSAM(虚拟存储存取方法)文件的优点是:动态地(),不需要文件进行(),并能较快的()进行查找。

顺序表的查找c语言代码
顺序表是一种线性表,它的元素在物理上是连续存储的。
在顺序表中,每个元素都有一个唯一的下标,也称为索引,可以通过索引来访问顺序表中的元素。
顺序表的查找是指在顺序表中查找某个元素是否存在,并返回其位置或者不存在的信息。
顺序表的查找可以分为两种:顺序查找和二分查找。
顺序查找是从顺序表的第一个元素开始,逐个比较,直到找到目标元素或者遍历完整个顺序表。
二分查找是在有序的顺序表中进行的,每次将查找区间缩小一半,直到找到目标元素或者查找区间为空。
下面是顺序查找的C语言代码:
```c
int sequential_search(int *a, int n, int key)
{
int i;
for (i = 0; i < n; i++)
{
if (a[i] == key)
{
return i;
}
}
return -1;
}
```
这个函数接受三个参数:一个整型数组a,数组的长度n,和要查找的元素key。
函数返回key在数组a中的位置,如果不存在则返回-1。
顺序查找的时间复杂度是O(n),其中n是顺序表的长度。
在最坏情况下,需要遍历整个顺序表才能找到目标元素,因此顺序查找的效率不高。
如果顺序表是有序的,可以使用二分查找来提高查找效率。
顺序表的查找是数据结构中的基本操作之一,也是算法设计中的重要内容。
在实际应用中,我们需要根据具体的情况选择合适的查找算法,以提高程序的效率。

实验五查找的应用一、实验目的:1、掌握各种查找方法及适用场合,并能在解决实际问题时灵活应用。
2、增强上机编程调试能力。
二、问题描述1.分别利用顺序查找和折半查找方法完成查找。
有序表(3,4,5,7,24,30,42,54,63,72,87,95)输入示例:请输入查找元素:52输出示例:顺序查找:第一次比较元素95第二次比较元素87 ……..查找成功,i=**/查找失败折半查找:第一次比较元素30第二次比较元素63 …..2.利用序列(12,7,17,11,16,2,13,9,21,4)建立二叉排序树,并完成指定元素的查询。
输入输出示例同题1的要求。
三、数据结构设计(选用的数据逻辑结构和存储结构实现形式说明)(1)逻辑结构设计顺序查找和折半查找采用线性表的结构,二叉排序树的查找则是建立一棵二叉树,采用的非线性逻辑结构。
(2)存储结构设计采用顺序存储的结构,开辟一块空间用于存放元素。
(3)存储结构形式说明分别建立查找关键字,顺序表数据和二叉树数据的结构体进行存储数据四、算法设计(1)算法列表(说明各个函数的名称,作用,完成什么操作)序号 名称 函数表示符 操作说明1 顺序查找 Search_Seq 在顺序表中顺序查找关键字的数据元素2 折半查找 Search_Bin 在顺序表中折半查找关键字的数据元素3 初始化 Init 对顺序表进行初始化,并输入元素4 树初始化 CreateBST 创建一棵二叉排序树5 插入 InsertBST 将输入元素插入到二叉排序树中6 查找 SearchBST在根指针所指二叉排序树中递归查找关键字数据元素 (2)各函数间调用关系(画出函数之间调用关系)typedef struct { ElemType *R; int length;}SSTable;typedef struct BSTNode{Elem data; //结点数据域 BSTNode *lchild,*rchild; //左右孩子指针}BSTNode,*BSTree; typedef struct Elem{ int key; }Elem;typedef struct {int key;//关键字域}ElemType;(3)算法描述int Search_Seq(SSTable ST, int key){//在顺序表ST中顺序查找其关键字等于key的数据元素。

01:查找特定的值••提交•统计•提问总时间限制:1000ms存限制:65536kB描述在一个序列(下标从1开始)中查找一个给定的值,输出第一次出现的位置。
输入第一行包含一个正整数n,表示序列中元素个数。
1 <= n <= 10000。
第二行包含n个整数,依次给出序列的每个元素,相邻两个整数之间用单个空格隔开。
元素的绝对值不超过10000。
第三行包含一个整数x,为需要查找的特定值。
x的绝对值不超过10000。
输出若序列中存在x,输出x第一次出现的下标;否则输出-1。
02:输出最高分数的学生•描述输入学生的人数,然后再输入每位学生的分数和,求获得最高分数的学生的。
输入第一行输入一个正整数N(N <= 100),表示学生人数。
接着输入N行,每行格式如下:分数分数是一个非负整数,且小于等于100;为一个连续的字符串,中间没有空格,长度不超过20。
数据保证最高分只有一位同学。
输出获得最高分数同学的。
来源习题(13-1)03:不高兴的津津描述津津上初中了。
妈妈认为津津应该更加用功学习,所以津津除了上学之外,还要参加妈妈为她报名的各科复习班。
另外每周妈妈还会送她去学习朗诵、舞蹈和钢琴。
但是津津如果一天上课超过八个小时就会不高兴,而且上得越久就会越不高兴。
假设津津不会因为其它事不高兴,并且她的不高兴不会持续到第二天。
请你帮忙检查一下津津下周的日程安排,看看下周她会不会不高兴;如果会的话,哪天最不高兴。
输入包括七行数据,分别表示周一到周日的日程安排。
每行包括两个小于10的非负整数,用空格隔开,分别表示津津在学校上课的时间和妈妈安排她上课的时间。
输出包括一行,这一行只包含一个数字。
如果不会不高兴则输出0,如果会则输出最不高兴的是周几(用1, 2, 3, 4, 5, 6, 7分别表示周一,周二,周三,周四,周五,周六,周日)。
如果有两天或两天以上不高兴的程度相当,则输出时间最靠前的一天。
04:谁拿了最多奖学金•提交•统计•提问总时间限制:1000ms存限制:65536kB描述某校的惯例是在每学期的期末考试之后发放奖学金。

对n个元素的表做顺序查找时,若查找每
个元素
顺序表查找又称线性查找,是指从表中第一个元素开始,逐步和给定的关键字进行比较,如果顺序表中某个元素和给定的关键字相等,则表示查找成功,否则就表示查找失败顺序表中的元素越多,它的效率就越低。
因此,它只适合表中元素比较少的顺序表,如果表中的元素非常多,我们必须另想办法最糟糕的情况应该是比较到线性表最后一个值,也没有查找到所需要的值,那么从线性表的第0个值开始比较,每次取出一个值比较,不符合,再取下一个值,依次比较,一直到最后一个,那么长度为N,就需要比较N次。
从一个具有n个节点的单
链表中查找其值等于x的节点,在查找成功的情况下,平均需要比较(n+1)/2个节点。
由于单链表只能进行单向顺序查找,以从第一个节点开始查找为例,查找第m个节点需要比较的节点数f(m)=m,查找
成功的最好情况是第一次就查找成功,只用比较1个节点,最坏情况则是最后才查找成功,需要比较n个节点。
所以一共有n种情况,平均下来需要比较的节点为
(1+2+3+...+(n-1)+n)/n=(n+1)/
2。



算法设计与分析各种查找算法的性能测试目录摘要 (2)第一章:简介(Introduction) (3)1.1 算法背景 (3)第二章:算法定义(Algorithm Specification) (4)2.1 数据结构 (4)2.2顺序查找法的伪代码 (4)2.3 二分查找(递归)法的伪代码 (5)2.4 二分查找(非递归)法的伪代码 (6)第三章:测试结果(Testing Results) (8)3.1 测试案例表 (8)3.2 散点图 (9)第四章:分析和讨论 (11)4.1 顺序查找 (11)4.1.1 基本原理 (11)4.2.2 时间复杂度分析 (11)4.2.3优缺点 (11)4.2.4该进的方法 (12)4.2 二分查找(递归与非递归) (12)4.2.1 基本原理 (12)4.2.2 时间复杂度分析 (13)4.2.3优缺点 (13)4.2.4 改进的方法 (13)附录:源代码(基于C语言的) (15)摘要在计算机许多应用领域中,查找操作都是十分重要的研究技术。
查找效率的好坏直接影响应用软件的性能,而查找算法又分静态查找和动态查找。
我们设置待查找表的元素为整数,用不同的测试数据做测试比较,长度取固定的三种,对象由随机数生成,无需人工干预来选择或者输入数据。
比较的指标为关键字的查找次数。
经过比较可以看到,当规模不断增加时,各种算法之间的差别是很大的。
这三种查找方法中,顺序查找是一次从序列开始从头到尾逐个检查,是最简单的查找方法,但比较次数最多,虽说二分查找的效率比顺序查找高,但二分查找只适用于有序表,且限于顺序存储结构。
关键字:顺序查找、二分查找(递归与非递归)第一章:简介(Introduction)1.1 算法背景查找问题就是在给定的集合(或者是多重集,它允许多个元素具有相同的值)中找寻一个给定的值,我们称之为查找键。
对于查找问题来说,没有一种算法在任何情况下是都是最优的。
有些算法速度比其他算法快,但是需要较多的存储空间;有些算法速度非常快,但仅适用于有序数组。

数据结构重点知识一、数组数组可是数据结构里的老熟人啦。
它就像是住在公寓里的居民,每个元素都住在固定的小房间里,有自己的编号。
数组的优点呢,就是访问速度特别快,就像你知道朋友住几零几房间,一下子就能找到他。
但是它的缺点也很明显哦,要是想在中间插入或者删除一个元素,那就像在公寓里突然要加一个房间或者拆一个房间一样麻烦,得把后面的元素都挪一挪。
二、链表链表就比较灵活啦。
它像是一群手拉手的小伙伴,每个元素都只知道自己下一个小伙伴是谁。
链表分为单向链表和双向链表。
单向链表只能顺着一个方向找下一个元素,双向链表就厉害啦,它既能找到下一个元素,还能找到前一个元素呢。
链表在插入和删除元素的时候就比较方便,就像小伙伴们手拉手,想加入或者离开这个小队伍都比较容易,不用像数组那样大动干戈。
三、栈栈这个东西很有趣哦。
它就像一个只能从一头进出的小盒子,先进去的元素要最后才能出来,这就是所谓的“后进先出”。
就好比你往一个细口瓶子里放东西,先放进去的东西被压在下面,最后才能拿出来。
栈在函数调用、表达式求值等方面可是大有用处的呢。
四、队列队列和栈有点相反,它是“先进先出”的。
就像排队买东西一样,先来的人先被服务。
在计算机里,比如打印机的任务队列,先提交的打印任务就会先被打印出来。
队列可以用数组或者链表来实现。
五、树树这个结构可复杂也可有趣啦。
它有根节点、叶子节点等。
二叉树是树结构里比较常见的一种,每个节点最多有两个子节点。
就像家族的族谱一样,有一个祖宗节点,下面有子孙节点。
树结构在文件系统、查找算法等方面都有很多应用。
比如二叉查找树,它可以让查找元素的效率提高很多。
六、图图是由顶点和边组成的。
它可以用来表示很多实际的关系,比如城市之间的交通路线。
图有有向图和无向图之分。
有向图的边是有方向的,就像单行道一样,只能按照规定的方向走;无向图的边就没有方向,就像普通的马路,两个方向都能走。
图的遍历算法也是数据结构里的重点内容,像深度优先遍历和广度优先遍历。

顺序表的查找-顺序查找查找(search):给定结点的关键字值 x ,查找值等于 x 的结点的存储地址。
按关键字 x 查:①成功,表中有 x ,返回 x 的存储地址;②不成功,x 不在表中,返回⽆效地址。
顺序查找就是以表的⼀端为起点,向另⼀个端点逐个元素查看,可以是从表头→表尾的顺序,也可以是从表尾→表头的顺序顺序查找⽅法,既适⽤于⽆序表,⼜适⽤于有序表。
顺序查找属于 “穷尽式搜索法”:通常以查找长度,度量查找算法的时间复杂性。
查找长度:即查找过程中测试的节点数⽬。
顺序查找的查找长度 = for 循环体的执⾏次数,最⼩为1,最多为n。
等概率下:平均查找长度 = (n + 1)/ 2最坏情况和平均情况:T(n)= O(n)效率最低的查找算法我们观察⼀下上图那两个 for循环体,不难发现,每次执⾏都需要判断两个条件:①测试是否循环到头;②测试是否找到元素 x。
因此我们不妨使⽤ “监督元” 技术,不仅简化了程序结构,也提⾼了查找速度。
若从表尾→表头的顺序查找,监督元则在表头处,称为 “表头监督元”,如下图:若从表头→表尾的顺序查找,监督元则在表头处,称为 “表尾监督元”,如下图:带表头监督元的顺序查找算法:int SQsearch(int a[],int x,int n){ // SQsearch 是函数名,仅此。
int i; i = n; a[0] = x; while(a[i] != x) i -- ; return i;}算法思想:① i = n;// 设置查找起点② a[0] = x;// 放置监督元,因为在进⼊循环体之前,已经预先在 a[0] 放置了⼀个元素 x,所以 x ⽆论是否真的在表中,总能找到 x ,使第三句的循环中⽌。
注意a[1] 到 a[n] 存储的才是真正的表元素。
如果 x 真存在表中,必然在某个 i ⼤于 0 时找到 x,循环终⽌。
如果循环变量 i 的值变到 0 时循环才终⽌,那就说明 x 不在表中。
中国的城市(按字母顺序查找):A : 鞍山(辽宁)安阳(河南)安顺(贵州)安庆(安徽)B: 北京蚌埠(安徽)包头(内蒙古)保定(河北)宝鸡(陕西)白银(甘肃)白云鄂博(内蒙古) 巴彦淖尔(内蒙古)北戴河(河北)博鳌(海南)承德(河北)本溪(辽宁)阜新(辽宁)白山(吉林)白城(吉林)亳州(安徽)滨州(山东)北海(广西)百色(广西)巴中(四川)宝山(云南)C:重庆成都(四川)长沙(湖南)长春(吉林)承德(河北)常州(江苏)池州(安徽)沧州(河北)赤峰(内蒙古)滁州(安徽)巢湖(安徽)常德(湖南)郴州(湖南)潮州(广东)崇左(广西)德阳(四川)D:大连(辽宁)大庆(黑龙江) 大同(山西)丹东(辽宁)大冶(湖北)东营(山东)登封(山东)大理(云南)德州(山东)东莞(广东)达州(四川)定西(甘肃)大石桥(辽宁、镁矿)E:鄂尔多斯(内蒙古)鄂州(湖北)F: 佛山(广东)福州(福建)抚顺(辽宁)阜阳(安徽)抚州(江西)防城港(广西)G: 广州(广东)贵阳(贵州) 桂林(广西)赣州(江西)贵港(广西)广元(四川)广安(四川)杭州(浙江)固原(宁夏)哈尔滨(黑龙江)H: 呼和浩特(内蒙古)合肥(安徽)海口(海南)邯郸(河北)湖州(浙江)黄山(安徽) 黄石(湖北)黄冈(湖北)衡阳(湖南)汉中(陕西)菏泽(山东)衡水(河北)呼伦贝尔(内蒙古)葫芦岛(辽宁)淮南(安徽)淮北(安徽)鹤壁(河南)淮安(江苏)怀化(湖南)惠州(广东)河源(广东)贺州(广西)河池(广西)鹤岗(黑龙江) 黑河(黑龙江)I:J:济南(山东)吉林(吉林)九江(江西)景德镇(江西)金昌(甘肃)揭阳(广东)吉安(江西)锦州(辽宁)鸡西(黑龙江) 佳木斯(黑龙江) 金华(浙江)济宁(山东)焦作(河南)荆州(湖北)荆门(湖北)娄底(湖南)江门(广东)酒泉(甘肃)嘉峪关(甘肃)K: 昆明(云南)开封(河南)克拉玛依(新疆)嘉兴(浙江)L: 兰州(甘肃)拉萨(西藏)洛阳(河南)柳州(广西)乐山(四川)临沧(云南)陇南(甘肃)丽江(云南)乐山(四川)连云港(江苏)廊坊(河北)辽阳(辽宁)辽源(吉林)泸州(四川)漯河(河南)来宾(广西)M: 绵阳(四川)牡丹江(黑龙江) 丽水(浙江)马鞍山(安徽)六安(安徽)龙岩(福建)莱芜(山东)临沂(山东)聊城(山东)茂名(广东)梅州(广东)眉山(四川)N: 南京(江苏)宁波(浙江)南通(江苏)南昌(江西)南平(福建)南阳(河南)宁德(福建)南宁(广西)内江(四川)南充(四川)O:P:莆田(福建)萍乡(江西)盘锦(辽宁)攀枝花(四川)平顶山(河南)平遥(山西)平凉(甘肃)濮阳(河南)许昌(河南)普洱(云南)Q:青岛(山东)泉州(福建)齐齐哈尔(黑龙江) 秦皇岛(河北)曲阜(山东)七台河(黑龙江) 秦州(江苏)衢州(浙江)曲靖(云南)庆阳(甘肃)R:日照(山东)清远(广东)钦州(广西)S:上海(沪)深圳(广东)天津苏州(江苏)沈阳(辽宁)石家庄(河北) 汕头(广东)三亚(海南)绍兴(浙江)十堰(湖北)上饶(江西)四平(吉林)松原(吉林)来宾(广西)宿迁(江苏)宿州(安徽)三明(福建)三门峡(河南)商丘(河南)随州(湖北)邵阳(湖南)韶关(广东)汕尾(广东)遂宁(四川)石嘴山(甘肃)双鸭山(黑龙江) 绥化(黑龙江)T: 天津唐山(河北)太原(山西)泰安(山东)泰州(江苏)铁岭(辽宁)通辽(内蒙古)通化(吉林)台州(浙江)铜陵(安徽)天水(甘肃)U:V:W:武汉(湖北无锡(江苏)乌鲁木齐(新疆)潍坊(山东)芜湖(安徽)武夷山(福建)渭南(陕西)乌海(内蒙古)乌兰察布(内蒙古)温州(浙江)威海(山东)梧州(广西)武威(甘肃)吴忠(甘肃)X: 西安(陕西)厦门(福建)西宁(青海)襄樊(湖北)咸阳(陕西)湘潭(湖南)忻州(山西)徐州(江苏)信阳(河南)邢台(河北)宣城(安徽)新余(江西)新乡(河南)孝感(湖北)咸宁(湖北)Y:烟台(山东)银川(宁夏)扬州(江苏)宜昌(湖北)岳阳(湖南)延安(陕西)营口(辽宁)延吉(吉林)伊春(黑龙江) 盐城(江苏)鹰潭(江西)宜春(江西)益阳(湖南)永州(湖南)阳江(广东)云浮(广东)玉林(广西)宜宾(四川)雅安(四川)玉溪(云南)Z: 郑州(河南)珠海(广东)漳州(福建)株洲(湖南)肇庆(广东)自贡(四川)舟山(浙江)张家界(湖南)遵义(贵州)湛江(广东)张家口(河北)张家界(湖南)朝阳(辽宁)镇江(江苏)淄博(山东)枣庄(山东)中山(广东)资阳(四川)周口(河南)驻马店(河南)昭通(云南)张掖(甘肃)中卫(甘肃)。
Java中常用的查找算法——顺序查找和二分查找一、顺序查找:a)原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数据最后一位。
b)图例说明:原始数据:int[] a={4,6,2,8,1,9,0,3};要查找数字:8代码演示:import java.util.Scanner;/** 顺序查找*/public class SequelSearch {public static void main(String[] arg) {int[] a={4,6,2,8,1,9,0,3};Scanner input=new Scanner(System.in);System.out.println("请输入你要查找的数:");//存放控制台输入的语句int num=input.nextInt();//调用searc()方法,将返回值保存在result中int result=search(a, num);if(result==-1){System.out.println("你输入的数不存在与数组中。
");}elseSystem.out.println("你输入的数字存在,在数组中的位置是第:"+(result+1)+"个");}public static int search(int[] a, int num) {for(int i = 0; i < a.length; i++) {if(a[i] == num){//如果数据存在return i;//返回数据所在的下标,也就是位置}}return -1;//不存在的话返回-1}}运行截图:二、二分查找a)前提条件:已排序的数组中查找b)二分查找的基本思想是:首先确定该查找区间的中间点位置:int mid = (low+upper)/ 2;然后将待查找的值与中间点位置的值比较:若相等,则查找成功并返回此位置。
01:查找特定的值••提交•统计•提问总时间限制:1000ms内存限制:65536kB描述在一个序列(下标从1开始)中查找一个给定的值,输出第一次出现的位置。
输入第一行包含一个正整数n,表示序列中元素个数。
1 <= n <= 10000。
第二行包含n个整数,依次给出序列的每个元素,相邻两个整数之间用单个空格隔开。
元素的绝对值不超过10000。
第三行包含一个整数x,为需要查找的特定值。
x的绝对值不超过10000。
输出若序列中存在x,输出x第一次出现的下标;否则输出-1。
02:输出最高分数的学生姓名•描述输入学生的人数,然后再输入每位学生的分数和姓名,求获得最高分数的学生的姓名。
输入第一行输入一个正整数N(N <= 100),表示学生人数。
接着输入N行,每行格式如下:分数姓名分数是一个非负整数,且小于等于100;姓名为一个连续的字符串,中间没有空格,长度不超过20。
数据保证最高分只有一位同学。
输出获得最高分数同学的姓名。
来源习题(13-1)03:不高兴的津津•描述津津上初中了。
妈妈认为津津应该更加用功学习,所以津津除了上学之外,还要参加妈妈为她报名的各科复习班。
另外每周妈妈还会送她去学习朗诵、舞蹈和钢琴。
但是津津如果一天上课超过八个小时就会不高兴,而且上得越久就会越不高兴。
假设津津不会因为其它事不高兴,并且她的不高兴不会持续到第二天。
请你帮忙检查一下津津下周的日程安排,看看下周她会不会不高兴;如果会的话,哪天最不高兴。
输入包括七行数据,分别表示周一到周日的日程安排。
每行包括两个小于10的非负整数,用空格隔开,分别表示津津在学校上课的时间和妈妈安排她上课的时间。
输出包括一行,这一行只包含一个数字。
如果不会不高兴则输出0,如果会则输出最不高兴的是周几(用1, 2, 3, 4, 5, 6, 7分别表示周一,周二,周三,周四,周五,周六,周日)。
如果有两天或两天以上不高兴的程度相当,则输出时间最靠前的一天。