一个简单的语法制导翻译器
- 格式:pptx
- 大小:314.42 KB
- 文档页数:48

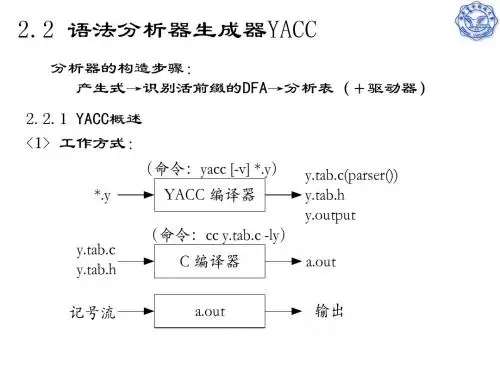
中国科学技术大学陈意云编译原理全套参考资料chapter4 第四章语法制导的翻译在3.7节用Yacc写的例子中,我们看到一种有用的描述形式:语言结构的属性附加在代表语言结构的文法符号上,这些属性值由附加在文法产生式的语义动作来计算,这些语义动作在归约对应的产生式时进行计算,由此得到结果。
这种描述形式可用来描述编译器的语义分析,因此本章系统地研究这种称之为“语法制导下的语言翻译”的描述方法及其实现。
它的语义动作(有时称为语义规则)的计算可以产生代码、把信息存入符号表、显示出错信息、或完成其它工作。
语义规则的计算结果就是我们所要的记号流的翻译。
本章讨论语义规则和产生式相联系的两种方式:语法制导的定义和翻译方案。
语法制导定义是较抽象的翻译说明,它隐蔽了一些实现细节;而翻译方案陈述了一些实现细节,主要是指明了语义规则的计算次序。
在第五章说明语义检查和第七章描述中间代码生成时,大量使用这两种方法。
本章还讨论语法制导定义和翻译方案的实现方法。
概念上的方法是,首先分析输入的记号串,建立分析树,然后从分析树得到描述结点属性间依赖关系的有向图,从这个依赖图得到语义规则的计算次序,然后进行计算,最终得到翻译的结果。
实际的实现并不需要按上面步骤逐步进行,本章将讨论几种不同限制下的实现方法。
4.1 语法制导的定义语法制导的定义是上下文无关文法的推广,其中每个文法符号都有一个属性集合,它分成两个子集,分别叫做该文法符号的综合属性集合和继承属性集合。
如果我们把分析树上的结点看成是保存对应文法符号的属性的记录,那么属性对应记录的域。
属性可以表示任何东西:串、数、类型、内存单元,或其它想表示的东西。
分析树结点的属性值由该结点所用产生式的语义规则定义。
在语法制导定义中,我们把其中的文法称为基础文法。
本节介绍语法制导定义的形式及其概念上的实现模型。
4.1.1 语法制导定义的形式在语法制导定义中,每个文法符号有一组属性,每个文法产生式A , ,有一组形式为b := f (c, c, …, c )的语义规则,其中f 是函数,b和c, c, …, c 是该产生式的文法符号的12k12k属性,并且:(1) 如果b是A的属性,c , c , …, c 是产生式右部文法符号的属性或A的其它属12k性,那么b叫做文法符号A的综合属性。


Translator++是一个翻译工具,其规则可能包括以下几个方面:
1. 语法规则:Translator++的语法规则是指其解析和处理输入文本的方式。
它应该能够识别和解析各种语言的语法结构,以便正确地翻译文本。
2. 词汇规则:Translator++的词汇规则是指其翻译过程中使用的词汇和短语。
它应该具有一个广泛的词汇库,以便能够翻译各种语言中的词汇和短语。
3. 语义规则:Translator++的语义规则是指其理解文本含义的方式。
它应该能够理解文本中的语境、语气和意图,以便正确地翻译文本。
4. 文化规则:Translator++的文化规则是指其处理文化差异的方式。
它应该能够理解不同文化中的文化符号、习俗和价值观,以便正确地翻译文本。
5. 输出规则:Translator++的输出规则是指其生成翻译结果的方式。
它应该能够生成准确、流畅和自然的翻译结果,以便用户能够轻松地理解和使用。
需要注意的是,这些规则可能因不同的Translator++版本和不同的语言对而有所不同。
因此,在使用Translator++时,建议仔细阅读其文档和用户手册,以了解其具体的规则和使用方法。

语法翻译法的实施步骤1. 简介语法翻译法是一种用于将一种程序设计语言转换为另一种程序设计语言的技术。
它通过将源语言的语法规则映射到目标语言的语法规则,实现源语言程序到目标语言程序的转换。
本文将介绍实施语法翻译法的具体步骤。
2. 步骤以下是实施语法翻译法的一般步骤:步骤1: 确定源语言和目标语言在开始进行语法翻译的过程中,首先需要确定源语言和目标语言。
源语言是我们要转换的程序设计语言,目标语言是将源语言转换成的语言。
确切地了解源语言和目标语言的语法规则和语义规则非常重要。
步骤2: 词法分析词法分析是将源程序分解为一个个的单词(Token)的过程。
在这一步骤中,我们需要编写一个词法分析器,它将源代码作为输入,并识别出其中的单词。
每个单词都包含一个词法类型和一个对应的字符串值。
示例:源代码: x = 5 * 2;词法分析输出:- 词法类型: 标识符,字符串值: x- 词法类型: 赋值运算符,字符串值: =- 词法类型: 数字,字符串值: 5- 词法类型: 运算符,字符串值: *- 词法类型: 数字,字符串值: 2- 词法类型: 分号,字符串值: ;步骤3: 语法分析语法分析是将词法分析器输出的单词流转换为语法树的过程。
在这一步骤中,我们需要编写一个语法分析器,它将识别源代码中的语法规则并生成一个语法树。
语法树用于表示程序的结构和层次关系。
示例:源代码: x = 5 * 2;语法树:=/ \\x */ \\5 2步骤4: 语法制导翻译语法制导翻译是基于语法树进行语法规则的翻译过程。
在这一步骤中,我们需要根据源语言和目标语言的语法规则,编写语法制导翻译器,它将遍历语法树并根据语法规则翻译每个节点。
示例:源代码: x = 5 * 2;目标语言: Python翻译结果: x = 5 * 2步骤5: 语义分析和翻译语义分析是对源代码进行静态语义检查的过程。
在这一步骤中,我们需要编写语义分析器,它将检查源代码是否符合源语言和目标语言的语义规则。




03091337 李璐 03091339 宗婷婷一、上机题目:实现一个简单语言(CPL)的编译器(解释器)二、功能要求:接收以CPL编写的程序,对其进行词法分析、语法分析、语法制导翻译等,然后能够正确的执行程序。
三、试验目的1.加深编译原理基础知识的理解:词法分析、语法分析、语法制导翻译等2.加深相关基础知识的理解:数据结构、操作系统等3.提高编程能力4.锻炼独立思考和解决问题的能力四、题目说明1.数据类型:整型变量(常量),布尔变量(常量)取值范围{…, -2, -1, 0, 1, 2, …}, {true, false}2、运算表达式:简单的代数运算,布尔运算3、程序语句:赋值表达式,顺序语句,if-else语句,while语句五、环境配置1.安装Parser Generator、Visual C++;2.分别配置Parser Generator、Visual C++;3.使用Parser Generator创建一个工程编写l文件mylexer.l;编译mylexer.l,生成mylexer.h与mylexer.c;4.使用VC++创建Win32 Console Application工程并配置该项目;加入mylexer.h与mylexer.c,编译工程;执行标识符数字识别器;注意:每次修改l文件后,需要重新编译l文件,再重新编译VC工程六、设计思路及过程设计流程:词法分析LEX的此法分析部分主要利用有限状态机进行单词的识别,在分析该部分之前,首先应该对YACC的预定义文法进行解释。
在YACC中用%union扩充了yystype的内容,使其可以处理char型,int型,node型,其中Node即为定义的树形结点,其定义如下:typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;/* 操作符 */typedef struct {int name; /* 操作符名称 */int num; /* 操作元个数 */struct NodeTag * node[1]; /* 操作元地址可扩展 */} OpNode;typedef struct NodeTag {NodeEnum type; /* 树结点类型 *//* Union 必须是最后一个成员 */union {int content; /* 内容 */int index; /* 索引 */OpNode op; /* 操作符对象 */};} Node;extern int Var[26];结点可以是三种类型(CONTENT,INDEX,OP)。


在Python中使用Ply进行词法语法分析关键词:Python Lex Yacc Ply 词法分析语法分析。
摘要:本文描述了如何在Pyhont中使用Ply进行词法分析和语法分析。
缩略语清单:1 PLY简介PLY是Python Lex-Yacc的缩写。
是用来在Python语言中中进行Lex、Yacc词法分析和语法分析的工具,它本身也完全采用Python写成。
在功能上与流行的Flex和Bison相比存在一些欠缺,但是其非常的简单易用。
下面我们就简单的介绍PLY的背景安装和使用。
Python具有良好的可扩展性,我们如果要使用Python语言来进行相关的词法语法分析,可以使用Flex以及Bison工具、以及C语言创建Python模块,然后在Python中使用。
这种做法能够极大的发挥Flex以及Bison的强大功能,而且运行效率勿庸置疑。
但是不够简单直观。
PLY的出现,使得我们可以直接在Python语言中进行词法语法分析,并且非常方便。
首先得安装Python解释器,我这里安装的是ActivePython 2.3.2。
然后到下面的网站下载PLY 的安装程序,当前版本是1.5。
/ply/下载之后解压缩,然后运行里面的setup.py,如下:python setup.py install那么PLY就安装到你的Python安装目录下,我们可以开始使用PLY了。
2 词法分析PLY进行词法分析的原理和Flex相似,但是在实现上有很大的不同。
下面用一个计算表达式的例子来说明。
下面的代码分析数学表达式,里面可以有圆括号,+-×/和=等赋值运算,整数,变量名等。
import lextokens = ('NAME','NUMBER','PLUS','MINUS','TIMES','DIVIDE','EQUALS','LPAREN','RPAREN',)#Tokens的正则表达式定义t_PLUS = r'\+'t_MINUS = r'-'t_TIMES = r'\*'t_DIVIDE = r'/'t_EQUALS = r'='t_LPAREN = r'\('t_RPAREN = r'\)'t_NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'def t_NUMBER(t):r'\d+'try:t.value = int(t.value)except ValueError:print"Integer value too large", t.valuet.value = 0return tt_ignore = " \t"def t_newline(t):r'\n+'t.lineno += t.value.count("\n")def t_error(t):print"Illegal character '%s'" % t.value[0]t.skip(1)# Build the lexerlex.lex()def startlex():s = "100*(3+5/2)"while True:token = lex.token()if not token:breakprint tokenif __name__=='__main__':startlex()PLY利用了Python的自省机制(introspection)。
计算机与信息学院《操作系统与编译原理联合课程设计报告》专题:编译原理部分学生姓名:学号:专业班级:指导教师:2014 年 7 月一、设计目标设计一个语法制导翻译器,将算术表达式、for语句、while语句翻译成四元式。
要求先确定一个定义算术表达式、for语句、while语句的文法,为其设计一个语法分析程序,为每条产生式配备一个语义子程序,按照一遍扫描的语法制导翻译方法,实现翻译程序。
对用户输入的任意一个正确的表达式,程序将其转换成四元式输出。
二、设计思路开发平台:Visual C++ MFC解决这个问题的方案分为以下几个步骤:1.将算数表达式、for语句、while语句转换为四元式的第一步为对读入的表达式进行处理,即删除不必要的空格、回车、换行等,保证之后的步骤能够顺利进行。
2.分析算术表达式、for语句、while语句的文法。
3.通过词法分析判断语句中的每个字符的类型,如:数字、字母、符号等。
4.建立每种文法的LR(0)分析表,通过每个文法的LR(0)分析表对相应的表达式进行语法分析。
5.在语法分析正确的情况下,通过语法分析的中间过程的符号栈输出四元式,四元式的形式为:(op arg1 arg2 result)。
(一)算术表达式转换为四元式将算术表达式转换为四元式首先考虑了括号的问题,对于不同的算术表达式第一步进行词法分析,即确定各种符号的位置。
而括号中的式子是优先级最高的,应该最先进行处理。
我使用了一个数组记录算术表达式中括号的位置,并且定义了first_cc和first_jj函数对括号的乘除法和加减法分别进行处理。
后将括号的式子以四元式的形式输出。
通过以上转换,已将原算术表达式中的括号中的容使用大写字母’A’、’B’……等代替(其中定义声明了change函数,用来将括号部分替换为大写字母)。
新的式子中,只含有加减乘除以及赋值这四种运算,后根据优先级的不同,逐步生成四元式。
其算法流程图如右图所示。
语法制导翻译
语法制导翻译是一种将源语言(通常为自然语言)的语法结构与目标语言的语法结构相对应的翻译方法。
它通过语法分析器和语法制导翻译器来实现。
在语法制导翻译中,源语言和目标语言的语法规则被定义成一个或多个上下文无关文法。
语法制导翻译的主要思想是在语法分析树中嵌入翻译动作,并通过语法制导翻译器将源语言转换为目标语言。
语法制导翻译器的主要任务是对每个语法分析树节点进行翻译动作的定义,并将这些翻译动作与语法分析器的分析过程相结合,最终生成目标语言的语法结构。
语法制导翻译是机器翻译领域的一种重要研究方向,它可以有效地解决自然语言翻译中的语言差异和歧义问题。
同时,它也是编译原理、计算机语言学等领域中的基础性问题。