北邮编译原理-词法分析文档和程序
- 格式:docx
- 大小:639.76 KB
- 文档页数:11


北邮编译原理北邮的编译原理课程主要介绍了编译器的构造和工作原理,包括词法分析、语法分析、语义分析、中间代码生成、目标代码生成和代码优化等各个阶段的任务和技术。
此外,还介绍了编译器构造过程中采用的近似于形式化的语法制导翻译技术,以及目标程序在运行时刻的环境,包括存储空间的分配、作用域的实现、参数的传递等。
具体来说,编译原理课程的核心内容包括以下几个方面:词法分析:这是编译过程的第一阶段,主要任务是从左到右逐个字符地扫描源程序,将构成源程序的字符串分解成一个个具有独立意义的单词(也称为记号或token),如标识符、常数、运算符等,并以记号流的形式输出。
语法分析:在词法分析的基础上,语法分析的任务是将记号流按照语言的语法规则层次地分组,形成语法短语,并构造出一棵分析树或抽象语法树(AST),以表示程序的语法结构。
语义分析:语义分析是对语法分析得到的语法结构进行语义检查,包括类型检查、控制流检查、名字的作用域和绑定等。
这一阶段的目的是确保源程序在语义上是正确的。
中间代码生成:在语义分析的基础上,中间代码生成阶段的任务是将语法结构转换为中间代码,这是一种更接近于目标代码的中间表示形式,便于进行后续的优化和代码生成。
代码优化:代码优化是对中间代码进行一系列等价变换,以改进目标程序的性能,如减少运行时间、减少存储空间等。
优化可以在编译的各个阶段进行,但主要在中间代码生成和目标代码生成之间进行。
目标代码生成:目标代码生成是编译过程的最后阶段,将优化后的中间代码转换为特定机器上的目标代码,通常是汇编语言或机器语言。
通过学习北邮的编译原理课程,学生可以掌握编译器的构造原理和实现技术,了解编译技术在软件开发中的重要作用,并为后续的软件开发和系统设计打下坚实的基础。


实验报告编译原理与技术ytinrete程序设计1题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求如下。
(1)、可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)、可以识别并读取源程序中的注释。
(3)、可以统计源程序汇总的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果(4)、检查源程序中存在的错误,并可以报告错误所在的行列位置。
(5)、发现源程序中存在的错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
|实验要求:方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:通过编写LEX源程序,利用LEX软件工具自动生成词法分析程序。
算法思路:首先通过遍历,统计行号和字符数,并记录所有的注释。
其次,再次读取,利用一个字符数组作为buffer保存一行的数据,在对其中的数据进行处理,完成之后再读下一行,跳过注释。
对于整行数据的处理,依靠空格将其分成单个单词再具体处理。
对于查错问题实在是一个难题,只能根据一些规则判定有错并记录。
&程序源代码:==*p || 'E'==*p || 'e'==*p)//小数和指数形式{(1,*p);p++;while(isdigit(*p)){(1,*p);p++;}}{sum_word++;(temp_word);cout<<endl<<"第"<<sum_word<<"个单词:"<<" 无符号数:" <<temp_word<<endl;}}elseif('#'==*p)//预处理文件特殊处理{while('\0'!=*p){(1,*p);》p++;}//p指向换行,完成直接退出(temp_word);}elseif('"'==*p)//字符串{();p++;while('"'!=*p)<{(1,*p);p++;}p++;sum_word++;cout<<endl<<"第"<<sum_word<<"个单词:"<<" 字符串:" <<temp_word<<endl;}elseif('+'==*p)//处理符号{。

1.正规式与有限自动机之间的关系。
——有限自动机M向正规式阿尔法的转换。
1)把状态转换图的概念拓展,令每条弧上都可以用一个正规式作标记。
2)在M 的转换图上加两个结点:x,y。
从x用一颗塞隆弧连接到M的所有初态结点;从M的终态结点用一颗塞隆弧连接到y。
这个新的NFA为M’,且L(M)=L (M')3)通过引入的3条有限自动机替换规则逐步消去M’中的所有结点,直到只剩下x和y为止。
这样,在x至y的弧线上的标记就是一颗塞隆上的正规式,也就是M接受的正规式。
2.正规式阿尔法向确定有限自动机M的转换。
1)由正规式阿尔法构造一个如下仅有两个结点x,y的状态图。
2)按所引入的3条正规式分裂规则分裂阿尔法。
3)重复步骤2直到每个弧上的标记是一颗塞隆上的一个字符或空串为止。
4)将所得到的NFA M进行确定化就可得到DFA M。
3.词法分析程序:4.任务:从左至右扫描源程序的字符串,按照词法规则识别出一个个正确的单词,并转换为相应的二元式形式,交给语法分析适用。
5.预处理原因:1)源程序中包含注解部分,还有无用的空格、跳格、回车换行等编辑字符,它们与词法分析无关。
2)一行语句结束应配上一个特殊字符说明。
3)有些语言要识别标号区,区分标号语句,找出续行符连接成完整语句等。
4)输出源程序清单以便复核。
6.超前搜索:注:一般高级语言不必超前搜索,但有些对关键词不加保护的语言,单词间没有明确界符,要在上下文环境中识别单词,这时需要超前搜索。
7.单词分类(以c语言为例):基本字(关键字、保留字),标识符(变量名、数组名、函数名、过程名......),常量,运算符,界符。
8.扫描器的输出格式:使用二元式(类号,内码),每个单词对应一个二元式。
其中类号用整数表示,类号既可区分单词种类,又可便于程序处理。
类号考虑原则是:1)每个基本字占有一个类号,内码缺省;2)各种标识符统一为一类,由内码来区分不同的标识符名。
通常将各标识符的符号表入口地址作为其内码。



编译原理实验词法分析程序实验一:词法分析程序1、实验目的从左至右逐个字符的对源程序进行扫描,产生一个个单词符号,把字符串形式的源程序改造成单词符号形式的中间程序。
2、实验内容表C语言子集的单词符号及内码值单词符号种别编码助记符内码值while 1 while --if 2 if --else 3 else --switch 4 switch --case 5 case --标识符 6 id id在符号表中的位置常数7 num num在常数表中的位置+ 8 + --- 9 - --* 10 * --<= 11 relop LE< 11 relop LT== 11 relop LQ= 12 = --; 13 ; --输入源程序如下if a==1 a=a+1;else a=a+2;输出对应的单词符号形式的中间程序3、实验过程实验上机程序如下:#include "stdio.h"#include "string.h"int i,j,k;char s ,a[20],token[20];int letter(){if((s>=97)&&(s<=122))return 1;else return 0;}int Digit(){if((s>=48)&&(s<=57))return 1;else return 0;}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(){if(strcmp(token, "while")==0)return 1;else if(strcmp(token, "if")==0)return 2;else if(strcmp(token,"else")==0)return 3;else if(strcmp(token,"switch")==0)return 4;else if(strcmp(token,"case")==0)return 5;else return 0;}void main(){printf("please input you source program,end('#'):\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!='#');i=1;memset(token,0,sizeof(char)*10);j=0;get();while(s!='#'){if(s==' '||s==10||s==13)get();else{switch(s){case'a':case'b':case'c':case'd':case'e':case'f':case'g':case'h':case'i':case'j':case'k':case'l':case'm':case'n':case'o':case'p':case'q':case'r':case's':case't':case'u':case'v':case'w':case'x':case'y':case'z':while(Digit()||letter()){token[j]=s;j=j+1;get();}retract();k=lookup();if(k==0)printf("(6,%s)\n",token); elseprintf("(%d,null)\n",k); break;case'0':case'1':case'2':case'3':case'4':case'5':case'6':case'7':case'8':case'9':while(Digit()){token[j]=s;j=j+1;get();}retract();printf("(%d,%s)\n",7,token); break;case'+':printf("(+,null)\n"); break;case'-':printf("(-,null)\n"); break;case'*':printf("(*,null)\n"); break;case'<':get();if(s=='=')printf("(relop,LE)\n"); else{retract();printf("(relop,LT)\n");}break;case'=':get();if(s=='=')printf("(relop,EQ)\n"); else{retract();printf("(=,null)\n");}break;case';':printf("(;,null)\n"); break;default:printf("(%c,error)\n",s);break;}memset(token,0,sizeof(char)*10);j=0;get();}}}4、实验结果实验结果分析:if是关键字,对应种别编码为2,输出(2,null)a是标识符,对应种别编码为6,值为a,输出(6,a)==的助记符是relop,内码值为LE,输出(relop,LE)1是常数,对应种别编码为7,值为1,输出(7,1)a是标识符,对应种别编码为6,值为a,输出(6,a)=是赋值符号,直接输出,(=,null)a是标识符,对应种别编码为6,值为a,输出(6,a)+是运算符,直接输出(=,null)1是常数,对应种别编码为7,值为1,输出(7,1);是语句结束符号,直接输出(;,null)else是关键字,对应种别编码为3,输出(3,null)a是标识符,对应种别编码为6,值为a,输出(6,a)=是赋值符号,直接输出,(=,null)a是标识符,对应种别编码为6,值为a,输出(6,a)+是运算符,直接输出(=,null)2是常数,对应种别编码为7,值为2,输出(7,2);是语句结束符号,直接输出(;,null)#是输入结束标志编译原理实验语法分析程序实验二:语法分析程序1、实验目的:将单词组成各类语法单位,讨论给类语法的形成规则,判断源程序是否符合语法规则3、实验内容:给定文法:G[E]:E→E+E|E-E|E*E|E/E|(E)E→0|1|2|3|4|5|6|7|8|9首先把G[E]构造为算符优先文法,即:G’[E]:E→E+T|TT→T-F|FF→F*G|GG→G/H|HH→(E)|i得到优先关系表如下:+ - * / i ( ) # + ·><·<·<·<·<··>·> - ·>·><·<·<·<··>·> * ·>·>·><·<·<··>·> / ·>·>·>·><·<··>·>i ·>·>·>·>·>·>( <·<·<·<·<·<·=) ·>·>·>·>·>·> # <·<·<·<·<·<·=构造出优先函数+ - * / i ( ) #f 6 8 10 12 12 2 12 2g 5 7 9 11 13 13 2 2要求输入算术表达式:(1+2)*3+2*(1+2)-4/2输出其对应的语法分析结果4、实验过程:上机程序如下:#include "stdio.h"#include "string.h"char a[20],optr[10],s,op;int i,j,k,opnd[10],x1,x2,x3;int operand(char s){if((s>=48)&&(s<=57))return 1;else return 0;}int f(char s){switch(s){case'+':return 6;case'-':return 8;case'*':return 10;case'/':return 12;case'(':return 2;case')':return 12;case'#':return 2;default:printf("error");}}int g(char s){switch(s){case'+':return 5;case'-':return 7;case'*':return 9;case'/':return 11;case'(':return 13;case')':return 2;case'#':return 2;default:printf("error");}}void get(){s=a[i];i=i+1;}void main(){printf("请输入算数表达式,并以‘#’结束:\n");i=0;do{scanf("%c",&a[i]);i++;}while(a[i-1]!='#');i=0;j=0;k=0;optr[j]='#';get();while((optr[j]!='#')||(s!='#')){if(operand(s)){opnd[k]=s-48;k=k+1;get();}else if(f(optr[j])<g(s)){j=j+1;optr[j]=s;get();}else if(f(optr[j])==g(s)){if(optr[j]=='('&&s==')'){j=j-1;get();}else if(optr[j]=='('&&s=='#'){printf("error\n");break;}else if(optr[j]=='#'&&s==')'){printf("error\n");break;}}else if(f(optr[j])>g(s)){op=optr[j];j=j-1;x2=opnd[k-1];x1=opnd[k-2];k=k-2;switch(op){case'+':x3=x1+x2;break;case'-':x3=x1-x2;break;case'*':x3=x1*x2;break;case'/':x3=x1/x2;break;}opnd[k]=x3;k=k+1;printf("(%c,%d,%d,%d)\n",op,x1,x2,x3);}else{printf("error\n");break;}}if(j!=0||k!=1)printf("error\n");}5、实验结果:实验结果分析:(1+2)*3+2*(1+2)-4/2#因为‘)’优先级大于‘*’,先计算1+2=3,并输出(+,1,2,3)原式变为:3*3+2*(1+2)-4/2#因为‘*’优先级大于‘+’,先计算3*3=9,并输出(*,3,3,9)原式变为:9+2*(1+2)-4/2#因为‘)’优先级大于‘-’,先计算1+2=3,并输出(+,1,2,3)原式变为:9+2*3-4/2#因为‘*’优先级大于‘-’,先计算2*3=6,并输出(*,2,3,6)原式变为:9+6-4/2#因为‘/’优先级大于‘#’,先计算4/2=2,并输出(/,4,2,2)原式变为:9+6-2#因为‘-’优先级大于‘#’,先计算6-2=4,并输出(-,6,2,4)原式变为:9+4#因为‘+’优先级大于‘#’,计算9+4=13,并输出(+,9,4,13)原式变为13#优先级等于#,跳出while循环,运算结束!。

实验1-3 《编译原理》S语言词法分析程序设计方案一、实验目的了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式;二、实验内容ﻩ1.根据状态转换图直接编程编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。
在此,词法分析程序作为单独的一遍,如下图所示。
具体任务有:(1)组织源程序的输入(2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件(3)删除注释、空格和无用符号(4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。
将错误信息输出到屏幕上。
(5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值三、实验要求1.能对任何S语言源程序进行分析ﻩ在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。
2.能检查并处理某些词法分析错误词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。
本实验要求处理以下两种错误(编号分别为1,2):1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。
2:源程序文件结束而注释未结束。
注释格式为:/* …… */四、保留字和特殊符号表单词的构词规则:字母=[A-Za-z]数字=[0-9]标识符=(字母|_)(字母|数字)*数字=数字(数字)*(.数字+| )四、S语言表达式和语句说明ﻩ1.算术表达式:+、-、*、/、%ﻩ2.关系运算符:>、>=、<、<=、==、!=3.赋值运算符:=,+=、-=、*=、/=、%=ﻩ4.变量说明:类型标识符变量名表;5.类型标识符:int char floatﻩ6.If语句:if表达式then 语句[else语句] ﻩ7.For语句:for(表达式1;表达式2;表达式3) 语句ﻩ8.While语句:while表达式do 语句9.S语言程序:由函数构成,函数不能嵌套定义。
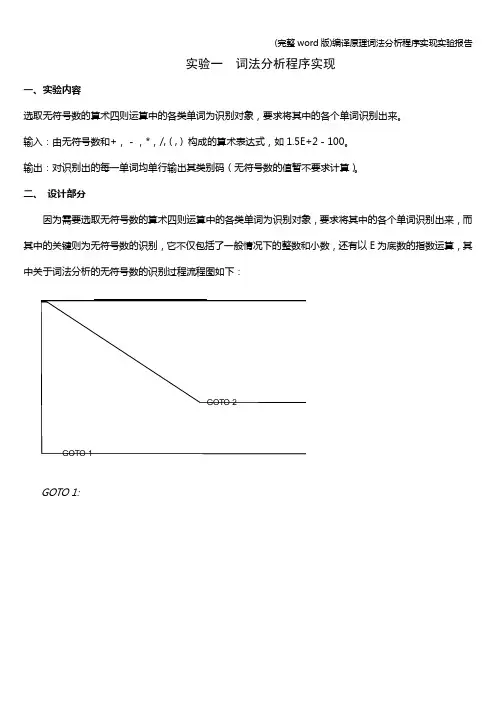
(完整word版)编译原理词法分析程序实现实验报告实验一词法分析程序实现一、实验内容选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。
输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。
输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。
二、设计部分因为需要选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来,而其中的关键则为无符号数的识别,它不仅包括了一般情况下的整数和小数,还有以E为底数的指数运算,其中关于词法分析的无符号数的识别过程流程图如下:GOTO 1:(完整word版)编译原理词法分析程序实现实验报告GOTO 2:三、源程序代码部分#include <stdio.h>#include<stdlib.h>#include <math.h>#define MAX 100#define UNSIGNEDNUMBER 1#define PLUS 2#define SUBTRACT 3#define MULTIPLY 4#define DIVIDE 5#define LEFTBRACKET 6#define RIGHTBRACKET 7#define INEFFICACIOUSLABEL 8#define FINISH 111int count=0;int Class;void StoreType();int Type[100];char Store[20]={'\0'};void ShowStrFile();//已经将要识别的字符串存在文件a中void Output(int a,char *p1,char *p2);//字符的输出过程int Sign(char *p);//'+''-''*''/'整体识别过程int UnsignedNum(char *p);//是否适合合法的正整数0~9int LegalCharacter(char *p);//是否是合法的字符:Sign(p)||UnsignedNum(p)||'E'||'.' void DistinguishSign(char *p);//'+''-''*''/'具体识别过程void TypyDistinguish();//字符的识别过程void ShowType();//将类别码存储在Type[100]中,为语法分析做准备void ShowStrFile()//已经将要识别的字符串存在文件a中{FILE *fp_s;char ch;if((fp_s=fopen("a.txt","r"))==NULL){printf("The FILE cannot open!");exit(0);}elsech=fgetc(fp_s);while(ch!=EOF){putchar(ch);ch=fgetc(fp_s);}printf("\n");}void StoreStr()//将文件中的字符串存储到数组Store[i] {FILE *fp=fopen("a.txt","r");char str;int i=0;while(!feof(fp)){fscanf(fp,"%c",&str);if(str=='?'){Store[i]='\0';break;}Store[i]=str;i++;}Store[i]='\0';}void ShowStore(){int i;for (i=0;Store[i]!='\0';i++)printf("%c",Store[i]);printf("\n");}void Output(int a,char *p1,char *p2){printf("%3s\t%d\t%s\t","CLASS",a,"VALUE");while(p1<=p2){printf("%c",*p1);p1++;}printf("\n");}int Sign(char *p){char ch=*p;if(ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')') return 1;elsereturn 0;}int UnsignedNum(char *p){char ch=*p;if('0'<=ch&&ch<='9')return 1;elsereturn 0;}int LegalCharacter(char *p){char ch=*p;if(Sign(p)||UnsignedNum(p)||ch=='E'||ch=='.')。

实验报告班级:2011211314姓名: oneseven学号:一.题目:词法分析程序设计与实现二.实验内容:设计并实现 C 语言的词法分析程序,要求如下。
(1) 可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2) 可以识别并读取源程序中的注释。
(3) 可以统计源程序中的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果。
(4) 检查源程序中存在的非法字符错误,并可以报告错误所在的行列位置。
三.实现要求:采用C/C++作为实现语言,手工编写词法分析程序。
四.实现功能:基本完成了实验内容中要求的所有功能。
(1)识别出源程序中的每个单词符号,并以记号的形式输出每个单词符号(2)识别并读取源程序中的注释(3) 统计源程序中的语句行数、单词个数和字符个数(4) 检查源程序中存在的非法字符错误,并可以报告错误所在的行列位置。
注:本程序未把注释中的单词符号,“”中的单词符号统计在单词个数中。
单词个数只包括了标示符,关键字,无符号数。
五.实验原理:1.词法分析程序的功能:输入源程序,输出单词符号的记号形式,如图所示:源程序单词符号的记号形式2.处理过程:每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直至整个源程序全部扫描完毕,并形成相应的单词串形式的源程序。
六.代码#include<iostream>#include<fstream>#include<string>#include <iomanip>using namespace std;string keyword[32]={"auto","break","case","char","const", //关键字"continue","default","do","double","else","extern","enum","float","for","goto","if","int","long","return","register","static","short","signed","unsigned","struct","switch","sizeof","typedef","union","volatile","void","while"};int column=0,row=1,character=0,word=0;ifstream inf("test.txt",ios::in);char c;int find_key(string word) //匹配关键字{for(int i=0;i<32;i++)if(keyword[i].compare(word)==0)return 1;return 0;}void choice(){while(c=='\n'||c==' '||c=='\t') //不计空白符{if (c=='\n'){row++;column=0; //row清零,重新计数另一行}c=inf.get();column++;}return;}void get() //读取字符{character++;c=inf.get();column++;return;}int process(){string str="";if(inf.fail())cout<<"请创建test.txt并输入程序"<<endl;else{ofstream outf("out.txt");outf<<setw(10)<<"正规表达式"<<setw(30)<<"记号"<<setw(30)<<"属性"<<endl;c=inf.get();column++;while(c!=EOF){switch(c){ //匹配字符对应记号case 'a'...'z':case 'A'...'Z':case '_':word++;while(isalpha(c)||isdigit(c)||c=='_'){str+=c;get();}if(c=='@'||c=='?'||c=='$'||c=='#'){int tag=column;while(isalpha(c)||isdigit(c)||c=='_'||c=='@'||c=='?'||c=='$'||c=='#'){str+=c;get();}outf<<setw(10)<<str<<setw(30)<<"ERROR"<<setw(30)<<"错误在第"<<row<<"行第"<<tag<<"列"<<endl;str="";break;}if(find_key(str)){outf<<setw(10)<<str<<setw(30)<<str<<setw(30)<<"关键字"<<endl;str="";}else{outf<<setw(10)<<str<<setw(30)<<"id"<<setw(30)<<"标示符"<<endl;str="";}break;case '0'...'9':word++;while(isdigit(c)||c=='.'||c=='e'||c=='E'){str+=c;if(c=='e'||c=='E'){get();str+=c;}get();}if(isalpha(c)){int tag=column;while(isalpha(c)||c=='_'||isdigit(c)||c=='@'||c=='?'||c=='$'||c=='#'){str+=c;get();}outf<<setw(10)<<str<<setw(30)<<"ERROR"<<setw(30)<<"错误在第"<<row<<"行第"<<tag<<"列"<<endl;str="";break;}outf<<setw(10)<<str<<setw(30)<<"num"<<setw(30)<<"无符号数"<<endl;str="";break;case'>':get();if(c=='=')outf<<setw(10)<<">="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else if(c=='>')outf<<setw(10)<<">>"<<setw(30)<<"bit_op"<<setw(30)<<"位运算符"<<endl;else{outf<<setw(10)<<">"<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;break;}get();break;case'<':get();if(c=='=')outf<<setw(10)<<"<="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else if(c=='<')outf<<setw(10)<<"<<"<<setw(30)<<"bit_op"<<setw(30)<<"位运算符"<<endl;else{outf<<setw(10)<<"<"<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;break;}get();break;case'=':get();if(c=='=')outf<<setw(10)<<"=="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else{outf<<setw(10)<<"="<<setw(30)<<"assign_op"<<setw(30)<<"赋值符"<<endl;break;}get();break;case'!':get();if(c=='=')outf<<setw(10)<<"!="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else{outf<<setw(10)<<"!"<<setw(30)<<"logic_op"<<setw(30)<<"逻辑运算符"<<endl;break;}get();break;case'|':get();if(c=='|')outf<<setw(10)<<"||"<<setw(30)<<"relop"<<setw(30)<<"逻辑运算符"<<endl;else{outf<<setw(10)<<"|"<<setw(30)<<"logic_op"<<setw(30)<<"位运算符"<<endl;break;}get();break;case'&':get();if(c=='&')outf<<setw(10)<<"&&"<<setw(30)<<"relop"<<setw(30)<<"逻辑运算符"<<endl;else{outf<<setw(10)<<"&"<<setw(30)<<"logic_op"<<setw(30)<<"位运算符"<<endl;break;get();break;case'+':get();if(c=='+')outf<<setw(10)<<"++"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else if(c=='=')outf<<setw(10)<<"+="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else{outf<<setw(10)<<"+"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;break;}get();break;case'-':get();if(c=='-')outf<<setw(10)<<"--"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else if(c=='=')outf<<setw(10)<<"-="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else{outf<<setw(10)<<"-"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;break;}get();break;case'*':get();if(c=='=')outf<<setw(10)<<"*="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else{outf<<setw(10)<<"*"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;break;}break;case '\"':str+=c;get();while(c!='\"'){str+=c;get();if(c==' '||c=='\t')character--;}str+='\"';outf<<setw(10)<<str<<setw(30)<<"literal"<<setw(30)<<"字符串"<<endl;str="";get();break;case'/':str+=c;get();if(c=='=')outf<<setw(10)<<"/="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else if(c=='/'){str+=c;get();while(c!='\n'&&c!=EOF){str+=c;get();}character--;outf<<setw(10)<<str<<setw(30)<<"annotation"<<setw(30)<<"注释"<<endl;}else if(c=='*'){str+=c;get();char tag=c;while(tag!='*'&&c!='/'&&c!=EOF){str+=c;tag=c;choice();get();}str+=c;outf<<setw(10)<<str<<setw(30)<<"annotation"<<setw(30)<<"注释"<<endl;}else{outf<<setw(10)<<"/"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;str="";break;}str="";get();break;case ' ':case '\n':case EOF:break;default:outf<<setw(10)<<c<<setw(30)<<c<<setw(30)<<"符号"<<endl;get();break;}choice();}outf<<"语句行数:"<<row<<endl;outf<<"单词个数:"<<word<<endl;outf<<"字符个数:"<<character<<endl;inf.close();outf.close();return 1;}inf.close();return 0;}int main(){int flag;flag=process();if(flag==1){cout<<"词法分析源程序详见test.txt"<<endl;cout<<"词法分析结果及错误分析详见out.txt"<<endl; //输出结果cout<<"语句行数:"<<row<<endl;cout<<"单词个数:"<<word<<endl;cout<<"字符个数:"<<character<<endl;}system("pause");return 0;}七.测试数据:(1)运行程序(2)测试代码test.txt(3)输出结果out.txt。
实验2 词法分析程序的设计一、实验目的掌握计算机语言的词法分析程序的开发方法。
二、实验内容编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
三、实验要求1、根据以下的正规式,编制正规文法,画出状态图;标识符<字母>(<字母>|<数字字符>)*十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*)八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)*十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*运算符和界符+ - * / > < = ( ) ;关键字if then else while do2、根据状态图,设计词法分析函数int scan( ),完成以下功能:1)从文本文件中读入测试源代码,根据状态转换图,分析出一个单词,2)以二元式形式输出单词<单词种类,单词属性>其中单词种类用整数表示:0:标识符1:十进制整数2:八进制整数3:十六进制整数运算符和界符,关键字采用一字一符,不编码其中单词属性表示如下:标识符,整数由于采用一类一符,属性用单词表示运算符和界符,关键字采用一字一符,属性为空3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。
四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、实验步骤1、根据正规式,画出状态转换图;2、根据状态图,设计词法分析算法;观察状态图,其中状态2、4、7、10(右上角打了星号)需要回调一个字符。
声明一些变量和函数:ch: 字符变量,存放最新读进的源程序字符。
strToken: 字符串变量,存放构成单词符号的字符串。
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符: = + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
程序设计一词法分析程序一.实验题目和要求题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求如下。
(1)、可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)、可以识别并读取源程序中的注释。
(3)、可以统计源程序汇总的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果(4)、检查源程序中存在的错误,并可以报告错误所在的行列位置。
(5)、发现源程序中存在的错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
实验要求:方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:通过编写LEX源程序,利用LEX软件工具自动生成词法分析程序。
二.程序设计思路采用C++来编写此程序。
根据书上的函数、变量提示写出各种函数、整体框架。
大部分变量名称与书上相同。
画出符号间转换自动机模型,之后根据自动机写函数、错误判断。
缓冲区用数组完成,标记位置的指针用int型来表示。
用lnum存储语句行数,wordnum存储单词个数,charnum存储字符个数。
标点和空格不计算为单词。
错误所在的行列位置存储在error.txt文件当中。
三.程序运行结果举例Code.txt:#include<stdio.h>main(){int num,n=0,m,l,t;printf("please input an integer:");scanf("%d",&num); //dsfsdffor(l=0;num!=0;l++){m=num%10; //sdfafdafor(t=0;t!=l;t++)m=m*2; //dafdafn=nm;num=num/10; /*dafdas2323*/}printf("//the result is %d //",n);return 0 ;}窗口运行结果:============================================================= *词法分析系统*=============================================================请输入需要分析的文件名称:code.txt------------------------------------------------------------- 处理完毕。
编译原理第四章语法分析班级:09211311学号:姓名:schnee目录1.实验题目和要求错误!未定义书签。
2.递归调用预测分析实现自顶向下分析(方法1)错误!未定义书签。
1. 消除左递归 (2)2. 画状态转移图 (3)3. 编程实现递归调用自顶向下分析 (3)3.LR实现自底向上分析(方法三)错误!未定义书签。
1. 构造识别所有活前缀的DFA (6)2. 构造LR分析表 (7)3. 编程实现算法,实现自底向上LR 分析 (8)4.运行结果截图 (11)1. 实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
numE idF F F T F T T T T E T E E |)(||/|*||→→-+→ 实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1) 编程实现算法,为给定文法自动构造预测分析表。
(2) 编程实现算法,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1) 构造识别所有活前缀的DFA 。
(2) 构造LR 分析表。
(3) 编程实现算法,构造LR 分析程序。
方法4:利用YACC 自动生成语法分析程序,调用LEX 自动生成的词法分析程序。
2. 递归调用预测分析实现 自顶向下分析(方法1)(1) 消除文法左递归。
文法改写为:numE idF FT FT T FT T TE TE E TE E |)(||/|*||''''''''→→→-+→→εε(2) 画出状态图得12891 F化简得36 E81 T(3) 预测分析程序的实现①说明定义函数error()为错误处理子程序。
定义函数forward_pointer()为指向输入串的指针前进一位的相关子程序。
实验报告班级:14姓名: oneseven学号:一.题目:词法分析程序设计与实现*二.实验内容:设计并实现 C 语言的词法分析程序,要求如下。
(1) 可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2) 可以识别并读取源程序中的注释。
(3) 可以统计源程序中的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果。
(4) 检查源程序中存在的非法字符错误,并可以报告错误所在的行列位置。
三.实现要求:采用C/C++作为实现语言,手工编写词法分析程序。
;四.实现功能:基本完成了实验内容中要求的所有功能。
(1)识别出源程序中的每个单词符号,并以记号的形式输出每个单词符号(2)识别并读取源程序中的注释(3) 统计源程序中的语句行数、单词个数和字符个数(4) 检查源程序中存在的非法字符错误,并可以报告错误所在的行列位置。
注:本程序未把注释中的单词符号,“”中的单词符号统计在单词个数中。
单词个数只包括了标示符,关键字,无符号数。
五.实验原理:1.词法分析程序的功能:输入源程序,输出单词符号的记号形式,如图所示:>源程序词法分析器单词符号的记号形式词法分析器2.处理过程:每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直至整个源程序全部扫描完毕,并形成相应的单词串形式的源程序。
六.代码#include<iostream>#include<fstream>—#include<string>#include <iomanip>using namespace std;string keyword[32]={"auto","break","case","char","const", .'z':case 'A'...'Z':case '_':word++;—while(isalpha(c)||isdigit(c)||c=='_'){str+=c;get();}if(c=='@'||c==''||c=='$'||c=='#'){int tag=column;】while(isalpha(c)||isdigit(c)||c=='_'||c=='@'||c==''||c=='$'||c=='#') {str+=c;get();}outf<<setw(10)<<str<<setw(30)<<"ERROR"<<setw(30)<<"错误在第"<<row<<"行第"<<tag<<"列"<<endl;str="";break;*}if(find_key(str)){outf<<setw(10)<<str<<setw(30)<<str<<setw(30)<<"关键字"<<endl;str="";}else{}outf<<setw(10)<<str<<setw(30)<<"id"<<setw(30)<<"标示符"<<endl;str="";}break;case '0'...'9':word++;while(isdigit(c)||c=='.'||c=='e'||c=='E'){:str+=c;if(c=='e'||c=='E'){get();str+=c;}get();}/if(isalpha(c)){int tag=column;while(isalpha(c)||c=='_'||isdigit(c)||c=='@'||c==''||c=='$'||c=='#') {str+=c;get();};outf<<setw(10)<<str<<setw(30)<<"ERROR"<<setw(30)<<"错误在第"<<row<<"行第"<<tag<<"列"<<endl;str="";break;}outf<<setw(10)<<str<<setw(30)<<"num"<<setw(30)<<"无符号数"<<endl;str="";break;case'>':)get();if(c=='=')outf<<setw(10)<<">="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else if(c=='>')outf<<setw(10)<<">>"<<setw(30)<<"bit_op"<<setw(30)<<"位运算符"<<endl;else{outf<<setw(10)<<">"<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl; ;break;}get();break;case'<':get();if(c=='=')outf<<setw(10)<<"<="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;》else if(c=='<')outf<<setw(10)<<"<<"<<setw(30)<<"bit_op"<<setw(30)<<"位运算符"<<endl;else{outf<<setw(10)<<"<"<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl; break;}get();~break;case'=':get();if(c=='=')outf<<setw(10)<<"=="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;else{outf<<setw(10)<<"="<<setw(30)<<"assign_op"<<setw(30)<<"赋值符"<<endl; <break;get();break;case'!':get();if(c=='=')outf<<setw(10)<<"!="<<setw(30)<<"relop"<<setw(30)<<"关系运算符"<<endl;>else{outf<<setw(10)<<"!"<<setw(30)<<"logic_op"<<setw(30)<<"逻辑运算符"<<endl; break;}get();break;case'|':—get();if(c=='|')outf<<setw(10)<<"||"<<setw(30)<<"relop"<<setw(30)<<"逻辑运算符"<<endl;else{outf<<setw(10)<<"|"<<setw(30)<<"logic_op"<<setw(30)<<"位运算符"<<endl; break;}/get();break;case'&':get();if(c=='&')outf<<setw(10)<<"&&"<<setw(30)<<"relop"<<setw(30)<<"逻辑运算符"<<endl;else{"outf<<setw(10)<<"&"<<setw(30)<<"logic_op"<<setw(30)<<"位运算符"<<endl; break;}break;case'+':get();if(c=='+')%outf<<setw(10)<<"++"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else if(c=='=')outf<<setw(10)<<"+="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else{outf<<setw(10)<<"+"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl; break;}<get();break;case'-':get();if(c=='-')outf<<setw(10)<<"--"<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;else if(c=='=')outf<<setw(10)<<"-="<<setw(30)<<"alg_op"<<setw(30)<<"运算符"<<endl;。