河南工业大学实验报告——查找和排序(排序)——张伟龙
- 格式:doc
- 大小:35.50 KB
- 文档页数:4

实验五-查找和排序实验报告范文查找及排序实验-可编辑修改---可编辑修改-实验五查找和排序1、实验目的掌握顺序查找的基本方法掌握简单排序和二分法查找的算法。
2.能运用线性表的查找方法解决实际问题。
2、实验内容1、给出在一个无序表A,采用顺序查找算法查找值为某的元素的算法2、给出一个无序表B,采用简单排序方法使该表递增有序,并采用二分查找算法查找值为某的元素的算法。
3、实验步骤(1)仔细分析实验内容,给出其算法和流程图;(2)用C语言实现该算法;(3)给出测试数据,并分析其结果;(4)在实验报告册上写出实验过程。
4、实验报告要求实验报告要求书写整齐,步骤完整,实验报告格式如下:1、[实验目的]2、[实验设备]3、[实验步骤]4、[实验内容]5、[实验结果(结论)]排序创建二叉捌L「1折半查找算法描述如下:intSearch_Bin(SSTableST,KeyTypekey)low=1;high=ST.length; while(low<=high){mid=(low+high)/2;ifEQ(key,ST.elem[mid].key)returnmid;eleifLT(key,ST.elem[mid].key)high=mid-1;elelow=mid+1;}return0;}//Search_Bin;2.顺序查找算法描述如下:typedeftruct{ElemType某elem;intlength;}SSTable;顺序查找:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查记录;反之,查找不成功。
intSearch_Seq(SSTableST,KeyTypekey){ST.elme[O].key=key;for(i=ST.Iength;!EQ(ST.elem[i].key,key);--i);returni;}(3)写出源程序清单(加适当的注释)。
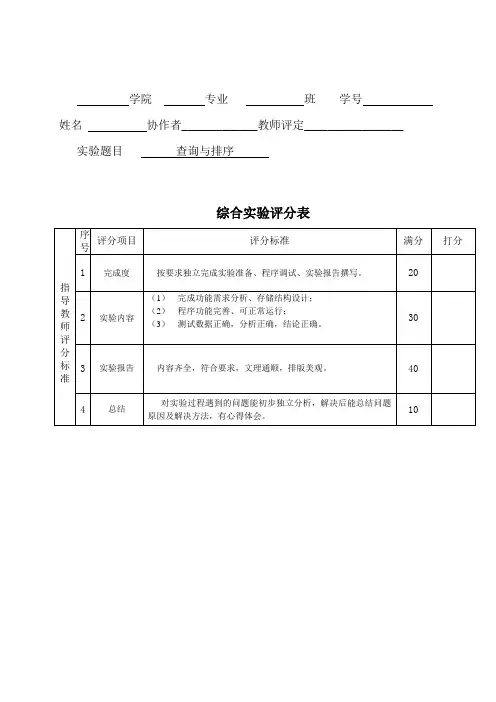
学院专业班学号姓名协作者_____________教师评定_________________ 实验题目查询与排序综合实验评分表实验报告一、实验目的与要求1、掌握散列表的构造及实现散列查找;2、掌握堆排序的算法;3、综合比较各类排序算法的性能。
二、实验内容#include"stdio.h"#include"stdlib.h"#include"string.h"#include"windows.h"#define MAX 20typedef struct{unsigned long key;int result;char name[30];}RNode;RNode t[MAX],r[MAX];int h(unsigned long k) /*散列函数*/{return((k-3109005700)%11);}void insert(RNode t[],RNode x) /*插入函数,以线性探查方法解决冲突*/ {int i,j=0;i=h(x.key);while((j<MAX)&&(t[(i+j)%MAX].key!=x.key)&&(t[(i+j)%MAX].key>0))j++;if(j==MAX) printf("full\n");i=(i+j)%MAX;if(t[i].key==0){t[i]=x;}else{if(t[i].key==x.key)printf("记录已存在!\n");}}int search(RNode t[],unsigned long k) /*插入函数,以线性探查方法解决冲突*/ {int i,j=0;i=h(k);while((j<MAX)&&(t[(i+j)%MAX].key!=k)&&(t[(i+j)%MAX].key!=0))j++;i=(i+j)%MAX;if(t[i].key==k)return(i);if(j==MAX)return MAX;elsereturn(-i);}void sift(RNode r[],int v,int w){int i,j;RNode a;i=v;a=r[i];j=2*i+1;while(j<=w){if((j<w)&&(r[j].result>r[j+1].result))j++;if(a.result>r[j].result){r[i]=r[j];i=j;j=2*j+1;}else break;}r[i]=a;}void sort(RNode r[],int n){int i;RNode y;for(i=n/2-1;i>=0;i--)sift(r,i,n-1);for(i=n-1;i>0;i--){y=r[0];r[0]=r[i];r[i]=y;printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[i].name,r[i].key,r[i].result);sift(r,0,i-1);}printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[0].name,r[0].key,r[0].result);}int menu() /*菜单函数*/{int select;printf("\n\n");printf("\n");printf("\t\t*************查找排序实验******************\n");printf("\t\t*\n");printf("\t\t*************欢迎进入系统******************\n");printf("\t\t* menu: *\n");printf("\t\t* 1.查找*\n");printf("\t\t* 2.排序*\n");printf("\t\t* 0.退出*\n");printf("\t\t*******************************************\n");printf("\n");printf("\t\t\t请输入0--2\n ");printf("\n");printf("请选择您所要的操作(选择(0)退出):");scanf("%d",&select);getchar();return(select);}void main() /*主函数*/{int i,s,n,select;int j=0,m=0;RNode y;for(i=0;i<MAX;i++)t[i].key=0; /*初始化*/for(i=0;i<10;i++) /*导入记录*/ {switch(i){case 0:{RNode x;x.key=310900***;strcpy(," ***");x.result=90;insert(t,x);break;}case 1:{RNode x;x.key=31090***1;strcpy(," ***");x.result=95;insert(t,x);break;}case 2:{RNode x;x.key=3109005***;strcpy(," ***");x.result=92;insert(t,x);break;}case 3:{RNode x;x.key=31090***;strcpy(," ***");x.result=93;insert(t,x);break;}case 4:{RNode x;x.key=3109005***;strcpy(," ***");x.result=94;insert(t,x);break;}case 5:{RNode x;x.key=310900***;strcpy(," ***");x.result=91;insert(t,x);break;}case 6:{RNode x;x.key=3109005***;strcpy(," ***");x.result=96;insert(t,x);break;}case 7:{RNode x;x.key=310900***;strcpy(," ***");x.result=99;insert(t,x);break;}case 8:{RNode x;x.key=310900***;strcpy(," ***");x.result=98;insert(t,x);break;}case 9:{RNode x;x.key=310900***;strcpy(,"***");x.result=97;insert(t,x);break;}}}printf("\n\n\n\n\n\n\n");system("cls");loop:{printf("\n\n\n");select=menu();switch(select){case 1:{printf("\n请输入要查找的学生学号:");scanf("%u",&y.key);s=search(t,y.key);if(s==MAX||s<0) printf("not find\n");else{printf("\n\n你要查找的学生信息\n");printf("学生姓名:%s\t学生学号:%u",t[s].name,t[s].key);} break; }case 2:{for(i=0;i<MAX;i++){if(t[i].key!=0){r[j++]=t[i];m++;}}printf("排序之前:\n\n");for(i=0;i<m;i++)printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[i].name,r[i].key,r[i].result);printf("\n排序之后:\n");sort(r,m);break;}case 0:exit(0);}getchar();goto loop;}}三、实验结果和数据处理(1)查找数据(310900****)(2)排序四、总结这次的课程实验完成了主控界面,录入,输出,排序,查找,结束界面等功能。

查找排序实验报告一、实验目的本次实验的主要目的是深入理解和比较不同的查找和排序算法在性能和效率方面的差异。
通过实际编程实现和测试,掌握常见查找排序算法的原理和应用场景,为今后在实际编程中能够选择合适的算法解决问题提供实践经验。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
计算机配置为:处理器_____,内存_____,操作系统_____。
三、实验内容1、查找算法顺序查找二分查找2、排序算法冒泡排序插入排序选择排序快速排序四、算法原理1、顺序查找顺序查找是一种最简单的查找算法。
它从数组的一端开始,依次比较每个元素,直到找到目标元素或者遍历完整个数组。
其时间复杂度为 O(n),在最坏情况下需要遍历整个数组。
2、二分查找二分查找适用于已排序的数组。
它通过不断将数组中间的元素与目标元素进行比较,将查找范围缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n),效率较高。
3、冒泡排序冒泡排序通过反复比较相邻的两个元素并交换它们的位置,将最大的元素逐步“浮”到数组的末尾。
每次遍历都能确定一个最大的元素,经过 n-1 次遍历完成排序。
其时间复杂度为 O(n^2)。
4、插入排序插入排序将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的合适位置。
其时间复杂度在最坏情况下为 O(n^2),但在接近有序的情况下性能较好。
5、选择排序选择排序每次从待排序数组中选择最小的元素,与当前位置的元素交换。
经过 n-1 次选择完成排序。
其时间复杂度为 O(n^2)。
6、快速排序快速排序采用分治的思想,选择一个基准元素,将数组分为小于基准和大于基准两部分,然后对这两部分分别递归排序。
其平均时间复杂度为 O(n log n),在大多数情况下性能优异。
五、实验步骤1、算法实现使用Python 语言实现上述六种查找排序算法,并分别封装成函数,以便后续调用和测试。

xxx大学实验报告 )——查找查找和排序(一课程名称数据结构实验项目实验三1501 计类信息学院计类系专业班级院系号学姓名期日指导老师绩成批改日期实验目的一1.掌握哈希函数——除留余数法的应用; 2. 掌握哈希表的建立; 3. 掌握冲突的解决方法; 4. 掌握哈希查找算法的实现。
实验内容及要求二哈希,实验内容:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79)。
实现该哈希表的散列,并m=16函数定义为:H(key)=key MOD 13, 哈希表长为。
计算平均查找长度(设每个记录的查找概率相等)使用线性探测再散列或链2. 1. 哈希表定义为定长的数组结构;实验要求:输出等概率散列完成后在屏幕上输出数组内容或链表;4. 地址法解决冲突;3.完成散列后,输入关键字完成查找操作,要分别测查找下的平均查找长度;5. 试查找成功与不成功两种情况。
可尝试使用不同解决不同解决冲突的方法会使得平均查找长度不同,注意:(根据完成情况自选,但至少能使用一种方法冲突的办法,比较平均查找长度。
解决冲突)实验过程及运行结果三#include<stdio.h>#include <stdlib.h>#include <string.h>#define hashsize 16#define q 13int sign=2;typedef struct Hash{值域 // int date; //标记 int sign;}HashNode;线性冲突处理void compare(HashNode H[],int p,int i,int key[]) // { p++; if(H[p].sign!=0) { sign++;compare(H,p,i,key);}elseH[p].date=key[i];H[p].sign=sign; sign=2;}}void Hashlist(HashNode H[],int key[]){ int p;for(int i=0;i<12;i++) {p=key[i]%q; if(H[p].sign==0) { H[p].date=key[i];H[p].sign=1;}else compare(H,p,i,key);}}查找冲突处理int judge(HashNode H[],int num,int n) //{n++; if(n>=hashsize) return 0; if(H[n].date==num) {位置\t 数据\n); 牰湩晴尨 printf(%d\t %d\n\n,n,H[n].date);return 1;}elsejudge(H,num,n);}int search(char num,HashNode H[]) //查找{ int n;n= num % q;if(H[n].sign==0) {牰湩晴尨失败);return 0; } if(H[n].sign!=0&&H[n].date==num) {数据\t 牰湩晴尨位置\n);printf(%d\t %d\n\n,n,H[n].date);} else if(H[n].sign!=0&&H[n].date!=num) {if(judge(H,num,n)==0) return 0;}return 1;}int main(void){ int key[q]={19,14,23,1,68,20,84,27,55,11,10,79}; float a=0;HashNode H[hashsize];for(int i=0;i<hashsize;i++)H[i].sign=0;Hashlist(H,key);数据\n\n);\t 牰湩晴尨位置 for(inti=0;i<hashsize;i++){if(H[i].sign!=0){printf(%d\t %d\n,i,H[i].date);else{H[i].date=0;printf(%d\t %d\n,i,H[i].date);} } int num;'查找完成):\n); 请输入查找数值(‘-1牰湩晴尨for(int i=0;;i++){scanf(%d,&num);if(num==-1)break;if(search(num,H)==0)不存在\n); 牰湩晴尨 } for(inti=0;i<hashsize;i++){printf(%d ,H[i].sign);a=a+H[i].sign; } printf(\%2.0f,a);%0.2f\n,a/12);平均查找长度:牰湩晴尨return 0;}四调试情况、设计技巧及体会首先得确定哈希函数,虽然冲突是无法避免的,但是我们应该选择合适的函数,减少冲突,最简单的可以采用开放定止法,出现冲突后,以原地址为基点再次寻找下一个地址。

排序和查找的实验报告实验报告:排序和查找引言排序和查找是计算机科学中非常重要的基本算法。
排序算法用于将一组数据按照一定的顺序排列,而查找算法则用于在已排序的数据中寻找特定的元素。
本实验旨在比较不同排序和查找算法的性能,并分析它们的优缺点。
实验设计为了比较不同排序算法的性能,我们选择了常见的几种排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
在查找算法的比较实验中,我们选择了顺序查找和二分查找两种常见的算法。
同样地,我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
实验结果在排序算法的比较实验中,我们发现快速排序和归并排序在大多数情况下表现最好,它们的平均执行时间和空间占用都要优于其他排序算法。
而冒泡排序和插入排序则表现较差,它们的执行时间和空间占用相对较高。
在查找算法的比较实验中,二分查找明显优于顺序查找,尤其是在数据规模较大时。
二分查找的平均执行时间远远小于顺序查找,并且占用的空间也更少。
结论通过本实验的比较,我们得出了一些结论。
首先,快速排序和归并排序是较优的排序算法,可以在大多数情况下获得较好的性能。
其次,二分查找是一种高效的查找算法,特别适用于已排序的数据集。
最后,我们也发现了一些排序和查找算法的局限性,比如冒泡排序和插入排序在大数据规模下性能较差。
总的来说,本实验为我们提供了对排序和查找算法性能的深入了解,同时也为我们在实际应用中选择合适的算法提供了一定的参考。
希望我们的实验结果能够对相关领域的研究和应用有所帮助。

淮海工学院计算机科学系实验报告书课程名:《数据结构》题目:查找、排序的应用实验班级:软件112学号:2011122635姓名:排序、查找的应用实验报告要求1目的与要求:1)查找、排序是日常数据处理过程中经常要进行的操作和运算,掌握其算法与应用对于提高学生数据处理能力和综合应用能力显得十分重要。
2)本次实验前,要求同学完整理解有关排序和查找的相关算法和基本思想以及种算法使用的数据存储结构;3)利用C或C++语言独立完成本次实验内容或题目,程序具有良好的交互性(以菜单形式列出实验排序和显示命令,并可进行交互操作)和实用性;4)本次实验为实验成绩评定主要验收内容之一,希望同学们认真对待,并按时完成实验任务;5)本次实验为综合性实验,请于2012年12月23日按时提交实验报告(纸质报告每班10份);6)下周开始数据结构课程设计,务必按时提交实验报告,任何同学不得拖延。
2 实验内容或题目题目:对记录序列(查找表):{287,109,063,930,589,184,505,269,008,083}分别实现如下操作:1)分别使用直接插入排序、冒泡排序、快速排序、简单选择排序、堆排序(可选)、链式基数排序算法对纪录序列进行排序,并显示排序结果;2)对上述纪录列表排好序,然后对其进行折半查找或顺序查找;3 实验步骤与源程序#include "stdio.h"#include "stdlib.h"#define LIST_SIZE 20#define TRUE 1#define FALSE 0typedef int KeyType;typedef struct{KeyType key;}RecordType;typedef struct{RecordType r[LIST_SIZE+1];int length;}RecordList;void seqSearch(RecordList *l){KeyType k; int i;printf("请输出要查询的元素k:");fflush(stdin);scanf("%d",&k);i=l->length;while (i>=0&&l->r[i].key!=k)i--;printf("该元素的位置是");printf("%d",i+1);//cout<<"该元素在图中第"<<i<<"个位置"<<endl; printf("\n");}void BinSrch(RecordList *l){KeyType q;int mid;printf("请输入要查询的元素k:");fflush(stdin);scanf("%d",&q);int low=1;int high=l->length;while(low<=high){mid=(low+high)/2;if(q==l->r[mid].key){printf("该元素的位置为:");printf("%d",mid+1);//注意不能随便使用&printf("\n");break;}else if(q<l->r[mid].key)high=mid-1;elselow=mid+1;}}void inputkey(RecordList *l){int i;printf("请输入线性表长度:");//遇到错误:1.print用法scanf("%d",&(l->length));//&将变量的地址赋值,而不是变量的值for(i=1;i<=l->length ;i++){printf("请输入第%d个元素的值:",i);fflush(stdin);scanf("%d",&(l->r[i].key));}}void InsSort(RecordList *l){for(int i=2;i<=l->length;i++){l->r[0].key=l->r[i].key;int j=i-1;while(l->r[0].key<l->r[j].key){l->r[j+1].key=l->r[j].key;j=j-1;}l->r[j+1].key=l->r[0].key;}}//直接插入排序void BubbleSort(RecordList *l){int x,i,n,change,j;n=l->length;change=TRUE;for(i=1;i<=n-1&&change;++i){change=FALSE;for(j=1;j<=n-i;++j)if(l->r[j].key>l->r[j+1].key){x=l->r[j].key;l->r[j].key=l->r[j+1].key ;l->r[j+1].key=x;change=TRUE;}}}//冒泡排序法int QKPass(RecordList *l,int left,int right) {int x;x=l->r[left].key ;int low=left;int high=right;while(low<high){while(low<high&&l->r[high].key>=x)high--;if(low<high){l->r[low].key=l->r[high].key;low++;}while(low<high&&l->r[low].key<=x)low++;if(low<high){l->r[high].key=l->r[low].key;high--;}}l->r[low].key=x;return(low);}void QKSort(RecordList *l,int low,int high){int pos;if(low<high){pos=QKPass(l,low,high);QKSort(l,low,pos-1);QKSort(l,pos+1,high);}}//快速排序void SelectSort(RecordList *l){int n,i,k,j,x;n=l->length;for(i=1;i<=n-1;++i){k=i;for(j=i+1;j<=n;++j)if(l->r[j].key<l->r[k].key) k=j;if(k!=i){x=l->r[i].key;l->r[i].key=l->r[k].key;l->r[k].key=x;} }}void output(RecordList *l){for(int i=1;i<=l->length;i++){printf("%d",l->r[i].key);printf("\n");}}void main(){RecordList *l,*t,*m,*n;l=(RecordList *)malloc(sizeof(RecordList));int low;int high;int flag=1;int xuanze;while(flag!=0){printf("####################################################\n");printf("###### 请选择你要进行的操作! #########\n");printf("###### 1.直接插入排序; #########\n");printf("###### 2.冒泡排序; #########\n");printf("###### 3.快速排序; #########\n");printf("###### 4.简单选择排序; #########\n");printf("###### 5.顺序查找; #########\n");printf("###### 6.折半查找; #########\n");printf("###### 7.退出! #########\n");printf("####################################################\n");scanf("%d",&xuanze);switch(xuanze){case 1:inputkey(l);InsSort(l);printf("直接插入排序结果是:\n");output(l);break;case 2:inputkey(l);BubbleSort(l);printf("冒泡排序结果是:\n");output(l);break;case 3:inputkey(l);low=1;high=l->length;QKSort(l,low,high);printf("快速排序结果是:\n");output(l);break;case 4:inputkey(l);SelectSort(l);printf("简单选择排序结果是:\n");output(l);break;case 5:inputkey(l);InsSort(l);printf("排序结果是:\n");output(l);seqSearch(l);break;case 6:inputkey(l);InsSort(l);printf("排序结果是:\n");output(l);break;BinSrch(l);case 7:flag=0;break;}}}4 测试数据与实验结果(可以抓图粘贴)《数据结构》实验报告- 10 -5 结果分析与实验体会1.编程时要细心,避免不必要的错误;2.要先熟悉书本上的内容,否则编译会有困难;3.不能太过死板,要灵活运用所学知识。

河南工业大学
《管理信息系统》实验报告
姓名:
学号:
专业班级:
指导教师:
河南工业大学管理学院
实验报告题目:
1、某图书馆图书借阅管理信息系统系统分析
2、学籍管理信息系统系统分析
3、小型超市进、销、存信息系统系统分析
4、图书馆图书管理信息系统系统分析
实验报告内容要求:
【实验步骤】
1.系统项目概述
概要说明所选管理项目的目的,业务范围,主要任务,项目的重要性,必要性和可行性。
2.项目工作计划
说明所选管理项目开发计划,要确定项目各部分的开发任务,人员分工,估计开发进度,其中开发任务包括各部分的系统子项,,进度采用表格或GANTT图描述。
3.管理业务流程分析
通过对所选项目业务调查分析,介绍其的典型组织机构,管理功能及业务流程,给出项目的主要业务流程,利用“业务流程图”或“表格分配图”描述.。
4.数据流程图
明确数据流程的调查与分析过程,绘制数据流程图,编制数据字典;根据业务流程分析结果,结合项目的任务,功能及特点,画出“数据流程图”。
5.数据字典及E-R图
根据“数据流程图”,编写相应的“数据字典”,根据以上分析结果,画出E-R图。
6.总结和体会
独立完成上述内容,并提交书面系统分析报告,简要说明项目开发中成功和失败的经验教训。

河南工业大学《大学计算机基础及office应用》实验报告专业班级:机械学号:2014300 姓名:实验单元一Windows 7和Word的操作及应用实验一Windows 7基本操作实验时间:10月22日【实验目的】1、熟练掌握文件和文件夹的创建及删除。
2、掌握文件和文件夹的编辑操作。
3、掌握查看文件的视图方式,能够显示隐藏文件及文件的扩展名。
4、掌握库的新建及将文件夹添加到库中。
5、掌握通过控制面板设置PC机的用户帐户、硬件和声音、日期和时间、输入法以及系统和安全的方法。
【实验环境】安装了Windows 7操作系统的PC机。
【实验内容】教材88页的实训项目2-1和92页的实训项目2-2。
(要求:创建的Word文件的名字以学生本人的姓名命名)【实验步骤】根据老师要求完成实验操作。
【实验结果】【实验体会】我通实践操作,熟练1、掌握文件和文件夹的创建及删除。
2、掌握文件和文件夹的编辑操作。
3、掌握查看文件的视图方式,能够显示隐藏文件及文件的扩展名。
4、掌握库的新建及将文件夹添加到库中。
5、掌握通过控制面板设置PC机的用户帐户、硬件和声音、日期和时间、输入法以及系统和安全的方法。
感受到了计算机的操作方便实验二Word文档的基本编辑实验时间:10月30日【实验目的】1、掌握文档的建立、保存与打开方法。
2、掌握文本内容的基本编辑方法。
3、掌握文档的排版方法。
【实验环境】安装了Windows XP操作系统和Word应用软件的PC机。
【实验内容】由学生自选一篇带标题的含多个段落的文章,结合教材133页的实践4.1按如下要求完成对文档的编辑与排版。
1、为标题设置样式“标题1”。
2、为文章第一行的文字设置红色的双下划线。
3、将正文的所有文字设为“小四”、“楷体_GB2312”。
4、设置正文首字下沉,字体为“华文彩云”,下沉3行,距正文“0厘米”。
5、正文所有文字大纲级别设为“正文文本”,左、右缩进都为“0”,段前、段后间距为“0”,首行缩进为“2字符”,行距为“固定值20磅”。

一、实训目的本次实训旨在通过实践操作,掌握顺序查找的基本原理和方法,熟悉顺序查找在解决实际问题中的应用,并提高对数据结构中查找算法的理解和运用能力。
二、实训内容1. 理解顺序查找的基本概念和原理。
2. 编写顺序查找的算法实现。
3. 利用顺序查找算法解决实际问题。
4. 分析顺序查找的效率。
三、实训步骤1. 理论学习首先,通过查阅资料和课堂讲解,了解了顺序查找的基本概念。
顺序查找是一种基本的查找算法,它的工作原理是从线性表的第一个元素开始,逐个比较,直到找到要查找的元素或者查找完整个线性表。
2. 算法实现根据顺序查找的原理,编写了以下伪代码:```function sequentialSearch(arr, x):for i from 0 to length(arr) - 1:if arr[i] == x:return ireturn -1```3. 代码调试将伪代码转换为实际编程语言(如Python)的代码,并进行调试,确保算法的正确性。
```pythondef sequential_search(arr, x):for i in range(len(arr)):if arr[i] == x:return ireturn -1# 测试代码array = [5, 3, 7, 2, 8, 6, 1]target = 7result = sequential_search(array, target)print("元素位置:", result)```4. 测试与分析使用不同的测试数据对顺序查找算法进行测试,分析其性能。
- 测试数据1:已排序数组```array = [1, 2, 3, 4, 5, 6, 7, 8, 9]target = 7result = sequential_search(array, target)print("元素位置:", result)```- 测试数据2:未排序数组```array = [5, 3, 7, 2, 8, 6, 1]target = 7result = sequential_search(array, target)print("元素位置:", result)```5. 效率分析通过对比不同数据规模下的查找时间,分析了顺序查找的效率。

一、实验目的本次实验旨在通过编写程序实现查找和排序算法,掌握基本的查找和排序方法,了解不同算法的优缺点,提高编程能力和数据处理能力。
二、实验内容1. 查找算法本次实验涉及以下查找算法:顺序查找、二分查找、插值查找。
(1)顺序查找顺序查找算法的基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若找到相等的元素,则查找成功;若线性表中所有的元素都与要查找的元素进行了比较但都不相等,则查找失败。
(2)二分查找二分查找算法的基本思想是将待查找的元素与线性表中间位置的元素进行比较,若中间位置的元素正好是要查找的元素,则查找成功;若要查找的元素比中间位置的元素小,则在线性表的前半部分继续查找;若要查找的元素比中间位置的元素大,则在线性表的后半部分继续查找。
重复以上步骤,直到找到要查找的元素或查找失败。
(3)插值查找插值查找算法的基本思想是根据要查找的元素与线性表中元素的大小关系,估算出要查找的元素应该在大致的位置,然后从这个位置开始进行查找。
2. 排序算法本次实验涉及以下排序算法:冒泡排序、选择排序、插入排序、快速排序。
(1)冒泡排序冒泡排序算法的基本思想是通过比较相邻的元素,将较大的元素交换到后面,较小的元素交换到前面,直到整个线性表有序。
(2)选择排序选择排序算法的基本思想是在未排序的序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
(3)插入排序插入排序算法的基本思想是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序算法的基本思想是选择一个元素作为基准元素,将线性表分为两个子表,一个子表中所有元素均小于基准元素,另一个子表中所有元素均大于基准元素,然后递归地对两个子表进行快速排序。
三、实验结果与分析1. 查找算法通过实验,我们发现:(1)顺序查找算法的时间复杂度为O(n),适用于数据量较小的线性表。

排序查找实验报告排序查找实验报告一、引言排序和查找是计算机科学中非常重要的基础算法。
排序算法可以将一组无序的数据按照某种规则重新排列,而查找算法则可以在大量数据中快速找到目标元素。
本实验旨在通过实际操作和观察,对比不同的排序和查找算法的性能和效果,以便更好地理解和应用这些算法。
二、实验目的本实验的主要目的有以下几点:1. 理解不同排序算法的原理和特点;2. 掌握不同排序算法的实现方法;3. 比较不同排序算法之间的性能差异;4. 理解不同查找算法的原理和特点;5. 掌握不同查找算法的实现方法;6. 比较不同查找算法之间的性能差异。
三、实验过程1. 排序算法实验在排序算法实验中,我们选择了冒泡排序、选择排序和快速排序三种常见的排序算法进行比较。
首先,我们编写了一个随机生成一组无序数据的函数,并将其作为排序算法的输入。
然后,分别使用冒泡排序、选择排序和快速排序对这组数据进行排序,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和排序结果的准确性。
2. 查找算法实验在查找算法实验中,我们选择了顺序查找、二分查找和哈希查找三种常见的查找算法进行比较。
首先,我们编写了一个生成有序数据的函数,并将其作为查找算法的输入。
然后,分别使用顺序查找、二分查找和哈希查找对这组数据进行查找,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和查找结果的准确性。
四、实验结果1. 排序算法实验结果经过实验比较,我们发现快速排序算法在大多数情况下具有最好的性能表现,其平均时间复杂度为O(nlogn)。
冒泡排序算法虽然简单,但其时间复杂度为O(n^2),在数据量较大时效率较低。
选择排序算法的时间复杂度也为O(n^2),但相对于冒泡排序,其交换次数较少,因此效率稍高。
2. 查找算法实验结果顺序查找算法是最简单的一种查找算法,其时间复杂度为O(n),适用于小规模数据的查找。
二分查找算法的时间复杂度为O(logn),适用于有序数据的查找。
河南工业大学《大学计算机基础及office应用》实验报告专业班级:学号:姓名:实验单元二Excel的操作及应用实验四Excel工作表的基本操作和格式化实验时间:【实验目的】1、熟练掌握各种数据类型的输入方法。
2、对表格进行格式化编辑。
【实验环境】安装了Windows 7操作系统和Office 2010应用软件的PC机。
【实验内容】按照教材209页的“实训项目4_1 商品销售报表”的要求完成相应操作。
【实验步骤】(此项由学生自己参照教材210页实训步骤完成。
)【实验结果】(以截图的方法呈现,参照教材210页图4-98。
将制作好的电子表格保存下来,实验五和实验六继续要使用。
)【实验体会】(至少150字,写出实验遇到问题及其解决方案和收获。
)实验五Excel数据管理实验时间:【实验目的】1、熟练使用填充工具对数据进行完善。
2、熟练使用公式或者函数完成数据管理。
3、掌握对数据的排序、筛选和分类汇总。
【实验环境】安装了Windows 7操作系统和Office 2010应用软件的PC机。
【实验内容】在实验四操作结果的基础上按照教材211页的“实训项目4_2 数据管理”的要求完成相应操作。
【实验步骤】(此项由学生自己完成)【实验结果】(以截图的方法呈现,将制作好的电子表格保存下来,实验六继续要使用。
)【实验体会】(至少150字)实验六Excel创建图表实验时间:【实验目的】掌握为表格数据创建图表的方法。
【实验环境】安装了Windows 7操作系统和Office 2010应用软件的PC机。
【实验内容】在实验四操作结果的基础上按照教材213页的“实训项目4_3 创建图表”的要求完成相应操作。
【实验步骤】(此项由学生自己完成)【实验结果】(以截图的方法呈现)【实验体会】(至少150字)。
河南工业大学实验报告(2014~2015学年-第1学期)一、实验目的:1. 了解结构化程序设计的基本思想;2. 掌握使用工程组织多个程序文件的方法。
3. 掌握函数嵌套的使用方法。
4.掌握递归函数的编程方法。
二.编程环境Windows8.1Codeblock三.实验要求及内容:1.编写一个函数,利用参数传入一个3位数number,找出101~number 之间所有满足下列两个条件的数:它是完全平方数,又有两位数字相同,如144、676等,函数返回找出这样的数据的个数,并编写主函数。
输入输出示例:Enter a number :150 count = 2①源代码②测试用例Enter a number :150Count = 2;③实验结果2. 用递归函数计算x n的值。
输入输出示例:Enter x:2Enter n:3Root = 8.00①源代码②测试用例Enter x:2Enter n:3Root = 8.00③实验结果3. 用递归方法编写求斐波那契数列项的函数,返回值为整型,并写出相应的主函数。
斐波那契数列的定义为:f(0)= 0,f(1)=1)+ f(n-1)(n>1)①源代码②实验用例输入10输出55③实验结果如下图4. 输入两个整数m和n(m≥0且n≥0),输出函数Ack(m,n)的值。
Ack(0,n)= n+1Ack(m,0)= Ack(m-1,1)Ack(m,n)= Ack(m-1,Ack(m,n-1))(m>0且n>0)输入输出示例:Enter x:2Enter y:3Ackerman(2,3)= 9①源代码如下图②测试用例输入x : 2输入y: 3输出Ackerman (2,3) = 9③实验结果如下图5*(选做):输入一个正整数n,将其转换为二进制后输出。
要求定义并调用函数dectobin(n),它的功能是输出n的二进制。
例如,调用dectobin(10),①源代码②测试用例输入20输出10100③实验结果如下图6. 输入n(n<10)个整数,统计其中素数的个数。
一、实验目的本次实验旨在通过实际操作,加深对排序和查找算法的理解,掌握几种常见的排序和查找方法,提高编程能力,并了解它们在实际应用中的优缺点。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 排序算法(1)冒泡排序冒泡排序是一种简单的排序算法,基本思想是通过相邻元素的比较和交换,逐步将较大的元素移动到序列的后面,较小的元素移动到序列的前面,直到整个序列有序。
(2)选择排序选择排序是一种简单直观的排序算法,基本思想是遍历整个序列,每次从剩余未排序的元素中找到最小(或最大)的元素,将其与未排序序列的第一个元素交换,然后继续在剩余未排序的元素中寻找最小(或最大)的元素。
(3)插入排序插入排序是一种简单直观的排序算法,基本思想是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序是一种效率较高的排序算法,基本思想是选取一个基准值,将待排序序列分为两个子序列,一个子序列中所有元素都比基准值小,另一个子序列中所有元素都比基准值大,然后递归地对两个子序列进行快速排序。
2. 查找算法(1)顺序查找顺序查找是一种最简单的查找算法,基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若相等,则查找成功;若线性表中所有元素都与要查找的元素不相等,则查找失败。
(2)二分查找二分查找是一种效率较高的查找算法,基本思想是对于有序的线性表,通过将待查找元素与线性表中间的元素进行比较,逐步缩小查找范围,直到找到目标元素或查找失败。
四、实验结果与分析1. 排序算法分析(1)冒泡排序:时间复杂度为O(n^2),空间复杂度为O(1),稳定排序。
(2)选择排序:时间复杂度为O(n^2),空间复杂度为O(1),不稳定排序。
(3)插入排序:时间复杂度为O(n^2),空间复杂度为O(1),稳定排序。
查找和排序实验报告查找和排序实验报告一、引言查找和排序是计算机科学中非常重要的基础算法。
在实际应用中,我们经常需要在大量数据中查找特定的值,或者按照一定的规则对数据进行排序。
因此,研究和优化查找和排序算法对于提高计算机程序的效率具有重要意义。
本实验旨在通过对比不同的查找和排序算法的性能,探究它们的优缺点以及适用场景。
二、查找算法查找算法是指在给定的数据集合中寻找特定值的过程。
常见的查找算法有线性查找、二分查找和哈希查找。
1. 线性查找线性查找是最简单直观的查找算法,它从数据集合的第一个元素开始逐个比较,直到找到目标值或者遍历完整个数据集合。
线性查找的时间复杂度为O(n),其中n为数据集合的大小。
线性查找适用于小型数据集合或者数据无序的情况。
2. 二分查找二分查找是一种高效的查找算法,它要求数据集合必须有序。
二分查找的基本思想是将数据集合分成两部分,通过比较目标值与中间值的大小关系来确定目标值在哪一部分中,然后再在该部分中继续进行二分查找。
二分查找的时间复杂度为O(log n),其中n为数据集合的大小。
二分查找适用于大型有序数据集合。
3. 哈希查找哈希查找是一种基于哈希表的查找算法,它通过将目标值映射到哈希表中的位置来快速定位目标值。
哈希查找的时间复杂度为O(1),但需要额外的空间来存储哈希表。
哈希查找适用于大型数据集合且目标值的分布较为均匀的情况。
三、排序算法排序算法是指将一组数据按照一定的规则进行重新排列的过程。
常见的排序算法有冒泡排序、插入排序、选择排序、快速排序和归并排序。
1. 冒泡排序冒泡排序是一种简单直观的排序算法,它通过多次比较和交换相邻元素的方式将最大(或最小)的元素逐步“冒泡”到数据集合的一端。
冒泡排序的时间复杂度为O(n^2),其中n为数据集合的大小。
冒泡排序适用于小型数据集合或者数据基本有序的情况。
2. 插入排序插入排序是一种稳定的排序算法,它通过将数据集合分为已排序和未排序两部分,每次从未排序部分中选择一个元素插入到已排序部分的正确位置上。
河南工业大学实验报告
课程数据库系统原理及应用 _
实验名称实验九查询优化
院系____信息科学与工程学院____ 专业班级__ 计科1201班 _________
姓名________伍志强__ 学号_____201216010506 _
指导老师:孙宜贵日期 2014年12月5日
一.实验目的
1.了解数据库查询优化方法和查询计划的概念。
2.了解语句优化,了解常见的修改SQL语句来降低查询代价的方法。
二.实验内容及要求
阅读本实验的参考资料,并在网上搜集SQL SERVER优化的相关内容,选择自己感兴趣的内容进行实验并记录,最后谈谈相关感受。
三.实验过程及结果(含源代码)
由数据分析可得,union的用时要比or的用时要长,而且扫描的次数要多,因此union的执行效率要比or的执行效率要低。
四.实验中的问题及心得
通过这次实验,一个列的标签同时在主查询和WHERE子句中的查询中出现,那么很可能当主查询中的列值改变之后,子查询必须重新查询一次。
查询嵌套层次越多,效率越低,因此应当尽量避免子查询。
如果子查询不可避免,那么要在子查询中过滤掉尽可能多的行。
当然还有更多优化的sql语句的方法,我了解到了不同的查询方式,所需要的执行时间的差别,虽然现在只是几毫秒的差别的,但是对于计算机的执行速度来说,已经算大的了,而且依次长久下去,计算机的执行速度将越来越慢,由此可以看出查询优化的重要性。
xxx大学实验报告课程名称数据结构实验项目实验三查找和排序(一)——查找院系信息学院计类系专业班级计类1501姓名学号指导老师日期批改日期成绩一实验目的1.掌握哈希函数——除留余数法的应用;2. 掌握哈希表的建立;3. 掌握冲突的解决方法;4. 掌握哈希查找算法的实现。
二实验内容及要求实验内容:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79),哈希函数定义为:H(key)=key MOD 13, 哈希表长为m=16。
实现该哈希表的散列,并计算平均查找长度(设每个记录的查找概率相等)。
实验要求:1. 哈希表定义为定长的数组结构;2. 使用线性探测再散列或链地址法解决冲突;3. 散列完成后在屏幕上输出数组内容或链表;4. 输出等概率查找下的平均查找长度;5. 完成散列后,输入关键字完成查找操作,要分别测试查找成功与不成功两种情况。
注意:不同解决冲突的方法会使得平均查找长度不同,可尝试使用不同解决冲突的办法,比较平均查找长度。
(根据完成情况自选,但至少能使用一种方法解决冲突)三实验过程及运行结果#include <stdio.h>#include <stdlib.h>#include <string.h>#define hashsize 16#define q 13int sign=2;typedef struct Hash{int date; //值域int sign; //标记}HashNode;void compare(HashNode H[],int p,int i,int key[]) //线性冲突处理{p++;if(H[p].sign!=0){sign++;compare(H,p,i,key);}else{H[p].date=key[i];H[p].sign=sign;sign=2;}}void Hashlist(HashNode H[],int key[]){int p;for(int i=0;i<12;i++){p=key[i]%q;if(H[p].sign==0){H[p].date=key[i];H[p].sign=1;}elsecompare(H,p,i,key);}}int judge(HashNode H[],int num,int n) //查找冲突处理{n++;if(n>=hashsize) return 0;if(H[n].date==num){printf("位置\t 数据\n");printf("%d\t %d\n\n",n,H[n].date);return 1;}elsejudge(H,num,n);}int search(char num,HashNode H[]) //查找{int n;n= num % q;if(H[n].sign==0){printf("失败");return 0;}if(H[n].sign!=0&&H[n].date==num){printf("位置\t 数据\n");printf("%d\t %d\n\n",n,H[n].date);}else if(H[n].sign!=0&&H[n].date!=num){if(judge(H,num,n)==0) return 0;}return 1;}int main(void){int key[q]={19,14,23,1,68,20,84,27,55,11,10,79};float a=0;HashNode H[hashsize];for(int i=0;i<hashsize;i++)H[i].sign=0;Hashlist(H,key);printf("位置\t 数据\n\n");for(int i=0;i<hashsize;i++){if(H[i].sign!=0){printf("%d\t %d\n",i,H[i].date);}else{H[i].date=0;printf("%d\t %d\n",i,H[i].date);}}int num;printf("请输入查找数值(‘-1’查找完成):\n");for(int i=0;;i++){scanf("%d",&num);if(num==-1)break;if(search(num,H)==0)printf("不存在\n");}for(int i=0;i<hashsize;i++){printf("%d ",H[i].sign);a=a+H[i].sign;}printf("\n%2.0f",a);printf("平均查找长度:%0.2f\n",a/12);return 0;}四调试情况、设计技巧及体会首先得确定哈希函数,虽然冲突是无法避免的,但是我们应该选择合适的函数,减少冲突,最简单的可以采用开放定止法,出现冲突后,以原地址为基点再次寻找下一个地址。
河南工业大学实验报告
课程名称数据结构实验项目实验三查找和排序(二)——排序院系信息学院计科系专业班级计科1203 姓名张伟龙学号 201216010313 指导老师范艳峰日期 2013.6.5 批改日期成绩
一实验目的
掌握希尔排序、快速排序、堆排序的算法实现。
二实验内容及要求
实验内容:1.实现希尔排序。
2.实现快速排序。
3. 实现堆排序。
(三选一)
实验要求:1. 根据所选题目,用C语言编写程序源代码。
2. 源程序必须编译调试成功,独立完成。
三实验过程及运行结果
选择第三题:
Source Code:
#include <iostream>
#include<algorithm>
using namespace std;
void HeapAdjust(int *a,int i,int size) //调整堆
{
int lchild=2*i; //i的左孩子节点序号
int rchild=2*i+1; //i的右孩子节点序号
int max=i; //临时变量
if(i<=size/2) //如果i是叶节点就不用进行调整
{
if(lchild<=size&&a[lchild]>a[max])
{
max=lchild;
}
if(rchild<=size&&a[rchild]>a[max])
{
max=rchild;
}
if(max!=i)
{
swap(a[i],a[max]);
HeapAdjust(a,max,size); //避免调整之后以max为父节点的子树不是堆
}
}
}
void BuildHeap(int *a,int size) //建立堆
{
int i;
for(i=size/2;i>=1;i--) //非叶节点最大序号值为size/2
{
HeapAdjust(a,i,size);
}
}
void HeapSort(int *a,int size) //堆排序
{
int i;
BuildHeap(a,size);
for(i=size;i>=1;i--)
{
swap(a[1],a[i]); //交换堆顶和最后一个元素,即每次将剩余元素中的最大者放到最后面
HeapAdjust(a,1,i-1); //重新调整堆顶节点成为大顶堆
}
}
int main()
{
int a[100];
int size;
while(scanf("%d",&size)==1,size)
{
int i;
for(i=1;i<=size;i++)
cin>>a[i];
HeapSort(a,size);
for(i=1;i<=size;i++)
cout<<a[i]<<" ";
cout<<endl;
}
return 0;
}
四调试情况、设计技巧及体会
调试情况:主要是在多次调整使得数据保持堆这种结构上的操作,花费了不少时间
设计技巧:运用了堆的这种特殊的数据结构,使得在能够在O(nlogn)的时间复杂度内完成排序操作。
调整堆运用了递归算法,简化了程序。
体会:通过写Heapsort的程序,又学会了一种sort。
而且这种sort特别适用于大文件的排序上。
通过这次编程,又巩固了对递归算法的运用。