Greenplum数据仓库技术架构介绍
- 格式:pptx
- 大小:634.63 KB
- 文档页数:15


⼏款分布式数据库的对⽐1 概述随着海量数据问题的出现,海量管理能⼒,多类型,变化快,⾼可⽤性,低成本,⾼端可扩展性等需求给企业数据战略带来了巨⼤的挑战。
企业数据仓库、数据中⼼的技术选型变得尤其重要!所以在选型之前,有必要对⽬前市场上各种⼤数据量的解决⽅案进⾏分析。
2 主流分布式并⾏处理数据库产品介绍2.1 Greenplum 2.1.1 基础架构Greenplum 是基于Hadoop 的⼀款分布式数据库产品,在处理海量数据⽅⾯相⽐传统数据库有着较⼤的优势。
Greenplum 整体架构如下图:数据库由Master Severs 和Segment Severs 通过Interconnect 互联组成。
Master 主机负责:建⽴与客户端的连接和管理;SQL 的解析并形成执⾏计划;执⾏计划向Segment 的分发收集Segment 的执⾏结果;Master 不存储业务数据,只存储数据字典。
Segment 主机负责:业务数据的存储和存取;⽤户查询SQL 的执⾏。
2.1.2 主要特性Greenplum 整体有如下技术特点: Shared-nothing 架构Network Interconnect...Master Severs 查询解析、优化、分发Segment Severs 查询处理、数据存储ExternalSources 数据加载海量数据库采⽤最易于扩展的Shared-nothing架构,每个节点都有⾃⼰的操作系统、数据库、硬件资源,节点之间通过⽹络来通信。
◆基于gNet Software Interconnect数据库的内部通信通过基于超级计算的―软件Switch‖内部连接层,基于通⽤的gNet (GigE,10GigE) NICs/switches在节点间传递消息和数据,采⽤⾼扩展协议,⽀持扩展到1000个以上节点。
◆并⾏加载技术利⽤并⾏数据流引擎,数据加载完全并⾏,加载数据可达到4。
5T/⼩时(理想配置)。

gpdb原理GPDB(Greenplum Database)是一个基于PostgreSQL 开发,面向大型数据仓库和分析的高度并行化数据库管理系统。
GPDB的核心特性是可伸缩性、高性能和可靠性,适用于OLAP场景下的海量数据处理。
从技术架构来看,GPDB的设计思路是将一个大数据仓库拆分成多个子数据集,并将每个数据集分配到不同的计算节点上进行处理。
这种方式可以有效地提高数据的并行处理能力和整体性能,同时也可以更好地支持更高的数据容量和更广泛的计算任务。
在GPDB中,每个数据集都被称为“分布式表”,它们由一组相互协作的计算节点组成,每个节点负责处理其中的一部分数据。
同时,GPDB还支持数据分区(Partitioning),它可以将每个表的数据按照特定的规则划分到不同的节点上,以进一步提高计算效率。
GPDB的核心是“分布式查询处理器”(QP,Query Processor),它负责接收用户的SQL查询请求,将其转换为分布式任务并提交到相应的计算节点上进行处理。
QP基于PostgreSQL的执行引擎进行扩展,支持分布式查询规划和优化、数据划分和转移等功能。
在执行查询时,QP会将查询计划分配给不同的节点,每个节点处理自己分配到的数据,之后将结果返回给QP进行汇总。
GPDB还支持一种称为“MPP”(Massively Parallel Processing)的并行计算模式,它可以将一个查询拆分成多个子查询,并将每个子查询并发执行于不同的计算节点上。
每个节点都可以自主选择并行执行的任务,以提高整个查询的性能和可伸缩性。
MPP可以直接对接Hadoop生态,收集Hadoop集群中的数据进行复杂查询。
在GPDB中,数据的安全性和可靠性也得到了高度重视。
系统支持数据备份和恢复、事务处理、用户权限管理等功能,以确保数据的完整性和安全性。
分布式查询执行引擎还支持许多优化策略,如查询优化、并行查询优化和索引优化等,以进一步提高查询性能和响应速度。


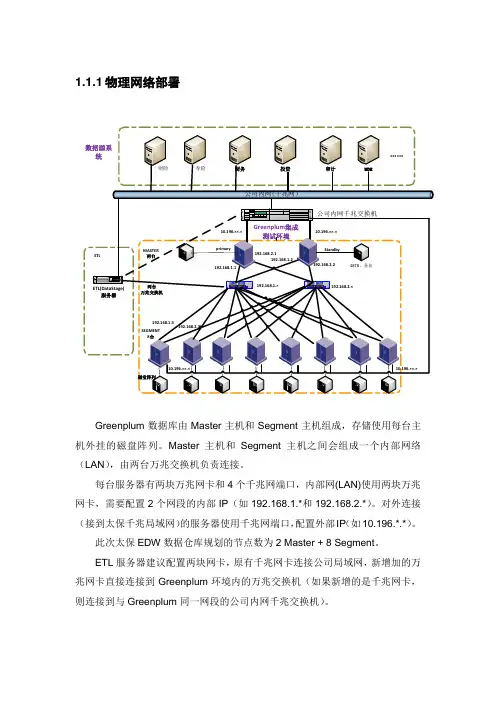
1.1.1 物理网络部署8台primary192.168.1.1192.168.2.1192.168.2.2磁盘阵列10.196.××.×10.196.××.×Greenplum数据库由Master主机和Segment主机组成,存储使用每台主机外挂的磁盘阵列。
Master主机和Segment主机之间会组成一个内部网络(LAN),由两台万兆交换机负责连接。
每台服务器有两块万兆网卡和4个千兆网端口,内部网(LAN)使用两块万兆网卡,需要配置2个网段的内部IP(如192.168.1.*和192.168.2.*)。
对外连接(接到太保千兆局域网)的服务器使用千兆网端口,配置外部IP(如10.196.*.*)。
此次太保EDW数据仓库规划的节点数为2 Master + 8 Segment。
ETL服务器建议配置两块网卡,原有千兆网卡连接公司局域网,新增加的万兆网卡直接连接到Greenplum环境内的万兆交换机(如果新增的是千兆网卡,则连接到与Greenplum同一网段的公司内网千兆交换机)。
1.1.2 存储配置EDW数据存储在每台Segment服务器的外挂磁盘阵列上,各服务器内置硬盘只存储系统文件、程序文件以及临时文件。
外置和内置磁盘都做RAID5保护。
根据容量的需求,我们建议对磁盘阵列(在做RAID5之后)进行如下划分:1)9台7.2TB(600GB*12)裸容量的HP磁盘阵列:a. 与Primary Master主机连接的1台:划分1个逻辑卷(磁盘分区),使用全部可用容量。
b. 与Segment 主机连接的8台:划分2个逻辑卷(磁盘分区),分别使用可用容量的一半。
2)1台48TB(2TB*24)的HP磁盘阵列:按照系统能够支持的最大容量来划分逻辑卷。
注意:请在上述分区安装XFS文件系统。
1.1.3 数据库实例配置每个Segment服务器上建立4个主数据库实例和4个镜像数据库实例(instance)。

greenplum集群原理
Greenplum是一种基于PostgreSQL的开源数据仓库系统,设计用于处理大规模数据集。
它使用MPP(大规模并行处理)架构,将数据分散到多个节点上,并使用这些节点进行并行查询处理,以提高查询性能。
Greenplum集群的基本原理是将数据分散到多个节点上,每个节点都有自己的存储和计算资源。
这种分布式架构允许多个节点同时处理查询,从而显著提高了大规模数据的查询性能。
在Greenplum集群中,有一个主节点(Master)和多个工作节点(Segment)。
主节点负责管理集群中的所有节点,协调查询请求并分发数据。
工作节点负责存储数据和执行查询操作。
当客户端发送查询请求时,主节点首先将查询计划分发给工作节点。
每个工作节点执行查询计划并返回结果给主节点。
主节点再将这些结果合并并返回给客户端。
Greenplum集群还具有强大的数据并行处理能力。
它将查询分成多个子任务,并将这些子任务分发给多个工作节点。
这些工作节点可以并行处理子任务,并在执行过程中自动进行数据分片和负载均衡。
这使得Greenplum集群能够高效地处理大规模数据集,提高查询性能。


2015/6/13 22:51 GP架构_1与GreenPlum类似的产品:IBM NITIZA(国内没人用)Terndata2007年被EMC收购GreenPlum国外市场:纳斯达克,skypeGreenPlum国内市场:阿里,民生银行,深发展银行,电信业(MPP架构)MPP架构:海量并行处理Massively Parallel Processingshare nothing 模式,每一个节点不进行资源共享,集群中每个节点有独立的CPU、内存、存储、总线等。
SMP架构:symmetric mass processing 对称多处理系统:耦合的多处理系统,共享总线、内存、IO资源,传统的ORCKLE,DB2是非常典型的产品ORACLE_RAC 处于半共享状态,各节点连接共享存储,所以不能算MPPGreenPlum 基于PostGreSQL8.2 之前在国内使用比较少,在国外使用广泛。
Mysql与PostGreSQL地位同等,但mysql被Oracle收购之后没落。
GreenPlum 在函数、dataloading、存储过程等继承了PostGreSQLGP增加BI和数据仓库的支持:A、外部表、并行加载(优势明显)B、资源队列管理的优化,对角色、用户、组进行资源优化分配,管理。
C、GP在查询优化器的增强、分布支持、分区表、执行计划的优化、空间回收、数据分析,简化调优,架构时对称、数据分布均匀的话,可以免去调优Master Host:访问系统的入口,所有请求都需要从Master Host访问,正常来讲,管理员也不可以直接访问SegmentHost ,系统中只允许直接访问MasterHost ,单独操作SegmentHost 影响一致性和完整性。
数据监听进程(PostGres):监听用户请求。
处理所有用户连接。
建立执行计划,通过网络层分发给SegmentHost。
协调整个处理过程,保证SegmentHost处理结果侧一致和同步。


gp基础知识
GP(Greenplum)是一个基于PostgreSQL的开源数据仓库系统,主要用于处理大规模数据分析任务。
它采用Master/Slave架构,具有两个Master节点(一个Primary节点和一个Standby节点)和多个Segment
节点,每个节点上可以运行多个数据库。
GP采用shared nothing架构(MPP),通过内存Cache存储状态的信息,而不在节点上保存状态的信息。
节点之间的信息交互都是通过节点互联网络实现,通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。
要优化GP系统,需要从全局考虑。
优化建议包括以下几个方面:
1. 硬件层:确保磁盘、主机、网络等硬件健康,OS为GP环境定制调优,
磁盘容量最大使用70%以前,每次dml操作、load数据后都要vacuum。
2. 资源的分配,并发资源竞争:通过资源队列限制gp系统里active queryes的数量,分配给指定query的资源多少,使gp系统最佳状态运行;清楚gp系统的运行负载,把后台管理放(如,data load,vacuum,backup等 )在系统负载低时运行。
3. 统计信息的准确性:确保统计信息准确,以支持查询优化器的正确决策。
4. 数据分布:合理分布数据,避免数据倾斜,以提高查询性能。
5. 数据库的设计:设计合理的数据库模式,包括表结构、索引、分区等。
6. SQL的优化:编写高效的SQL查询语句,利用查询优化器进行查询优化。
以上内容仅供参考,建议咨询数据库领域专业人士获取更准确的信息。
greenplum分区表表结构一、Greenplum分区表的特点Greenplum是一个开源的分布式关系型数据库管理系统,它支持水平分区和垂直分区。
分区表是Greenplum的一项重要特性,它将数据划分为多个分区,每个分区可以单独进行管理和查询,从而提高查询性能和数据管理的灵活性。
Greenplum分区表的特点如下:1. 提高查询性能:通过将数据划分为多个分区,可以实现并行查询,从而提高查询性能。
2. 灵活管理数据:可以根据实际需求对每个分区进行独立的管理和维护,例如备份、恢复、优化等。
3. 减少存储空间:可以根据数据的特点将其划分到不同的分区中,从而减少冗余数据的存储空间。
4. 支持数据范围查询:可以根据分区的范围进行数据查询,提高查询效率。
二、Greenplum分区表的使用场景Greenplum分区表适用于以下场景:1. 大数据量的数据存储和查询:当数据量非常大时,使用分区表可以提高查询性能,减少查询时间。
2. 数据按时间或范围划分:例如按照日期、月份、季度等将数据进行划分,可以方便地进行时间范围查询。
3. 多租户系统:当系统需要为多个租户提供服务时,可以使用分区表将数据进行划分,从而实现数据的隔离和独立管理。
三、创建Greenplum分区表的方法创建Greenplum分区表可以使用以下方法:1. 使用CREATE TABLE语句创建:可以在CREATE TABLE语句中使用PARTITION BY子句指定分区方式和列,并使用PARTITION 子句指定分区的范围。
2. 使用ALTER TABLE语句进行分区:可以使用ALTER TABLE语句的ADD PARTITION子句添加新的分区。
创建Greenplum分区表的示例代码如下:```CREATE TABLE sales (id INT,date DATE,amount NUMERIC)PARTITION BY RANGE (date)(PARTITION p1 START (DATE '2022-01-01') END (DATE '2022-03-31'),'2022-06-30'),PARTITION p3 START (DATE '2022-07-01') END (DATE '2022-09-30'),PARTITION p4 START (DATE '2022-10-01') END (DATE '2022-12-31'));```四、管理Greenplum分区表的方法管理Greenplum分区表可以使用以下方法:1. 添加新的分区:可以使用ALTER TABLE语句的ADD PARTITION子句添加新的分区。
数据仓库的基本架构数据仓库是一个用于存储和管理大量结构化和非结构化的数据的系统。
它旨在支持企业决策制定过程,提供准确、一致且易于访问的数据。
数据仓库的基本架构包括以下几个主要组件:数据源、数据抽取、数据转换、数据加载、数据存储和数据访问。
1. 数据源数据源是指数据仓库所需的原始数据的来源。
数据源可以是企业内部的各种业务系统,如销售系统、财务系统、人力资源系统等,也可以是外部数据源,如市场调研数据、社交媒体数据等。
数据源可以是关系型数据库、文件、API接口等形式。
2. 数据抽取数据抽取是指从数据源中提取数据并将其导入到数据仓库的过程。
数据抽取可以通过各种方式进行,如全量抽取、增量抽取、定时抽取等。
在数据抽取过程中,需要考虑数据的完整性、一致性和准确性。
3. 数据转换数据转换是指将从数据源中提取的数据进行清洗、整合和转换的过程。
在数据转换过程中,可以对数据进行去重、过滤、格式化、计算等操作,以确保数据的质量和一致性。
数据转换可以使用ETL(抽取、转换和加载)工具来实现。
4. 数据加载数据加载是指将经过转换的数据加载到数据仓库中的过程。
数据加载可以采用批量加载或者实时加载的方式进行。
批量加载是指将数据按批次导入到数据仓库中,适合于数据量较大的情况;实时加载是指将数据实时地导入到数据仓库中,适合于需要及时分析的场景。
5. 数据存储数据存储是指数据仓库中数据的物理存储方式。
数据存储可以采用关系型数据库、列式数据库、分布式文件系统等形式。
关系型数据库适合存储结构化数据,列式数据库适合存储大规模数据,分布式文件系统适合存储非结构化数据。
6. 数据访问数据访问是指用户通过查询和分析工具来访问数据仓库中的数据。
数据访问可以通过SQL查询、OLAP(联机分析处理)、数据挖掘等方式进行。
数据访问工具可以提供丰富的数据可视化和分析功能,匡助用户更好地理解和利用数据。
总结:数据仓库的基本架构包括数据源、数据抽取、数据转换、数据加载、数据存储和数据访问六个主要组件。
Greenplum是一个基于开源PostgreSQL的分布式数据库,采用shared-nothing架构,即主机、操作系统、内存、存储都是每台服务器独立自我控制,不存在共享。
Greenplum本质上是一个关系型数据库集群,实际上是由多个独立的数据库服务组合而成的一个逻辑数据库。
与Oracle的RAC不同,这种数据库集群采取的是MPP(Massively Parallel Processing)架构。
Greenplum最大的特点就是基于低成本的开放平台基础上提供强大的并行数据计算性能和海量数据管理能力。
这个能力主要指的是并行计算能力,是对大任务、复杂任务的快速高效计算。
Greenplum内部使用udp网络,但是Greenplum会对数据包进行校验,因此可靠性等同于TCP。
greenplum原理Greenplum是一种基于分布式架构的开源数据仓库系统,它是PostgreSQL的一个分支,用于处理大规模数据分析和处理任务。
下面是Greenplum的一些原理:1、分布式架构:Greenplum采用分布式架构,可以将数据分布在多个节点上,并通过并行处理来提高性能。
每个节点都可以独立处理查询请求,并通过分布式存储系统来协作完成数据读写操作。
2、数据分片:Greenplum支持对表进行数据分片,将数据划分为多个小的片段,然后分布在不同的节点上。
这样可以提高查询效率和并行处理能力。
数据分片可以是水平分片(将数据按照某个字段进行哈希)或垂直分片(将不同的表或列划分为不同的片段)。
3、并行查询:Greenplum支持并行查询,可以将一个查询任务划分为多个子任务,然后在多个节点上同时执行。
这样可以加速查询速度,提高系统性能。
4、数据倾斜:在Greenplum中,数据可能会在某些节点上分布不均匀,导致某些节点的负载较重,而其他节点的负载较轻。
这种现象称为数据倾斜。
为了解决这个问题,Greenplum支持动态负载均衡,可以自动检测负载不均衡的情况,并将数据重新分配到负载较轻的节点上。
5、数据复制:Greenplum支持数据复制,可以将数据在多个节点上进行备份,以提高数据的可用性和容错性。
当一个节点发生故障时,系统可以自动切换到其他可用的节点上继续执行查询任务。
6、数据压缩:Greenplum支持对数据进行压缩,以减少存储空间和提高读写性能。
常见的压缩算法包括Run-length Encoding(RLE)和Delta Encoding(Delta)。
总的来说,Greenplum通过分布式架构、数据分片、并行查询、动态负载均衡、数据复制和数据压缩等技术,实现了高性能、高可用性和可扩展性的数据仓库系统。
GreenPlum数据库简介及应用GreenPlum数据库是一种高性能、可扩展的关系型数据库管理系统(DBMS),特别适用于大数据分析和处理。
它是由Pivotal Software公司开发的,其核心功能是基于PostgreSQL构建的。
GreenPlum数据库具有强大的并行处理能力,可以在大规模数据集上执行快速且复杂的查询。
它通过分布式存储和计算来实现高度的并行化处理,充分利用集群中的每个节点的计算和存储资源。
这使得GreenPlum数据库能够处理大规模数据集,并且具有水平扩展性,可以根据需要添加更多的节点来增加处理能力。
此外,GreenPlum数据库支持多维数据模型,可用于大型数据仓库和分析应用。
它提供了丰富的数据分区、索引和优化功能,以及用于数据切片、压缩和并行加载的工具。
它还具有高度可定制化的架构,并支持多种数据操作语言和工具,如SQL、Python和R等。
GreenPlum数据库的应用范围广泛,适用于各种行业和领域。
例如,在金融领域,它可用于大规模的数据分析和风险管理;在零售业,可以用于销售数据分析和市场营销策略;在医疗保健行业,可用于大数据分析和患者管理等。
GreenPlum数据库的优势还包括可靠性和容错性。
它支持数据复制和备份,以确保数据的安全性和可恢复性。
此外,它还提供了数据安全和权限控制功能,以保护敏感信息和遵守合规性要求。
总之,GreenPlum数据库是一个功能强大的工具,可帮助组织处理和分析大规模的数据。
它的高性能、可扩展性和丰富的功能使得它成为大数据分析和处理的理想选择。
无论是企业还是研究机构,GreenPlum数据库都能提供高效、可靠和安全的数据管理解决方案。
概述随着海量数据问题的出现,海量管理能力,多类型,变化快,高可用性,低成本,高端可扩展性等需求给企业数据战略带来了巨大的挑战。
企业数据仓库、数据中心的技术选型变得尤其重要!所以在选型之前,有必要对目前市场上各种大数据量的解决方案进行分析。
主流分布式并行处理数据库产品介绍1.1 Greenplum 1.1.1 基础架构Greenplum 是基于Hadoop 的一款分布式数据库产品,在处理海量数据方面相比传统数据库有着较大的优势。
Greenplum 整体架构如下图:数据库由Master Severs 和Segment Severs 通过Interconnect 互联组成。
Master 主机负责:建立与客户端的连接和管理;SQL 的解析并形成执行计划;执行计划向Segment 的分发收集Segment 的执行结果;Master 不存储业务数据,只存储数据字典。
Segment 主机负责:业务数据的存储和存取;用户查询SQL 的执行。
1.1.2 主要特性Greenplum 整体有如下技术特点: Shared-nothing 架构Network Interconnect... Master Severs 查询解析、优化、分发Segment Severs 查询处理、数据存储 External Sources 数据加载海量数据库采用最易于扩展的Shared-nothing架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
◆基于gNet Software Interconnect数据库的内部通信通过基于超级计算的“软件Switch”内部连接层,基于通用的gNet (GigE,10GigE) NICs/switches在节点间传递消息和数据,采用高扩展协议,支持扩展到1000个以上节点。
◆并行加载技术利用并行数据流引擎,数据加载完全并行,加载数据可达到4。
5T/小时(理想配置)。
并且可以直接通过SQL语句对外部表进行操作◆支持行、列压缩存储技术海量数据库支持ZLIB和QUICKLZ方式的压缩,压缩比可到10:1。