实验一 spss入门
- 格式:doc
- 大小:1.52 MB
- 文档页数:17

《SPSS 及在医学中的应用》实验指导书任课教师:谭建军应用专业:生物技术专业实验学时:32实验一认识SPSS一、实验目的通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,对SPSS 有一个浅层次的综合认识。
要求掌握SPSS的基本运行程序,了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。
二、实验性质基础三、主要仪器及试材计算机及SPSS软件四、实验内容[1]打开SPSS的基本方法;[2]打开文件、保存文件;[3]认识各种窗口类型;[4]练习系统参数设置;[5]录入数据;[6]保存数据文件;[7]编辑数据文件;五、实验学时10学时六、实验方法与步骤[1]找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS;[2]认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语句编辑窗;[3]练习系统参数设置;[4]认识SPSS数据编辑窗;[5]按要求录入数据;[6]联系基本的数据修改编辑方法;[7]保存数据文件。
七、实验注意事项遇到各种难以处理的问题,请询问指导老师。
八、上机作业试录入以下数据文件,并按要求进行变量定义。
数据:要求:(a) 变量名同表格名,以“()”内的内容作为变量标签。
对性别(Sex)设值标签“男=0;女=1”。
(b) 正确设定变量类型。
其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
(c) 变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
实验二数据文件的整理一、实验目的通过本次实验,掌握数据文件的基本整理技巧。
二、实验性质基础三、主要仪器及试材计算机及SPSS软件四、实验内容[1]排序[2]文件拆分与合并[3]重编码[4]计算产生新变量[5]缺失值的处理五、实验学时10学时六、实验方法与步骤[1]找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS;[2]打开一个已经存在的数据文件;[3]按要求完成上机作业;[4]关闭SPSS。
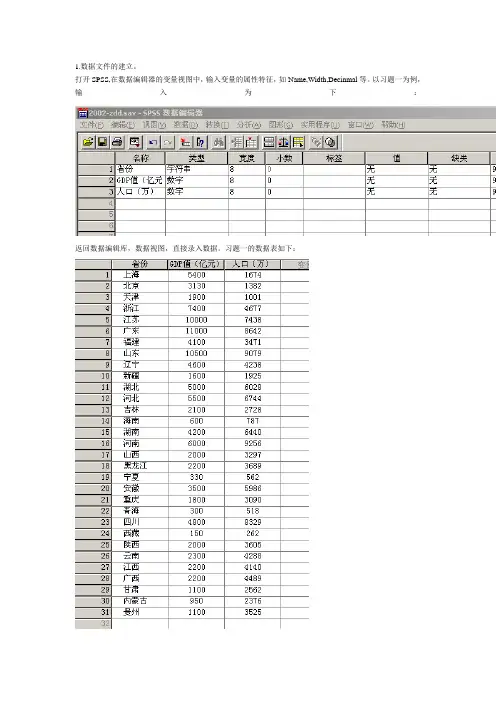
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。

实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。

实验⼀SPSS的基本操作及数据处理1.实验⼀:SPSS的基本操作及数据处理内容:1、收集到以下关于两种减肥产品使⽤情况的调查数据,请问在SPSS 中应如何组织该份资料?2、为研究某地区住户的家庭住房条件和购房意向,进⾏问卷调查。
调查内容包括被调查者的性别、职业、年龄、家庭的⽉收⼊、常住⼈⼝数、现住房⾯积、购房意向等问题。
现调查了2000⼈,得到2000分问卷数据。
(数据⽂件:"住房状况调查.sav")(1)定位到个案号码为122的个案,并将该个案删除。
(2)定位到年龄为32的个案,并插⼊⼀条个案。
(3)选择A1变量,并将其删除。
(4)添加⼀个新的变量。
3、现有两个SPSS数据⽂件,分别为"学⽣成绩⼀.sav"和"学⽣成绩⼆.sav",分布存放了学⽣学号、性别和若⼲课程成绩的数据。
请将着两份数据⽂件以学号为关键变量进⾏横向合并,形成⼀个完整的数据⽂件。
4、针对当前⼤学⽣所关⼼的社会热点问题,以⼩组形式设计⼀份调查问卷并进⾏调查。
试在SPSS中录⼊所获得的调查数据⽣成SPSS数据⽂件。
5、利⽤住房状况调查数据(数据见“住房状况调查.sav”)(1)通过数据排序功能分析本市户⼝和外地户⼝家庭的住房⾯积情况。
(2)分析被调查家庭中有多少⽐例的家庭对⽬前的住房满意且近⼏年不准备购买住房。
(3)分析本市户⼝家庭和外地户⼝家庭⽬前⼈均住房⾯积的平均值是否有较⼤差距,未来计算购买住房的平均⾯积是否有较⼤差距。
(4)分析被调查家庭的⼈均住房⾯积的分布特征。
6、利⽤职⼯问卷调查数据(数据见”职⼯数据.sav”),依据职称级别计算实发⼯作,计算规则是:实发⼯资等于基本⼯资减去失业保险,之后,依据职称1-4登记分别将以上计算结果上浮5%,3%,2%,1%。
7、收集到某菜市场某天若⼲蔬菜的销售单价和销售量的数据,见数据⽂件“蔬菜销售.sav”,现希望计算该菜市场该天蔬菜销售的平均价格。

SPSS第一次作业一实验目的1、掌握均值比较,用于计算指定变量的综合描述统计量,2、掌握单样本T检验(One-Sample T Test),检验单个变量的均值与假设之间是否存在差异;3、掌握独立样本T检验(Independent-Samples Test),用于检验两组来自独立总体的样本,企图理综题的均值或中心位置是否一样4、掌握配对样本T检验(Paired-Samples Test),用于检验两个相关的样本是否来自具有相同均值的总体。
二、实验内容1、题目:某康体中心的减肥班学员入班时的体重数据和减肥训练一个月后的体重数据记录在数据文件data08-06中,试分析一个月的训练是否有效。
如果按性别分组分析结果又如何?如果按体重等级分组检查训练结果,结果会是怎样的?(此问题满足配对样本T检验(Paired-Samples T Test)的条件,因此用配对样本T检验来解决此问题。
)1.1问题:分析一个月的训练是否有效。
1)实验步骤:第1步数据组织;打开SPSS数据文件data08-06。
第2步打开主对话框;选择Analyse→Compare Means →Paired-Samples T Test ,打开同下图样的配对样本T检验主对话框。
2)运行结果:a)配对样本统计量Paired Samples Statistics表1.1.1b)配对样本相关关系Paired Samples Correlations表1.1.2c)配对样本T检验结果Paired Samples Test表1.1.33)结果分析:表1.1.1是对训练前后体重的单变量描述统计量,表中显示的事配对变量的变量标签,对数为1对。
Means给出训练前后的体重均值,分别为71.255与68.912。
N即观测量数目训练前后均为51。
Std.Deviation训练前后的标准差,分别为7.0989和7.2289Std.Deviation训练前后的均值标准误,分别为0.9940和1.0122 表1.1.2中给出训练前后体重之间的相关系数,Correlation为0.951,不相关的概率为0.000。

实验一 SPSS基本操作
一、实验目的
通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,对SPSS有一个浅层次的综合认识。
二、实验性质
必修,基础层次
三、主要仪器及试材
计算机及SPSS软件
四、实验内容
1.操作SPSS的基本方法
2.打开文件、保存文件
3.认识各种窗口类型
4.练习系统参数设置
五、实验学时
2学时
六、实验方法与步骤
1.开机
2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS
3.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语
句编辑窗
4.练习系统参数设置
5.关闭SPSS,关机
七、实验注意事项
1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。
2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员
同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
5.上机时间,禁止使用计算机从事与课程无关的工作。
八、上机作业
1.学习掌握spss打开与关闭的各种方法以及各种spss文件类型的打开与保存方法。
2.打开spss5种类型的窗口,认识窗口特征及其功能。
3.熟悉spss系统参数设置的影响,了解spss系统参数设置的基本方法。
4.任选一个菜单中的命令,试用Help获得英文帮助,熟悉获得帮助的操作。
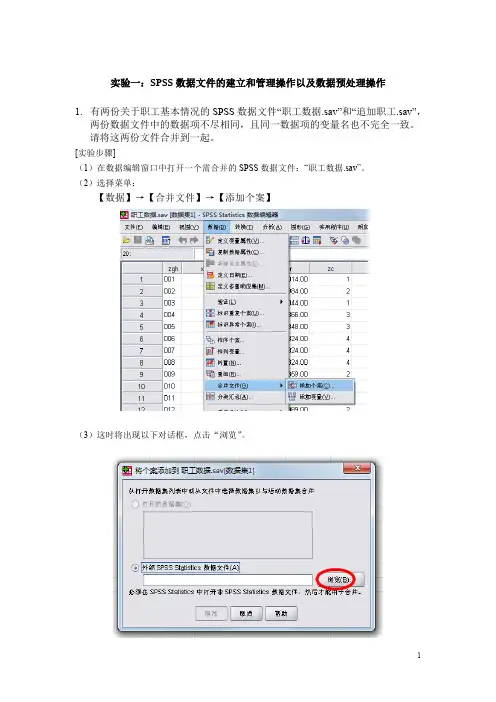
实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。

(完整)SPSS实验指导手册(定稿)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整)SPSS实验指导手册(定稿))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整)SPSS实验指导手册(定稿)的全部内容。
实验一 SPSS的数据管理[目的要求]熟悉SPSS的菜单和窗口界面及SPSS的数据管理功能.[实验内容][实验步骤][实验结果]实验二描述性统计分析[目的要求]利用SPSS进行描述性统计分析。
[实验内容][实验步骤]1、定义变量,建立数据文件并输入数据.2、选择菜单“Analyze→Descriptive Statistics→Frequencies”,选择分析变量,要输出的统计量以及要绘制的统计图,即完成了频数分析.3、在1的基础上,选择菜单“Analyze→Descriptive Statistics→Descriptives",选择分析变量即完成了描述性分析。
4、在1的基础上,选择菜单“Analyze→Descriptive Statistics→Explore",选择Dependent变量和Factor变量,要输出的统计量以及要绘制的统计图,即完成了探索分析.5、在1的基础上,首先对频数变量的值进行加权处理,再选择菜单“Analyze→DescriptiveStatistics→Crosstabs",选择分组变量和分析变量,然后选择卡方检验,定义列联表单元格中需要计算的指标,即完成了交叉列联表分析。
实验三均值检验[目的要求]利用SPSS进行单样本、两独立样本以及成对样本的均值检验。

一、数据文件的建立
变量名:学号、姓名、性别、籍贯、民族、数学、语文、英语、综合
【备注】性别:男=1,女=2;籍贯:西部=1,非西部=0;民族:汉族=1,少数民族=2
录入15个记录,信息自定。
二、根据以上文件,完成下列操作
1、按数学成绩降序排序
2、计算不同性别学生的英语平均成绩
3、计算文化课成绩(文化课成绩=数学+语文+英语+综合),升序排序
4、建立新的变量集:(1)基本信息(2)各科成绩
5、用分数段将综合成绩重新赋值,保持其他原有记录
6、选取文化课成绩≥400,籍贯为西部的少数民族学生的记录
实验报告的填写
课程名称、专业班级、学号、实验地点、指导教师
1、实验名称:SPSS软件的基本操作
2、实验目的:掌握相关软件的基本操作,了解软件自带的排序、分类汇总、变量重新赋值、筛选等功能
3、实验内容
4、实验步骤:2+3+6。

实验一 SPSS基本操作
【实验目的】
1、熟悉SPSS的安装、启动方法、SPSS的操作界面;
2、掌握数据的输入、导入方法,变量的定义;
3、掌握数据的排序、重新编码(分组)的方法、计算等功能;
4、掌握数据的选取方法
【实验内容】
1、将EXCEL格式的“学生成绩”数据,通过直接打开、数据库查询方式两种
方式建立SPSS格式的数据;
2、对各个变量进行说明(变量标签),对major变量建立值标签,调整stat、math
变量的小数位为0;
3、按照stat变量进行两种排序(升序),一种是按照排序变量的值大小,重新得
到排序后的名单;一种不改变原来名单的顺序;写出分数最高的5人和分数最低的5人;
4、分别用Count(计数)、Recode(重新编码)和可视离散化三种方式按照stat
成绩将学生分为60分以下、60-70分、70-80分、80-90分、90分以上5组(分组后的数据定义为gstat变量,并给出合适的变量标签,每组给出值标签);
5、计算每位学生stat和math分数的简单平均值;
6、从所有学生中选出统计学成绩和数学成绩都及格的同学;
7、从所有学生中随机抽取20%的学生。

SPSS实验指导书SPSS统计分析软件概述SPSS(Statistical Package for the Social Science)社会科学统计软件包;SPSS(Statistical Product and Service Solutions)统计产品与服务解决方案。
20世纪60年代末,美国斯坦福大学的三位研究生研制开发了最早的统计分析软件SPSS,并于1975年在芝加哥成立了研发和经营SPSS软件的SPSS公司。
随着微型计算机和操作系统的发展,SPSS公司相继推出了17个版本。
SPSS使用基础(安装和启动略)SPSS有两个基本窗口,分别是数据编辑窗口(Data Editor)和结果输出窗口(Viewer)。
数据编辑窗口(Data Editor)是SPSS的主程序窗口,在软件启动时自动打开,直到退出。
运行时只能打开一个数据编辑窗口,关闭该窗口意味着退出。
该窗口的主要功能:定义SPSS数据的结构、录入编辑和管理待分析的数据。
SPSS的所有统计分析功能都是针对该窗口中的数据的。
这些数据通常以SPSS数据文件的形式保存在计算机磁盘上,其文件扩展名为.sav。
数据编辑窗口由窗口主菜单、工具栏、数据编辑区、系统状态显示区组成。
1、窗口主菜单窗口主菜单将SPSS常用的数据编辑、加工和分析的功能列了出来。
2、工具栏将一些常用的功能以图形按钮的形式组织在工具栏,使操作更加快捷和方便。
3、数据编辑区显示和管理SPSS数据结构和数据内容的区域。
(数据视图和变量视图)4、系统状态显示区显示系统的当前运行状态。
SPSS结果输出窗口(Viewer)该窗口的主要功能是显示管理SPSS统计分析结果、报表及图形,允许同时创建或打开多个输出窗口。
SPSS统计分析的所有输出结果都显示在该窗口中。
输出结果通常以SPSS输出文件的形式保存在计算机的磁盘上,其文件扩展名为.spo。
SPSS的数据编辑窗口是专门负责输入和管理待分析数据的,而输出窗口则负责接收和管理统计分析的结果。
在SPSS 中进行实验一的基本统计方法包括描述统计和推论统计两个方面。
描述统计用于对实验数据的整体特征进行描述,而推论统计则用于对样本数据进行推断,从而得出总体的结论。
以下是在SPSS 中进行实验一时常用的基本统计方法:描述统计:1. 均值(Mean):计算数据的平均值,反映数据的集中趋势。
2. 标准差(Standard Deviation):衡量数据的离散程度。
3. 频数统计(Frequencies):统计分类变量的频数分布。
4. 中位数(Median):数据的中间值,不受极端值影响。
5. 最大最小值(Minimum, Maximum):显示数据的最大值和最小值。
6. 百分位数(Percentiles):显示数据的分位数,如四分位数等。
推论统计:1. 相关分析(Correlation):分析两个连续变量之间的关系。
2. t检验(Independent Samples T-Test, Paired Samples T-Test):比较两组样本均值是否存在显著差异。
3. 方差分析(ANOVA):比较两个或多个组之间均值是否存在显著差异。
4. 卡方检验(Chi-Square Test):用于比较分类变量之间的关联性。
5. 线性回归(Linear Regression):分析自变量和因变量之间的线性关系。
6. 非参数检验(Mann-Whitney U Test, Kruskal-Wallis Test):适用于非正态分布数据或秩次数据的假设检验。
以上是在SPSS 中常用的实验一基本统计方法,通过这些方法可以对实验数据进行全面的描述和分析,从而得出科学、客观的结论。
在使用这些方法时,需要根据实际情况选择合适的统计方法,并正确解读结果。
实验一一、实验目的:1.掌握SPSS的数据编辑功能利用SPSS的数据编辑器窗口,可以对打开的数据文件进行增加、删除、复制、剪切和粘贴等一般性操作,还可以对数据文件中的数据进行顺序、转置、拆分、聚合、加权等操作,对多个数据文件可以根据变量或个案进行合并。
可以根据需要把将要分析的变量集中到一个集合中,打开时指定打开该集合,而不必打开整个数据文件。
2.掌握表格的生成和编辑利用SPSS可以生成数十种风格的表格,利用编辑窗口或监视器可以编辑所要生成的表格。
在SPSS的高级版本中,统计成果多被归纳为表格或图形的形式。
3.掌握图形的生成和编辑利用SPSS可以生成数十种基本图形和交互式图形。
其中基本图形包括条形图、线形图、面积图、圆饼图、高低图、帕雷托图、控制图、箱形图、误差条形图、散点图、直方图、ROC曲线图、P-P概率图、Q—Q图、序列图和时间序列图等。
交互式图形比基本图形更漂亮,可有不同风格的2D、3D图形。
交互式图形包括条形交互作用图、点形交互作用图、线形交互作用图、带形交互作用图、圆形交互作用图、箱形交互作用图、误差条形交互作用图、直方交互作用图和散点交互作用图等。
4.会用SPSS的简单统计功能(1)摘要性分析摘要性分析是对原始数据进行描述性分析,是统计工作的出发点。
统计学的一系列基本描述指标,不仅让人了解资料的特征,而且可启发人们对之作进一步的深入分析。
SPSS统计软件通过调用摘要性分析,可完成均数、标准差、标准误差等指标的计算,对于计数和一些等级资料,可完成构成比率等指标的计算和2检验。
SPSS的摘要性分析包括以下几个过程:1) Frequencies(频数)过程调用此过程可进行频数分布表的分析。
频数分布表是描述性统计中最常用的方法之一,此外还可对数据的分布趋势进行初步分析。
2) Descriptives(描述)过程调用此过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,且可将原始数据转换成标准Z分值并存人数据库。
目录1.实验一 SPSS的数据管理2.实验二描述性统计分析3.实验三均值检验4.实验四方差分析5.实验五聚类分析和判别分析6.实验六因子分析和主成分分析7.实验七相关分析和回归分析8.实验八非参数检验9.实验九绘制统计图实验三均值检验一、实验目的学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤(一)描述统计(Means过程)实验内容:某医师测得血红蛋白值(g%)如表3.1,试利用Means过程作基本的描述性统计分析。
1.建立数据文件。
定义4个变量:ID、Gender、Age和HB,分别表示编号、性别、年龄和血红蛋白值。
2. 选择菜单“Analyze→Compare Means→Means”,弹出“Means”对话框。
在对话框左侧的变量列表中,选择变量“血红蛋白值”进入“Dependent List”列表框,选择变量“性别”进入“Independent List”,单击“Next”按钮,选择变量“年龄”进入“Independent List”。
3.单击“Options”按钮,在弹出的“选择描述统计量”对话框中设置输出的描述统计量。
4.单击“OK”按钮,得到输出结果。
(二)单样本T检验(One-Sample T Test过程)实验内容:某地区10年测得16-18岁人口的平均血红蛋白值为10.25。
现在抽查测量了该地区40个16-18岁人口的血红蛋白如表1,试分析该地区现在16-18岁人口的血红蛋白与10年前相比,是否有显著的差异?实验步骤:1.打开数据文件。
2. 选择菜单“Analyze→Compare Means→One-Sample T Test”。
弹出“One-Sample T Test”对话框。
3.在对话框左侧的变量列表中选择变量“血红蛋白”进入“Test Variable(s)”框;在“Test Value”编辑框中输入过去的平均血红蛋白值10.25.4.单击“OK”按钮,得到输出结果。
浙江海洋大学
《数据分析》课程
实验报告一
学生姓名:学号:指导教师:
实验时间: 班级: 报告评分:
一、实验室名称:数学专业综合实验室
二、实验项目名称:SPSS基本操作
三、实验内容:
1.将文件data.txt中的数据导入到SPSS中,并将文档中的第一行作为变量名;
2.将文件data.xls中的数据导入到SPSS中,并将文档中的第一行作为变量名;
3.对上述导入到SPSS中的数据所有变量进行简单的描述性统计:列出数据的频
数分布表;计算算术平均数、中位数、众数;计算全距、四分位差、标准差、方差等。
4.计算每位同学的总分,给出每位同学的排名,最低总分和最高总分的同学的
学号及各门课程的成绩。
5.绘制变量6个变量的直方图、饼图、箱式图,并简单解释相关量。
四、实验目的
1.学会应用两种以上的方法完成描述统计学所学的统计量的计算程序;如列出
数据的频数分布表;计算算术平均数、中位数、众数;计算全距、四分位差、标准差、方差等。
2.能够完成统计图的绘制(主要包括直方图、曲线图、饼形图、茎叶图);
3.能够撰写出规范的描述统计分析报告。
五、实验数据及结果分析(截图、解释、回答问题)。
实验一、SPSS基本操作一、实验目的及要求了解SPSS 10.0软件的操作环境,掌握SPSS10.0软件的基本操作方法。
二、实验内容数据的输入和保存;数据的预分析;两样本均数比较的t检验;保存和导出分析结果等操作的方法。
三、实验仪器、设备及材料硬件环境:PC软件环境:操作系统Windows系列ﻩﻩﻩSPSS10.0四、实验原理计量地理学中关于地理数据统计学分析的基本理论及SPSS10.0软件操作指南。
五、实验步骤§1.1 数据的输入和保存1.1.1 SPSS界面当打开SPSS后,展现在我们面前的界面如下:请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。
1.1.2 定义变量选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下:GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.531.67 1.80 1.87 2.07 2.11GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK按钮。
一、实验目的和要求1、熟练掌握SPSS软件进入和退出等操作,了解SPSS的基本窗口和菜单安排。
2、明确SPSS数据的基本组织方式和数据行列的含义。
3、掌握从哪些方面描述SPSS数据文件的结构特征。
4、熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。
二、实验步骤及过程三、实验结果分析四、实验体会一、实验目的和要求1、熟练掌握SPSS数据筛选的基本方法和具体操作。
2、熟练掌握SPSS数据排序、计数的具体操作。
3、掌握SPSS分类汇总的含义并熟练掌握具体操作。
4、掌握各种数据分组的特点和适用场合,并熟练掌握SPSS组距分组的具体操作。
二、实验步骤进入SPSS环境,并导入数据。
点击“转换——>计算变量”进入计算变量对话框进行变量计算,并通过数据——>排序个案、数据——>分类汇总、数据——>加权个案等对数据进行预处理。
三、实验内容及过程四、实验结果分析一、实验目的和要求1、熟练掌握SPSS频数分析的基本方法和具体操作。
2、明确基本描述统计量的含义,并熟练掌握其计算的具体操作。
3、掌握交叉列联表的基本方法,了解卡方检验的基本思想,能够数量掌握其具体操作。
4、掌握对多选项问题的不同拆分方法和应用场合,并熟练掌握SPSS进行多选项数分析。
二、实验步骤进入SPSS环境,并导入数据。
点击“分析——>描述统计——>频率”进入对变量的频数计算;点击“分析——>描述统计——>描述”,对变量进行描述统计分析;“分析——>描述统计——>列联表”,对数据变量进行交叉列联表分析;“分析——>描述统计——>比率”,对数据变量进行比率分析。
三、实验内容及过程。
SPSS是什么?1968年,美国斯坦福大学三名研究生为解决社会学研究中的统计分析问题,研发了SPSS软件软件包,原意为Statistical Package for the Social Sciences,即“社会科学统计软件包”。
2000年,随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司正式将英文全称更改为Statistical Product and Service Solutions,意为“统计产品与服务解决方案”.2009年,随着SPSS公司成为预测分析领域的领导者,SPSS公司旗下主要产品的名称前面统一冠以PASW字样,全称为“Predictive Analysis Software”, 即“预测分析软件”。
这样主要产品家族,称为PASW Statistics, PASW modeler,PASW PES,PASW Data Collection等.2010年,随着SPSS公司被IBM公司并购,各子产品前面不再以PASW为名,修改为统一加IBM SPSS字样.相关网站 。
SPSS Statistics的运行模式SPSS Statistics(以下简称SPSS)主要有两种运行模式:1.完全窗口菜单运行模式这种模式通过选择窗口菜单和对话框完成各种操作。
用户无须学会编程,简单易用。
2. 程序运行模式这种模式是在语句( Syntax)窗口中直接运行编写好的程序或者在脚本( script)窗口中运行脚本程序的一种运行方式。
这种模式要求掌握 SPSS的语句或脚本语言。
SPSS Statistics的启动运行windows[开始]→[程序]→[IBM SPSS Statistics]->[IBM SPSS Statistics 19],进入IBM SPSS Statistics 系统。
SPSS Statistics主要窗口介绍SPSS软件运行过程中会出现多个界面,各个界面用处不同。
其中,主要的界面有三个:数据编辑窗口、结果输出窗口和语句窗口。
1.数据编辑窗口启动SPSS后看到的第一个窗口便是数据编辑窗口,如图1-1所示。
在数据编辑窗口中可以进行数据的录入、编辑以及变量属性的定义和编辑,是SPSS的基本界面。
主要由以下几部分构成:标题栏、菜单栏、工具栏、编辑栏、变量名栏、观测序号、窗口切换标签、状态栏标题栏图1-1 数据浏览界面♦标题栏:显示数据编辑的数据文件名。
♦菜单栏:通过对这些菜单的选择,用户可以进行几乎所有的SPSS操作。
关于菜单的详细的操作步骤将在后续实验内容中分别介绍。
为了方便用户操作,SPSS软件把菜单项中常用的命令放到了工具栏里。
当鼠标停留在某个工具栏按钮上时,会自动跳出一个文本框,提示当前按钮的功能。
另外,如果用户对系统预设的工具栏设置不满意,也可以用[视图]→[工具栏] →[设定]命令对工具栏按钮进行定义。
♦编辑栏:可以输入数据,以使它显示在内容区指定的方格里。
♦变量名栏:列出了数据文件中所包含变量的变量名♦观测序号:列出了数据文件中的所有观测值。
观测的个数通常与样本容量的大小一致。
♦窗口切换标签:用于“数据视图”和“变量视图”的切换。
即数据浏览窗口与变量浏览窗口。
数据浏览窗口用于样本数据的查看、录入和修改。
变量浏览窗口用于变量属性定义的输入和修改。
♦状态栏:用于说明显示SPSS当前的运行状态。
SPSS被打开时,将会显示“IBM SPSS Statistics Processor”的提示信息。
2.结果输出窗口在 SPSS中大多数统计分析结果都将以表和图的形式在结果观察窗口中显示。
结果输出窗口如图1-2所示,窗口右边部分显示统计分析结果,左边是导航窗口,用来显示输出结果的目录,可以通过单击目录来展开右边窗口中的统计分析结果。
当用户对数据进行某项统计分析,结果输出窗口将被自动调出。
当然,用户也可以通过双击后缀名为.spo的SPSS输出结果文件来打开该窗口。
3.语句窗口不作介绍。
注意:(1)SPSS以“sav”为扩展名的文件保存数据窗口,以“sps”为扩展名的文件保存语句(syntax)窗口,以“”sp v”为扩展名的文件保存输出窗口。
(1)命令语句文件可用于下次处理。
我们能用SPSS Statistics做些什么?运用SPSS,可进行地理数据的整理(数据排序、剔除畸形值等);计算地理数据的分布特征值(极值、平均数、中位数、众数、方差、均方差、变异系数、峰度、偏度等);做地理学问题的统计假设检验(U检验、F检验、T检验、x2检验、方差分析等);进行地理要素的相关分析、回归分析、聚类分析、判别分析、主成份分析;并输出各种统计图表等。
实验一SPSS入门一、实验目的通过本次实验,对SPSS这一软件有一初步认识,为以后进一步分析打下基础。
二、有关名词含义Variable____变量,每一列为一变量(或要素)。
Case____案例(或观测量),相当于一个记录,每一行为一个安例。
Data View____数据窗口Variable View____数据结构窗口三、实验内容1.创建数据文件数据文件用来存放所要分析的数据。
创建数据文件分三个步骤:(1)制定数据文件结构在录入数据之前要对如何处理数据有个设想,即计算哪些变量,做什么样的统计学处理,生成哪种统计图等。
本例对每个变量做一般性统计描述性处理。
(2)录入数据一是录入数据之前应该根据实验的设计定义每个变量类型;二是将每一个具体的变量值录入数据库单元格内。
(3)数据编辑数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data 菜单中。
2.读取外部数据3.数据整理SPSS数据整理包括排序、转置、插入观测量、选择变量等。
4.数据统计处理根据数据处理要求计算出各变量的平均值、标准差、最大值、最小值等。
5.生成统计图将统计处理的结果用统计图形式输出,使结果一目了然。
6.保存文件统计处理完毕之后将各个窗口的数据、结果或图形保存,以便需要时再读出。
四、实验步骤1.创建一个数据文件(1)启动SPSS系统,选取File/New/Data项,进入数据编辑窗口,在“变量视图”中,按表1定义各数据项SPSS中的变量共有11个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Values )、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)、度量标准(Measure)和角色(Role,19.0版本新增的一个属性)。
定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。
在数据编辑窗口单击“变量视窗”标签,进入变量视窗界面,即可按表1-1对各变量的各个属性进行设置。
表 1-1取左下脚“数据视图”项,进入数据视图窗口,按表1-2进行数据录入。
表1-2(2)编辑数据文件利用Edit菜单项下提供的子菜单项(或弹出式菜单)Undo、Cut、Paste、Copy、Clear、Find等,进行恢复、剪切、粘贴、复制、删除、查找等基本的数据编辑操作。
2.读取外部数据SPSS可以很容易地读取Excel数据,步骤如下:(2)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图1-3。
图1-3(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图1-4所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel 工作表中的位置框。
图1-43.数据整理1)进行排序处理(本例以数据排序为例)选取【数据】->【排序个案】项,进入如图1-5所示名为【排序个案】的对话框。
图1-5在左侧源变量框中选取pop2001,点击中间方向按钮,使其进入名为【排序依据】的列表框中;在【排序顺序】组中选取【升序】单选钮后,单击OK按钮,系统进行以升序方式按变量名为pop2001进行排序。
2)从已有变量生成新变量选取【转换】->【计算变量】项,在如图1-6所示【计算变量】对话框的【目标变量】下键入area2,在【数字表达式】下键入area / 1000000,按OK建立了新变量area2,其值= area / 1000000;同样方法生成人口密度新变量pop_dens,其值= pop2001 / area2。
图1-63)新增新变量在【变量视图】中创建agg_reg新变量,其中decimals= 0, label= "Major regions of the world”,左击Values处,弹出如图1-7所示【值标签】对话框,使得1 = "Africa", 2 = "North America", 3 "Latin America", 4 = "Oceania", 5 = "Asia", 6 = "Europe"。
在data view中输入agg_reg变量的值,使得”1”对应5 个African 子区域,”2" 对应North America, "3" 对应3 个Latin American子区域,"4" 对应Oceania, "5" 对应4个Asia子区域,"6"对应4个欧州子区域。
图1-74)增加个案的数据合并(【数据】->【合并文件】->【添加个案】)将新数据文件中的观测合并到原数据文件中,在SPSS中实现数据文件纵向合并的方法如下选择菜单【数据】→【合并文件】→【添加个案】,选择需要追加的数据文件,单击打开按钮,弹出如图1-8所示【添加个案】对话框,选择个案数据来源的文件及变量。
图1-85)增加变量的数据合并(【合并文件】→【添加变量】)增加变量时指把两个或多个数据文件实现横向对接。
例如将不同课程的成绩文件进行合并,收集来的数据被放置在一个新的数据文件中。
在 SPSS中实现数据文件横向合并的方法如下:选择菜单【数据】→【合并文件】→,选择合并的数据文件,单击“打开”,弹出添加变量,所要添加的变量并确定后,两个数据文件将按观测的顺序一对一地横向合并。
图1-96)数据拆分在进行统计分析时,经常要对文件中的观测进行分组,然后按组分别进行分析。
例如要求按性别不同分组。
在SPSS中具体操作如下:♦选择菜单【数据】→【分割文件】,打开如图1-10所示【分割文件】对话框。