统计学主观题
- 格式:doc
- 大小:753.00 KB
- 文档页数:34

一、计算题1、(1)已知:225=n ,5.6=x ,5.2=s ,96.1025.0=z 。
网络用户每天平均上网时间的95%的置信区间为:33.05.62255.296.15.62±=⨯±=±n s z x α即(6.17,6.83)。
(2)样本比例4.022590==p 。
龄在20岁以下的网络用户比例的95%的置信区间为: 064.04.0225)4.01(4.096.14.0)1(2±=-⨯⨯±=-±n p p z p α 即(33.6%,46.4%)。
2、步骤一,建立假设。
因为制造商想要根据样本数据验证该等级的轮胎的平均寿命大于40000公里,所以用右侧检验,备择假设为:平均寿命大于40000公里。
H0: μ ≤ 40000公里 H1: μ > 40000公里步骤二,确定合适的统计量和抽样分布。
因为对总体均值进行假设检验,且总体方差未知,n<30, 所以用t 检验。
步骤三:选择显著性水平α,确定临界值。
α=0.05, df = 20 – 1 = 19,为右侧检验,所以t α=1. 7291步骤四:确定决策法则,计算检验统计量的值检验统计量:894.020500040*********=-=-=n s x t μ 步骤五:作出统计决策因为t=0.894 < t α =1.729,所以以0.05的显著性水平,不足以拒绝零假设:轮胎的平均寿命小于40000公里。
不能认为制造商的产品同他所说的标准相符.3、解: 已知σ =2000,E=400, 1-α=95%, z α/2=1.96即应抽取97人作为样本。
4、已知 n=100,p =65% , p 服从正态分布9704.964002000)96.1()(2222222≈=⨯==E z n σα1-α= 95%,a/2=0.025,z α/2=1.96该城市下岗职工中女性比例的置信区间为55.65%~74.35%5、(1)已知:50=n ,96.105.0=z 。

二、主观题(共4道小题)6.指出下面的数据类型:(1)年龄(2)性别(3)汽车产量(4)员工对企业某项改革措施的态度(赞成、中立、反对)(5)购买商品时的支付方式(现金、信用卡、支票)参考答案:(1)年龄:离散数值数据(2)性别:分类数据(3)汽车产量:离散数值数据(4)员工对企业某项改革措施的态度(赞成、中立、反对):顺序数据(5)购买商品时的支付方式(现金、信用卡、支票):分类数据7.某研究部门准备抽取2000个职工家庭推断该城市所有职工家庭的年人均收入。
要求:(1)描述总体和样本。
(2)指出参数和统计量。
参考答案:(1)总体:全市所有职工家庭;样本:2000个职工家庭(2)参数:全市所有职工家庭的人均收入;统计量:2000个职工家庭的人均收入。
8.一家研究机构从IT从业者中随机抽取1 000人作为样本进行调查,其中60%回答他们的月收入在5 000元以上,50%的人回答他们的消费支付方式是用信用卡。
要求:(1)这一研究的总体是什么(2)月收入是分类变量、顺序变量还是数值型变量(3)消费支付方式是分类变量、顺序变量还是数值型变量(4)这一研究涉及截面数据还是时间序列数据参考答案:(1) 所有IT从业者。
(2) 月收入十数值型变量(3)消费支付方式是分类变量(4) 涉及截面数据9.一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
要求:(1)这一研究的总体是什么(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值型变量(3)研究者所关心的参数是什么(4)“消费者每月在网上购物的平均花费是200元”是参数还是统计量(5)研究者所使用的主要是描述统计方法还是推断统计方法参考答案:(1)网上购物的所有消费者(2) 分类变量(3) 所有消费者网上购物的平均花费、所有消费者选择网上购物的主要原因(4) 统计量(5) 描述统计《统计学A》第二次作业二、主观题(共1道小题)31.自填式、面访式、电话式各有什么长处和弱点参考答案:自填式优点:调查成本最低;适合于大范围的调查;适合于敏感性问题的调查。


统计专业考试题及答案一、选择题(每题2分,共20分)1. 以下哪个选项是描述总体参数的?A. 样本均值B. 总体均值C. 样本标准差D. 总体标准差2. 假设检验中的零假设通常表示什么?A. 研究者想要证明的效应B. 研究者想要拒绝的效应C. 研究者认为不存在效应D. 研究者认为存在效应3. 在回归分析中,如果自变量X与因变量Y的相关系数为0,这意味着什么?A. X和Y之间存在线性关系B. X和Y之间不存在线性关系C. X和Y之间存在非线性关系D. X和Y之间存在强线性关系4. 以下哪个是描述性统计分析中的度量?A. 回归系数B. 均值C. 标准误D. 置信区间5. 抽样分布是什么的分布?A. 总体B. 样本C. 总体参数D. 样本统计量6. 以下哪个是统计学中常用的离散型分布?A. 正态分布B. 二项分布C. 泊松分布D. 均匀分布7. 描述数据集中趋势的度量是:A. 方差B. 标准差C. 均值D. 众数8. 以下哪个不是统计图?A. 条形图B. 散点图C. 箱线图D. 流程图9. 以下哪个是衡量数据变异程度的度量?A. 均值B. 方差C. 标准差D. 范围10. 以下哪个是时间序列分析中常用的方法?A. 回归分析B. 因子分析C. 移动平均D. 主成分分析二、简答题(每题10分,共30分)11. 简述中心极限定理的含义及其在实际应用中的重要性。
12. 解释什么是抽样误差,并举例说明它如何影响统计推断。
13. 描述相关系数的计算方法及其在数据分析中的作用。
三、计算题(每题25分,共50分)14. 假设有一个样本数据集,其均值为50,标准差为10,样本量为100。
计算样本均值的95%置信区间。
15. 给定两个变量X和Y的散点图,如果计算出的相关系数为0.6,并且回归方程为Y = 2X + 3,请计算当X增加1个单位时,Y的平均变化量是多少?四、论述题(共30分)16. 论述统计推断与描述性统计的区别,并举例说明它们在数据分析中的应用。

统计学测试题(附答案)一、单选题(共50题,每题1分,共50分)1、在双侧检验中,原假设与备择假设应选为()。
A、H0:M ≠M0,H1:M = M0B、H0:M= M0 ,H1:M<M0C、H0:M= M0 ,H1:M ≠M0D、H0:M = M0 ,H1:M ≥M0正确答案:C2、由变量y倚变量x回归和由变量x倚变量y回归所得到的回归方程是不同的,这表现在()。
A、一个是直线方程,另一个是曲线方程B、与方程对应的两条直线只有一条经过点C、方程中参数不同,意义也不同D、参数估计的方法不同正确答案:C3、连续调查与不连续调查的划分依据是()。
A、调查的组织形式B、调查单位包括的范围是否全面C、调查登记的时间是否连续D、调查资料的来源正确答案:C4、重点调查中重点单位是指()。
A、能用以推算总体标志总量的单位B、具有典型意义或代表性的单位C、标志总量在总体中占有很大比重的单位D、那些具有反映事物属性差异的品质标志的单位正确答案:C5、统计整理是()。
A、统计调查的前提,统计分析的继续B、统计研究的最终阶段C、统计分析的前提,统计调查的继续D、统计研究的初始阶段正确答案:C6、标志的具体表现是指()。
A、标志名称之后所列示的属性B、标志名称之后所列示的数值C、标志名称之后所列示的属性或数值D、如性别正确答案:C7、按水平法计算的平均发展速度推算可以使()。
A、推算的各期水平之和等于各期实际水平之和B、推算的各期增长量等于实际的逐期增长量C、推算的各期定基发展速度等于实际的各期定基发展速度D、推算的期末水平等于实际期末水平正确答案:D8、现有一数列:3,9,27,81,243,729,2 187,反映其平均水平最好用()。
A、算术平均数B、调和平均数C、几何平均数D、中位数正确答案:C9、某质量管理部门对某企业准备出厂的180件产品进行抽样调查,发现有170件为合格品,为证明该企业的全部产品的合格率是否达到95%,应采用哪一种假设检验()。
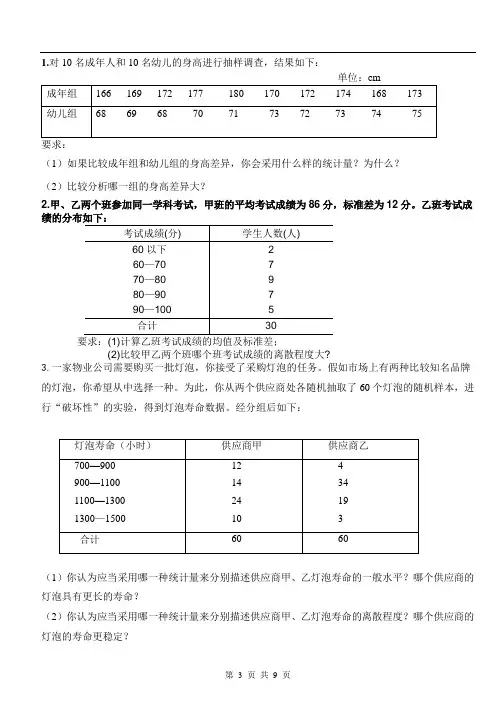
1.对10名成年人和10名幼儿的身高进行抽样调查,结果如下:(1)如果比较成年组和幼儿组的身高差异,你会采用什么样的统计量?为什么?(2)比较分析哪一组的身高差异大?2.甲、乙两个班参加同一学科考试,甲班的平均考试成绩为86分,标准差为12分。
乙班考试成(2)比较甲乙两个班哪个班考试成绩的离散程度大?3.一家物业公司需要购买一批灯泡,你接受了采购灯泡的任务。
假如市场上有两种比较知名品牌的灯泡,你希望从中选择一种。
为此,你从两个供应商处各随机抽取了60个灯泡的随机样本,进行“破坏性”的实验,得到灯泡寿命数据。
经分组后如下:(1)你认为应当采用哪一种统计量来分别描述供应商甲、乙灯泡寿命的一般水平?哪个供应商的灯泡具有更长的寿命?(2)你认为应当采用哪一种统计量来分别描述供应商甲、乙灯泡寿命的离散程度?哪个供应商的灯泡的寿命更稳定?4.一种产品需要人工组装,现有三种可供选择的组装方法。
为比较哪种方法更好,随机抽取10个工人,让他们分别用三种方法组装。
下面是10个工人分别用三种方法在相同时间内组装产品数量(1) 你准备采用什么方法来评价组装方法的优劣?试说明理由; (2) 如果让你选择一种方法,你会作出怎样的选择?试说明理由。
5. 某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1) 假定总体标准差为15元,求样本均值的抽样标准差; (2) 在95%的置信水平下,求允许误差;(3) 如果样本均值为120元,求总体均值95%的置信区间。
(注:96.1025.0=z ,557.42)29(205.0=χ)6..技术人员对奶粉装袋过程进行了质量检验,每袋的平均重量标准为406=μ克,标准差为1.10=σ克。
监控这一过程的技术人员每天随机抽取36袋,并对每袋重量进行测量。
现考虑这36袋奶粉所组成样本的平均重量x 。
(1)给出x x σμ和的值,写出x 的抽样分布。

统计学考试题及答案一、选择题(每题2分,共20分)1. 以下哪个选项是描述变量的集中趋势的度量?A. 方差B. 标准差C. 平均数D. 变异数答案:C2. 总体参数与样本统计量的主要区别是什么?A. 总体参数是固定的,样本统计量是变化的B. 总体参数是变化的,样本统计量是固定的C. 总体参数是估计的,样本统计量是已知的D. 总体参数是已知的,样本统计量是估计的答案:A3. 以下哪个分布是对称分布?A. 正态分布B. 泊松分布C. 二项分布D. 几何分布答案:A4. 抽样误差是指:A. 抽样过程中产生的误差B. 测量过程中产生的误差C. 抽样方法不当产生的误差D. 数据录入错误答案:A5. 以下哪个是统计推断的步骤?A. 收集数据B. 建立假设C. 进行实验D. 编写报告答案:B6. 相关系数的取值范围是:A. -1 到 1B. 0 到 1C. -∞ 到∞D. 1 到∞答案:A7. 以下哪个不是描述变量离散程度的度量?A. 方差B. 标准差C. 均值D. 极差答案:C8. 以下哪个是统计学中的基本概念?A. 变量B. 常数C. 函数D. 定理答案:A9. 以下哪个是描述变量分布形态的度量?A. 偏度B. 方差C. 均值D. 标准差答案:A10. 以下哪个是统计学中的抽样方法?A. 简单随机抽样B. 系统抽样C. 分层抽样D. 所有选项答案:D二、简答题(每题10分,共30分)1. 简述中心极限定理的内容及其在实际应用中的意义。
答案:中心极限定理指出,大量独立同分布的随机变量之和,在样本量足够大时,其分布趋近于正态分布,不论原始总体分布如何。
这一定理在实际应用中意义重大,因为它允许我们使用正态分布的性质来估计和推断总体参数,即使我们不知道总体的具体分布。
2. 什么是置信区间?请解释其在统计推断中的作用。
答案:置信区间是指在一定置信水平下,总体参数可能落在的区间范围。
在统计推断中,置信区间允许我们估计总体参数的可能值,同时给出一个可信度的度量。

第1章绪论1. 社会经济统计学的研究对象是( )A. 社会经济现象的数量方面B. 统计工作单位C. 社会经济的内在规律D. 统计方法正确答案:[A ]2. 要考察全国居民的人均住房面积,其统计总体是( )A. 全国所有居民户B. 全国的住宅C. 各省市自治区D. 某一居民户正确答案:[A ]3. 要了解某市工业企业生产设备情况,此场合的统计总体是()A. 该市全部工业企业B. 该市的所有企业C. 某工业企业的一台设备D. 该市全部工业企业的所有生产设备正确答案:[D ]4. 要了解某市工业企业生产设备情况,此场合的总体单位是()A. 该市全部工业企业B. 该市的所有企业C. 各工业企业的各种生产设备D. 工业企业的工人正确答案:[C ]5. 统计学是一门研究客观事物数量方面和数量关系的()A. 社会科学B. 自然科学C. 方法论科学D. 实质性科学正确答案:[C ]多选题1. 以下几种标志属于数量标志的有:()A. 所有制B. 生产能力C. 增加值D. 企业规模正确答案:[B,C,D,]2. 收集统计数据的基本方法包括:()A. 统计调查B. 实验C. 描述统计D. 推断统计正确答案:[A,B,]3. 经济统计学属于()A. 社会科学B. 自然科学C. 一般的方法论科学D. 有特定研究对象的方法论科学正确答案:[A,D,]4. 要研究全国国有企业工人的工资与劳保福利情况,下列各项属于统计指标的数据有:()A. 老王年年工资收入3万元B. 国有企业人均年工资2.5万元C. 李大妈年工资收入1万元D. 某市国有企业职工年平均收入3.5万元正确答案:[B,D,]5. 以下指标中属于质量指标的有()A. 国内生产总值B. 钢材年产量C. 生产能力利用率D. 单位生产总值的能源消耗量正确答案:[C,D,]判断题1. 统计数据是统计实践活动的成果.正确答案:[T ]2. 所谓标志是指总体单位的数量特征。
正确答案:[F ]3. 指标反映统计总体的数量特征。

大学统计学考试题及答案一、选择题(每题3分,共30分)1. 以下哪项不是描述统计学研究内容的?A. 数据收集B. 数据分析C. 数据解释D. 统计推断答案:C2. 统计学中的“总体”指的是:A. 研究对象的全体B. 研究对象的一部分C. 研究对象的样本D. 研究对象的个体答案:A3. 在统计学中,随机变量的期望值是指:A. 随机变量的平均值B. 随机变量的中位数C. 随机变量的众数D. 随机变量的方差答案:A4. 下列哪个选项是描述数据的集中趋势的?A. 方差B. 标准差C. 平均数D. 极差答案:C5. 以下哪个统计量用于度量数据的离散程度?A. 均值B. 中位数C. 众数D. 标准差答案:D6. 相关系数的取值范围是多少?A. -1到1之间B. 0到1之间C. 1到无穷大D. -无穷大到无穷大答案:A7. 以下哪个选项不是假设检验的步骤?A. 提出假设B. 收集数据C. 计算检验统计量D. 做出决策答案:D8. 在回归分析中,自变量是指:A. 因变量B. 被解释变量C. 解释变量D. 无关变量答案:C9. 以下哪个选项是时间序列分析的目的?A. 预测未来趋势B. 描述过去数据C. 进行假设检验D. 进行数据分类答案:A10. 以下哪个选项是统计学中的抽样误差?A. 由于随机抽样导致的误差B. 由于测量工具不准确导致的误差C. 由于数据录入错误导致的误差D. 由于样本量不足导致的误差答案:A二、填空题(每题3分,共30分)1. 在统计学中,________是指一组数据中出现次数最多的数值。
答案:众数2. 标准差是衡量数据________程度的统计量。
答案:离散3. 统计学中的“样本”是指从总体中随机抽取的________。
答案:一部分4. 相关系数的绝对值越接近1,表示两个变量之间的________越强。
答案:相关性5. 假设检验中的“零假设”通常表示没有________效应。
答案:显著6. 在回归分析中,如果自变量增加一个单位,因变量相应增加的单位数称为________。

统计学考试题及答案一、选择题(每题2分,共20分)1. 以下哪项不是描述性统计分析的内容?A. 计算平均数B. 计算中位数C. 计算标准差D. 进行假设检验答案:D2. 总体和样本的关系是:A. 样本是总体的一部分B. 总体是样本的一部分C. 总体和样本是相同的D. 总体和样本没有关系答案:A3. 以下哪个不是统计量?A. 平均数B. 方差C. 众数D. 总体答案:D4. 标准正态分布的均值和标准差分别是:A. 0, 1B. 1, 0C. -1, 1D. 1, 1答案:A5. 以下哪个是参数估计的步骤?A. 收集数据B. 建立假设C. 计算统计量D. 所有选项都是答案:D6. 相关系数的取值范围是:A. (-1, 1)B. (0, 1)C. [-1, 1]D. 无限制答案:C7. 以下哪个是统计推断的前提?A. 随机抽样B. 总体分布已知C. 样本量足够大D. 所有选项都是答案:A8. 以下哪个是时间序列分析的目的?A. 预测未来趋势B. 描述过去数据C. 分析数据关系D. 以上都是答案:A9. 以下哪个是统计图表?A. 散点图B. 柱状图C. 饼图D. 所有选项都是答案:D10. 以下哪个是统计软件?A. ExcelB. RC. SPSSD. 所有选项都是答案:D二、简答题(每题10分,共30分)1. 描述统计与推断统计的区别是什么?答案:描述统计主要关注数据的收集、整理和描述,它通过图表和数值来描述数据的特征,如平均数、中位数、众数等。
而推断统计则是基于样本数据来推断总体特征,它涉及概率论和假设检验,目的是估计总体参数或检验关于总体的假设。
2. 什么是正态分布?其特点有哪些?答案:正态分布是一种连续概率分布,其概率密度函数呈钟形曲线。
其特点包括:对称性,均值、中位数和众数相等;其均值为0,标准差为1的标准正态分布曲线是正态分布的基准形式;大多数数据值集中在均值附近。
3. 什么是假设检验?其基本步骤有哪些?答案:假设检验是统计推断的一种方法,用于基于样本数据对总体参数进行估计或检验。

统计学考试试题及答案一、选择题(每题2分,共20分)1. 以下哪项是描述数据集中趋势的统计量?A. 方差B. 众数C. 标准差D. 极差答案:B2. 正态分布曲线的特点是:A. 对称的B. 偏斜的C. 不对称的D. 非连续的答案:A3. 以下哪项是统计学中的基本概念?A. 样本B. 总体C. 变量D. 所有上述选项答案:D4. 回归分析中,自变量和因变量之间的关系是:A. 因果关系B. 相关关系C. 无关关系D. 既不是因果关系也不是相关关系答案:B5. 在统计学中,用于衡量两个变量之间线性关系强度的统计量是:A. 相关系数B. 回归系数C. 标准差D. 变异系数答案:A6. 假设检验中,零假设通常表示:A. 效应存在B. 效应不存在C. 效应显著D. 效应不显著答案:B7. 以下哪项是统计学中用于估计总体参数的样本统计量?A. 总体均值B. 样本均值C. 总体方差D. 样本方差答案:B8. 以下哪项是描述数据分布形态的统计量?A. 均值B. 方差C. 偏度D. 峰度答案:C9. 抽样调查的目的通常是为了:A. 收集数据B. 估计总体参数C. 进行假设检验D. 所有上述选项答案:B10. 以下哪项是描述数据离散程度的统计量?A. 均值B. 中位数C. 极差D. 众数答案:C二、填空题(每题2分,共10分)1. 统计学中的总体是指__________。
答案:研究对象的全部个体2. 抽样误差是指__________。
答案:样本统计量与总体参数之间的差异3. 回归方程中的斜率表示__________。
答案:自变量每变化一个单位,因变量平均变化的量4. 置信区间的宽度与__________有关。
答案:置信水平和样本大小5. 假设检验中,第一类错误是指__________。
答案:错误地拒绝了零假设三、简答题(每题5分,共15分)1. 请简述统计学中样本和总体的区别。
答案:总体是指研究对象的全部个体,而样本是从总体中随机抽取的一部分个体。
统计专业考试试题一、单项选择题(每小题1分,共25分。
下列每小题的备选答案中只有一个最符合题意,请将所选答案的字母填人括号内)。
1.2001年,浙江省国内生产总值列全国各省市(区)的( )。
A.第3位B.第4位C.第5位D.第6位2.统计表从形式上看,主要由( )构成。
A.主词和宾词B.各标题和数字C.总体及分组D.标志和指标3.相关分析是一种( )。
A.定性分析B.定量分析C.以定性分析为前提的定量分析D.以定量分析为前提的定性分析4.在国民经济核算中,流量与存量是( )。
A.质量指标B.总量指标C.相对指标D.平均指标5.某城市今年以同样多的人民币只能购买去年90%的商品,则今年该城市的物价指数为( )。
A.111.11 B.110.00 C.90.00 D.90.916.按照《浙江省统计工作监督管理条例》第九条规定,本省行政区域内的国家机关、企业事业组织,社会团体和其他组织等基本统计单位,应当在依法设立或变更后( )内,到当地县级以上人民政府统计机构办理统计登记或变更手续。
A.10日B.15日C.30日D.60日7.某企业的职工工资水平比上年提高了5%,职工人数增加了2%,则该企业工资总额增长( )。
A.7%B.7.1%C.10%D.11%8.已知各时期发展水平之和与最初水平及时期数,要计算平均发展速度( )。
A.用水平法计算B.用累计法计算C.两种方法都不能计算D.两种方法都能计算9.在一般情况下( )。
A.劳动力资源总数大于在业人数B.劳动力资源总数等于在业人数C.劳动力资源总数等于人口数D.劳动力资源总数小于在业人数10.一般而言,所谓美国经济衰退是指其国内生产总值连续( )个季度的负增长。
A.一B.二C.三D.四11.某市为了掌握在春节期间商品的销售情况,拟对占该市商品销售额80%的五个大商业企业进行调查。
这种调查的组织方式是( )。
A.普查B.重点调查C.抽样调查D.典型调查12.统计调查中搜集的原始资料是指()。
自考00065国民经济统计概论计算题知识点汇总第二章统计数据资料的搜集与整理1.组距=上限-下限2.组中值=(上限+下限)÷2或下限+(上限-下限)÷23.计算开口组组中值(即有上限无下限)=上限-相邻组的组距÷2=下限+相邻组组距÷2第三章综合指标1.结构相对指标=各组总量指标数值÷总体总量指标数值×12.比例相对数=总体中某一部分的指标数值÷总体中另一部分的指标数值3.比较相对数=总体中某项指标数值÷另一总体的该项指标数值4.强度相对指标=某一总量指标数值÷另一性质不同而有联系的总量指标数值5.动态相对指标=报告期指标数值÷基期指标数值6.计划完成程度指标数值=实际完成指标数值÷计划指标数值7.计划完成程度相对指标=(1±实际提高(降低)百分比}÷(1±计划提高(降低)百分比}8.算术平均数=总体单位某一数量标志值总和÷总体单位数9.简单算术平均法P6410.加权算数平均法P6511.简单调和平均法P6812.加权调和平均法P6813.简单几何平均数P7114.加权几何平均数P7115.组距数列确定众数P7216.中位数计算P7317.全距P7818.平均差简单平均法P8019.平均差加权平均法P8120.标准差简单平均法P8221.标准差加权平均法P8322.交替标志的标准差P84成数交替标志的平均数交替标志的标准差23.标志变异系数P86平均差系数标准差系数24.组内方差平均数P8925.组间方差P89第四章时间数列1.时期数列平均发展水平计算公式P1002.时点数列平均发展水平计算公式P1013.相对指标和平均发展指标时间数列计算平均发展水平P1044.增长量=报告期水平基期水平助其增长量=报告期水平前一期水平累计增长量=报告期水平-固定期水平5.平均增长量=逐期增长量之和÷逐期增长量个数=累计增长量÷(时间数列项数-1)6.发展速度=报告期水平÷基期水平7.增长速度=增长量÷基期水平=(报告期水平基期水平)÷基期水平=报告期水平÷基期水平-18.水平发展速度P1119.水平增长速度P114=平均发展速度-110.常见的测定长期趋势的方法方程式法P120第九章人口与劳动统计1.期末人口总数=期初人口数+(本期内出生人数本期内死亡人数)+(本期内迁入人数-本期内迁出人数)2.年平均人口数=(年初人口数+年末人口数)÷2P2463.城市(乡村)人口占总人口百分比=城市人口(乡村)÷总人口×14.城乡人口比例=城市人口÷乡村人口×15.人口密度=某地区人口数(人)÷该地区土地面积数(平方公里)6.性别构成指标=男性(或女性)人数÷总人口数×17.性比例指标=男性人数÷女性人数×18.少儿人口系数=14岁以下人口数÷总人口数×19.老年人口系数=65岁以上人口数÷总人口数×110.总负担系数=(14岁以下人口数+65岁以上人口数)÷15到64岁人口数×111.负担少年人口系数=14岁以下人口数÷15到64岁人口数×112.负担老年人口系数=65岁以上人口数÷15到64岁人口数×113.初等教育就学率=小学在校人数÷6到13岁人口数×114.中等教育就学率=中学在校人数÷14到19岁人口数×115.文盲率(含识字很少)=与识字很少人数÷15岁及以上人口数×116.人均收教育程度=∑(某种学制年限×受该学制教育的人数)÷∑受该学制教育的人数×117.人口出生率=年出生人数÷年平均人口数×1000%18.育龄妇女生育率(一般生育率)=年出生人数÷育龄妇女年平均人数×1000%(15到49岁)19.人口出生率=育龄妇女生育率×育龄妇女在总人口中的比重20.人口死亡率=年死亡人数÷年平均人口数×1000%21.年龄别死亡率(特殊死亡率)=,某年龄组死亡人数÷该年龄组的平均人数×1000%22.婴儿死亡率=未满1岁的婴儿死亡数÷(2/3的本年出生人数+1/3去年出生人数)×1000%23.人口自然增长率=人口自然增长量÷年平均人口数×1000%24.人口自然增长量=全年出生人数全年死亡人数25.人口迁入率=一定时期迁入人口数÷该时期平均人口数×1000%26.人口迁出率=一定时期迁出人口数÷该时期平均人口数×100027.人口总迁移率=人口迁入率+人口迁出率28.人口净迁移率=人口迁入率-人口迁出率29.人口增长量=人口自然增长量+人口机械增长量=(出生人数-死亡人数)+(迁入人数-迁出人数)=年末人口数-年初人口数30.年末人口数=年初人口数+(出生人数-死亡人数)+(迁入人数-迁出人数)=年初人口数+人口增长量31.年人口增长率=(年末人口数-年初人口数)÷年初人口数×1000%=年末人口数÷年初人口数-1=(年末人口数-年初人口数)÷年平均人口数×1000%=人口增长数÷年平均人口数×1000%32.人口增长率=人口自然增长率+人口机械增长率33.劳动力资源平均人数=(期末劳动力资源数+期初劳动力资源数)÷234.平均受教育年限=∑(某一受教育年限×该年限人数)÷劳动力资源总数35.劳动力资源的平均年龄=∑(各年龄组中值×该年龄组人口数)÷劳动力资源总数36.城镇(乡村)劳动力资源比重=城镇(乡村)劳动力资源数÷劳动力资源总数37.劳动力资源可利用率=∑(就业人数+失业人数)÷劳动力资源总人数×1=经济活动人口数÷劳动力资源总数×138.分年龄组(或性别)劳动力参与率=某年龄组(或性别)经济活动人口数/同一年龄组(或性别)劳动力资源总数×139劳动力资源实际利用率=就业人数/劳动力资源总数×140.就业率=就业人数/经济活动人口数×1=就业人数/(就业人数+失业人数)×141.劳动力失业率=失业人数/经济活动人口数×142.劳动力资源可能潜力程度=16岁及以上在校学生数/劳动力资源总数×143.丧丧失劳动能力系数=丧失劳动能力人数/劳动力适龄人口数(16岁以上人口数)×144.劳动生产率指数=报告期劳动生产率/基期劳动生产率=生产量指数(产值指数)/劳动力人数指数45.人均指标=产量(产值或国内生产总值)平均人口数46.生产发展超前系数=国内生产总值增长速度/人口增长速度(大于或等于1保持协调反之)47.消费发展超前系数=某种消费品支出的增长速度平均人口增长数度(同上)第十章国民财富统计1.土地垦殖率(垦殖指数)=耕地面积/土地总面积×12.耕地生产率=农产品产量或产值/耕地面积3.林木蓄积量=平均每株的材积量×单位面积上的平均株数×森林面积(立方米)4.森林覆盖率=森林面积/土地总面积×15.森林密度=森林覆盖面积/森林总面积×1=林木株数/相应的林地面积6.矿产资源保有量=年初保有储量/年末保有储量土年内因普查勘探重算等原因增减数-开采量-损失量-其它原因减少量7.矿产储量动态指标=年末保有储量/年初保有储量×18.径流量=降水量-蒸发量9.固定资产折旧额=固定资产原产值预计残值-预计清理费用/固定资产预计使用年限10.固定资产磨损率(固定资产磨损系数)=固定资产磨损额(累计折旧额)/固定资产原值×111.固定资产有用率=固定资产净值/固定资产原值×112.固定资产动态指标=报告期固定资产原值(或净值)/基期固定资产原值(或净值)×113.固定资产利用指标=一定时期生产成果价值/一定时期生产经营性固定资产平均价值14.流动资产周转次数=生产经营收入额/流动资产平均价值15.流动资产周转日数=报告期日历日数/流动资产周转次数=日历日数×流动资产平均价值÷生产经营收入额16.资产产值率=一定时期的生产成果/一定时期流动资产平均占用额17.在资产负债表中,(1)各机构部门之和=合计(2)非金融资产+金融资产=金融负债+资产负债差额(3)非金融资产+金融资产-金融负债=资产负债差额(自有资金)(4)项目来源合计=项目使用合计(5)国内金融资产合计=国内负债合计(6)国内对外的金融资产=国外部门负债(7)国内对外负债=国外部门金融资产(8)国民财产=非金融资产+国外金融资产与负债净额+储备资产=各部门资产与负债差额之和第十一章国民经济生产统计1.标准实物产量=∑(实物产量×折算系数)折算系数=某产品的实际规格或含量/标准品的规格或含量2.农业总产出(农业总产值)=种植业总产出+林业总产出+牧业总产出+渔业总产出+其它农业总产出3.农业总产出=∑(某农产品当年实际总产量×该种农产品的单价)产品法4.本期生产成品价值=自备原料生产的产品数量×本期不含增值税(销项税)的产品实际销售平均单价5.工业企业工业总产出(工业总产值)=本期生产成品价值+对外加工费收入+自制半成品在制品期末期初差额价值6.建筑工程产值=报告期已完成施工产值+期末期初未完施工产值差额7.建筑工程已完施工产值=∑[实际完成工程实物量×预算单价×(1+间接费率)]×(1+计划利润率)×(1+税率)8.运输产业产出=铁路运输总产出+公路运输+公路养护+水上运输+航空运输+管道运输9.邮电通信业总产出=邮政业务收入+长途电信业务收入+市内电话业务收入+地方国营通信收入-市话初装费10.批发零售贸易业总产出=按销售价格计算的已销售商品价值按购进价格计算的已销售商品价值运。
人力资源统计学高频知识点:【简答题】第一章企业人力资源统计学绪论1.简述企业人力资源的含义。
答:企业人力资源也称企业劳动力资源,是指企业所拥有的具有能够从事生产活动的脑力和体力劳动者。
人力资源从资源的角度,强调劳动力的开发、配置、利用与保护。
人力资源是“人”的实物形态。
2.简述标志和指标的区别和联系。
答:标志与指标是两个相互区别又相互联系的概念。
区别表现在:前者说明总体单位的特征,总体单位是标志的载体,而后者说明总体的特征,总体是指标的载体;前者既可以用数量表示(数量标志),也可以用文字表示(品质标志),而后者只能用数量表示。
两者的联系表现在:很多指标来源于标志。
例如,将各总体单位的标志值汇总可得标志总量,这个标志总量便是总体的指标。
3.简述相对指标的种类。
答:相对指标的种类有:①计划完成相对数;②结构相对数;③比例相对数;④比较相对数;⑤强度相对数;⑥动态相对数。
4.简述平均指标的特点。
答:平均指标的特点有:①将各总体单位的差异抽象化;②只有数量标志的标志值才能平均;③被平均的对象必须满足“同质性”。
5.为了保证计算结果的唯一性和可比性,在总量指标因素分析的统计实践中是如何处理拉氏指数与帕氏指数的?答:在总量指标因素分析的统计实践中,拉氏指数与帕氏指数只能二选一。
为了保证指数体系的对等性,一般规定:质量指标作同度量因素固定在基期,而数量指标作同度量因素则固定在报告期。
即质量指标综合指数采用帕氏指数,而数量指标综合指数采用拉氏指数。
第二章企业人力资源规模、结构与素质统计6.企业在进行人力资源规模统计时,需要注意哪些潜在的统计原理?答:企业在进行人力资源规模统计时,需要注意这样一条潜在的统计原理:①工资发放是核心,②工作关系是补充,③企业能否自由支配劳动力资源是关键。
7.简述企业人力资源的自然属性结构包含的内容。
答:企业人力资源的自然属性结构包含的内容有:①企业人力资源的性别结构;②企业人力资源的年龄结构;③企业人力资源的学历结构;④企业人力资源的民族结构。
统计学练习题及答案一、选择题1. 以下哪个不是描述性统计分析的范畴?A. 均值B. 方差C. 标准差D. 回归分析答案:D2. 在统计学中,总体是指:A. 研究中的所有个体B. 研究中的部分个体C. 研究中的随机样本D. 研究中的实验组答案:A3. 以下哪个是参数估计的方法?A. 描述统计B. 假设检验C. 点估计D. 相关分析答案:C4. 以下哪个是统计学中的离散型随机变量?A. 身高B. 体重C. 年龄D. 家庭中的子女数答案:D5. 正态分布的均值和方差之间的关系是:A. 均值等于方差的平方B. 方差等于均值的平方C. 方差是均值的函数D. 均值和方差是独立的答案:D二、简答题1. 简述抽样分布的概念。
答:抽样分布是指在多次抽样的情况下,样本统计量(如样本均值、样本方差等)的分布情况。
它描述了在不同样本中,这些统计量如何变化。
2. 解释什么是标准正态分布,并给出其均值和标准差。
答:标准正态分布是一种特殊的正态分布,其均值为0,标准差为1。
这种分布是正态分布的一种特殊形式,常用于标准化数据。
三、计算题1. 给定一组数据:10, 12, 14, 16, 18, 20,求这组数据的平均值和标准差。
答:平均值 = (10+12+14+16+18+20)/6 = 14.5标准差 = sqrt(((10-14.5)^2 + (12-14.5)^2 + (14-14.5)^2 + (16-14.5)^2 + (18-14.5)^2 + (20-14.5)^2)/6) = 3.772. 假设有一个总体,其均值为μ=100,标准差为σ=20。
从这个总体中随机抽取一个样本容量为n=36的样本,样本均值为x̄=105。
请问样本均值是否显著高于总体均值?答:使用t检验,t = (x̄ - μ) / (σ / sqrt(n)) = (105 - 100) / (20 / sqrt(36)) = 5 / 10 = 0.5。
统计学主观题⼆、主观题(共4道⼩题)6. 指出下⾯的数据类型:(1)年龄(2)性别(3)汽车产量(4)员⼯对企业某项改⾰措施的态度(赞成、中⽴、反对)(5)购买商品时的⽀付⽅式(现⾦、信⽤卡、⽀票)参考答案:(1)年龄:离散数值数据(2)性别:分类数据(3)汽车产量:离散数值数据(4)员⼯对企业某项改⾰措施的态度(赞成、中⽴、反对):顺序数据(5)购买商品时的⽀付⽅式(现⾦、信⽤卡、⽀票):分类数据7. 某研究部门准备抽取2000个职⼯家庭推断该城市所有职⼯家庭的年⼈均收⼊。
要求:(1)描述总体和样本。
(2)指出参数和统计量。
参考答案:(1)总体:全市所有职⼯家庭;样本:2000个职⼯家庭(2)参数:全市所有职⼯家庭的⼈均收⼊;统计量:2000个职⼯家庭的⼈均收⼊。
8. ⼀家研究机构从IT从业者中随机抽取1 000⼈作为样本进⾏调查,其中60%回答他们的⽉收⼊在5 000元以上,50%的⼈回答他们的消费⽀付⽅式是⽤信⽤卡。
要求:(1)这⼀研究的总体是什么?(2)⽉收⼊是分类变量、顺序变量还是数值型变量?(3)消费⽀付⽅式是分类变量、顺序变量还是数值型变量?(4)这⼀研究涉及截⾯数据还是时间序列数据?参考答案:(1) 所有IT从业者。
(2) ⽉收⼊⼗数值型变量(3)消费⽀付⽅式是分类变量(4) 涉及截⾯数据9.⼀项调查表明,消费者每⽉在⽹上购物的平均花费是200元,他们选择在⽹上购物的主要原因是“价格便宜”。
要求:(1)这⼀研究的总体是什么?(2)“消费者在⽹上购物的原因”是分类变量、顺序变量还是数值型变量?(3)研究者所关⼼的参数是什么?(4)“消费者每⽉在⽹上购物的平均花费是200元”是参数还是统计量?(5)研究者所使⽤的主要是描述统计⽅法还是推断统计⽅法?参考答案:(1)⽹上购物的所有消费者(2) 分类变量(3) 所有消费者⽹上购物的平均花费、所有消费者选择⽹上购物的主要原因(4) 统计量(5) 描述统计⼆、主观题(共1道⼩题)31.⾃填式、⾯访式、电话式各有什么长处和弱点?参考答案:⾃填式优点:调查成本最低;适合于⼤范围的调查;适合于敏感性问题的调查。
二、主观题(共4道小题)6. 指出下面的数据类型:(1)年龄(2)性别(3)汽车产量(4)员工对企业某项改革措施的态度(赞成、中立、反对)(5)购买商品时的支付方式(现金、信用卡、支票)参考答案:(1)年龄:离散数值数据(2)性别:分类数据(3)汽车产量:离散数值数据(4)员工对企业某项改革措施的态度(赞成、中立、反对):顺序数据(5)购买商品时的支付方式(现金、信用卡、支票):分类数据7. 某研究部门准备抽取2000个职工家庭推断该城市所有职工家庭的年人均收入。
要求:(1)描述总体和样本。
(2)指出参数和统计量。
参考答案:(1)总体:全市所有职工家庭;样本:2000个职工家庭(2)参数:全市所有职工家庭的人均收入;统计量:2000个职工家庭的人均收入。
8. 一家研究机构从IT从业者中随机抽取1 000人作为样本进行调查,其中60%回答他们的月收入在5 000元以上,50%的人回答他们的消费支付方式是用信用卡。
要求:(1)这一研究的总体是什么?(2)月收入是分类变量、顺序变量还是数值型变量?(3)消费支付方式是分类变量、顺序变量还是数值型变量?(4)这一研究涉及截面数据还是时间序列数据?参考答案:(1) 所有IT从业者。
(2) 月收入十数值型变量(3)消费支付方式是分类变量(4) 涉及截面数据9.一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
要求:(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值型变量?(3)研究者所关心的参数是什么?(4)“消费者每月在网上购物的平均花费是200元”是参数还是统计量?(5)研究者所使用的主要是描述统计方法还是推断统计方法?参考答案:(1)网上购物的所有消费者(2) 分类变量(3) 所有消费者网上购物的平均花费、所有消费者选择网上购物的主要原因(4) 统计量(5) 描述统计二、主观题(共1道小题)31.自填式、面访式、电话式各有什么长处和弱点?参考答案:自填式优点:调查成本最低;适合于大范围的调查;适合于敏感性问题的调查。
自填式缺点:较低的回收率;不适用于较复杂的问题的调查;调查中回答问题的情况不受控制(比如多人采用相同的回答);调查周期长。
面访式优点:较高的回答率;调查员可以对回答进行解释、确认、澄清,避免含混不清的回答。
面访式缺点:调查成本高;不适用于敏感性问题;调查员的素质会影响调查质量。
电话式优点:速度快;便于调查控制;适合于大范围的调查。
电话式缺点:受电话安装情况的限制;在涉及复杂问题,或问题较多时,容易被拒绝回答。
二、主观题(共5道小题)16.为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:要求:(1)指出上面的数据属于什么类型。
(2)用Excel制作一张频数分布表。
(3)绘制一张条形图,反映评价等级的分布。
(4)绘制评价等级的帕累托图。
参考答案:(1)顺序数据(2) 用数据分析——直方图制作:(3) 用数据分析——直方图制作:接收频率E 16 D 17 C 32 B 21 A 14(4)逆序排序后,制作累计频数分布表:接收频数频率(%) 累计频率(%)C 32 32 32B 21 21 53D 17 17 70E 16 16 86A 14 14 10017.某行业管理局所属40个企业2002年的产品销售收入数据如下:要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
参考答案:(1)1、确定组数:,取k=62、确定组距:组距=( 最大值- 最小值)÷组数=(114-42)÷6=10.83,取103、分组频数表销售收入频数频率%累计频数累计频率%80.00 - 89.002 5.02 5.090.00 - 99.0037.5512.5100.00 - 109.00922.51435.0110.00 - 119.001230.02665.0120.00 - 129.00717.53382.5130.00 - 139.00410.03792.5140.00 - 149.002 5.03997.5150.00+1 2.540100.0总和40100.0(2)频数频率%累计频数累计频率%先进企业1025.01025.0良好企业1230.02255.0一般企业922.53177.5落后企业922.540100.0总和40100.018. 一种袋装食品用生产线自动装填,每袋重量大约为50g,但由于某些原因,每袋重量不会恰好是50g。
下面是随机抽取的100袋食品,测得的重量数据如下:单位:g要求:(1)构建这些数据的频数分布表。
(2)绘制频数分布的直方图。
(3)说明数据分布的特征。
参考答案:解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数:,取k=6或72、确定组距:组距=( 最大值- 最小值)÷组数=(61-40)÷6=3.5,取3或者4、5组距=( 最大值- 最小值)÷组数=(61-40)÷7=3,3、分组频数表组距3,上限为小于频数百分比累计频数累积百分比有效40.00 - 42.003 3.03 3.043.00 - 45.0099.01212.046.00 - 48.002424.03636.049.00 - 51.001919.05555.052.00 - 54.002424.07979.055.00 - 57.001414.09393.058.00+77.0100100.0合计100100.0直方图:组距4,上限为小于等于频数百分比累计频数累积百分比有效<= 40.001 1.01 1.041.00 - 44.0077.088.045.00 - 48.002828.03636.049.00 - 52.002828.06464.053.00 - 56.002222.08686.057.00 - 60.001313.09999.061.00+1 1.0100100.0合计100100.0直方图:组距5,上限为小于等于频数百分比累计频数累积百分比有效<= 45.001212.012.012.046.00 - 50.003737.049.049.051.00 - 55.003434.083.083.056.00 - 60.001616.099.099.061.00+1 1.0100.0100.0合计100100.0直方图:分布特征:左偏钟型。
19.甲乙两个班各有40名学生,期末统计学考试成绩的分布如下:要求:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
(2)比较两个班考试成绩分布的特点。
(3)画出雷达图,比较两个班考试成绩的分布是否相似。
参考答案:(1)(2)甲班成绩中的人数较多,高分和低分人数比乙班多,乙班学习成绩较甲班好,高分较多,而低分较少。
(3)分布不相似。
20.已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):单位:亿元要求:(1)用Excel绘制国内生产总值的线图。
(2)绘制第一、二、三产业国内生产总值的线图。
(3)根据2004年的国内生产总值及其构成数据绘制饼图。
参考答案:(1)(2)(3)二、主观题(共7道小题)18.随机抽取25个网络用户,得到他们的年龄数据如下:要求;(1)计算众数、中位数:(2)根据定义公式计算四分位数。
(3)计算平均数和标准差;(4)计算偏态系数和峰态系数:(5)对网民年龄的分布特征进行综合分析:参考答案:(1)1、排序形成单变量分值的频数分布和累计频数分布:频数频率累计频数累计频率Valid 151 4.01 4.0 161 4.028.0 171 4.0312.0 181 4.0416.0 19312.0728.0 2028.0936.0 211 4.01040.0 2228.01248.0 23312.01560.0 2428.01768.0 251 4.01872.0 271 4.01976.0 291 4.02080.0 301 4.02184.0311 4.02288.0341 4.02392.0381 4.02496.0411 4.025100.0Total25100.0从频数看出,众数Mo有两个:19、23;从累计频数看,中位数Me=23。
(2)Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)均值=24.00;标准差=6.652(4)偏度系数SK=1.080;峰度系数K=0.773(5)分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:,取k=62、确定组距:组距=( 最大值 - 最小值)÷组数=(41-15)÷6=4.3,取53、分组频数表频数频率累计频数累计频率Valid <= 151 4.01 4.0 16 - 20832.0936.0 21 - 25936.01872.0 26 - 30312.02184.0 31 - 3528.02392.0 36 - 401 4.02496.0 41+1 4.025100.0 Total25100.0分组后的均值与方差:均值23.3000标准差7.02377方差49.333偏度系数Skewness 1.163峰度系数Kurtosis 1.302分组后的直方图:19.某银行为缩短顾客到银行办理业务等待的时间。
准备采用两种排队方式进行试验:一种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客。
得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟。
第二种排队方式的等待时间(单位:分钟)如下:5.5 6.6 6.7 6.8 7.1 7.3 7.47.8 7.8要求:(1)画出第二种排队方式等待时间的茎叶图。
(2)计算第二种排队时间的平均数和标准差。
(3)比较两种排队方式等待时间的离散程度。