XMOS的麦克风阵列语音识别方案
- 格式:pdf
- 大小:757.50 KB
- 文档页数:13

一文带你全面熟悉智能语音之麦克风阵列技术的原理麦克风阵列技术是智能语音领域的关键技术之一,其原理主要涉及麦克风的排列方式、信号处理算法和声源定位技术。
麦克风阵列技术的应用广泛,包括语音识别、语音指令控制、语音唤醒等领域。
首先,麦克风阵列技术中麦克风的排列方式非常重要。
麦克风阵列一般采用线性阵列或圆形阵列的方式,麦克风之间的间距要适当,以便在获取声音信号时保持一定的角度分辨率。
常见的线性阵列包括线性辐射阵列和线性非辐射阵列,前者可实现波束形成,后者可消除噪声对波束形成的影响。
而圆形阵列则可以提供全方位的感知能力,适用于多声源定位和追踪。
其次,麦克风阵列技术中的信号处理算法是实现语音增强和噪声削减的关键。
常见的信号处理算法包括自适应波束形成、空间滤波、噪声估计和消除等。
自适应波束形成算法通过调整麦克风阵列的权重来强化目标信号,抑制背景噪声。
空间滤波算法可以根据麦克风阵列的几何形状和声源位置,对声音进行滤波和增强。
噪声估计和消除算法可以检测到现场的噪声状况,并进行实时消除,提高语音信号的清晰度和可听性。
最后,麦克风阵列技术中的声源定位技术是实现多声源分离和定位的关键。
常见的声源定位技术包括基于时延差的定位、基于空间谱的定位和基于声学特征的定位等。
基于时延差的定位技术通过计算麦克风阵列上各个麦克风上的声音到达时间差,推断声源的位置。
基于空间谱的定位技术通过分析麦克风阵列接收到的声音的空间谱信息,推断声源的方向。
基于声学特征的定位技术则通过分析声音的特征参数,如声音的频率、幅度、谐波等特征,推断声源的位置。
总的来说,麦克风阵列技术通过合理的麦克风排列方式、信号处理算法和声源定位技术,实现了对语音信号的增强和噪声削减,提高了语音识别和语音控制的准确性和可靠性。
麦克风阵列技术的广泛应用将进一步推动智能语音技术的发展。


麦克风阵列在语音识别中的应用
随着人工智能技术的不断发展,语音识别技术逐渐走进人们的生活。
而在语音识别技术中,麦克风阵列的应用起到了重要的作用。
本文将介绍麦克风阵列在语音识别中的应用,并从多个方面阐述其重要性。
一、麦克风阵列介绍
麦克风阵列是由多个麦克风组成的一种变体形式,它可以将多个麦克风的输入信号进行数字信号处理和分析,并从中提取出任意方向的声音信号。
麦克风阵列通常由四个或更多麦克风组成,这些麦克风通常围绕着一个中心点布置,以形成一个可控制的虚拟听取器。
二、麦克风阵列在语音识别中的应用
1. 声纹识别
麦克风阵列可以用于声纹识别中,通过对人声信号进行分析和处理,从而实现语音识别。
在声纹识别中,麦克风阵列可以提高识别准确性和抗干扰能力,从而更好地识别人的声音特征。
2. 环境噪声抑制
麦克风阵列可以有效地抑制周围环境中的噪声,比如电视声、交通噪声等,从而提高语音识别的精确性和准确性。
麦克风阵列能够精确分析和抑制噪声,使得语音信号更加清晰,使得语音识别更准确。
3. 清晰度提升
麦克风阵列可以通过将多个麦克风的输入信号组合起来,从而使得语音信号更加清晰,更容易被识别。
麦克风阵列可以通过深度学习等技术,将多个麦克风的输入信号进行分析和处理,从而提升语音识别的清晰度和准确性。
三、总结
麦克风阵列在语音识别技术中发挥着重要作用,能够提高识别准确性和抗干扰能力,从而更好地识别人的声音特征。
麦克风阵列还能有效地抑制环境噪声,提高语音识别的精确性和准确性,从而使得语音识别更加优秀。
随着人工智能技术的发展,麦克风阵列技术将会在语音识别中扮演更加重要的作用。
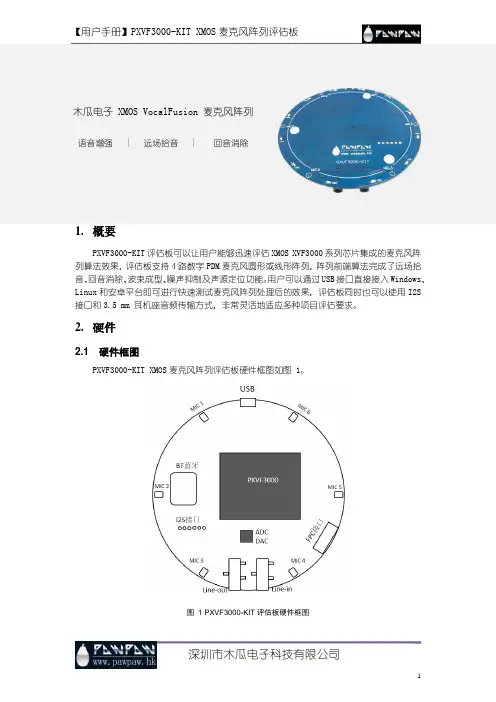
木瓜电子 XMOS VocalFusion 麦克风阵列语音增强 | 远场拾音 | 回音消除1.概要PXVF3000-KIT评估板可以让用户能够迅速评估XMOS XVF3000系列芯片集成的麦克风阵列算法效果,评估板支持4路数字PDM麦克风圆形或线形阵列,阵列前端算法完成了远场拾音、回音消除、波束成型、噪声抑制及声源定位功能。
用户可以通过USB接口直接接入Windows、Linux和安卓平台即可进行快速测试麦克风阵列处理后的效果,评估板同时也可以使用I2S 接口和3.5 mm 耳机座音频传输方式,非常灵活地适应多种项目评估要求。
2.硬件2.1 硬件框图PXVF3000-KIT XMOS麦克风阵列评估板硬件框图如图 1。
图 1 PXVF3000-KIT评估板硬件框图硬件框图包含如下内容:USB:♦USB提供设备5V电源供应♦USB Audio Class 2.0/1.0(UAC 2.0/ UAC 1.0)传输音频信号♦USB DFU PXVF3000-KIT评估板固件更新♦USB HID 指令/控制传输MIC:♦Invensence ICS-41350 PDM 麦克风♦MIC 1~6 圆形均匀分布,半径43mmPXVF3000:♦核心板,完成远程拾音、回音消除、波束成型等语音前端算法硬件模组BT蓝牙:蓝牙模块将PXVF3000的输入输出音频信号无线传输ADC/DAC:♦DAC负责PXVF3000的数字转模拟信号播放输出♦ADC可以使用模拟信号转换数字信号输入,作为PXVF3000的回音消除参考信号FPC接口:实现线形(长条形)麦克风阵列扩展,其他麦克风阵列阵型调整性扩展I2S接口:I2S数据接口兼容主从模式输入输出PXVF3000声音信号Line-out:3.5mm耳机座子立体声输出PXVF3000声音信号Line-in:3.5mm耳机座子Mono通道输入给PXVF3000作为参考信号3.评估板快速使用PXVF3000-KIT评估板出厂默认使用圆形4路麦克风阵列,分别是使用MIC 1、MIC 3、MIC 4和MIC6组成的矩形阵列如图 2。

麦克风阵列解决方案
《麦克风阵列解决方案》
在如今的科技发展中,麦克风阵列正成为解决多种音频采集和处理问题的热门选择。
麦克风阵列是一种成组的麦克风系统,能够同时采集多个声音信号,并通过信号处理技术将它们合成为单一的音频信号。
它在语音识别、会议录音、音频增强等领域有着广泛的应用。
对于无线耳机和智能音箱,麦克风阵列的应用尤为广泛。
通过利用麦克风阵列的方向性,可以实现更准确的语音识别和识别目标方向。
这种技术不仅可以提高设备的用户体验,还可以为语音交互和人机交互的发展提供有力的支持。
此外,对于大型会议室和演讲场所,麦克风阵列系统也发挥着不可或缺的作用。
传统的单颗麦克风往往无法有效捕捉到远处的声音,而麦克风阵列可以通过多颗麦克风的联合工作,实现全方位声音的捕捉和清晰传输。
这对于重要会议和演讲活动来说,是非常重要的。
总的来说,麦克风阵列解决方案为音频采集和处理带来了新的技术突破和解决方案。
它在多个领域的应用都取得了积极的成果,同时也为音频技术的发展带来了新的动力和方向。
相信随着技术的不断进步,麦克风阵列将会在更多的领域中得到广泛应用,为人们的生活带来更多便利和乐趣。



xmos方案简介xmos方案是一种基于XMOS芯片的音频处理解决方案,通过硬件加速和高度可配置的软件处理,提供了高质量的音频处理和分析功能。
该方案可以广泛应用于音频设备、语音识别系统、传感器数据处理等领域。
背景随着数字音频技术的快速发展,人们对音频处理和分析的要求也越来越高。
传统的音频处理方案往往需要借助外部DSP芯片或者复杂的算法来完成,而XMOS 芯片通过其独特的多核架构和高度灵活的软件编程环境,成为了一种更加高效和可定制的音频处理方案。
原理xmos方案的核心是XMOS芯片,该芯片集成了多个处理核心,每个核心都可以独立运行和处理音频数据。
这些核心之间可以通过XMOS的通信接口进行高效的数据交换和协同工作。
通过适当的编程和配置,可以将不同的音频处理任务分配到不同的核心上,从而实现高效的音频处理和分析。
主要特点xmos方案具有以下几个主要特点:高度可配置的软件环境XMOS芯片提供了一个灵活的软件编程环境,开发人员可以根据不同的应用需求进行定制化编程。
这意味着xmos方案可以适应不同的音频处理和分析任务,提供高度定制化的解决方案。
多核架构XMOS芯片内置了多个处理核心,每个核心都具有独立的运算能力和存储资源。
这使得xmos方案可以同时处理多个音频流,实现更高的并行处理能力。
通过合理的任务分配和资源调度,可以提升音频处理和分析的效率。
低功耗设计XMOS芯片采用了先进的功耗管理技术,能够在保证高性能的同时降低功耗消耗。
这使得xmos方案在电池供电设备或者对功耗要求较高的场景下具有更好的应用潜力。
应用场景xmos方案可以应用于多个领域,包括但不限于以下几个方面:音频设备xmos方案可以用于音频处理设备,例如音频接口、音频处理器和音频编解码器等。
通过合理的编程和配置,可以实现高质量的音频采集、回放和处理功能。
语音识别系统xmos方案可以应用于语音识别系统,通过对语音数据的实时处理和分析,可以实现高准确度的语音识别功能。


科技成果——麦克风阵列声源识别、定向和定位技术成果简介
利用麦克风阵列技术准确定向声源,采用模式识别技术辨别并区分话音和其它声响,采用时延和几何方法确定声源方位,实时处理,算法稳定,抗噪能力强。
应用于监控摄像头辅助系统(引导摄像头转向异常方向,标定录像带中的异常时刻,异常情况时报警等),室内防盗系统(识别破门破窗等异常声响并录音或报警),办公室夜间防盗系统(识别并定向或定位夜间出现的各类异常声响并录音或报警),交通监控系统,保护区监控系统(如偷猎者方位,非法车辆识别、定位和报警等),视像会议系统中的话者定向,机械异常声响识别和定位,基于麦克风阵列的语音获取系统的话者定向或定位,灾场搜寻系统(机器人载,无人机载,营救人员穿戴)。
项目水平国内领先
成熟程度样机
合作方式
合作开发、专利许可、技术转让、技术入股。

麦克风阵列定位原理
麦克风阵列定位的原理基于多输入多输出(MIMO)技术,通过多个麦克风接收到的信号进行处理,从而确定声源的位置。
具体来说,麦克风阵列定位的原理可以分为以下几个步骤:
1. 麦克风阵列接收声音信号:麦克风阵列由多个麦克风组成,可以接收到多个方向的声音信号。
2. 信号处理:通过对每个麦克风接收到的信号进行时域或频域分析,可以得到该麦克风接收到的声音信号的相位和幅度信息。
3. 计算到达时间差:对于基于时间差的定位算法,可以通过计算多个麦克风接收到的声音信号到达的时间差,得到声源到每个麦克风的距离和方向信息。
4. 计算声源位置:根据多个麦克风接收到的信号的到达时间差和相位信息,可以计算出声源在阵列中的位置坐标。
麦克风阵列定位技术具有定位精度高、抗干扰能力强等优点,被广泛应用于语音识别、声源定位、环境监测等领域。
不同类型的麦克风阵列,如线性麦克风阵列、圆形麦克风阵列、三维矩阵麦克风阵列等,可以适应不同的应用场景和要求。
基于语音识别的无线麦克风阵列信号处理研究随着人工智能、大数据、云计算等技术的不断发展,语音识别技术也日渐成熟,并且被广泛应用于智能家居、智能客服、智能语音助手等领域。
而在语音识别技术的基础上,又发展出了无线麦克风阵列技术,可以实现优质的语音采集和信号处理,广泛应用于会议室、音频录制等领域。
一、无线麦克风阵列技术的概述无线麦克风阵列技术是利用多个麦克风进行语音信号采集,并通过信号处理技术对采集到的语音信号进行虑波、分离、降噪等处理,以提高语音识别精度,同时也可用于音频录制、会议等场合。
与传统的有线麦克风相比,无线麦克风阵列具备自适应、可扩展、维护成本低等优点。
其由多个无线麦克风节点组成,可以在场景变化时自动调节,提高语音采集效果。
同时,无线通信技术的进步也促进了无线麦克风阵列技术的发展。
二、语音识别技术的发展语音识别是基于自然语言处理技术,通过计算机进行语音信号的模式分类和特征提取,实现对语音信号的准确识别。
随着语音识别技术的不断发展和优化,其识别精度逐渐提高。
传统的语音识别技术通常基于词典匹配、卡尔曼滤波、高斯混合模型等基本算法,但这些算法在面对噪声、语调、口音等情况时容易出现错误。
目前,深度学习等技术的应用很大程度上解决了这些问题,特别是深度神经网络模型在语音识别领域的应用,极大地提高了语音识别的精度和稳定性。
三、无线麦克风阵列与语音识别的结合无线麦克风阵列技术和语音识别技术的结合,可以实现更加可靠和高效的语音信号采集和处理,进而实现更高的语音识别精度。
其中,无线麦克风阵列的信号处理技术是关键。
传统的信号处理技术包括定向图法、自适应波束形成等,可以实现在噪声环境下的信号分离和降噪,利用语音增强技术可以进一步提高识别准确度。
在此基础上,还可以加入深度学习等技术的优化,对特定场景下的语音信号进行模型训练和优化,实现更高的识别精度和稳定性。
四、无线麦克风阵列信号处理技术的研究方向在无线麦克风阵列信号处理技术方面,目前的研究方向主要包括:1. 阵列构型设计和优化。
麦克风阵列信号处理算法研究麦克风阵列是指由多个麦克风组成的阵列,通过对阵列中麦克风信号的处理,可以实现信号的方向性增强、空间滤波和噪声抑制等效果。
因此,在语音识别、语音增强、远场语音采集等领域都有广泛的应用。
麦克风阵列可以形成的微弱信号从而提高语音识别的准确性。
与单一麦克风相比,麦克风阵列能够对方向性声源进行有效的捕捉,并且可以对噪声进行滤波抑制,对听觉信号进行增强处理。
然而,麦克风阵列系统的性能受多种因素影响,包括麦克风位置、信号处理算法等。
在麦克风阵列信号处理算法中,主要包括波束形成和方向估计两个方面。
波束形成是指对接收到的麦克风信号进行加权和相位校准,从而形成一个指向目标信号的波束;方向估计是指对目标信号的方向进行估计。
波束形成算法是麦克风阵列信号处理算法中的核心内容。
常见的波束形成算法包括广义旁瓣消除(Generalized Sidelobe Canceller,GSC)、最小均方(Minimum Mean Square Error,MMSE)和最大信噪比(Maximum Signal-to-Noise Ratio,MSNR)等。
广义旁瓣消除算法是一种基于自适应滤波的波束形成算法,其主要思想是通过在线更新权重系数,抑制麦克风阵列接收到的信号中的旁瓣干扰。
最小均方算法和最大信噪比算法则是一种基于统计建模的波束形成算法,通过对麦克风阵列中接收到的信号进行统计建模,进而实现信号的增强和噪声的滤波。
除了波束形成算法外,方向估计算法也是麦克风阵列信号处理算法中的重要内容。
常见的方向估计算法包括时延和相位差(Time Delay and Phase Difference,TDPD)算法、最大似然(Maximum Likelihood,ML)算法等。
时延和相位差算法是一种基于时间差信号处理的方向估计算法,可以通过对阵列中麦克风的时间差和相位差进行计算,从而估计目标信号的方向。
最大似然算法则是一种基于概率统计的方向估计算法,通过对阵列中接收到的信号进行统计建模,进而实现目标信号方向的估计。
专利名称:基于XMOS平台的USB麦克风阵列多声道采集装置专利类型:实用新型专利
发明人:邓自成,邱松晓,杨瑞云
申请号:CN201621241998.5
申请日:20161121
公开号:CN206332831U
公开日:
20170714
专利内容由知识产权出版社提供
摘要:本实用新型公开了基于XMOS平台的USB麦克风阵列多声道采集装置,包括XMOS芯片;与所述XMOS芯片相连的至少一个数字麦克风和/或通过多通道ADC与所述XMOS芯片相连的至少一个模拟麦克风;与所述XMOS芯片里面的USB PHY相连的USB数据线。
与现有技术相比,本实用新型能够实现高达32个的模拟麦克风和数字麦克风;可以实现分板设计,采用标准化的USB接口,保证了信号传输的稳定性,同时解除了对操作系统的CPU的绑定;本实用新型加上了XMOS主控和外部时钟,使得多个麦克风采集的信号能够在时间上一致和同步。
申请人:深圳市木瓜电子科技有限公司
地址:518042 广东省深圳市福田区车公庙天安数码城天发大厦CD座605室
国籍:CN
代理机构:广东广信君达律师事务所
代理人:杨晓松
更多信息请下载全文后查看。
XMOS推出支持立体声AEC的XVF3500语音处理
器
XMOS推出支持立体声AEC的XVF3500语音处理器,以及世界首款立体声AEC远场线性麦克风阵列解决方案VocalFusion立体声评估套件(XK-VF3500-L33)。
XVF3500语音处理器提供2通道全双工声学回声消除(AEC)。
该解决方案专为在基于语音的智能电视、条形音箱、机顶盒和数字媒体适配器等不断成长的市场中工作的开发人员而设计所有这些市场都需要有立体声AEC来支持整个房间的语音接口解决方案。
独特的是,该解决方案还支持可配置的AEC延迟,而使AEC参考信号可以被准确校准,并使延迟能被调整,从而为现有消费类电子产品提供远场语音售后配件。
XMOS公司总裁兼首席执行官Mark Lippett在评论这一产品发布时表示:该设备和评估套件将进一步推动我们房间边缘的嵌入式语音控制设备的整合,尤其是那些用于高品质音乐和电视控制的设备。
我们期待在下个月在拉斯维加斯举办的美国消费类电子展(CES)上展示这个解决方案。
我们已经具备了最全面的远场拾音解决方案组合,而这一发布进一步巩固了这个地。