家谱的设计与实现(二叉树)
- 格式:pdf
- 大小:113.36 KB
- 文档页数:10

二叉树的实现实验原理二叉树是一种常见的数据结构,它由节点组成,每个节点最多有两个子节点,通常称为左子节点和右子节点。
二叉树的实现原理如下:1. 节点的定义:每个节点包含一个值和两个指针,分别指向左子节点和右子节点。
节点可以使用类或结构体来表示,具体的实现方式取决于编程语言。
2. 树的定义:树由节点组成,其中一个节点被指定为根节点。
根节点没有父节点,其他节点都有且只有一个父节点。
每个节点最多有两个子节点,即左子节点和右子节点。
3. 添加节点:向二叉树中添加节点时,需要遵循以下规则:- 如果树为空,将节点作为根节点添加到树中。
- 如果节点的值小于当前节点的值,将节点添加为当前节点的左子节点。
- 如果节点的值大于等于当前节点的值,将节点添加为当前节点的右子节点。
4. 遍历树:遍历二叉树可以按照不同的顺序进行,常见的遍历方式有三种:- 前序遍历(Preorder Traversal):先访问根节点,然后按照前序遍历方式遍历左子树,最后按照前序遍历方式遍历右子树。
- 中序遍历(Inorder Traversal):先按照中序遍历方式遍历左子树,然后访问根节点,最后按照中序遍历方式遍历右子树。
- 后序遍历(Postorder Traversal):先按照后序遍历方式遍历左子树,然后按照后序遍历方式遍历右子树,最后访问根节点。
遍历树的过程可以使用递归或迭代的方式来实现,具体的实现方法取决于编程语言和使用的数据结构。
5. 删除节点:删除二叉树中的节点时,需要考虑多种情况。
如果要删除的节点是叶子节点,可以直接删除它。
如果要删除的节点只有一个子节点,可以将子节点移动到要删除的节点的位置。
如果要删除的节点有两个子节点,可以选择将其中一个子节点替代要删除的节点,或者选择左子树的最大节点或右子树的最小节点替代要删除的节点。
根据上述原理,可以使用类或结构体等数据结构和递归或迭代的方式来实现二叉树。
具体的实现方法和细节可能因编程语言而异,但以上原理是通用的。

家谱的设计与实现(树,查找)家谱的设计主要是实现对家庭成员信息的建立、查找、插入、修改、删除等功能。
可。
基本功能如下:(1)家谱中每个成员的信息包括:姓名、性别。
(2)家谱祖先数据的录入(树的根结点)。
(3)家庭成员的添加:即添加某人的儿女(包括姓名和性别),儿女的数目由控制台端给出,然后输入相应的儿女姓名和性别(此处所有儿女的姓名不能重名)。
(4)家庭成员的修改:可以修改某一成员的姓名。
(5)家庭成员的查询:查询某一成员在家族中的辈分(第几代),并能查询此成员的所有子女及这一辈的所有成员。
(6)家庭成员的删除:删除此成员时,若其有后代,将删除其所有后代成员。
#include <stdio.h>#include <malloc.h>#include <string>#include <stdlib.h>#define MAX 10typedef struct node{ //定义data存储结构char name[MAX]; //姓名char sex; //性别int generation;//代目}node;typedef struct ft{ //创建结构体struct node l; //家谱中直系家属struct ft *brother;//用来指向兄弟struct ft *child;//用来指向孩子}ft;ft *root; //root是结构体ft的指针ft *search(ft *p,char ch[]) // 搜索指针函数{ft *q;if(p==NULL)return NULL;//没有家谱,头指针下为空if(strcmpi(p->,ch)==0)return p;//家谱不为空,头指针下有这个人if(p->brother){q=search(p->brother,ch);//在兄弟中找if(q)return q;//找到}if(p->child){q=search(p->child,ch);//在孩子中找if(q!=NULL)return q;}return NULL;//没有找到}ft *parent(ft *p,ft *q,int *flag) //通过parent函数得到双亲结点。

二叉树的常用算法设计和实现一、引言二叉树是一种重要的数据结构,广泛应用于计算机科学中。
掌握二叉树的常用算法设计和实现对于理解和应用二叉树具有重要意义。
本文档将介绍二叉树的常用算法设计和实现,包括二叉树的遍历、查找、插入和删除等操作。
二、算法设计1. 遍历算法:二叉树的遍历是二叉树操作的核心,常用的遍历算法包括先序遍历、中序遍历和后序遍历。
每种遍历算法都有其特定的应用场景和优缺点。
2. 查找算法:在二叉树中查找特定元素是常见的操作。
常用的查找算法有二分查找和线性查找。
二分查找适用于有序的二叉树,而线性查找适用于任意顺序的二叉树。
3. 插入算法:在二叉树中插入新元素也是常见的操作。
插入操作需要考虑插入位置的选择,以保持二叉树的特性。
4. 删除算法:在二叉树中删除元素也是一个常见的操作。
删除操作需要考虑删除条件和影响,以保持二叉树的特性。
三、实现方法1. 先序遍历:使用递归实现先序遍历,可以通过访问节点、更新节点计数器和递归调用下一个节点来实现。
2. 中序遍历:使用递归实现中序遍历,可以通过访问节点、递归调用左子树和中继判断右子树是否需要访问来实现。
3. 后序遍历:使用迭代或递归实现后序遍历,可以通过访问节点、迭代处理左子树和右子树或递归调用左子树和更新节点计数器来实现。
4. 二分查找:在有序的二叉搜索树中实现二分查找,可以通过维护中间节点和边界条件来实现。
5. 线性查找:在任意顺序的二叉树中实现线性查找,可以通过顺序遍历所有节点来实现。
6. 插入和删除:针对具体应用场景和删除条件,选择适当的插入位置并维护节点的插入和删除操作。
在有序的二叉搜索树中实现插入和删除操作相对简单,而在其他类型的二叉树中则需要考虑平衡和维护二叉搜索树的特性。
四、代码示例以下是一个简单的Python代码示例,展示了如何实现一个简单的二叉搜索树以及常用的二叉树操作(包括遍历、查找、插入和删除)。
```pythonclass Node:def __init__(self, data):self.data = dataself.left = Noneself.right = Noneclass BinarySearchTree:def __init__(self):self.root = Nonedef insert(self, data):if not self.root:self.root = Node(data)else:self._insert(data, self.root)def _insert(self, data, node):if data < node.data:if node.left:self._insert(data, node.left)else:node.left = Node(data)elif data > node.data:if node.right:self._insert(data, node.right)else:node.right = Node(data)else:print("Value already in tree!") # Value already in tree!def search(self, data):return self._search(data, self.root)def _search(self, data, node):if data == node.data:return Trueelif (not node.left and data < node.data) or (notnode.right and data > node.data):return Falseelse:return self._search(data, node.left) orself._search(data, node.right)def inorder_traversal(self): # inorder traversal algorithm implementationif self.root: # If the tree is not empty, traverse it in-order.self._inorder_traversal(self.root) # Recursive function call for in-order traversal.print() # Print a new line after traversal to clear the output area for the next operation.def _inorder_traversal(self, node): # Helper function for in-order traversal algorithm implementation. Traverse the left subtreefirst and then traverse the right subtree for a given node (start with root). This method handles recursive calls for traversal operations efficiently while keeping track of nodes already visited and。

摘要本文设计了一个对数据输入,输出,储存,查找的多功能软件,本文需要保存家族的基本信息,包括姓名及它们的关系,但是由于家族信息很巨大而且关系很复杂所以采用二叉树来表示它们的关系。
并且具有保存文件的功能,以便下次直接使用先前存入的信息。
家谱的功能是查询家族每个人的信息,并且输出它们的信息,还要具有查询输出功能。
本文采用二叉树来存取家族的基本信息,头结点作为父亲节点,他的左孩子为他的妻子,妻子结点的右孩子为他的孩子,依次存储每个家庭的信息。
可以查找每个父亲的孩子和每个人的所有祖先。
关键词:二叉树家谱结点目录1 系统功能概述 (1)1.1 系统功能 (1)图2 成员二叉树功能模块图 (4)1.2 总体功能模块 (4)2 系统各功能模块的详细设计 (5)2.1功能选择 (5)2.2信息输入 (7)2.3信息输出 (7)2.4信息存盘 (7)2.5信息清盘 (8)2.6信息查询 (9)2.7源程序 (11)3设计结果与分析 (22)3.1菜单函数功能测试 (22)4.2输入功能函数测试 (23)3.3输出功能函数测试 (23)3.4清盘功能函数测试 (23)3.5存盘功能函数测试 (24)3.6查询功能函数测试 (24)总结 (26)参考文献 (27)1 系统功能概述1.1 系统功能实现的法是先定义一个二叉树,该二叉树上的每个结点由三个元素组成:姓名、指向它左孩子的指针、以及指向它右孩子的指针构成。
该家谱管理系统将信息用文件的法进行存储管理,再从文件中将成员信息以递归的法创建二叉树。
该输入成员信息的法是将父亲结点存上父亲的信息,然后父亲结点的左孩子存上母亲的信息,母亲结点的右孩子存上孩子的信息。
(1)定义结构体结构体为表示一个对象的不同属性提供了连贯一致的法,结构体类型的说明从关键词struct开始,成员可以由各种数据类型混合构成,成员甚至还可以是数组或者其他类型的结构,但是,结构体中不能包含自身定义类型的成员。

二叉树的现实中典型例子二叉树是一种常用的数据结构,它具有广泛的应用。
下面列举了十个二叉树在现实中的典型例子。
一、文件系统文件系统是计算机中常见的二叉树应用之一。
文件系统中的目录和文件可以组织成一棵树,每个目录称为一个节点,而文件则是叶子节点。
通过树的结构,我们可以方便地对文件和目录进行管理和查找。
二、组织架构企业或组织的组织架构通常可以用二叉树来表示。
每个部门可以看作是一个节点,而员工则是叶子节点。
通过组织架构树,我们可以清晰地了解到企业或组织内部的管理层级关系。
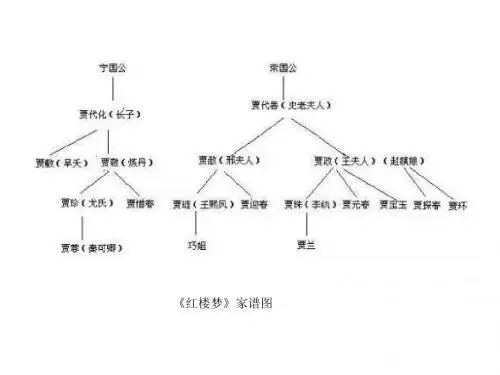
三、家谱家谱是一个家族的血缘关系的记录,一般可以用二叉树来表示。
每个人可以看作是一个节点,而父子关系则是节点之间的连接。
通过家谱树,我们可以追溯家族的历史和血缘关系。
四、编译器编译器是将高级语言转换为机器语言的程序。
在编译过程中,编译器通常会使用语法分析树来表示源代码的结构。
语法分析树是一种特殊的二叉树,它将源代码表示为一个树状结构,方便进行语法分析和编译优化。
五、数据库索引数据库中的索引是一种用于提高数据查询效率的数据结构。
常见的索引结构包括B树和B+树,它们都是二叉树的变种。
通过索引树,数据库可以快速地定位到需要查询的数据,提高数据库的检索性能。
六、表达式求值在数学计算中,表达式求值是一项重要的任务。
通过使用二叉树,我们可以方便地表示和计算表达式。
二叉树的叶子节点可以是操作数,而内部节点可以是运算符。
通过遍历二叉树,我们可以按照正确的顺序对表达式进行求值。
七、电路设计在电路设计中,二叉树也有广泛的应用。
例如,我们可以使用二叉树来表示逻辑电路的结构,每个门电路可以看作是一个节点,而连接线则是节点之间的连接。
通过电路设计树,我们可以方便地进行电路的布线和优化。
八、图像处理图像处理是一项常见的计算机技术,而二叉树在图像处理中也有重要的应用。
例如,我们可以使用二叉树来表示图像的像素信息,每个像素可以看作是一个节点,而像素之间的关系则是节点之间的连接。

教你如何搭建一颗二叉树并实现二叉树的四种遍历方式(详解四种遍历方式)一,四种遍历二叉树的方式1.根据访问结点操作发生位置命名**(前中后)序**NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。
(简洁记法"根左右") ** LNR:** 中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。
(简洁记法"左根右")LRN:后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
(简洁记法"左右根")由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtree)和R(Rightsubtree)又可解释为根、根的左子树和根的右子树。
NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
示例:如图是一颗二叉树,1.首先我们来求它的前序遍历结果ABDEC2,中序遍历结果DBEAC3,后序遍历:DEBCA2.二叉树的层序遍历设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历如上图:层序遍历结果为: ABCDE二,接着我们用代码来实现一颗树并且求他的遍历结果import java.util.ArrayList;import java.util.LinkedList;import java.util.List;import java.util.Queue;class Node{ //写一个节点类public char val;public Node left;public Node right;public Node(char val) {this.val = val;}}public class TestTree {public static Node buildTree(){ //构造出一棵树Node a = new Node('A'); //创建树的结点Node b = new Node('B');Node c = new Node('C');Node d = new Node('D');Node e = new Node('E');a.left = b; //把各个结点按照树的结构链接起来a.right = c;b.left = d;b.right = e;return a; //返回树的根节点}public static void preOrder(Node root){ //树的先序遍历if(root == null){ //如果是空树就返回return;}System.out.print(root.val + " "); //访问当前根结点的值preOrder(root.left); //递归访问访问左子树preOrder(root.right); //递归访问右子树}public static void inOrder(Node root){if(root == null){return;}inOrder(root.left);System.out.print(root.val + " ");inOrder(root.right);}public static void postOrder(Node root){if(root == null){return;}postOrder(root.left);postOrder(root.right);System.out.print(root.val + " " );}public static List<List<Character>> levelOrder(Node root) { if(root == null) {return new ArrayList<>();}List<List<Character>> res = new ArrayList<>(); //创建一个二维List内部List用来存储每层的数据Queue<Node> queue = new LinkedList<Node>();queue.add(root);while(!queue.isEmpty()){int count = queue.size(); //每次循环获取到的size为上次循环新进入的结点List<Character> list = new ArrayList<>();while(count > 0){Node node = queue.poll();list.add(node.val);if(node.left != null)queue.add(node.left);if(node.right != null)queue.add(node.right);count--;}res.add(list);}return res;}public static void main(String[] args) {Node tree = buildTree();//调用构造树方法System.out.println("先序遍历:");preOrder(tree);System.out.println();System.out.println("中序遍历:");inOrder(tree);System.out.println();System.out.println("后序遍历:"); postOrder(tree);System.out.println();System.out.println("层序遍历:");List<List<Character>> list = levelOrder(tree) ; System.out.println(list);}}结果展示:。

《数据结构》课程实训报告题目:家谱树完成人:专业班级:学号:指导教师:年月日1.题目与要求1.1问题提出本人计划编写一个家谱管理系统,主要用来管理家族成员的基本信息。
1.2本系统涉及的知识点结构体,数组,循环,函数,分支,指针1.3功能要求1、确定整个程序的功能模块。
实现程序的主界面,要对主界面的功能选择输入进行容错处理。
2、实现单个结点信息的录入。
3、对录入日期信息进行合法性检验。
4、采用改变字体颜色的方式突出显示主界面的功能项。
5、计算从出生日期到死亡日期的实际天数6、若家谱树为空,则新建家谱树。
实现成员节点的添加。
基本功能中可以强制要求所有成员不同名,即不考虑同名情况(符合小家族的实际情况)。
7、添加成员节点时,可以选择将新添加的节点作为整个家谱的上一代祖先,或者将新添加的节点作为某个现有成员的孩子。
8、作为某个现有成员的孩子,根据给出的父节点的姓名将该结点添加到相应位置,注意,针对某一父节点,添加第一个孩子和其它孩子的区别。
9、要求在孩子兄弟二叉树中按各个孩子的年龄进行排序。
10、将家谱树保存到二进制文件。
注意,不能保存空白节点。
11、从文件读入家谱信息,重建孩子兄弟二叉树形式的家谱。
12.从文件中读出所有节点信息到一个数组中,然后按一年中生日的先后进行快速排序。
13、按姓名查询家谱成员并显示该成员的各项信息。
14、给出某一成员的姓名,删除该成员和该成员的所有子孙。
15、成员信息的修改。
信息修改时要给出选择界面让用户选择需要修改的信息项。
基本功能中可以限定不容许修改父亲姓名和本人姓名。
对日期信息进行修改时要进行检验。
16、实现层次递进的方式显示整个家谱,显示结果应该体现家谱树的结构。
17、按各种关键字进行查询,要求给出关键字选择界面,并显示符合查询条件的节点信息。
18、信息统计基本要求包括:平均身高,平均寿命,男女成员各多少,平均家庭人口数目(假定每个成员构成一个家庭,该家庭的家庭成员是指成员本人和他的孩子,即家庭人口数=孩子数+1)。

数据结构_家谱管理系统【数据结构_家谱管理系统】一、引言家谱是记录家族成员关系的重要文献,传统的家谱管理方式已经无法满足现代社会的需求。
为了更好地管理家族信息,提高家族成员之间的联系和交流,我们设计并开发了一款家谱管理系统。
本文将详细介绍该系统的设计和实现。
二、系统概述家谱管理系统是一个基于数据结构的软件应用,旨在帮助用户管理家族成员的信息,包括姓名、性别、出生日期、配偶、子女等。
系统提供了多种功能,包括添加、删除、修改、查询、统计等操作,方便用户对家谱信息进行维护和管理。
三、系统设计1. 数据结构选择在家谱管理系统中,我们选择了树这种数据结构来表示家族关系。
每个节点代表一个家庭成员,节点之间通过指针连接,形成家族的层级结构。
2. 数据模型设计家族成员的信息可以通过一个结构体来表示,包括姓名、性别、出生日期等字段。
每个节点除了包含成员信息外,还包含指向配偶的指针和指向子女的指针。
3. 系统功能设计家谱管理系统提供了以下功能:(1) 添加成员:用户可以输入成员信息,系统根据用户输入创建一个新的节点,并将其插入到适当的位置。
(2) 删除成员:用户可以指定要删除的成员,系统会删除该成员及其所有子孙节点。
(3) 修改成员信息:用户可以选择要修改的成员,然后输入新的信息进行更新。
(4) 查询成员信息:用户可以通过姓名、出生日期等条件查询成员信息。
(5) 统计家族人数:系统可以统计家族的总人数、男性人数、女性人数等信息。
四、系统实现1. 数据结构实现我们使用C语言来实现家谱管理系统。
通过定义一个节点结构体,使用指针来连接各个节点,实现家族关系的表示和管理。
2. 功能实现(1) 添加成员:根据用户输入的信息,创建一个新节点,并将其插入到适当的位置。
插入操作需要遍历树来找到合适的位置。
(2) 删除成员:根据用户指定的成员,删除该节点及其所有子孙节点。
删除操作需要递归地遍历树。
(3) 修改成员信息:根据用户选择的成员,更新其信息。

数据结构(二叉树)家谱管理系统数学与计算机学院课程设计说明书课程名称: 数据结构与算法课程设计课程代码:题目: 二叉树生成家谱年级/专业/班:学生姓名:学号:开始时间: 2015 年 12 月 09 日完成时间: 2015 年 12 月 29 日课程设计成绩:指导教师签名:年月日目录(小三黑体,居中)1 需求分析 (6)1.1任务与分析 (6)1.2测试数据 (6)2 概要设计 (7)2.1 ADT描述 (7)2.2程序模块结构 (8)2.3各功能模块 (9)3 详细设计 (11)3.1结构体定义 (11)3.2 初始化 (12)3.3 插入操作 (14)3.4 查询操作 (17)4 调试分析 (19)5 用户使用说明 (20)6 测试结果 (20)结论 (25)附录 (26)参考文献 (27)摘要随着计算机科学技术、计算机产业的迅速发展,计算机的应用普及也在以惊人的速度发展,计算机应用已经深入到人类社会的各个领域。
计算机的应用早已不限于科学计算,而更多地应用在信息处理方面。
计算机可以存储的数据对象不再是纯粹的数值,而扩展到了字符、声音、图像、表格等各种各样的信息。
对于信息的处理也不再是单纯的计算,而是一些如信息存储、信息检索等非数值的计算。
那么,现实世界的各种数据信息怎样才能够存储到计算机的内存之中,对存入计算机的数据信息怎样进行科学处理,这涉及计算机科学的信息表示和算法设计问题。
为解决现实世界中某个复杂问题,总是希望设计一个高效适用的程序。
这就需要解决怎样合理地组织数据、建立合适的数据结构,怎样设计适用的算法,以提高程序执行的时间效率和空间效率。
“数据结构”就是在此背景下逐步形成、发展起来的。
在各种高级语言程序设计的基本训练中,解决某一实际问题的步骤一般是:分析实际问题;确定数学模型;编写程序;反复调试程序直至得到正确结果。
所谓数学模型一般指具体的数学公式、方程式等,如牛顿迭代法解方程,各种级数的计算等。

家谱的实现与设计
首先,数据的收集和管理是实现家谱的基础。
可以通过采访家族成员、查阅历史文献和公共数据库等方式收集家族成员的个人信息和关系。
这些
信息可以包括姓名、性别、出生日期、父母、配偶、子女等。
在数据管理
方面,可以选择使用数据库来存储和管理数据,数据库可以提供高效的数
据检索和管理功能。
家谱的功能扩展是为了提供更多的价值和服务。
除了基本的家族成员
关系和血统记录功能之外,可以考虑添加其他功能如全球定位系统(GPS)跟踪家族成员的活动轨迹、上传和分享家族照片和视频等。
另外,可以与
社交媒体和云存储平台进行集成,使得家谱的信息能够更方便地与亲友共
享和访问。
此外,在实现家谱时还要考虑数据的隐私和安全保护。
可能有些家族
成员对于个人信息的公开程度有所不同,因此应该提供不同的权限设置,
使得每个家族成员可以控制自己信息的公开程度。
同时,应该采用措施保
护数据的安全,如数据加密、身份验证等。
最后,实现和设计家谱需要考虑到用户的使用体验。
用户的使用体验
包括界面的简洁和美观、功能的便捷和稳定等。
在开发过程中可以进行用
户测试和反馈收集,及时修复和改进存在的问题。
同时,也可以添加一些
生动有趣的元素,如家族故事、名言警句等,增强用户对于家谱的兴趣和
参与度。
总之,实现和设计家谱需要考虑数据收集和管理、用户界面设计、功
能扩展、数据隐私和安全保护以及用户体验等方面。
通过合理的规划和设
计,可以创建一个方便、实用且引人入胜的家谱,让家族成员能够更好地了解和连接彼此,传承家族文化和记忆。
二叉树的建立及相关算法的实现
二叉树是一种特殊的树结构,它只允许每个节点最多有两个子树,每
个节点被称为父节点,它的子节点分别被称为左子节点和右子节点。
二叉
树的结构可以用来表示复杂的数据结构,对数据进行查询和存储,并能够
实现各种复杂的算法。
由于二叉树的结构比较简单,因此建立二叉树的技术不复杂。
通常,
我们从一个空二叉树开始,每次向树中添加一个节点,以完成树的建立。
在这里,我们主要介绍二叉树的建立,它是一种特殊的二叉树,其特点是,对于任意一个节点,它的左子树上所有节点的值均小于它的节点值,而它
的右子树上所有节点的值均大于它的节点值。
建立二叉树的一般步骤如下:
(1)构建一个空的二叉树。
(2)从根节点开始,比较插入节点和该节点的值。
(3)如果插入节点的值大于该节点的值,则插入节点放在右子树;
如果插入节点的值小于该节点的值,则插入节点放在左子树;
(4)假设一个新节点X,将要插入到该节点Y为根节点的子树中,
如果X的值大于Y的值,则将X插入到右子树上,否则将X插入到左子树上。
(5)插入过程中,继续比较X和左右子树的值。
基于二叉树的族谱生成系统的设计与实现族谱是家族世系传承的记录,是一个家族的历史和文化的宝库。
然而,传统的手工写作方式存在着繁琐工作量、易于出错、维护不方便等问题。
为了更好地管理和维护族谱,我们可以借助计算机科学的思想和技术实现一款族谱生成系统。
本系统基于二叉树作为数据结构,实现了一个族谱生成系统,可以支持多人同时使用。
具体实现步骤如下:1.确定数据结构。
我们选择二叉树作为数据结构,因为二叉树可以很好地描述一个家族的族谱结构。
每个节点代表一个人,它包含了人的姓名、性别、出生日期、死亡日期等信息。
每个节点最多有两个子节点,分别代表先祖和后代关系。
2. 实现数据录入模块。
用户可以通过输入框分别输入每个节点的信息,或者通过导入E某cel文件的方式批量录入信息。
3. 实现数据导出模块。
用户可以将族谱导出为E某cel或PDF格式,方便共享和传播。
4.实现族谱查询模块。
用户可以通过姓名、出生日期、亲戚关系等关键词进行查询,并可快速定位到对应的节点。
6.实现权限管理模块。
由于家族信息涉及个人隐私,系统应该具备一定的权限管理功能,例如管理员可以对数据进行修改,普通用户只能进行查询。
7.实现系统设置模块。
系统设置功能包括主题色调、字体大小、默认导出格式、默认排序方式等,可以让用户根据个人喜好进行个性化设置。
总体而言,基于二叉树的族谱生成系统可以有效地解决传统手工写作方式存在的问题,并可以大大提高家族管理的效率和便捷程度。
同时,系统应该不断完善和升级,加强安全性和易用性,请使用者谨慎保管数据和密码。
家谱管理系统 -数据结构大作业家谱管理系统数据结构大作业在当今数字化的时代,信息管理系统在各个领域都发挥着重要作用。
家谱作为家族历史和传承的重要记录,也需要一个高效、便捷的管理系统来保存、整理和查询相关信息。
本次数据结构大作业,我将深入探讨家谱管理系统的设计与实现。
一、需求分析家谱管理系统的主要用户包括家族成员和对家族历史感兴趣的研究者。
系统需要满足以下基本需求:1、能够存储家族成员的详细信息,如姓名、出生日期、逝世日期、籍贯、职业等。
2、支持家族关系的建立和维护,如父子、母子、夫妻等关系。
3、提供便捷的查询功能,用户可以根据姓名、出生日期、关系等条件快速找到所需的家族成员信息。
4、支持家谱的可视化展示,以清晰呈现家族成员之间的关系结构。
5、具备数据的添加、删除和修改功能,以保证家谱信息的及时更新。
二、数据结构选择为了有效地存储和管理家谱数据,我们需要选择合适的数据结构。
考虑到家谱中家族成员之间的层次关系,树结构是一个理想的选择。
在这里,我们可以使用二叉树来表示家族关系。
每个节点代表一个家族成员,节点中存储成员的相关信息。
父节点与左子节点表示父子关系,父节点与右子节点表示父女关系。
另外,为了提高查询效率,我们还可以结合哈希表来存储家族成员的信息。
通过哈希函数将成员的关键信息(如姓名)映射到哈希表中的特定位置,从而实现快速的查找和访问。
三、系统功能模块设计1、数据录入模块提供友好的用户界面,方便用户输入家族成员的信息。
对输入的数据进行合法性检查,确保信息的准确性和完整性。
2、数据存储模块利用选择的数据结构(二叉树和哈希表)将家族成员的信息进行存储。
确保数据的安全存储,防止数据丢失或损坏。
3、查询模块支持多种查询条件,如按姓名、出生日期、关系等进行查询。
快速返回查询结果,并以清晰的方式展示给用户。
4、关系维护模块允许用户添加新的家族成员,并建立其与其他成员的关系。
支持修改和删除家族成员的信息及关系。
二叉树遍历前序中序后序算法嘿,朋友,今天咱们聊聊二叉树的遍历,听上去有点复杂,其实一点都不难,就像吃瓜一样轻松!先来简单介绍一下,二叉树就像家里的家谱树,每个节点代表一个家庭成员,左右两个孩子代表着它的“后代”。
而遍历嘛,就是咱们要找出树上的每一个成员,看看他们在干啥。
首先是前序遍历,听这个名字就知道,它是先看爸爸,然后看左边的孩子,最后再看右边的。
这就像咱们去亲戚家串门,进门先跟长辈打招呼,再去找小朋友玩,先礼后兵,懂不懂?这样一来,整个树就都在咱的掌控之中,简直是如虎添翼。
再说这中序遍历,简单得很,就是先看左边,再看爸爸,最后再看右边。
就像咱们吃饭,先把青菜吃了,接着吃主食,最后来个甜点,吃得心满意足。
通过这种方式,咱们能得到一个排好序的结果,简直是个小吃货的心愿。
然后就是后序遍历,听名字就觉得有点神秘。
它的顺序是先看左边的孩子,再看右边的,最后才是爸爸。
这个遍历方式就像是收拾家,先把玩具放回去,再把书整理好,最后再把桌子擦一擦,整个过程干净利落,谁看了都得点赞!这样一来,不论是前、中、后,咱都能把树上的每一个节点清清楚楚地遍历一遍,真是爽快!可能会遇到一些难缠的树,比如不平衡的二叉树,这时候就像是一个在打怪的游戏,咱们得运用聪明才智,找到最优解。
你要是用前序遍历的话,能迅速找到每个节点,可是要是用后序遍历,那可就需要更多的耐心和时间。
每一种遍历方法都有它独特的魅力,就像每个人的性格,各有千秋,谁也不能小看谁!说到这里,咱们还得提提递归和非递归的方法。
递归就像是个循环的故事,永远在重复,直到找到结果;而非递归呢,就是更为直接,像一刀切的方式,让人省心省力。
每种方式都有它的优缺点,选哪个好,得看你自己的情况,真是一个聪明的选择题呢!哎,提到遍历,大家最关心的就是效率问题了。
前序、中序、后序,各有高低,性能的差异就像爬山,谁能跑得快,谁就能早到山顶。
不过别担心,只要有方法,效率就会提高,想要在这棵树上玩得开心,最重要的就是要选择合适的遍历策略。
课程设计报告课程名称《数据结构》课题名称排序综合专业班级学号姓名联系方式指导教师20 11 年12 月21 日目录1. 问题陈述 (3)2.设计方法阐述 (3)2.1总体规划 (3)2.2功能构想 (4)2.2.1增加成员 (4)2.2.2修改成员资料 (5)2.2.3删除成员 (6)2.2.4打开家谱 (7)2.2.5新建家谱 (8)2.2.6保存家谱 (10)2.2.7查看某代信息 (11)2.2.8按姓名查找 (12)2.2.9按生日查找 (12)2.2.10查看成员关系 (13)2.2.11按出生日期排序 (14)2.3板块整合 (15)2.4调试分析 (19)3.总结 (19)4. 测试结果 (20)1.问题陈述家谱用于记录某家族历代家族成员的情况与关系。
现编制一个家谱资料管理软件,实现对一个家族所有的资料进行收集整理。
支持对家谱的存储、更新、查询、统计等操作。
并用计算机永久储存家族数据,方便随时调用。
2.设计方法阐述2.1总体规划在动手编制程序之前,先要做好程序的规划,包括程序储存数据所用的结构,数据类型等等,只有确定了数据类型和数据结构,才能在此基础上进行各种算法的设计和程序的编写。
首先是考虑数据类型。
在家谱中,家族成员是最基本的组成部分,对于家族管理中,已经不能再进行细分了,所以选定家族成员作为数据的基本类型,并在程序中定义COperationFamilytree 类。
其中COperationFamilytree 类的各种属性可以根据需要进行添加或删除,从日常生活应用的角度出发,制定了COperationFamilytree 类中包含了一下属性:char name[MAX_CHARNUM]; //姓名Date birthday; //出生日期In tsex; //性别char addr[MAX_CHARNUM]; //基本资料int live; //健在否Date deathday; //死亡日期int ChildNums(Person pNode) ; //返回pNode孩子数intInSiblingPos(Person pNode); //返回pNode在其兄弟中的排行为方便计算机进行比较,在familytree类的某些属性中用数字代替了某些不会改变的字符串,譬如性别(1代表男,0代表女)、判断是否健在(1为是,0为否)。