第六章 误差椭圆(cehui2010)
- 格式:ppt
- 大小:2.53 MB
- 文档页数:75


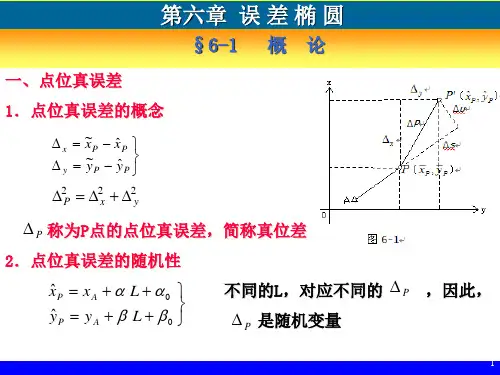
Padding投影误差椭圆误差椭圆,英文名称是error ellipse,是指待定点位置各方向上误差分布规律的椭圆。
点位误差曲线一种典型的曲线,作图也不方便,因此降低了他的实用价值。
但是它的形状与以E、F为长短半轴的椭圆很相似,此椭圆称为点位误差椭圆,即误差椭圆。
φE、E、F称为误差椭圆的参数。
通过原点P的线段PA与误差椭圆的交点,为PA的纵向误差,与该线段垂直的线段PB,与误差椭圆的交点为PA的纵向误差。
应用在测量工作中,特别是在精度要求较高的工程测量中,往往利用点位误差椭圆对布网方案进行精度分析。
其中s定义椭圆的规模,可以是任意的数(例如,s=1)。
现在的问题是如何选择s,使得所得到的椭圆规模代表我们所选择的置信水平(例如,95%的置信水平对应于s=5.991)。
我们的2D数据从零协方差的高斯分布中采样得到。
这意味着x值和y值也是高斯分布。
因此,等式(2)的左手侧实际上代表独立正态分布数据样本的平方和。
根据所谓的卡方(Chi-Square)分布,高斯数据点平方的总和是已知的。
卡方分布用“自由度”的形式定义,它表示未知量的数目来。
在我们的例子中,有两个未知数,因此自由度是二。
因此,我们可以很容易地获取上述和的概率,通过计算卡方似然,s等于一个特定的值。
事实上,由于我们感兴趣的是置信区间,我们正在寻找s小于或等于某个特定值的概率,这个特定值可以用累积卡方分布得到。
由于统计人员都是懒惰的(这个翻译我也是醉了【好吧,其实就是我翻译的】原文为“As statisticians are lazy people”期待大家可以给出更好的翻译),我们通常无法尝试计算这个概率,而只是看一个概率表。




误差椭圆,也被称为置信椭圆或测量误差椭圆,是在统计学和测量学中广泛使用的一个概念。
主要用于表示二维数据点的分布、测量误差的范围或不确定性。
它由三个主要参数定义:中心、主轴和次轴。
中心:这是误差椭圆的几何中心,代表了所有测量数据的平均位置或最可能的位置。
在理想的情况下,如果我们有无限精确的测量设备,所有的测量数据都会落在这个点上。
然而,在现实世界中,由于各种因素的影响,如设备误差、环境噪声等,测量数据通常会在这个点附近分布。
主轴:主轴是误差椭圆的长轴,代表了数据点分布的主要方向。
它的长度通常被定义为包含一定比例(例如,68%,95%或99%)测量数据的椭圆的半径。
这个比例的选择取决于我们对误差的容忍度或我们对数据的信心水平。
主轴的方向也是非常重要的,因为它可以告诉我们哪些因素对测量结果的影响最大。
次轴:次轴是误差椭圆的短轴,与主轴垂直。
次轴的长度代表了数据点在垂直于主轴的方向上的分布范围。
与主轴一样,次轴的长度也被定义为包含一定比例测量数据的椭圆的半径。
如果次轴的长度小于主轴的长度,这意味着测量数据在主轴方向上的变化比在次轴方向上的变化更大,也就是说,某些因素对测量结果的影响较小。
这三个参数共同定义了误差椭圆,为我们提供了一个直观的方式来理解和表示二维测量数据的不确定性或误差范围。
通过分析和比较不同误差椭圆的这三个参数,我们可以更好地理解我们的测量系统的性能,找出可能的改进方向,以及更准确地解释我们的测量结果。


eep 椭圆概率误差摘要:1.椭圆概率误差的概念解释2.椭圆概率误差的计算方法3.椭圆概率误差的应用场景4.降低椭圆概率误差的方法5.总结正文:在统计学和机器学习中,椭圆概率误差(Ellipsoid Probability Error,简称eep)是一个重要的概念,它用来衡量模型预测结果的不确定性。
椭圆概率误差主要应用于贝叶斯学习中,帮助我们更好地理解模型预测的不确定性。
椭圆概率误差是基于椭圆几何的概念而来。
在二维空间中,椭圆表示的是一个固定长轴和短轴的椭圆形状。
在贝叶斯学习中,椭圆概率误差描述的是真实值在一个椭圆区域内分布的概率。
这个椭圆的形状和大小由模型参数和不确定性程度决定。
计算椭圆概率误差的方法主要包括以下几个步骤:1.估计模型参数:通过最大似然估计或贝叶斯估计等方法,得到模型参数的估计值。
2.计算不确定性:根据模型参数的估计值,计算预测结果的不确定性。
不确定性越大,椭圆的概率误差越大。
3.计算椭圆边界:根据不确定性,计算椭圆的边界。
边界上的点表示模型预测结果的不确定性最大,而边界内的点表示不确定性较小。
4.计算概率误差:根据椭圆边界,计算真实值落在椭圆内的概率。
椭圆概率误差在许多应用场景中具有重要意义,例如:1.导航系统:在导航系统中,椭圆概率误差可以帮助我们确定目标位置的不确定性,从而提高导航准确性。
2.金融风险管理:在金融领域,椭圆概率误差可以用于衡量投资组合的风险和收益,辅助投资者做出更明智的决策。
3.医疗诊断:在医学领域,椭圆概率误差可以帮助医生评估诊断结果的不确定性,降低误诊率。
为了降低椭圆概率误差,我们可以采取以下方法:1.增加数据量:更多的高质量数据可以提高模型的准确性,从而降低椭圆概率误差。
2.优化模型结构:选择更适合问题的模型结构,如深度学习模型,可以降低模型的预测不确定性。
3.改进参数估计方法:使用更先进的参数估计方法,如贝叶斯优化,可以提高参数估计的准确性,进而降低椭圆概率误差。

《两种模型误差的可区分性及其可靠性理论》读书报告李春福(120091217)湖北·武汉·洪山区鲁磨路388号,中国地质大学信息工程学院1200926,430074摘要:本文通过对误差的一般性认识,进而了解和学习了两种模型误差的可区分性及其可靠性理论。
通过学习,我基本掌握了其研究的指导思想和处理问题的方法,最后以独特的方式,来总结两种模型误差的可区分性及其可靠性理论的认识和学习心得。
关键词:误差模型误差可区分性可靠性一、引言到目前为止,我们应对误差的方法大体可归纳为:1、粗差,设定限差M,大于M就舍去,小于M就认为没有粗差,这样就存在两类误差,不是误差、而被舍去和是粗差而接受为无差值。
2、偶然误差采用平差模型进行平均分配误差,以使观测值在限差内。
3、系统误差一般设置参数,作为一个未知数进行平差,在《误差理论与可靠性理论》第三章得到详细论述。
二、补偿误差与粗差的同时性(提出问题)我们在学习本书的过程中,一个重要的术语是模型误差,它与系统误差构成了人们正确研究误差理论的难点和热点。
因为现实中,我们总是习惯用模型和定量描述的方法去研究客观世界及其规律,由于人们知识等的限制,在选择模型时就会出现选择模型误差,这种误差与系统误差一般都会同时出现在所研究的过程中,传统的做法总是把他们分开处理,譬如说,在补偿系统误差时乃假设粗差已不存在,而在粗差检测时又假设系统误差已经改正。
事实上,这种假设的前提几乎是不可能出现的,在摄影测量加密时,这两类不同的误差是经常是同时存在且相互影响的。
所以对于系统误差的补偿、粗差的检测和定位已经变形分析,人们总是希望所要研究的模型误差与其他模型误差能很好的想区分,就目前来说,单个被选假设下的可靠性理论发展已经很成熟,所以作者在本书第六章专门强调从单个备选假设下的可靠性理论发展到两个备选假设下的可靠性理论——可区分行理论是十分必要的。
对于单个备选假设下的可区分性问题,一般是依托扩展的高斯--马尔科夫模型研究。