基于非参数统计方法的收入分配差距的实证检验_刘瀑
- 格式:pdf
- 大小:1.28 MB
- 文档页数:3

非参数统计方法概览非参数统计方法是一种不依赖于总体分布形态的统计方法,它不对总体分布做出任何假设,而是通过对样本数据的排序、计数和排名等操作,来进行统计推断和假设检验。
非参数统计方法在实际应用中具有广泛的适用性和灵活性,能够处理各种类型的数据,包括连续型数据、离散型数据和顺序型数据等。
本文将对非参数统计方法进行概览,介绍其基本原理和常用方法。
一、基本原理非参数统计方法的基本原理是通过对样本数据的排序和计算,来推断总体的统计特征。
与参数统计方法相比,非参数统计方法不需要对总体分布形态做出任何假设,因此更加灵活和适用于各种情况。
非参数统计方法主要基于样本的秩次信息,通过比较和计算秩次差异来进行统计推断和假设检验。
二、常用方法1. Wilcoxon符号秩检验Wilcoxon符号秩检验是一种非参数的假设检验方法,用于比较两个相关样本的差异。
它基于样本的秩次信息,通过计算秩次差异的总和来判断两个样本是否存在显著差异。
Wilcoxon符号秩检验适用于小样本和非正态分布的情况。
2. Mann-Whitney U检验Mann-Whitney U检验是一种非参数的假设检验方法,用于比较两个独立样本的差异。
它基于样本的秩次信息,通过计算秩次和来判断两个样本是否存在显著差异。
Mann-Whitney U检验适用于小样本和非正态分布的情况。
3. Kruskal-Wallis单因素方差分析Kruskal-Wallis单因素方差分析是一种非参数的假设检验方法,用于比较多个独立样本的差异。
它基于样本的秩次信息,通过计算秩次和来判断多个样本是否存在显著差异。
Kruskal-Wallis单因素方差分析适用于小样本和非正态分布的情况。
4. Friedman多因素方差分析Friedman多因素方差分析是一种非参数的假设检验方法,用于比较多个相关样本的差异。
它基于样本的秩次信息,通过计算秩次和来判断多个样本是否存在显著差异。
Friedman多因素方差分析适用于小样本和非正态分布的情况。

非参数统计的方法与应用非参数统计是指一类不依赖于任何参数假设的统计方法,特别是不依赖于任何分布假设的统计方法。
相较于参数统计,非参数统计具有更广泛的适用范围和更强的鲁棒性,适用于数据形式和规模不确定的情况。
本文将介绍非参数统计的方法和应用,希望读者可以对此有更深刻的认识。
一、非参数统计的基础非参数统计的基础是经验分布函数、核密度估计和分位数等概念。
经验分布函数是指样本分布函数,它给出了样本观测值小于等于某个值的概率。
核密度估计是将样本的实际观测值拟合为一个概率密度函数,通过选择核函数和带宽大小来控制拟合的平滑程度。
分位数是一种描述样本分布位置的指标,例如中位数、分位数和分位点。
在实际应用中,非参数统计方法可以用于拟合和检验数据的分布、比较两个或多个数据集之间的差异,以及探究变量之间的关系等。
因为它不需要假设特定的分布结构,因此可以在数据形式、规模和质量方面具有更大的灵活性。
二、非参数统计方法的分类根据数据类型和假设类型,非参数统计方法可以划分为不同的类型。
常用的非参数统计方法主要包括:1. 秩和检验:适用于从两个或多个独立样本中检验两个或多个总体的中位数是否相等。
2. Wilcoxon符号秩检验:适用于从两个独立样本中检验两个总体的中位数是否相等。
3. Kruskal-Wallis单因素方差分析:适用于从两个或多个独立样本中比较几个相互独立的总体的中位数是否相等。
4. Mann-Whitney U检验:适用于从两个独立样本中检验两个总体的分布是否相等。
这是一个非参数的等价于t检验的方法。
5. Kolmogorov-Smirnov检验:适用于从两个或多个样本中检验两个总体的分布是否相等。
6. Anderson-Darling检验:适用于从一个样本中检验给定某一个分布类型的数据是否符合该分布。
例如,我们可以使用这个检验来检验数据是否服从正态分布。
7. 卡方检验:适用于检验两个或多个与分类变量相关的样本间比例差异是否存在显著差异。

非参数统计方法简介随着数据科学和统计学领域的不断发展,非参数统计方法作为一种灵活且强大的工具被广泛运用在各种领域中。
与参数统计方法相比,非参数统计方法不依赖于总体参数的具体分布,因此在数据分布未知或偏离常规分布时表现得更为优越。
本文将对非参数统计方法进行简要介绍,包括其基本原理、常用方法以及在实际应用中的一些典型场景。
基本原理非参数统计方法是一种基于数据本身特征进行推断的统计分析方法,不对总体参数作出具体的假设。
其核心思想是利用数据的排序、排名等非参数化的特征进行分析,从而得出统计推断结论。
以Wilcoxon秩和检验为例,该检验是一种常用的非参数假设检验方法,适用于样本数据不满足正态分布假设的情况。
它基于样本数据的秩次比较来判断两个总体的位置差异是否显著。
通过对数据进行排序、赋予秩次并计算秩和统计量,可以在不依赖于具体分布假设的情况下进行假设检验。
常用方法除了Wilcoxon秩和检验外,非参数统计方法还包括Mann-Whitney U检验、Kruskal-Wallis检验、Spearman相关性分析等多种常用方法。
这些方法在实际应用中具有广泛的适用性,能够有效应对不同数据类型和分布形态下的统计推断问题。
Mann-Whitney U检验适用于独立两样本的位置差异检验,Kruskal-Wallis检验则扩展至多样本情形。
Spearman相关性分析是一种用于衡量两变量之间非线性相关性的方法,通过秩次的计算来评估两变量的相关性程度。
实际应用非参数统计方法在各行业和领域中都有着重要的应用价值。
在医学领域,由于很多指标的分布并不服从正态分布假设,非参数统计方法成为临床研究中常用的工具之一。
在金融领域,对于涉及风险评估和收益分析的数据,非参数统计方法能够更准确地捕捉数据背后的规律,提供有效的决策支持。
总的来说,非参数统计方法以其灵活性和适用性在数据分析中发挥着重要的作用。
在实际应用中,了解不同非参数方法的原理和适用条件,能够更好地进行数据分析和推断,提高统计分析的准确性和效率。

使用非参数统计检验进行分析的指南1980年代末,汉斯拉伊大学(Hansraj College)经济学荣誉毕业生的平均薪酬约为每年100万印度卢比。
这一数字大大高于80年代初或90年代初毕业的人们。
他们平均水平如此之高的原因是什么呢?沙鲁克·汗是印度收入最高的名人之一,1988年毕业于汉萨拉吉学院,当时他在那里攻读经济学荣誉学位。
这一点,以及还有很多的例子都会告诉我们,平均值并不是很好的可以指示出数据的中心在哪里。
它可能会受到异常值的影响。
在这种情况下,查看中位数是更好的选择。
它是一个很好的数据中心的指示器,因为一半数据位于中间值以下,另一半位于中间值上方。
到目前为止,一切都很好——我相信你已经看到人们早些时候提出了这一点。
问题是没有人告诉你如何进行像假设检验这样的分析。
统计检验用于制定决策。
为了使用中位数进行分析,我们需要使用非参数检验。
非参数测试是分布独立的检验,而参数检验假设数据是正态分布的。
说参数检验比非参数检验更加的臭名昭著是没有错的,但是前者没有考虑中位数,而后者则使用中位数来进行分析。
接下来我们就进入非参数检验的内容。
**注意:**本文假定你具有假设检验,参数检验,单尾检验和双尾检验的先决知识。
1.非参数测试与参数测试有何不同?当总体参数的信息完全已知时使用参数检验,而当总体参数的信息没有或很少使用非参数检验,简单的说,参数检验假设数据是正态分布的。
然而,非参数检验对数据没有任何分布。
但是参数是什么?参数不过是无法更改的总体特征。
让我们看一个例子来更好地理解这一点。
一位老师使用以下公式计算了班级学生的平均成绩:看上面给出的公式,老师在计算总分时已经考虑了所有学生的分数。
假设学生的分数是准确的,并且没有遗漏的分数,你是否可以更改学生的总分数?并不可以。
因此,平均分被称为总体的一个参数,因为它不能被改变。
2.什么时候可以应用非参数检验?让我们看一些例子。
1.比赛的获胜者由名词决定,而名次是根据越过终点线来进行排名的。

非参数统计方法非参数统计方法是一种统计学中的重要概念,它不依赖于总体的具体分布形式,而是利用样本数据进行推断和分析。
与参数统计方法相比,非参数统计方法更加灵活和广泛适用,并且不需要对总体进行特定的假设。
本文将介绍非参数统计方法的原理、常用的方法和应用领域。
一、非参数统计方法的原理非参数统计方法的核心思想是基于样本数据来进行推断,而不需要对总体的分布形式做出先验假设。
非参数统计方法主要利用统计排序和秩次来进行推断分析,因此非参数统计方法也常被称为秩次统计方法或分布自由方法。
非参数统计方法的基本原理包括以下几个方面:1. 统计排序:对样本数据进行排序,将每个观测值按照大小进行排列,得到一系列秩次。
2. 秩次:将每个观测值与排序后的位置相对应,得到每个观测值的秩次。
3. 检验统计量:通过计算秩次之间的差异来判断总体分布是否存在差异。
4. 非参数假设检验:通过计算检验统计量的概率分布,判断总体分布是否符合我们的假设。
二、常用的非参数统计方法1. 秩和检验(Mann-Whitney U检验):用于比较两个独立样本是否来自同一总体。
2. 秩和差检验(Wilcoxon符号秩检验):用于比较两个相关样本是否来自同一总体。
3. 克鲁斯卡尔-瓦里斯检验:用于比较三个或更多独立样本是否来自同一总体。
4. 费希尔精确检验:用于比较两个分类变量之间的关联性。
5. 秩和相关检验(Spearman等级相关系数):用于比较两个变量之间的相关性。
三、非参数统计方法的应用领域非参数统计方法在各个领域都有广泛的应用,以下列举几个常见的应用领域:1. 医学研究:非参数统计方法可以用于比较两种治疗方法的效果,判断是否存在显著差异。
2. 经济学研究:非参数统计方法可以用于分析收入差距、失业率等经济指标的差异。
3. 生态学研究:非参数统计方法可以用于比较不同区域的生物多样性指标,评估生态系统的稳定性。
4. 社会科学研究:非参数统计方法可以用于分析社会调查数据,比较不同群体的行为差异。

统计学习理论中的非参数检验方法统计学习理论是一种研究如何通过数据来进行预测和决策的学科。
它提供了一种对数据进行分析和推断的方法,其中非参数检验方法起着重要的作用。
非参数检验方法是指不对总体分布做任何假设或者对总体分布进行某种特定形式的参数化约束的统计检验方法。
一、概述统计学习理论中的非参数检验方法是一种基于样本数据的统计推断方法,它不依赖于总体分布的具体形式,而是基于样本数据的经验分布进行推断。
与参数检验方法相比,非参数检验方法具有更广泛的适用性和更强的鲁棒性。
二、常用的非参数检验方法1. Wilcoxon秩和检验:Wilcoxon秩和检验是一种非参数的配对样本检验方法,用于比较两组相关样本的均值差异。
它基于样本数据的秩次来进行推断,不依赖于总体分布的具体形式。
2. Mann-Whitney U检验:Mann-Whitney U检验是一种非参数的独立样本检验方法,用于比较两组独立样本的均值差异。
它基于样本数据的秩次来进行推断,不依赖于总体分布的具体形式。
3. Kruskal-Wallis H检验:Kruskal-Wallis H检验是一种非参数的多组独立样本检验方法,用于比较多组独立样本的均值差异。
它基于样本数据的秩次来进行推断,不依赖于总体分布的具体形式。
4. Friedman检验:Friedman检验是一种非参数的多组配对样本检验方法,用于比较多组配对样本的均值差异。
它基于样本数据的秩次来进行推断,不依赖于总体分布的具体形式。
5. 卡方检验:卡方检验是一种非参数的拟合优度检验方法,用于检验观察值与理论值之间的偏差程度。
它适用于分类变量的分析,不依赖于总体分布的具体形式。
三、非参数检验方法的优缺点非参数检验方法具有以下优点:1. 不依赖于总体分布的具体形式,对数据的偏离程度不敏感;2. 适用性广泛,可以应用于不同类型的数据和问题;3. 无需对参数进行估计,简化了统计推断的过程。
然而,非参数检验方法也存在一些限制:1. 样本量要求较大,否则可能出现效果不稳定的情况;2. 结果的解释相对复杂,不如参数检验方法直观。
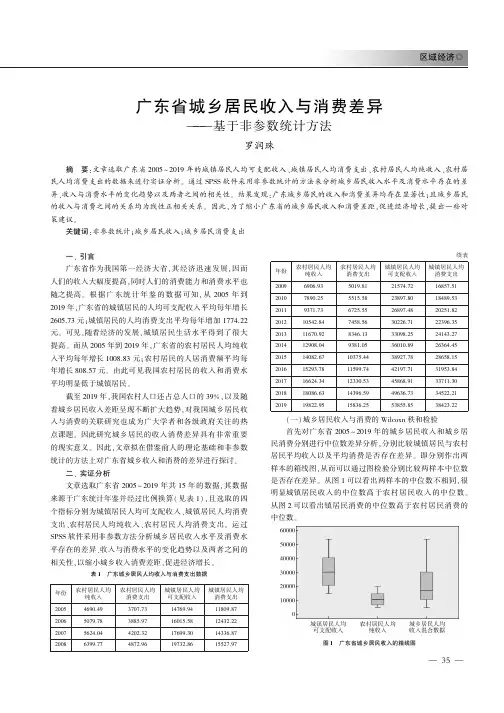
区域经济Һ㊀广东省城乡居民收入与消费差异基于非参数统计方法罗润珠摘㊀要:文章选取广东省2005~2019年的城镇居民人均可支配收入㊁城镇居民人均消费支出㊁农村居民人均纯收入㊁农村居民人均消费支出的数据来进行实证分析ꎮ通过SPSS软件采用非参数统计的方法来分析城乡居民收入水平及消费水平存在的差异㊁收入与消费水平的变化趋势以及两者之间的相关性ꎮ结果发现:广东城乡居民的收入和消费差异均存在显著性ꎻ且城乡居民的收入与消费之间的关系均为线性正相关关系ꎮ因此ꎬ为了缩小广东省的城乡居民收入和消费差距ꎬ促进经济增长ꎬ提出一些对策建议ꎮ关键词:非参数统计ꎻ城乡居民收入ꎻ城乡居民消费支出一㊁引言广东省作为我国第一经济大省ꎬ其经济迅速发展ꎬ因而人们的收入大幅度提高ꎬ同时人们的消费能力和消费水平也随之提高ꎮ根据广东统计年鉴的数据可知ꎬ从2005年到2019年ꎬ广东省的城镇居民的人均可支配收入平均每年增长2605.73元ꎻ城镇居民的人均消费支出平均每年增加1774.22元ꎮ可见ꎬ随着经济的发展ꎬ城镇居民生活水平得到了很大提高ꎮ而从2005年到2019年ꎬ广东省的农村居民人均纯收入平均每年增长1008.83元ꎻ农村居民的人居消费额平均每年增长808.57元ꎮ由此可见我国农村居民的收入和消费水平均明显低于城镇居民ꎮ截至2019年ꎬ我国农村人口还占总人口的39%ꎬ以及随着城乡居民收入差距呈现不断扩大趋势ꎬ对我国城乡居民收入与消费的关联研究也成为广大学者和各级政府关注的热点课题ꎮ因此研究城乡居民的收入消费差异具有非常重要的现实意义ꎮ因此ꎬ文章拟在借鉴前人的理论基础和非参数统计的方法上对广东省城乡收入和消费的差异进行探讨ꎮ二㊁实证分析文章选取广东省2005~2019年共15年的数据ꎬ其数据来源于广东统计年鉴并经过比例换算(见表1)ꎬ且选取的四个指标分别为城镇居民人均可支配收入㊁城镇居民人均消费支出㊁农村居民人均纯收入㊁农村居民人均消费支出ꎮ运过SPSS软件采用非参数方法分析城乡居民收入水平及消费水平存在的差异㊁收入与消费水平的变化趋势以及两者之间的相关性ꎬ以缩小城乡收入消费差距ꎬ促进经济增长ꎮ表1㊀广东城乡居民人均收入与消费支出数据年份农村居民人均纯收入农村居民人均消费支出城镇居民人均可支配收入城镇居民人均消费支出20054690.493707.7314769.9411809.8720065079.783885.9716015.5812432.2220075624.044202.3217699.3014336.8720086399.774872.9619732.8615527.97续表年份农村居民人均纯收入农村居民人均消费支出城镇居民人均可支配收入城镇居民人均消费支出20096906.935019.8121574.7216857.5120107890.255515.5823897.8018489.5320119371.736725.5526897.4820251.82201210542.847458.5630226.7122396.35201311670.928346.1333098.2524143.27201412908.049381.0536010.8926364.45201514082.6710375.4438927.7828658.15201615293.7811599.7442197.7131953.84201716624.3412330.5345868.9133711.30201818086.6314396.5949636.7334522.21201919822.9515836.2553855.8538423.22㊀㊀(一)城乡居民收入与消费的Wilcoxn秩和检验首先对广东省2005~2019年的城乡居民收入和城乡居民消费分别进行中位数差异分析ꎬ分别比较城镇居民与农村居民平均收入以及平均消费是否存在差异ꎮ即分别作出两样本的箱线图ꎬ从而可以通过图检验分别比较两样本中位数是否存在差异ꎮ从图1可以看出两样本的中位数不相同ꎬ很明显城镇居民收入的中位数高于农村居民收入的中位数ꎮ从图2可以看出镇居民消费的中位数高于农村居民消费的中位数ꎮ图1㊀广东省城乡居民收入的箱线图53图2㊀广东省城乡居民消费的箱线图然后根据以上问题对城乡居民收入和城乡居民消费分别做出如下假设检验问题:H0:MX=MYꎬ城乡居民收入不存在差异H1:MX>MYꎬ城镇居民收入高于农村居民收入H0:MX1=MY1ꎬ城乡居民消费不显著差异H1:MX1>MY1ꎬ城镇居民消费高于农村居民消费表2是城镇居民收入(X)数据和农村居民收入(Y)数据分别在它们在混合样本中的秩ꎬ求其秩和W分别为335和130ꎮ由此可得两样本的秩和存在明显差异ꎬ拒绝原假设即城镇居民收入与农村居民收入不存在显著差异ꎮ然后在SPSS软件中我们进行非参数检验中的Wilcoxon秩和检验ꎬ得到检验统计量的p值为0.001ꎬ因此ꎬ在0.01的显著性水平下ꎬ我们不接受原假设ꎬ即城镇居民收入显著高于农村居民收入ꎮ表3是城镇居民消费(X1)数据和农村居民消费(Y1)数据分别在它们在混合样本中的秩ꎬ求其秩和W分别为337和128ꎮ由此可得两样本数据秩和存在显著性差异ꎬ拒绝原假设即城镇居民消费与农村居民消费不存在显著差异ꎬ接受备择假设即城镇居民消费高于农村居民消费支出ꎮ然后在SPSS软件中我们进行非参数检验中的Wilcoxon秩和检验ꎬ得到检验统计量的p值为0.001ꎬ因此ꎬ在0.01的显著性水平下ꎬ我们不接受原假设ꎬ即城镇居民消费显著高于农村居民消费支出ꎮ表2㊀城镇居民和农村居民收入数据在混合样本中的秩农村居民人均纯收入秩城镇居民人均可支配收入秩4690.49114769.94125079.78216015.58145624.04317699.30166399.77419732.86186906.93521574.72207890.25623897.80219371.73726897.482210542.84830226.712311670.92933098.252412908.041036010.8925续表农村居民人均纯收入秩城镇居民人均可支配收入秩14082.671138927.782615293.781342197.712716624.341545868.912818086.631749636.732919822.951953855.8530表3㊀城镇居民和农村居民消费数据在混合样本中的秩农村居民人均消费支出秩城镇居民人均消费支出秩3707.73111809.87133885.97212432.22154202.32314336.87164872.96415527.97185019.81516857.51205515.58618489.53216725.55720251.82227458.56822396.35238346.13924143.27249381.051026364.452510375.441128658.152611599.741231953.842712330.531433711.32814396.591734522.212915836.251938423.2230㊀㊀(二)城乡居民收入与消费的趋势检验在非参数统计中ꎬ运用Cox-Stuart趋势存在性检验来检验一组数据的变化趋势ꎬ该方法是一种不依赖于趋势结构的快速判断趋势是否存在的方法ꎮ为保证数对同分布且不受局部干扰ꎬCox-Stuart提出最好的拆分点是数列中位于中间位置的数ꎬ在无趋势的原假设下ꎬ检验统计量服从参数为数对个数和发生概率为0.5的二项分布ꎮ因此对此问题做出以下假设检验问题:H0:数据序列无趋势ꎬH1:数据序列有增长趋势表4㊀广东省城乡居民人均收入与消费的Cox-Stuart检验序号农村之间的差额Di=xi-xi+cꎬc=7城镇之间的差额Di=xi-xi+cꎬc=7人均纯收入人均消费支出人均可支配收入人均消费支出1-6980.43-4638.40-18328.31-12333.402-7828.26-5495.08-19995.31-13932.233-8458.63-6173.12-21228.48-14321.284-8894.01-6726.78-22464.85-16425.875-9717.41-7310.72-24294.19-16853.796-10196.38-8881.01-25738.93-16032.687-10451.22-9110.70-26958.37-18171.40㊀㊀由表4可知ꎬ广东省的城乡居民人均收入与消费的前后不同时期的差值都为负ꎬ都存在上升趋势ꎮ同样ꎬ通过计算ꎬ63区域经济Һ㊀知道上述4个检验的统计量都是K=min(S+ꎬS-)=S+=0ꎬ其中S+表示正的Di数目ꎬS-表示负的Di的数目ꎮ在SPSS软件中用回归分析检验ꎬ得到检验的p值为0.0078ꎬ在0.01的显著性水平下ꎬ拒绝原假设ꎬ即数据序列有增长趋势ꎮ因此也说明符合经济理论和经济发展规律ꎮ(三)城乡居民收入与消费的相关性分析在非参数统计中ꎬ常用Spearman秩相关性检验来检验对不服从正态分布㊁总体分布未知等情况下来描述变量之间的相关性ꎮ那么Spearman秩相关性检验的假设检验问题为:H0:X与Y不相关ꎬH1:X与Y是相关的ꎮ采用Spearman秩相关检验具体分析城镇居民和农村居民的人均收入与消费的关系的散点图分别如图3和图4所示ꎮ图3㊀城镇居民人均收入与消费的散点图图4㊀农村居民人均收入与消费的散点图从图3和图4可知ꎬ无论是城镇居民还是农村居民ꎬ其人均收入与消费都呈现了高度的正相关关系ꎮ为了验证其显著性ꎬ在SPSS软件中进行相关性检验ꎮ城镇居民人均收入与消费和农村居民人均收入与消费的Spearman秩相关系数都是1ꎬ再进行单边检验ꎬ由结果可知两者的相关性在0.01都显著ꎬ因此在显著性水平拒绝原假设ꎬ认为城镇居民人均收入与消费之间以及农村居民人均收入与消费之间都存在正相关关系ꎮ换句话说随着城镇居民人均收入水平的提高ꎬ居民人均消费水平也会提高ꎻ随着农村居民人均收入水平的提高ꎬ居民人均消费水平也会提高ꎮ三㊁总结文章运用非参数统计的方法对广东省的2005~2019年的城乡居民人均收入与消费水平差异分析后ꎬ则有以下结论:1)城乡的收入和消费水平存在较大的差距ꎻ2)城乡居民收入和消费水平均随着我国经济水平的上升而呈现上升的趋势ꎻ3)广东省城乡的收入与消费均呈现高度的正相关关系ꎬ即随着收入水平的提高ꎬ消费水平也会随之提高ꎮ根据许多学者的研究成果可知ꎬ收入是决定消费水平的主要因素ꎮ因此城乡居民的消费差异的根本原因是城乡居民多年来的收入差距ꎮ因此ꎬ缩小城乡居民的收入水平差距将会促进城乡居民消费水平的缩小ꎬ而缩小城乡居民收入水平差距实质上就是充分提高农民的收入水平ꎬ即缩小了城乡居民的收入差距ꎮ因此ꎬ文章提出了以下对策建议:1)稳定农民农业收入ꎬ做好农村剩余劳动力转移工作ꎬ增加农民非农业收入ꎮ2)对农民的扶贫工作要精准到位ꎬ加大帮扶力度ꎮ3)加大对农村的财政投入力度ꎬ并鼓励社会投资的跟进和参与ꎮ4)全面推动农业生产模式改革ꎬ为现代农业的发展营造条件ꎮ5)加速构建新型农村金融服务体系ꎬ为农民收入的快速增加提供支撑等ꎮ参考文献:[1]刘瀑.河南城乡居民收入与消费差异的非参数检验[J].统计与决策ꎬ2017(16):115-117.[2]吴喜之ꎬ赵博娟.非参数统计[M].北京:中国统计出版社ꎬ2013.[3]夏蓉.我国城乡居民消费差异实证分析[J].消费导刊ꎬ2008(5):2.[4]李景海ꎬ王克林.基于状态空间模型和多层模型的广东城乡消费差异研究[J].统计与信息论坛ꎬ2013ꎬ28(7):76-81.作者简介:罗润珠ꎬ广东财经大学ꎮ73。

第十一届山东省统计科研优秀成果奖获奖名单书籍类一等奖1. 山东省民营企业创新驱动发展模式构建研究杨涛山东英才学院二等奖1. 中国企业转型升级的知识创新与产业技术创新战略联盟问题研究王玉梅烟台南山学院2. 中国国民收入核算矩阵的编制与应用研究周南南等青岛科技大学山西财经大学3. 统计实务徐冰济宁市统计局三等奖1. 扶贫互助资金合作社运行现状及运行机制研究——以山东省为例高杨山东青年政治学院2. 海洋生态经济模型构建与应用研究陈东景青岛大学3. 2016青岛市统计课题研究与分析汇编李刚青岛市统计局4. 供应琏视角的营运资金管理研究张先敏青岛科技大学5. 临沂统计治理现代化探索与实践张凡春临沂市统计局优秀奖1. 基于性别视角的收入分配研究高艳云青岛大学2. “十二五”青岛发展统计报告李刚青岛市统计局3. 薛暮桥在山东解放区时的对敌经济斗争张凡春等临沂市统计局4. 煤矿动力灾害危险性预测方法研究边平勇山东科技大学5. 教育统计的世界——统计原理与SPSS应用张黎青岛大学6. 统计学基础阮红伟青岛大学7. 山东高校社会服务能力研究李波临沂大学课题类一等奖1. 济南市科技创新报告肖辉等济南市统计局2. Hadoop技术在政府统计大数据处理中的应用研究胡宝芳等山东女子学院3. 建立人才发展统计体系的对策研究司江伟等中国石油大学(华东)4. 青岛工业转型升级实证探析与提质增效路径研究尹正德青岛市统计局5. 山东半岛城市群空间结构与产业结构的耦合关系及优化研究单宝艳等山东建筑大学6. 不同养老模式下养老机构老年人医疗服务评价研究吴炳义等潍坊医学院7. 大数据背景下的超网络统计分析方法及应用研究索琪青岛科技大学8. 一体化住户调查数据质量控制及评估方法研究王象永等国家统计局山东调查总队9. 大数据视角下基于“一套表”的工作模式研究张芳丽等山东农业工程学院10. 青岛市从需求侧总量拉动向供给侧结构推动的经济发展路径研究张德祥青岛市统计局11. 乘势经济新常态力拔江北第一县——“千年商都”即墨案例研究宋书国即墨市统计局12. 基于空间统计技术的中国省域人力资本空间聚集和溢出效应研究徐珊等山东青年政治学院13. 山东半岛蓝色经济区发展优势统计研究郭思亮齐鲁师范学院14. 现代科学技术在统计工作中的应用研究王霞等山东建筑大学15. 低碳建筑评价指标体系及模型构建刘中文等山东女子学院16. 生产性服务业与制造业的互动与融合——基于投入产出模型的研究杜培林等济南大学17. 生产安全事故大数据处理及其开发应用研究周江涛等滨州学院二等奖1. 新型城镇化驱动下山东省单位型就业空间布局优化策略研究赵虎等山东建筑大学2. 山东省农产品流通体系效率测评及影响因素研究王能等德州学院吕晶等枣庄市统计局3. 转型升级结硕果突破瓶颈谋振兴——“十二五”末期枣庄市工业经济转型升级探析4. 山东半岛城市群区域资源环境与经济协调发展测度模型研究李娜等山东协和学院5. 山东省生态效率统计测度方法研究宗科等山东科技大学6. 提升制造业产业竞争力与实现经济快速发展关系问题研究徐晶济宁市统计局7. 低碳经济下我国区域金融生态环境综合评价研究高朋钊等山东女子学院8. 经济时序数据的季节调整方法及应用研究刁艳华等山东协和学院9. 济南市区域性经济中心建设的数量分析孙夕良等济南市统计局10. 山东省城乡社会保险非均等程度测定及其改进路径研究黄俊祺等山东女子学院11. 大数据背景下旅游统计创新研究单铭磊等山东青年政治学院王东翔青岛市统计局12. 青岛市金融业和“财富管理金融综合改革试验区”现状评价及加快发展的对策研究13. 新常态下枣庄县域经济协同发展问题研究陈成等枣庄市统计局14. 山东省各地市城镇化水平与城镇居民生活质量协调发展分析戴金辉等山东工商学院15. 加快“文化+”融合发展推动文化产业换档提速林清济南市统计局16. 县级政府资产负债表及其信息披露研究国凤兰等山东科技大学17. 综合化网络问卷调查平台建设与应用研究盛雯雯等日照职业技术学院18. 德州市产业结构与城镇化关系研究张学荣德州市统计局19. 山东高端装备制造业产业竞争力评价指标体系构建与实证研究田刚元等滨州学院20. 山东省宏观税负水平测度及其与经济增长关系的实证分析徐维爽齐鲁师范学院21. 即墨市“智慧统计”建设与应用研究宋书国即墨市统计局杨世涛等德州市统计局22. 京津冀协同发展背景下德州市区域经济实力比较及加快发展路径研究23. 上市公司会计稳健性与CFO性别相关性的模型构建与统计分析吕宏等山东女子学院24. 山东省区域循环经济统计指标体系与评价方法研究李婧等山东协和学院25. 青岛市市北区产业竞争力评价薛纪宾市北区统计局26. 山东省智慧城市建设评价模型研究李吉英等滨州学院27. 居民生活质量评价指标体系研究王象永等国家统计局山东调查总队28. 新型城镇化发展质量评价研究王战友等山东管理学院29. 基于二维不确定语言变量定性数据的统计分析与应用研究荣丽丽等山东广播电视大学30. 基于贝叶斯统计的供应琏金融风险测度分析刘建勇等鲁东大学31. 基于SPSS多元线性回归分析的大学生创业影响模型构建研究赵德忠等淄博职业学院32. 滨州市“四上”企业现状、问题简析及促进纳新工作对策王智童等滨州市统计局33. 依托物联网无缝数据采集技术提升工业能源数据统计质量对策研究贾萍等山东青年政治学院于海生等鲁东大学34. 青荣城际铁路对山东半岛蓝色经济区旅游业影响的测度研究及实证分析35. 基于公司治理视角的企业内部控制评价体系研究——以中小企业为例谭振梅等山东女子学院三等奖1. 培育枣庄经济增长新动能的战略思考沈道坦等枣庄市统计局2. 从经济普查看德州市工业发展王惠德州市统计局3. 基于SWOT分析模型的青岛市民营工业经济发展现状及对策研究刘俐娜青岛市统计局4. 基于Agent建模与仿真的低碳生态城市统计测度方法及应用研究刘中文等山东女子学院5. 抢抓“全域旅游”新机遇打造旅游战略性支柱产业周晓静曲阜市统计局6. 生态文明建设统计测度方法研究于法家等菏泽市统计局7. 城市商业综合体数据贡献现状调查报告刘晓彬市南区统计局8. 电子商务对经济增长贡献的统计评价指标体系研究李华等淄博职业学院9. 新常态下临沂经济增长动力研究程凯等临沂市统计局10. 基于生命周期理论的绿色房地产评价指标体系构建研究刘桂菊等泰山学院11. 变点检测问题的现代非参数统计推断及其应用李强等泰山学院12. 服务业品牌价值评估指标体系研究李画画等山东科技大学13. 我国新能源企业资本结构与企业绩效关系的实证分析赵克杰山东建筑大学14. 以技改投资为突破创新驱动青岛工业转型升级王元青岛市统计局15. 基于环境承载力分析的山东省低碳旅游景区门票动态定价研究高朋钊等山东女子学院16. 基于因子分析的山东省文化产业竞争力定量评价与提升对策研究刘凯等滨州学院17. 新型城镇化测度及其与经济发展关系统计研究——以山东城市群为例于晓红山东英才学院18. 缺失数据下可加部分非线性模型的统计推断及应用周小双等德州学院19. 青岛海洋经济发展路径及前景目标的展望与研究刘俐娜青岛市统计局20. 银信合作视阈下影子银行统计监测研究林飞等山东协和学院21. 基于因子分析法的智慧旅游综合评价研究张孝丽等山东协和学院22. 莱西市石墨烯产业发展研究报告孙世盛莱西市统计局23. 山东省汽车运输企业能源消耗统计模型的研究李秀芬等日照职业技术学院24. 基于ESDA的山东省城市化格局及演变研究王林林等滨州学院25. 基于循环经济的企业可持续发展评价指标体系研究吕鹏山东英才学院26. 山东省产业结构调整与能源消费的相关性研究崔元丽等山东协和学院27. 新型城镇化对青岛市居民生活用能影响的实证研究王东翔青岛市统计局28. 黄河三角洲高效生态经济区能源利用效率评价研究黄利国等滨州学院29. 基于Hadoop的数据挖掘在统计工作中的应用研究王黎峰等山东青年政治学院30. 枣庄绿色发展的SWOT分析于亚波等枣庄市统计局31. “互联网+”时代的政府统计创新研究侯延香等山东建筑大学安洪庆等潍坊医学院32. 基于倾向指数模型的城乡基本医疗卫生服务可及程度测度及实证应用研究33. 空间统计方法在传染病研究中的应用杨丽等潍坊医学院34. 基于云平台的海量交通数据统计分析孙洪峰等山东女子学院35. 从战略性新兴产业发展看枣庄工业转型吕晶等枣庄市统计局36. 城市轨道交通综合效益的产生与作用机理研究张国宾等李沧区统计局37. 文化产业统计系统优化路径探析郭继文山东交通学院38. 黄河三角洲绿色制造绩效评价及实施模式研究王伟等滨州学院39. 基于个人效用与健康的最优退休年龄实证分析张智涛等滨州学院40. 基于ISO26000中国产品海外形象评价指标体系研究吕臣等泰山学院41. 贝叶斯分层分析模型及其应用研究张凡春等临沂市统计局42. 联网直报背景下区县政府统计管理体制优化研究王娜娜泰山区统计局43. 我国保险业统计分析与建模研究赵长利等山东交通学院44. 山东省循环经济测度指标与评价方法研究姜山等滨州学院45. 新常态经济背景下经济增长人力资本投入统计指标因素分析白丽苹等泰山医学学院46. 文化产业统计指标体系研究董凤鸣等菏泽学院47. 我国统计管理体制改革研究赵小燕等山东管理学院陈绍武等曲阜市统计局48. 释放政策减税红利激活企业发展动能——“营改增”对曲阜企业发展和财税收入影响的调研分析优秀奖1. 山东省食品产业创新能力综合评价研究王辉等德州学院2. 特征价格方法在房地产价格指数编制中的应用研究袁忠香等临沂大学3. 山东省上市公司商业信用风险机理与评估研究张文华等淄博职业学院4. 济南城镇中低收入阶层住房保障体系研究高斌等山东女子学院5. 山东省城市化进程中的城市治理研究——评估指标体系构建李晓泰山医学学院6. 移动互联时代山东零售服务业竞争力综合评价指标体系研究秦晓庆山东英才学院7. 空间统计方法及其在大气污染统计中的应用研究闫保英等山东农业工程学院8. 基于制度系统灰关联熵的城乡居民收入差距度量与实证分析刘伟等潍坊学院9. 当代女大学生创业意识调查与能力培养研究高斌等山东女子学院10. 推动我国能源利用效率的统计研究苏玉等日照职业技术学院11. 关于山东省制造业民营企业发展状况的调研分析谷振涛等山东英才学院12. 文化产业统计指标体系研究杨静等淄博职业学院13. 县级医院医疗质量评价指标体系研究李磊等泰山医学学院14. “互联网+”模式应用思考与研究——平度“农村淘宝”项目运纪春英平度市统计局营情况调研报告15. 枣庄电子商务市场机遇与挑战并存于亚波等枣庄市统计局16. 新常态下县区经济结构调整对能源消费影响的统计研究于晓丽等泰山区统计局17. 县乡统计方法制度改革研究尹德玉等日照职业技术学院18. 山东体育旅游文化产业统计指标体系研究刘林星等滨州学院19. 基于区位商视角下的山东省产业结构调整与就业结构变动的实证分析刘娜等滨州学院20. 基于模糊层次分析法的融资风险评价研究——以山东省建筑业许凤玉等滨州学院上市公司为例21. BSC视阈下山东省文化产业竞争力评价指标体系构建研究王申等等山东现代学院22. 大数据背景下企业众包模式运行效率统计测度研究李瑞雪等山东协和学院23. 山东省公立医院医疗服务质量评价体系及实证研究温艳等青岛大学24. 基于供给角度的枣庄市经济增长动力分析侯方等枣庄市统计局25. 新常态下枣庄市房地产业发展新特征研究孟祥焱等枣庄市统计局26. 黄河三角洲区域内金融资源配置与经济增长关系的统计分析研究彭伟等滨州学院27. 山东省文化产业与经济增长关系实证研究时亚栋等菏泽学院28. 基于云存储环境的非结构化数据存储研究徐栋等日照职业技术学院29. 政府部门间数据资源共享研究任敏等滨州学院30. 环保支出统计研究隋涛等滨州学院31. 非线性季节财务风险预警模型研究杨华等淄博职业学院32. 物流产业统计核心指标体系及管理研究解京淑等淄博职业学院33. 大数据时代电子商务产业数据管理与共享机制研究郑志新等聊城大学34. 地方政府性债务风险评估体系研究魏青琳等山东协和学院35. 工效学用户测评抽样设计及抽样精度研究李莉莉青岛大学36. 经济结构调整对能源消费影响的统计研究周志刚等潍坊学院37. 大数据背景下统计理论和方法创新研究报告康梅娟等临沂大学38. 大数据背景下政府统计管理及质量创新研究张晓敏等临沂大学39. 山东省民营企业国际化发展的切入路径与模式选择赵琳等山东英才学院40. 基于大数据的小微企业信息采集及挖掘研究赵红艳等山东英才学院41. 新型城镇化测度与经济发展关系统计研究张玲菏泽学院42. 基于实时数据交换的统计方法与平台研究陈卓艳等山东科技大学43. 大数据时代生产安全事故统计分析与预测方法研究黄培花等滨州学院44. 非结构化数据分析及应用研究董茜等山东管理学院45. 网络入侵异常行为检测统计方法研究冯敏等泰山医学学院46. 大数据环境下云计算技术在统计工作中的应用研究王晓燕等山东协和学院47. 抢抓“互联网+”重大机遇着力打造经济增长新引擎——曲阜市电子商务现状调研分析张婷婷等曲阜市统计局曲阜市人力资源和社会保障局48. 我国城乡居民收入水平与旅游消费的关系研究宗荃等山东女子学院49. 构建国家诚信体系背景下高校就业统计指标体系研究孙士生等临沂大学50. 时间序列数据的小波分析方法研究王怀亮等菏泽学院51. 曲阜市镇街主体功能区建设调研报告陈绍武等曲阜市统计局52. 大数据背景下政府统计模式改进研究王红娟等临沂大学53. 基于大数据技术的政府统计改进研究李明娟等临沂大学54. 低相关序列在统计信息安全中的应用任文丽等德州学院55. 随机辛算法在统计力学中的应用尹秀玲等德州学院56. 金融随机模型参数估计及其算法研究韩潇等山东农业工程学院57. 曲阜市企业上市资源情况调研报告陈绍武等曲阜市统计局曲阜市人力资源和社会保障局58. 现代信息技术在统计工作中的应用研究陈巩等滨州学院59. 基于S-粗集理论的数据分析模型及其在德州市经济数据统计中的应用于秀清等德州学院60. 建筑业总部与分部统计规范的实践讨论张祥伟等阳谷县统计局61. 基于Ontology的数据挖掘研究贾保先等聊城大学论文类一等奖1. 基于HADOOP的大数据描述统计分析宋廷山等齐鲁师范学院2. 我国公路运输价格指数编制研究——以济南市为例胡海清等山东英才学院3. 第三产业份额提升是结构红利还是成本病李翔等曲阜师范大学4. 补齐软实力“短板”拓展“走出去”空间——青岛市建筑业“一带一路”建设实施路径研究孙辉等青岛市统计局5. 基于内容分析法的中国节约集约用地政策演进分析吕晓等曲阜师范大学6. 我国金融发展与经济增长协调效应研究王文波等青岛大学7. 关于改进综合考核群众满意度调查工作的若干思考沈道坦枣庄市统计局8. 产业集群转型升级视阙下的区域创新平台构建——基于青岛西海岸经济新区的研究李治国等中国石油大学(华东)9. 制度变迁、路径依赖与经济增长的模型与实证分析——兼论中国制度红利杨友才青岛科技大学10. 基于线性协整与面板协整的失业保险基金支出促进就业功能研究董芳等滨州学院11. 中国产业结构高度化的空间关联效应分析——基于社会网络分析方法林春艳等山东财经大学二等奖1. 青岛民生服务业发展品质探析姚栋青岛市统计局2. 中国制造业全球价值链长度和上游度的测算及其影响因素分析——基于世界投入产出表的研究马风涛山东科技大学3. 平阴县金融运行分析报告李新平阴县统计局4. 青岛市快递业发展研究石岩青岛市统计局5. 基于SBM和Malmquist生产率指数的中国海洋经济效率评价研究赵林等曲阜师范大学6. 平阴县域经济的发展现状及分析麻荣玉等平阴县统计局7. 资本深化与我国消费率的关系研究丁建勋青岛理工大学8. 积极培育新业态和新商业模式助推消费品市场升级发展刘琴等槐荫区统计局9. 逐鹿江北:竞争力视野下的即墨市——全国十强县(市)比较分析研究赵玉梅即墨市统计局10. 城镇化进程中农户宅基地退出的决策行为及影响因素于伟等曲阜师范大学11. 组合类信用互换BDS的定价研究吴健华等济南大学12. 结构参数,出口固定投入成本与贸易扩展边际张凤青岛理工大学13. 中国财税政策的环境治理效应研究——基于省级面板数据的实证分析张玉青岛科技大学14. 基于实物期权法的海域使用权定价研究闻德美等山东科技大学15. 欠发达地区加快发展生产性服务业的路径研究李厚银菏泽市统计局16. 我国城镇社会保障均等化的省域差异及空间格局时涛等泰山医学院17. 城镇化水平与城镇居民生活质量协调发展的测度戴金辉等山东工商学院18. 中国上市公司信用风险研究:基于ZPP和KMV模型李莉莉青岛大学19. 基于非参数统计方法对股票收益率的实证分析孔令苹微山县统计局20. 基于变结构copula模型的股票市场分析刘昆仑齐鲁师范学院21. 改进的灰色预测模型及其应用沙秀艳等曲阜师范大学22. 大数据视角下关于跨部门基本单位名录库的思考陈爱伟等山东农业工程学院23. 滨州市生态环境质量综合评价陈淑清等滨州学院三等奖1. 从统计综合指数视角探寻青岛如何践行五大发展理念李刚青岛市统计局2. 复杂统计方法在黄海西海岸极端降水趋势及成因研究中的应用王怀亮等菏泽学院3. 临沂经济发展新常态特征及对策研究张凡春临沂市统计局4. 金融业发展对即墨市经济增长的贡献分析赵玉梅即墨市统计局5. 交通基础设施空间非均衡测度与区域经济增长研究吕承超青岛科技大学6. 互联网+时代对德州传统制造业转型的思考刘行德州市统计局7. 滨州市生产性服务业发展的现状与政策支持研究宋晓健滨州市统计局8. 即墨市战略性新兴产业发展情况探析丁松兵即墨市统计局9. 企业能源统计工作的探索与实践周红潍柴控股集团有限公司彭利达等山东管理学院10. 机构投资者是现金分红的内生动力吗——基于异质机构投资者的经验研究11. 基于非期望产出SBM模型的全要素能源效率测算王景波山东科技大学12. 大数据时代统计创新能力分析赵明霞阳谷县统计局13. 基于财政金融激励视角的特色小镇统计评估体系研究赵锦华潍坊滨海经济技术开发区中央商务区开发建设管理服务中心14. 要素价格扭曲、资本深化与我国消费率朱晓媛等青岛理工大学15. “中国梦”实现过程的中国经济总量和人民生活水平预测吴庆军曲阜师范大学16. 非寿险未决赔款准备金评估的平滑化方法研究邱艺伟滨州市统计局17. 基于改进LDA主题模型的社会网络话题发现算法iMLDA 仇丽青等山东科技大学18. 我国金融生态对经济增长影响的非线性特征解析逮进等青岛大学19. 时变参数状态空间模型估计研究吴健华等济南大学20. 非寿险公司经营风险统计模型研究闫春等山东科技大学21. 浅议新常态下工业结构调整的必然性赵明霞阳谷县统计局22. 新常态下济宁市产业转型升级问题探究孔令苹等微山县统计局23. 纵向数据下变系数部分非线性模型的经验似然推断周小双等德州学院24. 基于随机模拟的统计模型计算及实证分析邵伟等曲阜师范大学25. 内生性回收率与信用风险度量研究吴健华等济南大学26. 山东省县域经济的空间分异及其成因杜霞枣庄学院27. 因子模型中正交旋转方法的改进张颖等济南大学28. 基于GM(1,1)幂模型的振荡统计数据预测陈继光山东英才学院29. 社会转型时期城市阶层的阶梯消费王琪等青岛科技大学30. 中国低碳经济的现状与对策研究张庭发齐鲁师范学院31. 山东省移动终端消费习惯分析李雪萍等山东建筑大学山东省统计局32. 浅谈设施农业发展状况及对策研究范荣梅平阴县统计局33. 变结构pair copula模型在金融危机传染分析中的应用刘昆仑齐鲁师范学院优秀奖1. 山东省信息化与工业化融合水平测度及动态融合关系实证检验刁艳华等山东协和学院2. 应用新方法 HOMR-HOM均一化1961~2010年北疆最高和最低气温张延伟济南大学3. 滨州市城区苔藓植物主要重金属含量的调查与分析李玉玺等滨州学院4. 依法治统势在必行武颂沂水县统计局5. 输血病案质量影响因素及应对策略于龙广滨州医学院烟台附属医院6. 浅析二胎政策对社会经济的影响孔令苹微山县统计局7. 如何减小问卷调查中的调查员相关误差胡顺奇枣庄学院8. 基于组织层面变量企业文化的测量方法王炳成等山东科技大学9. 平阴县新型农村社区建设现状及问题的探讨范荣梅平阴县统计局10. 县域经济由经济增长型向统筹发展型的转变探析赵明霞阳谷县统计局11. 社区文化认同响应旅游开发的模型研究及个案分析单铭磊山东青年政治学院12. 欧元区国家银行风险与主权风险的关联性研究杨继梅青岛科技大学。

统计学中的非参数统计方法统计学是一门研究如何收集、整理、分析和解释数据的学科。
在统计学中,参数统计方法和非参数统计方法是两种常见的数据分析方法。
本文将重点介绍统计学中的非参数统计方法。
一、非参数统计方法的概念和特点非参数统计方法是指不对总体分布做出特定假设的一类统计方法,它不要求总体服从特定的概率分布,因此被广泛应用于各种实际问题的数据分析中。
与参数统计方法相比,非参数统计方法的主要特点包括灵活性高、使用范围广以及对数据的分布假设不敏感等。
二、非参数统计方法的应用领域非参数统计方法在各个学科领域都有广泛的应用,包括但不限于以下几个方面:1. 生物学领域:非参数统计方法常被用于生物医学研究中,比如在药物试验中评估不同治疗方案或药物的疗效。
2. 经济学领域:非参数统计方法在经济学研究中也有重要应用,比如用于分析收入分配的不平等性、评估政策的效果等。
3. 环境科学领域:非参数统计方法在环境科学领域的应用也较为常见,例如用于分析水质、空气质量等指标在不同区域的差异性。
4. 工程学领域:非参数统计方法在工程学中也被广泛使用,比如用于分析制造过程中的质量控制和性能评估等。
5. 社会学领域:非参数统计方法在社会学研究中的应用较多,如用于分析人口统计数据、教育程度对收入的影响等。
三、非参数统计方法的常见技术非参数统计方法包括多种常见的技术,以下介绍其中几个常用的技术:1. 秩和检验(Mann-Whitney U检验):用于比较两组独立样本的位置差异,特别适用于小样本情况或数据不服从正态分布的情况。
2. 威尔科克森秩和检验(Wilcoxon Signed-Rank Test):用于比较两组配对样本数据的位置差异。
3. 克鲁斯卡尔-瓦利斯检验(Kruskal-Wallis Test):用于比较多组独立样本间的位置差异,常用于替代方差分析。
4. 皮尔逊相关系数(Pearson Correlation):用于衡量两个连续变量之间的线性相关性。

第二届中国统计学年会分组报告(分会场)时间:10 月26 日地点:浙江工商大学下沙校区 A 教学楼分会场1——经济统计理论与方法专题(A)主持与评论人:赵彦云中国人民大学教授8:30~8:50傅德印兰州商学院多元统计分析方法检验体系的构建8:50~9:10李锐、向书坚中南财经政法大学信息学院统计学系基于非平稳的长记忆性检验理论及实证分析9:10~9:30刘洪、黄燕中南财经政法大学信息学院基于经典计量模型的统计数据质量评估方法9:30~9:50陈光慧、刘建平暨南大学经济学院统计学系基于卡尔曼滤波估计的连续性抽样调查研究主持与评论人:王仁曾华南理工大学教授9:50~10:10王斌会暨南大学经济学院统计系西格玛水平与不合格品率的关系研究10:10~10:25 茶歇10:25~10:45李晓玉、常宁上海财经大学统计学系上海市消费者信心指数编制研究10:45~11:05高艳云山西财经大学统计学院计算机价格指数的编制——基于hedonic 模型的研究主持与评论人:杨仲山东北财经大学教授11:05~11:25许永洪厦门大学经济学院计划统计系基于中国城市统计数据的CPI 偏差估计11:25~11:45孙宪华、张臣曦天津财经大学统计学院房屋特征的质量效应及其对房地产价格指数的影响——基于Hedonic 模型和Chow 检验的整合分析11:45~12:05叶瑞铃、郭晋源、谢邦昌、苏志雄台湾辅仁大学统计信息学系致理技术学院会计信息系资料采矿的未来趋势1 2:05~13:30 午餐主持与评论人:王力宾云南财经大学教授13:30~13:50张勇国家统计局统计教育中心将MPPS 抽样设计引入统计教学的思考13:50~14:10于忠义天津财经大学统计学院简明统计学术史纲要14:10~14:30张鸣芳、潘索贤上海财经大学统计学系中国主要价格指数季节变动模式测定研究主持与评论人:王艳明山东工商学院教授14:30~14:50柯蓉上海海事大学经济管理学院基于马尔可夫决策多阶段库存控制策略研究14:50—15:05 茶歇15:05—15:25黄恒君兰州商学院统计学院整体偏态分布情况下平均数问题研究15:25—15:45侯瑜东北财经大学经济与社会发展研究院突发水污染事件损失评估指标及估算方法分会场2——数理统计理论与方法专题G主持与评论人:许鹏湖南大学教授8:30~8:50蒋翠侠、许启发、张世英山东工商学院数学与信息科学学院多元条件Copula-GARCD-JSU 模型及应用8:50~9:10Miao-Hsiang Lin;Yu-Tai Hsieh Institute of Statistical Science Academia Sinica;NationalTaiwan Univeristy of Science and TechnologyExtendedFour-Parameter Beta-Binomial Model as a Mental Testing Mode9:10~9:30朱建平、靳刘蕊厦门大学计划统计系基于模型参数基展开的函数回归及其应用9:30~9:50吴继英、赵喜仓江苏大学统计系偏离-份额分析法空间模型及其应用主持与评论人:杨益民(南京财经大学教授)9:50~10:10邹幼涵、刘国传、陈瑞照、黄登源Department of Statistics and Information Science Fu JenCatholic University;Graduate Institute of Applied Statistics Fu Jen Catholic University;GraduateInstitute of Applied Statistics Fu Jen Catholic University多变量线性回归模型建构程序之研究10:10~10:25 茶歇10:25~10:45赵进文东北财经大学统计学院,中国人民大学应用统计科学研究中心异常值点对单位根检验的致命影响10:45~11:05喻开志、邹红西南财经大学统计学院西南财经大学消费经济研究所随机系数整值滑动过程主持与评论人:房祥忠(北京大学教授)11:05~11:25朱建平、方匡南厦门大学经济学院计划统计系有序秩聚类及对地震活跃期的分析11:25~11:45Sean Kuo Department of Statistics National Chengchi UniversityMulti-spectra CWT-based algorithm MCWT inmass spectra for peak extraction11:45~12:05Cheyu Hung College of Statistics Capital University of Economics and Business StatSoftHoldings Inc. Taiwan BranchPredictive Analysis for Quality Control1 2:05~13:30 午餐主持与评论人:郑明复旦大学教授13:30~13:50雷钦礼暨南大学经济学院统计学系非线性协和模型:理论与方法13:50~14:10顾蓓青、王蓉华上海师范大学数理信息学院威布尔分布场合步加试验和步降试验的效率比较分析14:10~14:30王蓉华、袁芳、雷平、徐晓岭上海师范大学数理信息学院,上海对外贸易学院商务信息学院指数分布串—并联混合系统产品的统计分析主持与评论人:朱建平厦门大学教授14:30~14:50吴鉴洪浙江工商大学统计与数学学院面板数据模型的诊断检验问题的研究14:50—15:05 茶歇15:05—15:25Ren-Dao Ye Tie-Feng Ma Song-Gui Wang 杭州电子科技大学财经学院Generalized inferences on the common mean of several inverse gaussian population15:25—15:45郭宝才浙江工商大学统计与数学学院一种带警戒限的均值图15:45—16:05王大荣、张忠占北京工业大学应用数理学院Simultaneous Variable Selection for Heteroscedastic Regression Models分会场3——国民经济核算B主持与评论人:李宝瑜山西财经大学教授8:30~8:50杨灿厦门大学计划统计系关于服务业统计若干问题的探讨8:50~9:10朱启贵上海交通大学安泰经济与管理学院我国国民经济核算体系改革与发展30 年9:10~9:30王永瑜兰州商学院统计学院资源租金核算理论与方法研究9:30~9:50尚红云、蒋萍东北财经大学统计学院能源消耗的双极分解模型及其在中国的应用主持与评论人:凌亢南京人口管理干部学院教授9:50~10:10魏瑾瑞、孙秋碧福州大学管理学院统计系资本服务及其测量——关于SNA2008 修订版的一个议题10:10~10:25 茶歇10:25~10:45刘丹丹东北财经大学经济与社会发展研究院未观测经济影响了中国经济增长吗10:45~11:05卢宁、李国平西安交通大学经济与金融学院基于EKC 框架的社会资本水平对环境质量的影响研究——来自中国1995-2006 面板数据主持与评论人:彭国富河北经贸大学教授11:05~11:25曹跃群、刘冀娜重庆大学贸易与行政学院,南开大学经济学院经济系第三产业资本存量地区差异及其成因11:25~11:45钱雪亚、王秋实浙江大学公共管理学院中国人力资本和物质资本水平:基于总资本框架的估算11:45~12:05王娟、李兴绪云南财经大学统计与数学学院工资上调的效应——基于投入产出价格模型的分析1 2:05~13:30 午餐统计方法在其它领域的应用(I1)主持与评论人:陈相成河南财经学院教授13:30~13:50田成诗东北财经大学统计学院中国有效就业量的测算(1978-2005)13:50~14:10张爱婷西安财经学院统计学院农村劳动力流动的经济增长效应测度及实证分析14:10~14:30徐映梅、程佩玲中南财经政法大学信息学院统计系2004 年国际贸易关系网络影响因素分析——基于40 个国家或地区的贸易流量矩阵数据主持与评论人:胡毅新疆财经学院教授14:30~14:50马树才、张华新辽宁大学经济学院教授公共就业服务体系效率研究14:50—15:05 茶歇15:05—15:25章迪平、孙敬水浙江工商大学基于技术进步的服务业发展方式转变实证研究——以浙江为例15:25—15:45陶然中国人民大学统计学院政府统计数据质量成本关系模型探讨15:45—16:05谷彬东北财经大学统计学院中国服务业技术效率测算与影响因素实证研究分会场4——统计方法在其它领域的应用(I2)主持与评论人:刘洪中南财经政法大学教授8:30~8:50许玉雪台北大学统计系台湾农业贸易自由化之政策仿真分析-TWAPS 系统之应用8:50~9:10苏为华、孔伟杰浙江工商大学统计学院,浙江大学基于知识产权保护的国际贸易和FDI 技术溢出效应研究9:10~9:30赵楠中央财经大学统计学院中国四大直辖市能源利用效果的对比分析9:30~9:50Tsung-Chi Cheng and Wei-jen Wen Department of Statistics National Chengchi University;Department of International Business National Chengchi UniversityDeterminants of Performing Arts Attendance in Taiwan: A Multivariate Probit Analysis主持与评论人:许玉雪台北大学教授9:50~10:10余厚强、蒋萍东北财经大学统计学院国际石油价格与国内石油价格波动关系研究10:10~10:25 茶歇10:25~10:45Su-Fen Yang Department of Statistics National Chengchi UniversityMONITORING A PROCESS USING VSI LOSS CONTROL CHARTS10:45~11:05许冰、曾菊英浙江工商大学统计与数学学院医疗服务价格联动机制研究——基于龙游县人民医院的数据分析主持与评论人:韩兆洲暨南大学教授11:05~11:25王鸿龙、姚修慎、蔡宗宪台北大学统计学系,元智大学资讯工程学系驾驶行为对油耗影响之研究11:25~11:45杨君琦、谢邦昌、刘晓雯、李信达辅仁大学企业管理系暨管理学,辅仁大学统计信息学系,国立中央大学企业管理研究所,国立中央大学企业管理研究所海洋产业与天然灾害研究之科技计划人力规划初探11:45~12:05郝枫、肖红叶天津财经大学统计学院要素-产品比价研究:国际经验与历史证据1 2:05~13:30 午餐主持与评论人:马树才辽宁大学教授13:30~13:50王桂芝、孙家彩、李洁南京信息工程大学数理学院关于我国人口发展趋势预测与结构分析13:50~14:10周福林河南财经学院统计学系人口普查数据的家庭人口学研究经济计量方法(H2)主持与评论人:杭斌山西财经大学教授14??0~14:30刘田、史代敏西南财经大学统计学院基于奇异值分解去势的线性与非线性趋势序列单位根检验14:30~14:50朱慧明、曾慧芳湖南大学工商管理学院基于MCMC 的贝叶斯变结构金融时序Garch 模型分析14:50—15:05 茶歇15:05—15:25戴丽娜郑州大学商学院基于Copula 函数的商业银行操作风险计量的研究15:25—15:45袁靖山东工商学院统计学院基于泰勒规则构建我国融入资产价格的最优货币政策规则及金融状况指数FCI分会场5——收入与消费专题(C)主持与评论人:刘杨中央财经大学教授8:30~8:50杭斌山西财经大学统计学院习惯形成下的缓冲储备行为8:50~9:10阮敬、纪宏首都经济贸易大学统计学院亲贫困增长的公理性标准及其测度指标评价9:10~9:30丛培华山东威海市统计局共比离差法优于基尼系数法9:30~9:50洪兴建、习明浙江工商大学统计与数学学院,深圳职业技术学院收入不平等指标的比较研究主持与评论人:赵卫亚浙江工商大学教授9:50~10:10姜磊南开大学经济学系我国现代部门劳动分配比例的变动趋势与影响因素——基于中国省级面板数据的分析10:10~10:25 茶歇10:25~10:45孙敬水、陈娟浙江工商大学统计与数学学院从分布分解的视角看收入不平等的变化10:45~11:05郭香俊、杭斌东北财经大学统计学院,山西财经大学统计学院城乡居民,谁更谨慎?——中国城乡居民预防性储蓄动机比较经济计量方法(H1)主持与评论人:王振龙陕西广播电视大学教授11:05~11:25王璐西南交通大学数学学院统计系中国股市和债市波动的变相关结构——基于门限混合COPULA 模型11:25~11:45许启发、蒋翠侠、王永喜山东工商学院统计学院组合投资决策的收益-风险分析框架11:45~12:05Ting-Pin Wu;Son-Nan Chen Department of Statistics,National Taipei University;Departmentof Banking and Finance NationalChengchi UniversityValuation of Interest Rate Spread Options in a Multifactor LIBOR Market Model1 2:05~13:30 午餐主持与评论人:汪荣明华东师范大学教授13:30~13:50许冰、叶娅芬浙江工商大学统计与数学学院基于理性预期模型的最优货币政策在我国的应用13:50~14:10李腊生、张岩天津财经大学统计学院我国上市公司财务危机的判断与预警——基于因子分析Logit 模型的经验证据14:10~14:30蒋翠侠、许启发、张世英山东工商学院统计学院基于多目标优化和效用理论的高阶矩动态组合投资14:30~14:50刘晓焕中南财经政法大学信息学院基于CVaR 的开放式股票基金市场风险的研究14:50—15:05 茶歇分会场6——经济增长与发展专题(E)主持与评论人:林洪广东商学院教授8:30~8:50蒋志华、白斌飞、李庆子成都信息工程学院统计系中国东部、中部及西部经济社会发展对比研究8:50~9:10孙蕾厦门大学经济学院计划统计系教育产出结构、资源配置与中国经济增长9:10~9:30顾六宝、王孟欣河北大学经济学院我国东西部均衡积累路径的模拟与分析主持与评论人:顾六宝河北大学教授9:30~9:50李金昌、曾慧浙江工商大学统计与数学学院基于金融市场发展的FDI 溢出与经济增长关系:省际面板数据研究9:50~10:10卢二坡安徽财经大学统计与应用数学学院转型期中国经济短期波动对长期增长影响的实证研究10:10~10:25 茶歇10:25~10:45施凤丹国家统计局统计科学研究所统计监测研究室中国能源消费与经济增长的实证研究:1978-200710:45~11:05程开明浙江工商大学统计与数学学院城市化、技术创新与经济增长主持与评论人:余华银安徽财经大学教授11:05~11:25白仲林、郭小力、史哲天津财经大学统计学院中国省级CPI 的俱乐部趋同性——CPI 对宏观调控冲击区域效应的经验分析11:25~11:45吴敬天津财经大学统计学院国家治理机制、绩效与经济增长—基于不同类型国家的实证研究11:45~12:05吴丽丽山西财经大学统计学院政府如何应对PPI 上涨?1 2:05~13:30 午餐主持与评论人:杜金柱内蒙古财经学院教授13:30~13:50赵慧卿、郝枫天津商业大学经济学院,天津财经大学统计学院ULC 与中国竞争力测度研究13:50~14:10章上峰、许冰浙江工商大学统计与数学学院时变弹性生产函数与全要素生产率14:10~14:30钱争鸣、吴琳、邓明厦门大学经济学院统计系我国FDI 区位分布影响因素的Dynamic Panel Data 模型分析14:30~14:50邹卫星天津财经大学经济系经济增长结构:程序化事实及其经济基础分会场7——金融保险财税专题(D1)主持与评论人:张小斐山东经济学院教授8:30~8:50李进芳、王仁曾兰州商学院统计学院,华南理工大学经济与贸易学院VaR 方法在开放式基金风险测量中的应用8:50~9:10方匡南、朱建平厦门大学计划统计系我国股票市场beta 系数稳定性研究9:10~9:30郑宏、蒋萍东北财经大学统计学院基于GARCH 模型族的上海银行间同业拆放利率shibor行为实证分析主持与评论人:雷钦礼暨南大学教授9:30~9:50丁媛浙江工商大学统计与数学学院中国货币政策与通货膨胀的滞后协整关系研究——基于近期通胀数据的实证研究9:50~10:10刘卫华天津财经大学统计学院货币增速、需求利率弹性与通货膨胀10:10~10:25 茶歇10:25~10:45何庆光广西财经学院数学与统计系财政分权、转移支付与地方税收入综合评价专题(F)主持与评论人:刘建平暨南大学教授10:45~11:05王吉培、张志伟西南财经大学统计学院基于粗糙集神经网络的商业银行信贷风险研究11:05~11:25郑宇庭Department of Statistics National Chengchi University Taipei Taiwan中小企业新巴赛尔协议之信用评等模型研究11:25~11:45袁建文广东商学院统计学系广东省最终需求结构的能源消耗强度优化模型及分析11:45~12:05袁捷敏江西财经大学信息管理学院数学与决策科学系我国城乡一体化进程指数与发展阶段划分标准1 2:05~13:30 午餐主持与评论人:杨灿厦门大学教授13:30~13:50石刚、王卉彤中央财经大学统计学院我国主体功能区的划分与评价——基于承载力视角13:50~14:10张琳琅西南财经大学统计学院基于DEA 超效率模型的我国商业银行效率评价——控制环境因素14:10~14:30王建平、陈相成河南财经学院统计系长江水质污染状况的动态加权综合评价主持与评论人:孙秋碧福州大学教授14:30~14:50李灿、徐映梅湖南商学院信息学院,中南财经政法大学信息学院库区农户生活满意度的分析14:50—15:05 茶歇15:05—15:25冯利英内蒙古财经学院统计与数学学院内蒙古经济运行质量评价体系研究15:25—15:45廖颖林上海财经大学应用统计研究中心基于顾客满意度陷阱的市场细分方法研究15:45—16:05纪建强国防科技大学人文与社会科学学院社会科学系基于贝叶斯网络的武器装备采办风险评估分会场8——金融保险财税专题(D2)主持与评论人:赵民德台湾中央研究院教授8:30~8:50王泽填、姚洋、裴辉儒北京大学中国经济研究中心人民币均衡汇率的估计8:50~9:10肖红叶、王莉、白东杰天津财经大学统计学院人民币均衡汇率决定机制及其影响因素的作用分析9:10~9:30王黎明上海财经大学统计学系运用结构变点理论的人民币均衡汇率研究9:30~9:50黎实、黎梅、李林、高勇标西南财经大学中国金融研究中心面板删失视角下的中国上市商业银行股权结构与绩效研究主持与评论人:傅德印兰州商学院教授9:50~10:10徐国祥、李宇海上海财经大学应用统计研究中心我国金属期货价格指数编制研究10:10~10:25 茶歇10:25~10:45马丹西南财经大学统计学院成交风险、交易成本、逆向选择风险与投资者订单选择策略10:45~11:05闫瑾湖南大学统计学院宏观金融运行稳定性监测的实证研究主持与评论人:董麓天津财经大学教授11:05~11:25刘扬、张桂香中央财经大学统计学院,首都医科大学卫生管理学院我国农村人身保险需求的实证分析11:25~11:45胡玉琴浙江财经学院数学与统计学院我国养老保险制度改革的性别利益分析11:45~12:05沈锡飞、苏为华杭州市政府金融办,浙江工商大学统计与数学学院供需平衡原理与新股发行决策——兼论不同市场条件下的IPO 发行博弈1 2:05~13:30 午餐统计方法在其它领域的应用(I3)。

非参数统计方法在假设检验中的应用研究论文素材一、引言假设检验是统计学中一种重要的分析方法,用于根据样本数据推断总体参数的性质。
传统的假设检验通常基于参数统计方法,即假设总体参数服从某种特定的概率分布。
然而,在实际应用中,往往无法确定总体分布的具体形式,这时就需要使用非参数统计方法。
本文旨在探讨非参数统计方法在假设检验中的应用,并提供相应的研究素材。
二、非参数统计方法概述非参数统计方法是指不对总体参数做任何假设的统计方法。
它的优势在于不依赖具体的分布假设,因此更加灵活,适用范围更广。
非参数统计方法主要包括秩和检验、分布自由度检验和重抽样检验等。
1. 秩和检验秩和检验是非参数统计方法中常用的一种方法,适用于两组或多组独立样本的比较。
该方法将观测值按照大小排列,通过比较秩和的大小来进行假设检验。
常见的秩和检验包括Wilcoxon秩和检验和Mann-Whitney U检验。
2. 分布自由度检验分布自由度检验是一种非参数的拟合优度检验方法,用于检验观测数据与某个理论分布是否一致。
该方法基于观测数据的经验分布函数,通过计算观测数据的累积概率与理论分布的累积概率之间的差异来进行假设检验。
3. 重抽样检验重抽样检验是一种基于数据重抽样的非参数统计方法。
常见的重抽样检验包括Bootstrap方法和Permutation方法。
Bootstrap方法通过随机抽样产生重复样本,从而估计总体参数的分布。
Permutation方法则通过对样本数据的重新排列来进行假设检验。
三、非参数统计方法的应用研究素材1. 秩和检验的应用研究文献1:Smith, J. et al. (2015). "A Comparative Study of Nonparametric Rank Tests for Gene Differential Expression Analysis." Journal of Biometrics, 30(4), 123-135.该研究通过比较不同的秩和检验方法在基因差异表达分析中的应用效果,探讨了不同方法的优缺点并给出了相应的建议。
基于Bootstrap思想的非参数检验p值的估计方法吕书龙;刘文丽【摘要】在总体分布未知且样本量较小时,基于Bootstrap思想和随机模拟方法,讨论了非参数检验的三种方法及其检验p值的估计,并通过R程序加以实现.最后以已知分布的随机样本构建某些统计量为例作模拟实验,给出三种估计方法与常规方法的比较.%Based on the Bootstrap idea and the method of stochastic simulation,this paper discussed three estimation methods of nonparametric test and its' p value calculation when the population (distribution) is unknown and the sample size is small.It also put forward the realization programs by R software.At the end,it took some random samples with known distribution as the sources of simulation to compare the above methods with general methods.【期刊名称】《福州大学学报(自然科学版)》【年(卷),期】2018(046)001【总页数】7页(P20-26)【关键词】非参数检验;Bootstrap;随机模拟;检验p值;R软件【作者】吕书龙;刘文丽【作者单位】福州大学数学与计算机科学学院,福建福州 350116;福州大学数学与计算机科学学院,福建福州 350116【正文语种】中文【中图分类】O212.70 前言参数型假设检验特别是基于正态总体的假设检验,无论是从理论上还是实践上都已经成为经典. 参数型假设检验的前提要求总体服从的分布形式或分布族是已知的,这对构造检验统计量并确定其分布和精确计算检验p值都提供了最有利的条件. 但在实际问题中,总体的分布通常是未知的,于是,人们就希望在总体分布不假定的前提下,基于数据本身来构造反映总体特征及问题的统计量或信息,从而达到统计推断的目的,这也是非参数统计的宗旨. 众所周知,采用检验p值完成假设检验的推断已成为一种最基本的模式. 作为非参数统计的一个主要分支,非参数检验在医学、生物学、信息学、金融、管理、教育等众多领域应用广泛.如何构造检验统计量并计算检验p值,是非参数检验的一个关键问题,特别是在样本量较小的情况下,这个问题尤为突出. 但本研究注意到由于非参数方法不假定总体分布,对原始数据的使用也不像参数型方法,这可能会导致非参数方法的有效性低于参数方法. 而通过重抽样Bootstrap方法[1-2]可以很好地给出总体特征的估计及精度表示[3]、区间估计以及假设检验等,甚至能发现常规检验方法中可能存在的不稳定问题. 检验p值的估计是非参数假设检验的基本问题,Nilsson [4]提出检验p值的数据量缩减型Monte-Carlo非参数估计方法,并给出其在生物信息学上的应用. Silverman [5]探讨了基于Bootstrap的渐近枢轴统计量的经验分布函数的核方法及检验p值的估计. 本研究尝试探讨宽泛的检验p值估计方法及其适用范围.1 问题描述设总体X~F(x),F(x)未知,X1, X2, …, Xn为其独立同分布样本,x1, x2, …, xn为样本观测值. 为推断与总体相关的某些问题,通常要构造样本函数T=T(X1, X2, …, Xn),即统计量. 但由于F(x)未知,此时统计量T的研究基本上可归入非参数领域.假设检验应用广泛,很多的实际问题都可以转化成假设检验而得到较好解决. 在作假设检验时,是否拒绝原假设H0,基本上都是通过先假定H0成立,再计算其检验p值并根据检验p值的大小来进行推断. 各种统计软件仅根据统计量T的分布给出检验p值,但是否拒绝原假设全部交给使用者自行裁定. 如果统计量T的分布难以确定,就会导致检验p值的计算变得无章可循,实际问题也就难以得到有效的解决.本研究在总体分布未知且小样本条件下,避开统计量的理论分布探讨,单纯从模拟仿真的角度,通过Bootstrap法产生的自助样本,构造“检验统计量”并结合随机模拟、经验分布和核密度估计[6]等方法实现原假设下的检验p值的估计,从而在一定程度上解决了上述假定条件下假设检验问题的推断.2 主要理论和工具1) 格列汶科(Glivenko)定理给出用样本的经验分布来估计总体的分布函数的理论,即若设总体X的分布函数为F(x),经验分布函数为Fn(x),则有(1)2) 通过重复采样的自助样本实现小样本的估计和推断是Bootstrap思想的优势,该方法的核心是对于预先构造(或待研究)的样本函数T(X1, X2, …, Xn; Fn), 注意其观测值就一个,即Tx(x1, x2, …, xn; Fn). 将x1, x2, …, xn作为母本,从该母本中随机重复抽取大量的子样本并计算作为T(X1, X2, …, Xn; Fn)的估计,然后再从这些估计中研究T(X1, X2, …, Xn; Fn)的分布规律. 其中,表示子样本的经验分布函数. 基于这样一个推理,如果是Fn的良好估计,则T(X1, X2, …, Xn; Fn)的分布规律就会体现在大量的中.3) 设K(x)为定义在(-∞, +∞)上的一个Borel可测函数,hn>0为常数,则称(2)为总体密度函数f(x)的一个核估计. 其中, K(x)称为核函数; hn称为窗宽. 利用核密度函数估计法可对T(X1, X2, …, Xn; Fn)的密度进行估计.3 检验p值估计的基本思路和算法先确定假设检验问题和类型,构造检验统计量;然后利用Bootstrap重抽样得到检验统计量的模拟抽样序列;在抽样序列的基础上,利用Bootstrap法、经验分布法和核密度估计法计算不同检验问题和类型对应的检验p值.3.1 三类检验问题假定检验统计量为T(X1, X2, …, Xn; Fn),其一次试验的值为Tx(x1, x2, …, xn),检验p值的直观意义表示为发生比Tx(x1, x2, …, xn)更极端事件的概率. 对于三类假设检验问题,下面给出检验p值的形式表示.1) 双侧检验,p1=P(T≥Tx(x1, x2, …, xn)),如果p1<=0.5,则检验p值=2p1,否则检验p值=2(1-p1);2) 右侧检验,检验p值=P(T≥Tx(x1, x2, …, xn));3) 左侧检验,检验p值=P(T≤Tx(x1, x2, …, xn)).3.2 检验p值的模拟估计依据Bootstrap思想对样本x1, x2, …, xn有放回重抽样N次,即得到T(X1, X2, …, Xn; Fn)的模拟值N个,即有了足够多的模拟估值基于上述理论,就可以从模拟仿真角度研究T(X1, X2, …, Xn; Fn)的检验p值计算问题.3.2.1 Bootstrap法估计检验p值1) 记将该序列按值从小到大排序,仍然记为2) 计算T=Tx(x1, x2, …, x n; Fn),并确定T值在序列中的位置TR. 如果T值无法在序列中完全匹配到,则T值必然落在序列内部某两个相邻值构成的区间中,可通过线性插值得到TR的位置估计.设T∈(Ti, Ti+1),则(3)3) 基于Bootstrap的百分位数法,给出三类检验问题的检验p值公式:;;(4)另外,还可以基于通过中心极限定理将其近似成正态分布,从而给出相应的检验p值估计.3.2.2 经验分布法估计检验p值构造序列的经验分布函数由格列汶科定理,有由此可得出三类检验问题的检验p值公式:;;(5)通过经验分布函数法得到的检验p值本质上和Bootstrap法得到的检验p值是一致的,只是表达方式不同而已.3.2.3 核密度法估计检验p值1) 选择合适的窗宽及核函数,构造序列的核密度估计函数fT, N(x);2) 根据分布函数和密度函数的关系,可计算概率FT(x)=P(T≤x)=fT, N(t)dt;3) 记p1=P(T≤Tx)=fT, N(t)dt, p2=P(T≥Tx)=fT, N(t)dt,则p双侧=2p1(p1≤0.5)或2p2 (p2≤0.5); p右侧=p2; p左侧=p1(6)4 模拟分析与R实现为了更好地说明本研究提出的算法,下面给出正态型参数检验和非参数检验的两个例子,并与常规的假设检验进行比较.例1 设总体X~N(100, σ2),其中σ2未知(模拟取σ2=16),其样本为X1,X2, (X20)观测值为100.09, 100.53, 101.84, 94.25, 101.35, 101.88, 100.96, 96.45, 102.87, 98.82, 99.88, 96.97, 105.99, 103.23, 100.60, 95.67, 101.89, 100.65, 97.48, 99.13, 试给出关于E(X)=100的三类检验问题的检验p值.解上述问题可通过单正态总体t检验完成,即构造检验统计量软件通过函数t.test 给出检验结果,如表1所示, 采用本研究算法的程序见附录1.表1 常规算法与本研究算法的检验p值Tab.1 p value of conventional algorithm and our algorithm类型常规算法取σ2=16t检验法本研究算法Bootstrap法经验分布函数法核密度法双侧检验0.9763620.9669010.9878000.9876000.998354左侧检验0.5118180.5165490.4939000.4938000.499130右侧检验0.4881810.4834510.5061000.5062000.500870由表1可知,本研究三种算法较常规算法在左侧检验p值的估计方面略微偏小,从而导致右侧检验p值相应变大,同时双侧检验的p值也略微偏大. 实际上对于本研究算法,定义的统计量函数可以更简单,不像参数法需要明确的已知分布才能计算检验p值. 此处定义也可方便地算出检验p值.如果研究的问题是:设Y=X2,求关于E(Y)=10 016的三种假设检验问题的检验p 值. 显然使用常规的方法难以计算检验p值,而本研究算法却可以很轻松地估计出检验p值,只需将统计量函数定义为(注: EY=[E(X)]2+σ2=μ2+σ2)例2 对于中风病人与健康成人血液中尿酸浓度数据,见表2[7],问两类人血液中的尿酸浓度的变异是否存在显著差异?表2 中风病人与健康成人血液中尿酸浓度数据Tab.2 Data of uric acid concentration in the blood of stroke patients and healthy adults (g·L-1)x病人0.0820.1070.0750.1460.0630.0920.1190.0560.1280.0520.0490.135y健康人0.0470.0630.0520.0680.0560.0420.0600.0740.0810.065本例的假设检验问题可表示为H0: 两类人群的尿酸浓度的方差相等, 即(7)文献[7]采用Moses检验法,并给出拒绝H0的推断. Moses检验的作法是将两样本分组,保证每组长度都一样,如各分成m1, m2组;然后计算两样本各小组的离差平方和SSAi, SSBj, i=1, 2, …, m1;j=1, 2, …, m2;再将SSAi, SSBj合并后计算样本1的m1个组的秩和S,从而构造Moses统计量TM(8)王星[7]认为如果两组数据的方差存在很大差异,从平均看,其中一组的离差平方和比另一组的离差平方和要小. 文献[7]以每组3个样本点依据前后顺序将样本1分成4组,样本2分成3组且弃用最后1个样本点,并给出Mann-Whitney的Wα表法进行查表检验. 文献[7]介绍了这种方法,并给出具体的计算过程. 本研究对其中的三个细节问题作深入探讨,一是如何分组,二是不正好分组时弃用哪些样本点,三是检验的结论是否会随分组不同而不同. 本研究认为引入随机分组和随机弃用,结合大量模拟来进行检验更符合实际情况. 为了说明上述问题,设计R程序(见附录2)并整理运行结果,如表3所示.表3 文献[7]方法的某1 000次随机模拟的统计结果Tab.3 Statistical results by1 000 stochastic simulations based on the method in literature [7]TM值(x 组)356789101112出现次数11252282119151617若按照文献[7]提供的方法,得到显著性水平为0.05时的临界值0和12,上述程序模拟1 000次,合计出现了383次接受原假设的情况(如表3所示),且经过多次模拟表明,出现上述检验错误的频率大致都在38%左右. 以上说明不同的随机分组和取点会造成检验结论的不同,即上述三个细节问题必须慎重考虑. 依据文献[7]构造的随机模拟表明该方法可能呈现出相当大的不稳定性.为此有必要充分考虑上述三个细节问题,并探讨更加稳定的算法来解决上述方差相等与否的检验问题. 对数据先作一下基本分析,计算其样本均值、样本方差和样本极差,直观判断两组数据的差异性.表4为基本统计量,从表4看出这两组数据的各项统计量指标都存在较大的差异,检验的结论应该拒绝原假设才合理. 为了避免出现上述随机分组、取点的干扰,引入刀切法思想,即构造原样本的舍一样本方差:;i=1, 2, …, n(9)以表2数据为例,依次去掉样本x的1个样本点,计算舍一方差共12(m1=12)个;样本y的舍一方差共10(m2=10)个. 借鉴Moses检验的作法(注意此处每组的长度不等),构造两个统计量(10)若式(7)中原假设成立,则上述两个TM值既不太大也不太小,否则可拒绝原假设,程序见附录3.表5为检验p值的比较,从表5看出修正后的Moses检验的检验p值远小于文献[7]方法得到的检验p值,相对于文献[7]而言有更强的理由拒绝原假设.表4 基本统计量Tab.4 Basic statistics样本均值方差最小值最大值极差x0.0920.00118010.0490.1460.097y0.0610.00014450.0420.0810.039表5 检验p值的比较Tab.5 Comparison of p values类型文献[7]中的Moses检验修正Moses检验双侧检验0.02851.546441×10-65 实例分析风险价值方法 (value at risk, VaR)作为金融风险度量的一种重要方法,在金融风险管理中应用广泛. 金融资产价格变化的分布经常出现尖峰厚尾的现象,若使用模型设定法(如价格变化服从t分布或正态分布等),估计往往不精确甚至不符合实际. 本研究以2016年上证指数前一日收盘价与后一日开盘价(共计244个数据)的日对数收益率rxt=log(开盘价t)-log(收盘价t-1), t=2, 3, …, 244(合计243个数据)为例,构造这样一个风险检验问题:在置信度为95%时,H0:VaR=-3.40%,即以95%的置信度认为日对数收益率不低于-3.40%. 图1(a)给出日对数收益率的核密度估计图,该图显示收益率的分布呈现尖峰厚尾的现象. 这个检验问题(左侧检验)用常规的方法难以处理,因为不知道VaR的分布,而用本研究方法却能方便地给出结果,过程如下:1) 利用核估计对243个对数收益率求得置信度为95%的VaR值(该值等于-3.40%);2) 利用Bootstrap方法,求得置信度为95%的VaR的n个(不妨取n=10 000)模拟值,并再次利用核估计给出VaR的估计分布;然后基于该分布计算VaR的检验p 值,给出结论. 图1(b)给出VaR的模拟分布密度. 计算程序见附录4,主要结果见表6,由于检验p值都较大,不妨接受VaR=-3.40%的假设.图1 日对数收益率和VaR的核密度估计Fig.1 Kernel density estimations of daily log returns and VaR表6 VaR的检验p值Tab.6 p value of VaR Bootstrap法经验分布函数法核密度法0.48700.48690.49906 结语例1说明了使用Bootstrap进行检验p值估计的可行性;例2说明Bootstrap方法可用来解释一些不当的作法. 实例分析表明,基于Bootstrap法的检验p值可方便用来解决实际问题. 总的来说,使用Bootstrap方法估计检验p值,关键在于构造合适的统计量,确定统计量的类型(连续或离散),最后通过自助样本的经验分布序列得到统计量的近似分布,进而给出p值估计.参考文献:[1] EFRON B, TIBSHIRANI R J. An introduction to bootstrap[M]. New York: Chapman and Hall, 1993.[2] EFRON B. Bootstrap methods: another look at the Jackknife[J]. Ann Statist, 1979, 7(1): 1-26.[3] KULESA A, KRZYWINSKI M, BLAINEY P, et al. Points of siginificance: sampling distribution and the bootstrap[J]. Nature methods, 2015, 12(6): 477-478.[4] NILSSON B. A compression algorithm for pre-simulated Monte Carlo p-value functions: application to the ontological analysis of microarray studies[J]. 2008, 29(6): 768-772.[5] SILVERMAN B W. Density estimation for statistics and data analysis[M]. London: Chapman and Hall, 1986.[6] RACINEA J S, MACKINNON J G. Inference via kernel smoothing of bootstrap p values[J]. 2006, 51(12): 5949-5957.[7] 王星. 非参数统计[M]. 北京:清华大学出版社, 2009.。
非参数统计方法学非参数统计方法学是统计学中一个重要的分支,它通过对数据分布的形状和参数假设进行较少的假设或不做任何假设来进行统计推断。
相比于参数统计方法,非参数统计方法无需对总体参数做出任何假设,因此更加灵活和具有普适性。
本文将介绍非参数统计方法学的基本概念、常见应用以及优缺点。
一、基本概念非参数统计方法学是指不依赖总体具体分布或分布类型的统计推断方法。
在非参数统计中,不对总体的分布形式进行具体的假设,而是利用样本数据进行分析和推断。
非参数统计方法通常是基于统计量的排序或秩次进行推断,因此具有较强的鲁棒性和普适性。
二、常见应用1. 秩和检验:秩和检验是一种常见的非参数检验方法,适用于两组或多组独立样本的差异性比较。
通过对样本数据进行排序,计算秩和来进行假设检验,例如Wilcoxon秩和检验、Mann-Whitney U检验等。
2. 秩相关检验:秩相关检验用于检验两个变量之间的相关性,常见的方法包括Spearman秩相关系数和Kendall秩相关系数。
与传统的相关性检验相比,秩相关检验不要求数据满足线性关系和正态分布假设。
3. 分布拟合检验:非参数统计方法还可用于检验数据是否符合特定的分布假设,如Kolmogorov-Smirnov检验和Anderson-Darling检验用于检验样本数据是否符合正态分布。
4. 生存分析:生存分析是研究个体生存时间或失效时间与影响因素之间关系的方法,常用的生存分析方法包括Kaplan-Meier法、Log-rank 检验等,这些方法常用于医学和生物领域的研究。
三、优缺点1. 优点:非参数统计方法不依赖总体分布的具体形式,适用范围广泛;具有较强的鲁棒性,对异常值和偏差数据不敏感;适用于小样本和非正态数据的分析。
2. 缺点:非参数统计方法通常需要更大的样本量才能获得相同的显著性水平;对于大样本数据,非参数方法可能缺乏效率;在一些情况下,参数方法可能提供更精确和高效的结果。
专利名称:一种基于隐私保护的收入分配差距基尼系数度量方法
专利类型:发明专利
发明人:刘白,张明武,石润华
申请号:CN201910378270.9
申请日:20190508
公开号:CN110162999A
公开日:
20190823
专利内容由知识产权出版社提供
摘要:本发明公开了一种基于隐私保护的收入分配差距基尼系数度量方法,采用基于隐私保护的收入分配差距基尼系数度量系统;系统包括云端服务器CS、用户端CR、可信第三方机构TI、科研机构SRI;首先进行系统初始化,产生公钥和私钥数据,对私有数据加密,把加密后的私有数据发送到云端服务器,云端服务器对加密数据进行聚合、均值,利用经济学原理,计算基尼系数的密文数据,云端服务器将计算后的密文数据发送给科研机构,科研机构对密文数据进行解密,根据解密后的数据及基尼系数的定义计算基尼系数,最后科研机构得到n个人收入数据差距的基尼系数。
本发明使得其他个人和机构在保证个人收入隐私的情况下,完成了个人收入分配差距基尼系数的度量。
申请人:湖北工业大学
地址:430068 湖北省武汉市武昌区南湖李家墩1村1号
国籍:CN
代理机构:武汉科皓知识产权代理事务所(特殊普通合伙)
代理人:魏波
更多信息请下载全文后查看。
企业财务业绩评价分析——基于非参数统计
李佳航;牛加岩
【期刊名称】《现代商业》
【年(卷),期】2024()3
【摘要】近年来,中国企业的国际竞争力不断增强,中国企业的数量也在不断增加,但是中国企业是否真正走向了国际化,这个问题还有待研究。
财务绩效是指公司的战略执行能否对公司的最终运营成果和业绩做出贡献。
本文根据偿债能力、盈利能力、营运能力和发展能力等指标,选取中国、美国和德国10家入选全球500强企业为个案,运用非参数统计的方法,比较中国企业和美国、德国企业之间的差异。
研究发现,中国企业要想缩小与其他国家的差距,就必须改善产业经营的结构,稳步提高各类型企业的整体实力。
首先进行合理的投资,减少资产负债率;其次盘活企业的资产,提高企业的周转能力;同时扩大公司的经营范围,增加业务收入的增长;最后提高经营效率,缩短公司之间的营业净利率差距。
【总页数】4页(P185-188)
【作者】李佳航;牛加岩
【作者单位】黑龙江科技大学
【正文语种】中文
【中图分类】F275
【相关文献】
1.对世界500强企业发展水平的统计分析──基于非参数统计方法的分析
2.非参数统计方法在上市公司经营业绩分析中的应用
3.关于非参数统计方法下的企业财务绩效评价的思考
4.基于《企业绩效评价标准值》的永安林业企业财务绩效评价分析
5.陕西省农产品生产效率统计测度与评价——基于非参数DEA前沿的实证分析
因版权原因,仅展示原文概要,查看原文内容请购买。
学术研究中的非参数检验方法摘要:非参数检验是一种广泛应用于统计学中的统计方法,尤其在处理分类变量和数据缺失时具有独特的优势。
本文旨在介绍非参数检验的基本原理、应用场景以及其在学术研究中的重要性。
通过具体案例分析,展示非参数检验在数据分析和实证研究中的应用,并讨论其与参数检验的区别和联系。
一、非参数检验的基本原理非参数检验是一种基于数据分布不依赖于总体分布的统计方法。
它主要包括卡方检验、秩和检验、二项分布检验等。
这些方法的特点是不需要知道总体分布,也不需要假设数据服从某一特定分布,因此适用于处理不确定的数据分布情况。
二、非参数检验的应用场景非参数检验在学术研究中具有广泛的应用,例如在心理学、医学、经济学、社会学等领域。
它可以用于比较不同组之间的数据分布差异,识别数据中的异常值和趋势,以及评估数据的可靠性和稳定性。
此外,非参数检验还适用于处理缺失数据和分类变量,因为这些数据类型不适合使用参数检验。
三、非参数检验的优势和局限性非参数检验的优势在于它对数据的适用性更广,无需知道或假设数据符合特定的分布。
此外,非参数检验的结果更加稳健,能够更好地处理异常值和组间差异。
然而,非参数检验也具有一定的局限性,例如它可能无法提供精确的参数估计,对于小样本数据可能不够敏感。
四、案例分析为了更好地理解非参数检验的应用,我们以一个实际研究案例为例进行分析。
该案例涉及对一组医学数据的分析,研究人员想知道不同药物治疗效果之间的差异。
通过对两组患者的治疗结果进行非参数检验,研究人员可以比较不同药物治疗效果的数据分布,进而评估哪种药物更有效。
五、结论本文介绍了非参数检验的基本原理、应用场景、优势和局限性,并通过具体案例分析了其在学术研究中的应用。
非参数检验作为一种重要的统计方法,在处理不确定的数据分布和分类变量时具有独特的优势。
尽管它可能无法提供精确的参数估计,但对于小样本数据和异常值具有较强的鲁棒性。
在未来的学术研究中,非参数检验将继续发挥重要作用,为数据分析和实证研究提供有力支持。