各种乘法器比较
- 格式:pdf
- 大小:470.85 KB
- 文档页数:14
各种乘法器⽐较各种乘法器⽐较韦其敏08321050引⾔:乘法器频繁地使⽤在数字信号处理和数字通信的各种算法中,并往往影响着整个系统的运⾏速度。
如何实现快速⾼效的乘法器关系着整个系统的运算速度和资源效率。
本位⽤如下算法实现乘法运算:并⾏运算、移位相加、查找表、加法树。
并⾏运算是纯组合逻辑实现乘法器,完全由逻辑门实现;移位相加乘法器将乘法变为加法,通过逐步移位相加实现;查找表乘法器将乘积结果存储于存储器中,将操作数作为地址访问存储器,得到的输出数据就是乘法运算结果;加法树乘法器结合移位相加乘法器和查找表乘法器的优点,增加了芯⽚耗⽤,提⾼运算速度。
注:笔者使⽤综合软件为Quartus II 9.1,选⽤器件为EP2C70,选⽤ModelSim SE 6.1b进⾏仿真,对于其他的软硬件环境,需视具体情况做对应修改。
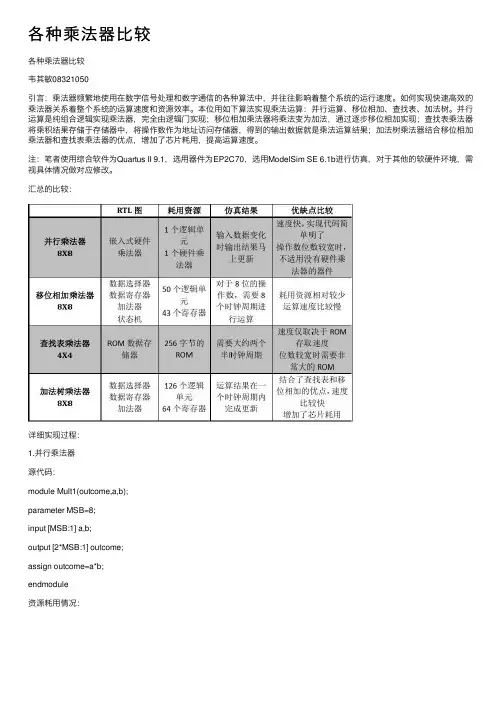
汇总的⽐较:详细实现过程:1.并⾏乘法器源代码:module Mult1(outcome,a,b);parameter MSB=8;input [MSB:1] a,b;output [2*MSB:1] outcome;assign outcome=a*b;endmodule资源耗⽤情况:ModelSim测试激励⽂件源代码:`timescale 10ns/1ns module Mult1_test();reg [8:1] a,b;wire [16:1] outcome;Mult1 u1(outcome,a,b); parameter delay=2;initialbegina=1;b=0;endinitial foreverbegin#delaya=a+1;b=b+1;if(outcome>=16'h0FFF)$stop;endendmodule仿真时序波形:DE2-70拥有300个嵌⼊式硬件乘法器单元,Quartus II综合并⾏乘法器时⾃动采⽤嵌⼊式乘法器来实现,因此中和报表中仅耗⽤了⼀个LE单元和⼀个九位的嵌⼊式乘法器单元。

实验十二模拟乘法器调幅(AM、DSB、SSB)一、实验目的1.掌握用集成模拟乘法器实现全载波调幅。
抑止载波双边带调幅和单边带调幅的方法。
2.研究已调波与调制信号以及载波信号的关系。
3.掌握调幅系数的测量与计算方法。
4.通过实验对比全载波调幅、抑止载波双边带调幅和单边带调幅的波形。
5.了解模拟乘法器(MC1496)的工作原理,掌握调整与测量其特性参数的方法。
二、实验内容1.调测模拟乘法器MC1496正常工作时的静态值。
2.实现全载波调幅,改变调幅度,观察波形变化并计算调幅度。
3.实现抑止载波的双边带调幅波。
4.实现单边带调幅。
三、实验原理幅度调制就是载波的振幅(包络)随调制信号的参数变化而变化。
本实验中载波是由晶体振荡产生的465KHz高频信号,1KHz的低频信号为调制信号。
振幅调制器即为产生调幅信号的装置。
1.集成模拟乘法器的内部结构集成模拟乘法器是完成两个模拟量(电压或电流)相乘的电子器件。
在高频电子线路中,振幅调制、同步检波、混频、倍频、鉴频、鉴相等调制与解调的过程,均可视为两个信号相乘或包含相乘的过程。
采用集成模拟乘法器实现上述功能比采用分离器件如二极管和三极管要简单得多,而且性能优越。
所以目前无线通信、广播电视等方面应用较多。
集成模拟乘法器常见产品有BG314、F1596、MC1495、MC1496、LM1595、LM1596等。
(1)MC1496的内部结构在本实验中采用集成模拟乘法器MC1496来完成调幅作用。
MC1496是四象限模拟乘法器。
其内部电路图和引脚图如图12-1所示。
其中V1、V2与V3、V4组成双差分放大器,以反极性方式相连接,而且两组差分对的恒流源V5与V6又组成一对差分电路,因此恒流源的控制电压可图12-1 MC1496的内部电路及引脚图正可负,以此实现了四象限工作。
V7、V8为差分放大器V5与V6的恒流源。
(2)静态工作点的设定1)静态偏置电压的设置静态偏置电压的设置应保证各个晶体管工作在放大状态,即晶体管的集-基极间的电压应大于或等于2V ,小于或等于最大允许工作电压。

DC综合乘法器的命名规则通常遵循一定的规范,以确保清晰、准确地标识设备。
一般来说,乘法器的命名通常包括以下部分:
1.基本功能描述:首先,名称应描述乘法器的基本功能。
例如,如果它是一
个模拟乘法器,那么名称中可能会包含“模拟”或“A”等关键词。
2.输入和输出信号:乘法器的名称也可能包含输入和输出信号的描述。
例
如,如果乘法器有两个输入信号和一个输出信号,那么名称中可能会包含这些信号的缩写或描述。
3.其他特性:除了基本功能和输入/输出信号外,名称还可能包含其他特性,
如增益、精度、带宽等。
这些特性对于理解乘法器的性能和应用场景非常重要。
总的来说,DC综合乘法器的命名规则旨在提供一个清晰、易于理解的标识,帮助工程师和其他相关人员快速了解该设备的基本功能和特性。
当然,具体的命名规则可能因制造商和产品系列而有所不同。
因此,在实际应用中,最好参考制造商提供的技术规格和文档,以获得更准确的信息。

计算机基础知识计算机基本运算计算机基础知识——计算机基本运算计算机基本运算是指计算机进行数据处理时所进行的基本操作,包括加法、减法、乘法、除法和求余等。
这些基本运算是计算机实现各种应用功能的基础。
本文将介绍计算机基本运算的原理、实现和应用。
一、加法运算加法运算是计算机最基本的运算之一。
计算机通过加法运算实现数字相加,从而实现数据的累加和累减。
计算机采用二进制进行加法运算,设置进位位来实现多位数相加。
具体的加法运算过程是将两个数位对齐,逐位相加,并考虑进位的情况。
实现加法运算的基本电路是加法器电路。
加法器电路由半加器和全加器两部分组成。
半加器实现两个位的相加,全加器实现三个位的相加。
通过级联多个全加器,可以实现多位数的相加。
加法运算广泛应用于计算机的各个领域,如算术运算、图像处理、音频处理等。
二、减法运算减法运算是计算机基本运算之一,用于实现数字相减。
计算机采用补码表示负数,通过借位运算实现减法。
减法运算的实现方式是将减数取反,然后与被减数相加。
具体的减法运算过程是将两个数位对齐,逐位相减,并考虑借位的情况。
减法运算的电路实现与加法器电路类似,只需将一个输入置反即可。
减法运算广泛应用于计算机的各个领域,如算术运算、图像处理、音频处理等。
三、乘法运算乘法运算是计算机基本运算之一,用于实现数字相乘。
计算机采用乘法器电路实现乘法运算。
乘法器电路由部分乘积器和加法器组成。
部分乘积器实现局部的位乘法运算,加法器实现部分乘积的累加。
乘法运算的实现方式是将乘数的每一位与被乘数相乘,然后将所有部分乘积相加。
具体的乘法运算过程是将乘数的每一位与被乘数相乘,得到部分乘积。
然后将所有部分乘积相加,并考虑进位的情况。
乘法运算广泛应用于计算机的各个领域,如数值计算、数据压缩、图形处理等。
四、除法运算除法运算是计算机基本运算之一,用于实现数字相除。
计算机采用除法器电路实现除法运算。
除法器电路通过连续的移位和减法运算实现除法。


乘法器的工作原理
乘法器是一种用于实现数字乘法运算的电路或器件。
它将两个输入的数字进行相乘,并得到其乘积作为输出。
乘法器的工作原理基于逻辑门电路的组合与串联。
乘法器通常是由多个部分组成的,其中包括乘法器的位数、运算规则以及乘法器内部的逻辑门电路。
这些部分协同工作以实现精确且高效的乘法运算。
在一个典型的乘法器中,输入信号将首先被分为不同的位数。
每一位数将被独立处理,并最终合并以得到最终的乘积结果。
每个位数的处理过程包括了多个逻辑运算,例如与门、或门和异或门。
为了完成乘法运算,乘法器将两个输入位进行逐位相乘。
这里的位可以是二进制位,也可以是十进制位。
逐位相乘的方法可以通过一系列的逻辑门电路来实现。
这些逻辑门电路可以对输入位进行操作,并生成相乘位的输出。
在乘法器中,最低有效位(LSB)的运算最先进行。
在相邻的
位运算完成后,它们的结果会被以并行的方式传递给下一位的运算。
这样一直进行到最高有效位(MSB)的运算完成。
最后,所有位的乘法结果会被整合在一起,形成最终的乘积。
乘法器的性能取决于其位数和逻辑门电路的设计。
更高的位数会产生更精确的乘法结果,但也会增加乘法器的复杂性和功耗。
因此,在设计乘法器时需要权衡精确性和性能之间的关系。
总之,乘法器是一种通过组合逻辑门电路来实现数字乘法运算的电路或器件。
它将输入信号分解为不同的位数,并使用逻辑门电路逐位相乘。
最后,将每个位的乘法结果合并在一起,得到总体的乘积输出。

VHDL八位乘法器一.设计思路纯组合逻辑构成的乘法器虽然工作速度比较快,但过于占用硬件资源,难以实现宽位乘法器,基于PLD器件外接ROM九九表的乘法器则无法构成单片系统,也不实用。
这里介绍由八位加法器构成的以时序逻辑方式设计的八位乘法器,具有一定的实用价值,而且由FPGA构成实验系统后,可以很容易的用ASIC大型集成芯片来完成,性价比高,可操作性强。
其乘法原理是:乘法通过逐项移位相加原理来实现,从被乘数的最低位开始,若为1,则乘数左移后与上一次的和相加;若为0,左移后以全零相加,直至被乘数的最高位。
二.方案设计与论证此设计是由八位加法器构成的以时序逻辑方式设计的八位乘法器,它的核心器件是八加法器,所以关键是设计好八位加法器。
方案:由两个四位加法器组合八位加法器,其中四位加法器是四位二进制并行加法器,它的原理简单,资源利用率和进位速度方面都比较好。
综合各方面的考虑,决定采用方案二。
三.工作原理ARICTL是乘法运算控制电路,它的START信号上的上跳沿与高电平有2个功能,即16位寄存器清零和被乘数A[7...0]]向移位寄存器SREG8B加载;它的低电平则作为乘法使能信号,乘法时钟信号从ARICTL的CLK输入。
当被乘数被加载于8位右移寄存器SREG8B后,随着每一时钟节拍,最低位在前,由低位至高位逐位移出。
当为1时,一位乘法器ANDARITH打开,8位乘数B[7..0]在同一节拍进入8位加法器,与上一次锁存在16位锁存器REG16B中的高8位进行相加,其和在下一时钟节拍的上升沿被锁进此锁存器。
而当被乘数的移出位为0时,一位乘法器全零输出。
如此往复,直至8个时钟脉冲后,由ARICTL的控制,乘法运算过程自动中止,ARIEND输出高电平,乘法结束。
此时REG16B的输出即为最后的乘积。
四.工作原理框图五.程序清单1.library ieee; ----四位二进制并行加法器use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity add4b isport( cin:in std_logic;a,b:in std_logic_vector(3 downto 0);s:out std_logic_vector(3 downto 0);cout:out std_logic);end;architecture one of add4b issignal sint,aa,bb:std_logic_vector(4 downto 0);beginaa<='0' & a;bb<='0' & b;sint<=aa+bb+cin;s<=sint(3 downto 0);cout<=sint(4);end;2.library ieee; --由两个四位二进制并行加法器级联而成的八位二进制加法器;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity adder8b isport( cin:in std_logic;a,b:in std_logic_vector(7 downto 0);s:out std_logic_vector(7 downto 0);cout:out std_logic);end;architecture one of adder8b iscomponent add4b --对要调用的元件add4b的端口进行说明port( cin:in std_logic;a,b:in std_logic_vector(3 downto 0);s:out std_logic_vector(3 downto 0);cout:out std_logic);end component;signal carryout: std_logic;beginu1:add4b port map(cin,a(3 downto 0),b(3 downto 0),s(3 downto 0),carryout);u2:add4b port map(carryout,a(7 downto 4),b(7 downto 4),s(7 downto 4),cout);end;3.library ieee; --一位乘法器;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity andarith isport( abin:in std_logic;din:in std_logic_vector(7 downto 0);dout:out std_logic_vector(7 downto 0));end;architecture one of andarith isbeginprocess(abin,din)beginfor i in 0 to 7 loopdout(i)<=din(i) and abin;end loop;end process;end;4.library ieee; --乘法运算控制器use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity arictl isport( clk,start:in std_logic;clkout,rstall,ariend:out std_logic);end;architecture one of arictl issignal cnt4b:std_logic_vector(3 downto 0);beginrstall<=start;process(clk,start)beginif start='1' then cnt4b<="0000";elsif clk'event and clk='1' thenif cnt4b<8 then --小于8则计数,等于8则表明乘法运算已经结束cnt4b<=cnt4b+1;end if;end if;end process;process(clk,cnt4b,start)beginif start='0' thenif cnt4b<8 thenclkout<=clk; ariend<='0';else clkout<='0'; ariend<='1';end if;else clkout<=clk; ariend<='0';end if;end process;end;5.library ieee; --16位锁存器use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity reg16b isport( clk,clr:in std_logic;d:in std_logic_vector(8 downto 0);q:out std_logic_vector(15 downto 0));end;architecture one of reg16b issignal r16s:std_logic_vector(15 downto 0);beginprocess(clk,clr)beginif clr='1' then r16s<="0000000000000000";elsif clk'event and clk='1' thenr16s(6 downto 0)<=r16s(7 downto 1);r16s(15 downto 7)<=d;end if;end process;q<=r16s;end;6.library ieee; --8位右移寄存器use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity sreg8b isport( clk,load:in std_logic;din:in std_logic_vector(7 downto 0);qb:out std_logic);end;architecture one of sreg8b issignal reg8:std_logic_vector(7 downto 0);beginprocess(clk,load)beginif clk'event and clk='1' thenif load='1' then reg8<=din;else reg8(6 downto 0)<=reg8(7 downto 1);end if;end if;end process;qb<=reg8(0);end;7.library ieee;--8位乘法器顶层设计use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity mult8x8 isport( clk:in std_logic;start:in std_logic;a,b:in std_logic_vector(7 downto 0);dout:out std_logic_vector(15 downto 0);ariend:out std_logic);end;architecture struc of mult8x8 iscomponent adder8b isport( cin:in std_logic;a,b:in std_logic_vector(7 downto 0);s:out std_logic_vector(7 downto 0);cout:out std_logic);end component;component andarith isport( abin:in std_logic;din:in std_logic_vector(7 downto 0);dout:out std_logic_vector(7 downto 0)); end component;component arictl isport( clk,start:in std_logic;clkout,rstall,ariend:out std_logic);end component;component reg16b isport( clk,clr:in std_logic;d:in std_logic_vector(8 downto 0);q:out std_logic_vector(15 downto 0));end component;component sreg8b isport( clk,load:in std_logic;din:in std_logic_vector(7 downto 0);qb:out std_logic);end component;signal gndint :std_logic;signal intclk :std_logic;signal rstall :std_logic;signal qb :std_logic;signal andsd :std_logic_vector(7 downto 0);signal dtbin :std_logic_vector(8 downto 0);signal dtbout :std_logic_vector(15 downto 0);begindout<=dtbout; gndint<='0';u1:arictl port map( clk,start,intclk,rstall,ariend);u2:sreg8b port map(intclk,rstall,b,qb);u3:andarith port map(qb,a,andsd);u4:adder8b port map(gndint,dtbout(15 downto 8),andsd,dtbin(7 downto 0),dtbin(8));u5:reg16b port map(intclk,rstall,dtbin,dtbout);end;六.仿真结果图以下是8位乘法器顶层设计的仿真波形图,其它各模块的仿真波形图省略。

verilog 乘法除法Verilog是一种硬件描述语言,广泛应用于数字电路设计和验证。
本文将介绍Verilog中的乘法和除法原理及其在实际应用中的实现。
一、Verilog乘法器原理与实现1.原理Verilog乘法器的原理是基于位级运算。
输入的两个二进制数按位进行与运算,得到乘积的位级表示。
然后通过移位和加法运算,将位级乘积转换为最终的整数乘积。
2.实现Verilog乘法器的实现主要分为三个部分:全加器、位级乘法器和移位器。
全加器用于处理乘数和被乘数的各位与运算结果;位级乘法器用于计算乘数和被乘数的各位与运算;移位器用于调整位级乘积的位数。
3.实例以下是一个简单的Verilog乘法器实例:```module multiplier(input [7:0] a, b [7:0], output [15:0] result);wire [15:0] partial_product;wire [15:0] temp_result;// 位级乘法器wire [15:0] product [7:0];genvar i;generatefor (i = 0; i < 8; i = i + 1) beginassign product[i] = a * b[i];endendgenerate// 移位器assign partial_product = {product[7], product[6:0]};// 全加器assign temp_result = partial_product + result;assign result = temp_result;endmodule```二、Verilog除法器原理与实现1.原理Verilog除法器的原理是采用迭代算法,将除法问题转化为加法和减法问题。
除数和被除数按位进行与运算,得到余数的位级表示。
然后通过循环移位和加法运算,将余级表示转换为最终的整数商和余数。


摘要本文是在理解伽罗瓦域乘法器工作原理的基础上,设计一个伽罗瓦域乘法器,并通过verilog硬件描述语言,用Modelsim,Synplify软件对其进行仿真,综合。
关键词:伽罗瓦域乘法器Verilog 仿真综合AbstractThis article is in understanding the working principle of Galois field multiplier based on the design of a Galois field multiplier, and through the verilog hardware descriptionlanguage, with Modelsim, Synplify software from simulation, synthesis.Key words: Galois Field Multiplier Simulation synthesis目录摘要............................................................................ .............................................................................. . (1)Abstract...................................................................... .............................................................................. . (2)正文............................................................................ .............................................................................. . (4)一、课题及设计要求............................................................................ (4)a)课题内容............................................................................. (4)b)设计要求............................................................................. (4)二、伽罗瓦域背景介绍............................................................................ (4)a)域和伽罗瓦域............................................................................. .. (4)b)伽罗瓦域两种操作——加法与乘法............................................................................. . (4)三、算法描述............................................................................ . (4)四、设计过程............................................................................ . (6)a)过程描述............................................................................. (6)b)程序流程图............................................................................. (7)五、verilog源代码............................................................................ (8)a)主程序............................................................................. .. (8)b)测试程序............................................................................. (11)六、modelsim仿真结果............................................................................ (12)a)仿真后主要信号、变量的波形............................................................................. (12)b)mul_128模块的输入信号和输出信号............................................................................. (13)c)dina和dinb输入和dout输出............................................................................. .. (13)d)验证参数............................................................................. (13)七、综合............................................................................ .............................................................................. .. 15八、现有伽罗瓦域乘法器实现方法优劣比较 (15)九、总结............................................................................ .............................................................................. .. 15a)体会心得............................................................................. (15)b)建议............................................................................. ...............................................................................16致谢............................................................................ .............................................................................. . (17)参考文献............................................................................ .............................................................................. .. 18正文一、课题及设计要求a) 课题内容伽罗瓦域GF(2^128)乘法器是Ghash算法(一种用于加解密系统散列算法)的核心部件,其速度与硬件开销决定着整个Ghash模块的整体性能。

高速乘法器的性能比较简介:对基于阵列乘法器、修正布斯算法(MBA)乘法器、华莱士(WT)乘法器和MBA-WT混合乘法器的四种架构的32位乘法器性能进行了比较,在选择乘法器时,应根据实际应用,从面积、速度、功耗等角度权衡考虑乘法是数字信号处理中重要的基本运算。
在图像、语音、加密等数字信号处理领域,乘法器扮演着重要的角色,并在很大程度上左右着系统性能。
随着实时信号处理的提出和集成电路工艺水平的进步,人们开始致力于高速乘法器设计。
最 初,阵列乘法采用移位与求和算法,部分乘积项(Partial Product, PP)数目决定了求和运算的次数,直接影响乘法器的速度。
修正布斯算法(Modified Booth Algorithm, MBA)对乘数重新编码,以压缩PP。
华莱士树(Wallace Tree, WT)结构改变求和方式,将求和级数从O(N)降为O(logN),提高了运算速度,但是WT存在结构不规整,布线困难的缺点。
用4:2压缩器(4:2 compressor)代替全加器(FA)可以解决这一问题。
将MBA算法和WT结构的优点相结合,形成了MBA-WT乘法器。
以下1~4节将分别介绍阵列乘法器、MBA乘法器、WT乘法器、MBA WT乘法器。
最后对四种乘法器的性能进行比较,并总结全文。
1 阵列乘法器阵 列乘法器基于移位与求和算法。
被乘数与乘数中的某一位相乘,产生一组PP,将该组PP移位,使LSB与乘数对应位对齐;求出全部PP,并相应移位;对所有 PP 求和,得到乘积。
因此,加法阵列结构非常重要。
CRA (Carry Ripple Adder)存在进位问题,运算速度慢。
CSA (Carry Save Adder)将本级进位传至下级,求和速度快,且速度与字长无关。
阵列乘法器中,CSA把PP阵列缩减至Sum和Carry两项,再用高速加法 器求和得积。
阵列乘法器结构规范,利于布局布线。
因 为乘数和被乘数可正、可负,所以一般用二进制补码表示,以简化加、减运算。
模拟乘法器电路原理
乘法器电路是一种用于计算两个输入数的乘积的电子电路。
它由多个逻辑门和电子元件组成,能够将输入信号相乘得到输出信号。
在一个乘法器电路中,通常会有两个输入端和一个输出端。
输入端通常被标记为A和B,分别表示待乘数和乘数。
输出端通常被标记为P,表示乘积。
乘法器电路的工作原理是根据乘法的性质,将每一位的乘积相加得到最后的结果。
具体的实现方式可以有多种,下面介绍一种常见的实现方式。
乘法器电路通常被分为多个级别,每个级别负责计算某一位的乘积。
第一个级别接收A和B的最低位,通过逻辑门或触发器计算出对应的乘积,并将其存储为P的最低位。
然后,每个级别的输出和前一级别输出的进位信号经过逻辑门或触发器进行运算,得到当前级别的乘积和进位信号。
这个过程会一直进行,直到计算完所有位的乘积。
最后,所有级别的乘积和进位信号会被加和,得到最终的输出结果P,即A和B的乘积。
乘法器电路的实现可以使用多种逻辑门和元件,如AND门、OR门、XOR门、D触发器等。
具体的电路设计取决于要求的精度和速度。
需要注意的是,乘法器电路的设计和实现是一项复杂的任务,需要考虑多种因素,如延迟、功耗和精度等。
因此,在实际应用中,通常会使用专门的乘法器芯片,而不是自己设计和制造乘法器电路。
实验四模拟乘法器的应用(振幅调制器)一.实验目的1.掌握用集成模拟乘法器F1496实现普通调幅和抑制载波的双边带调幅的方法与过程;2.研究输出已调波信号与输入载波信号、调制信号的关系。
3.掌握调幅系数的测量方法。
二.实验原理集成模拟乘法器是完成两个模拟量(电压或电流)相乘的电子器件。
高频电子线路中的振幅调制、同步检波、混频、倍频、鉴频、鉴相等调制与解调过程,均可视为两个信号相乘的过程。
F1496是双平衡四象限模拟乘法器,电路如图4-1所示。
引脚⑧与⑩接输入电压U x,①与④接另一输入电压U y,输出电压U o从引脚⑥与⑿输出。
引脚②与③外接电阻为电流负反馈电阻,可调节乘法器的信号增益,并扩展输入电压U y的线性动态范围。
引脚⒁为负电源(双电源供电时)或接地端(单电源供电时)。
本实验将完成普通调幅和抑制载波调幅的内容。
三.实验设备1. 示波器SS7802A 1台2. 信号源EE1643 1台3. 数字万用表1块4. 高频电路实验板G31块四.实验内容与步骤实验电路如图4-1所示,按图接好电路。
1.载波输入端平衡调节在调制信号输入端IN2输入调制信号UΩ(t),UΩ(t)为f=1KHz幅度为100mV(V P-P)的正弦信号。
将示波器接至OUT处,调节电位器R P2,使示波器上输出的波形幅度最小。
(然后去掉输入信号UΩ)。
2.抑制载波调幅(在载波输入端平衡的状态下进行)1)输入端IN1输入载波信号U C(t),U C(t)为f=465KHz,幅度U C(p-p)=30mv的正弦信号,将示波器接至OUT处。
调节R P1,使输出电压Vo最小。
2)入端IN2输入调制信号UΩ(t),其频率为1KHz,幅度由零逐渐增大,当UΩ(p—p)为几百毫伏时,将出现如图4-2所示的抑制载波的调幅信号。
由于器件内部参数不可能完全对称,致使输出波形出现漏载信号。
可通过调节电位器R P2来改善波形的对称性。
记录波形并测出V O(p-p)值。
模拟乘法器工作原理今天来聊聊模拟乘法器工作原理吧。
不知道你们有没有去过那种传统的菜市场。
菜贩在计算总价的时候,其实就有点像模拟乘法器在工作。
比如说菜的单价是每斤5元,你买了3斤,菜贩心里或者拿个小本子一算,就知道总价是15元,这个过程从数学上来说就是乘法:单价×重量= 总价。
模拟乘法器干的事呀,大体上是类似的,只不过它处理的可不是这种买菜算账的数,而是电信号。
模拟乘法器呢,最基本的它有两个输入信号。
这两个输入信号就像两首不同旋律的曲子同时在播放。
当你把这两个信号输入到模拟乘法器的时候,它能处理这两个信号,输出一个新的信号,这个新信号的值就是原来两个输入信号值相乘的结果。
打个比方,就像咱们厨师做菜,有两种食材,土豆和肉,把它们按照一定的比例搭配放入锅中翻炒,最后出锅就变成了一道融合这两种食材味道的新菜,这个新菜就相当于模拟乘法器的输出信号。
有意思的是,模拟乘法器要实现乘法的功能并不是那么简单,这就要说到它背后的电子电路原理了。
从比较基础的模拟乘法器来说,它利用了某些电子器件的特性。
例如,在那些采用了双极型晶体管的模拟乘法器里,是基于晶体管的电流- 电压等特性来实现乘法功能的。
不过,老实说,我一开始也不明白那些复杂的电路表达式到底怎么来的,像那些包含着各种电子元件参数的公式,看起来就像天书一样。
后来我慢慢学才明白,原来它是通过对不同电路部分的精心设计,让输入的电压或者电流信号进行特定的转换和组合,最终实现这个乘法结果的输出。
这就好比我们做一套复杂的手工,每个零部件看似单独存在,但按照特定的步骤组合在一起就能变成一个有新功能的东西。
实际应用案例也有不少呢。
在音频处理领域,模拟乘法器就大有用武之地。
比如说,在音频的调制和解调过程中,利用模拟乘法器的乘法特性,可以把原始的音频信号和一个载波信号相乘,从而实现将音频信号搭载到载波上(调制),或者从载波上把音频信号分离出来(解调)。
在使用模拟乘法器的时候也有一些注意事项。
数字电路算术运算数字电路是现代计算机和电子设备的核心组成部分,它们用于执行各种算术运算。
算术运算是处理数字的基本操作,包括加法、减法、乘法和除法等。
数字电路通过逻辑门和触发器等基本元件组成,能够实现这些算术运算。
本文将详细介绍数字电路中的算术运算及其实现原理。
一、加法运算加法是最基本的算术运算之一,数字电路实现加法运算主要通过全加器来实现。
全加器是一个三输入一输出的电路,它可以将两个二进制位以及进位标志位相加得到一个和位以及进位输出。
在数字电路中,两个二进制位的加法运算可以通过级联多个全加器来实现。
每个全加器的输入由两个相对应的二进制位和上一个全加器的进位输出决定,输出则作为下一个全加器的进位输入。
二、减法运算减法是加法的逆运算,数字电路实现减法运算一般通过在加法运算的基础上做一些变换来实现。
常用的方法是采用补码进行减法运算。
在补码表示法中,正数和负数的表示方式略有不同。
正数的补码与原码相同,负数的补码是将对应正数的补码按位取反,再加1。
通过这种方式,减法运算可以转化为加法运算,即将被减数与减数的补码相加得到结果。
三、乘法运算乘法是多位数相乘得到另一个多位数的运算,数字电路实现乘法运算一般采用乘法器来实现。
乘法器是一个复杂的电路,通过将乘法转化为多次的移位和加法运算来实现。
在数字电路中,乘法运算可以采用“部分积”的形式进行。
具体步骤为:将乘数的每一位与被乘数相乘,然后将所得结果相加得到最终的积。
这个过程可以通过逐位与被乘数相乘并将乘积相加的方式实现。
四、除法运算除法是将一个数分为若干个相等或近似相等部分的运算,数字电路实现除法运算一般通过除法器来实现。
除法器是一个复杂的电路,它通过对除数和被除数进行移位、减法和比较等操作,逐步计算出商和余数。
在数字电路中,除法运算可以采用“长除法”的形式进行。
具体步骤为:先将除数与被除数进行比较,如果除数小于被除数,则商的对应位为0,之后将除数左移一位,再与被除数比较,直到比较结果大于被除数为止。
原码乘法器原理今天来聊聊原码乘法器原理。
你看啊,在生活里我们经常会遇到计数和相乘的情况。
比如说去市场买苹果,每个苹果3元钱,你想买5个,很自然地就会用3乘以5得到15元。
这简单的乘法呢,在电子设备里,原码乘法器就像是一个超级算账小能手,专门处理这样的数学计算,不过是用一种适合机器运行的方式。
说到原码乘法,咱们先讲讲什么是原码。
原码呢,就是一个数的二进制表示,很直白地表示出了数的正负。
就好像用+ 和- 号表示正数和负数一样简单直接。
那原码乘法器的原理啊,就像是我们人工计算乘法竖式的过程。
打个比方吧,假设我们要计算12乘以5(这里为了方便理解我们先用十进制举例)。
我们会用5依次乘以12的每一位数,然后错位相加。
原码乘法器在二进制世界里做的差不多就是这样的事儿。
它把两个要相乘的原码数,一个看成被乘数,一个看成乘数。
先看乘数的最低位,如果是1呢,就把被乘数照原样写下来;如果是0呢,就写0。
然后把这个结果往左移动一位(这就像是竖式计算里的错位啦),再看乘数的下一位,同理操作,最后把这些结果加起来。
有意思的是,在机器里做这些事情,可不像咱们拿笔在纸上算这么简单。
机器是用电信号和一堆逻辑电路来表示这些数字和运算的。
比如说逻辑门电路,就像一道道小关卡一样,它们对电信号进行处理,从而完成乘数位与被乘数位的判断、移位和相加等操作。
老实说,我一开始也不明白为什么原码乘法器要这么复杂地设计,后来发现这和计算机内部的体系结构有关。
计算机的硬件结构决定了它处理数据的方式,原码乘法器这样设计可以高效地利用硬件资源并且以比较稳定的方式完成乘法计算。
在实际应用当中啊,原码乘法器用处可大了。
就像在数字信号处理中,对一些音频、视频信号进行编码和解码时,经常会涉及到很多乘法运算。
原码乘法器就会以非常快的速度完成这些运算,保证我们看到顺畅的视频和听到清晰的音频。
不过要注意哦,原码乘法也有一些小问题呢。
由于原码表示正负的方式,在计算的过程中可能会涉及到比较复杂的符号处理,还可能会有精度的损失。
各种乘法器比较韦其敏08321050引言:乘法器频繁地使用在数字信号处理和数字通信的各种算法中,并往往影响着整个系统的运行速度。
如何实现快速高效的乘法器关系着整个系统的运算速度和资源效率。
本位用如下算法实现乘法运算:并行运算、移位相加、查找表、加法树。
并行运算是纯组合逻辑实现乘法器,完全由逻辑门实现;移位相加乘法器将乘法变为加法,通过逐步移位相加实现;查找表乘法器将乘积结果存储于存储器中,将操作数作为地址访问存储器,得到的输出数据就是乘法运算结果;加法树乘法器结合移位相加乘法器和查找表乘法器的优点,增加了芯片耗用,提高运算速度。
注:笔者使用综合软件为Quartus II 9.1,选用器件为EP2C70,选用ModelSim SE 6.1b进行仿真,对于其他的软硬件环境,需视具体情况做对应修改。
汇总的比较:详细实现过程:1.并行乘法器源代码:module Mult1(outcome,a,b);parameter MSB=8;input [MSB:1] a,b;output [2*MSB:1] outcome;assign outcome=a*b;endmodule资源耗用情况:ModelSim测试激励文件源代码:`timescale 10ns/1nsmodule Mult1_test();reg [8:1] a,b;wire [16:1] outcome;Mult1 u1(outcome,a,b); parameter delay=2;initialbegina=1;b=0;endinitial foreverbegin#delaya=a+1;b=b+1;if(outcome>=16'h0FFF)$stop;endendmodule仿真时序波形:结果分析:DE2-70拥有300个嵌入式硬件乘法器单元,Quartus II综合并行乘法器时自动采用嵌入式乘法器来实现,因此中和报表中仅耗用了一个LE单元和一个九位的嵌入式乘法器单元。
如果把器件改成Cyclone系列的EP1C3,则由于该器件没有内嵌硬件乘法器,综合实现并行乘法器所耗用的LE单元数需要106个,如下图所示:并行乘法器可以看作是纯组合逻辑电路,依靠组合逻辑实现两数相乘,这种方法能在输入数据改变时立即得到相乘结果,延时很短,但是耗用的资源随操作数位数的增加而迅速变多。
并行乘法器实现代码非常简短,适用于器件内有嵌入式硬件乘法器的情况。
2.移位相加乘法器源代码:module shifta(r,l,e,clk,q);input [7:0] r;input l,e,clk;output reg [15:0] q;integer k;wire [15:0] r16;assign r16={{8{1'b0}},r};always@(posedge clk)beginif(l) q<=r16;else if(e)begin q[0]<=1'b0;for(k=1;k<16;k=k+1)q[k]<=q[k-1];endendendmodulemodule shiftb(r,l,e,clk,q0,z);input [7:0] r;input l,e,clk;output q0,z;reg [7:0] q;integer k;always@(posedge clk)beginif(l) q<=r;else if(e)beginfor(k=7;k>0;k=k-1)q[k-1]<=q[k];q[7]<=1'b0;endendassign z=(q==0);assign q0=q[0];endmodulemodule sum(a,p,psel,sum);input [15:0] a,p;input psel;output [15:0] sum;reg [15:0] sum;wire [15:0] ap_sum;integer k;assign ap_sum=a+p;always @(psel or ap_sum)begin sum=psel?ap_sum:16'b0; end endmodulemodule reg16(r,clk,rst,e,q);input [15:0] r;input clk,rst,e;output reg [15:0] q;always@(posedge clk or negedge rst) beginif(rst==0) q<=0;else if(e) q<=r;endendmodulemodule Mult2(clock,reset,s,z,b0,ea,eb,ep,psel,done);input clock,reset,s,z,b0;output reg done;output reg ea,eb,ep,psel;reg [1:0] t,y;parameter S1=2'b00,S2=2'b01,S3=2'b10;always @(s or t or z)begin: state_tablecase(t)S1: if(s==0) y=S1; else y=S2;S2: if(z==0) y=S2; else y=S3;S3: if(s==1) y=S3; else y=S1;default: y=2'bxx;endcaseendalways@(posedge clock or negedge reset)begin: state_flipflopsif(reset==0) t<=S1;else t<=y;endalways@(s or t or b0)begin: fsm_outputsea=0;eb=0;ep=0;done=0;psel=0;case(t)S1:ep=1;S2:begin ea=1;eb=1;psel=1;if(b0) ep=1;else ep=0;endS3:done=1;endcaseendendmodule顶层原理图:也可以使用Verilog HDL例化模块代替顶层原理图,代码如下:module Mult2(DataA,LA,DataB,LB,clk,reset,start,p,Done);input [7:0] DataA,DataB;input LA,LB,clk,reset,start;output [15:0] p;output Done;wire EA,EB,EP,ER,psel,qb,zb;wire [15:0] qa,sum;multshift_cntrlf0(.clock(clk),.reset(reset),.s(start),.z(zb),.b0(qb),.ea(EA),.eb(EB),.ep(EP),.psel(psel),.done(Done)); shifta f1(.r(DataA),.l(LA),.e(EA),.clk(clk),.q(qa));shiftb f2(.r(DataB),.l(LB),.e(EB),.clk(clk),.q0(qb),.z(zb));sum f3(.a(qa),.p(p),.psel(psel),.sum(sum));reg16 f4(.r(sum),.clk(clk),.rst(reset),.e(EP),.q(p));endmodule资源耗用情况:RTL图:顶层:Shifta: shiftb:ModelSim测试激励文件源代码:`timescale 10ns/1nsmodule Mult2_test();reg [7:0] a,b;reg reset,clk,start,la,lb;wire done;wire [15:0] outcome;Mult2u1(.DataA(a),.LA(la),.DataB(b),.LB(lb),.clk(clk),.reset(reset),.start(start),.p(outcome),.Done(done)); parameter delay=2;integer i;initialbegina=0;b=0;reset=0;start=0;la=0;lb=0;clk=0;i=0;endinitial foreverbegin#delayclk=~clk;i=i+1;if(i==50)$stop;endinitialbegin#delay#delay#delay#delay#delayreset=1;#delaya=62;b=40;start=1;la=1;lb=1;#delay#delaystart=0;;la=0;lb=0;#delay#delaya=0;b=0;endendmoduleModelSim仿真结果波形图:结果分析:在综合报表中可以看到,移位相加乘法器实现八位乘法器仅仅使用了50个LE单元和43个寄存器。
在不使用嵌入式硬件乘法器的情况下,移位相加乘法器相比于并行乘法器更节省资源,这随操作数位数的增加而越发明显。
而其缺点则在于,由于需要进行逐步移位,因而需要一定的时间来完成两数相乘操作。
从ModelSim仿真波形可以看出,从开始到完成需要经历8个时钟周期。
3.查找表乘法器顶层原理图:LMP_ROM模块是使用Quartus II自带宏模块自动生成的,其中包含了一个256字节的ROM 存储器。
存储器内存放乘积结果,需要使用文件(Mult3_rom.mif)进行初始化,用来实现乘法功能。
mif文件生成方法有很多种,常用的有Matlab,C语言等,也可以直接用文本编辑软件(如记事本)按照规律直接输入。
笔者使用LabVIEW软件生成该mif文件,程序如下图所示。
程序运行后会在程序所在目录生成所需文件(Mult3_rom.mif)。
也可以使用Verilog HDL例化模块代替顶层原理图,代码如下:module Mult3(a,b,clk,outcome);input [3:0] a,b;input clk;output [7:0] outcome;wire [7:0] din;assign din[7:4]=a;assign din[3:0]=b;LMP_ROM u1(.address(din),.clock(clk),.q(outcome)); Endmodule资源耗用情况:RTL图:由于需要调用Quartus II内置的LPM_ROM宏模块,所以无法用ModelSim进行仿真。
使用直接使用Quartus II进行时序仿真,结果如下图:结果分析:查找表乘法器将乘积结果直接存放在存储器中,将操作数作为地址访问存储器,得到的输出数据就是乘法的结果。