模式识别实验贝叶斯最小错误率分类器设计
- 格式:doc
- 大小:175.00 KB
- 文档页数:6


实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。

模式识别专业:电子信息工程班级:电信****班学号:********** 姓名:艾依河里的鱼一、贝叶斯决策(一)贝叶斯决策理论 1.最小错误率贝叶斯决策器在模式识别领域,贝叶斯决策通常利用一些决策规则来判定样本的类别。
最常见的决策规则有最大后验概率决策和最小风险决策等。
设共有K 个类别,各类别用符号k c ()K k ,,2,1 =代表。
假设k c 类出现的先验概率()k P c以及类条件概率密度()|k P c x 是已知的,那么应该把x 划分到哪一类才合适呢?若采用最大后验概率决策规则,首先计算x 属于k c 类的后验概率()()()()()()()()1||||k k k k k Kk k k P c P c P c P c P c P P c P c ===∑x x x x x然后将x 判决为属于kc ~类,其中()1arg max |kk Kk P c ≤≤=x若采用最小风险决策,则首先计算将x 判决为k c 类所带来的风险(),k R c x ,再将x 判决为属于kc ~类,其中()min ,kkk R c =x可以证明在采用0-1损失函数的前提下,两种决策规则是等价的。
贝叶斯决策器在先验概率()k P c 以及类条件概率密度()|k P c x 已知的前提下,利用上述贝叶斯决策规则确定分类面。
贝叶斯决策器得到的分类面是最优的,它是最优分类器。
但贝叶斯决策器在确定分类面前需要预知()k P c 与()|k P c x ,这在实际运用中往往不可能,因为()|k P c x 一般是未知的。
因此贝叶斯决策器只是一个理论上的分类器,常用作衡量其它分类器性能的标尺。
最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j j i i X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即()()1,min k i i aR a x R a x ==则k a 就是最小风险贝叶斯决策。

一、实验意义及目的1、掌握贝叶斯判别定理2、能利用matlab编程实现贝叶斯分类器设计3、熟悉基于matlab的算法处理函数,并能够利用算法解决简单问题二、算法原理贝叶斯定理是关于随机事件A和B的条件概率(或边缘概率)的一则定理。
其中P(A|B)是在B发生的情况下A发生的可能性公式为:贝叶斯法则:当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。
内容:(1)两类w服从正态分布,设计基于最小错误率的贝叶斯分类器,对数据进行分类。
(2)使用matlab进行Bayes判别的相关函数,实现上述要求。
(3)针对(1)中的数据,自由给出损失表,并对数据实现基于最小风险的贝叶斯分类。
三、实验内容(1)尝两类w服从正态分布,设计基于最小错误率的贝叶斯分类器,对数据进行分类。
代码清单:clc;clear all;meas=[0 0;2 0;2 2;0 2;4 4;6 4;6 6;4 6];%8x2矩阵这里一行一行2个特征[N n]=size(meas);species={'one';'one';'one';'one';'two';'two';'two';'two'};%这里也对应一行一行的sta=tabulate(species)[c k]=size(sta);priorp=zeros(c,1);for i=1:cpriorp(i)=cell2mat(sta(i,k))/100;%计算概率end%cell2mat(sta(:,2:3)) 提取数组中的数据本来sta数组中数据为矩阵不能直接用%估算类条件概率参数cpmean=zeros(c,n);cpcov=zeros(n,n,c);for i=1:ccpmean(i,:)=mean(meas(strmatch(char(sta(i,1)),species,'exact'),:));%exact精确查找cpmean放的每一类的均值点几类就几行cpcov(:,:,i)=cov(meas(strmatch(char(sta(i,1)),species,'exact'),:))*(N*priorp(i)-1)/(N*priorp(i));end%求(3 1)的后验概率x=[3 1];postp=zeros(c,1);for i=1:cpostp(i)=priorp(i)*exp(-(x-cpmean(i,:))*inv(cpcov(:,:,i))*(x-cpmean(i,:))'/2)/((2*pi)^(n/2)*det(cpcov(:,:,i)));endif postp(1)>postp(2)disp('第一类');elsedisp('第二类');end运行结果:(2)使用matlab进行Bayes判别的相关函数,实现上述要求。

实验1 图像的贝叶斯分类1.1 实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
1.2 实验仪器设备及软件HP D538、MATLAB1.3 实验原理1.3.1 基本原理阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
此过程中,确定阈值是分割的关键。
对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。

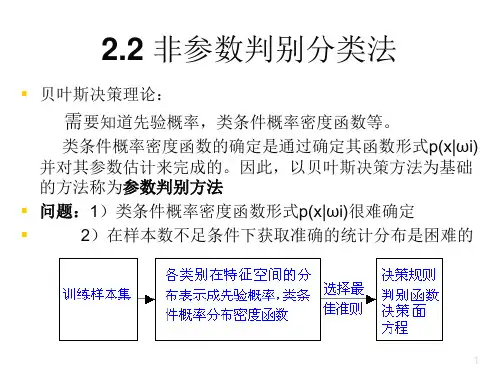
1、模式识别主要由四部分组成:数据获取、预处理、特征提取和选择、分类决策。
2、预处理的目的就是去除噪声,加强有用的信息。
3、特征提取和选择是为了有效地实现分类识别,对原始数据进行变换,得到最能反映分类本质的特征。
4、分类决策就是在特征空间中用统计方法把被识别的对象归为某一类。
5、统计决策理论是处理模式分类问题的基本问题之一,它对模式分析和分类器的设计有着实际的指导意义。
6、几种常用的决策规则:(1)基于最小错误率的贝叶斯决策(尽量减少分类的错误)(2)基于最小风险的贝叶斯决策(考虑各种错误造成的不同损失)(3)在限定一类错误率条件下是另一类错误率为最小的两类别决策(限制其中某一类错误率不得大于某个常数而是另一类错误率尽可能小)(4)最小最大决策(5)序贯分类法(先用一部分特征来分类,逐步加入特征以减少分类损失)(6)分类器(基于上面的四种决策规则对观察向量x进行分类是分类器设计的主要问题)7、对观察样本进行分类是模式识别的目的之一。
8、在分类器设计出来以后总是以错误率的大小,通常来衡量其性能的优劣。
9、再利用样本集设计分类器的过程中,利用样本集估计错误率是个不错的选择。
10、对于错误率的估计问题可分为两种情况:(1)对于已设计好的分类器,利用样本来估计错误率。
(2)对于为设计好的分类器,需将样本空间分成两部分,即分为设计集和检验集,分别用以设计分类器和估计错误率。
线性判别函数1、在实际问题中,我们往往不去恢复类条件概率密度,而是利用样本集直接设计分类器。
即首先给定某个判别函数类,然后利用样本集确定出判别函数类中的未知参数。
2、将分类器设计问题转化为求准则函数极值的问题,这样就可以利用最优化技术解决模式识别问题。
3、决策树,又称多级分类器,是模式识别中进行分类的一种有效方法,对于多类或多峰分布问题,该方法尤为方便。
利用数分类器可以把一个复杂的多类别分类问题转化为若干个简单的分类问题来解决。
它不是企图用一种算法、一个决策规则去把多个类别一次分开,而是采用分级的形式,是分类问题逐步得到解决。

模式识别大作业(总21页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如 vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率 vs. 图2先验概率 vs.图3先验概率 vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2); error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。


模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。

实验一 Bayes 分类器设计【实验目的】对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
【实验原理】最小风险贝叶斯决策可按下列步骤进行:(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即()()1,min k i i aR a x R a x ==则k a 就是最小风险贝叶斯决策。
【实验内容】假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率是的曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为N (-2,0.25)、N (2,4)试对观察的结果进行分类。
【实验要求】1)用matlab 完成基于最小错误率的贝叶斯分类器的设计,要求程序相应语句有说明文字,要求有子程序的调用过程。
第一章 绪论1.什么是模式?具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的___信息__。
2.模式识别的定义?让计算机来判断事物。
3.模式识别系统主要由哪些部分组成?数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第二章 贝叶斯决策理论1.最小错误率贝叶斯决策过程? 答:已知先验概率,类条件概率。
利用贝叶斯公式得到后验概率。
根据后验概率大小进行决策分析。
2.最小错误率贝叶斯分类器设计过程?答:根据训练数据求出先验概率类条件概率分布 利用贝叶斯公式得到后验概率如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3.最小错误率贝叶斯决策规则有哪几种常用的表示形式? 答:4.贝叶斯决策为什么称为最小错误率贝叶斯决策?答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式答:∑====mj Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)⎩⎨⎧∈>=<211221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑===Mj j j i i i i i A P A B P A P A B P B P A P A B P B A P 1)()|()()|()()()|()|(= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布?答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。
Bayes分类器设计实验⼆ Bayes 分类器设计⼀、实验⽬的通过实验,加深对统计判决与概率密度估计基本思想、⽅法的认识,了解影响Bayes 分类器性能的因素,掌握基于Bayes 决策理论的随机模式分类的原理与⽅法。
⼆、实验内容设计Bayes 决策理论的随机模式分类器。
假定某个局部区域细胞识别中正常(a 1)与⾮正常(a 2)两类先验概率分别为正常状态:P(a 1)=0、9; 异常状态:P(a 2)=0、1。
三、⽅法⼿段Bayes 分类器的基本思想就是依据类的概率、概密,按照某种准则使分类结果从统计上讲就是最佳的。
换⾔之,根据类的概率、概密将模式空间划分成若⼲个⼦空间,在此基础上形成模式分类的判决规则。
准则函数不同,所导出的判决规则就不同,分类结果也不同。
使⽤哪种准则或⽅法应根据具体问题来确定。
四、Bayes 算法1、实验原理多元正太分布的概率密度函数由下式定义112211()exp ()()2(2)T dp X X X µµπ-??=--∑-∑ 由最⼩错误概率判决规则,可得采⽤如下的函数作为判别函数()(|)(),1,2,,i i i g x p X P i N ωω==L这⾥,()i P ω为类别i ω发⽣的先验概率,(|)i p X ω为类别i ω的类条件概率密度函数,⽽N 为类别数。
设类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p X ω,i=1,2,……,N 服从正态分布,即有(|)i p X ω~(,)i i N µ∑,那么上式就可以写为1122()1()exp ()(),1,2,,2(2)T i i dP g X X X i N ωµµπ-??=--∑-=∑L由于对数函数为单调变化的函数,⽤上式右端取对数后得到的新的判别函数替代原来的判别函数()i g X 不会改变相应分类器的性能。
因此,可取111()()()ln ()ln ln(2)222T i i i i i i d g X X X P µµωπ-=--∑-+-∑- 显然,上式中的第⼆项与样本所属类别⽆关,将其从判别函数中消去,不会改变分类结果。
贝叶斯分类器设计原理与实现贝叶斯分类器是一种基于贝叶斯定理的机器学习算法,常被用于文本分类、垃圾邮件过滤等任务。
本文将介绍贝叶斯分类器的设计原理和实现。
一、贝叶斯分类器的原理贝叶斯分类器基于贝叶斯定理,该定理描述了在已知一些先验条件下,如何通过新的观测数据来更新我们对于某个事件发生概率的判断。
在分类任务中,我们希望通过已知的特征,预测出一个样本属于某一类别的概率。
在贝叶斯分类器中,我们通过计算后验概率来决定样本的分类。
后验概率是指在已知某个条件下,事件发生的概率。
根据贝叶斯定理,后验概率可以通过先验概率和条件概率来计算。
先验概率是指在没有任何其他信息的情况下,事件发生的概率;条件概率是指在已知其他相关信息的情况下,事件发生的概率。
贝叶斯分类器根据特征的条件独立性假设,将样本的特征表示为一个向量。
通过训练数据,我们可以计算出每个特征在不同类别中的条件概率。
当有一个新的样本需要分类时,我们可以根据贝叶斯定理和特征的条件独立性假设,计算出该样本属于每个类别的后验概率,从而实现分类。
二、贝叶斯分类器的实现贝叶斯分类器的实现主要包括训练和预测两个步骤。
1. 训练过程训练过程中,我们需要从已知的训练数据中学习每个特征在不同类别下的条件概率。
首先,我们需要统计每个类别出现的频率,即先验概率。
然后,对于每个特征,我们需要统计它在每个类别下的频率,并计算出条件概率。
可以使用频率计数或者平滑方法来估计这些概率。
2. 预测过程预测过程中,我们根据已训练好的模型,计算出待分类样本属于每个类别的后验概率,并选择具有最大后验概率的类别作为最终的分类结果。
为了避免概率下溢问题,通常会将概率取对数,并使用对数概率进行计算。
三、贝叶斯分类器的应用贝叶斯分类器在自然语言处理领域有广泛的应用,尤其是文本分类和垃圾邮件过滤。
在文本分类任务中,贝叶斯分类器可以通过学习已有的标记文本,自动将新的文本分类到相应的类别中。
在垃圾邮件过滤任务中,贝叶斯分类器可以通过学习已有的垃圾邮件和正常邮件,自动判断新的邮件是否为垃圾邮件。
实验二 贝叶斯最小错误率分类器设计
一、实验目的
1. 了解模式识别中的统计决策原理
2. 熟悉并会根据给出的相关数据设计贝叶斯最小错误率分类器。
3. 熟悉并会使用matlab 进行相关程序的编写
二、实验原理
分类器的设计首先是为了满足对数据进行分门别类,是模式识别中一项非常基本和重要的任务,并有着极其广泛的应用。
其定义是利用预定的已分类数据集构造出一个分类函数或分类模型(也称作分类器),并利用该模型把未分类数据映射到某一给定类别中的过程。
分类器的构造方法很多,主要包括规则归纳、决策树、贝叶斯、神经网络、粗糙集、以及支持向量机(SVM)等方法。
其中贝叶斯分类方法建立在贝叶斯统计学的基础之上,能够有效地处理不完整数据,并且具有模型可解释、精度高等优点,而被认为是最优分类模型之一。
本实验就是基于贝叶斯方法的分类器构造,其中构造的准则是最小错误率。
下面,我们对最小错误率的分类器设计做一个简单的回顾。
假设是一个二类的分类问题,有12,ωω两类。
若把物体分到1ω类中,那么所犯的错误有两种情况,一种是物体本属于1ω类,分类正确,错误率为0;另一种情况是,物体本属于2ω类,分类错误,错误率就为11-(|)p x ω。
因此,要使得错误率最小的话,1(|)p x ω就应该最大。
而第一种情况,也可以归属于1(|)=1p x ω。
因此,基于贝叶斯最小错误率的二类分类决策规则可以表述为如下表达式。
121
122
(|)>(|)(|)<(|)p x p x x p x p x x ωωωωωω∈⎧⎨
∈⎩ 同理,推广到多类分类,比如说有N 类时,贝叶斯最小错误率分类决策规则可以做出
如下表述:
(| ) = arg max p(| ) j=1,2,
N,i j i j
p x x x ωωω∈
从上述表达式,我们可以看出,贝叶斯最小错误率分类器设计的决策规则就相当于后验概率最大的决策规则。
三、实验内容与要求
1. 实验数据
任务:将细胞识别进行正常和异常的两类分类
已知数据:假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类,其中先验概率分别为
正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
两类的类条件概率分布为参数是(-2,0.25)和(2,4)的正态分布。
现有一系列待观察的细胞,其观察值为表1所示。
2. 实验要求
(1)用Matlab 完成分类器的设计,要求程序相应语句有说明文字,最好有子程序的调用过程。
(2)根据例子画出后验概率的分布曲线,并给出分类的结果填入表1中。
选作:假若决策准则为贝叶斯最小风险,且决策表如下所示:
最小风险贝叶斯决策表:
请重新设计程序,画出相应的后验概率的分布曲线和分类结果,并比较两个结果。
实验原理及内容:
在已知P(w i ),P(X|w i ) ,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:
假设是一个二类的分类问题,有12,ωω两类。
若把物体分到1ω类中,那么所犯的错误有两种情况,一种是物体本属于1ω类,分类正确,错误率为0;另一种情况是,物体本属于2ω类,分类错误,错误率就为11-(|)p x ω。
因此,要使得错误率最小的话,1(|)p x ω就应该最大。
而第一种情况,也可以归属于1(|)=1p x ω。
因此,基于贝叶斯最小错误率的二类分类决策规则可以表述为如下表达式。
121
122
(|)>(|)(|)<(|)p x p x x p x p x x ωωωωωω∈⎧⎨
∈⎩
将X 归类于后验概率最小的那一类。
序号 1 2 3 4
5
6
7
8
观察值
3.9847
-3.5549
1.2401
-0.9780
-0.7932
-2.8531
-2.7605
-3.7287
类别
W1 W1 W1 W1 W1 W1 W1 W1 序号 9
10
11
12
13
14
15
16
观察值 -3.5414
-2.2692
-3.4549
-3.0752
-3.9934
2.8792
-0.9780
0.7932
类别 W1 W1 W1 W1 W1 W2 W1 W2 序号 17
18
19
20 21 22
23
24
观察值 1.1882
3.0682
-1.5799
1.4885 0.7431
-0.4221
-1.1186
4.2532
类别
W2 W2 W1 W1
W1
W2 W1 W2
实验程序:
x= [-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682
-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 ] pw1=0.9 ; pw2=0.1 e1=-2; a1=0.5 e2=2;a2=2
m=numel(x) %得到待测细胞个数
pw1_x=zeros(1,m) %存放对w1的后验概率矩阵
pw2_x=zeros(1,m) %存放对w2的后验概率矩阵
results=zeros(1,m) %存放比较结果矩阵
for i = 1:m %计算在w1下的后验概率
pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2))
%计算在w2下的后验概率
pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2))
end
for i = 1:m
if pw1_x(i)>pw2_x(i) %比较两类后验概率
result(i)=0 %正常细胞
else
result(i)=1 %异常细胞
end
end
a=[-5:0.05:5] %取样本点以画图
n=numel(a)
pw1_plot=zeros(1,n)
pw2_plot=zeros(1,n)
for j=1:n
pw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2)) %计算每个样本点对w1的后验概率以画图
pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2))
end
figure(1)
hold on
plot(a,pw1_plot,'k-',a,pw2_plot,'r-.')
for k=1:m
if result(k)==0
plot(x(k),-0.1,'b*') %正常细胞用*表示
else
plot(x(k),-0.1,'rp') %异常细胞用五角星表示
end;
end;
legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞') xlabel('样本细胞的观察值')
ylabel('后验概率')
title('后验概率分布曲线')
grid on
return ;
实验结果与分析
曲线分析如下
后验概率曲线与判决结果在一张图上:后验概率曲线如图所示,带*的曲线为判决成异常细胞的后验概率曲线;另一条平滑的曲线为判为正常细胞的后验概
率曲线。
根据最小错误概率准则,判决结果见曲线下方,其中“*”代表判决为正常细胞,“五角星”代表异常细胞各细胞分类结果:
各细胞分类结果:
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 0 1 0
1
0为判成正常细胞,1为判成异常细胞
实验心得与体会
通过这次试验,我了解了贝叶斯最小错误率分类器的优势,通过计算期望,可以对现实问题进行数学计算,从而获得最优解。
但由于我水平有限,难以做出结果,所以只能从网络上寻找答案,并仔细阅读了程序,希望对以后的学习有一定的帮助。
经过实验,我对模式识别的认识更深入了,希望能学好模式识别。