HMM隐形马尔可夫模型实验报告(可打印修改)
- 格式:pdf
- 大小:142.41 KB
- 文档页数:7

隐马尔科夫模型在体育竞技中的应用实践一、介绍隐马尔科夫模型隐马尔科夫模型(Hidden Markov Model, HMM)是一种用于对时间序列数据进行建模和预测的统计模型。
它是由Soviet mathematician Andrey Markov于20世纪初提出的,后来由Leonard E. Baum和其他科学家拓展和完善。
HMM被广泛应用于语音识别、自然语言处理、生物信息学等领域,并且在体育竞技中也有着重要的应用。
二、HMM在体育竞技中的应用1. 运动员状态预测在体育竞技中,运动员的状态(如疲劳、兴奋、专注等)对比赛结果有着重要的影响。
HMM可以通过分析历史比赛数据和运动员的生理指标,预测运动员当前的状态,进而指导教练制定训练和比赛策略。
2. 比赛结果预测体育竞技的结果往往受到众多因素的影响,包括运动员的表现、赛事的环境、对手的水平等等。
HMM可以对这些因素进行建模,从而帮助分析预测比赛结果。
例如,在足球比赛中,HMM可以考虑球队的历史表现、主客场优势、对手实力等因素,得出对比赛结果的预测。
3. 运动员能力评估HMM可以对运动员的能力进行量化评估。
通过对运动员比赛数据的分析,结合HMM的模型,可以得出运动员在不同方面的能力水平,为训练和选拔提供科学依据。
三、HMM在体育竞技中的案例分析1. 篮球比赛中的应用研究人员利用HMM对NBA比赛数据进行分析,发现在比赛的关键时刻,球员的状态转移会对比赛结果产生重要影响。
通过对比赛数据的建模和分析,他们提出了一种更科学的换人策略,取得了较好的效果。
2. 足球运动员状态预测在一项研究中,科学家利用HMM对足球运动员的生理数据进行分析,发现在比赛中,运动员的状态变化与比赛结果密切相关。
基于这一发现,他们提出了一种针对不同状态的训练策略,帮助运动员提高竞技表现。
3. 棒球比赛结果预测研究人员使用HMM对棒球赛事的历史数据进行分析,发现投手的状态变化与比赛结果有关。



基于隐马尔可夫模型的机器翻译研究机器翻译是一项依赖于计算机技术的研究,旨在将一种自然语言(源语言)转换成另一种自然语言(目标语言)。
随着人工智能技术的日益发展,机器翻译技术不断完善,其应用领域也越来越广。
与传统的基于规则和统计分析的机器翻译方法相比,基于隐马尔可夫模型(Hidden Markov Model,HMM)的机器翻译方法在语音识别、自然语言处理等领域具有广泛的应用前景。
一、HMM的基本原理HMM是一种基于概率模型的非监督学习算法,是统计机器学习中的经典算法之一。
它被广泛应用于语音识别、文本分类、自然语言处理等领域。
HMM模型由初始概率分布、状态转移概率矩阵、状态观测概率矩阵三部分组成。
假设一个序列的每一个元素到底处于哪一个状态是未知的,仅知道每个状态发射对应观测值的概率。
HMM的目标是根据观测序列,推断出最有可能的隐含状态序列。
这个过程被称为解码。
二、HMM在机器翻译中的应用随着人们生活方式的改变和经济全球化的发展,人们在跨文化交流和国际贸易中越来越需要进行语言翻译。
机器翻译技术的发展不断推动着这项工作的进步。
基于HMM的机器翻译使用的是隐含语言模型,它能够学习源语言和目标语言之间的映射关系,从而实现准确、高速的机器翻译。
HMM作为一种基本的语音识别算法,最早被应用于机器翻译中的语音翻译问题。
由于语音翻译涉及到多个层面的信息,包括声音、语法、词法和语义等方面,所以使用HMM将声学模型和语言模型进行结合,可以有效地提高翻译的准确性。
三、HMM机器翻译技术的优缺点基于HMM的机器翻译技术,虽然能够有效地提高翻译的准确性,但也存在一些不足之处。
比如说,HMM是一种传统方法,它对于长句和复杂句子的处理效果并不好。
此外,HMM模型需要存储大量的概率矩阵,计算速度相对较慢,同时需要大量的训练数据。
不过,尽管存在这些缺点,基于HMM的机器翻译技术仍然具有其独特的优点。
HMM能够精确地识别语音,在音信号处理方面有着广泛的应用。
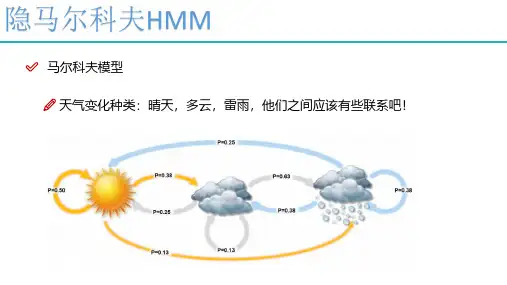
马尔科夫模型天气变化种类:晴天,多云,雷雨,他们之间应该有些联系吧!马尔科夫模型状态之间可以发生转换,昨天和今天转换的情况:马尔科夫模型今天能得到明天的情况,明天能得到后天的情况,以此类推可以无限的玩下去那是不是得有一个初始的情况才能一直玩下去啊!这里我们就定义好了一个一阶马尔科夫模型:状态:晴天,多云,雷雨状态转换概率:三种天气状态间的转换概率初始概率:晴天马尔科夫模型计算今天(t=1)的天气状况:今天为晴天的概率=初始晴天概率X晴天转晴天概率 +初始多云概率X多云转晴天概率 +初始雷雨概率X雷雨转晴天概率。
游戏难度加大了现在我们漂到了一个岛上,这里没有天气预报,只有一片片的海藻。
这些海藻状态能观察到的:这里我们就没有直接的天气信息了,有的是间接的信息,海藻的状态跟天气的变换有一定的关系。
既然海藻是能看到的,那它就是观察状态,天气信息看不到就是隐藏状态。
隐马尔科夫模型隐马尔科夫模型当前的状态只和前一状态有关:某个观测只和生成它的状态有关:隐马尔科夫模型的组成三个必备:初始概率(π),隐藏状态转移概率矩阵(A),生成观测状态概率矩阵(B)。
隐藏状态与观察状态(B矩阵):要解决的问题: 模型为1.给定模型 及观测序列 计算其出现的概率2.给定观测序列 ,求解参数 使得 最大3.已知模型 和观测序列 求状态序列,使得最大求观测序列的概率暴力求解:我们要求的是在给定模型下观测序列出现的概率,那如果我能把所有的隐藏序列都给列出来,也就可以知道联合概率分布 。
, 现在要求的目标就很明确了。
在给定模型下,一个隐藏序列出现的概率,那就由初始状态慢慢转换嘛。
出现的概率为:求观测序列的概率对于固定的隐藏序列 ,得到观察序列 的概率:联合概率:观测序列概率:复杂度:如果隐藏状态数有N个,前向算法给定t时刻的隐藏状态为i,观测序列为o1,o2...ot的概率叫做前向概率:前向算法当t=T时, 这表示最后一个时刻,隐藏状态位于第i号状态上并且观测到y1,y2...yT的概率。

基于隐马尔可夫模型HMM的语音识别系统原理摘要:进入21世纪以来,多媒体信息技术飞跃发展,其中的一个热点就是语音识别技术,实现人机对话及交流一直是人类梦寐以求的。
古典《天方夜谭》中的“芝麻开门”就是一种语音识别。
语音识别(Automatic S!oeechR-ecogndon)就是让机器能听懂人说的话并按照人的意图去执行相应任务,是一门涉及到信号处理,神经心理学,人工智能,计算机,语言学,通信等学科的涉及面非常宽的交艾学科。
近年来,在工业、军事、交通、医学等诸多方面都有着广泛的应用。
关键词:隐马尔可夫模型;信号分析处理:语音识别我们可以设想,在不久的将来坐在办公司里的经理会对电脑说:“嗨!伙计,帮我通知一下公司所有员工,今天下午3:00准时开会。
”这是科学家在几十年前的设想,语音识别长久以来一直是人们的美好愿望,让计算机领会人所说的话,实现人机对话是发展人机通信的主要目标。
进入21世纪,随着计算机的日益普及,怎样给不熟悉计算机的人提供一个友好而又简易的操作平台,是我们非常感兴趣的问题,而语音识别技术就是其中最直接的方法之一。
20世纪80年代中期以来,新技术的逐渐成熟和发展使语音识别技术有了实质性的进展,尤其是隐马尔可夫模型(HMM)的研究和广泛应用,推动了语音识别的迅速发展,同时,语音识别领域也正处在一个黄金开发的关键时期,各国的开发人员正在向特定人到非特定人,孤立词汇向连接词,小词汇量向大词汇量来扩展研究领域,可以毫不犹豫地说,语音识别会让计算机变得“善解人意”,许多事情将不再是“对牛弹琴”,最终用户的口述会取代鼠标,键盘这些传统输入设备,只需要用户的嘴和麦克风就能实现对计算机的绝对控制。
1隐马尔可夫模型HMM的引入现在假定HMM是一个输出符号序列的统计模型,具有N个状态s1,s2…sn,在一个周期内从一个状态转到另一个状态,每次转移时输出一个符号,转移到了哪个状态以及输出什么符号,分别由状态转移概率和转移时的输出概率来决定,由于只能观测到输出符号序列,不能观测到状态转移序列,因此成为隐藏的马尔可夫模型。

基于隐马尔可夫模型(hmm)的模式识别理论报告人:时间:2020年4月21日地点:实验室概述基于隐马尔可夫模型(hmm)的模式识别方法在模式识别中有着广泛的应用。
如语音识别、手写字识别、图想纹理建模与分类。
hmm还被引入移动通信核心技术“多用户的检测”。
近年来,另外在生物信息可学、故障诊断等领域也开始得到应用。
近几年已经已被学者用于人脸识别的研究之中,是今年来涌现出来的优秀人脸识别方法之一。
经过不断改进,尤其是最近的嵌入式隐马尔可夫模型(ehmm)已经在人脸识别方面取得很大的进展,经过实验,识别率较高,有很好的鲁棒性等优点。
隐马尔可夫模型基本理论依据来源于随机过程中马尔可夫过程理论。
马尔可夫及其马尔可夫过程马尔可夫(A. Markov ,1856—1922)俄国数学家. 他开创了一种无后效性随机过程的研究,即在已知当前状态的情况下,过程的未来状态与其过去状态无关,这就是现在大家熟悉的马尔可夫过程.马尔可夫的工作极大的丰富了概率论的内容,促使它成为自然科学和技术直接有关的最重要的数学领域之一.在工程技术方面目前已被广泛用于通信,模式识别方面。
x(t)与马尔可夫过程相关的概念.随机变量与随机过程把随机现象的每个结果对应一个数,这种对应关系称为随机变量.例如某一时间内公共汽车站等车乘客的人数,电话交换台在一定时间内收到的呼叫次数等等,都是随机变量的实例.随机过程随机过程是一连串随机事件动态关系的定量描述.即和“时间”相关的随机变量。
一般记为x(t)。
比如在一天24小时,在每个整点时刻徐州火车站的旅客数量。
马尔可夫过程与马尔可夫链设x(t)是一随机过程,过程在时刻t0+1所处的状态与时刻t0所处的状态相关,而与过程在时刻t0之前的状态无关,这个特性成为无后效性.无后效的随机过程称为马尔可夫过程(MarkovProcess).举例:比如在万恶的旧社会流离失所的百姓在每天的饥饿程度是一个随机过程。
假如他们在t0时刻(今天)的饥饿状态是五分饱,他们在t0+1所(明天)的饥饿状态的概率取决于t0时刻(今天),而和t0时刻(今天)之前(昨天、前天。
机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。

隐马尔可夫模型描述一个含有隐含未知参数的马尔可夫过程
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的数据分析,例如模式识别。
HMM在建模的系统被认为是一个马尔可夫过程与未观测(隐藏的)到状态的统计马尔可夫模型。
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态之间存在转换概率。
可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个做输出概率。
如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。
通过下图骰子例子说明:第一个骰子是我们平常见的骰子(称骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。
第二个骰子是个四面体(称骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
第三个骰子有八个面(称骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
HMM模型相关的算法主要分为三类:
1、知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题有两种解法,给出两个不同的答案。
第一种解法求最大似然状态路径,说通俗点呢,就是求一串骰子序列,这串骰子序列产生观测结果的概率最大。
第二种解法,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。

机器学习_隐马尔可夫模型HMM1. 马尔可夫链马尔可夫链是满足马尔可夫性质的随机过程。
马尔可夫性质是无记忆性。
也就是说,这一时刻的状态,受且只受前一时刻的影响,而不受更往前时刻的状态的影响。
我们下面说的隐藏状态序列就马尔可夫链。
2. 隐马尔可夫模型隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,用它处理的问题一般有两个特征:第一:问题是基于序列的,比如时间序列,或者状态序列。
第二:问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观测到的,即隐藏状态序列,简称状态序列,该序列是马尔可夫链,由于该链不能直观观测,所以叫“隐”马尔可夫模型。
简单地说,状态序列前项能算出后项,但观测不到,观测序列前项算不出后项,但能观测到,观测序列可由状态序列算出。
HMM模型的主要参数是λ=(A,B,Π),数据的流程是通过初始状态Pi生成第一个隐藏状态h1,h1结合生成矩阵B生成观测状态o1,h1根据转移矩阵A生成h2,h2和B再生成o2,以此类推,生成一系列的观测值。
HMM3. 举例1) 问题描述假设我关注了一支股票,它背后有主力高度控盘,我只能看到股票涨/跌(预测值:2种取值),看不到主力的操作:卖/不动/买(隐藏值:3种取值)。
涨跌受主力操作影响大,现在我知道一周之内股票的涨跌,想推测这段时间主力的操作。
假设我知道有以下信息:i. 观测序列O={o1,o2,...oT} 一周的涨跌O={1, 0, 1, 1, 1}ii. HMM模型λ=(A,B,Π)•隐藏状态转移矩阵A 主力从前一个操作到后一操作的转换概率A={{0.5, 0.3,0.2},{0.2, 0.5, 0.3},{0.3, 0.2, 0.5}}•隐藏状态对观测状态的生成矩阵B(3种->2种)主力操作对价格的影响B={{0.6, 0.3, 0.1},{0.2, 0.3, 0.5}}•隐藏状态的初始概率分布Pi(Π)主力一开始的操作的可能性Pi={0.7, 0.2,0.1}2) 代码c) 分析这里我们使用了Python的马尔可夫库hmmlearn,可通过命令 $ pip install hmmlearn安装(sklearn的hmm已停止更新,无法正常使用,所以用了hmmlearn库)马尔可夫模型λ=(A,B,Π),A,B,Π是模型的参数,此例中我们直接给出,并填充到模型中,通过观测值和模型的参数,求取隐藏状态。

HMM基本原理及其实现(隐马尔科夫模型)HMM(隐马尔科夫模型)基本原理及其实现HMM基本原理Markov链:如果⼀个过程的“将来”仅依赖“现在”⽽不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程。
马尔可夫链是时间和状态参数都离散的马尔可夫过程。
HMM是在Markov链的基础上发展起来的,由于实际问题⽐Markov链模型所描述的更为复杂,观察到的时间并不是与状态⼀⼀对应的,⽽是通过⼀组概率分布相联系,这样的模型称为。
HMM是双重随机过程:其中之⼀是Markov链,这是基本随机过程,它描述状态的转移,是隐含的。
另⼀个随机过程描述状态和观察值之间的统计对应关系,是可被观测的。
HMM的定义:HMM实际上是分为两个部分的,⼀是马尔可夫链,由参数,A描述,它利⽤⼀组与概率分布相联系的状态转移的统计对应关系,来描述每个短时平稳段是如何转变到下⼀个短时平稳段的,这个过程产⽣的输出为状态序列;⼆是⼀个随机过程,描述状态与观察值之间的统计关系,⽤观察到的序列来描述隐含的状态,由B描述,其产⽣的输出为观察值序列。
HMM根据其结构的不同可以分为多种类型。
根据状态转移概率矩阵的不同,HMM可分为各态遍历模型、从左到右模型、并⾏路径从左到右模型和⽆跳转从左到右模型等。
根据观察值概率不同,HMM可分为离散HMM、半连续HMM、连续HMM等。
下图是⼀个典型的HMM:HMM有三个典型的问题:已知模型参数,计算某⼀特定输出序列的概率,通常使⽤解决。
已知模型参数,寻找最可能的能产⽣某⼀特定输出序列的隐含状态的序列,通常使⽤解决。
已知输出序列,寻找最可能的状态转移以及输出概率,通常使⽤以及解决。
HMM的实现C语⾔版: 1、 HTK(Hidden Markov Model Toolkit) HTK是英国剑桥⼤学开发的⼀套基于C语⾔的隐马尔科夫模型⼯具箱,主要应⽤于语⾳识别、语⾳合成的研究,也被⽤在其他领域,如字符识别和DNA排序等。
使用隐马尔科夫模型进行航空安全预测的技术指南引言隐马尔科夫模型(Hidden Markov Model, HMM)是一种统计模型,被广泛应用于语音识别、自然语言处理、生物信息学等领域。
在航空领域,HMM也可以被用来进行航空安全预测,帮助航空公司和相关机构更好地了解飞行安全情况,及时发现和解决潜在的安全隐患。
本文将介绍使用HMM进行航空安全预测的技术指南。
HMM简介HMM是一个由状态和观测值组成的动态系统模型。
在HMM中,系统处于一系列可能的状态之一,每个状态都有一个与之相关的输出观测值。
然而,这些状态是隐藏的,我们只能观测到对应的输出值,而不能直接观测到状态本身。
HMM模型由初始状态概率分布、状态转移概率矩阵和观测概率分布组成。
在航空安全预测中,我们可以将飞行过程抽象成一个由不同状态组成的序列,比如起飞、巡航、下降、着陆等。
每个状态对应着一系列观测值,比如飞行高度、速度、机身姿态等。
通过分析这些观测值的序列,我们可以利用HMM模型来预测飞行过程中的潜在安全隐患。
数据准备在使用HMM进行航空安全预测之前,首先需要准备好相关的数据。
这些数据可以包括飞行过程中的各种观测值,比如飞行高度、速度、姿态、气象条件等。
同时,还需要标记每个飞行过程的安全状态,比如正常飞行、飞行故障、紧急情况等。
这些数据可以通过飞行数据记录仪(FDR)和驾驶舱语音记录仪(CVR)来获取。
数据预处理在获得原始数据之后,需要对数据进行预处理,以便用于HMM模型的训练和预测。
预处理的过程包括数据清洗、特征提取和序列标记等步骤。
数据清洗可以去除异常值和缺失值,以保证数据的质量和完整性。
特征提取则是提取出对安全预测有用的特征,比如飞行过程中的关键参数和状态转换情况。
最后,需要给每个飞行过程的状态进行标记,以便用于HMM模型的训练。
模型训练在数据预处理完成后,就可以开始训练HMM模型了。
模型的训练过程包括参数初始化和模型优化两个步骤。
参数初始化是指对HMM模型的初始状态概率分布、状态转移概率矩阵和观测概率分布进行初始化。
隐马尔科夫模型(HMM作者:leivo 来源:博客园发布时间:2010-10-29 00:59 阅读:497 次原文链接[收藏]介绍我们通常都习惯寻找一个事物在一段时间里的变化规律。
在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等。
一个最适用的例子就是天气的预测。
首先,本文会介绍声称概率模式的系统,用来预测天气的变化然后,我们会分析这样一个系统,我们希望预测的状态是隐藏在表象之后的,并不是我们观察到的现象。
比如,我们会根据观察到的植物海藻的表象来预测天气的状态变化。
最后,我们会利用已经建立的模型解决一些实际的问题,比如根据一些列海藻的观察记录,分析出这几天的天气状态。
Generating Patterns有两种生成模式:确定性的和非确定性的。
确定性的生成模式:就好比日常生活中的红绿灯,我们知道每个灯的变化规律是固定的。
我们可以轻松的根据当前的灯的状态,判断出下一状态。
非确定性的生成模式:比如说天气晴、多云、和雨。
与红绿灯不同,我们不能确定下一时刻的天气状态,但是我们希望能够生成一个模式来得出天气的变化规律。
我们可以简单的假设当前的天气只与以前的天气情况有关,这被称为马尔科夫假设。
虽然这是一个大概的估计,会丢失一些信息。
但是这个方法非常适于分析。
马尔科夫过程就是当前的状态只与前n个状态有关。
这被称作n阶马尔科夫模型。
最简单的模型就当n=1时的一阶模型。
就当前的状态只与前一状态有关。
(这里要注意它和确定性生成模式的区别,这里我们得到的是一个概率模型)。
下图是所有可能的天气转变情况:对于有M个状态的一阶马尔科夫模型,共有M*M个状态转移。
每一个状态转移都有其一定的概率,我们叫做转移概率,所有的转移概率可以用一个矩阵表示。
在整个建模的过程中,我们假设这个转移矩阵是不变的。
该矩阵的意义是:如果昨天是晴,那么今天是晴的概率为0.5,多云的概率是0.25,雨的概率是0.25。
隐马尔科夫模型HMM (⼀)HMM 模型 隐马尔科夫模型HMM (⼀)HMM 模型基础 隐马尔科夫模型(Hidden Markov Model ,以下简称HMM )是⽐较经典的机器学习模型了,它在语⾔识别,⾃然语⾔处理,模式识别等领域得到⼴泛的应⽤。
当然,随着⽬前深度学习的崛起,尤其是,等神经⽹络序列模型的⽕热,HMM 的地位有所下降。
但是作为⼀个经典的模型,学习HMM 的模型和对应算法,对我们解决问题建模的能⼒提⾼以及算法思路的拓展还是很好的。
本⽂是HMM 系列的第⼀篇,关注于HMM 模型的基础。
1. 什么样的问题需要HMM 模型 ⾸先我们来看看什么样的问题解决可以⽤HMM 模型。
使⽤HMM 模型时我们的问题⼀般有这两个特征:1)我们的问题是基于序列的,⽐如时间序列,或者状态序列。
2)我们的问题中有两类数据,⼀类序列数据是可以观测到的,即观测序列;⽽另⼀类数据是不能观察到的,即隐藏状态序列,简称状态序列。
有了这两个特征,那么这个问题⼀般可以⽤HMM 模型来尝试解决。
这样的问题在实际⽣活中是很多的。
⽐如:我现在在打字写博客,我在键盘上敲出来的⼀系列字符就是观测序列,⽽我实际想写的⼀段话就是隐藏序列,输⼊法的任务就是从敲⼊的⼀系列字符尽可能的猜测我要写的⼀段话,并把最可能的词语放在最前⾯让我选择,这就可以看做⼀个HMM 模型了。
再举⼀个,我在和你说话,我发出的⼀串连续的声⾳就是观测序列,⽽我实际要表达的⼀段话就是状态序列,你⼤脑的任务,就是从这⼀串连续的声⾳中判断出我最可能要表达的话的内容。
从这些例⼦中,我们可以发现,HMM 模型可以⽆处不在。
但是上⾯的描述还不精确,下⾯我们⽤精确的数学符号来表述我们的HMM 模型。
2. HMM 模型的定义 对于HMM 模型,⾸先我们假设Q 是所有可能的隐藏状态的集合,V 是所有可能的观测状态的集合,即:Q ={q 1,q 2,...,q N },V ={v 1,v 2,...v M } 其中,N 是可能的隐藏状态数,M 是所有的可能的观察状态数。
隐马尔可夫模型(Hidden Markov Model,HMM)是一种用于建模时序数据的统计模型,广泛应用于语音识别、自然语言处理、生物信息学等领域。
随着交通领域数据的不断增加和技术的进步,HMM也被应用于交通预测中,为城市交通管理和规划提供了有力的支持。
一、隐马尔可夫模型概述隐马尔可夫模型是一种具有概率特征的动态系统,描述了一个观测序列和一个状态序列之间的关系。
在HMM中,系统的状态是隐藏的,我们无法直接观测到,但可以通过观测变量间接推断出系统的状态。
HMM包括三个基本要素:状态集合、观测集合和状态转移概率矩阵。
在交通预测中,我们可以将道路交通流量的变化看作观测序列,而交通状态(如畅通、拥堵)则是隐藏的状态序列。
通过对历史交通数据的分析和建模,我们可以利用HMM来预测未来的交通状态和道路流量变化,为交通管理部门提供决策依据。
二、HMM在交通预测中的应用1. 基于历史数据的状态转移概率估计HMM可以通过观测序列的历史数据来估计状态转移概率矩阵,从而揭示不同交通状态之间的转移规律。
例如,拥堵状态可能会持续一段时间后转变为畅通状态,而畅通状态也可能在某些条件下转变为拥堵状态。
这些转移概率的估计可以帮助我们理解交通状态的演变规律,并为未来的交通预测提供基础。
2. 预测未来交通状态利用HMM建模得到的状态转移概率矩阵,可以结合当前的观测序列,通过前向算法和维特比算法来推断未来交通状态的概率分布。
这为交通管理部门提供了预测道路拥堵情况和交通流量的能力,有助于制定合理的交通管控策略和优化交通流。
3. 基于实时数据的动态调整随着交通数据的实时更新,HMM模型能够根据最新的观测序列和历史数据动态调整状态转移概率矩阵,从而实现对交通状态的实时预测。
这种动态调整能够更好地适应交通状态的突发变化,为交通管理部门提供更及时准确的决策支持。
三、实际案例与效果分析在某城市的交通管理中心,他们利用HMM模型对道路交通状态进行预测。
自然语言处理实验报告课程:自然语言处理系别:软件工程专业:年级:学号:姓名:指导教师:实验一隐马尔可夫模型与序列标注实验一、实验目的1掌握隐马尔可夫模型原理和序列标注2使用隐马尔可夫模型预测序列标注二、实验原理1.隐马尔可夫模型隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。
所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。
2. 使用隐马尔可夫模型做预测需要的处理步骤收集数据:可以使用任何方法。
比如股票预测问题,我们可以收集股票的历史数据。
数据预处理:收集完的数据,我们要进行预处理,将这些所有收集的信息按照一定规则整理出来,从原始数据中提取有用的列,并做异常值处理操作。
样本生成:根据收集的数据生成样本。
训练模型:根据训练集,估计模型参数。
序列预测并分析结果:使用模型对测试集数据进行序列标注,计算准确率,进行误差分析,可以进行可视化。
三、实验数据收集1.训练数据由于训练数据需要进行大量标注工作,所以训练数据选择了现有的已标注的人民日报1998语料库。
所有文章都已分词完毕,如:1998,瞩目中华。
新的机遇和挑战,催人进取;新的目标和征途,催人奋发。
英雄的中国人民在以江泽民同志为核心的党中央坚强领导和党的十五大精神指引下,更高地举起邓小平理论的伟大旗帜,团结一致,扎实工作,奋勇前进,一定能够创造出更加辉煌的业绩!2.测试数据测试数据使用搜狗实验室的新闻数据集,由于该数据集也是没有标注的数据集,所以手动标注了少量用于测试。
四、实验环境1.Python3.7和JDK1.8五、实验步骤1.数据收集及数据预处理训练数据使用人民日报1998语料库,所以不需要进行太多预处理,主要是测试数据集,我们使用搜狗实验室的新闻数据集,以下是收集和处理过程。