中医药统计学spss操作步骤及答题格式
- 格式:pdf
- 大小:424.28 KB
- 文档页数:53



使用SPSSSPSS中文版统计软件的统计分析操作方法SPSS(Statistical Package for the Social Sciences)是一种用于统计分析的软件工具,它可以帮助研究人员对数据进行处理、分析和解释。
下面将介绍SPSS中文版统计软件的常见统计分析操作方法。
一、数据导入和预处理1. 启动SPSS软件后,在主界面选择"文件"->"打开"->"数据",然后选择要导入的数据文件,如Excel或CSV格式文件。
2.在数据导入对话框中,选择正确的数据类型和分隔符,并指定变量名和数据属性。
3.完成数据导入后,可以对数据进行预处理操作,如数据清洗、变量选择、数据转换等。
二、描述统计分析1.在数据导入后,在主界面选择"统计"->"描述性统计"->"频数",然后选择要进行频数分析的变量。
2.设置所需的统计量和显示选项,如均值、标准差、最小值、最大值等,并生成描述统计表。
三、数据可视化1.在主界面选择"图表"->"柱形图",然后选择要进行柱形图分析的变量。
2.设置柱形图的样式、颜色和标题等,并生成柱形图。
3.可以根据需要选择其他类型的统计图表,如折线图、散点图、饼图等,以进行数据可视化展示。
四、假设检验1.在主界面选择"分析"->"描述统计"->"交叉表",然后选择要进行交叉表分析的变量。
2.设置所需的交叉表分析选项,如分组变量、交叉分类表等,并生成交叉表。
3.可以根据需要进行卡方检验、t检验、方差分析等假设检验方法来比较两个或多个变量之间的差异。
五、回归分析1.在主界面选择"回归"->"线性",然后选择要进行回归分析的因变量和自变量。

上机实习必做的练习题(留作业)第一单元医学资料的统计描述定量资料:习题1①②③,2,3分类资料:习题4,5,6第二单元定量资料的统计推断t检验:习题1,3,4方差分析:习题8,10第三单元分类资料的统计推断卡方检验:习题4,5,8秩和检验:习题10,12,14第四单元回归与相关习题1.①②③④⑤2.①②3.第五单元生存分析习题2,3附件:作业、上机考试答题格式及评分标准一、描述性题目(一)集中趋势和离散趋势指标的计算某卫生防疫站对30名麻疹易感儿童经气溶胶免疫一个月后,测得其血凝抑制抗体滴度资料如下:请计算平均滴度。
抗体滴度1:81:161:321:641:1281:2561:512合计例数26510421301.题意分析:这是抗体滴度资料,应该计算几何均数。
(方法正确得10分)2.计算结果(18分):经SPSS计算,得:G=48.53.答(5分):该30名麻疹易感儿童经气溶胶免疫一个月后血凝抑制抗体平均滴度为1:48.5(二)医学参考值的计算测得某地300名正常人尿汞值,其频数表如下。
欲根据此资料制定95%正常值范围。
300例正常人尿汞值(ug/L)频数表尿汞值例数尿汞值例数尿汞值例数0-4924-1648-34-4728-952-08-5832-956-212-4036-460-016-3540-564-020-2244-068-7211.题意分析:本资料为偏态分布资料,应该用百分位数法制定。
由于尿汞为有毒有害物质,应制定单侧上限即可,即计算P95。
(方法正确得10分)2.计算结果(18分):经SPSS计算得:P95=36.8(ug/L)3.答(5分):该地正常人尿汞值95%正常值范围为<36.8(ug/L)(三)可信区间的计算(P426,习题1)请估计当地女大学生收缩压均数。
1.题意分析:根据题意应该计算95%的可信区间。
(方法正确得10分)2.计算结果(18分):经SPSS计算,得:95%的可信区间:92-1133.答(5分):该地女大学生收缩压均数95%的可信区间:92-113(mmHg)二、t检验(一)单样本t检验(P51:例4-5)1.题意分析:按题意应该是样本均数与总体均数的比较,用单样本t检验(one sample t test)。

SPSS操作步骤及解析SPSS(Statistical Package for the Social Sciences)是一种用于数据分析的统计软件包。
它可以进行数据整理、描述统计分析、统计推断、回归分析、因子分析、聚类分析等各种统计分析。
下面是SPSS的操作步骤及解析。
1.数据导入:在SPSS中,数据可以以多种格式导入,如Excel文件、CSV文件、数据库导入等等。
点击“文件”按钮,然后选择“导入数据”选项。
在出现的对话框中选择要导入的文件,然后按照指示逐步完成导入过程。
3.描述统计分析:描述统计分析是指对数据进行基本的统计描述,包括计数、平均数、标准差、最小值、最大值等等。
点击“统计”按钮,在出现的下拉菜单中选择“描述统计”选项。
在打开的对话框中,选择要统计的变量,然后点击“确定”按钮即可生成统计描述。
4.数据转换:数据转换是指通过运算或者函数对数据进行转换,以得到更有意义的变量或者指标。
点击“转换”按钮,在出现的下拉菜单中选择“计算变量”选项。
在打开的对话框中,输入要进行的运算或者函数,然后点击“确定”按钮即可生成新的变量。
5.统计推断:统计推断是指通过样本数据对总体数据进行推断性统计分析。
点击“分析”按钮,在出现的下拉菜单中选择“统计推断”选项。
根据具体需求选择适当的统计方法,如t检验、方差分析、相关分析等等。
在打开的对话框中选择变量,并进行相应的设置,然后点击“确定”按钮即可生成推断性分析结果。
6.回归分析:回归分析是指通过对自变量和因变量之间的关系进行建模,预测因变量的取值。
点击“分析”按钮,在出现的下拉菜单中选择“回归”选项。
在打开的对话框中选择要进行回归分析的变量,然后进行相应的设置,如回归方法、模型选择等等,最后点击“确定”按钮即可生成回归分析结果。
7.图表制作:总结:。

spss使用教程SPSS(Statistical Package for the Social Sciences)是一款功能强大的统计分析软件,广泛应用于社会科学领域的数据处理和统计分析。
本篇文章将为您提供一份SPSS的使用教程,帮助您快速上手和掌握该软件的基本操作和常用功能。
一、数据准备在使用SPSS进行统计分析前,首先需要准备好待处理的数据。
SPSS支持的数据格式有多种,包括Excel、CSV、文本等。
确保您的数据文件中每列都有一个明确的变量名,并且每行代表一个完整的数据观测。
二、导入数据1. 打开SPSS软件,选择“文件”->“打开”->“数据”,然后浏览文件目录,选择您想要导入的数据文件,点击“打开”按钮。
2. 在打开数据对话框中,选择正确的数据格式,并指定数据所在的位置,点击“确定”按钮。
3. SPSS将会自动加载您的数据文件,并在主界面显示数据的内容。
三、数据清洗与整理在完成数据导入后,可能需要对数据进行清洗和整理,以保证数据的准确性和一致性。
1. 删除无效数据:使用“筛选”功能,过滤掉数据中的无效观测值或缺失数据。
2. 数据转换:例如将文本数据转换为数值型数据,或者对数值数据进行分组处理。
3. 数据整理:根据需要,可以将数据按照不同的变量进行排序、合并或拆分。
四、数据描述统计1. 统计量计算:选择“分析”->“描述统计”->“统计”,在统计对话框中选择您想要计算的统计量,如均值、标准差等。
2. 频数分布:选择“分析”->“描述统计”->“频数”,在频数对话框中选择需要进行频数统计的变量。
3. 图形展示:选择“图形”->“柱状图”或其他适合的图形类型,可视化显示数据的分布情况。
五、数据分析SPSS提供了多种数据分析功能,包括描述性统计、回归分析、方差分析、聚类分析等。
以下是一些常用的数据分析方法:1. 描述性统计:了解数据的基本分布情况,包括均值、标准差、最大值、最小值等。
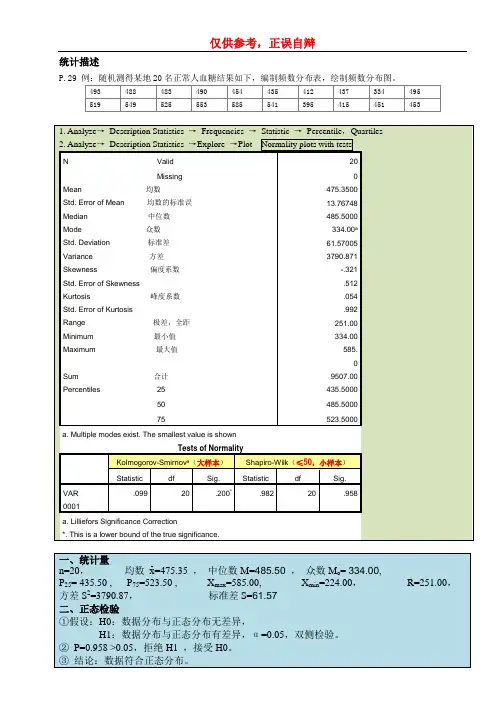
统计描述P.291. Analyze→Description Statistics →Frequencies →Statistic →Percentile,Quartiles2. Analyze→Description Statistics →Explore →Plot Normality plots with testsN Valid 20Missing 0Mean 均数475.3500Std. Error of Mean 均数的标准误13.76748 Median 中位数485.5000Mode 众数334.00aStd. Deviation 标准差61.57005 Variance 方差3790.871 Skewness 偏度系数-.321Std. Error of Skewness .512 Kurtosis 峰度系数.054Std. Error of Kurtosis .992 Range 极差,全距251.00 Minimum 最小值334.00 Maximum 最大值585.Sum 合计9507.00 Percentiles 25 435.500050 485.500075 523.5000a. Multiple modes exist. The smallest value is shownTests of NormalityKolmogorov-Smirnov a(大样本)Shapiro-Wilk(≤50,小样本)Statistic df Sig. Statistic df Sig..099 20 .200*.982 20 .958VAR0001a. Lilliefors Significance Correction*. This is a lower bound of the true significance.┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉一、计量资料单样本t检验P.56 例4-7:已知人参中M物质的含量服从正态分布,u=63.5,今9次测得一批人工培植人参中M物质的含量为40.0、41.0、41.5、41.8、42.4、43.1、43.5、43.8、44.2,推断这批人工培植人参中M物质的含┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉┉配对t检验P.57例4-8:为研究三棱莪术液的抑瘤效果,将20只小白鼠配成10对,每对中的两只随机分到试验组和对照组,两组都接种肿瘤,试验组在接种肿瘤三天后注射30%的三棱莪术液0.5,正态分布资料两样本均数比较的t检验P.60例4-9:某医师研究转铁蛋白测定对病毒性肝炎诊断的临床意义,测得12名正常人和15名病毒性肝炎患者血清转铁蛋白含量的结果如下:正常人:265.4、271.5、284.6、291.3、254.8、275.9、281.7、268.6、264.1、273.2、270.8、260.5患者:256.9、235.9、215.4、251.8、224.7、228.3、231.1、253.0、221.7、218.8、233.8、230.9、240.7、260.7、224.4本例为完全随机设计资料,推断转铁蛋白测定对病毒性肝炎诊断的意义。


例题0801随机设计的方差分析(1)正态性检验(2)方差分析第一步1第三步例题8-2 随机区组设计资料的方差分析例题8-3拉丁方设计资料的方差分析18-01 析因分析点击“添加”点击选项第九章行列表资料的假设检验(卡方检验)一、四格表的卡方检验例题9-1两个样本率的比较(不需要校正)第一种做法:数据可以还原成最初数据,然后输入。
1 输入数据2 操作步骤点击确定就ok啦。
第二种做法:1数据输入:变量视图数据视图2 操作点击数据---选中下拉框中的加权个案点击加权个案---选中Frequence加权个案----点击确定以下操作同第一种做法。
例题9-2两个样本率的比较(需要连续性校正)操作方法同例题9-1注意:结果输出, 出现理论频数小于5的格子,故读取的结果是continuity correction连续校正一行例题9-3 交叉分类2×2表关联性分析。
1 数据输入同9-1,2,对Frequence进行加权处理即:点击加权个案---选中Frequence加权个案----点击确定2 可以进行分析了点击确定即可。
数据输入和分析结果见“给同学们文件夹”配对四格表的卡方检验例题9-4配对四格表资料的观察结果有无差异的检验1 变量视图和数据视图如下:2 对Frequence进行加权处理3点击分析——统计描述——交叉表例题9-5配对四格表资料的关联性分析变量视图和数据视图如下:对Frequence进行加权处理以下操作同9-1,2,3,点击分析——统计描述——交叉表-点击确定即可。
二、行列表资料的卡方检验(四格表的扩展,操作相似)例题9-6 多个样本率的比较(p153页)方法参照9-1,1数据输入及处理:变量视图和数据视图2 对Frequence进行加权处理即:点击数据——加权个案---选中Frequence加权个案----点击确定3以下操作同9-1,2,3,点击分析——统计描述——交叉表点击确定即可。
例题9-7 两组或多组构成比的比较(p153页)数据输入和操作同上1变量视图和数据视图如下:2 对Frequence进行加权处理即:点击数据——加权个案---选中Frequence加权个案----点击确定3以下操作同9-1,2,3,点击分析——统计描述——交叉表例题9-8 行列表分类资料关联性分析(四格表资料关联性分析的扩展)操作相似。
SPSS详细步骤一、多选题1.录入数据(1)桌面新建记事本,名字随意。
(2)ABCDE各选项有则输入1,无则输入0(3)每一行录入一个人第一题和第二题的数据,如例题,第一行为1110001101(ABC,BCE) (4)保存。
2.SPSS软件中打开(1)文件--打开--数据(2)找到桌面(Destop)(3)文件类型--文本格式(4)打开所保存文件(5)下一步,第二步--固定宽度,下一步,鼠标点击每列一条变量终止线,下一步,下一步,完成。
(6)变量视图,修改变量名。
(可以省略,自己知道前五个为一组,后五个为一组即可)3.求个案数,响应比率,个案比率。
(1)分析--多重响应--定义变量集(2)选定前五个变量,点击箭头转入集合中的变量(3)二分法--计数值:1(即1表示有,0表示无)(4)名称:第一题。
--点击添加至多重响应集(5)选定后五个变量,点击箭头转入集合中的变量(6)二分法--计数值:1(7)名称:第二题。
--点击添加至多重响应集--关闭(8)分析--多重响应--频率(9)选定第一题第二题点击箭头转入表格--确定(10)N值为个案数,N值右侧百分比为响应比率,个案百分比为个案比例--填入自制手绘表格。
4.求期望数,卡方,P(P,渐进显著性,Sig,一个意思)(1)做第一题的卡方(2)在第一题频率表中找到N值(个案数)(3)复制或者记录N 值(4)文件--新建--数据(5)第一列变量粘贴或者竖着输入N值(变量名默认为V AR00001,可以自己修改) (6)第二列变量依次输入1,2,3,4,5(代表ABCDE第一列个案数相对应,变量名默认V AR00002)(7)数据--加权个案--频率变量V AR00001--确定(8)分析--非参数检验--旧对话框--卡方(9)选定V AR00002--点击箭头转入检验变量列表(10)期望值--值--从左至右输入题目所给选项比(例如1:2:2:3:2,则1添加,2添加,2添加,3添加,2添加)--确定(11)将V AR00002中期望数填入自制手写表格。
Spss操作要点详细版第一章导论——SPSS介绍学习目标:初步认识SPSS软件的内容一、SPSS界面说明SPSS for Windows是SPSS/PC的Windows版本,具有Windows软件的共同特点,其界面十分友好,打开SPSS程序就会出现图1-2界面。
标题栏菜单栏工具栏数据栏标签图1-2 SPSS 11.5 for Windows 界面该界面为SPSS 的数据编辑窗口,其组成部分及主要功能如下:1。
标题栏:功能与其它Windows软件一致。
2.菜单栏:由10个菜单项组成,每个菜单包括一系列功能。
各菜单的主要功能如下。
2.1 File:文件操作菜单。
单击Fil e,有图1-3下拉菜单,主要功能包括:·New:新建数据编辑窗口、语句窗口、结果输出窗口等;·Open和Open Database:打开数据编辑窗口、语句窗口、结果输出窗口等;·Read Text Data:读入文本文件;·Save和Save As:保存文件;·Display Data Info:显示数据的基本信息;·Prin t和Print Preview:将数据管理窗口中的数据以表格的形式打印出来。
图1-3 File菜单项的下拉菜单图1-4 Edit菜单项的下拉菜单2.2 Edit:文件编辑菜单。
主要用于数据编辑,如图1-4,主要功能包括:·UndoRedo或modify cell values:撤消或恢复刚修改过的观测值;·cut,copy,paste:剪切、拷贝、粘贴指定的数据;·paste variables:粘贴指定的变量;·clear:清除所选的观测值或变量;·find:查找数据。
2.3 View:视图编辑菜单。
用于视图编辑,进行窗口外观控制。
包含显示/隐藏切换、表格特有的隐藏编辑/显示功能及字体设置等功能。
七年制中医SPSS软件分析:综合分析为研究某中学初一、初二、初三年级周日锻炼时间情况,从这三个年级中各随机抽取20名学生,调查得出学生周日锻炼时间的数据见表1。
问这三个年级学生周日锻炼时间是否不同。
表1:初中不同年级学生的锻炼时间(min)初一初二初三37.856 70.793 86.928 58.785 73.923 61.435 64.130 67.169 49.099 62.728 52.534 45.230 40.400 44.399 33.091 63.469 41.704 62.268 58.209 63.319 59.16436.65038.51148.94529.36741.98869.41933.10938.87253.40162.81438.45432.80237.68348.94448.86941.92046.85965.06738.40348.77851.05747.60948.42842.81452.30354.32735.59155.01336.08421.30746.41941.83637.48135.78131.35445.19040.92438.87727.259经数据分析结果如下:表2:三个年级之间的t检验结果组别t P初一和初二初一和初三初二和初三2.854.091.120.00710.00020.2710问:⑴该资料采用的是何种统计分析方法?⑵所使用的统计方法是否正确?为什么?⑶若不正确,应采用何种统计分析方法?⑷写出分析思路,利用SPSS软件给出你的解答。
200870101012 张春艳2008级七年制中医答:(1)该资料采用的是成组t检验,即两个独立样本的t检验方法。
(2)该方法不正确,因为此资料为多个独立样本的均数比较,应当用单因素方差分析,成组t检验只能用于两个独立样本的均数比较,用于多个组检验会加大犯“存伪”错误的概率。
(3)应采用单因素方差分析法。
一、计量资料的统计描述统计类型正态或非正态分布1-Sample K-S统计特征集中趋势:均数中位数离散程度:极差方差标准差标准误四分位间距Frequencies:频数表,计量、计数(P2.5,P97.5)Descriptive:正态分布资料(均数,标准差)Explore:功能最强大,四分位间距,可信区间频数表的分析1. 频数表的输入:组中值,频数2. 加权:Data→weight(频数)3. 正态性分布检验1-Sample K-S(组中值)4. 统计描述:Frequencies Descriptive Explore(95%CI)(组中值)结果的书写:1.正态性检验的结果Z P 结论2.统计描述正态分布x s非正态资料M(Q)二、计量资料的假设检验(一)配对设计1. 正态性分布检验analyze→nonparametric tests→1-sample k-S (d)非正态转32. 配对t假设检验analyze→compare means→paired-sample t test 结果书写3. 符号秩和检验analyze→Nonparametric tests→2Related samples 结果书写结果的书写:1. 正态性检验的结果Z P 结论2. 方法的选择3. 假设检验的结果t(Z)、P 结论(二)两样本成组设计1.正态性分布检验(Data→split)analyze→nonparametric tests→1-sample k-S (撤销split)非正态转步骤32. t检验analyze→compare means→Independent- sample t test 方差不齐转步骤3,方差齐结果阅读3. 秩和检验(如方差不齐、非正态或无确切值)假设检验analyze→Nonparametric tests→ 2 Independent samples tests结果的书写:1. 正态性检验的结果Z P 结论2. 方差齐性检验结果F P 结论3. 方法的选择4. 假设检验的结果t(Z)、P 结论1.高蛋白Z=0.320,P=1.000;低蛋白Z=0.264,P=1.000;可以认为两资料呈正态。