OpenMax_IL_Bellagio_代码分析_-_台湾清华RTlab实验室_OpenMax_IL_代码分析
- 格式:ppt
- 大小:1.24 MB
- 文档页数:25

Image Lab™中文操作手册F a s t a n d R e l i a b l eImage Lab 全自动图像获取和分析软件用于Molecular Imager ChemiDoc™ XRS+、Molecular Imager Gel Doc™ XR+ 和 Criterion Stain Free TM 成像系统,可应用于凝胶电泳和转印膜的数字成像和分析,而自动化的工作流程能加速图像获取步骤及参数优化,并针对调整好的凝胶或转印膜影像进行系统性分析,进而得到所需的分析数据结果。
一、软件操作界面启动精灵程序桌面主窗口工具列分析工具列状态列1. 主窗口工具列a ta2. 显示工具列3. 分析工具列(1)图像工具(Image To ols)(2)泳道及条带工具(Lane and Ban d To ols)(3)分子量工具(MW Molecular W e igh t)(4)自动定量工具(Q u anti ty Too l s)(5)注释工具(A nnot a tion To ols)(6)手动定量工具(V o lum e To ols)二、使用Image Lab 软件进行化学发光图像获取流程1. 建立图像获取程序:放大图像显示设定缩小全窗口大小亮度明暗度转换改变图像色彩转换3D成模式像图像信息在凝胶成像(Gel Imaging)对话框中选择Chemi(化学发光)应用程序(1)在成像区域(Imaging Area)对话框中的下拉式选单中选择合适的样品大小(非必需,可之后通过Position Gel选择)(2)选择成像曝光(Image Exposure)方法,可以人为评估曝光时间并以手动设定(Manual Exposure),或是使用信号累积模式(Signal Accumulation Mode,SAM)来进行操作。
在建立一个化学发光的程序时最难的任务就是图像曝光的确定,因为您想获得一个充分利用了相机大的动态范围的图像。

操作系统lab2实验报告实验目的:本实验的目的是通过设计和实现一个简单的操作系统内核,加深对操作系统基本概念和原理的理解。
具体实验内容包括进程管理、内存管理和文件系统的设计与实现。
实验环境:1.操作系统:Linux2.编程语言:C语言一、实验背景1.1 操作系统简介操作系统是计算机系统中的一个重要组成部分,负责管理和控制计算机的各种资源,提供用户和应用程序的接口,以及协调和调度各种任务的执行。
1.2 实验目标本实验的主要目标是设计和实现一个简单的操作系统内核,包括进程管理、内存管理和文件系统等功能。
二、实验内容2.1 进程管理①进程创建描述进程创建的过程和相关数据结构,包括创建新进程的系统调用、进程控制块等。
②进程调度描述进程调度的算法和实现方式,包括进程调度队列、调度算法等。
③进程同步与通信描述进程同步和通信的机制和方法,包括信号量、互斥锁、条件变量等。
2.2 内存管理①内存分配描述内存分配的算法和实现方式,包括连续内存分配、非连续内存分配等。
②页面置换描述页面置换的算法和实现方式,包括最优页面置换算法、先进先出页面置换算法等。
2.3 文件系统①文件操作描述文件操作的系统调用和相关数据结构,包括文件打开、读写、关闭等。
②文件系统结构描述文件系统的组织结构和实现方式,包括超级块、索引节点、块位图等。
三、实验步骤3.1 环境搭建搭建实验环境,包括安装Linux操作系统、编译器等。
3.2 进程管理实现根据设计要求,实现进程创建、调度、同步与通信等功能。
3.3 内存管理实现根据设计要求,实现内存分配、页面置换等功能。
3.4 文件系统实现根据设计要求,实现文件操作和文件系统结构。
3.5 测试与调试编写测试用例,对实现的操作系统内核进行测试和调试,并记录实验结果。
四、实验结果分析分析测试结果,评估实验过程中遇到的问题和解决方法,总结操作系统内核的性能和功能特点。
五、实验总结对实验过程中的收获和经验进行总结,提出改进和优化的建议。


SELECT研究的探索与分析New l ooks at g lycemia, i nflammation, and h eart f ailure 2024 ADA 专题内容现场吸引上千名听众,热烈参与讨论•Semaglutide and p rediabetes p rogression/r egression in p eople with v ascular d isease - w hat h ave w e l earned from SELECT? •Role of g lycemia on c ardiovascular o utcomes - n ew d ata from SELECT•Heart failure and i nflammatory m arker c hanges in SELECTSELECT —New looks at glycemia, inflammation, and heart failure 2024年6月22日,星期六,08:00-09:30继SELECT 主要结果公布,2024ADA 再次发布最新数据并同步发表全文研究概览Donna H. Ryan彭宁顿生物医学研究中心司美格鲁肽2.4mg 对超重/肥胖患者CVOT研究结果回顾及长期体重管理结果SELECT 研究的深度分析Steven E. Kahn 华盛顿大学司美格鲁肽2.4mg 对超重/肥胖患者糖尿病前期的影响新启示Ildiko Lingvay 德克萨斯大学西南医疗中心司美格鲁肽2.4mg 的心血管获益与血糖的关系新数据Jorge Plutzky 哈佛医学院司美格鲁肽2.4mg 对合并心衰的超重/肥胖患者的心血管结局新获益研究概览Donna H. Ryan彭宁顿生物医学研究中心司美格鲁肽2.4mg 对超重/肥胖患者CVOT研究结果回顾及长期体重管理结果SELECT 研究的深度分析Steven E. Kahn 华盛顿大学司美格鲁肽2.4mg 对超重/肥胖患者糖尿病前期的影响新启示Ildiko Lingvay 德克萨斯大学西南医疗中心司美格鲁肽2.4mg 的心血管获益与血糖的关系新数据Jorge Plutzky 哈佛医学院司美格鲁肽2.4mg 对合并心衰的超重/肥胖患者的心血管结局新获益研究人群SELECT 研究的背景超重/肥胖合并CVD ,但不合并T2DM 的患者,是CVD 二级预防的潜在获益人群研究假设主要结果研究意义SELECT 是一项CVOT 研究,并不是关于减重的研究尚缺乏减重药物能改善心血管结局的证据心血管事件减少司美格鲁肽多重代谢和心血管获益被证实可通过多重作用机制使T2DM 患者心血管获益2司美格鲁肽2.4mg 的减重获益SELECT 研究设计旨在研究司美格鲁肽2.4mg 对MACE 风险的降低研究设计1-3司美格鲁肽 2.4 mg OW 安慰剂事件驱动 (≥1,225事件数)平均随访:39.8个月随机化 (1:1)N=17,604†•年龄≥45岁•超重/肥胖(BMI≥27kg/m 2)•确诊CVD *•既往无糖尿病病史(HbA 1c <6.5%)主要目标1,2在标准治疗下,与安慰剂相比,每周一次皮下注射司美格鲁肽2.4 mg 可降低已确诊CVD 的超重/肥胖人群的MACE 风险关键试验数字2完成实验*†N=8,544 (97.1%)完成实验*†N=8,517 (96.8%)41 个国家和地区804个中心17,604†例患者患者基线特征患者特征司美格鲁肽2.4mg(N=8803)安慰剂(N=8801)年龄(岁)61.6±8.961.6±8.8女性(%)27.827.5BMI(kg/m2)33.3±5.033.4±5.0 BMI≥30kg/m2(%)71.071.9HbA1c(%) 5.78±0.34 5.78±0.33 HbA1c5.7—6.4%(%)66.866.1MI病史(%)76.476.2心衰病史(%)24.524.2收缩压(mmHg)131.0±15.6130.9±15.3接受他汀治疗(%)87.787.6LDL-c(mg/dL)78 (61--102)78 (61--102)均值(IQR)甘油三酯(mg/dL)134(99--188)135(100--190)均值(IQR)受试者比例(%)20%降低MACE*发生风险司美格鲁肽2.4mg 显著降低MACE 风险20%02468100612182430364248在司美格鲁肽2.4mg 组中,首次确认的MACE 曲线分离出现在最大体重减轻之前1提示MACE 降低独立于体重降低司美格鲁肽2.4 mg安慰剂与安慰剂相比,在长达5年的时间内司美格鲁肽2.4 mg 显著降低MACE*发生风险1所有三个组分 (CV 死亡、非致死性心梗和非致死性卒中)对于降低MACE 风险均有贡献1MACE获益在不同性别/年龄/BMI/HbA1c亚组中保持一致HR (95% CI)主要分析司美格鲁肽 2.4mg/安慰剂0.80 (0.72; 0.90)性别女性0.84 (0.66; 1.07)男性0.79 (0.70; 0.90)年龄 (岁)<550.81 (0.64; 1.04)≥55 to <650.78 (0.64; 0.95)≥65 to <750.77 (0.64; 0.93)≥750.92 (0.67; 1.25)BMI (kg/m2)<300.74 (0.60; 0.91)≥30 to <350.76 (0.64; 0.91)≥35 to <400.93 (0.74; 1.18)≥40 to <450.83 (0.55; 1.26)≥45 0.92 (0.51; 1.65)HbA1c水平 (%)<5.70.82 (0.68; 1.00)≥5.7 0.79 (0.69; 0.90)0.250.512司美格鲁肽2.4mg更优安慰剂更优司美格鲁肽2.4 mg 在所有评估的CV 结局中显示出获益一致风险比显示,司美格鲁肽2.4 mg 在次要心血管结局方面具有一致的获益1MACE*0.80 [0.72; 0.90]CV 死亡§0.85 [0.71; 1.01]复合心衰结局†¥0.82 [0.71; 0.96]全因死亡¥0.81 [0.71; 0.93]扩展 MACE ‡§0.80 [0.73; 0.87]全因死亡、心梗或卒中0.80 [0.72; 0.88]非致死性心梗0.72 [0.61; 0.85]非致死性/致死性心梗0.72 [0.61; 0.85]非致死性卒中0.93 [0.74; 1.15]非致死性/致死性卒中0.89 [0.72; 1.11]冠脉血流重建0.77 [0.68; 0.87]不稳定心绞痛住院0.87 [0.67; 1.13]心衰住院/急诊就诊0.79 [0.60; 1.03]肾病0.78 [0.63; 0.96]0.4 1.0 2.7安慰剂更优司美格鲁肽2.4 mg 更优15%对比安慰剂组,司美格鲁肽2.4mg 组的心血管死亡风险下降(p 值=0.066)司美格鲁肽2.4mg 改善多种驱动CV 结局的代谢危险因素司美格鲁肽2.4mg 组对比安慰剂组,自基线至104周的改变1(基线: 4.0 mmol/L)(基线: 1.5 mmol/L)(基线: 5.8%)(基线: 131 mmHg)(基线: 1.9 mg/L)(基线: 96.6 kg)(基线: 111.3 cm)-4.6%-18.3%-0.3%-3.8mmHg-9.4%-7.6 cm-39%-0.0%-0.9%-1.0cm-1.9%-3.2%-0.5-2%与基线的比值mmH g体重(%)腰围(cm )血压(mmHg )HbA1c (%)hsCRP (%)甘油三酯(%)总胆固醇(%)在试验中: 指的是参与者在临床试验的整个过程中的状态。

openmmlab 源码解读在本文中,我们将深入探讨OpenMMLab源码的各个部分,以帮助读者更好地理解这个强大的机器学习框架。
OpenMMLab是由一流的研究人员和工程师开发的,它为深度学习提供了丰富的工具和库。
通过理解其源码,我们可以深入了解其背后的工作原理,以及如何优化和使用这个框架。
首先,OpenMMLab的架构设计是其核心优势之一。
它采用了模块化的设计理念,使得每个组件都可以独立地进行开发和优化。
这种设计方式不仅提高了代码的可读性和可维护性,还使得新功能的添加和现有功能的修改变得更加简单。
此外,OpenMMLab还支持多线程和GPU加速,大大提高了训练和推断的速度。
在OpenMMLab中,一个重要的组件是MMDataLayer,它负责数据的读取、预处理和增强。
通过使用MMDataLayer,用户可以方便地加载各种数据集,并对其进行必要的预处理,例如归一化、裁剪和翻转等。
这个组件的设计充分考虑了灵活性和可扩展性,使得用户可以根据自己的需求轻松定制数据增强规则。
另一个值得关注的组件是MMSegmentation,它是一个强大的语义分割工具。
MMSegmentation基于PyTorch实现,它支持多种分割算法,例如FCN、Mask R-CNN等。
通过使用MMSegmentation,用户可以方便地训练和评估分割模型,并进行可视化分析。
这个组件的源码简洁明了,易于理解和修改,为研究者提供了很大的便利。
除了上述组件外,OpenMMLab还提供了许多其他有用的工具和库,例如MMClassification、MMDetection和MMGeneration等。
这些工具和库都经过精心设计和优化,使得用户可以更加高效地进行机器学习研究和开发。
在总结部分,我们可以看到OpenMMLab是一个功能强大、易于使用和灵活的机器学习框架。
通过深入解读其源码,我们可以更好地理解其背后的工作原理和设计思想。
这不仅有助于我们更好地使用这个框架,还可以启发我们在自己的研究中应用类似的架构和技术。


OpenMMLab是一套用于目标检测的开源工具包,它提供了许多预训练模型和工具,可以帮助开发者快速构建目标检测系统。
下面是一个利用OpenMMLab搭建目标检测系统的简单例子。
步骤一:安装OpenMMLab首先,需要安装OpenMMLab工具包。
可以从官方网站下载并安装相应的版本。
步骤二:准备数据集为了训练和测试目标检测系统,需要准备相应的数据集。
通常需要包含标注的图像和对应的标签信息。
可以使用OpenMMLab提供的工具进行数据集的标注和格式转换。
步骤三:选择模型OpenMMLab提供了多种预训练模型,可以根据实际需求选择合适的模型。
例如,可以选择YOLO、SSD、Faster R-CNN等模型。
步骤四:配置模型参数根据选择的模型,配置相应的参数,例如学习率、批量大小、优化器等。
可以通过修改配置文件或使用命令行参数进行设置。
步骤五:训练模型使用准备好的数据集和配置文件,训练目标检测模型。
可以通过OpenMMLab提供的训练工具或自己编写代码实现训练过程。
步骤六:评估模型性能使用测试数据集对训练好的模型进行评估,可以通过计算精度、召回率、F1分数等指标来评估模型的性能。
下面是一个简单的代码示例,演示如何使用OpenMMLab进行目标检测:```pythonimport cv2import openmmlabfrom openmmlab.models.detection import DetNet, YOLOv3, SSD, FasterRCNN# 加载预训练模型model = DetNet(num_classes=2) # 假设使用的是DetNet模型,类别数为2(背景和目标)model.load_pretrained_weights('path/to/pretrained/model') # 替换为预训练模型的路径model.eval() # 设置模型为评估模式# 加载测试数据集test_dataset = 'path/to/test/dataset' # 替换为测试数据集的路径img_names = sorted(test_dataset) # 获取测试图像的名称列表img_paths = [test_dataset / img_name for img_name in img_names] # 构建测试图像的路径列表imgs = [cv2.imread(img_path) for img_path in img_paths] # 加载测试图像的灰度图像部分img = cv2.cvtColor(cv2.merge(imgs), cv2.COLOR_BGR2RGB) # 将多通道图像合并为一个图像对象boxes = [] # 初始化目标边界框列表scores = [] # 初始化目标置信度列表for i, im in enumerate(img): # 对每个图像进行目标检测pred = model(im) # 对图像进行预测,得到边界框和置信度列表boxes += pred[0] # 将预测的边界框添加到列表中scores += pred[1] # 将置信度列表添加到列表中results = {'boxes': boxes,'scores': scores,} # 将检测结果存储到一个字典中,其中boxes包含边界框坐标,scores包含目标置信度列表print(results) # 输出检测结果```以上是一个简单的示例,实际应用中可能还需要进行更多的数据处理和模型优化。

练习1、理解通过make生成执行文件的过程。
[练习1.1] 操作系统镜像文件ucore.img 是如何一步一步生成的?在proj1执行命令make V=可以得到make指令执行的过程从这几条指令中可以看出需要生成ucore.img首先需要生成bootblock,而生成bootblock需要先生成bootmain.o和bootasm.o还有sign,这三个文件又分别由bootmain.c、bootasm.S、sigh.c来生成。
ld -m elf_i386 -N -e start -Ttext 0x7C00 obj/boot/bootasm.o obj/boot/bootmain.o –o obj/bootblock.o这句话用于生成bootblock,elf_i386表示生成elf头,0x7C00为程序的入口。
'obj/bootblock.out' size: 440 bytes这句话表示生成的bootblock的文件大小,因为大小不到512字节,所以需要给blootblock填充,填充的功能在sign.c中有所体现,最后两字节设置为了0x55,0xAAbuf[510] = 0x55;buf[511] = 0xAA;FILE *ofp = fopen(argv[2], "wb+");size = fwrite(buf, 1, 512, ofp);[练习1.2] 一个被系统认为是符合规范的硬盘主引导扇区的特征是什么?前面已经提到过:引导扇区的大小为512字节,最后两个字节为标志性结束字节0x55,0xAA,做完这样的检查才能认为是符合规范的磁盘主引导扇区。
Sign.c文件中有作检查:if (size != 512) {fprintf(stderr, "write '%s' error, size is %d.\n", argv[2], size);return -1;}练习2:使用qemu执行并调试lab1中的软件。

华东师范大学软件学院实验报告实验课程:操作系统实践年级:大二实验成绩:实验名称:Pintos-User Programs 姓名:实验编号:学号:实验日期:2018/12/27指导教师:组号:实验时间:4学时一、实验目的当前, 我们已经完成了pintos 的第一部分(熟悉了其基础结构和线程包), 现在是开始处理系统中允许运行用户程序的部分的时候了。
基本代码已经支持加载和运行用户程序, 但不能加载和运行或交互性。
在此项目中, 我们将使程序能够通过系统调用与操作系统进行交互。
我们将在"userprog" 目录中进行工作, 但我们也将与pintos 的几乎所有其他部分进行交互。
具体目的如下:(1)了解Pintos操作系统的功能流程及内核的软件工程结构。
(2)通过Pintos操作系统内核的剖析,了解现有Pintos操作系统在处理用户程序方面中存在的参数传递问题,有效解决其参数传递的问题。
(3)通过Pintos内核剖析,了解其中断处理的机制,学会操作系统中断功能的编写方法。
(4)了解现有Pintos操作系统的系统调用功能,根据其中断机制,完善系统调用功能,使Pintos系统具有处理用户中断请求的功能。
(5)通过Pintos内核剖析,解决现有Pintos操作系统中存在的进程终止时缺少终端提示的问题。
(6)通过Pintos内核剖析,解决现有Pintos操作系统中存在的运行文件禁止写操作的问题。
二、实验内容与实验步骤实验内容如下:(1)在分析内核的基础上,对Pintos操作系统的参数传递问题提出有效的策略,设计算法,分步跟踪和调试,通过实践,有效解决参数传递问题,并对实验结果进行分析。
(2)通过Pintos操作系统内核的剖析,了解其中断处理的机制,在此基础上,完善Pintos的系统调用功能,设计算法,分步跟踪和调试,通过测试分析完善的系统调用功能。
(3)在分析内核的基础上,对现有Pintos操作系统进行完善,增加进程终止的终端提示功能,设计算法,分步跟踪和调试,通过实践,验证终端提示功的有效性。
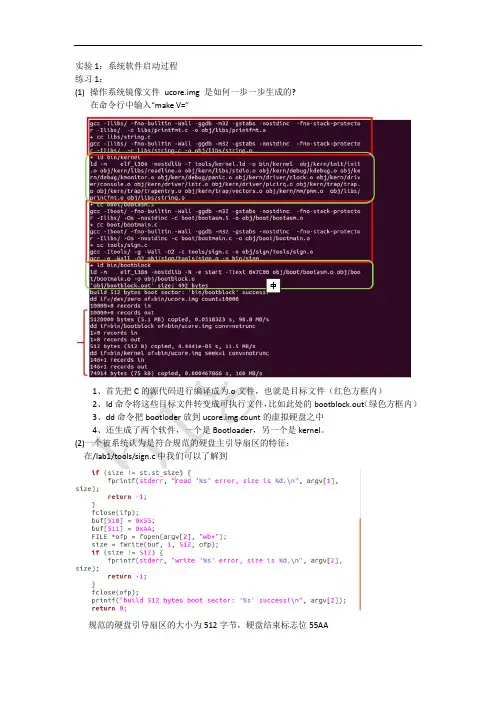
实验1:系统软件启动过程练习1:(1)操作系统镜像文件ucore.img 是如何一步一步生成的?在命令行中输入“make V=”1、首先把C的源代码进行编译成为.o文件,也就是目标文件(红色方框内)2、ld命令将这些目标文件转变成可执行文件,比如此处的bootblock.out(绿色方框内)3、dd命令把bootloder放到ucore.img count的虚拟硬盘之中4、还生成了两个软件,一个是Bootloader,另一个是kernel。
(2)一个被系统认为是符合规范的硬盘主引导扇区的特征:在/lab1/tools/sign.c中我们可以了解到规范的硬盘引导扇区的大小为512字节,硬盘结束标志位55AA练习2:(1)从CPU 加电后执行的第一条指令开始,单步跟踪BIOS 的执行改写Makefile文件lab1-mon: $(UCOREIMG)$(V)$(TERMINAL) -e "$(QEMU) -S -s -d in_asm -D $(BINDIR)/q.log -monitor stdio -hda $< -serial null"$(V)sleep 2$(V)$(TERMINAL) -e "gdb -q -x tools/lab1init"在调用qemu时增加-d in_asm -D q.log参数,便可以将运行的汇编指令保存在q.log 中。
(2)在初始化位置0x7c00 设置实地址断点,测试断点正常。
在tools/gdbinit结尾加上set architecture i8086b *0x7c00 //在0x7c00处设置断点。
continuex /2i $pc //显示当前eip处的汇编指令(3)将执行的汇编代码与bootasm.S 和bootblock.asm 进行比较,看看二者是否一致。
Notice:在q.log中进入BIOS之后的跳转地址与实际应跳转地址不相符,汇编代码也与bootasm.S 和bootblock.asm不相同。

实验名称:并行处理技术在图像识别中的应用实验目的:1. 了解并行处理技术的基本原理和应用场景。
2. 掌握并行计算环境搭建和编程技巧。
3. 分析并行处理技术在图像识别任务中的性能提升。
实验时间:2023年10月15日-2023年10月25日实验设备:1. 主机:****************************,16GB RAM2. 显卡:NVIDIA GeForce RTX 2080 Ti3. 操作系统:Windows 10 Professional4. 并行计算软件:OpenMP,MPI实验内容:本实验主要分为三个部分:1. 并行计算环境搭建2. 图像识别任务并行化3. 性能分析和比较一、并行计算环境搭建1. 安装OpenMP和MPI库:首先在主机上安装OpenMP和MPI库,以便在编程过程中调用并行计算功能。
2. 编写并行程序框架:使用C++编写一个并行程序框架,包括并行计算函数和主函数。
3. 编译程序:使用g++编译器编译程序,并添加OpenMP和MPI库的相关编译选项。
二、图像识别任务并行化1. 数据预处理:将原始图像数据转换为适合并行处理的格式,例如将图像分割成多个子图像。
2. 图像识别算法:选择一个图像识别算法,如SVM(支持向量机)或CNN(卷积神经网络),并将其并行化。
3. 并行计算实现:使用OpenMP或MPI库将图像识别算法的各个步骤并行化,例如将图像分割、特征提取、分类等步骤分配给不同的线程或进程。
三、性能分析和比较1. 实验数据:使用一组标准图像数据集进行实验,例如MNIST手写数字识别数据集。
2. 性能指标:比较串行和并行处理在图像识别任务中的运行时间、准确率等性能指标。
3. 结果分析:分析并行处理在图像识别任务中的性能提升,并探讨影响性能的因素。
实验结果:1. 并行处理在图像识别任务中显著提升了运行时间,尤其是在大规模数据集上。
2. 并行处理对准确率的影响较小,甚至略有提升。
Ubuntu linux 操作系统与实验教程(第2版)课后习题第一章习题一1、判断题(1)在一台主机上只能安装一个虚拟机。
(2)在一个虚拟机下只能安装一个操作系统。
(3)格式化虚拟机下的操作系统就是格式化主机的操作系统。
(4)虚拟机的安装有三种安装类型。
(5)VMware Workstation 15 默认分配的推荐虚拟机的存是1G。
(6)Ubuntu 有两种安装方式:即Ubuntu和安装Ubuntu。
(7)解压vmware-install.pl文件安装VM tools。
(8)VMtools安装完成后可以在主机和虚拟机之间任意拖动和复制文件。
2、简答题(1)请简述在虚拟机的安装过程中,四种网络类型的特点?(2)简述.vmdk 和.vmx 文件的不同点?(3)Ubuntu应该建立几个分区?每个分区的大小是多少?(4)虚拟机捕获屏幕有什么作用?3、实验题(1)安装VMware Workstation Pro 15。
(2)为安装ubuntukylin-16.04.06创建虚拟机。
(3)在虚拟机中安装ubuntukylin-16.04.06。
(4)在Ubuntu下安装VM tools。
(5)上述实验完成后创建快照,如果使用Ubuntu过程中出现问题,可以恢复快照。
(6)更改虚拟机的内存、添加硬盘。
第二章习题二1、判断题(1)Linux操作系统诞生于1991 年8月。
(2)Linux是一个开放源的操作系统。
(3)Linux是一个类unix操作系统。
(4)Linux是一个多用户系统,也是一个多任务操作系统。
(5)Ubuntu Linux 16.04默认的桌面环境是Gnome。
(6)Ubuntu每一年发布一个新版本。
(7)ubuntu Linux 16.04包含LibreOffice套件。
2、简答题(1)什么是Linux?(2)简述Linux系统的产生过程?(3)简述Linux系统的组成?(4)什么是Linux 内核版本?举例说明版本号的格式。
一、实验背景禁忌搜索算法(Tabu Search,TS)是一种基于局部搜索的优化算法,最早由Glover和Holland于1989年提出。
该算法通过引入禁忌机制,避免陷入局部最优解,从而提高全局搜索能力。
近年来,禁忌搜索算法在蛋白质结构预测、调度问题、神经网络训练等领域得到了广泛应用。
本次实验旨在验证禁忌搜索算法在求解组合优化问题中的性能,通过改进禁忌搜索算法,提高求解效率,并与其他优化算法进行对比。
二、实验目的1. 研究禁忌搜索算法的基本原理及其在组合优化问题中的应用;2. 改进禁忌搜索算法,提高求解效率;3. 将改进后的禁忌搜索算法与其他优化算法进行对比,验证其性能。
三、实验方法1. 算法实现本次实验采用Python编程语言实现禁忌搜索算法。
首先,初始化禁忌表,存储当前最优解;然后,生成新的候选解,判断是否满足禁忌条件;若满足,则更新禁忌表;否则,保留当前解;最后,重复上述步骤,直到满足终止条件。
2. 实验数据本次实验采用TSP(旅行商问题)和VRP(车辆路径问题)两个组合优化问题作为实验数据。
TSP问题要求在给定的城市集合中找到一条最短的路径,使得每个城市恰好访问一次,并返回起点。
VRP问题要求在满足一定条件下,设计合理的配送路径,以最小化配送成本。
3. 对比算法本次实验将改进后的禁忌搜索算法与遗传算法、蚁群算法进行对比。
四、实验结果与分析1. TSP问题实验结果(1)改进禁忌搜索算法(ITS)实验结果表明,改进后的禁忌搜索算法在TSP问题上取得了较好的效果。
在实验中,设置禁忌长度为20,迭代次数为1000。
改进禁忌搜索算法的求解结果如下:- 最短路径长度:335- 迭代次数:1000- 算法运行时间:0.0015秒(2)遗传算法(GA)实验结果表明,遗传算法在TSP问题上的求解效果一般。
在实验中,设置种群规模为100,交叉概率为0.8,变异概率为0.1。
遗传算法的求解结果如下:- 最短路径长度:345- 迭代次数:1000- 算法运行时间:0.003秒(3)蚁群算法(ACO)实验结果表明,蚁群算法在TSP问题上的求解效果较好。
清华大学操作系统lab3实验报告范文实验3:虚拟内存管理练习1:给未被映射的地址映射上物理页ptep=get_pet(mm->dir,addr,1);if(ptep==NULL){//页表项不存在cprintf("get_pteindo_pgfaultfailed\n"); gotofailed;}if(某ptep==0){//物理页不在内存之中//判断是否可以分配新页if(pgdir_alloc_page(mm->pgdir,addr,perm)==NULL){ cprintf("pgdir_alloc_pageindo_pgfaultfailed\n"); gotofailed;}}ele{if(wap_init_ok){tructPage某page=NULL;ret=wap_in(mm,addr,&page);if(ret!=0){//判断页面可否换入cprintf("wap_inindo_pgfaultfailed\n");gotofailed;}//建立映射page_inert(mm->pgdir,page,addr,perm);wap_map_wappable(mm,addr,page,1);}ele{cprintf("nowap_init_okbutptepi%某,failed\n",某ptep); gotofailed;}}ret=0;failed:returnret;}练习2:补充完成基于FIFO算法_fifo_map_wappable(tructmm_truct某mm,uintptr_taddr,tructPage某page,intwap_in){lit_entry_t某head=(lit_entry_t某)mm->m_priv;lit_entry_t某entry=&(page->pra_page_link);aert(entry!=NULL&&head!=NULL);lit_add(head,entry);return0;}pra_page_link用来构造按页的第一次访问时间进行排序的一个链表,这个链表的开始表示第一次访问时间最近的页,链表的尾部表示第一次访问时间最远的页。
LMS b中文操作指南比利时LMS国际公司北京代表处2009年7月内容¾ Desktop桌面操作¾ Signature信号特征测试分析¾ Spectral Testing谱分析¾ Geometry几何建模¾ ODS工作变形分析LMS b中文操作指南— Desktop桌面操作比利时LMS国际公司北京代表处2009年2月LMS b中文操作指南— Desktop桌面操作目录1.开始 (2)2.浏览数据 (3)3.显示数据 (4)3.1.测试的数据 (4)3.2.图形拷贝 (8)3.3.几何图形显示 (8)4.数据调理 (10)5.搜索功能 (11)6.Documentation 界面 (13)6.1.添加附件 (13)6.2.添加模板 (14)6.3.添加用户属性 (15)7.导入外部数据 (17)1. 开始¾ 启动 LMS b Desktop 从 开始菜单 Æ 所有程序 Æ LMS b 9AÆ Desktop 或者通过 桌面的快捷图标软件打开后,通过底部的导航条,可以看到两个界面:Documentation 和 Navigator 。
默认会打开一个空白的Project ,软件激活“Navigator”页面中的“Data Viewing”子页面。
可以浏览数据,图形显示数据。
页面在LMS b 资源管理器中可以看到Project ,另外还有:My Computer: 资源管理器最后一个项目。
可以浏览您电脑中的数据。
My Links: 此处可以链接常用Project 的快捷方式,首先从“My Computer”找到Project ,右键单击Copy ,然后到 “My Links”右键单击Paste as link 。
Search Results: LMS b 软件可以进行搜索,搜索的结果放在此处。
Input Basket: 暂时存放准备作处理的数据。
Bellagio OpenMAX IL框架的研究及应用王琳琳北京邮电大学计算机科学技术学院,北京(100876)E-mail:linlin4381@摘要:OpenMAX IL是由Khronos组织发起并起草的一个公开的技术标准,其目标是提供多媒体应用的移植性。
Bellagio OpenMAX IL (1.1 project 0.3 release) 框架是一个开源项目,对OpenMAX IL API(1.1 version)的实现。
本文详细分析了Bellagio OpenMAX IL框架的core 和component 的实现机制,并实现了AAC decoder component。
关键词:OpenMAX IL,Codec,AAC,多媒体中图分类号:TP 371.引言OpenMAX IL是由Khronos组织发起并起草的一个公开的技术标准,2005年12月发布第一个版本,目前的最新版本是version 1.1。
该标准针对嵌入式设备或/和移动设备的多媒体软件架构。
在架构底层上为多媒体的codec和数据处理定义了一套统一的编程接口(OpenMAX IL API),对多媒体数据的处理功能进行系统级抽象,为用户屏蔽了底层的细节。
因此,多媒体应用程序和多媒体框架通过OpenMAX IL可以以一种统一的方式来使用codec 和其他多媒体数据处理功能,具有了跨越软硬件平台的移植性。
Bellagio OpenMAX IL (1.1 project 0.3 release) 框架是一个开源项目,是对OpenMAX IL API(1.1 version)的实现。
本文第一节介绍Bellagio OpenMAX IL框架下core的实现机制;第二节介绍component的实现机制;第三节给出了如何在Bellagio OpenMAX IL框架下开发component;第四节是本文的结论。
2.Core 的实现机制Core 是用来动态地装载和卸载component,并且用来建立component之间的通信的[1]。
查看图像475查看图像一旦凝胶成像,图像便会显示在工作区中。
很多控件都可以优化查看效果并对图像进行分析。
结果概述这是具有条带和泳道检测及注释功能的凝胶图像。
标记会识别可显示或隐藏的图像覆盖。
请参阅显示凝胶选项(第 48页)获取完整信息。
Gel Doc TM EZ 系统 | 查看图像48有多种方式可以查看与结果关联的数据。
可以将数据作为分析表、泳道轮廓、标准曲线和报告进行查看。
请参阅显示数据(第 54 页)。
显示凝胶图像显示在第 47 页上的凝胶图像上方的工具栏图标。
以下部分将对每个工具进行描述。
显示凝胶选项注释可以选择是否显示图像上已绘制的文本和箭头注释。
泳道和条带可以打开或关闭任意图像覆盖,比如泳道框架、泳道、条带、泳道标记和分子量图例。
显示凝胶图像49条带属性可以显示所选泳道或所有泳道的以下属性。
•条带数•条带标记•分子量•相对前沿•体积•绝对定量•相对定量•条带 %•泳道 %体积如果已在凝胶上绘制好体积边界,则可以显示体积边界及其体积标记。
缩放工具缩放工具可以调整凝胶图像的大小。
单击放大镜的“+”符号可以放大图像;单击“-”符号可以缩小图像。
也可以通过鼠标右键对图像进行缩放。
右键单击并拖动以选择要放大的区域。
再次右键单击以返回到原始视图。
也可以通过鼠标上的滚轮(如果有的话)调整图像大小。
适合窗口如果当前已对图像某个区域进行放大,单击此按钮便可显示整个图像。
Gel Doc TM EZ 系统 | 查看图像50图像转换使用“图像转换”对话框可以调整图像亮度和对比度以优化图像显示效果,以便看清模糊图像。
最大和最小范围会随图像现有的明暗度值而改变。
注意:这些调整并不会更改数据,只会更改数据的显示方式。
肉眼无法看到图像包含的完整范围。
频率分布柱状图会显示图像中的总数据范围和范围内每个点上的数据量。
“自动缩放”按钮会自动确定特定图像的最佳设置。
图像最亮的部分会设置为最小强度,最暗的部分会设置为最大强度。