Proc. R. Soc. Lond.-1897-Hough-236-8
- 格式:pdf
- 大小:369.62 KB
- 文档页数:3

Linux中/proc目录下文件详解/proc文件系统下的多种文件提供的系统信息不是针对某个特定进程的,而是能够在整个系统范围的上下文中使用。
可以使用的文件随系统配置的变化而变化。
命令procinfo能够显示基于其中某些文件的多种系统信息。
以下详细描述/proc下的文件。
--------------------------------------------------------------------------------/proc/cmdline文件这个文件给出了内核启动的命令行。
它和用于进程的cmdline项非常相似。
--------------------------------------------------------------------------------/proc/cpuinfo文件这个文件提供了有关系统CPU的多种信息。
这些信息是从内核里对CPU的测试代码中得到的。
文件列出了CPU的普通型号(386,486,586,686 等),以及能得到的更多特定信息(制造商,型号和版本)。
文件还包含了以bogomips表示的处理器速度,而且如果检测到CPU的多种特性或者bug,文件还会包含相应的标志。
这个文件的格式为:文件由多行构成,每行包括一个域名称,一个冒号和一个值。
--------------------------------------------------------------------------------/proc/devices文件这个文件列出字符和块设备的主设备号,以及分配到这些设备号的设备名称。
--------------------------------------------------------------------------------/proc/dma文件这个文件列出由驱动程序保留的DMA通道和保留它们的驱动程序名称。
casade项供用于把次DMA控制器从主控制器分出的DMA行所使用;这一行不能用于其它用途。

通过读 proc 等方式获取 Linux 系统状态信息的一些方法(转)2007-11-23 16:50现在又要搞进程的 CPU,MEM 信息,继续查索 本文中所有样例,2.6.x kernel 的取自 rhel4, 2.4.x kernel 的取自 rh9. Copyright: icymoon@NKU 1.需要的系统状态信息 CPU Usage Memory/Swap Usage Disk Usage Disk I/O Ratio Process Information2.相关文件及计算方法(1)CPU Usage 相关文件:/proc/stat 的第一行 文件样例&基本计算方法: a. 2.4.x kernel:cpu 3156877 522645 1178059 169750391 cpu0 1111979 148713 315873 42075428 cpu1 444227 139960 119846 42947960 cpu2 1113218 155429 480187 41903159 cpu3 487453 78543 262153 42823844 page 1265588 10643253 swap 121 1258 intr 135336914 43651993 84 0 0 1 0 3 0 1 0 0 0 0 0 2 0 0 0 0 0 30 0 0 0 0 0 0 778176 42 60685630 30220952 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 disk_io: (8,0):(788586,178980,2529284,609606,21286496) (8,1):(3,3,24,0,0) ctxt 171689341 btime 1177119654 processes 3110142在 kernel 2.4.x 下,第一行只有五个字段,后四个字段依次是自从系统 启动以来,系统运行在 user mode, nice, system mode 下和 idle 状态的时 间,以 1/100 秒为单位。
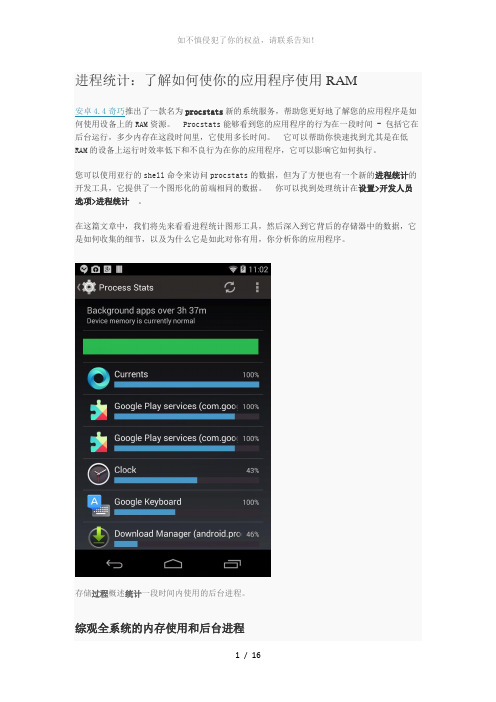
进程统计:了解如何使你的应用程序使用RAM安卓4.4奇巧推出了一款名为procstats新的系统服务,帮助您更好地了解您的应用程序是如何使用设备上的RAM资源。
Procstats能够看到您的应用程序的行为在一段时间 - 包括它在后台运行,多少内存在这段时间里,它使用多长时间。
它可以帮助你快速找到尤其是在低RAM的设备上运行时效率低下和不良行为在你的应用程序,它可以影响它如何执行。
您可以使用亚行的shell命令来访问procstats的数据,但为了方便也有一个新的进程统计的开发工具,它提供了一个图形化的前端相同的数据。
你可以找到处理统计在设置>开发人员选项>进程统计。
在这篇文章中,我们将先来看看进程统计图形工具,然后深入到它背后的存储器中的数据,它是如何收集的细节,以及为什么它是如此对你有用,你分析你的应用程序。
存储过程概述统计一段时间内使用的后台进程。
综观全系统的内存使用和后台进程当您打开进程统计,你看到的全系统内存不足的情况,并了解如何进程使用的内存随着时间的总结。
在右边的图像给你什么,你可能一个典型的设备上看到的一个例子。
在我们可以看到,在屏幕的顶部:•我们正在收集过去〜3.5小时数据。
•目前该设备的RAM情况良好(“设备的内存是目前正常”)。
•在此期间,整个时间内存状态一直不错 - 这是显示由绿条。
如果设备内存是越来越低,你会看到代表总时间与低内存量栏左侧的黄色和红色区域。
下面的绿条,我们可以看到在后台,他们已经把系统上的内存负载运行的进程的概述:•右边的百分比数字表示每个时间进程已经花费的总持续时间期间运行的量。
•蓝条表示每个过程的相对计算的内存负载。
(内存负荷runtime*avg_pss,我们将进入更详细的版本。
)•一些应用程序可能会多次列出,因为什么被显示的是进程(例如,谷歌Play业务运行在两个过程)。
这些应用程序的存储器负荷是其各个处理的负荷的总和。
•有在该已经全部运行的100%的时间前几道工序,但与由于其相对存储器使用不同的权重。

芯片后端proc用法
芯片后端proc的用法是指在芯片设计中,使用proc(process)对芯片进行后端优化和布局布线。
芯片设计分为前端设计和后端设计两个阶段,前端设计主要涉及到逻辑设计、验证、综合和分区等,而后端设计则是对前端设计的综合优化,并进行物理布局和布线,具体包括以下几个步骤:
1. 综合:将逻辑电路和寄存器传递给综合工具,将其转换为基本构建模块(Gates和Flip-Flops)而不是原始的高级代码。
综合的目标是最小化电路的面积、功耗和时延。
2. 分区:将整个芯片分成不同的区域,以方便后续的布局布线操作。
通过合理的分区,可以降低布局布线的复杂度,并提高整体性能。
3. 布局:在每个区域内,对逻辑电路进行布局,即确定每个逻辑门的位置。
布局的目标是最小化布线的长度、减少布线的交叉和增加电路的可靠性。
4. 布线:在完成布局后,对芯片进行布线操作,即将各个逻辑门之间的连线进行连接。
布线的目标是保证信号的正确传输,同时最小化延迟和功耗。
5. 特殊处理:在芯片设计中,还可能需要进行一些特殊处理,如时钟树合成、功耗分析和电磁兼容性等。
通过以上的后端处理,可以对芯片进行优化,提高芯片的性能、
功耗和可靠性。
芯片后端proc的使用需要结合具体的芯片设计工具和技术来进行,通常由专业的芯片设计工程师来完成。

Linux /proc信息说明cd /proc/之后,你会发现很多的目录和文件,今天首先来介绍的就是那些以数字命名的目录--它们就是linux中的进程号,每当你创建一个进程时,里面就会动态更新多出一个名称为pid的目录,然后你ls -l /proc/pid会发现如下信息:dr-xr-xr-x 2 user group 0 Sep 19 16:17 attr-r-------- 1 user group 0 Sep 19 16:17 auxv-r--r--r-- 1 user group 0 Sep 19 16:17 cgroup--w------- 1 user group 0 Sep 19 16:17 clear_refs-r--r--r-- 1 user group 0 Sep 18 14:18 cmdline-rw-r--r-- 1 user group 0 Sep 19 16:17 coredump_filter-r--r--r-- 1 user group 0 Sep 19 16:17 cpusetlrwxrwxrwx 1 user group 0 Sep 19 16:17 cwd ->/home/user/zbs/mysql/node-2-r-------- 1 user group 0 Sep 19 16:17 environlrwxrwxrwx 1 user group 0 Sep 19 16:17 exe ->/home/user/zbs/xtradb-5.1.47_group/libexec/mysqlddr-x------ 2 user group 0 Sep 18 14:38 fddr-x------ 2 user group 0 Sep 19 16:17 fdinfo-r-------- 1 user group 0 Sep 19 16:17 io-r-------- 1 user group 0 Sep 19 16:17 limits-rw-r--r-- 1 user group 0 Sep 19 16:17 loginuid-r--r--r-- 1 user group 0 Sep 19 16:17 maps-rw------- 1 user group 0 Sep 19 16:17 mem-r--r--r-- 1 user group 0 Sep 19 16:17 mountinfo-r--r--r-- 1 user group 0 Sep 19 16:17 mounts-r-------- 1 user group 0 Sep 19 16:17 mountstatsdr-xr-xr-x 10 user group 0 Sep 19 16:17 net-r--r--r-- 1 user group 0 Sep 19 16:17 numa_maps-rw-r--r-- 1 user group 0 Sep 19 16:17 oom_adj-r--r--r-- 1 user group 0 Sep 19 16:17 oom_score-r--r--r-- 1 user group 0 Sep 19 16:17 pagemap-r--r--r-- 1 user group 0 Sep 19 16:17 personalitylrwxrwxrwx 1 user group 0 Sep 19 16:17 root -> /-rw-r--r-- 1 user group 0 Sep 19 16:17 sched-r--r--r-- 1 user group 0 Sep 19 16:17 sessionid-r--r--r-- 1 user group 0 Sep 19 16:17 smaps-r--r--r-- 1 user group 0 Sep 19 16:17 stack-r--r--r-- 1 user group 0 Sep 18 14:18 stat-r--r--r-- 1 user group 0 Sep 18 14:18 statm-r--r--r-- 1 user group 0 Sep 18 14:18 status-r--r--r-- 1 user group 0 Sep 19 16:17 syscalldr-xr-xr-x 20 user group 0 Sep 19 16:17 task下面我们挑常用的来解释(用红色标注出)cmdline:这个主要是当前这个进程被运行时的command line,里面包括了运行时指定的一些参数,比如如果是mysqld的话就包括basedir==,datadir==,port=,socket=等等信息,你可以自己尝试一下。

你不知道的Linux内核中的proc文件系统简介procfs文件系统是内核中的一个特殊文件系统。
它是一个虚拟文件系统: 它不是实际的存储设备中的文件,而是存在于内存中。
procfs中的文件是用来允许用户空间的程序访问内核中的某些信息(比如进程信息在 /proc/[0-9]+/中),或者用来做调试用途(/proc/ksyms,这个文件列出了已经登记的内核符号,这些符号给出了变量或函数的地址。
每行给出一个符号的地址,符号名称以及登记这个符号的模块。
程序ksyms、insmod和kmod使用这个文件。
它还列出了正在运行的任务数,总任务数和最后分配的PID。
)这个文档描述了内核中procfs文件系统的使用。
它以介绍所有和管理文件系统相关的函数开始。
在函数介绍后,它还展示了怎么和用户空间通信,和一些小技巧。
在文档的最后,还给出了一个完整的例子。
注意/proc/sys中的文件属于sysctl文件,它们不属于procfs文件系统,被另外一套完全不同的api管理。
seq_fileprocfs在处理大文件时有点笨拙。
为了清理procfs文件系统并且使内核编程简单些,引入了seq_file机制。
seq_file机制提供了大量简单的接口去实现大内核虚拟文件。
seq_file机制适用于你利用结构序列去创建一个返回给用户空间的虚拟文件。
要使用seq_file机制,你必须创建一个”iterator”对象,这个对象指向这个序列,并且能逐个指向这个序列中的对象,此外还要能输出这个序列中的任一个对象。
它听起来复杂,实际上,操作过程相当简单。
接下来将用实际的例子展示到底怎么做。
首先,你必须包含头文件。
接下来,你必须创建迭代器方法:start, next, stop, and show。
start方法通常被首先调用。
这个方法的函数原型是:void *start(struct seq_file *sfile, loff_t *pos);sfile没什么作用,通常被忽略。
proc节点的read函数proc节点的read函数是一个用于读取文件内容的函数。
它可以打开文件,读取文件中的数据,并将其返回给调用者。
read函数具有以下几个参数和功能:1. 文件路径(file_path):read函数需要接收一个文件路径作为参数,指定要读取的文件的位置和名称。
2. 读取模式(mode):read函数可以根据不同的读取模式来读取文件。
常见的读取模式包括:- "r":以只读模式打开文件,如果文件不存在则报错。
- "w":以写入模式打开文件,如果文件不存在则创建新文件,如果文件已存在则清空文件内容。
- "a":以追加模式打开文件,如果文件不存在则创建新文件,如果文件已存在则在文件末尾追加内容。
- "b":以二进制模式打开文件。
3. 编码格式(encoding):read函数可以指定文件的编码格式,以便正确地读取文件内容。
常见的编码格式包括:- "utf-8":UTF-8编码,适用于大多数文本文件。
- "gbk":GBK编码,适用于中文文本文件。
- "latin-1":Latin-1编码,适用于某些特定的文本文件。
read函数的使用步骤如下:1. 打开文件:read函数首先会根据文件路径和读取模式打开文件。
2. 读取文件内容:read函数会根据指定的编码格式读取文件中的数据,并将其存储在一个字符串变量中。
3. 关闭文件:读取完成后,read函数会关闭文件,释放资源。
read函数的返回值是一个字符串,包含了文件中的全部内容。
调用者可以根据需要对读取到的内容进行进一步处理,比如进行字符串分割、正则表达式匹配等操作。
proc节点的read函数是一个非常实用的文件读取函数,它可以帮助我们轻松地读取文件内容并进行进一步处理。
无论是读取文本文件还是二进制文件,无论是读取整个文件还是逐行读取,read函数都可以满足我们的需求。
Prolog语言解八皇后问题1、实验环境Visual Prolog2、实验目的和要求自学Prolog语言学习使用visual prolog解八皇后问题3、解题思路、代码3.1解题思路八个皇后分别为A,B,C,D,E,F,G,H其值分别为第1,2,3……8列皇后所在位置domainspredicatesclausesgoal3.2代码PREDICATESDOMAINScell=c(integer, integer)list=cell*int_list=integer*PREDICATESsolution(list)member(integer,int_list)nonattack(cell,list)CLAUSESsolution([]).solution([c(X,Y)|Others]):-solution(Others),member(Y,[1,2,3,4,5,6,7,8]),nonattack(c(X,Y),Others).nonattack(_,[]).nonattack(c(X,Y),[c(X1,Y1)|Others]):-Y<>Y1,Y1-Y<>X1-X,Y1-Y<>X-X1,nonattack(c(X,Y),Others).member(X,[X|_]).member(X,[_|Z]):-member(X,Z).GOALsolution([c(1,A),c(2,B),c(3,C),c(4,D),c(5,E),c(6,F),c(7,G),c(8,H)]).4、实验步骤4.1输入:4.2输出:……………..(后面还有一页输出,略)5、讨论和分析这个语言没教过,只有几页PPT,看了也没用,到网上下了一本Prolog语言教程看了好几天才会。
Prolog 语言及其基本结构是:事实、规则、目标(问题),prolog 程序没有特定的运行顺序,其运行顺序是由电脑决定的,而不是编程序的人,prolog 程序中没有if、when、case、for 这样的控制流程语句,prolog 程序和数据高度统一,prolog 程序实际上是一个智能数据库,有强大的递归功能。
Linux内核参数及Oracle相关参数调整修改内核参数的⽅法RedHat向管理员提供了⾮常好的⽅法,使我们可以在系统运⾏时更改内核参数,⽽不需要重新引导系统。
这是通过/proc虚拟⽂件系统实现的。
/proc/sys⽬录下存放着⼤多数的内核参数,并且设计成可以在系统运⾏的同时进⾏更改。
更改⽅法有两种:⽅法⼀:修改/proc/sys⽬录下的相应⽂件,⽐如:/proc/sys/net/ipv4/ip_forward,修改后⽴刻可⽤,不⽤重启系统,但重启系统,会恢复到默认值。
⽅法⼆:修改/etc/sysctl.conf ⽂件,该⽂件中以(变量=值)的形式设置内核参数,修改后,不能⽴刻⽣效,需要执⾏/sbin/sysctl –p 命令,使配置⽂件⽣效。
注意: /etc/sysctl.conf和/proc/sys下的⽂件其实都对应着⼀个参数,它们之间的对应关系,有简单规则:将/proc/sys中的⽂件转换成sysctl中的变量的规则:1.去掉前⾯部分/proc/sys2.将⽂件名中的斜杠变为点这两条规则可以将/proc/sys中的任⼀⽂件名转换成sysctl中的变量名。
例如:/proc/sys/net/ipv4/ip_forward =》 net.ipv4.ip_forward/proc/sys/kernel/hostname =》 kernel.hostname可以使⽤下⾯命令查询所有可修改的变量名例⼦:以打开内核的转发功能。
IP转发是指允许系统对来源和⽬的地都不是本机的数据包通过⽹络,RedHat默认屏蔽此功能,在需要⽤本机作为路由器、NAT等情况下需要开启此功能。
⽅法⼀:修改/proc下内核参数⽂件内容直接修改内核参数ip_forward对应在/proc下的⽂件/proc/sys/net/ipv4/ip_forward。
⽤下⾯命令查看ip_forward⽂件内容:# cat /proc/sys/net/ipv4/ip_forward该⽂件默认值0是禁⽌ip转发,修改为1即开启ip转发功能。
题目:proc contents r 用法目录1. proc contents r 简介2. proc contents r 的基本用法3. proc contents r 的参数介绍4. proc contents r 的常见应用场景5. 总结1. proc contents r 简介在SAS语言中,proc contents r 是一个非常常用的程序,用于查看SAS数据集的结构和属性信息。
通过使用 proc contents r,用户可以了解数据集中包含的变量名称、变量类型、变量长度等属性信息,帮助用户更好地理解和分析数据。
本文将介绍 proc contents r 的基本用法、参数介绍以及常见应用场景。
2. proc contents r 的基本用法使用 proc contents r 程序非常简单,只需在SAS编辑器或SAS Studio中输入如下命令即可:```sasproc contents data=dataset_name;run;```其中,data=dataset_name 是要查看的数据集名称,用户可以将其替换为自己的数据集名称。
运行上述命令后,SAS将返回一个包含数据集结构和属性信息的报表,展示数据集中包含的变量、变量类型、变量长度等信息。
3. proc contents r 的参数介绍除了基本用法外,proc contents r 还支持一些参数,用户可以根据自己的需求来进行设置。
常用的参数包括:- var:指定要查看的变量名称,可以同时指定多个变量,用空格分隔。
- out:将结果保存为一个新的数据集,供后续分析使用。
- short:仅显示变量名称和类型,不显示其他属性信息。
- position:显示变量在数据集中的位置信息。
- memtype:指定要查看的数据集成员类型,如data、view等。
用户可以根据自己的需求,灵活运用这些参数来定制 proc contents r 的输出结果。