企业IT运维服务指标体系
- 格式:docx
- 大小:145.03 KB
- 文档页数:60

it运维服务管理指标IT运维服务管理指标随着信息技术的快速发展,IT运维服务管理在企业中扮演着至关重要的角色。
无论是保障系统稳定运行,还是提供优质的技术支持,IT运维服务管理都需要有一套科学有效的指标体系来衡量和评估。
本文将从不同的维度介绍IT运维服务管理的指标,帮助企业更好地管理和优化IT运维服务。
一、服务可用性指标服务可用性是衡量IT运维服务质量的重要指标之一。
它反映了系统或服务在一定时间内可正常使用的能力。
常用的服务可用性指标包括:1.1 系统可靠性:反映系统在一段时间内的故障次数和故障恢复时间。
例如,平均故障间隔时间(MTBF)和平均故障恢复时间(MTTR)。
1.2 服务可用性率:反映系统或服务在一段时间内可用的比例。
例如,99.9%的可用性表示系统每年最多只有8小时的停机时间。
1.3 服务质量指标:反映系统或服务在提供服务过程中的性能表现,如响应时间、吞吐量等。
二、问题管理指标问题管理是IT运维服务管理中的重要环节,它涉及到对故障、变更和事件等问题的有效管理和解决。
以下是常用的问题管理指标:2.1 问题解决率:反映问题解决的效率和质量。
通常以问题解决的平均时间和解决率来衡量。
2.2 问题重复率:反映同一问题在一段时间内的重复发生情况。
较高的问题重复率可能意味着解决问题的根本原因没有得到有效解决。
2.3 问题溢出率:反映无法解决的问题数量。
较高的问题溢出率可能意味着团队的能力不足或问题管理流程不完善。
三、变更管理指标变更管理是IT运维服务管理中的关键环节,它涉及到对系统和服务的变更进行规范、控制和评估。
以下是常用的变更管理指标:3.1 变更成功率:反映变更实施的成功率和质量。
通常以变更成功的比例来衡量。
3.2 变更失败率:反映变更实施的失败率和原因。
较高的变更失败率可能意味着变更管理流程不完善或变更实施缺乏规范。
3.3 变更影响度:反映变更对系统和服务的影响程度。
较高的变更影响度可能意味着变更实施风险较大,需要更加谨慎评估和控制。


it运维管理体系指标IT运维管理体系指标是衡量企业IT运维管理绩效的重要标准,它可以帮助企业评估自身的运维管理水平,发现问题并进行改进。
本文将从IT运维管理体系指标的定义、分类和重要性等方面进行详细介绍。
一、IT运维管理体系指标的定义IT运维管理体系指标是指用于评估和衡量企业IT运维管理绩效的一系列指标。
它可以反映企业在IT运维管理方面的优势和劣势,帮助企业发现问题并制定改进措施。
IT运维管理体系指标通常包括运维效率、运维质量、运维成本等多个方面的指标。
二、IT运维管理体系指标的分类1. 运维效率指标运维效率指标反映了企业IT运维团队的工作效率。
常见的运维效率指标包括平均故障修复时间、平均故障修复率、平均故障处理效率等。
通过监控这些指标,企业可以评估运维团队的响应速度和处理效率,及时发现并解决故障。
2. 运维质量指标运维质量指标衡量了企业IT运维服务的质量水平。
常见的运维质量指标包括故障发生率、故障再发生率、用户满意度等。
这些指标可以帮助企业评估运维服务的可靠性和稳定性,从而提升用户满意度。
3. 运维成本指标运维成本指标反映了企业IT运维管理的经济效益。
常见的运维成本指标包括每台设备的平均运维成本、每个故障的平均处理成本等。
通过监控这些指标,企业可以评估运维管理的经济效益,合理控制运维成本。
三、IT运维管理体系指标的重要性1. 评估绩效IT运维管理体系指标可以帮助企业评估自身的运维管理绩效,发现问题并进行改进。
通过监控和分析指标数据,企业可以了解自身在运维效率、运维质量和运维成本等方面的表现,及时调整运维策略,提升绩效。
2. 改进管理IT运维管理体系指标可以帮助企业发现问题和短板,并制定相应的改进措施。
通过对指标数据的分析,企业可以识别出导致运维效率低下、运维质量不高和运维成本过高的原因,从而采取相应的管理措施,提升运维管理水平。
3. 提升用户满意度IT运维管理体系指标中的运维质量指标可以帮助企业评估运维服务的可靠性和稳定性,进而提升用户满意度。

ITSM运维服务体系介绍ITSM(IT Service Management,IT服务管理)是指通过规范和集成各种IT服务管理过程,以提高IT服务质量、降低IT服务成本、提升IT部门效率和响应能力的一种管理方式。
ITSM运维服务体系是在ITSM理念指导下建立的一套完善的IT运维服务管理体系。
本文将从ITSM运维服务体系的概念、原则、架构和实施过程等方面进行详细介绍。
一、ITSM运维服务体系的概念及原则ITSM运维服务体系是指在ITSM理念的引领下,通过规范和集成各种IT运维服务管理流程和工具,构建了一个完整的IT运维服务体系。
它包括了服务战略、服务设计、服务过渡、服务运营和持续改进等环节,以确保IT运维服务的稳定性、高效性和质量。
1.用户至上:将用户需求放在首位,为用户提供满足其业务需求的稳定、高效的IT运维服务。
2.过程导向:通过规范和标准化各个IT运维服务管理流程,确保服务质量和可靠性。
3.持续改进:通过监控、评估和优化IT运维服务,不断提升运维服务质量和水平。
4.可测量性:通过设定衡量指标和指标体系,对运维服务进行定量评估和监控。
二、ITSM运维服务体系的架构1.服务战略:这个环节主要关注IT运维服务的规划和战略目标的制定,包括明确服务目标、制定服务策略、评估服务需求和制定服务策略等。
2.服务设计:在这个环节中,主要进行IT运维服务的详细设计和开发,包括制定服务架构、定义服务流程、确定服务级别协议(SLA)和设计服务目录等。
3.服务过渡:这个环节主要关注将新的或变更的IT运维服务交付给用户,并确保用户顺利使用,包括服务测试、培训和变更控制等。
4.服务运营:在这个环节中,主要进行IT运维服务的实施和运营,包括服务请求管理、事件管理、问题管理和变更管理等。
5.持续改进:这个环节主要是通过不断的监控和评估IT运维服务的性能和效果,以便对运维服务进行优化和改进,包括制定改进计划、实施改进行动和评估改进效果等。


it运维考核指标IT运维考核指标IT运维是指企业或组织在日常运营中对信息技术系统进行监控、维护、修复和优化的过程。
对于一个运维团队来说,评估运维工作的效果和质量非常重要。
为了确保IT运维的高效、稳定和安全,需要建立一套科学合理的考核指标体系。
一、故障处理能力故障处理是IT运维工作中最基本的任务之一。
考核指标应包括故障响应时间、故障处理时间、故障解决率等。
故障响应时间是指从故障发生到运维人员开始处理的时间,应尽量缩短。
故障处理时间是指从运维人员开始处理故障到故障解决的时间,应尽量减少。
故障解决率是指成功解决故障的比例,应保持较高水平。
二、系统稳定性系统稳定性是衡量IT运维工作质量的重要指标。
考核指标可以包括系统可用性、系统崩溃次数等。
系统可用性是指系统能够正常运行的时间占总时间的比例,应保持较高水平。
系统崩溃次数是指系统在一段时间内发生故障导致无法正常运行的次数,应尽量减少。
三、安全性能安全性是IT运维工作中的核心要求之一。
考核指标可以包括信息安全漏洞的发现和修复时间、系统安全事件的响应时间等。
信息安全漏洞的发现和修复时间是指运维人员发现安全漏洞后及时进行修复的时间,应尽量缩短。
系统安全事件的响应时间是指运维人员在发生安全事件后开始处理的时间,应尽量缩短,确保安全事件不会扩大。
四、效率与优化IT运维的目标是提高系统的效率和性能。
考核指标可以包括系统资源利用率、系统响应时间等。
系统资源利用率是指系统使用的硬件资源、网络资源等的利用率,应确保合理使用资源,提高系统效率。
系统响应时间是指系统处理用户请求的时间,应尽量缩短,提高用户体验。
五、团队合作与沟通IT运维工作需要团队合作和良好的沟通协调能力。
考核指标可以包括团队协作效果、沟通响应时间等。
团队协作效果是指团队成员之间的合作效果,应确保团队协作顺畅高效。
沟通响应时间是指团队成员之间沟通交流的效率,应尽量缩短,确保沟通不延误工作。
六、知识与技能更新IT运维是一个快速发展的领域,考核指标应包括团队成员的知识学习和技能提升。

运维服务指标体系1.系统稳定性:系统稳定性是运维服务的基础,可以通过以下指标来评估:系统可用性、系统故障次数、系统恢复时间、系统性能指标等。
这些指标可以通过监控和日志数据来统计和计算,用以衡量系统稳定性的优劣程度。
2.故障处理:故障处理是运维服务中重要的工作内容,应对故障的速度和效果直接影响着系统的稳定性。
可以通过以下指标来评估故障处理能力:故障响应时间、故障修复时间、故障分析和解决率等。
这些指标可以帮助评估运维团队的应急能力和解决问题的能力。
3.变更管理:变更管理是运维服务中的关键环节,对于系统的稳定运行至关重要。
可以通过以下指标来评估变更管理的质量:变更执行成功率、变更计划执行时间、变更后故障率等。
这些指标可以帮助衡量变更管理的效果和变更对系统稳定性的影响。
4.巡检和预防:定期巡检和预防性维护是运维服务中的重要工作内容。
可以通过以下指标来评估巡检和预防的质量:巡检频率、巡检异常发现率、漏洞修复时间等。
这些指标可以帮助衡量巡检和预防对系统安全和稳定性的贡献。
5.客户满意度:客户满意度是评估运维服务的重要指标,反映了客户对运维服务的认可和满意程度。
可以通过客户反馈、调查问卷等方式来获取客户满意度数据,用以评估和改善运维服务的质量。
综上所述,运维服务指标体系是评估运维服务质量的重要工具,可以从系统稳定性、故障处理、变更管理、巡检和预防、客户满意度等多个方面进行考虑和设计,以全面衡量和评价运维服务的能力和质量。
通过合理制定和运用指标体系,可以帮助企业实现高效稳定的运维运营,提升系统的可用性和用户体验。


信息系统运行维护方案(IT运维服务方案)目录1运维服务内容3信息系统运行维护方案IT运维服务方案1.1服务目标31.2信息资产统计服务41.3网络、安全系统运维服务51。
4主机、存储系统运维服务111。
5数据库系统运维服务201。
6中间件运维服务232运维服务流程253服务管理制度规范273.1服务时间273。
2行为规范283。
3现场服务支持规范293.4问题记录规范304应急服务响应措施324。
1应急基本流程324。
2预防措施324。
3突发事件应急策略341服务内容1.1服务目标运行维护服务包括,信息系统相关的主机设备、操作系统、数据库和存储设备及其他信息系统的运行维护与安全防范服务,保证用户现有的信息系统的正常运行,降低整体管理成本,提高网络信息系统的整体服务水平.同时根据日常维护的数据和记录,提供用户信息系统的整体建设规划和建议,更好的为用户的信息化发展提供有力的保障。
用户信息系统的组成主要可分为两类:硬件设备和软件系统。
硬件设备包括网络设备、安全设备、主机设备、存储设备等;软件设备可分为操作系统软件、典型应用软件(如:数据库软件、中间件软件等)、业务应用软件等。
通过运行维护服务的有效管理来提升用户信息系统的服务效率,协调各业务应用系统的内部运作,改善网络信息系统部门与业务部门的沟通,提高服务质量。
结合用户现有的环境、组织结构、IT资源和管理流程的特点,从流程、人员和技术三方面来规划用户的网络信息系统的结构。
将用户的运行目标、业务需求与IT服务的相协调一致。
信息系统服务的目标是,对用户现有的信息系统基础资源进行监控和管理,及时掌握网络信息系统资源现状和配置信息,反映信息系统资源的可用性情况和健康状况,创建一个可知可控的IT环境,从而保证用户信息系统的各类业务应用系统的可靠、高效、持续、安全运行. 服务项目范围覆盖的信息系统资源以下方面的关键状态及参数指标:➢运行状态、故障情况➢配置信息➢可用性情况及健康状况性能指标➢统计运维数椐、提供信息系统管理和工作报告、归纳总结并提供用户想了解的数椐报告1.2信息资产统计服务此项服务为基本服务,包含在运行维护服务中,帮助我们对用户现有的信息资产情况进行了解,更好的提供系统的运行维护服务.服务内容包括:➢硬件设备型号、数量、版本等信息统计记录➢软件产品型号、版本和补丁等信息统计记录➢网络结构、网络路由、网络IP地址统计记录➢综合布线系统结构图的绘制➢其它附属设备的统计记录硬件设备清单如下表统计:1.3网络、安全系统运维服务从网络的连通性、网络的性能、网络的监控管理三个方面实现对网络系统的运维管理。
运维服务指标体系运维服务指标体系是指对于企业的运维服务进行评估和衡量的一套指标体系,旨在提供一个客观、科学的评估体系,帮助企业监控和管理其运维服务的质量和效果。
在实际应用中,运维服务指标体系可以帮助企业识别问题、优化流程、提高服务水平,从而提高整体的运维效率和效果。
一、响应时间响应时间是指从用户提交问题或请求到运维团队给予响应的时间。
用户在运维服务中的体验很大程度上取决于响应时间的快慢。
较短的响应时间可以有效提高用户满意度,并减少用户因等待过长时间而导致的不满情绪。
因此,响应时间是一个非常重要的运维服务指标。
二、故障处理时间故障处理时间是指从故障发生到最终解决该故障所花费的时间。
故障处理时间是评估运维团队处理能力和效率的重要指标。
较短的故障处理时间可以有效降低系统停机时间、提高服务可用性,从而提高用户体验。
三、问题解决率问题解决率是指运维团队解决用户问题的有效率。
包括问题解决次数、解决率等指标。
高问题解决率意味着运维团队具备快速定位和解决问题的能力,可以最大限度地减少用户遇到的问题。
四、问题再次发生率问题再次发生率是指同一问题在一段时间内的再次发生次数。
问题再次发生率可以反映运维团队的问题解决的持久性和稳定性。
较低的问题再次发生率表明运维团队解决问题的措施有效,并且提供的解决方案能够持久稳定地解决问题。
五、变更成功率变更成功率是指变更计划成功实施的比例。
在运维服务中,经常需要进行系统或配置的变更。
高变更成功率意味着变更计划的制定和实施具备科学性和可行性,减少了系统的风险和不稳定性。
六、服务可用性服务可用性是指系统能够提供服务的时间占全部时间的比例。
服务可用性能反映运维团队维护服务的稳定性和可靠性。
高服务可用性可以最大程度地减少系统停机时间,提供持续稳定的服务。
七、客户满意度客户满意度是指客户对运维服务的满意程度。
通过定期进行客户满意度调查、评估,可以了解客户对运维团队的意见和建议,进而优化服务流程和提高服务质量。
1 业务运维管理体系1.1 业务运维成熟度运维管理5级成熟度模型业务运维成熟度自我评估是指运维服务组织已建立并实施了运维服务能力管理体系,根据定期的或临时性的管理要求,对整个运维服务能力管理或特定范围就运维服务能力管理的符合性和有效性所进行的内部检查。
自我评估旨在发现运维服务能力管理和实施中的问题或不足,识别改进点和行动措施,从而促进本组织运维服务能力和服务质量的持续改进。
1.2 运维多层指标体系1.2.1 体系模型构建完善健全的业务层次、多维度监控指标体系模型1.2.2 问题程度划分模型使用了基于5级层次的性能与问题程度划分模型,确保测评的粒度、真实情况及用户可接受性;1.2.3 典型指标体系参考1.2.3.1 业务与一般的面向技术的性能指标不同,业务指标一般是根据不同行业的用户特点来具体分析梳理的,以下以连锁快消行业某个企业的业务举例说明业务指标的梳理与建立。
会员 会员总数、新增会员等 订单 订单数、新增订单、成功订单、订单转化率、客单价等 交易 交易额、销量统计、销售排行、销售机会、销售漏斗、业务趋势、退款金额、毛利等 库存 库存总量、库存占用资金、运销率、商品销售排行等 门店 门店总数、新增门店、关闭门店、优秀门店、问题门店等 客户 客户总数、新增客户、潜在客户、关注客户等 1.2.3.2 用户体验(前端)1.2.3.2.1 A pp移动性能 行为动作 影响用户数、错误用户数、崩溃用户数、响应时间、http请求次数、请求错误次数等 行为流程 用户转化率、事件数、总用户数、平均耗时、错误数、崩溃数等 用户分析 新增用户数、活跃用户数、HTTP错误用户数、网络失败用户数、崩溃错误用户数、HTTP错误率、网络失败率、崩溃率、会话数等 HTTP请求 响应时间、吞吐率、HTTP错误率、网络失败率、请求次数、TCP、DNS、SSL、网络延迟时间、首包时间等 错误 请求错误率、HTTP错误率、网络失败率、错误次数、影响用户数、POST参数、响应头、响应内容、调用堆栈等 Socket请求 建立连接最慢的主机、Read耗时最长的主机、Write耗时最长的主机、异常最多的主机、连接耗时等 Socket异常 异常用户、异常次数、使用用户、App版本、影响用户数、异常堆栈等 页面加载 平均响应时间、平均执行时间、执行次数、首屏时间、白屏时间、吞吐量、耗时、JS错误、JS错误次数、JS错误类型、错误堆栈、响应时间分解图、页面加载资源时序图等 Ajax 平均响应时间、响应时间、执行次数、耗时、Ajax错误、Ajax错误次数、错误类型、响应时间分解图等 接入方式 响应时间、请求错误率、活跃会话数、新增用户数、活跃用户数、启动次数等 运营商 响应时间、HTTP错误率、请求错误率、网络失败率、活跃会话数、新增用户数、活跃用户数、启动次数等 系统版本 响应时间、请求错误率、吞吐率、活跃会话数、HTTP错误率、网络失败率、新增用户数、活跃用户数、启动次数等 App版本 响应时间、HTTP错误率、请求错误率、网络失败率、活跃会话数、新增用户数、活跃用户数、启动次数等 设备 响应时间、活跃会话数、HTTP错误率、网络失败率、新增用户数、活跃用户数、启动次数等 地域 响应时间、吞吐率、请求错误率、活跃会话数、新增用户数、活跃用户数、系统版本崩溃数等 视频流 推流信息:直播间、已播放时长、平均帧率、平均码率、瞬时帧率、固定帧率、瞬时码率、错误次数、影响直播错误次数、普通错误次数、推流失败错误占比等 观看信息:观看人数、浏览次数、卡顿率、延迟时间、可用率、平均卡顿时长、平均延迟时间、平均卡顿次数、平均错误次数、卡顿分布等 崩溃 崩溃率、崩溃用户数、崩溃次数、使用用户数、Bug数、已修复Bug数、未修复Bug数、影响用户数、崩溃堆栈等 ANR/卡顿 ANR/卡顿率、ANR/卡顿用户、ANR/卡顿次数、人均ANR/卡顿次数、App版本、影响设备、影响用户数等 组合分析 响应时间、吞吐率、活跃用户数、HTTP错误率、网络失败率等 劫持分析 访问量最高的劫持域名、劫持分布、请求次数、吞吐率、劫持占比等 交互 执行时间、执行次数、耗时、记录时间、操作系统、设备、地理信息、接入方式、剩余电量、屏幕朝向、CPU、Memory、视图、请求数等 拓扑图 自身服务、外部服务、HTTP错误率、网络失败率、响应时间 移动运营 新增和启动用户 新增用户、新增用户占比、启动用户、启动次数、活跃用户、累计总用户等 地域分析 新增用户、新增用户占比、活跃用户、活跃用户占比、启动次数、启动次数占比等 活跃用户 日活跃DAU、周活跃WAU、月活跃MAU、DAU/MAU等 留存用户 留存用户、新用户、次日留存率、7日留存率、30日留存率等 渠道分析 新增用户、活跃用户、启动次数、累计用户总数等 设备分析 新增用户、新增用户占比、活跃用户、活跃用户占比、启动次数、启动次数占比等 1.2.3.2.2 B rowser整体 访客数、总IP数、总页面数、浏览量、JS错误率、JS错误页面数、AJAX错误数、吞吐率、Apdex等 Ajax 响应时间、错误类型、Post数据、接收数据、请求次数、调用页面、性能趋势等 网页 响应时间、吞吐率、JS错误数、AJAX请求数、终端用户响应时间、首屏时间、首字节时间、服务器连接时间、响应可用时间、前端时间、文档准备时间、文档下载时间、文档处理时间、页面渲染时间、页面访问量等 浏览器 响应时间、吞吐率、JS错误数、AJAX请求数、终端用户响应时间、首屏时间、首字节时间、服务器连接时间、响应可用时间、前端时间、文档准备时间、文档下载时间、文档处理时间、页面渲染时间、页面访问量等 运营商 响应时间、吞吐率、JS错误数、AJAX请求数、终端用户响应时间、首屏时间、首字节时间、服务器连接时间、响应可用时间、前端时间、文档准备时间、文档下载时间、文档处理时间、页面渲染时间、页面访问量等 JS错误 错误类型、错误数量、错误信息、发生时间、IP、地域、浏览器及版本号、UA 数据、错误堆栈等 1.2.3.3 网络网站监控 HTTP/HTTPs监控 响应时间、可用率、响应服务器IP、下载字节数、下载速度、HTTP响应头信息等 Ping监控 响应时间、可用率、主机IP、数据包大小、TTL、发送的包数、收到的包数、丢包率、Ping快照等 DNS监控 响应时间、可用率、DNS解析服务器、主机记录、记录类型、记录值、TTL等 TraceRoute监控 响应时间、可用率、最大跳数、数据包大小、跳转路径等 FTP监控 响应时间、可用率、FTP报文等 TCP监控 响应时间、可用率、主机IP等 UDP监控 响应时间、可用率、主机IP、UDP报文等 SMTP监控 响应时间、可用率、主机IP、SMTP响应内容、HTTP响应头信息等 网页性能监控 页面可用性 目标IP、DNS服务器、元素瀑布图、网络诊断结果等 元素可用性 元素类型、状态、元素URL等 元素响应时间 首屏时间、网络层时间、DNS解析时间、连接建立时间、SSL握手时间、重定向时间、首字节时间等 元素性能评估 性能评估得分、静态资源CDN使用率、首屏时间、响应时间、请求个数、域名数等 1.2.3.4 应用(后端)业务流程 可用率、可用性、故障次数、正确率、正确性、错误次数、响应时间等 业务拓扑 业务健康度、事务健康度、响应时间、请求数、错误数等 Web应用 事务 运行状态、每分钟执行次数、响应时间、Apdex值、错误率、错误次数、总执行次数等 请求 响应时间、吞吐率、错误次数、错误/分钟、错误率、异常率、请求次数、缓慢请求率、非常慢请求率 外部服务 响应时间、吞吐率、耗时、HTTP错误率、网络错误率等 数据库 数据库类型、操作类型、访问次数、吞吐量、平均响应时间、最大响应时间和最小响应时间 NoSQL 响应时间、吞吐率、调用者耗时占比、key名称、Value大小、SQL操作执行次数、耗时等 错误 错误URL、错误时间、错误次数、请求参数、异常URL、异常时间、异常次数等 后台任务 响应时间、吞吐量、CPU使用率、内存使用情况、访问次数、平均耗时、错误数等 运维视图 事务健康度、层健康度、节点健康度、响应时间、请求数、错误数等 1.2.3.5 服务1.2.3.5.1 中间件Web/App Server Apache 吞吐率、并发连接数、线程数、运行时间等 Nginx 吞吐率、并发连接数、版本、连接丢失率等 Tomcat JVM内存、线程、处理时间、请求数、网络流量等 Weblogic 空闲HEAP、吞吐量、空闲线程数、JMS连接数等 Varnish 内存、缓存命中数、缓存Object数、过期Object数、线程数等 Jboss JVM内存使用率、服务器应答时间、EJB、线程池、JDBC连接池等 WebSphere CPU使用、内存使用、JVM使用、响应时间、实时会话、JDBC连接池、JMS 队列等 Resin Karaf Netty WildFly Glassfish 内存使用、进程内存、虚拟内存、线程池等 ColdFusion TomEE IIS 当前连接数、运行时间、每秒接收字节数、每秒发送字节数、每秒传输字节数、每秒接收文件数等 Express Gunicorn 请求响应时间、每秒请求数、每秒错误数、每秒异常数、每秒告警数等 消息中间件 ActiveMQ 内存使用、存储使用、消费者连接数、生产者连接数、排队消息数、过期消息数等 RabbitMQ 消息总数、每分钟消息数、平均消息发送时间、总流量、每分钟流量数等 JMS ZeroMQ RocketMQ MSMQ 每秒进入消息数、每秒向外消息数、队列会话总数、队列大小、队列消息数等 TXC for MQ ONS MQ 其他 Kafka 最大消费滞后、日志刷新速率、传入字节速率、传出字节速率、延迟consumer请求数等 Docker CPU使用率、内存使用量、运行容器数、停止容器数、顶级容器数等 ElasticSearch 线程总数、排队线程数、活跃线程数、事务日志的大小、索引段使用的内存、GET请求次数等 Solr 每秒缓存驱逐数、每秒缓存命中数、每秒缓存插入数、每秒缓存查找数、每秒平均请求数等 Gearman 队列任务数、运行任务数、注册任务数、workers数量等 HAProxy 每秒错误请求数、每秒HTTP请求数、每秒创建的后端会话数、活跃前端会话数、后端主机数量等 HDFS 总容量、缓存容量、已使用缓存、磁盘容量、磁盘剩余空间、已使用磁盘空间、预估容量损失等Mesos CPU总数、总内存、占用内存、磁盘空间总量、丢弃消息数、活跃框架数、无效任务数等 ZooKeeper 接收的字节数、发送的字节数、客户端连接总数、接收数据包数、发送数据包数等 PHP-FPM 活跃进程数、空闲进程数、最大活跃进程数、总进程数、缓存请求数等 Weblogic Weblogic实例 可用性:服务可用性 性能: 系统CPU利用率、WebLogic CPU利用率、JVM内存利用率、系统内存利用率、提交成功的事务耗费的时间(秒)Workload监控 信息: Server名称(隐藏)、IP地址、主机名、MAC地址(隐藏)、版本、操作系统、物理内存容量、当前堆大小、使用的堆大小、丢弃的事务数、应用程序出错回滚的事务数、资源出错回滚的事务数、系统出错回滚的事务数、超时回滚的事务数、当前连接数、总连接数、最高连接数、当前JMS服务数、最高JMS服务数、总JMS服务数 Web应用 可用性: Web应用可用性 信息: 当前Session数、应用名称(隐藏)、会话数最高值、当前活动的Session数 DatabaseConnectionPool 可用性: 连接池可用性 性能: 等待的连接数、连接池使用率 信息: 连接池名称(隐藏)、连接池大小、当前活动的连接数量、泄漏的连接数、平均活动连接数 Thread Pool 信息: 线程池名称(隐藏)、当前空闲线程数、等待的请求数、总线程数、最长等待的请求时间 JMS 信息: JMS Server名称(隐藏)、已接收的JMS消息数、等待处理的JMS 消息数 Jboss JBOSS AS 可用性: 服务可用性 性能: 主机CPU利用率、JBoss CPU利用率、主机内存利用率、JVM内存利用率、JBOSS Session、JBOSS Free Memory、JBOSS Thread 信息: 实例名称(隐藏)、显示名称(隐藏)、HomeDir(隐藏)、IP地址、主机名、版本、JNP(JNDI Provider)监听端口(隐藏)、操作系统、主机Mac地址(隐藏)、物理内存容量、堆的总大小、空闲堆大小、已使用内存(隐藏)、最大堆大小、最大线程数、最小线程数、JMS当前连接数、JMS总连接数、JMS最高连接数、JMS允许的最大连接数 Web应用 可用性: Web应用可用性 信息: 应用名称(隐藏)、上下文根 JDBC连接池 可用性: JDBC连接池可用性 性能: 活动的连接数 信息: 连接池名称(隐藏)、最大连接数、最小连接数 Websphere WebSphere AS 可用性: WebSphere AS可用性 性能: 系统CPU利用率、WebSphere AS CPU利用率、系统内存利用率、JVM内存利用率、活动的线程、最大百分比、活动线程利用率 信息: Pid、主机名、IP地址、操作系统、Cell名称、节点名称、Server名称、Cluster名称、空闲内存、使用的内存、分配总内存、连续运行时间、活动的本地事务、已提交的本地事务数、已回滚的本地事务数、已超时的本地事务数、平均池大小、MacAddress、显示名称 配置: 版本、构建号、Data Source个数、Web应用个数、JVM允许使用的最大内存、JVM允许使用的最小内存、物理内存容量、HTTP端口、HTTPS端口、最小大小、最大大小 Cluster 可用性: Cluster可用性 信息: Cluster名称、Cluster成员、Cluster成员个数 JDBC连接池 可用性: 连接池可用性 性能: 平均等待时间、使用百分比、最大百分比 信息: Pool_ID、JDBC Provider名称、连接池名称、连接池类型、平均池大小、空闲池大小 配置: 最大连接数、最小连接数 Web应用 可用性: Web应用可用性 性能: 会话利用率 信息: Web应用名称、Web应用J2EE名称、并发活动的会话数、当前在内存中高速缓存的会话数、不再存在的会话的请求数 配置: 允许创建的最大会话数 1.2.3.5.2 数据库Oracle 并发性能、IO性能、内存进程 MySQL 吞吐率、并发连接数、查询缓存、表锁定、查询速率等 SQLServer 连接数、请求频率(请求/分钟)、执行出错数、磁盘IO请求、锁时间、锁频率、消耗内存数、日志大小、数据库大小等 MongoDB 库锁定、库查询、使用内存、索引命中率等 Redis 占用内存、执行命令数、命中率、即时连接数、请求连接次数、阻塞客户数、Pub/Sub通道数和Pub/Sub模式数等 Memcache 命中率占用内存、即时连接数、每秒请求连接次数、缓存数量、读写命令、内存使用率等 PostgreSQL 数据库容量、数据库连接数、数据库死锁数、数据库缓存命中率、共享缓冲区利用率等 DB2 运行状态、连接时间、日志空间使用率、命中率、表空间等 Sybase 内存利用情况、数据库信息、当前进程、CPU、内存、磁盘利用率等 CouchBase 内存命中率、数据操作、文档数、内存溢出错误、内存监控、磁盘队列、内存中文档值和元数据的存储情况、连接数等 CouchDB 数据库磁盘大小、数据库文档数、文档读写次数、HTTP请求数、视图读取次数、错误响应次数等 Cassandra 缓存请求数、缓存数据量、抛出的异常数、缓存的匹配数、客户端请求数、使用磁盘空间等 MariaDB DRDS Derby HSQL H2 Druid SQLite Oracle 实例可用性、监听器可用性 性能: 系统CPU利用率、Oracle DB CPU利用率、系统内存利用率、Oracle DB 内存利用率、PGA命中率、库缓存命中率、高速缓冲缓存命中率、物理读速率、物理写速率、数据块获取数/秒、一致性获取数/秒、内存排序比率、当前连接会话数、当前进程数、登陆会话数/秒、当前打开的游标数、当前锁数量、死锁数量、SQL解析次数/秒、事务数/秒、事务回滚率 信息: 资源名称、版本、操作系统、主机名称、IP地址、主机Mac地址、连续运行时间、实例名称、数据库名称、Domain名称、数据库大小、Open模式、SQL语句TOP10CPUTime、SQL语句TOP10DiskReads、OracleSQLTop10BufferGets、SQL语句TOP10BufferGets、磁盘排序次数、内存排序次数、事务回滚数、事务提交数 配置: 表空间个数、数据文件个数、Log模式、高速缓冲池、共享池、大型池、Java 池、日志缓冲池、SGA、PGA、物理内存容量 表空间: l● 表空间状态 l● 表空间增长率、表空间利用率 l● 表空间名称、表空间大小、表空间已用空间 数据文件: l● 数据文件状态 l● 数据文件增长率、数据文件利用率、物理读速率、物理写速率 l● 数据文件名称、数据文件ID、数据文件大小、数据文件已用空间 进程: l● 进程状态 l● Oracle实例名称(进程)、进程名称 文件系统: l● 文件系统利用率 l● 文件系统名称、文件系统已用空间、文件类型 l● 文件系统大小 SQLServer 服务可用性 性能: 系统CPU利用率、SQL Server CPU利用率、系统内存利用率、SQL Server 内存利用率、Optimizer Memory (KB)、缓存命中率、缓冲命中率、高速缓存对象所使用的8(KB)页的数目、高速缓存中高速缓存的对象数、连接时间、当前用户连接数占最大连接数的百分比、当前用户连接数、login/sec、logout/sec、阻塞进程数、每秒导致死锁的锁请求数、每秒事务数、活动事务数、每分语句重新编译的次数、每分收到的 Transact-SQL 命令批数、每分的 SQL 编译数、Page Read Rate、Page Write Rate 信息: 主机名、IP地址、操作系统、物理内存容量、服务器能够使用的动态内存总量(KB)、数据库个数、版本、Max Server Memory (MB)、服务连续运行时间、安装目录、产品名称 数据库: l● 数据库可用性 l● 数据空间使用率、日志空间使用率、每秒事务数、活动事务数 l● 数据库空间、Data File Size、Data Size、Index SizeUnused Space、Unallocated S pace、Log F ile(s) S ize、Unused S ize、Log F ile(s) U sed Size 1.2.3.6 基础资源1.2.3.6.1 系统服务器 CPU、内存、进程、磁盘、网卡信息、TCP等 防火墙 吞吐量、报文转发率、最大并发连接数、每秒新建连接数、转发时延、抖动等 路由器/交换机 CPU、内存、接口状态、流量、带宽占用等 负载均衡设备 CPU、内存、端口响应时间、运行状态、可用性、负载状况等 Windows主机 主机在线可用性 性能: CPU平均利用率、内存利用率、内存错页率、硬盘平均等待队列、硬盘平均磁盘时间、硬盘平均读写速率、分区平均利用率、核心内存利用率、虚拟内存利用率、主机总内存容量、分区总容量、分区总使用容量等 信息: 连续运行时间、主机基本信息、操作系统、MAC地址、系统版本、进程数、线程数、当前在线用户数、虚拟内存总量、虚拟内存已用量等 配置: CPU个数、内存总容量、硬盘个数、硬盘总容量、网卡个数、网卡类型、IP地址、主机名、分区个数、分区总容量等 CPU: l● CPU利用率 l● CPU名称、CPU ID号、CPU型号、CPU频率 硬盘: l● 硬盘等待队列、硬盘磁盘时间、硬盘读写速率 l● 硬盘名称、硬盘ID、硬盘容量 分区: l● 分区总已用容量、分区利用率 l● 分区名称、分区ID号、分区容量 网络接口: l● 管理状态、操作状态 l● 发送利用率、发送的丢包数、发送的错包数、发送速率、接收利用率、接收和发送利用率总和、接收的丢包数、接收的错包数、接收速率、接口带宽 l● 网卡ID号、接口名称、索引、接口类型、接口带宽、MAC地址、IP地址 Linux主机 可用性: 主机在线可用性 性能: CPU平均利用率、CPU平均负载、内存利用率、硬盘平均读写操作速率、硬盘平均读写速率、接收和发送的ICMP包率、Ping时延等 信息: 网络接口个数、主机说明、连续运行时间、主机操作系统等 配置: IP地址、分区总容量、CPU个数、内存总容量、硬盘总容量、硬盘个数等 CPU: l● CPU利用率 l● CPU名称、CPU型号、CPU频率 硬盘: l● 硬盘读速率、硬盘写速率 l● 硬盘名称、硬盘ID、硬盘容量 分区: l● 分区利用率 l● 分区名称、分区容量、分区已用容量、 网络接口: l● 管理状态、操作状态 l● 发送利用率、发送的丢包数、发送的错包数、发送速率、接收利用率、接收的丢包数、接收的错包数、接收速率 l● 索引、接口类型、接口带宽、MAC地址 AIX主机 可用性: 主机在线可用性 性能: CPU平均利用率、CPU平均负载、内存利用率、硬盘平均读写操作速率、硬盘平均读写速率、接收和发送的ICMP包率、CPU用户模式百分比、CPU空闲时间百分比、CPU系统模式百分比、、内存页面调进速率、内存页面调出速率、等待处理队列、内存错页率、Paging Space利用率等 信息: 主机操作系统的OID、主机操作系统、主机操作系统版本、连续运行时、主机说明、系统SP、进程数、僵死进程数、线程数、当前在线用户数、Paging Space总大小、Paging Space已用大小等 CPU个数、内存总容量、硬盘个数、网卡个数、MAC地址、IP地址、主机名、分区个数、分区总容量、硬盘总容量、主机的所有IP地址等 CPU: l● CPU利用率 l● CPU ID号、CPU名称、CPU型号、CPU频率 硬盘: l● 硬盘读速率、硬盘写速率 l● 硬盘名称、硬盘ID、硬盘容量 分区: l● 分区总可用容量、分区利用率 l● 分区名称、分区容量、分区ID、 网络接口: l● 管理状态、操作状态 l● 发送利用率、发送的丢包数、发送的错包数、发送速率、接收利用率、接收和发送利用率总和、接收的丢包数、接收的错包数、接收速率、接口带宽 l● 网卡ID号、接口名称、索引、接口类型、接口带宽、MAC地址、IP地址 路由器 可用性: 网络设备在线可用性 性能: CPU平均利用率、内存利用率、网络设备内存池占用容量、网络设备内存池可用容量、总接收吞吐量、总发送吞吐量、吞吐量、丢包率、接口接收的丢包数、接口发送的丢包数、接收和发送ICMP包率、发送的ICMP包率、接收的ICMP包率 信息: 网络设备的OID、连续运行时间、网络设备说明、交换机下的IP地址、网络设备MAC地址 配置: Config状态、CPU个数、内存总容量、网络接口个数、IP地址、网络设备名称 l● CPU利用率 l● CPU名称、CPU ID号 网络接口: l● 管理状态、操作状态 l● ARP包率、接收的ARP包数、发送的ARP包数、单播包率、接收单播包数、发送单播包数、发送利用率、发送的丢包数、发送的错包数、发送速率、广播包率、接收的广播包数、发送的广播包数、接收利用率、接收和发送利用率总和、接口累计接收和发送的包数、接口累计接收的包数、接口累计发送的包数、接收的丢包数、接收的错包数、接收速率、组播包率、发送组播包数、接收组播包数、接口带宽 l● 网卡ID号、接口名称索引、接口类型、接口带宽、MAC地址 链路: l● 链路可用性 l● 链路名称、链路ID号、所属网络接口、目标IP 交换机 可用性: 网络设备在线可用性 性能: CPU平均利用率、内存利用率、网络设备内存池占用容量、网络设备内存池可用容量、总接收吞吐量、总发送吞吐量、吞吐量、丢包率、接口接收的丢包数、接口发送的丢包数、接收和发送ICMP包率、发送的ICMP包率、接收的ICMP包率 信息: 网络设备的OID、连续运行时间、网络设备说明、交换机下的IP地址、网络设备MAC地址 配置: CPU个数、内存总容量、网络接口个数、IP地址、网络设备名称 CPU: l● CPU利用率 l● CPU名称、CPU ID号 网络接口: l● 管理状态、操作状态 l● ARP包率、接收的ARP包数、发送的ARP包数、单播包率、接收单播包数、发送单播包数、发送利用率、发送的丢包数、发送的错包数、发送速率、广播包率、接收的广播包数、发送的广播包数、接收利用率、接收和发送利用率总和、接口累计接收和发送的包数、接口累计接收的包数、接口累计发送的包数、接收的丢包数、接收的错包数、接收速率、组播包率、发送组播包数、接收组播包数、接口带宽 l● 网卡ID号、接口名称索引、接口类型、接口带宽、MAC地址 链路: l● 链路可用性 l● 链路名称、链路ID号、所属网络接口、目标IP 1.2.3.6.2 硬件服务器 主板、电源、电压、风扇、温度、功率等 机房动力:高压配电、低压配电、UPS、油机、电源、电池组、空调等 机房环动 机房环境:门禁、烟感、温度、湿度、漏水、安防、消防、防雷等 1.3 运维知识管理1.3.1 运维知识及其重要性随着企业IT设备和信息系统的增多,IT运维服务管理显得越来越重要。
it运维服务标准IT运维服务标准。
一、引言。
IT运维服务是指对企业信息技术系统的日常维护、监控和支持。
在当今数字化时代,IT运维服务的质量和效率对企业的正常运转和发展至关重要。
本文档旨在规范和指导IT运维服务的标准,以确保其能够满足企业的需求并保障信息系统的稳定运行。
二、服务范围。
1. 硬件设备维护,包括服务器、网络设备、存储设备等的安装、维护和故障排除。
2. 软件系统维护,包括操作系统、数据库、应用软件等的安装、配置、更新和维护。
3. 网络管理,包括网络拓扑规划、网络设备配置、网络安全管理等。
4. 数据备份和恢复,确保数据的定期备份和可靠的恢复机制。
5. 安全管理,包括防火墙配置、入侵检测、安全审计等安全保障措施。
6. 故障处理,对系统故障进行快速响应和有效处理,最大程度减少系统停机时间。
三、服务标准。
1. 响应时间,对于一般问题,响应时间不得超过2小时;对于紧急问题,响应时间不得超过30分钟。
2. 服务水平协议(SLA),与业务部门协商并制定合理的SLA,确保IT运维服务的质量和效率。
3. 工作流程,建立完善的工作流程,包括故障报告、处理流程、变更管理等,确保服务的规范和可控性。
4. 安全保障,严格执行安全策略,确保系统和数据的安全性和完整性。
5. 文档管理,对系统配置、故障处理、变更记录等进行详细的记录和管理,以便日后审计和追溯。
6. 值班制度,建立健全的值班制度,保障系统在非工作时间的稳定运行和紧急响应能力。
四、服务质量保障。
1. 绩效考核,建立科学的绩效考核机制,对运维人员的工作质量和效率进行评估。
2. 培训和提升,定期组织培训和技术交流,提升运维人员的专业水平和服务意识。
3. 持续改进,定期进行服务质量评估和客户满意度调查,及时发现问题并改进服务质量。
五、结语。
IT运维服务是企业信息化建设的重要保障,本文档所规定的标准和要求旨在确保IT运维服务能够满足企业的需求,保障信息系统的稳定运行,提高企业的运行效率和竞争力。
引言概述:IT运维服务是一种为企业提供全面的信息技术服务的方式。
它涉及到硬件、软件及网络设备的安装、配置、维护和优化等方面。
本文将介绍一个完整的IT运维服务方案,包括人员管理、设备管理、网络管理、安全管理和绩效评估等五个大点,每个大点分别阐述了相关的小点。
通过本方案的实施,企业可以确保其IT系统的高效运作,提高员工的工作效率,并保障系统的安全性和稳定性。
正文内容:1.人员管理:设立专门的IT运维团队,包括管理员、网络工程师、系统工程师等。
建立人员绩效考核体系,根据岗位职责制定明确的工作目标和指标。
提供培训和学习机会,以保证员工的专业知识不断更新和提升。
建立有效的沟通渠道,促进团队之间的合作和协调。
2.设备管理:建立设备清单,包括服务器、网络设备、存储设备等,并进行统一的资产管理。
制定设备维护计划,定期检查设备的健康状态,并进行必要的修复和升级。
关注设备性能监控,及时发现并解决设备故障或性能下降的问题。
确保设备备份和恢复机制的可靠性,以防止数据丢失和系统故障。
3.网络管理:建立网络拓扑图,并进行网络设备的规划和优化。
实施网络性能监控,及时发现网络故障和性能瓶颈。
配置网络安全策略,包括防火墙、入侵检测系统等,保障网络的安全性。
定期更新和升级网络设备的固件,提升网络的稳定性和安全性。
4.安全管理:制定安全策略和规范,包括密码策略、访问控制策略等。
定期对系统进行漏洞扫描和安全漏洞修复。
实施网络流量监控和日志审计,及时发现和应对安全事件。
进行定期的安全演练和培训,提高员工的安全意识和应急反应能力。
5.绩效评估:设定绩效评估指标,包括故障处理时长、系统可用性等。
定期进行绩效评估,对团队和个人的工作进行评价和奖励。
建立客户满意度调查机制,了解用户对IT运维服务的评价和需求。
根据评估结果不断改进和优化IT运维服务。
总结:。
it运维管理服务方案一、服务内容1.1 服务目标运行维护服务包括,信息系统相关的主机设备、操作系统、数据库和存储设备及其他信息系统的运行维护与安全防范服务,保证用户现有的信息系统的正常运行,降低整体管理成本,提高网络信息系统的整体服务水平。
同时根据日常维护的数据和记录,提供用户信息系统的整体建设规划和建议,更好的为用户的信息化发展提供有力的保障。
用户信息系统的组成主要可分为两类:硬件设备和软件系统。
硬件设备包括网络设备、安全设备、主机设备、存储设备等;软件设备可分为操作系统软件、典型应用软件(如:数据库软件、中间件软件等)、业务应用软件等。
通过运行维护服务的有效管理来提升用户信息系统的服务效率,协调各业务应用系统的内部运作,改善网络信息系统部门与业务部门的沟通,提高服务质量。
结合用户现有的环境、组织结构、IT资源和管理流程的特点,从流程、人员和技术三方面来规划用户的网络信息系统的结构。
将用户的运行目标、业务需求与IT服务的相协调一致。
信息系统服务的目标是,对用户现有的信息系统基础资源进行监控和管理,及时掌握网络信息系统资源现状和配置信息,反映信息系统资源的可用性情况和健康状况,创建一个可知可控的IT环境,从而保证用户信息系统的各类业务应用系统的可靠、高效、持续、安全运行。
服务项目范围覆盖的信息系统资源以下方面的关键状态及参数指标:运行状态、故障情况配置信息可用性情况及健康状况性能指标统计运维数椐、提供信息系统管理和工作报告、归纳总结并提供用户想了解的数椐报告1.2 信息资产统计服务此项服务为基本服务,包含在运行维护服务中,帮助我们对用户现有的信息资产情况进行了解,更好的提供系统的运行维护服务。
服务内容包括:硬件设备型号、数量、版本等信息统计记录软件产品型号、版本和补丁等信息统计记录网络结构、网络路由、网络IP地址统计记录综合布线系统结构图的绘制其它附属设备的统计记录硬件设备清单统计1.3 网络、安全系统运维服务从网络的连通性、网络的性能、网络的监控管理三个方面实现对网络系统的运维管理。
it运维管理体系指标的标准
IT运维管理体系的指标标准可以根据具体的目标和需求来确定,但一般包括以下几个方面的指标:
1. 故障率:衡量系统的稳定性和可靠性,通常用每单位时间内发生的故障数量来表示。
2. 平均修复时间(MTTR):指系统从故障发生到修复完成所需的平均时间。
3. 可用性:衡量系统的可用程度,通常用系统正常运行时间与总运行时间的比值来表示。
4. 响应时间:指系统对用户请求的响应速度,通常以毫秒或秒为单位。
5. 系统容量:指系统能够处理的工作量或负载,通常以并发用户数、吞吐量或处理能力来表示。
6. 变更管理:衡量变更管理过程的有效性和规范性,包括变更申请的及时性、变更记录的完整性等指标。
7. 服务水平协议(SLA)达标率:衡量运维团队能否按照SLA中规定的要求提供服务,包括故障响应时间、故障处理时间等指标。
8. 安全性指标:包括系统的漏洞数量、漏洞修复时间、安全事件的发生频率等。
9. 成本指标:包括IT运维的人力成本、设备成本、软件成本等。
这些指标可以根据实际情况进行具体细化和补充,以满足组织的具体需求和目标。
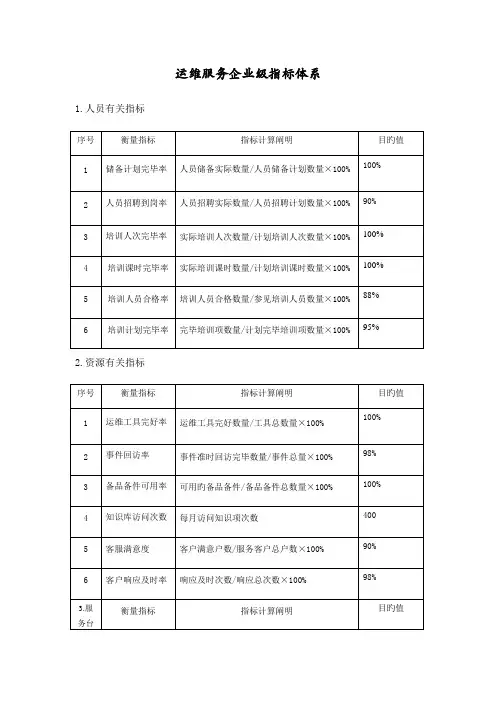
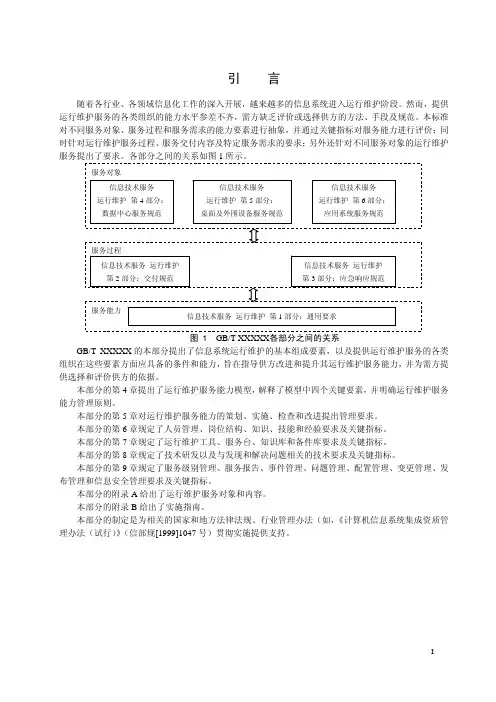
企业IT运维服务指标体系目录1概述 (1)2术语和定义 (1)3指标体系表 (2)4指标模板 (4)5附则 (4)附录A 指标要求及计算公式 (5)I公司IT运维服务指标体系1概述1.1编制目的为推动公司IT运维服务的“一体化、规范化”管理,实现管控模式的转变,确保公司IT战略目标落地,构建科学统一的IT运维指标体系,特制定本指标体系。
1.2适用范围本指标体系适用于公司总部、各分子公司以及各分子公司下属单位。
1.3编制原则IT运维服务指标体系应当涵盖促进企业IT运维服务成功的关键因素,并进行定量的测量与分析。
1.4规范性引用文件下列文件中的条款通过本部分的引用而成为本部分的条款。
凡是注日期的引用文件,其随后所有的修改单(不包括勘误的内容)或修订版均不适用于本部分,凡是不注日期的引用文件,其最新版本适用于本部分。
Q/CSG11801.2-2008 公司信息分类和编码第2分册:公共信息分类和编码GB/T24405.1信息技术服务管理第1部分:规范GB/T24405.2信息技术服务管理第2部分:实践规则GB/T16680-1996 软件文档管理指南2术语和定义2.1指标是指对特定对象的目标进行衡量的单位和方法。
2.2KPI全称为关键绩效指标,是指为了衡量特定对象的关键成功因素而设定的衡量单位和方法。
2.3决策层本文所指的决策层是指对IT运维、服务战略进行决策的群体。
2.4管理层本文所指的管理层是指对日常IT运维、服务进行管理并提出决策建议的群体。
2.5执行层本文所指的执行层是指日常IT运维、服务过程中执行具体运维或服务任务的群体。
2.6周期指对指标进行分析的间隔时间,周期分七种:日、周、月、季度、半年、年、投运至今。
MTBF 计算周期默认为自投运累计至今,其他指标计算周期默认为月。
2.7权重指该指标在同类指标中的比重。
3指标体系表3.1运行指标3.2服务指标4指标模板5附则5.1本指标体系由公司信息部负责解释。
5.2本指标体系自2012年1月1日起执行。
附录A 指标要求及计算公式A.1 运行指标A.1.1 网络安全运行状况A.1.1.1 关键网络安全设备MTBFA.1.1.1.1 关键路由器MTBFA.1.1.1.1.1 单台路由器指标注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.1.2 关键交换机MTBFA.1.1.1.2.1 单台交换机MTBF注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.1.3 关键负载均衡设备MTBFA.1.1.1.3.1 单台负载均衡设备MTBF注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.1.4 关键防火墙MTBFA.1.1.1.4.1 单台防火墙MTBF注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.1.5 关键IPS/IDS MTBFA.1.1.1.5.1 单台IPS/IDS MTBF注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.2 关键网络安全设备平均可用率A.1.1.2.1 关键路由器可用率A.1.1.2.1.1 单台路由器可用率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.2.2 关键交换机可用率A.1.1.2.2.1 单台交换机可用率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.2.3 关键负载均衡设备可用率A.1.1.2.3.1 单台负载均衡设备可用率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.2.4 关键防火墙可用率A.1.1.2.4.1 单台防火墙可用率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.2.5 关键IPS/IDS 可用率A.1.1.2.5.1 单台IPS/IDS可用率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.3 关键网络安全设备平均运行率A.1.1.3.1 关键路由器运行率A.1.1.3.1.1 单台路由器运行率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.3.2 关键交换机运行率A.1.1.3.2.1 单台交换机运行率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.3.3 关键负载均衡设备运行率A.1.1.3.3.1 单台负载均衡设备运行率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.3.4 关键防火墙运行率A.1.1.3.4.1 单台防火墙运行率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.3.5 关键IPS/IDS 运行率A.1.1.3.5.1 单台IPS/IDS运行率注:中断时长通过累加计算,同一采集周期内发生下列一种或多种情况,中断时长累加一次采集周期。
1) SNMP协议采集设备的当前正常运行时间(UPTIME)值小于上一次采集值;2) SNMP/SSH采集设备引擎/模块状态异常;3) 通过Ping测试,Ping超时或失败。
A.1.1.4 信息网络设备平均可用率A.1.1.4.1 局域网核心层网络设备可用率A.1.1.4.2 局域网汇聚层网络设备可用率A.1.1.4.3 综合数据网互联网络设备可用率A.1.1.4.4 互联网出口网络设备可用率A.1.1.5 信息网络设备平均运行率A.1.1.5.1 局域网核心层网络设备运行率A.1.1.5.2 局域网汇聚层网络设备运行率A.1.1.5.3 综合数据网互联网络设备运行率A.1.1.5.4 互联网出口网络设备运行率A.1.1.6 信息网络可用率A.1.1.7 信息网络运行率A.1.1.8 网络安全事件告警数A.1.1.8.1 状态类安全事件累计数A.1.1.8.2 网络攻击类安全事件累计数A.1.1.8.3 用户行为类安全事件累计数A.1.1.8.4 有害程序类安全事件累计数A.1.1.8.5 其他类安全事件累计数A.1.2 应用系统运行状况A.1.2.1 关键应用系统MTBFA.1.2.1.1 单个应用系统的MTBF注:1) 中断时长通过累加计算,故障通过用户模拟体验(如访问首页)探测,若响应时间超过阈值,中断时长累加一次采集周期。
A.1.2.2 关键应用系统平均可用率A.1.2.2.1 综合管理信息系统可用率注:1) 中断时长通过累加计算,故障通过用户模拟体验(如访问首页)探测,若响应时间超过阈值,中断时长累加一次采集周期。
A.1.2.2.2 营销管理信息系统可用率。