Druid之旅-大数据实时分析数据存储框架
- 格式:pdf
- 大小:4.65 MB
- 文档页数:42


druid 连接池原理Druid连接池原理Druid是一种高性能的开源连接池,用于管理数据库连接的资源。
它是阿里巴巴开源的项目,被广泛应用于Java开发中。
本文将介绍Druid连接池的原理和工作机制。
1. 连接池的基本概念连接池是一种用于管理数据库连接的技术,通过预先创建一定数量的数据库连接并将其保存在连接池中,应用程序可以从连接池中获取连接、使用连接、释放连接,从而提高数据库访问的效率和性能。
2. Druid连接池的特点Druid连接池相比其他连接池,具有以下几个特点:- 高性能:Druid连接池采用了一系列优化措施,如使用高效的数据结构、多线程并发访问等,使得连接的获取和释放效率更高。
- 安全可靠:Druid连接池内置了多项安全特性,如防止SQL注入、防火墙等,增强了应用程序对数据库的保护。
- 监控功能:Druid连接池提供了强大的监控功能,可以实时统计连接的使用情况、执行的SQL语句、慢查询等,方便开发人员进行性能分析和优化。
- 扩展性强:Druid连接池支持自定义扩展,可以根据具体需求对连接池进行定制化的配置和功能扩展。
Druid连接池的工作原理可以简单分为以下几个步骤:3.1 初始化连接池应用程序启动时,Druid连接池会根据配置参数初始化一定数量的数据库连接对象,并将这些连接对象保存在连接池中。
3.2 连接获取和分配当应用程序需要与数据库进行交互时,会从连接池中获取一个可用的连接。
Druid连接池采用了一种高效的算法来管理连接的分配和归还,保证连接的均衡分配和高效利用。
3.3 连接的使用应用程序通过获取到的连接对象,执行SQL语句或事务操作,并处理数据库返回的结果。
3.4 连接的释放应用程序在使用完连接后,需要将连接释放回连接池。
这样其他应用程序就可以继续使用该连接,而无需重新创建新的连接,提高了连接的复用率。
3.5 连接的销毁当连接池中的连接长时间没有被使用,或者连接出现异常情况时,连接池会对连接进行销毁,保证连接池中的连接始终是可用状态。

Druid(准)实时分析统计数据库——列存储+⾼效压缩Druid是⼀个开源的、分布式的、列存储系统,特别适⽤于⼤数据上的(准)实时分析统计。
且具有较好的稳定性(Highly Available)。
其相对⽐较轻量级,⽂档⾮常完善,也⽐较容易上⼿。
Druid vs 其他系统Druid vs Impala/SharkDruid和Impala、Shark 的⽐较基本上可以归结为需要设计什么样的系统Druid被设计⽤于:1. ⼀直在线的服务2. 获取实时数据3. 处理slice-n-dice式的即时查询查询速度不同:Druid是列存储⽅式,数据经过压缩加⼊到索引结构中,压缩增加了RAM中的数据存储能⼒,能够使RAM适应更多的数据快速存取。
索引结构意味着,当添加过滤器来查询,Druid少做⼀些处理,将会查询的更快。
Impala/Shark可以认为是HDFS之上的后台程序缓存层。
但是他们没有超越缓存功能,真正的提⾼查询速度。
数据的获取不同:Druid可以获取实时数据。
Impala/Shark是基于HDFS或者其他后备存储,限制了数据获取的速度。
查询的形式不同:Druid⽀持时间序列和groupby样式的查询,但不⽀持join。
Impala/Shark⽀持SQL样式的查询。
Druid vs ElasticsearchElasticsearch(ES) 是基于Apache Lucene的搜索服务器。
它提供了全⽂搜索的模式,并提供了访问原始事件级数据。
Elasticsearch还提供了分析和汇总⽀持。
根据研究,ES在数据获取和聚集⽤的资源⽐在Druid⾼。
Druid侧重于OLAP⼯作流程。
Druid是⾼性能(快速聚集和获取)以较低的成本进⾏了优化,并⽀持⼴泛的分析操作。
Druid提供了结构化的事件数据的⼀些基本的搜索⽀持。
Segment: Druid中有个重要的数据单位叫segment,其是Druid通过bitmap indexing从raw data⽣成的(batch or realtime)。

Druid是一种Java语言编写的高效、可扩展的数据库连接池。
以下是Druid 数据库连接池的一些基本使用步骤。
请注意,这只是一个简要的介绍,更详细和具体的配置和使用细节需要根据你的具体项目和需求进行调整。
### 1. 引入Druid依赖在你的项目中引入Druid的依赖,可以通过Maven、Gradle等构建工具实现。
Maven:<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.6</version></dependency>### 2. 配置数据源在项目的配置文件中配置Druid数据源,通常是在`application.properties` 或`application.yml` 文件中添加以下配置:spring:datasource:url: jdbc:mysql://localhost:3306/your_databaseusername: your_usernamepassword: your_passworddriver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource# Druid配置druid:initial-size: 5min-idle: 5max-active: 20max-wait: 60000time-between-eviction-runs-millis: 60000validation-query: SELECT 1 FROM DUALtest-while-idle: truetest-on-borrow: falsetest-on-return: falsepool-prepared-statements: truemax-pool-prepared-statement-per-connection-size: 20filters: stat,wall,log4jconnection-properties:druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500这是一个基本的Druid数据源配置,其中包括了连接池的一些基本参数。
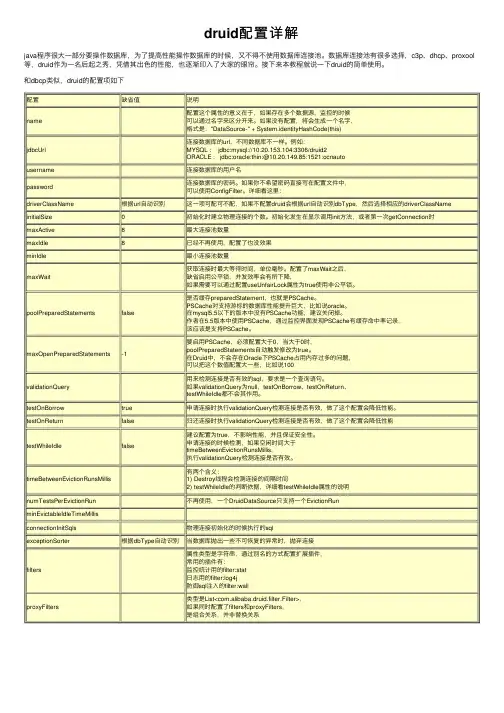
配置缺省值说明name 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。
如果没有配置,将会⽣成⼀个名字,格式是:"DataSource-" + System.identityHashCode(this)jdbcUrl 连接数据库的url,不同数据库不⼀样。
例如:MYSQL : jdbc:mysql://10.20.153.104:3306/druid2 ORACLE : jdbc:oracle:thin:@10.20.149.85:1521:ocnautousername连接数据库的⽤户名password连接数据库的密码。
如果你不希望密码直接写在配置⽂件中,可以使⽤ConfigFilter。
详细看这⾥:driverClassName根据url⾃动识别这⼀项可配可不配,如果不配置druid会根据url⾃动识别dbType,然后选择相应的driverClassName initialSize0初始化时建⽴物理连接的个数。
初始化发⽣在显⽰调⽤init⽅法,或者第⼀次getConnection时maxActive8最⼤连接池数量maxIdle8已经不再使⽤,配置了也没效果minIdle最⼩连接池数量maxWait 获取连接时最⼤等待时间,单位毫秒。
配置了maxWait之后,缺省启⽤公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使⽤⾮公平锁。
poolPreparedStatements false 是否缓存preparedStatement,也就是PSCache。
PSCache对⽀持游标的数据库性能提升巨⼤,⽐如说oracle。
在mysql5.5以下的版本中没有PSCache功能,建议关闭掉。
作者在5.5版本中使⽤PSCache,通过监控界⾯发现PSCache有缓存命中率记录,该应该是⽀持PSCache。
maxOpenPreparedStatements-1要启⽤PSCache,必须配置⼤于0,当⼤于0时,poolPreparedStatements⾃动触发修改为true。


druid数据库连接池工作原理Druid数据库连接池工作原理在当今的软件开发中,数据库连接池扮演着至关重要的角色。
它们可以有效地管理数据库连接,提高应用程序的性能和响应速度。
而Druid数据库连接池作为一种优秀的数据库连接池实现,其工作原理更是备受关注。
让我们来了解一下Druid数据库连接池的基本结构。
Druid数据库连接池由几个主要组件组成,包括连接池管理器、连接对象、连接池监控和连接池状态等。
其中,连接池管理器负责管理连接对象的创建、分配和释放,连接对象则表示与数据库的实际连接。
连接池监控用于监控连接池的状态和性能指标,以便及时调整连接池的配置参数。
Druid数据库连接池的工作原理可以概括为以下几个步骤:1. 初始化连接池:在应用程序启动时,Druid连接池会根据配置参数初始化一定数量的数据库连接,并将它们存放在连接池中。
2. 请求连接:当应用程序需要与数据库交互时,它会向连接池请求一个数据库连接。
连接池会从连接池中选择一个空闲的连接对象分配给应用程序,并将其标记为“繁忙”。
3. 数据库操作:应用程序使用连接对象进行数据库操作,如查询、更新等。
一旦操作完成,应用程序需要及时释放连接对象,以便连接池可以重新利用该连接。
4. 连接归还:当应用程序释放连接对象时,连接池会将该连接对象重新标记为“空闲”,并使其可供其他应用程序使用。
5. 连接监控:Druid连接池会定期检查连接对象的状态,包括连接是否超时、是否空闲等。
如果发现异常连接,连接池会及时进行回收或重新创建,以确保连接池的稳定运行。
总的来说,Druid数据库连接池通过有效地管理数据库连接对象,实现了连接的复用和性能的优化。
它可以根据应用程序的需求动态调整连接池的大小,提高数据库访问效率,并且通过连接池监控功能,能够及时发现和处理连接池中的问题,确保应用程序的稳定运行。
在实际应用中,合理配置Druid数据库连接池的参数是非常重要的。
通过调整连接池的最大连接数、最小空闲连接数、连接超时时间等参数,可以有效地提高数据库访问性能,避免连接泄漏和性能瓶颈。



每周一本书之《Druid实时大数据分析原理与实践》:来自腾讯、小米等公司的一线实践经验数据猿导读《Druid实时大数据分析原理与实践》旨在帮助技术人员更好地深入理解Druid 技术、大数据分析技术选型、Druid 的安装和使用、高级特性的使用,也包括一些源代码的解析,以及一些常见问题的快速回答。
作者 | abby随着社交通信、数字广告、电子商务、网络游戏等商业模式的发展,越来越多的互联网企业诞生。
他们都享受了大数据基础技术的红利,从初始就具备比较强大的数据收集、分析和处理能力,并且可以用在业务优化上。
很显然,因为行业的多样性,业务场景变得越来越复杂,对数据处理的要求已经不仅是体量大和速度快,还要数据结构灵活、编程接口强大、系统可扩展、原子化操作、高效备份、读性能加速或者写性能加速等。
在这个技术普及的时代,不仅互联网行业有越来越多的技术人员和数据人员开始参与到大数据工作中,而且很多传统软件从业者也慢慢受到吸引,双方互相借鉴,进一步扩大了大数据技术的能力和影响。
可以看到,传统的数据库、操作系统、编程语言等技术思想被引入来解决各种复杂的需求。
因此而诞生的包括NoSQL、SQL on Hadoop、ElasticSearch这样的新事物,逐渐把我们推进到一个全新的时代。
而Druid 作为一款开源的实时大数据分析软件,最近几年快速风靡全球互联网公司,特别是对于海量数据和实时性要求高的场景,包括广告数据分析、用户行为分析、数据统计分析、运维监控分析等,在腾讯、阿里、优酷、小米等公司都有大量成功应用的案例。
今天小编为大家推荐的《Druid实时大数据分析原理与实践》就是旨在帮助技术人员更好地深入理解Druid 技术、大数据分析技术选型、Druid 的安装和使用、高级特性的使用,也包括一些源代码的解析,以及一些常见问题的快速回答。
Druid是一个支持在大型数据集上进行实时查询而设计的开源数据分析和存储系统,提供了低成本、高性能、高可靠性的解决方案,整个系统支持水平扩展,管理方便。
JDBC与Druid简单介绍及Druid与MyBatis连接数据库序⾔java程序与数据建⽴连接,⾸先要从jdbc说起,然后直接上阿⾥认为宇宙最好的数据库连接池druid,然后再说上层程序对象与数据源映射关联关系的orm-mybatis。
JDBC介绍JDBC(Java DataBase Connectivity)是Java和数据库(关系型数据库)之间的⼀个桥梁。
1. 是⼀个规范⽽不是⼀个实现,能够执⾏SQL语句。
2. 它由⼀组⽤Java语⾔编写的类和接⼝组成,各种不同类型的数据库都有相应的实现。
3. 它不属于某⼀个数据库的接⼝,⽽是可以⽤于定义程序与数据库连接规范,通过⼀整套接⼝,由各个不同的数据库⼚商去完成所对应的实现类,由sun公司提出!执⾏sql过程为:类加载-->获取连接-->书写SQL-->执⾏语句--->处理结果集。
为什么会有连接池的存在?因为建⽴数据库连接是⼀个⾮常耗时、耗资源的⾏为,所以通过连接池预先同数据库建⽴⼀些连接,放在内存中,应⽤程序需要建⽴数据库连接时直接到连接池中申请⼀个就⾏,⽤完后再放回去,极⼤的提⾼了数据库连接的性能问题,节省了资源和时间。
什么是数据源JDBC2.0 提供了javax.sql.DataSource接⼝,它负责建⽴与数据库的连接,当在应⽤程序中访问数据库时不必编写连接数据库的代码,直接引⽤DataSource获取数据库的连接对象即可。
⽤于获取操作数据Connection对象。
数据源与数据库连接池组件数据源建⽴多个数据库连接,这些数据库连接会保存在数据库连接池中,当需要访问数据库时,只需要从数据库连接池中获取空闲的数据库连接,当程序访问数据库结束时,数据库连接会放回数据库连接池中。
常⽤的数据库连接池技术:这些连接技术都是在jdbc的规范之上建⽴完成的。
有如下:C3P0、DBCP、Proxool和DruidXDruid简介及简单使⽤实例官⽅⽹站⽂档:Druid连接池是阿⾥巴巴开源的数据库连接池项⽬。
druid实时索引Druid底层不保存原始数据,而是借鉴了Apache Lucene、Apache Solr以及ElasticSearch等检索引擎的基本做法,对数据按列建立索引,最终转化为Segment,用于存储、查询与分析。
首先,无论是实时数据还是批量数据在进入Druid前都需要经过Indexing Service这个过程。
在Indexing Service阶段,Druid主要做三件事:第一,将每条记录转换为列式(columnar format);第二,为每列数据建立位图索引;第三,使用不同的压缩算法进行压缩,其中默认使用LZ4,对于字符类型列采用字典编码(Dictionary encoding)进行压缩,对于位图索引采用Concise/Roaring bitmap进行编码压缩。
最终的输出结果也就是Segment。
下面,我们先讲解Druid的索引过程中的几个基本概念,再介绍实时索引的基本原理,最后结合我们在生产环境中使用过的两种索引模式加深对原理的理解。
1 Segment粒度与时间窗口Segment粒度(SegmentGranularity)表示每一个实时索引任务中产生的Segment所涵盖的时间范围。
比如设置{”SegmentGranularity” : “HOUR”},表示每个Segment任务周期为1小时。
时间窗口(WindowPeriod)表示当前实时任务的时间跨度,对于落在时间窗口内的数据,Druid会将其“加工”成Segment,而任何早于或者晚于该时间窗口的数据都会被丢弃。
Segment粒度与时间窗口都是DruidReal-Time中重要的概念与配置项,因为它们既影响每个索引任务的存活时间,又影响数据停留在Real-TimeNode上的时长。
所以,每个索引任务“加工”Segment的最长周期 =SegmentGranularity+WindowPeriod,在实际使用中,官方建议WindowPeriod<= SegmentGranularity,以避免创建大量的实时索引任务。
druid中聚合的最小粒度Druid中聚合的最小粒度简介•Druid是一款开源的大数据实时分析数据库•聚合是Druid中非常重要的功能,用于计算和统计数据•聚合的最小粒度影响数据计算的准确性和性能最小粒度的定义•最小粒度指数据在聚合过程中可被聚合的最小单元•在Druid中,最小粒度可理解为数据分片的最小单元确定最小粒度的因素1.数据源–数据源的粒度决定了最小粒度的选择–如果数据源的粒度较细,可以选择更小的最小粒度–如果数据源的粒度较粗,选择较大的最小粒度可以提高计算性能2.数据模型–数据模型的设计也会影响最小粒度的选择–如果数据模型较复杂,可能需要将数据聚合到更细粒度的最小粒度–如果数据模型较简单,可以选择较粗粒度的最小粒度3.查询需求–查询需求直接影响了最小粒度的选择–如果查询需要对较细粒度的数据进行计算和统计,需要选择更小的最小粒度–如果查询只需要对较粗粒度的数据进行计算和统计,可以选择较大的最小粒度最小粒度的影响•最小粒度的选择直接影响数据计算的准确性和性能•较小的最小粒度可以提高数据计算的准确性,但也增加了计算的复杂性和计算资源的消耗•较大的最小粒度可以提高计算性能,但可能导致数据计算的精度降低如何选择最小粒度1.确定数据源和数据模型2.分析查询需求,确定计算精度的要求3.根据数据源、数据模型和计算需求综合考虑,选择合适的最小粒度4.可以进行性能测试和调优,以确定最佳的最小粒度总结•Druid中聚合的最小粒度是非常重要的,直接影响数据计算的准确性和性能•最小粒度的选择需要考虑数据源、数据模型和查询需求等因素•多方面综合考虑,选择合适的最小粒度可以提高数据计算的准确性和性能。
最小粒度的选择与数据源•不同的数据源可能具有不同的数据粒度,这可能会影响最小粒度的选择。
•如果数据源的粒度很细,例如每秒生成的大量数据,那么选择较小的最小粒度可以更精确地分析和统计数据。
•如果数据源的粒度较粗,例如每天或每月生成的数据,那么选择较大的最小粒度可以节省计算资源并提高计算性能。
01实时数仓建设:实时数仓1.0传统意义上我们通常将数据处理分为离线数据处理和实时数据处理。
对于实时处理场景,我们一般又可以分为两类,一类诸如监控报警类、大屏展示类场景要求秒级甚至毫秒级;另一类诸如大部分实时报表的需求通常没有非常高的时效性要求,一般分钟级别,比如10分钟甚至30分钟以内都可以接受。
对于第一类实时数据场景来说,业界通常的做法比较简单粗暴,一般也不需要非常仔细地进行数据分层,数据直接通过Flink计算或者聚合之后将结果写入MySQL/ES/HBASE/Druid/Kudu等,直接提供应用查询或者多维分析。
如下图所示:实时数据场景而对于后者来说,通常做法会按照数仓结构进行设计,我们称后者这种应用场景为实时数仓,将作为本篇文章讨论的重点。
从业界情况来看,当前主流的实时数仓架构基本都是基于Kafka+Flink的架构(为了行文方便,就称为实时数仓1.0)。
下图是基于业界各大公司分享的实时数仓架构抽象的一个方案:实时数仓架构方案图这套架构总体依然遵循标准的数仓分层结构,各种数据首先汇聚于ODS数据接入层。
再接着经过这些来源明细数据的数据清洗、过滤等操作,完成多来源同类明细数据的融合,形成面向业务主题的DWD数据明细层。
在此基础上进行轻度的汇总操作,形成一定程度上方便查询的DWS轻度汇总层(注:这里没有画出DIM维度层,一般选型为Redis/HBase,下文架构图中同样没有画出DIM维度层,在此说明)。
最后再面向业务需求,在DWS层基础上进一步对数据进行组织进入ADS数据应用层,业务在数据应用层的基础上支持用户画像、用户报表等业务场景。
基于Kafka+Flink的这套架构方案很好的解决了实时数仓对于时效性的业务诉求,通常延迟可以做到秒级甚至更短。
基于上图所示实时数仓架构方案,笔者整理了一个目前业界比较主流的整体数仓架构方案:整体数仓架构图上图中上层链路是离线数仓数据流转链路,下层链路是实时数仓数据流转链路,当然实际情况可能是很多公司在实时数仓建设中并没有严格按照数仓分层结构进行分层,与上图稍有不同。
druid 解析查询语句Druid是一款高性能的实时分析数据库,主要用于大规模数据的实时查询和分析。
它具有快速的数据摄取速度、高效的查询性能和灵活的数据模型,被广泛应用于日志分析、业务指标监控和实时报表等领域。
本文将以Druid解析查询语句为题,介绍其常用的查询语法和功能,帮助读者更好地理解和使用Druid。
一、Druid查询语句概述Druid的查询语句主要包括选择器(Select)、过滤器(Filter)、聚合器(Aggregator)和分组(Group by)等关键字。
通过组合这些关键字,可以实现丰富多样的查询操作。
下面将介绍Druid查询语句的常用用法和示例。
1. 查询所有数据SELECT * FROM 表名2. 查询指定字段的数据SELECT 字段1, 字段2 FROM 表名3. 查询满足条件的数据SELECT * FROM 表名 WHERE 条件表达式4. 查询指定时间范围内的数据SELECT * FROM 表名 WHERE 时间字段 >= 开始时间 AND 时间字段<= 结束时间5. 查询并排序数据SELECT * FROM 表名 ORDER BY 字段1 ASC, 字段2 DESC6. 查询数据并分页SELECT * FROM 表名 LIMIT 开始位置, 查询数量7. 查询数据并进行聚合操作SELECT 聚合函数(字段) FROM 表名8. 查询数据并进行分组操作SELECT 聚合函数(字段) FROM 表名 GROUP BY 字段9. 查询数据并进行多字段分组操作SELECT 聚合函数(字段) FROM 表名 GROUP BY 字段1, 字段210. 查询数据并进行多字段分组和聚合操作SELECT 聚合函数(字段) FROM 表名 WHERE 条件表达式 GROUP BY 字段1, 字段2二、Druid查询语句示例下面将通过一些示例来进一步说明Druid查询语句的使用。
Druid的initialSize默认值1. 什么是DruidDruid是一个开源的分布式实时分析(OLAP)数据库,专为大规模数据集的快速查询和高吞吐量而设计。
它由Yahoo开发并于2012年开源。
Druid被广泛应用于实时分析、大数据探索和可视化等领域,其核心特点是高性能、低延迟和可扩展性。
2. Druid的initialSize参数Druid的initialSize是Druid连接池的一个配置参数,用于指定连接池在初始化时创建的连接数量。
连接池是一种用于管理数据库连接的技术,通过连接池可以提高数据库的访问效率和性能。
在Druid中,连接池是通过DruidDataSource来实现的,而initialSize参数则用于配置连接池的初始大小。
连接池的初始大小表示在连接池创建时,需要同时创建多少个数据库连接。
默认情况下,Druid的initialSize参数的默认值为0。
3. initialSize参数的作用initialSize参数的作用是在应用程序启动时,预先创建一定数量的数据库连接,以避免在高并发场景下频繁地创建和销毁数据库连接,从而提高数据库的访问效率。
通常情况下,数据库连接的创建和销毁是一个相对耗时的操作,频繁地创建和销毁连接会导致额外的性能开销。
通过配置initialSize参数,可以在应用程序启动时预先创建一定数量的连接,这些连接会被放入连接池中,当应用程序需要访问数据库时,可以直接从连接池中获取连接,而无需再次创建连接,从而减少了创建连接的时间开销。
4. initialSize参数的配置在Druid中,可以通过在配置文件中设置initialSize参数的值来进行配置。
下面是一个示例的Druid配置文件(druid.properties)中的initialSize参数的配置:# Druid连接池配置druid.initialSize=10在上述示例中,initialSize参数被设置为10,表示在应用程序启动时,连接池会预先创建10个数据库连接。
druid解析查询字段-回复Druid是一种快速实时数据查询和分析引擎,拥有自己的查询语言Druid SQL。
在Druid中,我们可以使用Druid SQL的解析查询字段功能,对查询结果进行更准确的分析和统计。
本文将一步一步地回答关于Druid解析查询字段的问题,并详细介绍相关概念和操作。
第一步:什么是解析查询字段?在Druid中,解析查询字段是指对查询结果进行特定字段的解析和处理。
Druid SQL提供了一系列函数和操作,使得用户可以对查询字段进行格式化、聚合、过滤等操作,以便更好地理解数据和满足特定的数据需求。
第二步:如何使用解析查询字段?使用解析查询字段可以通过在查询语句中使用Druid SQL的解析函数来实现。
下面是一些常用的解析函数:1. TO_TIMESTAMP:将日期字符串转换为Timestamp类型。
例如,TO_TIMESTAMP('2022-01-01', 'yyyy-MM-dd')将字符串'2022-01-01'转换为Timestamp类型。
2. EXTRACT:从日期或时间字段中提取特定部分,比如年、月、日、小时、分钟等。
例如,EXTRACT(DAY FROM timestamp_column)将从时间戳字段中提取出日期的天数。
3. FORMAT:格式化日期或数字字段。
例如,FORMAT(timestamp_column, 'yyyy-MM-dd')将格式化时间戳字段为'2022-01-01'的形式。
4. CASE WHEN:根据条件对字段进行分组、筛选或计算。
例如,CASE WHEN column1 > column2 THEN 'Bigger' ELSE 'Smaller' END将根据column1和column2的值返回不同的结果。
这些函数可以与SELECT语句中的其他操作和条件一起使用,实现对查询结果的解析和处理。
THE JOURNEY OF DRUID,A BIG DATA ANALYTICS DATA STOREERIC TSCHETTER,CREATOR OF DRUIDDEMO“”REQUIREMENTSREQUIREMENTS•Data Ingestion Rate•Ingest data and make it queryable in real-time •Arbitrary Drill-Downs, Slice-n-Dice •Arbitrary boolean filters•Availability•Downtime is evil“”WHAT WE TRIEDWHAT WE TRIED I. RDBMS - Relational DatabaseI. RDBMS - THE SETUP •Star Schema•Aggregate Tables•Query CachingI. RDBMS - THE RESULTS •Queries that were cached•fast•Queries against aggregate tables •fast to acceptable•Queries against base fact table •generally unacceptableI. RDBMS - PERFORMANCESelect COUNT(*) scan rate~5.5M rows / second / core 1 day of summarized aggregates60M+ rows1 query over 1 week, 16 cores~5 secondsPage load with 20 queries over a weeklong timeof dataI. RDBMS - Relational DatabaseI. RDBMS - Relational Database II. NoSQL - Key/Value Store•Pre-aggregate all dimensional combinations (truncate time) •Store results in a NoSQL store II. NOSQL - THE SETUP ts !gender agerevenue 1M 18$0.151F25$1.032F 18$0.01Key Value 1revenue=$1.191,M revenue=$0.151,F revenue=$1.041,18revenue=$0.161,25revenue=$1.031,M,18revenue=$0.151,F ,18revenue=$0.011,F ,25revenue=$1.03II. NOSQL - THE RESULTS •Queries were fast•range scan on primary key•Inflexible•not aggregated, not available •Not continuously updated •aggregate first, then display •Processing scales exponentiallyII. NOSQL - PERFORMANCE •Dimensional combinations => exponential increase •Tried limiting dimensional depth•still expands exponentially•Example: ~500k records•11 dimensions, 5-deep•4.5 hours on a 15-node Hadoop cluster•14 dimensions, 5-deep•9 hours on a 25-node Hadoop clusterI. RDBMS - Relational Database II. NoSQL - Key/Value StoreI. RDBMS - Relational Database II. NoSQL - Key/Value Store III. ???•Problem with RDBMS: scans are slow •Problem with NoSQL: computationally intractable•Problem with RDBMS: scans are slow •Problem with NoSQL: computationally intractable!•Tackling RDBMS issue seems easier“”INTRODUCING DRUIDDRUID – KEY FEATURES1.Real-Time Ingestion (Indigestion?)2.Slicing-n-Dicing Drill Down Fruit Ninjas3.AvailableRealtime NodesQuery APIQuery API a Historical Nodes Realtime NodesQuery API Hand Off DataQuery API a Historical Nodes Broker Nodes Realtime NodesQuery APIQuery API Query RewriteScatter/GatherHand Off DataDATA!timestamp publisher advertiser gender country ... click price! 2011-01-01T00:01:35Z Male USA 0 0.65! 2011-01-01T00:03:63Z Male USA 0 0.62! 2011-01-01T00:04:51Z Male USA 1 0.45! 2011-01-01T01:00:00Z Female UK 0 0.87! 2011-01-01T02:00:00Z Female UK 0 0.99! 2011-01-01T02:00:00Z Female UK 1 1.53! ...COLUMN COMPRESSION - DICTIONARIES•Create ids• -> 0, -> 1•Store•publisher -> [0, 0, 0, 1, 1, 1]•advertiser -> [0, 0, 0, 0, 0, 0] timestamp publisher advertiser gender country ... click price !2011-01-01T00:01:35Z Male USA 0 0.65!2011-01-01T00:03:63Z Male USA 0 0.62!2011-01-01T00:04:51Z Male USA 1 0.45!2011-01-01T01:00:00Z Female UK 0 0.87!2011-01-01T02:00:00Z Female UK 0 0.99!2011-01-01T02:00:00Z Female UK 1 1.53!...BITMAP INDEXEStimestamp publisher advertiser gender country ... click price! 2011-01-01T00:01:35Z Male USA 0 0.65! 2011-01-01T00:03:63Z Male USA 0 0.62! 2011-01-01T00:04:51Z Male USA 1 0.45! 2011-01-01T01:00:00Z Female UK 0 0.87! 2011-01-01T02:00:00Z Female UK 0 0.99! 2011-01-01T02:00:00Z Female UK 1 1.53! ...• -> [0, 1, 2] -> [111000]• -> [3, 4, 5] -> [000111]•Compress•CONCISE (http://ricerca.mat.uniroma3.it/users/colanton/concise.html)FAST AND FLEXIBLE QUERIESJUSTIN BIEBER ![1, 1, 0, 0]KE$HA ![0, 0, 1, 1]JUSTIN BIEBER !OR KE$HA ![1, 1, 1, 1]Rows POETS0JUSTIN(BIEBER1JUSTIN(BIEBER2KE$HA3KE$HAAVAILABILITY•Fault-tolerant•Rolling deployments/restarts•3 years, no downtime for update •Grow == start processes •Shrink == kill processesEXTENSIBLE•Extensibility model allows for significant customizability •Deep Storage•Service Discovery•Extra queries•Extra aggregations•Extra column types/storage formats•Scan speed•~53M rows / second / core•Realtime ingestion rate•~20k events / second / node on “real” data•Highest benchmark so far: 250k/second on toy data •http://druid.io/blog/2014/03/17/benchmarking-druid.html•Metamarkets cluster•~10 trillion events (impressions, bids, etc.) •>200 TB•175 machines•90% query latency < 1s, 95% < 2s•300k/s event ingestion sustained“”DRUID IS OPEN SOURCEUSE CASES•Interactive dashboards of!•KPIs•Page Views, Impressions, Uniques, Revenue •Server Metrics•Request latency, etc•Network Metrics•Packets, bytes, etcUSE CASES•If you ever say the following, investigate Druid•“I wish I could slice and dice into this data”•“I just did X, I wish I could see if it was working in real-time” •“I wish I could see this data with more fine-grained granularity” •“I wish I didn’t have to use pre-canned drill downs”DRUID IS OPENURL: http://druid.ioLanguage: JavaLicense: GPLv2!Used by ~10 companies in production Contributions from 40 people。