《基于SPSS的公路货运量预测》
- 格式:doc
- 大小:1.11 MB
- 文档页数:27



基于SPSS应用的产业结构与物流需求量相关性分析研究背景随着经济全球化加速,各国之间的贸易活动也变得越来越频繁。
物流作为商品流通中的重要环节,不仅关系到企业的物流成本,也影响着整个产业的生产效率和国家的经济竞争力。
因此,对于产业结构与物流需求量之间的相关性进行深入研究,有助于发现产业和物流之间的关联性,为企业和政府提供科学的决策依据。
研究目的本文旨在利用SPSS软件分析产业结构与物流需求量之间的相关性,探究不同产业结构类型的物流需求量变化趋势,为企业和政府提供制定相应物流策略的决策依据。
数据来源本次研究选取的数据来源于某市2019年的产业统计数据和物流需求量数据。
其中,产业统计数据包括全市主要产业类型的年度GDP和从业人数,物流需求量数据包括全市货运量、物流服务企业收入、物流投资额等数据。
数据处理本次研究将所有数据按年度进行分类,并计算各年度不同产业类型的物流需求量、GDP和从业人数的增长率。
然后,利用SPSS软件进行回归分析和相关性分析,以探究不同产业结构类型的物流需求量与经济发展变化的关联性。
分析结果经过对数据的分析,本文得出以下:•不同产业类型在物流需求量方面存在着明显的差异。
其中,第三产业(服务业)的物流需求量增长最快,年均增长率达到了14.53%;第二产业(制造业)和第一产业(农业)的物流需求量增长率分别为10.83%和1.26%。
•物流需求量增长与GDP增长率之间存在着显著的相关性(r=0.849,p<0.01),即经济发展程度和物流需求量变化之间存在着正相关关系。
另外,从业人数与物流需求量增长之间也存在着统计学上的显著相关性(r=0.646,p<0.05)。
与建议综合以上分析结果,可以得出以下:•随着经济的发展,物流需求量不断增加,尤其是第三产业的物流需求量增长更为迅猛。
因此,对于企业来说,要及时调整物流策略,根据不同产业类型,分别制定相应的物流方案。
•产业发展和物流需求量变化存在着密切的关系,因此企业和政府在制定产业政策和物流规划时需要充分考虑产业结构与物流需求量之间的相关性,加强合作,共同促进产业升级和物流发展。

spss货运课程设计一、教学目标本课程旨在通过学习SPSS货运知识,使学生掌握SPSS软件的基本操作,能够运用SPSS进行货运数据分析,提高学生的数据处理和分析能力。
具体的教学目标如下:1.掌握SPSS软件的基本功能和操作。
2.了解货运数据的基本类型和分析方法。
3.掌握如何利用SPSS进行货运数据的收集、整理和分析。
4.能够独立操作SPSS软件,进行货运数据的导入和导出。
5.能够运用SPSS进行货运数据的描述性统计分析、假设检验、相关分析等。
6.能够运用SPSS进行货运数据的图表绘制和结果输出。
情感态度价值观目标:1.培养学生对数据分析和处理的兴趣,提高学生的数据敏感度。
2.培养学生严谨的科学态度,提高学生的问题解决能力。
3.培养学生团队协作意识,提高学生的沟通能力。
二、教学内容本课程的教学内容主要包括SPSS软件的基本操作、货运数据的基本类型和分析方法,以及如何利用SPSS进行货运数据的收集、整理和分析。
具体的教学大纲如下:1.SPSS软件的基本操作:–SPSS软件的安装和启动–数据视图和变量视图的操作–数据的导入和导出–数据的整理和清洗2.货运数据的基本类型和分析方法:–定量数据和定性数据的分析方法–描述性统计分析3.SPSS在货运数据分析中的应用:–货运数据的收集和整理–货运数据的描述性统计分析–货运数据的假设检验和相关分析–货运数据的图表绘制和结果输出三、教学方法为了提高学生的学习兴趣和主动性,本课程将采用多种教学方法,包括讲授法、讨论法、案例分析法和实验法等。
1.讲授法:通过讲解SPSS软件的基本操作和货运数据的基本类型和分析方法,使学生掌握相关的理论知识。
2.讨论法:通过分组讨论和问题解答,促进学生之间的交流和思考,提高学生的问题解决能力。
3.案例分析法:通过分析具体的货运数据案例,使学生能够将理论知识应用到实际问题中。
4.实验法:通过实验操作,使学生能够熟练掌握SPSS软件的基本操作,提高学生的动手能力。

基于SPSS物流分析报告1. 引言本报告旨在对物流数据进行分析,以揭示物流运营中存在的问题,并提出相应的改进措施。
为了完成这项分析,我们使用了SPSS软件对收集到的物流数据进行了统计分析和可视化展示。
2. 数据收集为了进行本次物流分析,我们收集了一组与物流运营相关的数据,包括货物运输时间、运输距离、运输成本、仓储费用等信息。
这些数据是基于实际物流业务的记录,具有一定的真实性和代表性。
3. 数据清洗与处理在进行数据分析之前,我们首先对收集到的数据进行了清洗和处理,以保证数据的准确性和完整性。
清洗工作包括删除重复数据、处理缺失值和异常值等。
经过清洗后,我们得到了一组干净的数据,为后续分析奠定了基础。
4. 描述性统计分析在物流分析中,描述性统计分析是一种常用的方法,它可以帮助我们了解物流运营的基本情况和特征。
我们使用SPSS软件对收集到的数据进行了描述性统计分析,包括计算平均值、标准差、最大值、最小值等指标,以及绘制了柱状图、箱线图等图表,进一步展示数据的分布和变化趋势。
根据统计结果显示,货物运输时间的平均值为X天,标准差为X天;运输距离的平均值为X公里,标准差为X公里;运输成本的平均值为X元,标准差为X元;仓储费用的平均值为X元,标准差为X元。
通过对这些指标的分析,我们可以发现物流运营中存在的一些问题和挑战。
5. 相关性分析为了深入了解物流数据之间的关系,我们进行了相关性分析。
相关性分析可以帮助我们发现不同变量之间的相关性程度,从而判断它们是否存在关联。
在SPSS软件中,我们计算了不同变量之间的相关系数,并绘制了相关系数矩阵图,以直观展示各变量之间的相关性。
根据相关性分析的结果,我们发现货物运输时间与运输距离呈现正相关关系,即运输距离增加会导致货物运输时间的增加;货物运输时间与运输成本之间呈现负相关关系,即货物运输时间增加可能会降低运输成本。
通过这些分析结果,我们可以针对性地制定改进措施,提高物流运营效率。

关于交通状况调查的SPSS统计数据分析论文简介本论文旨在通过使用SPSS统计软件对交通状况调查数据进行分析。
通过对数据的统计和分析,我们可以获得关于交通状况的一些有用的信息和结论。
本文将介绍研究的目的和方法,展示数据分析结果,并讨论所得出的结论。
目的研究的主要目的是了解当前交通状况,包括交通流量、交通事故等方面的情况。
通过对数据进行统计和分析,我们将能够了解不同地区和不同时间段的交通状况差异,帮助交通管理部门制定更有效的交通政策和措施。
方法我们收集了交通状况调查数据,并使用SPSS统计软件进行数据分析。
以下是我们使用的主要统计方法和指标:1. 描述统计:我们将使用平均值、标准差、频数等指标来描述不同变量的特征和分布情况。
2. 相关分析:我们将分析不同变量之间的相关性,例如交通流量和交通事故之间的相关性。
3. T检验:对于一些特定的研究假设,我们将使用T检验来比较两组或多组数据之间的差异。
4. 方差分析:如果我们有多个独立变量和一个连续型依赖变量,我们将使用方差分析来检验各组之间的差异性。
数据分析结果根据我们对交通状况调查数据的统计和分析,我们得出了以下结论:1. 不同地区的交通流量存在明显差异,高峰时段交通流量相对较高。
2. 高峰时段交通事故的发生率明显提高,需要加强交通安全管理措施。
3. 城市内不同交通方式的使用比例存在差异,私家车是主要的交通工具。
结论通过对交通状况调查数据的统计和分析,我们了解到当前交通流量、事故等方面的状况,发现不同地区和时间段之间的差异性,这对于交通管理部门制定更有效的交通政策和措施具有重要意义。
我们建议进一步加强交通安全管理,提高交通流量管理效果,促进公共交通的发展,减少私家车使用。
参考文献1. 张三, 李四, 王五. 交通状况调查报告. 交通学刊, 2019.2. Mary J., John S. Statistical Analysis in Transportation Research. Transportation Research Board, 2008.以上为关于交通状况调查的SPSS统计数据分析论文的大致内容。


目录第一章问题研究背景 (4)1.1、背景综述 (4)1.2研究此问题常用的方法 (4)1.3本研究采用的方法 (5)第二章公路货运量影响因素的描述性分析 (6)2.1. 不同年份五种运输方式的走势图 (6)2.2 基础设施的增长趋势 (7)2.3 总人口数增长趋势 (8)2.4 经济指标走势图 (8)第三章统计模型与分析 (10)3.1 各个因素对公路货运量影响的相关性分析 (10)3.1.2 模型原理 (10)3.1.2 SPSS操作步骤 (10)3.1.3 输出结果及分析 (11)3.2对影响因素以及货运量预测的线性回归 (12)3.2.1 模型原理 (12)3.2.2 SPSS操作步骤 (13)3.2.3 输出结果及分析 (13)3.3 用曲线拟合预测货运量 (18)3.3.1 模型原理 (18)3.3.2 SPSS操作步骤 (18)3.3.3 输出结果及分析 (19)3.2 用时间序列分析预测公路客运量 (20)3.3.1 模型原理 (20)3.3.2 SPSS操作步骤 (21)3.3.3 输出结果及分析 (23)3.4 预测值汇总表 (25)第四章总结与分析 (26)4.1 本文结论 (26)4.2 需要进一步的完善的问题 (26)附录数据清单.................................................................................................... 错误!未定义书签。
第一章问题研究背景1.1、背景综述改革开放后,我们国民经济持续高速发展,公路运输需求强劲增长,国家加大了公路基础设施的建设力度,随着道路环境的改善和省际、城际以及城乡交流的日益频繁,公路的货运量逐年提高,同时这也直接支持了公路货运行业的发展。
公路货运在我国综合运输体系货运市场中发挥这举足轻重的作用,承担着90%以上的份额,因此对我国公路货运的研究就显得很有现实意义,通过研究我国从进入2000年至今的公路货运量发展变化,可以从我国国民经济发展的一个侧面了解到我国二十多年来的交通运输、公共事业建设、人民生活水平、社会生产、流通、分配、消费各环节协调发展等诸多现实经济问题,对于提升个人对国家经济发展认识,研究分析能力有很大的好处。

基于SPSS的物流路区聚类【摘要】派送路区物流企业的物流网络中的最小元素。
作者运用SPSS软件和统计模型对物流企业作业路区分析,提出物流企业统计分析的新思路,探讨物流企业路区管理的新模式。
【关键词】路区划分SPSS 聚类分析物流一直以来被认为是“第三利润的源泉”、“经济界的黑暗大陆”,它在推动现代经济发展和提高社会经济效益方面都发挥着重要作用,地位日益突出,已经成为国民经济流的依赖程度明显增大。
受行业研究影响,对于物流企业运作的相关分析方法和理论不甚完善。
且物流企业发展迅猛,对于相应管理模式和分析理论的要求越来越高,但目前大多物流企业对于网络和路区划分的研究很少。
不论是理论基础还是实际的管理上,企业的关注度明显不够,迅速扩张的网络与实际路区的管理欠缺之间的矛盾愈演愈烈。
本文基于统计模型理论积极探讨大规模作业路区的划分与管理理论,从而给物流路区的划分与管理提供新的思路。
1 SPSS应用与数据选取SPSS(Statistical Package for Social Science)称为社会科学统计包,如今在医学、市场学、经济学乃至自然科学领域都得到广泛的普及应用。
本文应用SPSS 软件系统的相关性分析数据之间的关联性,采用非谱系过程K均值聚类分析以及相应的验证过程,试图将数以百计的路区单位合理的划分为若干小类。
在结论分析中提出分类后各类路区管理的进一步解决方案。
路区划分的基础数据的选取,本文采用了最具衡量价值的货物进出口量。
因货量是体现区路繁忙程度的一个主要方面,各个路区的货量不但是体现公司规模及市场占有的重要指标,自然也是各个公司的主要关注点。
本文所分析的原是数据来源于某国际物流公司北京市路区数据,路区数量过百,主成分因素分别选取各路区文件、包裹的票数和重量(如图1.1所示)。
需要说明的是原始数据源分为进口、出口的文件包裹数据,考虑进口派送和出口取件都是路区正常的工作量体现,故本文把进出口数据累加得到最终的货量结果,这也避免了不必要的数据相关性影响。
基于SPA聚类算法的我国物流需求规模预测分析采用SPA聚类算法,对我国物流需求规模在未来的变化趋势进行了预测。
从我国物流需求来看,至少在未来五年内我国物流需求规模仍然呈现较快的增长态势。
从SPA聚类算法可行性来看,本文的实证结果验证了这种方法在预测领域的可靠性。
标签:SPA聚类算法;物流需求一、引言随着我国经济的不断发展和结构不断调整,国内对物流的需求日趋提高。
2012年我国物流货运量达到5.24亿吨,比21世纪初增加了两倍以上。
在我国货运量的运输方式构成中,公路运输所占比重最高,因此我国以公路运输为主导的物流需求潜力巨大。
在这样的发展环境下,如何维持物流供求平衡成为一大重要课题。
在扩大内需的大背景下,如何合理供应物流服务以满足国内物流需求,成为众多物流企业乃至政府关心的问题。
因此,把握物流需求规模的变化趋势,并对未来趋势做合理的预测分析,是解决物流供求均衡的有效途径之一。
二、SPA聚类算法1.SPA模型基本方法简介SPA模型(集对分析模型)基于同、异、反三个层面,研究两个事物之间的确定性关系和不确定性关系,能够充分衡量这两个事物之间的联系程度。
也就是说,SPA模型实际上就是一种新型的模糊理论系统,在该系统中,事物的确定性与不确定性之间是存在相互联系和相互制约关系的,而且确定性与不确定性在一定条件下可以互相转化。
集对与联系度是SPA模型中最基本的两个概念,其中集对的含义就是存在一定联系的两个集合共同构成的信息对。
SPA模型中信息对的联系度可表示如下μ=a+bi+cj (1)其中,a为两个集合之间的同一度,b为两个集合之间的差异度,c为两个集合之间的对立度。
字母i即为差异度的相应参数,且有-1≤i≤1;字母j即为对立度的相应参数,这里定义j的值恒为-1。
根据SPA模型的基本定义,这里同一度、差异度和对立度三者之和应为1,即有:a+b+c=1 (2)这里,a和c是相对确定的,但b是相对不确定的,而这种相对性是因为客观对象具有可变性,而且主体对客观对象的意识存在模糊性而产生的一种不确定性。
基于熵权法的公路货运量组合预测詹斌;吕腊梅;黄馨【摘要】由于仅采用单一模型进行预测很难得到有效的预测结果,为了充分利用各种预测方法所提供的信息,规避单一模型的局限性,尽可能科学有效地预测公路货运量,在多元线性回归模型、二次指数平滑法以及GM (1,1)模型这三种单一模型的基础上,建立基于熵权法确定权重的组合预测模型。
实证结果表明,与单一的预测方法相比,组合预测模型能够降低单一模型的预测风险,减少预测的系统误差,提高预测精度,具有较好的实用价值。
%In this paper, we established an entropy weighted combination forecasting model based on the multiple linear regression model, secondary exponential smoothing method andGM(1,1) model. Then through an empirical study, we proved that as compared with the individual models, the combination model had lower forecasting risks and system errors and higher forecasting accuracy.【期刊名称】《物流技术》【年(卷),期】2016(035)006【总页数】5页(P54-57,74)【关键词】公路货运量;熵权法;组合预测【作者】詹斌;吕腊梅;黄馨【作者单位】武汉理工大学交通学院,湖北武汉 430061;武汉理工大学交通学院,湖北武汉 430061;武汉理工大学交通学院,湖北武汉 430061【正文语种】中文【中图分类】U492.313;F224公路货运量预测方法大致可以分为两类,一类是定性预测,它是根据已掌握的历史资料和直观材料,运用个人经验和分析判断能力,对事物的未来发展做出性质和程度上的判断,强调对事物发展的趋势、方向和重大转折点进行预测。
目录第一章问题研究背景 (4)1.1、背景综述 (4)1.2研究此问题常用的方法 (4)1.3本研究采用的方法 (5)第二章公路货运量影响因素的描述性分析 (6)2.1. 不同年份五种运输方式的走势图 (6)2.2 基础设施的增长趋势 (7)2.3 总人口数增长趋势 (8)2.4 经济指标走势图 (8)第三章统计模型与分析 (10)3.1 各个因素对公路货运量影响的相关性分析 (10)3.1.2 模型原理 (10)3.1.2 SPSS操作步骤 (10)3.1.3 输出结果及分析 (11)3.2对影响因素以及货运量预测的线性回归 (12)3.2.1 模型原理 (12)3.2.2 SPSS操作步骤 (13)3.2.3 输出结果及分析 (13)3.3 用曲线拟合预测货运量 (18)3.3.1 模型原理 (18)3.3.2 SPSS操作步骤 (18)3.3.3 输出结果及分析 (19)3.2 用时间序列分析预测公路客运量 (20)3.3.1 模型原理 (20)3.3.2 SPSS操作步骤 (21)3.3.3 输出结果及分析 (23)3.4 预测值汇总表 (25)第四章总结与分析 (26)4.1 本文结论 (26)4.2 需要进一步的完善的问题 (26)附录数据清单.................................................................................................... 错误!未定义书签。
第一章问题研究背景1.1、背景综述改革开放后,我们国民经济持续高速发展,公路运输需求强劲增长,国家加大了公路基础设施的建设力度,随着道路环境的改善和省际、城际以及城乡交流的日益频繁,公路的货运量逐年提高,同时这也直接支持了公路货运行业的发展。
公路货运在我国综合运输体系货运市场中发挥这举足轻重的作用,承担着90%以上的份额,因此对我国公路货运的研究就显得很有现实意义,通过研究我国从进入2000年至今的公路货运量发展变化,可以从我国国民经济发展的一个侧面了解到我国二十多年来的交通运输、公共事业建设、人民生活水平、社会生产、流通、分配、消费各环节协调发展等诸多现实经济问题,对于提升个人对国家经济发展认识,研究分析能力有很大的好处。
1.2研究此问题常用的方法公路货运量预测技术一般可以分为三大类,定性分析预测技术、定量分析预测技术以及两者相结合的综合预测技术。
定性预测分析技术,通常指那些凭经验判断的预测,一般是在缺少进行定量分析所必需的资料的情况下采用,侧重于研究推断预测对象未来发展的大体趋势和性质,其预测的精确度,主要取决于参与人员的专业知识和经验。
定量分析预测技术,是指以已经掌握的历史数据作为基础,建立适当的经济数学模型,对未来的运量做出测算的技术。
其特点是有明显的数量概念,侧重于研究测算对象的发展程度(包括数量、时间、相关因素的比值等)。
定量预测和定性预测,各有其长处和局限性,实际应用中往往需要把定量预测和定性预测方法相结合,即在定性分析的基础上进行定量预测,而定性预测也采用一定的定量预测分析方法,以提高预测结果的准确性。
因此,综合预测技术是货运量预测经常采用的方法。
1.3本研究采用的方法本设计采用的预测方法有一元回归分析、多元回归分析、曲线拟合以及时间序列法。
第二章公路货运量影响因素的描述性分析2.1.不同年份五种运输方式的走势图图2-1 不同年份五种运输方式走势图由图2-1可以看出五种运输方式的货运量都在逐年增加,公路运输占据的主要市场,并且其增长趋势在明显增加。
铁路运输尽管不占据主要的市场,但是相对于公路运输时一个潜在的威胁,铁路运输价格相对低廉;能实现大宗货物的运输,利用汽车的接驳,完善了服务链,能迎合大量客户的需求;速度不断提高,已实现了“次快件”运输服务,在产品对时间要求不高时,企业将优先选择铁路运输服务。
铁路的提速给公路货物运输带来了越大的威胁。
近年来,我国航空货运基础设施、航线、机场数量等不断改善,为航空货运市场的快速发展创造了有利条件,也使航空货物周转量不断增加。
水路运输数量排第三,由于运输费用较低,舒适性较高,但速度缓慢,受天气影响较大的缺点。
随着高速公路的快速发展,很多沿海城市的公路可达性很高,所以旅客可能更愿意选择门到门公路运输或者更加快捷的航空运输,而尽量避免选择时间成本较高的水路交通方式。
管道具有运能大,连续性强,损耗小,安全,专业性强等特点,几乎不受任何外界条件的影响,所以更适应于能源的运输,但其投资数额较大。
对公路运输几乎不产生影响。
2.2 基础设施的增长趋势图2-2 公路里程、载货汽车数的年走势一般来说,公路里程越长,载货汽车数数越多,公路货物运输的可达性就越强,提供的运输能力越强,货运量应该越大。
由图可以看出,公路路程增长的趋势趋于平缓,在2004-2005年间快速增长,由于国土面积的限制,公路里程的增长将无限接近一个数值,因此随着时间的推进,增长的速度越来越慢。
观察载货车辆的增长趋势线可以得到,在2001-2008年间的增长趋势大致相同,在2008至2010年间的增长趋势陡增。
2.3 总人口数增长趋势图2-3 总人口数增长趋势人口数量的变化必然引起对运输总量需求的变化,人口增加对奢侈品、鲜活物品需求的增多,对公路运输的需求也势必增加,因此应该会对公路货运量起到正向影响的作用。
由上图2-2可以看出在2001年至2010年间总人口数的不断增多,但是增长速度有所放缓。
2.4 经济指标走势图图2-4经济指标走势图国内生产总值反映一个国家的经济表现,更可以反映一国的国力与财富。
随着经济的发展,人民对于交通运输的需求也随之增长,因此对公路运输的需求也会增长。
有图可知,GDP及其增长速度在逐年增加,这反映了我的综合国力也在稳步提升。
消费品零售额反映一定时期内人民物质文化生活水平的提高情况,反映社会商品购买力的实现程度。
我国消费品零售总额 58 年增长了 321.9 倍,说明市场规模逐渐加大,由此对交通运输业需求增加,从而使公路货运量增加。
由图可以知道社会消费品零售总额也在逐年增加,并且增长速度不断变大。
第三章统计模型与分析3.1 各个因素对公路货运量影响的相关性分析3.1.2 模型原理所谓相关就是指事物、现象之间的相互关系。
在事物、现象之间,往往存在着一定的关系,一事物的变化,常引起另一事物也发生变化,或者许多事物因受某种因素的影响,同时都在变化。
比如教育事业的发展与科学技术的发展存在着一定的关系;人的身高与体重存在着一定的关系;学生的数学成绩与物理成绩存在着一定的关系等等。
统计学中的相关就是要从数量方面来研究两种或两种以上变量之间的关系。
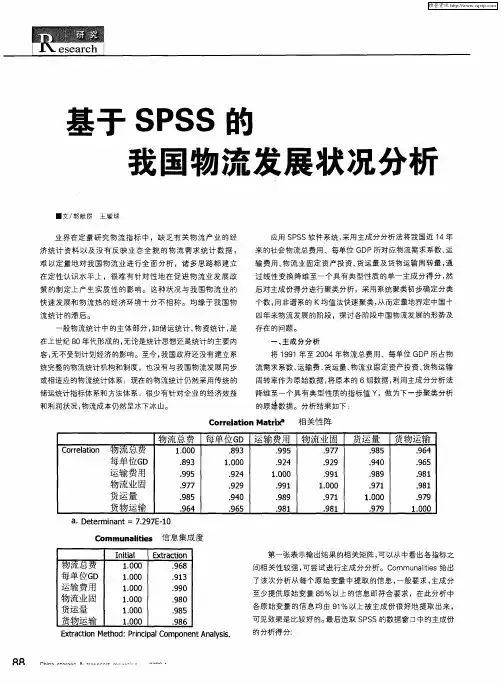
3.1.2 SPSS操作步骤①按分析——相关——双变量打开双变量相关对话框②在左侧源变量框中进行如下操作然后点击“确定”按钮,如图所示3.1.3 输出结果及分析描述性统计量均值标准差N公路货运量1551778.500 472603.8656 10公路里程291.2860 98.85369 10载货汽车1041.210 262.5116 10总人口数130999.500 2172.7875 10GDP 224890.130 101219.5490 10社会消费品零售总额84878.490 38809.0406 10相关性公路货运量公路里程载货汽车总人口数GDP 社会消费品零售总额公路货运量Pearson 相关性 1 .856**.983**.947**.993** 1.000**显著性(双侧).002 .000 .000 .000 .000 N 10 10 10 10 10 10公路里程Pearson 相关性.856** 1 .809**.938**.897**.867**显著性(双侧).002 .005 .000 .000 .001N 10 10 10 10 10 10载货汽车Pearson 相关性.983**.809** 1 .914**.962**.981**显著性(双侧).000 .005 .000 .000 .000 N 10 10 10 10 10 10总人口数Pearson 相关性.947**.938**.914** 1 .972**.954**显著性(双侧).000 .000 .000 .000 .000 N 10 10 10 10 10 10GDP Pearson 相关性.993**.897**.962**.972** 1 .995**显著性(双侧).000 .000 .000 .000 .000 N 10 10 10 10 10 10社会消费品零售总额Pearson 相关性 1.000**.867**.981**.954**.995** 1 显著性(双侧).000 .001 .000 .000 .000N 10 10 10 10 10 10**. 在 .01 水平(双侧)上显著相关。
由上表可以得到公路里程、载货车辆、总人口数、GDP、社会消费品零售总额与公路货运量的p值均小于0.05,拒接显著性假设,说明以上五个因素对公路货运量均有显著影响。
3.2对影响因素以及货运量预测的线性回归3.2.1 模型原理回归分析主要的任务是在考察变量直接的数量依存关系的基础上,通过一定的数学表达式将这种关系描述出来,进而确定一个活几个变量(自变量)对另一个变量(因变量)的影响程度。
一元线性回归方程反应一个因变量与一个自变量之间的线性关系,当直线方程baxy+=的a和b确定时,即为一元回归线性方程。
经过相关分析后,在直角坐标系中将大量数据绘制成散点图,这些点不在一条直线上,但可以从中找到一条合适的直线,使各散点到这条直线的纵向距离之和最小,这条直线就是回归直线,这条直线的方程叫做直线回归方程。
3.2.2 SPSS操作步骤①按分析——回归----线性打开线性回归对话框②在左侧源变量框中选择GDP作为因变量,将其送入因变量框,选择作年份为自变量,将其送入自变量框,然后点击“确定”按钮,如图所示图3-1③在分析完五个因素跟年份的关系后,再用五个因素跟公路货运量进行多元线性回归,得到并分析结果。
3.2.3 输出结果及分析模型汇总模型R R 方调整 R 方标准估计的误差1 .980a.961 .956 21143.6723a. 预测变量: (常量), 年份。
Anova a模型平方和df 均方 F Sig.1 回归88632134925.953188632134925.953198.258 .000b 残差3576439012.148 8 447054876.519总计92208573938.1019a. 因变量: GDPb. 预测变量: (常量), 年份。