简单网页的制作(转)
- 格式:ppt
- 大小:4.12 MB
- 文档页数:69
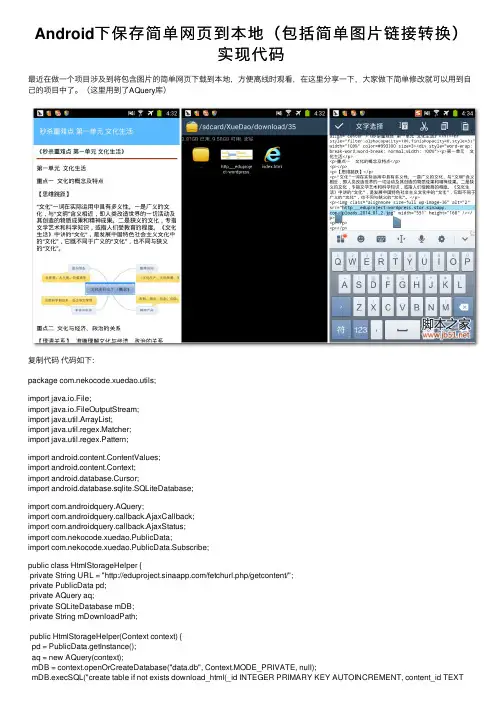
Android下保存简单⽹页到本地(包括简单图⽚链接转换)实现代码最近在做⼀个项⽬涉及到将包含图⽚的简单⽹页下载到本地,⽅便离线时观看,在这⾥分享⼀下,⼤家做下简单修改就可以⽤到⾃⼰的项⽬中了。
(这⾥⽤到了AQuery库)复制代码代码如下:package com.nekocode.xuedao.utils;import java.io.File;import java.io.FileOutputStream;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern;import android.content.ContentValues;import android.content.Context;import android.database.Cursor;import android.database.sqlite.SQLiteDatabase;import com.androidquery.AQuery;import com.androidquery.callback.AjaxCallback;import com.androidquery.callback.AjaxStatus;import com.nekocode.xuedao.PublicData;import com.nekocode.xuedao.PublicData.Subscribe;public class HtmlStorageHelper {private String URL = "/fetchurl.php/getcontent/";private PublicData pd;private AQuery aq;private SQLiteDatabase mDB;private String mDownloadPath;public HtmlStorageHelper(Context context) {pd = PublicData.getInstance();aq = new AQuery(context);mDB = context.openOrCreateDatabase("data.db", Context.MODE_PRIVATE, null);mDB.execSQL("create table if not exists download_html(_id INTEGER PRIMARY KEY AUTOINCREMENT, content_id TEXTNOT NULL, title TEXT NOT NULL)");mDownloadPath = pd.mAppPath + "download/";File dir_file = new File(pd.mAppPath + "download/");if(!dir_file.exists())dir_file.mkdir();}public void saveHtml(final String id, final String title) {if(isHtmlSaved(id))return;aq.ajax(URL+id, String.class, new AjaxCallback<String>() {@Overridepublic void callback(String url, String html, AjaxStatus status) {File dir_file = new File(mDownloadPath + id);if(!dir_file.exists())dir_file.mkdir();Pattern pattern = pile("(?<=src=\")[^\"]+(?=\")");Matcher matcher = pattern.matcher(html);StringBuffer sb = new StringBuffer();while(matcher.find()){downloadPic(id, matcher.group(0));matcher.appendReplacement(sb, formatPath(matcher.group(0))); }matcher.appendTail(sb);html = sb.toString();writeHtml(id, title, html);}});}private void downloadPic(String id, String url) {File pic_file = new File(mDownloadPath + id + "/" + formatPath(url)); aq.download(url, pic_file, new AjaxCallback<File>() {@Overridepublic void callback(String url, final File file, AjaxStatus status) {}});}private void writeHtml(String id, String title, String html) {File html_file = new File(mDownloadPath + id + "/index.html");FileOutputStream fos = null;try {fos=new FileOutputStream(html_file);fos.write(html.getBytes());} catch (Exception e) {e.printStackTrace();}finally{try {fos.close();} catch (Exception e2) {e2.printStackTrace();}}ContentValues values = new ContentValues();values.put("content_id", id);values.put("title", title);mDB.insert("download_html", "_id", values);}public boolean isHtmlSaved(String id) {File file = new File(mDownloadPath + id);if(file.exists()) {file = new File(mDownloadPath + id + "/index.html");if(file.exists())return true;}deleteHtml(id);return false;}public String getTitle(String id) {Cursor c = mDB.rawQuery("select * from download_html where content_id=?", new String[]{id}); if(c.getCount() == 0)return null;c.moveToFirst();int index1 = c.getColumnIndex("title");return c.getString(index1);}public ArrayList<Subscribe> getHtmlList() {Cursor c = mDB.rawQuery("select * from download_html", null);ArrayList<Subscribe> list = new ArrayList<Subscribe>();if(c.getCount() != 0) {c.moveToFirst();int index1 = c.getColumnIndex("content_id");int index2 = c.getColumnIndex("title");while (!c.isAfterLast()) {String id = c.getString(index1);if(isHtmlSaved(id)) {Subscribe sub = new Subscribe(id,c.getString(index2),Subscribe.FILE_DOWNLOADED);list.add(sub);}c.moveToNext();}}return list;}public void deleteHtml(String id) {mDB.delete("download_html", "content_id=?", new String[]{id});File dir_file = new File(mDownloadPath + id);deleteFile(dir_file);}private void deleteFile(File file) {if (file.exists()) { // 判断⽂件是否存在if (file.isFile()) { // 判断是否是⽂件file.delete(); // delete()⽅法你应该知道是删除的意思;} else if (file.isDirectory()) { // 否则如果它是⼀个⽬录File files[] = file.listFiles(); // 声明⽬录下所有的⽂件 files[];for (int i = 0; i < files.length; i++) { // 遍历⽬录下所有的⽂件this.deleteFile(files[i]); // 把每个⽂件⽤这个⽅法进⾏迭代}}file.delete();} else {//}}private String formatPath(String path) { if (path != null && path.length() > 0) { path = path.replace("\\", "_");path = path.replace("/", "_");path = path.replace(":", "_");path = path.replace("*", "_");path = path.replace("?", "_");path = path.replace("\"", "_");path = path.replace("<", "_");path = path.replace("|", "_");path = path.replace(">", "_");}return path;}}。

⽹页设计与制作(附微课视频第2版)参考答案第⼀章习题参考答案⼀、选择题1、A2、A3、B4、C5、A、B、C、D6、A、C、D7、B8、C9、B⼆、简答题1.答:URL是UniformResourceLocation的缩写,译为“统⼀资源定位符”,URL是Internet 上⽤来描述信息资源的字符串,主要⽤在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采⽤URL可以⽤⼀种统⼀的格式来描述各种信息资源,包括⽂件、服务器的地址和⽬录等;2答:⽂本、图像、动画、视频等。
3.答:⽹页结构语⾔的作⽤是将⽹页需要的内容以结构化、模块化的⽅式总结和存储,供表现语⾔和⾏为进⾏调⽤。
⽹页结构语⾔包括可扩展超⽂本标记语⾔XHTML 1.0和HTML 5等两种结构语⾔。
其中,XHTML 1.0为当前被⼴泛使⽤的标准,⽽HTML 5标准则是⽹页未来将被使⽤的标准。
⽹页表现语⾔的作⽤是为⽹页的结构语⾔定义尺⼨、位置、背景,以及⽂本的各种效果。
⽬前⽹页表现的国际标准语⾔为CSS 样式表技术。
⽹页结构语⾔和⽹页表现语⾔共同作⽤可以为⽤户呈现⽹页的整体画⾯,然⽽,⽹页是⼀种交互性的媒体,其除了可以呈现内容外,还可以根据⽤户的界⾯操作响应各种事件,此时,就需要⽤到⽹页的⾏为语⾔。
⽹页的⾏为语⾔包括多种类型,例如,JavaScript、JScript以及VBScript等。
4.答:⼀个完整的HTML5⽂档包含声明、头部和主体三个部分组成。
第⼆章习题参考答案⼀、选择题1.A、B2.A3.B4.D5.D6.D7.C⼆、简答题1.答:(⼀)⽹站功能需求分析;(⼆)⽹站的策划,本阶段主要包含⽹站栏⽬,内容,产品提炼等等;(三)⽹站设计,根据策划开始进⾏设计;(四)程序代码的开发;(五)上线测试;(5)后期维护;2.答:(1)对称与均衡对称分为左右对称、上下对称、重复对称、旋转对称等形式。
对称的造型在⼤⾃然中⽐⽐皆是,同时也是版式设计常⽤的构成形式。






《用Dreamweaver制作网页五》学案——实现网页间跳转(超链接)1课时学习目标:1、各小组完善首页和栏目网页。
2、实现网页间跳转(超链接的使用)资源平台:1、Dreamweaver 8.02、上节课收集的图片和文本素材、老师准备的网页素材、网上素材3、老师课前准备的信息技术学科资源网观看老师演示:1、如何实现网页间跳转(超链接的使用)前面我们已经做好了网站首页、栏目网页,并将它们都保存在了小组站点文件夹中,然而一个网站不仅仅只有一张网页,而是有很多张网页组成,并且各网页之间就是通过超级链接连在一起,那么Dreamweaver中如何来建立网页的超链接呢?超链接的标志:在网页中,单击了某些图片、有下划线或有明示链接的文字就会跳转到相应的网页中去。
操作方法如下:1、在网页中选中要做超级链接的文字或者图片。
2、在属性面板中单击“链接”栏后的黄色文件夹按钮,在弹出的对话框里选中相应的网页文件就完成了。
做好超级链接属性面板出现链接文件显示。
(如下图)3、保存文件,按F12预览网页。
在浏览器里光标移到超级链接的地方就会变成手型。
〖提示〗你也可以手工在链接输入框中输入地址。
给图片加上超级链接的方法和文字完全相同。
扩展:如果超级链接指向的不是一个网页文件。
而是其他文件例如zip、exe文件等等,单击链接的时候就会下载文件。
超级链接也可以直接指向地址而不是一个文件,那么单击链接直接跳转到相应的地址。
例如,在链接框里写上/那么,单击链接就可以跳转到网站制作教程网站。
【邮件地址的超级连接】在网页制作中,还经常看到这样的一些超级链接。
单击了以后,会弹出邮件发送程序,联系人的地址也已经填写好了。
这也是一种超级链接。
制作方法是:在编辑状态下,先选定要链接的图片或文字(比如:欢迎您来信赐教!),在插入菜单选“电子邮件链接”弹出如下对话框,填入E-Mail地址即可。
提示:还可以选中图片或者文字,直接在属性面板链接框中填写“mailto:邮件地址”。

HTML跳转及导航栏的制作方法1. HTML跳转的基本概念在网页设计和编写过程中,跳转是一个非常重要的功能。
通过跳转,用户可以在不同的页面之间进行导航,从而更好地浏览全球信息湾内容。
HTML中最常用的跳转方式是超信息(hyperlink),即通过<a>标签来创建信息,让用户点击文字或图片时可以跳转到其他页面或相应位置。
2. 超信息的基本语法在HTML中,超信息的基本语法如下:```html<a href="目标页面的URL">信息文本或图片</a>```其中,href属性用于指定信息的目标页面,可以是其他网页的位置区域,也可以是页面内的指定位置(如锚点)。
信息文本或图片则是用户点击时显示的内容。
3. 导航栏的制作方法导航栏是网页中常见的组件,用于提供全球信息湾的整体导航功能。
制作一个简单的水平导航栏可以通过HTML和CSS来实现。
在HTML 中创建一个无序列表,并设置列表项为导航信息:```html<ul><li><a href="首页.html">首页</a></li><li><a href="关于我们.html">关于我们</a></li><li><a href="产品.html">产品</a></li><li><a href="通信我们.html">通信我们</a></li></ul>```然后使用CSS来美化导航栏,设置样式、布局和动画效果,使其更加美观和易于操作。
4. 深入理解HTML跳转除了简单的静态跳转外,HTML还提供了一些更加复杂和灵活的跳转方式,如表单提交、页面定时跳转等。

⽤CSS_DIV画表格(table)进⾏⽹页排版【转】以往传统⽹页设计都喜欢使⽤table(表格)來建构⽹页,這樣的建构⽅式对于⽹页整体排版來讲并沒有太⼤的问题,可以完美相容于各个浏览器。
但是時代在进步,还在⽤table排⽹页感觉就有点过时了。
会这样说并不是想引起table和div之战,⽽是想要说对于⽹页的维护,table表格是⽐较⿇烦⼀点的,再加上程式码不太⼲净、过多的巢状,对于搜索引擎来讲,也⽐较难发现其中重要的部分。
那如果⽤CSS+DIV进⾏⽹页排版,就会⽐较好吗?基本上是可以这样讲,但是⼤家⼜会遇到⽹页校正的问题,⼀⼝⽓要调整四、五种版本的浏览器,这样很可能让⽹页设计者⼜跑回去⽤table表格排版。
但其实在CSS中,已经有语法是⽀援表格的了,并不是对表格进⾏样简单的样式定义,⽽是透过CSS的表格属性,完美画出表格,排除浏览器相容的问题,让传统的table排版的设计师,也可以快速转换。
本來想说使⽤table來产⽣清单排版,免除浏览器校正问题,但碍于搜索引擎对表格式的⽹页不好解析其內容,所以还是使⽤DIV排版,并默默的校正⼀堆浏览器。
但是这回因为⽹页化,因此所有的CSS与DIV⼏乎是重构的状态,所以在本來的分类⽂章清单中,样式也順便进⾏重构,可是问题來了?「重构=花时间」,因为要⽤CSS+DIV模拟成table的样式,如果⼀直使⽤float來排版,校正上其实很⿇烦,当然在浏览器的校正上,更是头⼤。
后來找了⼀下发现有不错的好东西,在diplay的属性上,有table相关的属性值可以使⽤!传统的table排版的问题⼀般來讲,table打好语法就可以呈现效果了,⽽且语法很简单,就单纯的table、tr、td,这三个语法就可以画出表格,在各个浏览器下也都可以正常的显⽰。
如果觉得排版不漂亮,就直接在语法內加上width、color等等的属性值,效果很容易就达到了,可是这样会让程式码杂乱。
对于搜寻引擎來讲,他们抓⽹站內容通常不会⼀次抓完,会先抓到⼀定的⽹页⼤⼩,之后再來,如果你把样式调整的程式码都放进去,很快的,搜寻引擎可能光收录你的表格样式,还沒抓到重点就已经达到抓取額度了,重要的资料沒被收录,倒是收录了⼀些不重要的样式设定。

h5页面制作软件教程篇一:iH5基础教程:HTML5编辑器介绍iH5基础教程:HTML5编辑器介绍一、公司介绍iH5是国际领先的HTML5制作工具和服务平台,你可以使用iH5轻松制作具有丰富动态效果的HTML5网页应用,可视化操作界面,无需编程基础。
二、网站结构1、 注册登录页面填写信息注册账号或点击右上角进入登录页面。
2、 ih5首页(1)作品推荐点击封面可查看作品,点击左上角可收藏此作品,点击右上角可获得作品二维码与作品链接,点击关注可关注作品的作者。
查看作品时,点击右上角可全屏观看,还可以关注作者或联系作者。
关注的设计师会出现在首页目录系统消息之下。
点击精品模板,可以按分类查看模板,点击下载按钮可下载模板,下载后将保存到您的个人主页下面,下载付费模板需充值V币,模板下载后不能另存为或再次发布成为模板。
(2)学习使用点击首页右下角学习使用按钮,可进入教学页面。
按基础篇、初级篇、中级篇、高级篇查看教学视频,也可以功能/应用详解。
(3)新建案例点击右下角新建案例或点击首页左上角帐户名进入个人页面,可以创建新的案例,篇二:移动端H5页面设计实战移动端H5页面设计实战目录为什么要设计H5页面 .................................................................. (2)赛程魔方3D旋转界面设计 .................................................................. . (4)双屏互动游戏设计 .................................................................. .. (8)资讯与游戏的结合设计 .................................................................. .. (11)刮刮乐在移动端互动游戏中的微创新 ..................................................................15互动调查小游戏的设计创新 .................................................................. . (19)设计小贴士 .................................................................. (23)为什么要设计H5页面移动设备的普及给媒体和娱乐带来了一场革命。
网页设计和发布流程第一步是对站点进行规划第二步是创建站点的基本结构第三步即可开始具体的网页创作过程最后一步是站点的发布第一节站点的规划与创建【教学目的与要求】一、规划站点二、创建一个站点【教学方法与手段】多媒体教学:借助多媒体手段,进行课堂理论教学;启发式教学:教学活动关注的重点从结果转向过程。
激发思维,师生互动,增强学生学习的主动性、积极性和创造性;【教学重点与难点】:基础知识:规划站点重点知识:创建一个站点2课时【教学组织过程】2课时1.上讲回顾2.教授新知【授课内容】一、规划站点Web站点是一组具有共享属性(如相关主题、类似的设计或共同目的等)的链接文档。
本地站点:是本地硬盘中存放远程网站所有文档的地方(文件夹)。
建立网站的通常做法是:在要地硬盘中建立一个文件夹用来存放网站的所有文件,往后就在该文件夹中创建和编辑文档。
待网页设计和测试好之后,再把它们拷贝到网站上供浏览者浏览。
1、规划站点结构注:规划站点的结构之前应先用笔绘出站点的结构图(如下图所示是一个典型的学校站点的结构图)2、规划站点的浏览机制一般可采用以下的方法:创建返回主页的链接显示网站专题目录显示当前位置搜索和索引反馈(将网页创作者或网站管理员公布在网页上,或创建一个E-MAIL 超级链接,以使用户能快速地将信息反馈到网站中)二、创建一个站点步骤:1、单击“文件”---“新建”---“站点”命令(或单击常用工具栏中“新建网页”按钮的下拉箭头,从打开的下拉菜单中选择“站点”命令)2、选择一种站点模板或向导3、单击“确定”按钮三、站点的基本操作1、打开站点:“文件”---“打开站点”2、删除站点:方法一:在Windows资源管理器中删除一个站点方法二:在FrontPage中删除站点,在“文件夹”视图或“网页”视图的“文件夹列表”中,右击站点所对应的目录,在快捷菜单中单击“删除”命令3、站点的设置“工具”----“站点设置”,有“常规”、“参数”、“高级”、“语言”、“导航”、“数据库”六个选项卡【课程小结】【作业】1.5 课后练习书本课后练习作业第二节利用表格进行网页布局【教学目的与要求】一、插入表格二、单元格的基本操作【教学方法与手段】多媒体教学:借助多媒体手段,进行课堂理论教学;启发式教学:教学活动关注的重点从结果转向过程。
难得啊!通达信、同花顺、大智慧收费实时DDE超赢机构版终于被完美破解了!大家可以永远免费使用!请看详细的破解方法/wg.htm目前流行的通达信、同花顺、大智慧都可以和61kankan完美地结合使用,功能比收费版更强大,堪称超级破解版!使用起来非常实惠方便。
下面分别详细介绍破解设置方法。
使用这三种之外软件的朋友可以直接打开浏览器使用,就是要手工输入股票代码,不能点击即查,稍微麻烦一些,但也很实用哦!一、如何在通达信软件中使用61kankan网全能外挂?通达信level2版:可以采用定制初始版面和使用外挂两种方式来方便地使用61kankan 网。
1.把61kankan网定制为初始版面:初始版面就是打开软件就使用的版面。
这里提供一个我们制作的较完美的初始版面,供大家参考。
如图,选中深振业A000006,底下61kankan网会自动选择深振业A 000006搜索,并显示相应股票数据,再任意点你的想看的查询项就OK了。
使用极其方便。
如果朋友们想使用这个版面,可以直接点击下载:留意看看.rar,保存后解压,然后登陆通达信软件-点击顶部菜单功能-定制版面-版面管理器-导入版面-选择留意看看.sp-打开-关闭就定制成功了,然后点击顶部菜单功能-定制版面-设置初始版面-选择留意看看,方框打勾-确定,这个版面就设置成初始版面了,打开软件就可以使用它了,确实方便。
如果不喜欢这个版面,也可以参照下文自己设置。
目前最流行的通达信和大智慧level2版本都支持定制版面功能。
各券商都有通达信level2版本,下载地址见下面附录,均为官方链接地址,请放心下载安装使用。
以通达信为例,请按照下列步骤操作:(大智慧详细设置步骤见本网论坛/bbs/read.php?tid=13)a、登陆通达信软件,点击顶部菜单功能-定制版面-新建空白版面-确定-在空白版面上点击右键-下插入,这时版面就分为上下两部分了(此时如下图):b、然后在空白版面下半部分点击右键--设置单元类型-行情报价-所有市场报价(此时如下图):/iguba/go.asp?Key=xxxxxx&NO=262&CLS=17或者点击一下,该网址即可复制成功,请点击>>>然后点击确定(如下图),这时可以看到如下版面:【注】:此时看以看到,鼠标双击点哪只股票,上面的评估数据会自动变成该股票的数据,点哪变哪!各项评估数据齐全,一网打尽,极为方便实用!d、在下半部版面上点击右键-退出设置版面-中文名称:留意看看-确定e、点击菜单--功能--定制版面--设置初始版面--选择留意看看--确定,这样以后每次登陆该通达信软件后即可显示以上版面。
兔展制作h5页面教程篇一:兔展最新版帮助手册一兔展最新版帮助手册(1) 1、使用什么浏览器制作兔展?您好,建议您使用最新版的谷歌浏览器(或safari)访问兔展,其他浏览器由于设置问题,可能会出现与H5使用不兼容的情况,影响您的精心制作体验。
2、兔展账号注册帐户需要注意什么呢?您好,请用真实的、常用的邮箱申领兔展的账号,注册账号使用的邮箱请不要含有非法字符,兔兔会有提示。
3、如何新建场景?您好,在兔展官网登录账号后,点击制作页面左上角的新建开始制作作品。
4、如何使用模板?您好,兔展有为用户提供各种风格和不同主题的模板,用户可以选择使用。
不需要使用模板的用户也可以选择用到空白模板自己制作。
5、如何制作作品?您好,兔展平台有分横屏制作和竖屏制作,制作方法都是一样的,只需选择对应的功用,添加需要使用的素材,然后进行编辑后处理,详情可访问兔展官方论坛查看一分钟入门操作指引.6、如何使用更多字体?您好,兔展作为行业首家上线多功能字体(共11种)的微场景制作平台,新增了部分使用频率较高的字体,您可以直接在线重新安装使用,具体操作方法访问兔展官方论坛,查看操作指引.7、兔展作品背景图片的格式、尺寸比例、分辨率、大小分别是多少?您好,兔展作品的背景图片可以使用JPG、DNG、GIF格式的,尺寸比例是640*960,分辨率是72,大小是1M以下,因此建议您在设计背景图片时,按以上要求制作。
8、作品图片上传后,能否旋转、自定义设置?您好,兔展可以实现图片的旋转和自定义,您可以旋转改变片段的角度,也可以自定义图片比例微小。
如果您担心图片数量没有调好,可以先勾选“原比例”,图片就会根据您填写的宽度,按原机构调整比例自动调整图片的高度。
9、如何编辑背景透明的图片?您好,您可以借助倚靠一些图片编辑工具(如ps,美图秀秀等),先将可能需要原来使用的素材抠下来,然后将素材保存为PNG格式上传兔展使用。
10、如何查看表单资料?您好,增加表单功能后,在制作页面右上角的表单数据里面相对应的表单,就可以查看并导出表单数据了。