回归分析例题
- 格式:doc
- 大小:87.00 KB
- 文档页数:4
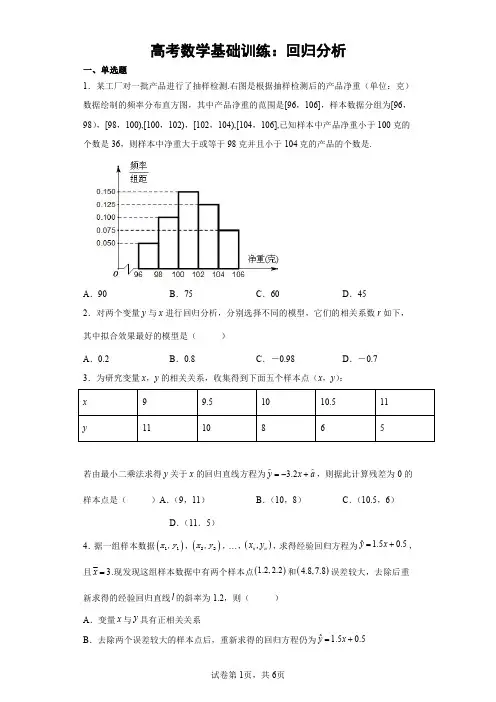
高考数学基础训练:回归分析一、单选题1.某工厂对一批产品进行了抽样检测.右图是根据抽样检测后的产品净重(单位:克)数据绘制的频率分布直方图,其中产品净重的范围是[96,106],样本数据分组为[96,98),[98,100),[100,102),[102,104),[104,106],已知样本中产品净重小于100克的个数是36,则样本中净重大于或等于98克并且小于104克的产品的个数是.A .90B .75C .60D .452.对两个变量y 与x 进行回归分析,分别选择不同的模型,它们的相关系数r 如下,其中拟合效果最好的模型是()A .0.2B .0.8C .-0.98D .-0.73.为研究变量x ,y 的相关关系,收集得到下面五个样本点(x ,y ):x 99.51010.511y1110865若由最小二乘法求得y 关于x 的回归直线方程为 3.2y x a=-+,则据此计算残差为0的样本点是()A .(9,11)B .(10,8)C .(10.5,6)D .(11.5)4.据一组样本数据()11,x y ,()22,x y ,…,(),n n x y ,求得经验回归方程为ˆ 1.50.5yx =+,且3x =.现发现这组样本数据中有两个样本点()1.2,2.2和()4.8,7.8误差较大,去除后重新求得的经验回归直线l 的斜率为1.2,则()A .变量x 与y 具有正相关关系B .去除两个误差较大的样本点后,重新求得的回归方程仍为ˆ 1.50.5yx =+C .去除两个误差较大的样本点后,y 的估计值增加速度变快D .去除两个误差较大的样本点后,相应于样本点()2,3.75的残差为0.055.对于样本相关系数,下列说法错误的是()A .可以用来判断成对样本数据相关的正负性B .可以是正的,也可以是负的C .样本相关系数越大,成对样本数据的线性相关程度也越高D .取值范围是[]1,1-6.下列说法中正确的是A .先把高二年级的2000名学生编号:1到2000,再从编号为1到50的学生中随机抽取1名学生,其编号为m ,然后抽取编号为50,100,150,m m m +++ 的学生,这种抽样方法是分层抽样法B .线性回归直线ˆˆy bxa =+不一定过样本中心()x y C .若两个随机变量的线性相关性越强,则相关系数r 的值越接近于1D .若一组数据2,4,a ,8的平均数是5,则该组数据的方差也是57.某同学用收集到的6组数据对(),(1,2,3,4,5,6)i i x y i =制作成如图所示的散点图(点旁的数据为该点坐标),并由最小二乘法计算得到回归直线1l 的方程:µµ11y b x a =+$,相关系数为1r ,相关指数为21R :经过残差分析确定点E 为“离群点”(对应残差过大的点),把它去掉后,再用剩下的5组数据计算得到回归直线2l 的方程:µµ22y b x a =+$,相关系数为2r ,相关指数为22R .则以下结论中,正确的是()①10r >,20r >;②µ10b >,µ20b >;③µµ12b b >;④2212R R >A .①②B .①②③C .②④D .②③④8.已知变量y 关于x 的非线性经验回归方程为0.5ˆe bx y-=,其一组数据如下表所示:x 1234ye3e 4e 5e 若5x =,则预测y 的值可能为()A .152e B .112e C .7e D .5e 第II 卷(非选择题)请点击修改第II 卷的文字说明二、填空题9.高中女学生的身高预报体重的回归方程是 0.7575.5y x =-(其中x , y 的单位分别是cm ,kg ),则此方程在样本()160,46处残差的绝对值是______.10.甲、乙、丙、丁四位同学在建立变量x ,y 的回归模型时,分别选择了4种不同模型,计算可得它们的相关指数R 2分别如下表:甲乙丙丁R 20.980.780.500.85建立的回归模型拟合效果最好的同学是__________.11.在一组样本数据()11,x y ,()22,x y ,…,(),n n x y (122,,,,n n x x x ≥⋅⋅⋅不全相等)的散点图中,若所有样本点()(),1,2,3,,i i x y i n =⋅⋅⋅都在直线210x y +-=上,则这组样本数据的相关系数r 为______.12.在一组样本数据()11,x y ,()22,x y ,…,()66,x y 的散点图中,若所有样本点(),i i x y ()1,2,,6i = 都在曲线212y bx =-附近波动.经计算6112i i x ==∑,6114i i y ==∑,62123ii x==∑,则实数b 的值为________.三、解答题13.某科技公司研发了一项新产品A ,经过市场调研,对公司1月份至6月份销售量及销售单价进行统计,销售单价x (千元)和销售量y (千件)之间的一组数据如下表所示:月份i 123456销售单价i x 99.51010.5118销售量iy 111086515(1)试根据1至5月份的数据,建立y 关于x 的回归直线方程;(2)若由回归直线方程得到的估计数据与剩下的检验数据的误差不超过065.千件,则认为所得到的回归直线方程是理想的,试问(1)中所得到的回归直线方程是否理想?参考公式:回归直线方程ˆˆˆybx a =+,其中i ii 122ii 1ˆnnx y n x yb xnx==-⋅⋅=-∑∑.参考数据:5i i i 1392x y ==∑,52i i 1502.5x ==∑.14.为了巩固拓展脱贫攻坚的成果,振兴乡村经济,某知名电商平台决定为脱贫乡村的特色水果开设直播带货专场.该特色水果的热卖黄金时段为2021年7月10日至9月10日,为了解直播的效果和关注度,该电商平台统计了已直播的2021年7月10日至7月14日时段中的相关数据,这5天的第x 天到该电商平台专营店购物的人数y (单位:万人)的数据如下表:日期7月10日7月11日7月12日7月13日7月14日第x 天12345人数y (单位:万人)75849398100(1)依据表中的统计数据,请判断该电商平台的第x 天与到该电商平台专营店购物的人数y (单位:万人)是否具有较高的线性相关程度?(参考:若0.30.75r <<,则线性相关程度一般,若0.75r >,则线性相关程度较高,计算r 时精确度为0.01)(2)求购买人数y 与直播的第x 天的线性回归方程;用样本估计总体,请预测从2021年7月10日起的第38天到该专营店购物的人数(单位:万人).参考数据:521(434i iy y =-=∑,51(64i i i x x y y =--=∑65.979≈.附:相关系数()()ni i x x y y r --=∑,回归直线方程的斜率121()()()niii nii x x y y bx x ==--=-∑∑ ,截距a y bx =-$$.15.近年来,明代著名医药学家李时珍故乡黄冈市蕲春县大力发展大健康产业,蕲艾产业化种植已经成为该县脱贫攻坚的主要产业之一,已知蕲艾的株高y (单位:cm)与一定范围内的温度x (单位:℃)有关,现收集了蕲艾的13组观测数据,得到如下的散点图:现根据散点图利用y a =+或dy c x=+建立y 关于x 的回归方程,令s =1t x=得到如下数据:xyst10.15109.943.040.16113niii s ys y=-⋅∑13113iii t yt y=-⋅∑1322113ik ss=-∑1322113ii t t =-∑ 1322113ii yy =-∑13.94-2.111.670.2121.22且(i s ,i y )与(i t ,i y )(i =1,2,3,…,13)的相关系数分别为1r ,2r ,且2r =﹣0.9953.(1)用相关系数说明哪种模型建立y 与x 的回归方程更合适;(2)根据(1)的结果及表中数据,建立 y 关于x 的回归方程;(3)已知蕲艾的利润z 与x 、y 的关系为1202z y x =-,当x 为何值时,z 的预报值最大.参考数据和公式:0.21×21.22=4.4562,11.67×21.22=247.637415.7365,对于一组数据(i u ,i v )(i =1,2,3,…,n ),其回归直线方程v u αβ=+的斜率和截距的最小二乘法估计分别为 1221ni i i nii u vnu v unuβ==-⋅=-∑∑, v u αβ=-,相关系数ni i u vnu vr -⋅∑.参考答案:1.A 【解析】【详解】样本中产品净重小于100克的频率为(0.050+0.100)×2=0.3,频数为36,∴样本总数为.∵样本中净重大于或等于98克并且小于104克的产品的频率为(0.100+0.150+0.125)×2=0.75,∴样本中净重大于或等于98克并且小于104克的产品的个数为120×0.75=90.考点:频率分布直方图.2.C 【解析】【分析】由相关系数的绝对值越大,越具有强大相关性,即可求解【详解】∵相关系数的绝对值越大,越具有强大相关性,C 相关系数的绝对值最大约接近1,∴C 拟合程度越好.故选:C 3.B 【解析】【分析】先求出线性方程的样本中心点,从而可求得 3.240y x =-+,再根据残差的定义可判断.【详解】由题意可知,99.51010.511105x ++++==,111086585y ++++==所以线性方程的样本中心点为(10,8),因此有 8 3.21040aa =-⨯+⇒=,所以 3.240y x =-+,在收集的5个样本点中,(10,8)一点在 3.240y x =-+上,故计算残差为0的样本点是(10,8).故选:B 4.A 【解析】【分析】由条件可知样本中心不变,可求出新的回归直线方程,即可判断.【详解】因为重新求得的经验回归直线l 的斜率为1.2,所以变量x 与y 具有正相关关系,故A 正确;当3x =时,315055y ..=⨯+=,设去掉两个误差较大的样本点后,横坐标的平均值为x ',纵坐标的平均值为y ',则12636322n x x x x n n n ++⋅⋅⋅+--=--'==,1210510522n y y y n n n y ++⋅⋅⋅+--'==--=,因为去除两个误差较大的样本点后,重新求得回归直线l 的斜率为1.2,所以ˆ53 1.2a =⨯+,解得 1.4ˆa =,所以去除两个误差较大的样本点后的经验回归方程为ˆ 1.2 1.4yx =+,故B 错误;因为1.5 1.2>,所以去除两个误差较大的样本点后y 的估计值增加速度变慢,故C 错误;因为ˆ 1.22 1.4 3.8y=⨯+=,所以ˆ 3.75 3.80.05y y -=-=-,故D 错误.故选:A.5.C 【解析】【分析】根据相关系数的概念,依次分析各选项即可得答案.【详解】解:对于A 选项,当相关系数为正时,表明变量之间是正相关,相关系数为负数时,表明相关系数为负数,故A 选项正确;对于B ,D 选项,相关系数范围是[]1,1-,故可以为正,也可以为负,故B ,D 选项正确;对于C 选项,当相关系数为负数时,样本相关系数越大,线性相关性就越弱,故C 选项错误;故选:C6.D 【解析】A 是系统抽样,B 选项线性回归直线ˆˆy bxa =+一定过样本中心(),x y ,C 选项若两个随机变量的线性相关性越强,则相关系数r 的绝对值越接近于1,D 选项若一组数据2,4,a ,8的平均数是5,求出a ,则该组数据的方差即可求解.【详解】A 选项:先把高二年级的2000名学生编号:1到2000,再从编号为1到50的学生中随机抽取1名学生,其编号为m ,然后抽取编号为50,100,150,m m m +++ 的学生,这种抽样方法是系统抽样法,所以该选项不正确;B 选项:线性回归直线ˆˆy bxa =+一定过样本中心(),x y ,所以该选项不正确;C 选项:若两个随机变量的线性相关性越强,则相关系数r 的绝对值越接近于1,所以该选项不正确;D 选项:若一组数据2,4,a ,8的平均数是5,24854a +++=,解得6a =,则该组数据的方差是()()()()22222545658554-+-+-+-=,所以该选项正确.故选:D 【点睛】此题考查抽样方法,回归直线,相关关系的辨析,求平均数和方差,关键在于熟练掌握相关概念和公式,准确计算.7.B 【解析】【分析】根据散点图逐项进行判断即可.【详解】①:由散点图可知,,x y 之间是正相关关系,所以10r >,20r >,故①正确;②③:由散点图可知,回归直线的斜率是正数,且1l 的斜率大于2l 的斜率,所以µ10b >,µ20b >,µµ12b b >,故②③正确;④:由散点图可知,去掉“离群点”E 后,相关性更强,拟合的效果更好,所以2212R R <,故④错误;故选:B.8.C 【解析】【分析】将0.5ˆe bx y-=两边同时取对数,得ln 0.5y bx =-,设0.5z bx =-,由样本中心()x z 必在回归直线0.5z bx =-上,可求出b ,从而即可求解.【详解】解:由题意,将0.5ˆe bx y-=两边同时取对数,得ln 0.5y bx =-,设0.5z bx =-,则x1234z13451234 2.54x +++==,13453.254z +++==,由0.5z bx =-,得3.25 2.50.5b =-,解得 1.5b =,所以 1.50.5e x y -=,所以当5x =时, 1.550.57e e y ⨯-==,故选:C.9.1.5##32【解析】【分析】利用回归直线方程,求出160x =的估计值,然后求解残差的绝对值.【详解】由样本数据得到,女大学生的身高预报体重的回归方程是 0.7575.5y x =-,当160x =时, 0.7516075.544.5y =⨯-=,此方程在样本()160,46处残差的绝对值:44.546 1.5-=.故答案为:1.5.10.选甲相关指数R 2越大,表示回归模型拟合效果越好.【解析】【分析】相关指数越大,相关性越强,拟合效果越好.根据相关指数的大小即可判断.【详解】相关指数2R 越大,相关性越强,回归模型拟合效果越好,所以效果最好的是甲.【点睛】如果两个变量间的关系是相关关系,相关指数2R 越大,相关系数r 越接近1,残差平方和越接近0,都代表拟合效果越好.11.1-【解析】【分析】根据直线斜率可知两个变量负相关,结合数据点都在直线上可确定1r =-.【详解】直线210x y +-=的斜率20k =-<,∴这两个变量成负相关,0r ∴<,又所有样本点都在直线210x y +-=上,1r ∴=-.故答案为:1-.12.1723【解析】【分析】设2t x =,可得回归直线方程为12y bt =-,求出样本中心点(),t y 代入可得b 的值.【详解】令2t x =则212y bx =-即12y bt =-,6212366i i x t ===∑,61147663ii y y ====∑,因为样本中心点237,63⎛⎫ ⎪⎝⎭在回归直线12y bt =-上,所以7231362b =-,可得:1723b =,故答案为:1723.13.(1)ˆ3240y x =-+.;(2)是.【解析】【分析】(1)先由表中的数据求出,x y ,再利用已知的数据和公式求出 ,ba ,从而可求出y 关于x 的回归直线方程;(2)当8x =时,求出 y 的值,再与15比较即可得结论【详解】(1)因为()199.51010.511105x =++++=,()1111086585y =++++=,所以23925108ˆ 3.2502.5510b -⨯⨯==--⨯,得()ˆ8 3.21040a=--⨯=,于是y 关于x 的回归直线方程为 3.240ˆyx =-+;(2)当8x =时,ˆ 3.284014.4y=-⨯+=,则ˆ14.4150.60.65yy -=-=<,故可以认为所得到的回归直线方程是理想的.14.(1)具有较高的线性相关程度(2) 6.470.8y x =+,314万人【解析】【分析】(1)由已知计算相关系数r 即可.(2)由列表计算 a、b ,可得线性回归方程进一步可得解.(1)由表中数据可得3,90x y ==,所以521()10i i x x =-=∑,又55211()434,()()64i i i i i y y x x y y ==-=--=∑∑,所以()()50.970.75i i x x y y r --=>∑,所以该电商平台直播黄金时段的天数x 与购买人数y 具有较高的线性相关程度.所以可用线性回归模型拟合人数y 与天数x 之间的关系.(2)由表中数据可得()()()5152164ˆ 6.410i i i i i x x y y b x x ==--===-∑∑,则ˆˆ90 6.4370.8a y bx =-=-⨯=,所以 6.470.8y x =+,令38x =,可得 6.4387031ˆ.84y =⨯+=(万人)15.(1)用d y c x =+模型建立y 与x 的回归方程更合适;(2)10ˆ111.54y x =-;(3)当温度为20时这种草药的利润最大.【解析】【分析】(1)利用相关系数1r ,2r ,比较1||r 与2||r 的大小,得出用模型d y c x=+建立回归方程更合适;(2)根据(1)的结论求出y 关于x 的回归方程即可;(3)由题意写出利润函数ˆz ,利用基本不等式求得利润z 的最大值以及对应的x 值.【详解】(1)由题意知20.9953r =-,10.8858r =,因为121r r <<,所有用d y c x =+模型建立y 与x 的回归方程更合适.(2)因为1311322113 2.1ˆ100.2113i i i i i t y t yd tt ==-⋅-===--∑∑,ˆˆ109.94100.16111.54cy dt =-=+⨯=,所以ˆy 关于x 的回归方程为10ˆ111.54y x=-(3)由题意知11012020(111.54ˆˆ)22z y x x x =-=--20012230.8()2x x =-+2230.8202210.8≤-=,所以22.8ˆ10z≤,当且仅当20x =时等号成立,所以当温度为20时这种草药的利润最大.。


专题5 回归分析例1.已知回归方程y=5x+1,则该方程在样本(1,4)处的残差为()A.﹣2B.1C.2D.5【解析】解:当x=1时,y=5x+1=6,∴方程在样本(1,4)处的残差是4﹣6=﹣2.故选:A.例2.研究变量x,y得到一组样本数据,进行回归分析,有以下结论①残差平方和越小的模型,拟合的效果越好;②用相关指数R2来刻画回归效果,R2越小说明拟合效果越好;③在回归直线方程y=−0.2x+0.8中,当解释变量x每增加1个单位时,预报变量y平均减少0.2个单位;④若变量y和x之间的相关系数为r=﹣0.9462,则变量y和x之间的负相关很强.以上正确说法的是①③④.【解析】解:①可用残差平方和判断模型的拟合效果,残差平方和越小,模型的拟合效果越好,故①正确;②用相关指数R2来刻画回归效果,R2越大说明拟合效果越好,故②错误;③在回归直线方程y=−0.2x+0.8中中,当解释变量x每增加1个单位时,预报变量y平均减少0.2个单位,故③正确;④若变量y和x之间的相关系数为r=﹣0.9462,r的绝对值趋向于1,则变量y和x之间的负相关很强,故④正确.故答案为:①③④.例3.下列命题中,正确的命题有②③.①回归直线y=b x+a恒过样本点中心(x,y),且至少过一个样本点;②用相关指数R2来刻画回归效果,表示预报变量对解释变量变化的贡献率,R2越接近于1说明模型的拟合效果越好;③残差图中残差点比较均匀的落在水平的带状区域中,说明选用的模型比较合适;④两个模型中残差平方和越大的模型的拟合效果越好.【解析】解:①回归直线y=b x+a恒过样本点中心(x,y),不一定过样本点,故①正确;②用相关指数R2来刻画回归效果,表示预报变量对解释变量变化的贡献率,R2越接近于1说明模型的拟合效果越好,正确;③残差图中残差点比较均匀的落在水平的带状区域中,说明选用的模型比较合适,正确;④两个模型中残差平方和越大的模型的拟合效果越差.故④错误,故正确的是②③,故答案为:②③例4.下列命题:①相关指数R2越小,则残差平方和越大,模型的拟合效果越好.②对分类变量X与Y的随机变量K2的观测值k来说,k越小,“X与Y有关系”可信程度越大.③残差点比较均匀地落在水平带状区域内,带状区域越宽,说明模型拟合精度越高.④两个随机变量相关性越强,则相关系数的绝对值越接近0.其中错误命题的个数为4.【解析】解:对于①,相关指数R2越小,则残差平方和越大,此时模型的拟合效果越差,所以①错误;对于②,对分类变量X与Y的随机变量K2的观测值k来说,k越小,“X与Y有关系”可信程度越小,所以②错误;对于③,残差点比较均匀地落在水平带状区域内,带状区域越宽,说明模型拟合精度越低,所以③错误;对于④,两个随机变量相关性越强,则相关系数的绝对值越接近1,所以④错误.综上知,错误命题的序号是①②③④,共4个.故答案为:4.例5.垃圾是人类日常生活和生产中产生的废弃物,由于排出量大,成分复杂多样,且具有污染性,所以需要无害化、减量化处理.某市为调査产生的垃圾数量,采用简单随机抽样的方法抽取20个县城进行了分析,得到样本数据(x i,y i)(i=1,2,……,20),其中x i和y i分别表示第i个县城的人口(单位:万人)和该县年垃圾产生总量(单位:吨),并计算得∑20i=1x i=80,∑20i=1y i=4000,∑20i=1(x i−x)2=80,∑20i=1(y i−y)2=8000,∑20i=1(x i−x)(y i−y)=7000.(1)请用相关系数说明该组数据中y与x之间的关系可用线性回归模型进行拟合;(2)求y关于x的线性回归方程;(3)某科研机构研发了两款垃圾处理机器,如表是以往两款垃圾处理机器的使用年限(整年)统计表:1年2年3年4年5年使用年限台数款式甲款520151050乙款152010550某环保机构若考虑购买其中一款垃圾处理器,以使用年限的频率估计概率.根据以往经验估计,该机构选择购买哪一款垃圾处理机器,才能使用更长久?参考公式:相关系数r=∑n i=1i−x)(y i−y)√∑i=1(x i−x)∑i=1(y i−y)2.对于一组具有线性相关关系的数据(x i,y i)(i=1,2,……,n),其回归直线y=b x+a的斜率和截距的最小二乘估计分别为:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2,a=y−b x.【解析】解:(1)由题意知相关系数r=∑20i=1i−x)(y i−y)√∑i=1(x i−x)2∑i=1(y i−y)2=√80×8000=78=0.875,因为y与x的相关系数接近1,所以y与x之间具有较强的线性相关关系,可用线性回归模型进行拟合.(2)由题意可得,b=∑20i=1(x i−x)(y i−y)∑20i=1(x i−x)2=70080=8.75,a=y−b x=400020−8.75×8020=200−8.75×4=165,所以y=8.75x+165.(3)以频率估计概率,购买一台甲款垃圾处理机器节约政府支持的垃圾处理费用X(单位:万元)的分布列为X﹣50050100P0.10.40.30.2E(X)=﹣50×0.1+0×0.4+50×0.3+100×0.2=30(万元)购买一台乙款垃圾处理机器节约政府支持的垃圾处理费用Y(单位:万元)的分布列为:Y﹣302070120P0.30.40.20.1E(Y)=﹣30×0.3+20×0.4+70×0.2+120×0.1=25(万元)因为E(X)>E(Y),所以该县城选择购买一台甲款垃圾处理机器更划算.例6.某基地蔬菜大棚采用水培、无土栽培方式种植各类蔬菜.据统计该基地的西红柿增加量y(百斤)与使用某种液体肥料x(千克)之间对应数据为如图所示的折线图.(1)依据数据的折线图,请计算相关系数r(精确到0.01),并以此判定是否可用线性回归模型拟合y 与x的关系?若是请求出回归直线方程,若不是请说明理由;(2)过去50周的资料显示,该地周光照量X(小时)都在30小时以上,其中不足50小时的周数有5周,不低于50小时且不超过70小时的周数有35周,超过70小时的周数有10周.蔬菜大棚对光照要求较大,某光照控制仪商家为该基地提供了部分光照控制仪,但每周光照控制仪最多可运行台数受周光照量X限制,并有如表关系:周光照量X(单位:小时)30<X<5050≤X≤70n≥2光照控制仪最多可运行台数542若某台光照控制仪运行,则该台光照控制仪周利润为3000元;若某台光照控制仪未运行,则该台光照控制仪周亏损1000元.若商家安装了5台光照控制仪,求商家在过去50周每周利润的平均值.附:对于一组数据(x1,y1),(x2,y2),……,(x n,y n),其相关系数公式r=∑n i=1i−x)(y i−y)√∑i=1i−x)2∑i=1i−y)2,回归直线y=b x+a的斜率和截距的最小二乘估计分别为:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=∑ni=1x i y i−nxy∑n i=1(x i−x)2,a=y−b x,参考数据√0.3≈0.55,√0.9≈0.95.【解析】解:(1)由已知数据可得x=2+4+5+6+85=5,y=3+4+4+4+55=4,因为∑5i=1(x i−x)(y i−y)=(−3)×(−1)+0+0+0+3×1=6,√∑5i=1(x i−x)2=√(−3)2+(−1)2+02+12+32=2√5,√∑5i=1(y i−y)2=√(−1)2+02+02+02+12=√2.所以相关系数r=∑n i=1i−x)(y i−y)√∑i=1i −x)2√∑i=1i−y)2=2√5⋅√2=√910≈0.95,因为r>0.75,所以可用线性回归模型拟合y与x的关系,因为b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=620=0.3,a=y−b x=2.5,所以回归直线方程y=0.3x+2.5.(2)记商家周总利润为Y元,由条件可得在过去50周里:X>70时,共有10周,只有2台光照控制仪运行,周总利润Y=2×3000﹣3×1000=3000元,当50≤X≤70时,共有35周,有4台光照控制仪运行,周总利润Y=4×3000﹣1×1000=11000元,当X<50时,共有5周,5台光照控制仪都运行,周总利润Y=5×3000=15000元,所以过去50周每周利润的平均值Y=3000×10+11000×35+15000×550=9800元,所以商家在过去50周每周利润的平均值为9800元.例7.湖南省从2021年开始将全面推行“3+1+2”的新高考模式,新高考对化学、生物、地理和政治等四门选考科目,制定了计算转换T分(即记入高考总分的分数)的“等级转换赋分规则”(详见附1和附2),具体的转换步骤为:①原始分Y等级转换;②原始分等级内等比例转换赋分.某校的一次年级统考中,政治、生物两选考科目的原始分分布如表:等级A B C D E比例约15%约35%约35%约13%约2%政治学科各等级对应的原始分区间[81,98][72,80][66,71][63,65][60,62]生物学科各等级对应的原始分区间[90,100][77,89][69,76][66,68][63,65]现从政治、生物两学科中分别随机抽取了20个原始分成绩数据,作出茎叶图:(1)根据茎叶图,分别求出政治成绩的中位数和生物成绩的众数;(2)该校的甲同学选考政治学科,其原始分为82分,乙同学选考生物学科,其原始分为91分,根据赋分转换公式,分别求出这两位同学的转化分;(3)根据生物成绩在等级B的6个原始分和对应的6个转化分,得到样本数据(Y i,T i),请计算生物原始分Y i与生物转换分T i之间的相关系数,并根据这两个变量的相关系数谈谈你对新高考这种“等级转换赋分法”的看法.附1:等级转换的等级人数占比与各等级的转换分赋分区间等级A B C D E原始分从高到低排序的等级人数占比约15% 约35% 约35% 约13% 约2%转换分T 的赋分区间[86,100] [71,85][56,70] [41,55] [30,40]附2:计算转换分T 的等比例转换赋分公式:Y 2−Y Y−Y 1=T 2−T T−T 1.(其中:Y 1,Y 2别表示原始分Y 对应等级的原始分区间下限和上限;T 1,T 2分别表示原始分对应等级的转换分赋分区间下限和上限.T 的计算结果按四舍五入取整).附3:∑ 6i=1(Y i −Y )(T i −T )=74,√∑ 6i=1(Yi −Y)2∑ 6i=1(T i −T)2=√5494≈74.12,r =∑n i=1i −Y)(T i −T)√∑i=1i −Y)2∑i=1i −T)2.【解析】解:(1)根据茎叶图知,政治成绩的中位数为72,生物成绩的众数为73; (2)甲同学选考政治学科的等级为A ,由转换赋分公式:98−8282−81=100−T T−86,解得T =87;乙同学选考生物学科的等级为A ,由赋分转换公式:100−9191−90=100−T T−86,解得T =87;所以甲、乙两位同学的转换分都是87分. (3)由题意知,r =∑n i=1i −Y)(T i −T)√∑ i=1(Y i −Y)2∑ i=1(T i −T)2=7474.12≈0.998, 说法1:等级转换赋分公平,因为相关系数十分接近1,接近函数关系,因此高考这种“等级转换赋分”具有公平性与合理性.说法2:等级转换赋分法不公平,在同一等级内,原始分与转化分是确定的函数关系,理论上原始分与转化分的相关系数为1,在实际赋分过程中由于数据的四舍五入,使得实际的转化分与应得的转化分有一定的误差,极小部分同学赋分后会出现偏高或偏低的现象. (只要说法有道理,都可以得分).例8.某市房管局为了了解该市市民2018年1月至2019年1月期间买二手房情况,首先随机抽样其中200名购房者,并对其购房面积m (单位:平方米,60≤m ≤130)进行了一次调查统计,制成了如图1所示的频率分布直方图,接着调查了该市2018年1月至2019年1月期间当月在售二手房均价y (单位:万元/平方米),制成了如图2所示的散点图(图中月份代码1﹣13分别对应2018年1月至2019年1月).(Ⅰ)试估计该市市民的购房面积的中位数m0;(Ⅱ)现采用分层抽样的方法从购房面积位于[110,130]的40位市民中随机抽取4人,再从这4人中随机抽取2人,求这2人的购房面积恰好有一人在[120,130]的概率;(Ⅲ)根据散点图选择y=a+b√x和y=c+d lnx两个模型进行拟合,经过数据处理得到两个回归方程,分别为y=0.9369+0.0285√x和y=0.9554+0.0306lnx,并得到一些统计量的值如表所示:y=0.9369+0.0285√x y=0.9554+0.0306lnx ∑13i=1(y i−y i)20.0005910.000164∑13i=1(y i−y)20.006050请利用相关指数R2判断哪个模型的拟合效果更好,并用拟合效果更好的模型预测出2019年12月份的二手房购房均价(精确到0.001).【参考数据】ln2≈0.69,ln3≈1.10,ln23≈3.14,ln25≈3.22,√2≈141,√3≈1.73,√23≈4.80.【参考公式】R2=1−∑ni=1(y i−y i)2∑n i=1(y i−y)2.【解析】解:(I)由频率分布直方图,可得,前三组频率和为0.05+0.1+0.2=0.35,前四组频率和为0.05+0.1+0.2+025=0.6,故中位数出现在第四组,且m0=90+10×0.150.25=96.(Ⅱ)设从位于[110,120)的市民中抽取x人,从位于[120,130]的市民中抽取y人,由分层抽样可知:440=x30=y10,则x=3,y=1,在抽取的4人中,记3名位于[11,120)的市民为A1,A2,A3,位于[120,130]的市民为B则所有抽样情况为:(A1,A2),(A1,A3),(A1,B),(A2,A3),(A2,B),(A3,B)共6种.而其中恰有一人在位于购房面积[120,130]的情况共有3种,故所求概率P=36=12,(III)设模型y=0.9369+0.0285√x和y=0.955+0.0306lnx的相关指数分别为R12,R22,则R12=1−0.0005910.006050,R22=1−0.0001640.006050,显然R12<R22,故模型y=0.9554+0.0306lnx的拟合效果更好.由2019年12月份对应的代码为24,则y=0.9554+0.0306ln24=0.9554+0.0306(3ln2+ln3)≈1.052万元/平方米.例9.某汽车公司拟对“东方红”款高端汽车发动机进行科技改造,根据市场调研与模拟,得到科技改造投入x(亿元)与科技改造直接收益y(亿元)的数据统计如表:x2346810132122232425y1322314250565868.56867.56666当0<x≤16时,建立了y与x的两个回归模型:模型①:y=4.1x+11.8;模型②:y=21.3√x−14.4;当x>16时,确定y与x满足的线性回归方程为:y=−0.7x+a.(Ⅰ)根据下列表格中的数据,比较当0<x≤16时模型①、②的相关指数R2,并选择拟合精度更高、更可靠的模型,预测对“东方红”款汽车发动机科技改造的投入为16亿元时的直接收益.回归模型模型①模型②回归方程y=4.1x+11.8y=21.3√x−14.4∑7i=1(y i−y i)2182.479.2(附:刻画回归效果的相关指数R2=1−∑n i=1(y i−y i)2∑n i=1(y i−y)2.)(Ⅱ)为鼓励科技创新,当科技改造的投入不少于20亿元时,国家给予公司补贴收益10亿元,以回归方程为预测依据,比较科技改造投入16元与20亿元时公司实际收益的大小;(附:用最小二乘法求线性回归方程y=b x+a的系数公式b=∑ni=1x i y i−nx⋅y∑n i=1x i2−nx2=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2;a=y−b x)(Ⅲ)科技改造后,“东方红”款汽车发动机的热效率X大幅提高,X服从正态分布N(0.52,0.012),公司对科技改造团队的奖励方案如下:若发动机的热效率不超过50%但不超过53%,不予奖励;若发动机的热效率超过50%但不超过53%,每台发动机奖励2万元;若发动机的热效率超过53%,每台发动机奖励4万元.求每台发动机获得奖励的数学期望.(附:随机变量ξ服从正态分布N(μ,σ2),则P(μ﹣σ<ξ<μ+σ)=0.6827,P(μ﹣2σ<ξ<μ+2σ)=0.9545.)【解析】解:(Ⅰ)由表格中的数据,有182.4>79.2,即182.4∑7i=1(y i−y)2>79.2∑7i=1(y i−y)2,∴模型①的R2小于模型②的R2,说明模型②的刻画效果更好.∴当x=16亿元时,科技改造直接收益的预测值为y=21.3×√16−14.4=70.8(亿元);(Ⅱ)由已知可得,x−20=0.5+2+3.5+4+55=3,则x=23,y−60=8.5+8+7.5+6+65=7.2,则y=67.2,∴a=y−0.7x=67.2+0.7×23=83.3,∴当x>16亿元时,y与x满足线性回归方程y=−0.7x+83.3,当x=20亿元时,科技改造直接收益的预测值为y=−0.7×20+83.3=69.3.∴当x=20亿元时,实际收益的预测值为69.3+10=79.3亿元>70.8亿元.∴科技改造投入20亿元时,公司的实际收益更大;(Ⅲ)∵P(0.52﹣0.02<X<0.52+0.02)=0.9545,∴P(X>0.50)=1+0.95452=0.97725,P(X≤0.50)=1−0.95452=0.02275,∵P(0.52﹣0.01<X<0.52+0.01)=0.6827,∴P(X>0.53)=1−0.68272=0.15865,∴P(0.50<X≤0.53)=0.97725﹣0.15865=0.8186.设每台发动机获得的奖励为Y(万元),则Y的分布列为:Y024P0.022750.81860.15865∴每台发动机获得的奖励的数学期望为:E(Y)=0×0.02275+2×0.8186+4×0.15865=2.2718(万元).例10.某高中数学建模兴趣小组的同学为了研究所在地区男高中生的身高与体重的关系,从若干个高中男学生中抽取了1000个样本,得到如下数据.数据一:身高在[170,180)(单位:cm)的体重频数统计体重(kg)[50,55)[55,60)[60,65)[65,70)[70,75)[75,80)[80,85)[85,90)人数206010010080201010数据二:身高所在的区间含样本的个数及部分数据身高x(cm)[140,150)[150,160)[160﹣170)[170﹣180)[180﹣190)平均体重y(kg)4553.66075(Ⅰ)依据数据一将下面男高中生身高在[170﹣180)(单位:cm)体重的频率分布直方图补充完整,并利用频率分布直方图估计身高在[170﹣180)(单位:cm)的中学生的平均体重;(保留小数点后一位)(Ⅱ)依据数据一、二,计算身高(取值为区间中点)和体重的相关系数约为0.99,能否用线性回归直线来刻画中学生身高与体重的相关关系,请说明理由;若能,求出该回归直线方程;(Ⅲ)说明残差平方和或相关指数R2与线性回归模型拟合效果之间关系.(只需写出结论,不需要计算)参考公式:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=∑ni=1x i y i−nx⋅y∑n i=1x i2−nx2,a=y−b x.参考数据:(1)145×45+155×53.6+165×60+185×75=38608;(2)1452+1552+1652+1752+1852﹣5×1652=1000.(3)663×175=116025,664×175=116200,665×175=116375.(4)728×165=120120.【解析】解:(1)身高在[170,180)的总人数为:20+60+100+100+80+20+10+10=400,体重在[55﹣60)的频率为:60400=0.15,体重在[70﹣75)的 频率为:80400=0.2,平均体重为:52.5×0.05+57.5×0.15+62.5×0.25+67.5×0.25+72.5×0.2 +77.5×0.05+82.5×0.025+87.5×0.025≈66.4,(2)因为 r =0.99→1,线性相关很强,故可以用线性回归直线来 刻画中学生身高与体重的相关, x =145+155+165+175+1855=165,y =45+75+60+53.6+66.45=60,b =∑ 8i=1x i y i −8x⋅y ∑ 8i=1x i 2−8x2=38608+175×66.4−5×165×601000=0.728, a =y −b x =60−0.728×165=−60.12, 所以回归直线方程为:y =0.728x −60.12,(3)残差平方和越小或相关指数 R 2 越接近于1,线性回归模型拟合效果越好.例11.2019年的“金九银十”变成“铜九铁十”,国各地房价“跳水”严重,但某地二手房交易却“逆市”而行.如图是该地某小区2018年11月至2019年1月间,当月在售二手房均价(单位:万元/平方米)的散点图.(图中月份代码1~13分别对应2018年11月~2019年11月)根据散点图选择y =a +b √x 和y =c +dlnx 两个模型进行拟合,经过数据处理得到两个回归方程分别为y ^=0.9369+0.0285√x和y^=0.9554+0.0306lnx,并得到以下一些统计量的值:y^=0.9369+0.0285√x y^=0.9554+0.0306lnx ∑13i=1(y i−y^i)20.0005910.000164∑13i=1(y i−y)20.006050(1)请利用相关指数R2判断哪个模型的拟合效果更好;(2)某位购房者拟于2020年4月购买这个小区m(70≤m≤160)平方米的二手房(欲购房为其家庭首套房).若购房时该小区所有住房的房产证均已满2但未满5年,请你利用(1)中拟合效果更好的模型解决以下问题:(i)估算该购房者应支付的购房金额;(购房金额=房款+税费,房屋均价精确到0.001万元/平方米)(ii)若该购房者拟用不超过100万元的资金购买该小区一套二手房,试估算其可购买的最大面积.(精确到1平方米)附注:根据有关规定,二手房交易需要缴纳若干项税费,税费是按房屋的计税价格(计税价格=房款)进行征收的.房产证满2年但未满5年的征收方式如下:首套面积90平方米以内(含90平方米)为1%;首套面积90平方米以上且140平方米以内(含140平方米)1.5%;首套面积140平方米以上或非首套为3%.参考数据:ln2≈0.69,ln3≈1.10,ln17≈2.83,ln19≈2.94,√2≈1.41,√3≈1.73,√17≈4.12,√19≈4.36.参考公式:相关指数R2=1−∑ni=1(y i−y^i)2∑n i=1(y i−y)2.【解析】解:(1)模型一中,y=0.9369+0.0285√x的残差平方和为0.000591,相关指数为R21−0.0005910.006050≈0.923,模型二中,y=0.9554+0.0306lnx的残差平方和为0.000164,相关指数为 R 21−0.0001640.006050≈0.973,∴ 相关指数较大的模型二拟合效果好些. (2)通过散点图确定2020年4月对应的 x =18, 代入(1)中拟合效果更好的模型二,代入计算 y =0.9554+0.0306ln18 =0.9554+0.0306×(ln 2+2ln 3) =0.9554+0.0306×(0.69+2×1.10) ≈1.044 (万元/平方米),则2020年4月份二手房均价的预测值为1.044(万元/平方米).(i )设该购房者应支付的购房金额 h 万元,因为税费中淵方只需缴纳契税, ①当70⩽m ⩽90 时,契税为计税价格的 1%, 故h =m ×1.044×(1%+1)=1.05444m ; ②当90<m ⩽144 时,契税为计税价格的 1.5%, 故h =m ×1.044×(1.5%+1)=1.05966m ; ③当144<m ⩽160 时,契税为计税价格的 3%, 故h =m ×1.044×(3%+1)=1.07532m ;∴ℎ={1.05444m ,70⩽m ⩽901.05966m ,90<m ⩽1441.07532m ,144<m ⩽160;∴ 当 70⩽m ⩽90 时购房金额为 1.05444m 万元, 当 90<m ⩽144 时购房金额为 1.05966m 万元, 当 144<m ⩽160 时购房金额为 1.07532m 万元.(ii )设该购房者可购买该小区二手房的最大面积为 t 平方米,由(i ) 知,当70⩽m ⩽90时,应支付的购房金额为 1.05444t ,又1.05444t ⩽1.05444×90<100, 又因为房屋均价约为1.044万元/平方米,所以 t <100,所以90⩽t <100, 由1.05966t ⩽100,解得 t ⩽1001.05966,且1001.05966≈94.4,所以该购房者可购买该小区二手房的最大面积为94平方米.例12.某新兴科技公司为了确定新研发的产品下一季度的营销计划,需了解月宣传费x (单位:万元)对月销售量y(单位:千件)的影响,收集了2020年3月至2020年8月共6个月的月宣传费x和月销售量y的数据如表:月份345678宣传费x5678910月销售量y0.4 3.5 5.27.08.610.7现分别用模型①y=b x+a和模型②y=e m x+n对以上数据进行拟合,得到回归模型,并计算出模型的残差如表:(模型①和模型②的残差分别为e1和e2,残差=实际值﹣预报值)x5678910y0.4 3.5 5.37.08.610.7e1﹣0.60.540.280.12﹣0.24﹣0.1e2﹣0.63 1.71 2.10 1.63﹣0.7﹣5.42(1)根据上表的残差数据,应选择哪个模型来拟合月宣传费x与月销售量y的关系较为合适,简要说明理由;(2)为了优化模型,将(1)中选择的模型残差绝对值最大所对应的一组数据(x,y)剔除,根据剩余的5组数据,求该模型的回归方程,并预测月宣传费为12万元时,该公司的月销售量.(剔除数据前的参考数据:x=7.5,y=5.9,∑6i=1x i y i=299.8,∑6i=1x i2=355,z=lny.z≈−1.41,∑6i=1x i y i=−73.10,ln10.7≈2.37,e4.034≈56.49.)参考公式:b=∑ni=1x i y i−nxy∑n i=1x i2−nx2,a=y−b x.【解析】解:(1)应选择模型①,因为模型①每组数据对应的残差绝对值都比模型②的小,残差波动小,残差点比较均匀地落在水平的带状区域内,说明拟合精度高.(2)由(1)知,需剔除第一组数据,则剔除后的x=7.5×6−55=8,y=5.9×6−0.45=7,5xy=280,5x2=320,∑5i=1x i y i=299.8−5×0.4=297.8,∑5i=1x i2=355−25=330.∴b=∑5i=1x i y i−5xy∑5i=1x i2−5x2=297.8−280330−320=1.78,a=y−b x=7−1.78×8=−7.24.得①的回归方程为y=1.78x−7.24,则当x=12时,y=1.78×12−7.24=14.12.故月宣传费为12万元时,该公司的月销售量为14.12千件.例13.新型冠状病毒肺炎COVID﹣19疫情发生以来,在世界各地逐渐蔓延.在全国人民的共同努力和各级部门的严格管控下,我国的疫情已经得到了很好的控制.然而,小王同学发现,每个国家在疫情发生的初期,由于认识不足和措施不到位,感染人数都会出现快速的增长.如表是小王同学记录的某国连续8天每日新型冠状病毒感染确诊的累计人数.日期代码x12345678累计确诊人数y481632517197122为了分析该国累计感染人数的变化趋势,小王同学分别用两种模型:①y=bx2+a,②y=dx+c对变量x和y的关系进行拟合,得到相应的回归方程并进行残差分析,残差图如下(注:残差e î=y i−y î):经过计算得它∑8i=1(x i−x)(y i−y)=728,∑8i=1(x i−x)2=42,∑8i=1(z i−z)(y i−y)=6868,∑8i=1(z i−z)2=3570,其中z i=x i2,z=18∑8i=1z i.(1)根据残差图,比较模型①,②的拟合效果,应该选择哪个模型?并简要说明理由;(2)根据(1)问选定的模型求出相应的回归方程(系数均保留两位小数);(3)由于时差,该国截止第9天新型冠状病毒感染确诊的累计人数尚未公布.小王同学认为,如果防疫形势没有得到明显改善,在数据公布之前可以根据他在(2)问求出的回归方程来对感染人数做出预测,那么估计该地区第9天新型冠状病毒感染确诊的累计人数是多少?附:回归直线的斜率和截距的最小二乘估计公式分别为:b=∑8i=1(x i−x)(y i−y)∑8i=1(x i−x)2,a=y−b x.【解析】解:(1)选择模型①,理由如下:根据残差图可以看出,模型①的估计值和真实值相对比较接近,模型②的残差相对比较大,所以模型①的拟合效果相对较好;(2)由(1)可知y关于x的回归方程为y=bx2+a,令z=x2,则y=bz+a,由所给的数据可得:z=18(1+4+9+16+25+36+49+64)=25.5,y=18(4+8+16+31+51+71+97+122)=50,b=∑8i=1(z i−z)(y i−y)∑8i=1(z i−z)2=68683570≈1.92,则a=y−b z≈50﹣1.92×25.5=1.04,所以y关于x的回归方程为y=1.92x2+1.04;(3)将x=9代入回归方程,可得y=1.92×92+1.04=156.56≈157(人),所以预测该地区第9天新型冠状病毒感染确诊的累计人数约为157人.例14.H市某企业坚持以市场需求为导向,合理配置生产资源,不断改革、探索销售模式.下表是该企业每月生产的一种核心产品的产量x(吨)与相应的生产总成本y(万元)的五组对照数据.产量x(件)12345生产总成本y(万元)3781012(Ⅰ)根据上达数据,若用最小二乘法进行线性模拟,试求y关于x的线性回归方程y=b x+a;参考公式:b=∑ni=1x i y i−nxy∑n i=1x i2−nx2,a=y−b x.(Ⅱ)记第(Ⅰ)问中所求y与x的线性回归方程y=b x+a为模型①,同时该企业科研人员利用计算机根据数据又建立了y与x的回归模型②:y=12x2+1.其中模型②的残差图(残差=实际值﹣预报值)如图所示:请完成模型①的残差表与残差图,并根据残差图,判断哪一个模型更适宜作为y关于x的回归方程?并说明理由;(Ⅲ)根据模型①中y与x的线性回归方程,预测产量为6吨时生产总成本为多少万元?【解析】解:(Ⅰ)计算x=15(1+2+3+4+5)=3,y=15(3+7+8+10+12)=8,∑5i=1x i2=12+22+32+42+52=55,∑5i=1x i y i=1⋅3+2⋅7+3⋅8+4⋅10+5⋅12=141,b=∑5i=1x i y i−nxy∑5i=1x i2−nx2=141−5×3×855−5×9=2.1,a=y−b x=8−2.1×3=1.7,因此,回归直线方程为y=2.1x+1.7.(Ⅱ)模型①的残差表为:x12345y3781012 y 3.8 5.9810.112.2 e﹣0.8 1.10﹣0.1﹣0.2画出残差图,如图所示;结论:模型①更适宜作为y关于x的回归方程,因为:理由1:模型①的4个样本点的残差点落在的带状区域比模型②的带状区域更窄;理由2:模型①的4个样本点的残差点比模型②的残差点更贴近进x轴..(不列残差表不扣分,写出一个理由即可得分.)(Ⅲ)根据模型①中y与x的回归直线方程,计算x=6时,y=2.1×6+1.7=14.3,所以预测产量为6吨时生产总成本为14.3万元.例15.为了解某企业生产的某产品的年利润与年广告投入的关系,该企业对最近一些相关数据进行了调查统计,得出相关数据见表:23456年广告投入x(万元)346811年利润y(十万元)根据以上数据,研究人员分别借助甲.乙两种不同的回归模型,得到两个回归方程,方程甲:方程甲:y(1)=b(x﹣1)2+2.75,方程乙:y(2)=c x﹣1.6.(1)求b(结果精确到0.01)与c的值.(2)为了评价两种模型的拟合效果,完成以下任务.①完成下表(备注:e î=y i−y î,e î称为相应于点(x i,y i)的残差;年广告投入x(万元)23456年利润y(十万元)346811模型甲估计值y î(1)残差e î(1)模型乙估计值y î(2)残差e î(2)②分别计算模型甲与模型乙的残差平方和Q1及Q2,并通过比较Q1,Q2的大小,判断哪个模型拟合效果更好.【解析】解:(1)设t=(x﹣1)2,则t=15(1+4+9+16+25)=11.∵y=6.4,∴6.4=b×11+2.75,解得b≈0.33.又x=4,∴6.4=c×4−1.6,即c=2.(2)①经计算,可得下表:年广告投入x(万元)23456年利润y(十万元)346811模型甲估计值y î(1) 3.08 4.07 5.728.0311残差e î(1)﹣0.08﹣0.070.28﹣0.030模型乙估计值y î(2) 2.4 4.4 6.48.410.4残差e î(2)0.6﹣0.4﹣0.4﹣0.40.6②Q1=(−0.08)2+(−0.07)2+0.282+(−0.03)2=0.0906.Q2=0.62×2+(−0.4)2×3=1.2.∵Q1<Q2,∴模型甲的拟合效果更好.。
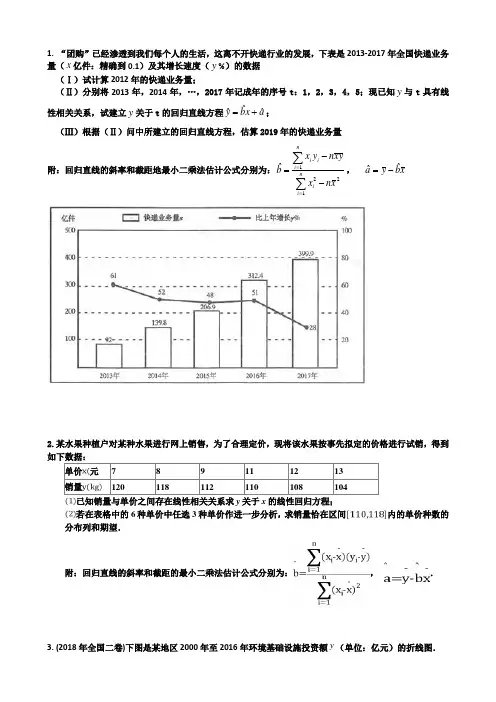
1. “团购”已经渗透到我们每个人的生活,这离不开快递行业的发展,下表是2013-2017年全国快递业务量(x 亿件:精确到0.1)及其增长速度(y %)的数据(Ⅰ)试计算2012年的快递业务量;(Ⅱ)分别将2013年,2014年,…,2017年记成年的序号t :1,2,3,4,5;现已知y 与t 具有线性相关关系,试建立y 关于t 的回归直线方程a x b yˆˆˆ+=; (Ⅲ)根据(Ⅱ)问中所建立的回归直线方程,估算2019年的快递业务量附:回归直线的斜率和截距地最小二乘法估计公式分别为:∑∑==--=ni ini ii x n xy x n yx b1221ˆ, x b y aˆˆ-=2.某水果种植户对某种水果进行网上销售,为了合理定价,现将该水果按事先拟定的价格进行试销,得到如下数据:单价元 7 8 9 11 12 13 销量120118112110108104已知销量与单价之间存在线性相关关系求y 关于x 的线性回归方程; 若在表格中的6种单价中任选3种单价作进一步分析,求销量恰在区间内的单价种数的分布列和期望.附:回归直线的斜率和截距的最小二乘法估计公式分别为:, .3. (2018年全国二卷)下图是某地区2000年至2016年环境基础设施投资额y (单位:亿元)的折线图.为了预测该地区2018年的环境基础设施投资额,建立了y 与时间变量t 的两个线性回归模型.根据2000年至2016年的数据(时间变量t 的值依次为1217,,…,)建立模型①:ˆ30.413.5y t =-+;根据2010年至2016年的数据(时间变量t 的值依次为127,,…,)建立模型②:ˆ9917.5y t =+. (1)分别利用这两个模型,求该地区2018年的环境基础设施投资额的预测值; (2)你认为用哪个模型得到的预测值更可靠?并说明理由.4.(2014年全国二卷) 某地区2007年至2013年农村居民家庭纯收入y (单位:千元)的数据如下表:年份 2007 2008 2009 2010 2011 2012 2013 年份代号t 1 2 3 4 5 6 7 人均纯收入y 2.93.33.64.44.85.25.9(Ⅰ)求y 关于t 的线性回归方程;(Ⅱ)利用(Ⅰ)中的回归方程,分析2007年至2013年该地区农村居民家庭人均纯收入的变化情况,并预测该地区2015年农村居民家庭人均纯收入.附:回归直线的斜率和截距的最小二乘法估计公式分别为:()()()121niii ni i t t y y b t t ∧==--=-∑∑,ˆˆay bt =-5(2019 2卷)18.11分制乒乓球比赛,每赢一球得1分,当某局打成10∶10平后,每球交换发球权,先多得2分的一方获胜,该局比赛结束.甲、乙两位同学进行单打比赛,假设甲发球时甲得分的概率为0.5,乙发球时甲得分的概率为0.4,各球的结果相互独立.在某局双方10∶10平后,甲先发球,两人又打了X 个球该局比赛结束.(1)求P(X=2);(2)求事件“X=4且甲获胜”的概率.。


回归分析精选题20道一.选择题(共12小题)1.设某大学的女生体重y (单位:)k g 与身高x (单位:)cm 具有线性相关关系,根据一组样本数据(i x ,)(1i y i=,2,⋯,)n ,用最小二乘法建立的回归方程为ˆ0.8585.71y x =-,则下列结论中不正确的是()A .y 与x 具有正的线性相关关系B .回归直线过样本点的中心(x ,)yC .若该大学某女生身高增加1c m ,则其体重约增加0.85k gD .若该大学某女生身高为170c m ,则可断定其体重必为58.79k g2.某商品销售量y (件)与销售价格x (元/件)负相关,则其回归方程可能是()A .ˆ10200yx =-+ B .ˆ10200yx =+ C .ˆ10200yx =-- D .ˆ10200yx =-3.有一散点图如图所示,在5个(,)x y 数据中去掉(3,10)D 后,下列说法正确的是( )A .残差平方和变小B .相关系数r 变小C .相关指数2R 变小D .解释变量x 与预报变量y 的相关性变弱4.在线性回归模型中,分别选择了4个不同的模型,它们的相关指数2R 依次为0.36、0.95、0.74、0.81,其中回归效果最好的模型的相关指数2R 为( )A .0.95B .0.81C .0.74D .0.365.已知四个命题:①在回归分析中,2R 可以用来刻画回归效果,2R 的值越大,模型的拟合效果越好; ②在独立性检验中,随机变量2K 的值越大,说明两个分类变量有关系的可能性越大;③在回归方程ˆ0.212yx =+中,当解释变量x 每增加1个单位时,预报变量ˆy平均增加1个单位;④两个随机变量相关性越弱,则相关系数的绝对值越接近于1; 其中真命题是( )A .①④B .②④C .①②D .②③6.某地区植被被破坏,土地沙化越来越严重,最近三年测得沙漠面积增加值分别为0.2万公顷、0.39万公顷和0.78万公顷,则沙漠面积增加数y (万公顷)关于年数x (年)的函数关系较为接近的是( )A .0.2yx= B .20.10.1y x x=+ C .40.2lo g yx=+ D .210xy=7.对于给定的样本点所建立的模型A 和模型B ,它们的残差平方和分别是212,,a a R 的值分别为1b ,2b ,下列说法正确的是( )A .若12a a <,则12b b <,A 的拟合效果更好 B .若12a a <,则12b b <,B 的拟合效果更好 C .若12a a <,则12b b >,A 的拟合效果更好 D .若12a a <,则12b b >,B 的拟合效果更好8.下列结论正确的是( )①函数关系是一种确定性关系; ②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法; ④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法. A .①②B .①②③C .①②④D .①②③④9.某车间加工零件的数量x 与加工时间y 的统计数据如表:现已求得上表数据的回归方程ˆˆˆy bx a =+中的ˆb 值为0.9,则据此回归模型可以预测,加工100个零件所需要的加工时间约为( )A .84分钟B .94分钟C .102分钟D .112分钟10.两个变量y与x的回归模型中,分别选择了4个不同模型,它们对应的22121()1()ni i i ni i y y Ry y ==-=--∑∑的值如下,其中拟合效果最好的模型是()A .模型1对应的20.48R =B .模型3对应的20.15R =C .模型2对应的20.96R =D .模型4对应的20.30R =11.对于回归分析,下列说法错误的是( )A .在残差图中,纵坐标表示残差B .若散点图中的一组点全部位于直线ˆ32yx =-+的图象上,则相关系数1r =C .若残差平方和越小,则相关指数2R 越大D .在回归分析中,变量间的关系若是非确定关系,那么因变量不能由自变量唯一确定 12.在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是( )A .总偏差平方和B .残差平方和C .回归平方和D .相关指数二.多选题(共1小题)13.下列有关回归分析的结论中,正确的有()A .运用最小二乘法求得的回归直线一定经过样本点的中心(x ,)yB .若相关系数r 的绝对值越接近于1,则相关性越强C .若相关指数2R 的值越接近于0,表示回归模型的拟合效果越好D .在残差图中,残差点分布的带状区域的宽度越窄,说明模型拟合的精度越高 三.填空题(共4小题)14.某商店统计了最近6个月某商品的进价x 与售价y (单位:元)的对应数据如表:假设得到的关于x 和y 之间的回归直线方程是ˆˆˆy bx a =+,那么该直线必过的定点是 .15.对具有线性相关关系的变量x ,y ,测得一组数据如表:根据上表,利用最小二乘法得它们的回归直线方程为ˆˆ10.5y x a=+,据此模型预测,当10x=时,y 的估计值是16.已知x 与y 之间的一组数据:已求得关于y 与x 的线性回归方程ˆ 2.10.85y x =+,则m 的值为 .17.对某城市进行职工人均工资水平x (千元)与居民人均消费水平y (千元)统计调查后知,y 与x 具有线性相关关系,满足回归方程0.6 1.5yx =+,若该城市居民人均消费水平为7.5(千元),则可以估计该城市人均消费额占人均工资收入的百分比约为 . 四.解答题(共3小题)18.某同学在生物研究性学习中想对春季昼夜温差大小与黄豆种子发芽多少之间的关系进行研究,于是他在4月份的30天中随机挑选了5天进行研究,且分别记录了每天昼夜温差与每天每100颗种子浸泡后的发芽数,得到如下资料:(1)从这5天中任选2天,记发芽的种子数分别为m ,n ,求事件“m ,n 均不小于25的概率.(2)从这5天中任选2天,若选取的是4月1日与4月30日的两组数据,请根据这5天中的另三天的数据,求出y 关于x 的线性回归方程ˆˆˆybx a =+;(3)若由线性回归方程得到的估计数据与所选出的检验数据的误差均不超过2颗,则认为得到的线性回归方程是可靠的,试问(2)中所得的线性回归方程是否可靠?(参考公式:1221ˆni i i ni i x y n x yb x n x==-=-∑∑,ˆˆ)ay bx =-19.随着人们经济收入的不断增长,个人购买家庭轿车已不再是一种时尚.车的使用费用,尤其是随着使用年限的增多,所支出的费用到底会增长多少,一直是购车一族非常关心的问题.某汽车销售公司作了一次抽样调查,并统计得出某款车的使用年限x 与所支出的总费用y(万元)有如下的数据资料:(1)在给出的坐标系中做出散点图;(2)求线性回归方程ˆˆˆybx a =+中的ˆa、ˆb ; (3)估计使用年限为10年时,车的使用总费用是多少?(最小二乘法求线性回归方程系数公式1221ˆni i i ni i x y n x yb x n x==-=-∑∑,ˆˆ)ay bx =-.20.一台机器使用的时间较长,但还可以使用,它按不同的转速生产出来的某机械零件有一些会有缺点,每小时生产有缺点零件的多少,随机器的运转的速度而变化,下表为抽样试验的结果:(1)画散点图;(2)如果y对x有线性相关关系,求回归直线方程;(3)若实际生产中,允许每小时的产品中有缺点的零件最多为89个,那么机器的运转速度应控制在什么范围内?(参考数值:511380 i iix y==∑,521145)iix==∑回归分析精选题20道参考答案与试题解析一.选择题(共12小题)1.设某大学的女生体重y (单位:)k g 与身高x (单位:)cm 具有线性相关关系,根据一组样本数据(i x ,)(1i y i=,2,⋯,)n ,用最小二乘法建立的回归方程为ˆ0.8585.71y x =-,则下列结论中不正确的是()A .y 与x 具有正的线性相关关系B .回归直线过样本点的中心(x ,)yC .若该大学某女生身高增加1c m ,则其体重约增加0.85k gD .若该大学某女生身高为170c m ,则可断定其体重必为58.79k g【分析】根据回归方程为ˆ0.8585.71yx =-,0.85>,可知A ,B ,C 均正确,对于D 回归方程只能进行预测,但不可断定. 【解答】解:对于A ,0.85>,所以y 与x 具有正的线性相关关系,故正确;对于B ,回归直线过样本点的中心(x ,)y ,故正确;对于C ,回归方程为ˆ0.8585.71yx =-,∴该大学某女生身高增加1c m ,则其体重约增加0.85k g,故正确;对于D ,170xc m=时,ˆ0.8517085.7158.79y =⨯-=,但这是预测值,不可断定其体重为58.79k g,故不正确故选:D .【点评】本题考查线性回归方程,考查学生对线性回归方程的理解,属于中档题. 2.某商品销售量y (件)与销售价格x (元/件)负相关,则其回归方程可能是()A .ˆ10200yx =-+ B .ˆ10200yx =+ C .ˆ10200yx =-- D .ˆ10200yx =-【分析】本题考查的知识点是回归分析的基本概念,根据某商品销售量y (件)与销售价格x(元/件)负相关,故回归系数应为负,再结合实际进行分析,即可得到答案.【解答】解:由x 与y 负相关, 可排除B 、D 两项,而C 项中的ˆ102000yx =--<不符合题意.故选:A .【点评】两个相关变量之间的关系为正相关关系,则他们的回归直线方程中回归系数为正;两个相关变量之间的关系为负相关关系,则他们的回归直线方程中回归系数为负.3.有一散点图如图所示,在5个(,)D后,下列说法正确的是()x y数据中去掉(3,10)A.残差平方和变小B.相关系数r变小C.相关指数2R变小D.解释变量x与预报变量y的相关性变弱【分析】利用散点图分析数据,判断相关系数,相关指数,残差的平方和,的变化情况.【解答】解:从散点图可分析得出:只有D点偏离直线远,去掉D点,变量x与变量y的线性相关性变强,相关系数变大,相关指数变大,残差的平方和变小,故选:A.【点评】本题考查了利用散点图分析数据,判断变量的相关性问题,属于运用图形解决问题的能力,属于容易出错的题目.4.在线性回归模型中,分别选择了4个不同的模型,它们的相关指数2R依次为0.36、0.95、0.74、0.81,其中回归效果最好的模型的相关指数2R为()A.0.95B.0.81C.0.74D.0.36【分析】根据两个变量y与x的回归模型中,它们的相关指数2R越接近于1,这个模型的拟合效果就越好,由此选出选项中的答案.【解答】解:两个变量y与x的回归模型中,它们的相关指数2R越接近于1,这个模型的拟合效果就越好,在所给的四个选项中0.95是相关指数最大的值,∴其拟合效果也最好.故选:A.【点评】本题考查了相关指数,这里不用求相关指数,而是根据所给的相关指数判断模型的拟合效果,解题的关键是理解相关指数越大拟合效果越好.5.已知四个命题:①在回归分析中,2R可以用来刻画回归效果,2R的值越大,模型的拟合效果越好;②在独立性检验中,随机变量2K的值越大,说明两个分类变量有关系的可能性越大;③在回归方程ˆ0.212y x=+中,当解释变量x每增加1个单位时,预报变量ˆy平均增加1个单位;④两个随机变量相关性越弱,则相关系数的绝对值越接近于1;其中真命题是()A.①④B.②④C.①②D.②③【分析】对4个选项分别进行判断,即可得出结论.【解答】解:①相关指数2R是用来刻画回归效果的,2R表示解释变量对预报变量的贡献率,2R越接近于1,表示解释变量和预报变量的线性相关关系越强,越趋近0,关系越弱,故2R的值越大,说明回归模型的拟合效果越好,故①正确.②由2K的计算公式可知,对分类变量X与Y的随机变量2K的观测值k来说,k越小,判断“X与Y有关系”的把握越小,随机变量2K的值越大,说明两个分类变量有关系的可能性越大,故②正确;③在回归直线方程ˆ0.212=+中,当解释变量x每增加一个单位时,预报变量ˆy平均增加y x0.2个单位,故③错误.④两个随机变量相关性越强,则相关系数的绝对值越接近于1;两个随机变量相关性越弱,则相关系数的绝对值越接近于0,故④不正确.故选:C.【点评】本题以命题的真假判断为载体,考查了抽样方法,相关系数,回归分析,独立性检验等知识点,难度不大,属于基础题.6.某地区植被被破坏,土地沙化越来越严重,最近三年测得沙漠面积增加值分别为0.2万公顷、0.39万公顷和0.78万公顷,则沙漠面积增加数y (万公顷)关于年数x (年)的函数关系较为接近的是( )A .0.2yx= B .20.10.1y x x=+ C .40.2lo g yx=+D .210xy=【分析】将(1,0.2),(2,0.39),(3,0.78)分别代入0.2y x=,20.10.1yx x=+,40.2lo g yx=+和210xy=中,验证即可.【解答】解:将(1,0.2),(2,0.39),(3,0.78)代入0.2y x=,当3x=时,0.6y=,和0.78相差较大;将(1,0.2),(2,0.39),(3,0.78)代入20.10.1y x x=+,当2x=时,0.6y=,和0.39相差较大;将(1,0.2),(2,0.39),(3,0.78)代入40.2lo g y x=+,当2x=时,0.7y=,和0.39相差较大;将(1,0.2),(2,0.39),(3,0.78)代入210xy =,当1x =时,0.2y =,当2x =时,0.4y =,与0.39相差0.01, 当3x=时,0.8y=,和0.78相差0.02;综合以上分析,选用函数关系210xy =较为近似.故选:D .【点评】本题考查了函数模型的应用问题,也考查了运算求解能力,是基础题.7.对于给定的样本点所建立的模型A 和模型B ,它们的残差平方和分别是212,,a a R 的值分别为1b ,2b ,下列说法正确的是( )A .若12a a <,则12b b <,A 的拟合效果更好 B .若12a a <,则12b b <,B 的拟合效果更好 C .若12a a <,则12b b >,A 的拟合效果更好D .若12a a <,则12b b >,B 的拟合效果更好【分析】比较两个模型的拟合效果时,如果模型残差平方和越小,则相应的相关指数2R 越大,该模型拟合的效果越好,即可得出结论.【解答】解:比较两个模型的拟合效果时,如果模型残差平方和越小, 则相应的相关指数2R 越大,该模型拟合的效果越好. 故选:C .【点评】本题是基础题.考查残差平方和、相关指数. 8.下列结论正确的是()①函数关系是一种确定性关系; ②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法; ④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法. A .①②B .①②③C .①②④D .①②③④【分析】本题是一个对概念进行考查的内容,根据相关关系的定义与回归分析的统计意义进行判断.【解答】解:①函数关系是一种确定性关系,这是一个正确的结论. ②相关关系是一种非确定性关系,是一个正确的结论.③回归分析是对具有相关关系的两个变量进行统计分析的一种方法,所以③不对. 与③对比,依据定义知④是正确的, 故选:C .【点评】本题的考点是相关关系,对本题的正确判断需要对相关概念的熟练掌握. 9.某车间加工零件的数量x 与加工时间y 的统计数据如表:现已求得上表数据的回归方程ˆˆˆy bx a =+中的ˆb 值为0.9,则据此回归模型可以预测,加工100个零件所需要的加工时间约为( )A .84分钟B .94分钟C .102分钟D .112分钟【分析】根据表中所给的数据,做出横标和纵标的平均数,得到样本中心点,代入样本中心点求出a 的值,写出线性回归方程.将100x=代入回归直线方程,得y ,可以预测加工100个零件需要102分钟,这是一个预报值,不是生产100个零件的准确的时间数. 【解答】解:由表中数据得:20x =,30y=,又ˆb 值为0.9,故300.92012a=-⨯=,0.912y x ∴=+.将100x=代入回归直线方程,得0.910012102y =⨯+=(分钟).∴预测加工100个零件需要102分钟.故选:C .【点评】本题考查线性回归方程的求法和应用,解题的关键是正确应用最小二乘法求出线性回归方程的系数的运算,再一点就是代入样本中心点可以求出字母a 的值,是一个中档题目. 10.两个变量y与x的回归模型中,分别选择了4个不同模型,它们对应的22121()1()ni i i ni i y y Ry y ==-=--∑∑的值如下,其中拟合效果最好的模型是()A .模型1对应的20.48R =B .模型3对应的20.15R =C .模型2对应的20.96R =D .模型4对应的20.30R =【分析】根据回归分析中相关指数2R 越接近于1,拟合效果越好,即可得出答案. 【解答】解:回归分析中,相关指数2R 越接近于1,拟合效果越好; 越接近0,拟合效果越差,由模型2对应的2R 最大,其拟合效果最好. 故选:C .【点评】本题考查了利用相关指数判断模型拟合效果的应用问题,是基础题. 11.对于回归分析,下列说法错误的是( )A .在残差图中,纵坐标表示残差B .若散点图中的一组点全部位于直线ˆ32y x =-+的图象上,则相关系数1r =C .若残差平方和越小,则相关指数2R 越大D .在回归分析中,变量间的关系若是非确定关系,那么因变量不能由自变量唯一确定 【分析】根据题意,对选项种的命题分析判断正误即可.【解答】解:对于A ,在残差图中,纵坐标为残差,横坐标可以选为样本编号,或身高数据,或体重的估计值等,所以A 正确;对于B,散点图中的一组点全部位于直线ˆ32=-+的图象上,则x,y成负相关,且相关y x关系最强,此时相关系数1r=-,所以B错误;对于C,若残差平方和越小,则残差点分布的带状区域的宽度越窄,其相关性越强,相关指数2R越大,所以C正确;对于D,回归分析中,变量间的关系若是非确定关系,即变量间的关系不是函数关系,因变量不能由自变量唯一确定,所以D正确.故选:B.【点评】本题考查了统计知识的概念与应用问题,掌握相关概念的含义是解题的关键,是基础题.12.在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是() A.总偏差平方和B.残差平方和C.回归平方和D.相关指数【分析】本题考查的回归分析的基本概念,根据拟合效果好坏的判断方法我们可得,数据点和它在回归直线上相应位置的差异是通过残差的平方和来体现的.【解答】解:拟合效果好坏的是由残差的平方和来体现的,而拟合效果即数据点和它在回归直线上相应位置的差异故据点和它在回归直线上相应位置的差异是通过残差的平方和来体现的.故选:B.【点评】拟合效果好坏的是由残差的平方和来体现的,也可以理解为拟合效果即数据点和它在回归直线上相应位置的差异,故据点和它在回归直线上相应位置的差异是通过残差的平方和来体现的.二.多选题(共1小题)13.下列有关回归分析的结论中,正确的有()A.运用最小二乘法求得的回归直线一定经过样本点的中心(x,)yB.若相关系数r的绝对值越接近于1,则相关性越强C.若相关指数2R的值越接近于0,表示回归模型的拟合效果越好D.在残差图中,残差点分布的带状区域的宽度越窄,说明模型拟合的精度越高【分析】利用回归分析中的相关知识对四个选项逐一分析判断即可.【解答】解:对于A,回归方程必定经过样本中心(x,)y,故选项A正确;对于B,由相关系数的意义可知,相关系数r的绝对值越接近于1,则相关性越强,故选项B正确;对于C ,若相关指数2R 的值越接近于1,表示回归模型的拟合效果越好,故选项C 错误; 对于D ,在残差图中,残差点分布的带状区域的宽度越窄,说明模型拟合的精度越高,故选项D 正确. 故选:A B D .【点评】本题考查了回归分析的理解,主要考查了回归方程的性质,相关系数的意义等,属于基础题.三.填空题(共4小题)14.某商店统计了最近6个月某商品的进价x 与售价y (单位:元)的对应数据如表:假设得到的关于x 和y 之间的回归直线方程是ˆˆˆy bx a =+,那么该直线必过的定点是13(2,8).【分析】根据回归方程必过点(,)x y ,计算出,x y 即可求得答案. 【解答】解:35289121362x+++++==,4639121486y+++++==,回归方程必过点(,)x y ,∴该直线必过的定点是13(2,8).故答案为:13(2,8).【点评】本题考查了回归方程,线性回归方程必过样本中心点(,)x y ,这是线性回归中最常考的知识点,希望大家熟练掌握.属于基础题.15.对具有线性相关关系的变量x ,y ,测得一组数据如表:根据上表,利用最小二乘法得它们的回归直线方程为ˆˆ10.5y x a=+,据此模型预测,当10x=时,y 的估计值是 106.5【分析】根据表中数据计算x 、y ,代入回归直线方程求得ˆa的值, 写出回归直线方程,利用方程求出10x =时ˆy的值即可. 【解答】解:根据表中数据,计算1(24568)55x=⨯++++=,1(2040607080)545y =⨯++++=,代入回归直线方程ˆˆ10.5y x a=+中,求得ˆ5410.55 1.5a =-⨯=,∴回归直线方程为ˆ10.5 1.5yx =+,据此模型预测,10x=时,ˆ10.510 1.5106.5y=⨯+=,即y 的估计值是106.5. 故答案为:106.5.【点评】本题考查了线性回归方程的应用问题,是基础题. 16.已知x 与y 之间的一组数据:已求得关于y 与x 的线性回归方程ˆ 2.10.85y x =+,则m 的值为 0.5 .【分析】首先求出这组数据的横标和纵标的平均数,写出这组数据的样本中心点,把样本中心点代入线性回归方程求出m 的值. 【解答】解:0123342x +++==,3 5.5715.544m m y++++==,∴这组数据的样本中心点是3(2,15.5)4m +, 关于y 与x 的线性回归方程ˆ 2.10.85y x =+,∴15.532.10.8542m +=⨯+,解得0.5m =,m∴的值为0.5.故答案为:0.5.【点评】本题考查回归分析,考查样本中心点满足回归直线的方程,考查求一组数据的平均数,是一个运算量比较小的题目,并且题目所用的原理不复杂,是一个好题.17.对某城市进行职工人均工资水平x (千元)与居民人均消费水平y (千元)统计调查后知,y 与x 具有线性相关关系,满足回归方程0.6 1.5yx =+,若该城市居民人均消费水平为7.5(千元),则可以估计该城市人均消费额占人均工资收入的百分比约为 75%.【分析】根据y 与x 具有线性相关关系,且满足回归方程,和该城市居民人均消费水平为,把消费水平的值代入线性回归方程,可以估计该市的职工均工资水平,做出人均消费额占人均工资收入的百分比. 【解答】解:y与x 具有线性相关关系,满足回归方程0.6 1.5yx =+,该城市居民人均消费水平为7.5y=,∴可以估计该市的职工均工资水平7.50.6 1.5x =+,10x ∴=,∴可以估计该城市人均消费额占人均工资收入的百分比约为7.5100%75%10⨯=,故答案为:75%【点评】本题考查线性回归方程的应用,考查用线性回归方程估计方程中的一个变量,利用线性回归的知识点解决实际问题. 四.解答题(共3小题)18.某同学在生物研究性学习中想对春季昼夜温差大小与黄豆种子发芽多少之间的关系进行研究,于是他在4月份的30天中随机挑选了5天进行研究,且分别记录了每天昼夜温差与每天每100颗种子浸泡后的发芽数,得到如下资料:(1)从这5天中任选2天,记发芽的种子数分别为m ,n ,求事件“m ,n 均不小于25的概率.(2)从这5天中任选2天,若选取的是4月1日与4月30日的两组数据,请根据这5天中的另三天的数据,求出y 关于x 的线性回归方程ˆˆˆybx a =+;(3)若由线性回归方程得到的估计数据与所选出的检验数据的误差均不超过2颗,则认为得到的线性回归方程是可靠的,试问(2)中所得的线性回归方程是否可靠?(参考公式:1221ˆni i i ni i x y n x yb x n x==-=-∑∑,ˆˆ)ay bx =-【分析】(1)用数组(,)m n 表示选出2天的发芽情况,用列举法可得m ,n 的所有取值情况,分析可得m ,n 均不小于25的情况数目,由古典概型公式,计算可得答案;(2)根据所给的数据,先做出x ,y 的平均数,即做出本组数据的样本中心点,根据最小二乘法求出线性回归方程的系数,写出线性回归方程.(3)根据估计数据与所选出的检验数据的误差均不超过2颗,就认为得到的线性回归方程是可靠的,根据求得的结果和所给的数据进行比较,得到所求的方程是可靠的.【解答】解:(1)用数组(,)m n 表示选出2天的发芽情况,m,n 的所有取值情况有(23,25),(23,30),(23,26),(23,16),(25,30),(25,26),(25,16),(30,26),(30,16),(30,26),共有10个设“m ,n 均不小于25”为事件A ,则包含的基本事件有(25,30),(25,26),(30,26) 所以3()10P A =,故事件A 的概率为310(2)由数据得12,27xy ==,3972x y=,31977i i i x y ==∑,321434i i x ==∑,23432x =由公式,得9779725ˆ4344322b -==-,5ˆ271232a=-⨯=-所以y 关于x 的线性回归方程为5ˆ32yx =-(3)当10x =时,ˆ22y=,|2223|2-<,当8x=时,ˆ17y=,|1716|2-<所以得到的线性回归方程是可靠的.【点评】本题考查回归直线方程的计算与应用,涉及古典概型的计算,是基础题,在计算线性回归方程时计算量较大,注意正确计算.19.随着人们经济收入的不断增长,个人购买家庭轿车已不再是一种时尚.车的使用费用,尤其是随着使用年限的增多,所支出的费用到底会增长多少,一直是购车一族非常关心的问题.某汽车销售公司作了一次抽样调查,并统计得出某款车的使用年限x 与所支出的总费用y(万元)有如下的数据资料:(1)在给出的坐标系中做出散点图;(2)求线性回归方程ˆˆˆybx a =+中的ˆa、ˆb ; (3)估计使用年限为10年时,车的使用总费用是多少?(最小二乘法求线性回归方程系数公式1221ˆni i i ni i x y n x yb x n x==-=-∑∑,ˆˆ)ay bx =-.【分析】(1)利用描点法作出散点图;(2)把数据代入公式,利用最小二乘法求回归方程的系数,可得回归直线方程; (3)把10x=代入回归方程得y 值,即为预报变量.【解答】解:(1)散点图如图,由图知y 与x 间有线性相关关系.(2)4x=,5y=,52190i i x ==∑,51112.3i i i x y ==∑,∴112.354512.3ˆ 1.239054210a-⨯⨯===-⨯;ˆˆ5 1.2340.08a y b x =-=-⨯=.(3)线性回归直线方程是ˆ 1.230.08y x =+,当10x=(年)时,ˆ 1.23100.0812.38y=⨯+=(万元),即估计使用10年时,支出总费用是12.38万元.【点评】本题考查了线性回归直线方程的求法及利用回归方程估计预报变量,解答此类问题的关键是利用公式求回归方程的系数,计算要细心.20.一台机器使用的时间较长,但还可以使用,它按不同的转速生产出来的某机械零件有一些会有缺点,每小时生产有缺点零件的多少,随机器的运转的速度而变化,下表为抽样试验的结果:(1)画散点图;(2)如果y 对x 有线性相关关系,求回归直线方程;(3)若实际生产中,允许每小时的产品中有缺点的零件最多为89个,那么机器的运转速度应控制在什么范围内?(参考数值:511380i i i x y ==∑,521145)i i x ==∑【分析】(1)根据表格数据,可得散点图;(2)先求出横标和纵标的平均数,代入求系数b 的公式,利用最小二乘法得到系数,再根据公式求出a 的值,写出线性回归方程,得到结果.(3)允许每小时的产品中有缺点的零件最多为89个,即线性回归方程的预报值不大于89,写出不等式,解关于x 的一次不等式,得到要求的机器允许的转数. 【解答】解:(1)散点图如图;(2)5x =,50y=,511380i i i x y ==∑,521145i i x ==∑∴13805550ˆ 6.5145555b-⨯⨯==-⨯⨯,ˆˆ17.5ay b x =-=∴回归直线方程为:ˆ 6.517.5yx =+;(3)由89y …得6.517.589x+…,解得11x …∴机器的运转速度应控制11转/秒内【点评】本题考查线性回归分析,考查线性回归方程,考查线性回归方程的应用,考查不等式的解法,是一个综合题目.。
![回归分析例题[整理]](https://uimg.taocdn.com/3316ef4976232f60ddccda38376baf1ffc4fe3c6.webp)
例题:利用我国原煤产量和铁路总货运量,建立一元线性回归预测方程。
解:第一步,准备和整理资料数据、搜集的资料要具有权威性和准确性。
1950~1990年我国煤炭产量与铁路货运量的实际数字见表3—8的X i和Y i两列。
第二步,确定自变量(原煤产量)和因变量(铁路货运量)。
第三步,作散点图。
根据数据资料作出的散点图见图3—10。
从该散点图看出,铁路货运量与煤产量的关系是一种正相关关系,特别在1980年以前,这种关系接近于线性。
第四步,确定预测模型的形式。
根据第三步选择线性回归模型:第五步,计算模型参数b0和b1。
首先把l 950年~1979年的数据代入计算,得到b0=34.499,b1=1.727,于是有回归方程:第六步.计算估计误差和相关系数。
经计算,估计标准误差:相关系数:r=0.9852。
第七步,初步经验检验。
从经验知道,铁路运量一般是应该随煤产量增加而增加的,就是说经验要求回归系数b1为正值,如果计算得到的是负值,就要检查原因。
在这里,b1为正值,说明回归方程并不违反经验常识,这一级检验通过。
第八步,统计检验。
统计检验包括以下几个方面的内容:a.离散系数检验。
要求小于10~15%。
b.相关系数检验。
一般认为相关系数r的绝对值若大于0.7,x和y就具有较高的相关程度。
本例中r=0.9852,两变量高度相关,c.判定系数检验。
r2=0.9726,说明因变量各实际值与估计值离差的97%以上已被回归方程解释,未被解释的只占不到3%。
d.t检验。
本例中t=30.4>t0.025(28)=2.084,模型通过了t检验。
e.D—W检验。
样本期间数n=30,自变量个数K’=1,显著性水平α=0.05的情况下,查D —W分布表得dL=1.35,du=1.49。
因为D—W=0.5492<dL=1.35,由判断标准可知,随机误差u i之间存在正的自相关问题。
也就是说,由于模型的随机误差存在正的自相关问题,用它进行预测可能会导致估计值过高。

1.1回归分析的基本思想及其初步应用例题:1.在画两个变量的散点图时,下面哪个叙述是正确的()(A)预报变量在x轴上,解释变量在y轴上(B)解释变量在X轴上,预报变量在y轴上(0可以选择两个变量中任意一个变量在x轴上(D)可以选择两个变量中任意一个变量在y轴上解析:通常把自变量X称为解析变量,因变量y称为预报变量.选B2,若一组观测值(xi, yi) (x2, y2) ••- (x…, y n)之间满足 y-bxi+a+e;(i=l> 2. •••!!)若巳恒为0,则仁为_____________解析:e』亘为0,说明随机误差对方贡献为0.答案:1.3.假设关于某设备的使用年限x和所支出的维修费用y (万兀),有如下的统计资料:X 2 3 4 5 6y 22 38 55 65 70若由资料可知y对x呈线性相关关系试求:(1)线性回归方程;(2)估计使用年限为10年时,维修费用是多少?解:(1)列表如下:i 1 2 3 4 5X] 2 3 4 5 622 38 55 65 70时•44 114 220 325 420X; 4 9 16 25 36_ _ 5 5x = 4, y = 5,»;=9o, »,北=112.3z'=l z'=l5 ___况一5xy干旱,仃112.3-5x4x5 …c十正方= ------------- = ------------ -- = 1.23,S,厂2 90 —5x42小「- 5x<=|a = y -bx = 5-1.23x4 = 0.08线性回归方程为:y =bx + a = 1.23x + Q.QS ( 2 )当 x=10 时,y = 1.23x10 + 0.08 = 12.38 (万兀)即估计使用10年时维修费用是1238万元课后练习:1.一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回归模型为y=7. 19x+73.93 用这个模型预测这个孩子10岁时的身高,则正确的叙述是()A.身高一定是145. 83cm;B.身高在145. 83cm以上;C.身高在145. 83cm以下;D.身I W J在 145. 83cm 左右.2.两个变量y与x的回归模型中,分别选择了 4个不同模型,它们的相关指数人2如下,其中拟合效果最好的模型是()A.模型1的相关指数人2为0. 98B.模型2的相关指数R2为。
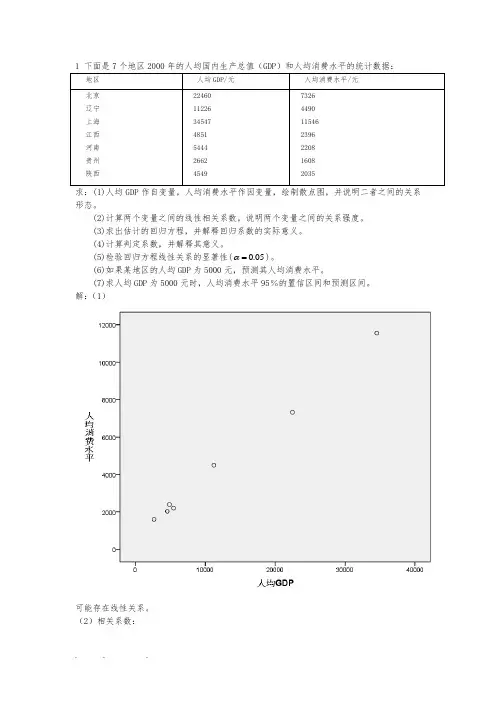
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。

回归分析例题SPSS求解过程(一)1、一元线性回归SPSS求解过程:判别:xy202.0173.2ˆˆˆ1+=+=ββ,且x与y的线性相关系数为R=0.951,回归方程的F检验值为75.559,对应F值的显著性概率是0.000<0.05,表示线性回归方程具有显著性,当对应F值的显著性概率>0.05,表示回归方程不具有显著性。
每个系数的t检验值分别是3.017与8.692,对应的检验显著性概率分别为:0.017(<0.05)和0.000(<0.05),即否定0H,也就是线性假设是显著的。
二、一元非线性回归SPSS求解过程:1、Y与X的二次及三次多项式拟合:所以,二次式为:2029.07408.00927.6xxY-+=三次式为:320046.01534.07068.1118.4xxxY+-+=2、把Y与X的关系用双曲线拟合:作双曲线变换:xVyU1,1==判别:V U 131.0082.0-=,x V y U 1,1==,V 与U 的相关系数为R=0.968,回归方程系数的F 检验值为196.227,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是440514与14.008,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。
3、把Y 与X 的关系用倒指数函数拟合:x bae Y =,则x b a Y 1ln ln +=令U1=LN (Y ),V1=V=1/x,有 U1=c+bV1.判别:V U 111.1458.21-=,x V y U /1,ln 1==,V 与1U 的相关系数为R=0.979,回归方程的F 检验值为303.190,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是195.221与-17.412,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。

概率与统计专题07 回归分析常见考点考点一 线性回归典例1.某电脑公司有6名产品推销员,其工作年限与年推销金额数据如下表:(1)求年推销金额y 关于工作年限x 的线性回归方程;(2)若第6名推销员的工作年限为11年,试估计他的年推销金额.附:回归直线的斜率和截距的最小二乘法估计公式分别为()()()121ˆ,ni i i nii tty y ba y bt tt==--==--∑∑.【答案】(1)0.50.4y x =+;(2)5.9万元. 【解析】 【分析】(1)根据表中的数据求出x ,y ,再利用公式可求出b ,a ,从而可求出推销金额y 关于工作年限x 的线性回归方程;(2)将11x =化入回归方程中求解即可 【详解】解(1)设所求的线性回归方程为y bx a =+,1(35679)65x =++++=,1(23345) 3.45y =++++=, 所以()()()5152110ˆ0.520iii i i xxy y bx x==--===-∑∑,0.4a y bx =-=.所以年推销金额y 关于工作年限x 的线性回归方程为0.50.4y x =+. (2)当11x =时,0.50.40.5110.4 5.9y x =+=⨯+=(万元). 所以可以估计第6名推销员的年推销金额为5.9万元变式1-1.某科技公司研发了一项新产品A ,经过市场调研,对公司1月份至6月份销售量及销售单价进行统计,销售单价x (千元)和销售量y (千件)之间的一组数据如下表所示:(1)试根据1至5月份的数据,建立y 关于x 的回归直线方程;(2)若由回归直线方程得到的估计数据与剩下的检验数据的误差不超过065.千件,则认为所得到的回归直线方程是理想的,试问(1)中所得到的回归直线方程是否理想?参考公式:回归直线方程ˆˆˆybx a =+,其中i ii 122ii 1ˆnnx y n x yb xnx==-⋅⋅=-∑∑.参考数据:5i i i 1392x y ==∑,52i i 1502.5x ==∑.【答案】(1)ˆ3240y x =-+.;(2)是.【解析】 【分析】(1)先由表中的数据求出,x y ,再利用已知的数据和公式求出,b a ,从而可求出y 关于x 的回归直线方程;(2)当8x =时,求出y 的值,再与15比较即可得结论 【详解】(1)因为()199.51010.511105x =++++=,()1111086585y =++++=,所以23925108ˆ 3.2502.5510b-⨯⨯==--⨯,得()ˆ8 3.21040a=--⨯=, 于是y 关于x 的回归直线方程为 3.240ˆyx =-+; (2)当8x =时,ˆ 3.284014.4y=-⨯+=, 则ˆ14.4150.60.65yy -=-=<, 故可以认为所得到的回归直线方程是理想的.变式1-2.如图是某地2014年至2020年生活垃圾无害化处理量(单位:万吨)的折线图.注:年份代码1~7分别对应年份2014~2020.(1)由折线图看出,可用线性回归模型拟合y 与t 的关系,请用相关系数加以证明; (2)建立y 关于t 的回归方程(系数精确到0.01),预测2022年某地生活垃圾无害化处理量. 附注:参考数据:719.32i i y ==∑,7140.17i i i t y ==∑0.55= 2.646≈.参考公式:相关系数()()niit t y y r --=∑,回归方程ˆˆˆya bt =+中斜率和截距的最小二乘法估计公式分别为()()()121ˆnii i nii tty y btt==--=-∑∑,ˆˆay bt =-. 【答案】(1)存在较强的正相关关系,理由见解析(2)ˆ0.100.92yt =+,1.82万吨【解析】 【分析】(1)、结合参考数据及参考公式()()niit t y y r --∑(2)、根据参考公式求出回归直线方程,进而可以根据回归直线方程进行数据统计. (1)由折线图看出,y 与t 之间存在较强的正相关关系,理由如下:719.32ii y==∑,7140.17i i i t y ==∑0.55=,123456747t ++++++==,()()7770.993ii i itty y t ytyr ---∴==≈≈∑∑.0.9930.75>,故y 与t 之间存在较强的正相关关系.(2)由(1)结合题中数据可得()()()771177222117 2.89ˆ0.103287ii i i i i iii i tty y t y tybtttt ====---==≈≈--∑∑∑∑, ˆˆ 1.3310.10340.92ay bt =-≈-⨯≈, y ∴关于t 的回归方程ˆ0.100.92y t =+,2022年对应的t 值为9,故0.1090.9.ˆ2182y=⨯+=, 预测2022年该地生活垃圾无害化处理量为1.82万吨.变式1-3.现代物流成为继劳动力、自然资源外影响企业生产成本及利润的重要因素.某企业去年前八个月的物流成本(单位:万元)和企业利润的数据(单位:万元)如下表所示:根据最小二乘法公式求得经验回归方程为ˆ321518yx =-...(1)求m 的值,并利用已知的经验回归方程求出8月份对应的残差值8ˆe; (2)请先求出线性回归模型ˆ321518yx =-..的决定系数2R (精确到0.0001),若根据非线性模型267.76ln 1069.2y x =-求得解释变量(物流成本)对于响应变量(利润)的决定系数200.9057R =,请说明以上两种模型哪种模型拟合效果更好.参考公式及数据:22121ˆ()1()niii nii y yR y y ==-=--∑∑,84x =,()821904i i y y =-=∑.【答案】(1)100,7;(2)284.8R =,ˆ321518yx =-..拟合程度更好. 【解析】 【分析】(1)根据线性回归方程横过定点(,x y )可求m ,由ˆˆi i i ey y =-求得8ˆe ; (2)根据2R 的计算公式计算2R 的值,再与20R 比较大小即可得解. (1)∵ˆ321518yx =-..,84x =, ∴ 3.284151.8117y =⨯-=.则1141161061221321141321178m +++++++=⨯,解得100m =;8月份对应的残差值()8ˆ132 3.286.5151.87e=-⨯-=. (2)()()()()()82222222221ˆ0.20.6 1.831 4.61784.8i i i y y=-=+++-+-+-+-+=∑,则()()822210218ˆ84.8110.9062904iii i i y yR R y y==-==-=->-∑∑, ∴线性回归模型ˆ321518yx =-..拟合程度更好.考点二 非线性回归典例2.新冠肺炎疫情发生以来,我国某科研机构开展应急科研攻关,研制了一种新型冠状病毒疫苗,并已进入二期临床试验.根据普遍规律,志愿者接种疫苗后体内会产生抗体,人体中检测到抗体,说明有抵御病毒的能力.通过检测,用x 表示注射疫苗后的天数,y 表示人体中抗体含量水平(单位:miu/mL ,即:百万国际单位/毫升),现测得某志愿者的相关数据如下表所示.根据以上数据,绘制了散点图.(1)根据散点图判断,e dx y c =与y a bx =+(a ,b ,c ,d 均为大于0的实数)哪一个更适宜作为描述y 与x 关系的回归方程类型?(给出判断即可,不必说明理由)(2)根据(1)的判断结果求出y 关于x 的回归方程,并预测该志愿者在注射疫苗后的第10天的抗体含量水平值;(3)从这位志愿者的前6天的检测数据中随机抽取4天的数据作进一步的分析,求其中的y 值大于50的天数为1的概率. 参考数据:其中ln w y =.参考公式:用最小二乘法求经过点()11,u v ,()22,u v ,()33,u v ,⋅⋅⋅,(),i i u v 的线性回归方程v bu a =+的系数公式,()()()1122211n niii i i i nniii i u u v v u v nuvb u u unu====---==--∑∑∑∑;a v bu =-.【答案】(1)e dx y c =更适合(2)0.740.90e x y +=,4023.87miu/mL (3)815【解析】 【分析】(1)根据散点图这些点的分布情况结合所学函数图象特点即可求解;(2)由(1)知该问题为变量之间的关系为非线性,先将非线性转化为线性关系,结合题目给出数据求出回归直线的相关系数,进而求出回归直线方程,在代入换 为y 关于x 的回归方程,将10x =代入方程中即可求出预报值. (3)根据古典概型的计算公式即可求解. (1)根据散点图可知这些点分布在一条曲线的附近,所以dx y ce =更适合作为描述y 与x 关系的回归方程类型. (2)设ln w y =,变换后可得ln w c dx =+,设ln p c =,建立ω关于x 的回归方程w p dx =+,()()()1621612.950.7417.50iii i i x w d xx w x ==--===-∑∑,所以 3.490.74 3.500.90p w d x =-=-⨯= 所以ω关于x 的回归方程为0.740.90w x =+,所以0.740.90e x y +=, 当10x =时,0.74100.908.3e e 4023.87y ⨯+==≈,即该志愿者在注射疫苗后的第10天的抗体含量水平值约为4023.87miu/mL. (3)由表格数据可知,第5,6天的y 值大于50,天数为1的概率314246815C C P C == 变式2-1.区块链技术被认为是继蒸汽机、电力、互联网之后,下一代颠覆性的核心技术区块链作为构造信任的机器,将可能彻底改变整个人类社会价值传递的方式,2015年至2019年五年期间,中国的区块链企业数量逐年增长,居世界前列现收集我国近5年区块链企业总数量相关数据,如表注:参考数据5174.691i i y ==∑,51312.761i i i x y ==∑,5110.980i i z ==∑,5140.457i i i x z ==∑(其中ln z y =).附:样本()(),1,2,,i i x y i n =⋅⋅⋅的最小二乘法估计公式为1221ni ii nii x y nxyb xnx==-=-∑∑,a y bx =-(1)根据表中数据判断,y a bx =+与e dx y c =(其中e 2.71828=⋅⋅⋅,为自然对数的底数),哪一个回归方程类型适宜预测未来几年我国区块链企业总数量?(给出结果即可,不必说明理由) (2)根据(1)的结果,求y 关于x 的回归方程;(3)为了促进公司间的合作与发展,区块链联合总部决定进行一次信息化技术比赛,邀请甲、乙、丙三家区块链公司参赛比赛规则如下:①每场比赛有两个公司参加,并决出胜负;②每场比赛获胜的公司与未参加此场比赛的公司进行下一场的比赛;③在比赛中,若有一个公司首先获胜两场,则本次比赛结束,该公司就获得此次信息化比赛的“优胜公司”,已知在每场比赛中,甲胜乙的概率为12,甲胜丙的概率为13,乙胜丙的概率为35,若首场由甲乙比赛,则求甲公司获得“优胜公司”的概率.【答案】(1)dx y ce = (2)0.75170.0591x y e -= (3)310【解析】 【分析】(1)根据表中数据判断y 关于x 的回归方程为非线性方程;(2)令ln z y =,将y 关于x 的非线性关系,转化为z 关于x 的线性关系,利用最小二乘法求解; (3)利用相互独立事件的概率相乘求求解; (1)根据表中数据e dx y c =适宜预测未来几年我国区块链企业总数量. (2)e dx y c =,ln ln y dx c ∴=+,令ln z y =,则ln z dx c =+,5110.980 2.19655ii zz ====∑,5112345355ii xx =++++===∑ 由公式计算可知122140.457310.980.7517,5545ni ii n i i x znxzb x nx==-⨯==--=-∑∑ˆln 2.1960.751730.0591c z dx =-=-⨯=- ln 0.75170.0591y x ∴=-,即ln 0.75170.0591y x ∴=-,即0.75170.0591x y e -=所以y 关于x 的回归方程为0.75170.0591x y e -= (3)设甲公司获得“优胜公司”为A 事件. 则11123112113232352253210()P A ⨯+⨯⨯⨯+⨯⨯⨯== 所以甲公司获得“优胜公司”的概率为310. 变式2-2.2021年11月4日,第四届中国国际进口博览会在上海开幕,共计2900多家参展商参展,420多项新产品,新技术,新服务在本届进博会上亮相.某投资公司现从中选出20种新产品进行投资.为给下一年度投资提供决策依据,需了解年研发经费对年销售额的影响,该公司甲、乙两部门分别从这20种新产品中随机地选取10种产品,每种产品被甲、乙两部门是否选中相互独立.(1)求20种新产品中产品A 被甲部门或乙部门选中的概率;(2)甲部门对选取的10种产品的年研发经费i x (单位:万元)和年销售额()1,2,,10i y i =(单位:十万元)数据作了初步处理,得到下面的散点图及一些统计量的值.根据散点图现拟定y 关于x 的回归方程为()23y b x a =-+.求a 、b 的值(结果精确到0.1);(3)甲、乙两部门同时选中了新产品A ,现用掷骰子的方式确定投资金额.若每次掷骰子点数大于2,则甲部门增加投资1万元,乙部门不增加投资;若点数小于3,则乙部门增加投资2万元,甲部门不增加投资,求两部门投资资金总和恰好为100万元的概率.附:对于一组数据()11,v u 、()22,v u 、、(),n n v u ,其回归直线u v αβ=+的斜率和截距的最小二乘估计分别为()()()121niii ni i v v u u v vβ==--=-∑∑,u v αβ=-,20162057.529877320520.5277-⨯=-⨯,2016657.51019877365 6.55567-⨯=-⨯. 【答案】(1)34; (2)0.1b =, 5.4a =;(3)100311443⎛⎫+⨯ ⎪⎝⎭.【解析】 【分析】(1)利用组合计数原理、古典概型的概率公式以及对立事件的概率公式可求得所求事件的概率; (2)令()23t x =-,计算出t 、y 的值,利用最小二乘法公式结合表格中的数据可求得a 、b 的值; (3)设投资资金总和恰好为n 万元的概率为n P ,则投资资金总和恰好为()1n +万元的概率为()1121233n n n P P P n +-=+≥,推导出数列{}1n n P P +-是首项为19,公比为13-的等比数列,利用累加法可求得100P 的值., (1)解:20种新产品中产品A 没有被甲部门和乙部门同时选中的概率1010191910102020C C 111C C 224P =⋅=⋅=,所以产品A 被甲部门或乙部门选中的概率为13144-=. (2)解:令()23t x =-,由题中数据得()10211320.510i i t x ==-=∑,10117.510i i y y ===∑,()101021132016i iii i i t y x y ===-=∑∑,()1010421138773i i i i t x ===-=∑∑,101102211020162057.5290.1877320520.527710i ii i i t y t yb t t==--⨯===≈-⨯-∑∑,297.520.5 5.4277a y bx =-=-⨯≈.(3)解:由题意知,掷骰子时甲部门增加投资1万元发生的概率为23,乙部门增加投资2万元发生的概率为13.设投资资金总和恰好为n 万元的概率为n P ,则投资资金总和恰好为()1n +万元的概率为()1121233n n n P P P n +-=+≥. 所以()()1112112333n n n n n n n P P P P P P P n +---=+-=--≥,因为123P =,212273339P =+⋅=,21721939P P -=-=, 所以数列{}1n n P P +-是首项为19,公比为13-的等比数列,所以111193n n n P P -+⎛⎫-=⨯- ⎪⎝⎭,所以()()()()10012132999810099P P P P P P P P P P =+-+-++-+-2982111111139939393⎛⎫⎛⎫⎛⎫=++⨯-+⨯-++⨯- ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭991001119323111344313⎡⎤⎛⎫⨯--⎢⎥ ⎪⎝⎭⎢⎥⎛⎫⎣⎦=+=+⨯ ⎪⎛⎫⎝⎭-- ⎪⎝⎭,所以投资资金总和恰好为100万元的概率是100311443⎛⎫+⨯ ⎪⎝⎭.变式2-3.某企业新研发了一种产品,产品的成本由原料成本及非原料成本组成.每件产品的非原料成本y (元)与生产该产品的数量x (千件)有关,经统计得到如下数据:根据以上数据绘制了散点图观察散点图,两个变量间关系考虑用反比例函数模型b y a x=+和指数函数模型dx y ce =分别对两个变量的关系进行拟合.已求得用指数函数模型拟合的回归方程为0.19548.376x y e -=,ln y 与x 的相关系数10.929r =-.(1)用反比例函数模型求y 关于x 的回归方程;(2)用相关系数判断上述两个模型哪一个拟合效果更好(精确到0.001),并用其估计产量为10千件时每件产品的非原料成本;(3)根据企业长期研究表明,非原料成本y 服从正态分布()2,N μσ,用样本平均数y 作为μ的估计值μ,用样本标准差s 作为σ的估计值σ,若非原料成本y 在(,)μσμσ-+之外,说明该成本异常,并称落在(,)μσμσ-+之外的成本为异样成本,此时需寻找出现异样成本的原因.利用估计值判断上述非原料成本数据是否需要寻找出现异样成本的原因? 参考数据(其中1iu x =):参考公式:对于一组数据()()()1122,,,,,,n n x y x y x y ⋯,其回归直线ˆˆˆya bx =+的斜率和截距的最小二乘估计公式分别为:1221ˆni ii nii x ynx y bxnx==-⋅=-∑∑,ˆˆay bx =-,相关系数()()niix x y y r --=∑【答案】(1)506y x=+(2)反比例函数模型拟合效果更好,产量为10千件时每件产品的非原料成本约为11元, (3)见解析【解析】 【分析】(1)令1u x =,则b y a x=+可转化为y a bu =+,求出样本中心,回归方程的斜率,转化求回归方程即可,(2)求出y 与1x的相关系数2r ,通过比较12,r r ,可得用反比例函数模型拟合效果更好,然后将10x =代入回归方程中可求结果(3)利用已知数据求出样本标准差s ,从而可得非原料成本y 服从正态分布()223,13.9N ,再计算(,)μσμσ-+,然后各个数据是否在此范围内,从而可得结论(1)令1u x=,则b y a x=+可转化为y a bu =+, 因为184238y ==, 所以8228121893.0680.3423ˆ501.5380.348i ii ii u y u ybuu==-⋅-⨯⨯===-⨯-∑∑,所以ˆˆ23500.346ay bu =-=-⨯=,所以650y u =+, 所以y 关于x 的回归方程为506y x=+ (2)y 与1x的相关系数为()()82iiu u y y r --=∑88i iu y u y-=∑30.50.99330.705==≈ 因为12r r <,所以用反比例函数模型拟合效果更好,把10x =代入回归方程得5061110y =+=(元), 所以产量为10千件时每件产品的非原料成本约为11元 (3) 因为184238y ==,所以23μ=,因为样本标准差为13.9s ===,所以13.9σ=,所以非原料成本y 服从正态分布()223,13.9N ,所以()()(,)2313.9,2313.99.1,36.9μσμσ-+=-+=因为56.5在(,)μσμσ-+之外,所以需要此非原料成本数据寻找出现异样成本的原因巩固练习练习一 线性回归1.为实施乡村振兴,科技兴农,某村建起了田园综合体,并从省城请来专家进行技术指导.根据统计,该田园综合体西红柿亩产量的增加量y (千克)与某种液体肥料每亩使用量x (千克)之间的对应数据如下.(1)由上表数据可知,可用线性回归模型拟合y 与x 的关系,请计算相关系数r 并加以说明(若0.75r >,则线性相关程度很高,可用线性回归模型拟合);(2)求r 关于x 的回归方程,并预测当液体肥料每亩使用量为15千克时,西红柿亩产量的增加量约为多少千克?附:相关系数公式()()niix x y y r --=∑ 3.16≈.回归方程y bx a =+中斜率和截距的最小二乘估计公式分别为()()()121nii i nii xx y yb xx==--=-∑∑,a y bx =-.【答案】(1)0.95,答案见解析;(2)700千克. 【解析】 【分析】(1)根据表中的数据先求出,x y ,再求()()51i i i x x y y =--∑求出相关系,再作判断即可,(2)根据线性回归方程公式求出回归方程,然后将15x =代入回归方程中可求得西红柿亩产量的增加量 【详解】解:(1)由已知数据可得2456855x ++++==,3004004004005004005y ++++==,所以()()()()()5131001000103100600i i i x x y y =--=-⨯-+-⨯+⨯+⨯+⨯=∑,====所以相关系数()()50.95iix x y y r --===≈∑.因为0.75r >,所以可用线性回归模型拟合y 与x 的关系.(2)()()()515216003020iii ii x x y y b x x ==--===-∑∑,400530250a =-⨯=, 所以回归方程为30250y x =+. 当15x =时,3015250700y =⨯+=,即当液体肥料每亩使用量为15千克时,西红柿由产量的增加量约为700千克. 2.下表是某公司从2014年至2020年某种产品的宣传费用的近似值(单位:千元)以x 为解释变量,y 为预报变量,若以11y b x a =+为回归方程,则相关指数210.9808R ≈;若以22ln y a b x =+为回归方程,则相关指数220.8457R ≈.(1)判断11y b x a =+与22ln y a b x =+,哪一个更适合作为该种产品的宣传费用的近似值y 关于年份代号x 的回归方程,并说明理由;(2)根据(1)的判断结果及表中数据,求出y 关于年份代号x 的回归方程(系数精确到0.1).参考数据:7711537.4,2334.1i i i i i y x y ====∑∑.参考公式:1221ˆˆˆ,ni ii nii x y nxybay bx xnx ==-==--∑∑. 【答案】(1)11y b x a =+更适合,理由见解析;(2)ˆ 6.650.4yx =+. 【解析】 【分析】(1)根据相关系数的绝对值越接近1,拟合效果越好即可得出答案. (2)利用最小二乘法即可求解. 【详解】(1)11y b x a =+更适合作为该种产品的宣传费用的近似值 y 关于年份代号x 的回归方程.因为20.98080.8457,R >越大,说明模型的拟合效果越好. (2)由表格中数据有123456747x ++++++==,72222222211234567140i i x==++++++=∑7172217ˆ7i ii ii x yxy bxx ==-==-∑∑537.42334.174537.47ˆ6.6, 6.6450.41401127a -⨯⨯≈=-⨯≈-,则ˆ 6.650.4yx =+. 3.某服装企业采用服装个性化设计为客户提供服务,即由客户提供身材的基本数据用于个人服装设计.该企业为了设计所用的数据更精准,随机地抽取了10位男子的身高和臂长的数据,数据如下表所示:(1)根据表中的数据,求男子的身高预报臂长的线性回归方程ˆˆˆybx a =+,并预报身高为170cm 的男子的臂长(男子臂长计算结果精确到0.01);(2)统计学认为,两个变量x 、y 的相关系数r 的大小可表明两变量间的相关性强弱.一般地,如果|r |∈[0.75,1],那么相关性很强;如果|r |∈[0.30,0.75),那么相关性一般;如果|r |∈[0,0.30),那么没有相关性.求出r 的值,并判断变量x 、y 的相关性强弱(结果精确到0.01).附:线性回归方程ˆˆˆy bx a =+其中ˆˆa y bx =-, 1.022b ∧≈,1011750i i x ==∑,101y 1730i i ==∑,()()niix x y y r --=∑101()()648i i i x x y y =--=∑715≈720≈【答案】(1) 1.02255ˆ.8y x =-;167.89cm;(2)0.91r ≈;变量,x y 间的相关性很强.【解析】 【分析】(1)根据表中的数据求出,x y,从而利用ˆˆa y bx =-可求出ˆa ,进而可得回归方程,然后当170x =时,代入回归方程可求出身高为170cm 的男子的臂长;(2)直接利用公式和已知的数据求解相关系数,再根据所给数据判断强弱 【详解】 (1)解:10117510ii xx ===∑,101y17310ii y ===∑由 1.022b ∧≈,得173 1.022ˆˆ175 5.85ay bx =-=-⨯=- 所以所求线性回归方程为 1.02255ˆ.8yx =- 当170x =时, 1.022170 5.85167.89ˆy=⨯-= 所以身高为170cm 的男性臂长约为167.89cm (2==10()()0.91iix x y y r --==≈∑因为r ∈[0.75,1],所以变量,x y 间的相关性很强.4.某汽车公司拟对“东方红”款高端汽车发动机进行科技改造,根据市场调研与模拟,得到科技改造投入x (亿元)与科技改造直接收益y (亿元)的数据统计如下:当016x <≤时,建立了y 与x 的两个回归模型:模型①: 4.111.8y x =+;模型②:21.314.4y x =;当16x >时,确定y 与x 满足的经验回归方程为:0.7y x a =-+.(1)根据下列表格中的数据,比较当016x <≤时模型①、②的相关指数2R ,并选择拟合精度更高、更可靠的模型,预测对“东方红”款汽车发动机科技改造的投入为16亿元时的直接收益.(附:刻画回归效果的相关指数()()22121ˆ1n i i i nii y yR y y ==-=--∑∑)(2)为鼓励科技创新,当科技改造的投入不少于20亿元时,国家给予公司补贴收益10亿元,以回归方程为预测依据,比较科技改造投入16亿元与20亿元时公司实际收益的大小.(附:用最小二乘法求经验回归方程ˆˆˆybx a =+的系数公式()()()1122211ˆˆˆ;n ni iiii i nniii i x y nx y x x y y bay bx xnx x x ====-⋅--===---∑∑∑∑) 【答案】(1)回归模型②刻画的拟合效果更好,70.8(亿元);(2)科技改造投入20亿元时,公司的实际收益更大. 【解析】【分析】(1)根据表中数据比较21R 和22R 可判断拟合效果,进而求出预测值;(2)求出,x y ,进而求出a ,得出回归方程,然后比较投入16亿元和20亿元时的收益即可求出结果. 【详解】由表格中的数据,有182.479.2>,即()()772211182.479.2iii i y y y y ==>--∑∑,()()772211182.479.211iit t y y y y ==∴-<---∑∑可见模型①的相关指数21R 小于模型②的相关指数22R . 说明回归模型②刻画的拟合效果更好.所以当16x =亿元时,科技改造直接收益的预测值为:ˆ21.314.470.8y ==(亿元).由已知可得:12345203,235x x ++++-==∴=,8.587.568607.6,67.65y y ++++-==∴=0.767.60.72383.7a y x ∴=+=+⨯=,∴当16x >亿元时,y 与x 满足的经验回归方程为:ˆ0.783.7yx +=-, ∴当20x 亿元时,科技改造直接收益的预测值y 0.72083.769.7=-⨯+=,∴当20x亿元时,实际收益的预测值为69.71079.7+=亿元70.8>亿元,∴科技改造投入20亿元时,公司的实际收益更大.练习二 非线性回归5.如图是某市2011年至2020年当年在售二手房均价(单位:千元/平方米)的散点图(图中年份代码1~10分别对应2011年~2020年).现根据散点图选择用y a bx =+和e c dx y +=两个模型对年份代码x 和房价y 的关系进行拟合,经过数据处理得到两个模型对应回归方程的相关指数2R 和一些统计量的值,如下表:表中ln i i w y =,101110i i w w ==∑.(1)请利用相关指数2R 判断:哪个模型的拟合效果更好;并求出该模型对应的回归方程(参数估计值精确到0.01);(2)根据(1)得到的方程预计;到哪一年,该市的当年在售二手房均价能超过10.5千元/平方米. 参考公式:对于一组数据()11,u v ,()22,u v ,…,(),n n u v ,其回归线v u αβ=+的斜率和截距的最小二乘估计分别为:()()()121ˆnii i nii uu v v uu β==--=-∑∑,ˆˆv u αβ=-.参考数据: 2.35e 10.49≈, 2.36e 10.59≈. 【答案】(1)模型e c dx y +=的拟合效果更好, 1.450.08ˆe x y+= (2)到2022年,该市的当年在售二手房均价能超过10.5千元/平方米 【解析】【分析】(1)根据相关指数的数值可知模型e c dx y +=的拟合效果更好,从而可得ln y c dx =+,利用最小二乘法即可求解.(2)由(1)将11,12x x ==代入即可求解. (1)由相关指数2R :0.90460.8821>,知模型e c dx y +=的拟合效果更好. ∵e c dx y +=,∴ln y c dx =+,令ln w y =,可知w 与x 满足线性模型回归方程ˆˆˆw c dx =+, ()11210 5.510x =++⋅⋅⋅+=, 则()()()10110216.60ˆ0.0882.5iii i i x x w w dx x ==--===-∑∑, ˆˆ 1.890.08 5.5 1.45cw dx =-=-⨯=, 所以回归方程为ˆ 1.450.08wx =+,即 1.450.08ˆe x y +=. (2)将11x =代入,可得 2.33 2.35ˆe e 10.5y=<<, 将12x =代入,可得 2.41 2.36ˆe e 10.5y=>>, 所以,根据方程预计:到2022年,该市的当年在售二手房均价能超过10.5千元/平方米. 6.某投资公司2012年至2021年每年的投资金额x (单位:万元)与年利润增量y (单位:万元)的散点图如图:该投资公司为了预测2022年投资金额为20万元时的年利润增量,建立了y 关于x的两个回归模型;模型①:由最小二乘公式可求得y 与x 的线性回归方程: 2.5020ˆ.5y x =-;模型②:由图中样本点的分布,可以认为样本点集中在由线:ln y b x a =+的附近,对投资金额x 做换元,令ln t x =,则y b t a =⋅+,且有101010102111122.00,230,569.00,50.92i i i i i i i i i t y t y t ========∑∑∑∑,(1)根据所给的统计量,求模型②中y 关于x 的回归方程;(2)分别利用这两个回归模型,预测投资金额为20万元时的年利润增量(结果保留两位小数);附:样本()()1,1,2,,i t y i n =⋯的最小乘估计公式为()()()121ˆˆˆ,nii i ni i tty y bay bt t t ==--==--∑∑;参考数据:ln20.6931,ln5 1.6094≈≈.【答案】(1)25l 32ˆn yx =- (2)模型①的年利润增量的预测值为47.50(万元),模型②的年利润增量的预测值为42.89(万元) 【解析】 【分析】(1)结合已知数据和公式求出ˆˆ,ab 这两个系数即可得回归方程; (2)把20x 代入模型①、②的回归方程,算出ˆy即可. (1)由题意,知10101122.00,230i i i i t y ====∑∑,可得 2.20,23t y ==,又由()()()10101110102221110569.0010 2.2023ˆ2550.9210 2.20 2.2010ii i i i i iii i tty y t y t ybtttt ====---⋅-⨯⨯====-⨯⨯--∑∑∑∑,则23252ˆ.2032ˆay bt =-=-⨯=- 所以,模型②中y 关于x 的回归方程25l 32ˆn yx =-. (2) 当20x 时,模型①的年利润增量的预测值为 2.5020 2.5047.5ˆ0y =⨯-=(万元),当20x时,模型②的年利润增量的预测值为()()ˆ25ln2032252ln2ln5322520.6931 1.60943242.89(y=⨯-=⨯+-≈⨯⨯+-=万元) 7.近年来,由于耕地面积的紧张,化肥的施用量呈增加趋势.一方面,化肥的施用对粮食增产增收起到了关键作用,另一方面,也成为环境污染、空气污染、土壤污染的重要来源之一如何合理地施用化肥,使其最大程度地促进粮食增产,减少对周围环境的污染成为需要解决的重要问题研究粮食产量与化肥施用量的关系,成为解决上述问题的前提某研究团队收集了10组化肥施用量和粮食亩产量的数据并对这些数据作了初步处理,得到了如图所示的散点图及一些统计量的值化肥施用量为x (单位:公斤),粮食亩产量为y (单位:百公斤).参考数据:表中ln ,ln (1,2,,10)i i i i t x z y i ===.(1)根据散点图判断,y a bx =+与d y cx =,哪一个适宜作为粮食亩产量y 关于化肥施用量x 的回归方程类型(给出判断即可,不必说明理由);(2)根据(1)的判断结果及表中数据,建立y 关于x 的回归方程;(3)根据(2)的回归方程,并预测化肥施用量为27公斤时,粮食亩产量y 的值;附:①对于一组数据(),(1,2,3,,)i i u v i n =,其回归直线ˆˆˆvu βα=+的斜率和截距的最小二乘估计分别为1221,ˆˆˆni i i ni i u v nuvav u unu ββ==-==--∑∑;②取 2.7e ≈.【答案】(1)d y cx =更适合作为y 关于x 的回归方程类型; (2)13y ex =; (3)810公斤. 【解析】 【分析】(1)根据散点图即可判断,d y cx =更适合作为y 关于x 的回归方程类型;(2)对d y cx =两边取对数,得ln ln ln y c d x =+,即ln z c dt =+,根据表中数据求出 1.5t z ==,再根据最小二乘法求出d 和c 的值,从而得出y 关于x 的回归方程; (3)由(2)得13y ex =,当27x =时,即可预测粮食亩产量y 的值. (1)解:根据散点图可判断,d y cx =更适合作为y 关于x 的回归方程类型. (2)解:对d y cx =两边取对数,得ln ln ln y c d x =+,即ln z c dt =+,由表中数据得:101115 1.51010i i t t ====∑,1011151.51010i i z z ====∑,101102211030.510 1.5 1.5146.510 1.5 1.5310i i i i i t z tzd tt ==--⨯⨯===-⨯⨯-∑∑,1ln 1.5 1.513c z dt =-=-⨯=,所以c e =,所以y 关于x 的回归方程为13y ex =. (3)解:由(2)得13y ex =,当27x =时,1327 2.738.1y e =⨯=⨯=,所以当化肥施用量为27公斤时,粮食亩产量约为810公斤. 8.某保险公司根据官方公布的历年营业收入,制成表格如下: 表1由表1,得到下面的散点图:根据已有的函数知识,某同学选用二次函数模型2y bx a =+(b 和a 是待定参数)来拟合y 和x 的关系.这时,可以对年份序号做变换,即令2t x =,得y bt a =+,由表1可得变换后的数据见表2.表2 (1)根据表中数据,建立y 关于t 的回归方程(系数精确到个位数);(2)根据(1)中得到的回归方程估计2021年的营业收入,以及营业收入首次超过4000亿元的年份.附:对于一组数据()()()1122,,,,,,n n u v u v uv ,其回归直线ˆˆv u βα=+的斜率和截距的最小二乘估计分别为()()()121ˆ nii i nii uu v vuuβ==--=-∑∑,ˆˆv u αβ=-. 参考数据:()()()10102451138.5,703.45, 1.05110, 2.32710i i i i i t y t t t t y y ===≈-≈⨯--≈⨯∑∑.【答案】(1)ˆ22144y t =-;(2)估计2021年的营业收入约为2518亿元,估计营业收入首次超过4000亿元的年份为2024年. 【解析】 【分析】(1)根据ˆ,ba 的公式,将题干中的数据代入,即得解;(2)代入121t =,可估计2021年的营业收入;令221444000t ->,可求解t 的范围,继而得到x 的范围,即得解 【详解】(1)()()()1051104212.32710ˆ221.05110iii i i t t y y bt t ==--⨯==≈⨯-∑∑, 703.452238.5144ˆˆay bt =-=-⨯≈-, 故回归方程为ˆ22144yt =-. (2)2021年对应的t 的值为121,营业收入ˆ221211442518y=⨯-=, 所以估计2021年的营业收入约为2518亿元. 依题意有221444000t ->,解得188.4t >,故2188.4x >.因为1314<<,所以估计营业收入首次超过4000亿元的年份序号为14,即2024年.。
回归分析经典例析1. 命题预测回归分析的基本思想及初步应用是新课标中的新增内容,主要是通过案例体会运用统计方法解决实际问题的思想和方法。
但由于运算复杂,出解答题的可能性不大,出现选择题或填空题形式的题目可能性较大。
2. 经典例析2.1概念理解客观题例 1.对有线性相关关系的两个变量建立的回归直线方程∧y= bxa+中,回归系数b()A.可以小于0 B.大于0 C.能等于0 D.只能小于0 简析:∵b= 0 时,则相关指数r= 0 ,此时不具有线性相关关系,但b可以大于0也可以小于0 .故答案选A例2.已知x、y之间的数据如下表所示,则y与x之间的线性的回归方程过点A.(0 ,0)B.(x,0)C.(0 ,y)D.(x,y)简析:回归直线一定过样本点的中心(x,y),故答案选D例3.工人月工资y(元)依劳动生产率x(千元)变化的回归方程∧y= 50+80x,下列判断正确的个数是()①劳动生产率为1000元时,工资为130元;②劳动生产率提高1000元,则工资提高80元;③劳动生产率提高1000元,则工资提高130元;④当月工资为210元时,劳动生产率为2000元。
A.1 B.2 C.3 D.4简析:本题考查线性回归直线方程,根据线性回归直线方程可获得对于两个变量之间整体关系的了解,根据线性回归直线方程,可以求出相应于x的估计值∧y;本题回归直线的斜率为80,故x每增加1 ,∧y增加80,即劳动生产率提高1000元时,工资提高80元。
由此可得①②④正确,故答案选C.还应注意回归直线方程∧y= bxa+中b的正负,请看例4:例4.设有一个回归方程为∧y= 2 - 2.5x,则变量x增加一个单位时,则A.y平均增加2.5个单位;B.y平均增加2个单位;C.y平均减少2.5个单位;D.y平均减少2个单位简析:斜率的估计值是- 2.5 ,即变量x每增加一个单位时,y平均减少2.5个单位,故答案为C.例5.对于一组具有线性相关关系的数据(1x ,1y ),(2x ,2y ),… ,(n x ,n y ),其回归方程中的截距为( )A.a = y -b x B. a = y - ∧b x C. ∧a = y - -b x D.∧a = y - ∧b x简析:本题考查回归方程中的截距公式∧a = y - ∧b x ,∴选D. 2.2回归分析客观题例6.若施化肥量x 与小麦产量y 之间的回归直线方程为∧y = 250 + 4x ,当施化肥量50kg 时,预计小麦产量为__________.简析:把x = 50kg 代入∧y = 250 + 4x ,即可求得∧y = 450 ,∴预计小麦产量为450 kg. 例7.用身高(cm )预报体重(kg )满足y = 0.849x - 85.712,若要找到41.638 kg 的人,__________是在150cm 中(填“一定”或“不一定”)。
下图是我国2008年至2014年生活垃圾无害化处理量(单位:亿吨)的折线图.(1)由折线图看出,可用线性回归模型拟合y 与t 的关系,请用相关系数加以说明;(2)建立y 关于t 的回归方程(系数精确到0.01),预测2016年我国生活垃圾无害化处理量. 参考数据:646.27,55.0)(,17.40,32.97127171≈=-==∑∑∑===i ii ii i iy y yt y参考公式:相关系数:.)()())((11221∑∑∑===----=ni ni iini i iy yt ty y t tr回归方程中斜率和截距的最小二乘估计公式:.ˆˆ,)())((ˆ121t b y at ty y t tbni ini i i-=---=∑∑==某互联网公司为了确定下一季的前期广告投入计划,收集了近6个月广告投入量x (单位:万元)和收益y (单位:万元)的数据如下表:月份 1 2 3 4 5 6 广告投入量 2 4 6 8 10 12 收益14.2120.3131.831.1837.8344.67他们分别用两种模型① y =bx +a ,② y =a e bx 分别进行拟合,得到相应回归方程并进行残差分析,得到如图所示的残差图及一些统计量的值。
xy∑=61i ii yx∑=612i ix730 1464.24 364(1)根据残差图,比较模型①,②的拟合效果,应该选择哪个模型?并说明理由; (2)残差绝对值大于2的数据被认为是异常数据,需要剔除: (i )剔除异常数据后求出(1)中所选模型的回归方程; (ii )若广告投入量x =18时,该模型收益的预报值时多少?附:对于一组数据(x 1 , y 1),(x 2 , y 2), … ,(x n , y n ),其回归直线a x b yˆˆˆ+=的斜率和截距的最小二乘估计分别为:.ˆˆ,)())((ˆ1221121x b y a x n xyx n yx x xy y x xbni ini i i ni ini i i-=--=---=∑∑∑∑====某公司为确定下一年度投人某种产品的宣传费,需了解年宣传费x (单位:千元)对年销售量y (单位:t )和年利润z (单位:千元)的影响. 对近8年的年宣传费x i 和年销售量y i (i =1,2,..,8)数据作了初步处理,得到下面的散点图及一些统计量的值.xyw∑=-812)(i ix x∑=-812)(i iw w∑=--81))((i i iy y x x∑=--81))((i iiy yw w46.6 563 6.8289.8 1.61469108.8其中:i i x w =,.8181∑==i iw w(1)根据散点图判断,bx a y +=与x d c y +=哪一个适宜作为年销售量y 关于年宣传费x 的回归方程类型?(给出判断即可,不必说明理由)(2)根据(1)的判断结果及表中数据,建立y 关于x 的回归方程;(3) 已知这种产品的年利润z 与y x ,的关系为x y z -=2.0.根据(2)的结果回答下列问题: (i)年宣传费49=x 时,年销售量及年利润的预报值是多少? (ii)年宣传费x 为何值时,年利润的预报值最大?附:对于一组数据),(,,),(,),(2211n n v u v u v u ,其回归直线u v βα+=的斜率和截距的最小二乘估计分别为.ˆ,)())((ˆ121u v u uv v u uni ini i iβαβ-=---=∑∑==为了预测2018年双十一购物狂欢节成交额,建立了y 与时间变量t 的两个回归模型。
回归分析练习题(有答案)(同名7277)1.1回归分析的基本思想及其初步应用二、填空题16. 在比较两个模型的拟合效果时,甲、乙两个模型的相关指数2R 的值分别约为0.96和0.85,则拟合效果好的模型是 .17. 在回归分析中残差的计算公式为 .18. 线性回归模型y bx a e =++(a 和b 为模型的未知参数)中,e 称为 .19. 若一组观测值(x 1,y 1)(x 2,y 2)…(x n ,y n )之间满足y i =bx i +a+e i (i=1、2.…n)若e i 恒为0,则R 2为_____三、解答题20. 调查某市出租车使用年限x 和该年支出维修费用y (万元),得到数据如下: 使用年限x2 3 4 5 6 维修费用y2.23.85.56.57.0(1) 求线性回归方程;(2)由(1)中结论预测第10年所支出的维修费用.(121()()()ni i i ni i x x y y b x x a y bx==⎧-⋅-⎪⎪=⎨-⎪⎪=-⎪⎩∑∑)21. 以下是某地搜集到的新房屋的销售价格y 和房屋的面积x 的数据:(1)画出数据对应的散点图;(2)求线性回归方程,并在散点图中加上回归直线; (3)据(2)的结果估计当房屋面积为2150m 时的销售价格. (4)求第2个点的残差。
二、填空题 16. 甲17. 列联表、三维柱形图、二维条形图 18. 随机误差19.解析: e i 恒为0,说明随机误差对y i 贡献为0.答案:1.三、解答题 20.解析: (1)列表如下:于是23.145905453.112552251251=⨯-⨯⨯-=--=∑∑==xx yx yx b i i i ii ,08.0423.15=⨯-=-=bx y a∴线性回归方程为:08.023.1^+=+=x a bx y (2)当x=10时,38.1208.01023.1^=+⨯=y (万元)即估计使用10年时维修费用是1238万元回归方程为: 1.230.08y x =+(2) 预计第10年需要支出维修费用12.38万元.21.解析:(1)数据对应的散点图如图所示:(2)1095151==∑=i ix x ,1570)(251=-=∑=x x l i ixx,308))((,2.2351=--==∑=y y x x l y i i i xy设所求回归直线方程为a bx y+=, 则1962.01570308≈==xxxyll b8166.115703081092.23≈⨯-=-=x b y a故所求回归直线方程为8166.11962.0+=x y(3)据(2),当2150x m =时,销售价格的估计值为:2466.318166.11501962.0=+⨯=y(万元)1、对于一元线性回归01(1,2,...,)ii i yx i n ββε=++=,()0iE ε=,2var()i εσ=,cov(,)0()i j i j εε=≠,下列说法错误的是(A)0β,1β的最小二乘估计0ˆβ,1ˆβ 都是无偏估计;(B)0β,1β的最小二乘估计0ˆβ,1ˆβ对1y ,2y ,...,ny是线性的;2、在回归分析中若诊断出异方差,常通过方差稳定化变化对因变量进行变换. 如果误差方差与因变量y 的期望成正比,则可通过下列哪种变换将方差常数化 (A) 1y ;(C) ln(1)y +;(D)ln y .3、下列说法错误的是(A)强影响点不一定是异常值;(B)在多元回归中,回归系数显著性的t 检验与回归方程显著性的F 检验是等价的;(C)一般情况下,一个定性变量有k 类可能的取值时,需要引入k-1个0-1型自变量; (D)异常值的识别与特定的模型有关.4、下面给出了4个残差图,哪个图形表示误差序列是自相关的(C)0β,1β的最小二乘估计0ˆβ,1ˆβ之间是相关的;(D)若误差服从正态分布,0β,1β的最小二乘估计和极大似然估计是不一样的.(C)(D)二、填空题(每空2分,共20分)1、考虑模型y Xβε=+,2var()nIεσ=,其中:X n p'⨯,秩为p',20σ>不一定已知,则ˆβ=__________________,ˆvar()β=___________,若ε服从正态分布,则22ˆ()n pσσ'-___________,其中2ˆσ是2σ的无偏估计.2、下表给出了四变量模型的回归结果:则残差平方和=_________,总的观察值个数=__ _______,回归平方和的自由度=________.3、已知因变量y与自变量1x,2x,3x,4x,下表给出了所有可能回归模型的AIC值,则最优子集是_____________________.4、在诊断自相关现象时,若0.66DW =,则误差序列的自相关系数ρ的估计值=_____ ,若存在自相关现象,常用的处理方法有迭代法、_____________、科克伦-奥克特迭代法.5、设因变量y 与自变量x 的观察值分别为12,,...,ny y y和12,,...,nx x x ,则以*x 为折点的折线模型可表示为_____________________.三、(共45分)研究货运总量y (万吨)与工业总产值1x (亿元)、农业总产值2x (亿元)、居民非商品支出3x (亿元)的线性回归关系.观察数据及残差值ie 、学生化残差iSRE 、删除学生化残差()i SRE 、库克距离iD 、杠杆值iich 见表一表一表二参数估计表已知0.025(6) 2.447t=,0.025(7) 2.365t=,0.05(3,6) 4.76F=,0.05(4,7) 4.12F=,根据上述结果,解答如下问题:1、计算误差方差2σ的无偏估计及判定系数2R.(8分)2、对1x,2x,3x的回归系数进行显著性检验.(显著性水平0.05α=)(12分)3、对回归方程进行显著性检验.(显著性水平α=)(8分)0.054、诊断数据是否存在异常值,若存在,是关于自变量还是关于因变量的异常值?(10分)5、写出y关于x,2x,3x的回归方程,并结合实1际对问题作一些基本分析(7分)四、(共8分)某种合金中的主要成分为金属A 与金属B ,研究者经过13次试验,发现这两种金属成分之和x 与膨胀系数y 之间有一定的数量关系,但对这两种金属成分之和x 是否对膨胀系数y 有二次效应没有把握,经计算得y 与x 的回归的残差平方和为3.7,y 与x 、2x 的回归的残差平方和为0.252,试在0.05的显著性水平下检验x 对y 是否有二次效应? (参考数据0.050.05(1,10) 4.96,(2,10) 4.1F F ==)五、(共12分)(1)简单描述一下自变量12,,...,px x x之间存在多重共线性的定义;(2分) (2)多重共线性的诊断方法主要有哪两种?(4分)(3)消除多重共线性的方法主要有哪几种?(6分)应用回归分析试题(二)二、填空题16. 在比较两个模型的拟合效果时,甲、乙两个模型的相关指数2R 的值分别约为0.96和0.85,则拟合效果好的模型是 甲 . 17. 在回归分析中残差的计算公式为列联表、三维柱形图、二维条形图 .18. 线性回归模型y bx a e =++(a 和b 为模型的未知参数)中,e 称为 随机误差 . 19. 若一组观测值(x 1,y 1)(x 2,y 2)…(x n ,y n )之间满足y i =bx i +a+e i (i=1、2.…n)若e i 恒为0,则R 2为___e i恒为0,说明随机误差对y i 贡献为0.三、解答题20. 调查某市出租车使用年限x 和该年支出维修费用y (万元),得到数据如下:(2)由(1)中结论预测第10年所支出的维修费用.(121()()()ni i i ni i x x y y b x x a y bx==⎧-⋅-⎪⎪=⎨-⎪⎪=-⎪⎩∑∑) 20.解析: (1)列表如下:4=x ,5=y , 90512=∑=i ix,3.11251=∑=i ii yx于是23.145905453.112552251251=⨯-⨯⨯-=--=∑∑==xxy x yx b i ii ii ,08.0423.15=⨯-=-=bx y a∴线性回归方程为:08.023.1^+=+=x a bx y (2)当x=10时,38.1208.01023.1^=+⨯=y (万元)即估计使用10年时维修费用是1238万元回归方程为: 1.230.08y x =+(2) 预计第10年需要支出维修费用12.38万元.21. 以下是某地搜集到的新房屋的销售价格y 和房屋的面积x 的数据:(1)画出数据对应的散点图;(2)求线性回归方程,并在散点图中加上回归直线; (3)据(2)的结果估计当房屋面积为2150m 时的销售价格. (4)求第2个点的残差。
线性回归分析法例题一、单选题1.相关分析研究的是()A、变量间相互关系的紧密程度B、变量之间因果关系C、变量之间严苛的相依关系D、变量之间的线性关系2.若变量X的值减少时,变量Y的值也减少,那么变量X和变量Y之间存有着()。
A、正相关关系B、负相关关系C、直线有关关系D、曲线有关关系3.若变量X的值增加时,变量Y的值随之下降,那么变量X和变量Y之间存在着()。
A、正有关关系B、负相关关系C、直线相关关系D、曲线相关关系4.相关系数等于零说明两变量()。
A.是严格的函数关系B.不存在相关关系C.不存有线性相关关系D.存在曲线线性相关关系5.有关关系的主要特征就是()。
A、某一现象的标志与另外的标志之间的关系是不确定的B、某一现象的标志与另外的`标志之间存有着一定的依存关系,但它们不是确认的关系C、某一现象的标志与另外的标志之间存在着严格的依存关系D、某一现象的标志与另外的标志之间存有着不确认的直线关系6.时间数列自身相关是指()。
A、两变量在相同时间上的依存关系B、两变量静态的依存关系C、一个变量随其时间相同其前后期变量值之间的依存关系D、一个变量的数值与时间之间的依存关系7.如果变量X和变量Y之间的相关系数为负1,表明两个变量之间()。
A、不存在相关关系B、相关程度很低C、有关程度很高D、全然负相关8.若物价上涨,商品的需求量愈小,则物价与商品需求量之间()。
A、并无有关B、存有正有关C、存在负相关D、无法判断是否相关9.有关分析对资料的建议就是()。
A.两变量均为随机的B.两变量均不是随机的C、自变量就是随机的,因变量不是随机的D、自变量不是随机的,因变量是随机的10.重回分析中直观重回就是指()。
A.时间数列自身回归B.两个变量之间的回归C.变量之间的线性重回D.两个变量之间的线性重回11.已知某工厂甲产品产量和生产成本有直线关系,在这条直线上,当产量为时,其生产成本为元,其中不随产量变化的成本为元,则成本总额对产量的回归方程为()A. y=+24xB. y=6+0.24xC. y=+6xD. y=24+x12.直线回归方程中,若回归系数为负,则()A.表明现象正相关B.表明现象负相关C.说明有关程度较弱D.无法表明有关方向和程度二、多项选择题1.以下属有关关系的存有()。
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
统计案例--回归分析 例题解析【要点梳理】1、称为是确定性函数,中,的关系与εεbx a bx a y x y +++= ;称为ε++=bx a y .2、直线x b a y ∧∧∧+=对数据的称为n ,此直线方程即为线性回归方程;=∧a b a 的估计值其中, x b y ∧-,=∧b ∑∑∑∑====--=---ni ini iini ini i ix n xyx n yx x xy y x x1221121)()())((,=x ,=y ,称为∧a ,称为∧b ,称为∧y .3、),(,),,(),,(2211n n y x y x y x n y x 对数据随机抽取到与对于变量,检验统计量是样本相关系数=r ⎥⎦⎤⎢⎣⎡-⎥⎦⎤⎢⎣⎡--=----∑∑∑∑∑∑======212212111221)()()()())((ni i ni i ni ii n i ni i i ni i iy n y x n x yx n yx y y x x y y x x并且具有以下性质:,1≤r r r 越接近于1,线形相关程度越 ; r 越接近于0,线形相关程度越 .4、检验的步骤如下:(1)作统计假设: .(2)根据小概0.05与2-n 在附表中查出r 的一个临界值05.0r . (1)根据样本相关系数计算公式算出的r 值(2)作统计推断,如果05.0r r >,表明有 的把握认为x 与y 之间具有线形相关关系.如果 ,我们没有理由拒绝原来的假设,这时寻找回归直线方程是毫无意义的.【典型例题】例1、 关于某设备的使用年限x 和所支出的维修费用y (万元),有如 下的统计资料:如由资料可知y 对x 呈线形相关关系. 试求:(1) 线形回归方程;(2) 估计使用年限为10年时,维修费用是多少?解:(1)55.75.65.58.32.2,4565432=++++==++++=y x ∑∑====515123.112,90i i i i iy x x()23.145905453.112552251251=⨯-⨯⨯-=--=∑∑==∧xx yx yx b i i i ii 于是08.0423.15=⨯-=-=∧∧x b y a .所以线形回归方程为:.08.023.1+=+=∧x a bx y (2)当10=x 时,)(38.1208.01023.1万元=+⨯=∧y 即估计使用10年是维修费用是12.38万元.点评:已知y x 与呈线性相关关系,就无须进行相关性检验.否则,应先进行相关性检验,若两个变量不具备相关关系,或者说,它们之间相关关系不显著,即使求出回归方程也是毫无意义的,而且用其估计和预测的量也是不可信的. 例2、一个车间为了规定工时定额,须要确定加工零件所花费的时间,为此进行了10次实验,(1)?是否具有线性相关关系与x y(2)如果.回归直线方程具有线形相关关系,求与x y(3) 并据此估计加工200个零件所用的时间为多少?解:(1)5510100908070605040302010=+++++++++=x 7.9110122115108102958981756862=+++++++++=y∑∑∑======1011011012255950,87777,38500i i i i i i iy x y x.于是:()()()()9998.07.9110877775510385007.91551055950101010221012210122101≈⨯-⨯-⨯⨯-=⎪⎭⎫ ⎝⎛-⎪⎭⎫ ⎝⎛--=∑∑∑===i i i i i ii y y x x yx yx r又查得相应于显著性水平0.05和2-n 的相关系数临界值632.005.0=r ,由.05.0具有相形相关关系与知,x y r r >(2)设所求的回归直线方程为a bx y +=∧,同时,利用上表可得()668.0551*******.915510559501010222≈⨯-⨯⨯-=--=∑∑∧x x y x y x b ii i ,96.5455668.07.91=⨯-=-=∧∧x b y a .即所求的回归直线方程为96.54668.0+=∧x y .(3)当200=x 时,y 的估计值56.18896.54200668.0=+⨯=∧y189≈.故加工200个零件时所用的工时约为189个. 点评:作相关性检验有时也用画散点图,观察所给的数据列成的点是否在一条直线的附近,这样做既直观又方便,因而对解相关性检验问题常用,但在许多实际问题中,有时很难说这些点是不是分布在一条直线的附近,这时就很难判断两个变量之间是否有相关关系,这时就应该利用样本的相关系数对其进行相关性检验;这种方法虽然较为繁琐,但却非常准确.在计算中应该特别注意要细心,不可出现计算的错误,也可借助于计算器等进行有关计算.例3、 为了解某地母亲身高x 与女儿身高y 的相关关系,随机测得10对母女的身高如下表所试对x 与y 进行一元线性回归分析,并预测当母亲身高为162cm 时女儿的身高为多少?解:(),8.158157160159101=+++=x (),1.159156159158101=+++= y()()∑=⨯-+++=-6.478.1581015716015910222222 xx i(),2.371.1598.1581015615715916015815910=⨯⨯-⨯++⨯+⨯=-∑ y x y x i i()()∑=⨯-+++=-,9.561.1591015615915810222222 y y i所以.71.09.566.472.37≈⨯=r而由附表查得632.005.0=r ,因为05.0r r >,从而有95%的把握认为x 与y 之间具有线性相关关系.回归系数.92.348.158782.01.159,78.06.472.37≈⨯-=≈=∧∧a b 所以y 对x 的回归直线方程是.78.092.34x y +=∧回归系数0.78反映出当母亲身高每增加1cm 时,女儿身高平均增加0.78cm ,92.34=∧a 可以解释为女儿身高不受母亲身高变化影响的部分.当161=x 时,5.16016178.092.34=⨯+=∧y ,这就是说当母亲身高为161cm 时,女儿的身高大致也接近161cm。
例题:利用我国原煤产量和铁路总货运量,建立一元线性回归预测方程。
解:
第一步,准备和整理资料数据、搜集的资料要具有权威性和准确性。
1950~1990年我国煤炭产量与铁路货运量的实际数字见表3—8的X i和Y i两列。
第二步,确定自变量(原煤产量)和因变量(铁路货运量)。
第三步,作散点图。
根据数据资料作出的散点图见图3—10。
从该散点图看出,铁路货运量与煤产量的关系是一种正相关关系,特别在1980年以前,这种关系接近于线性。
第四步,确定预测模型的形式。
根据第三步选择线性回归模型:
第五步,计算模型参数b0和b1。
首先把l 950年~1979年的数据代入计算,得到b0=34.499,b1=1.727,于是有回归方程:
第六步.计算估计误差和相关系数。
经计算,估计标准误差:
相关系数:r=0.9852。
第七步,初步经验检验。
从经验知道,铁路运量一般是应该随煤产量增加而增加的,就是说经验要求回归系数b1为正值,如果计算得到的是负值,就要检查原因。
在这里,b1为正值,说明回归方程并不违反经验常识,这一级检验通过。
第八步,统计检验。
统计检验包括以下几个方面的内容:
a.离散系数检验。
要求小于10~15%。
b.相关系数检验。
一般认为相关系数r的绝对值若大于0.7,x和y就具有较高的相关程度。
本例中r=0.9852,两变量高度相关,
c.判定系数检验。
r2=0.9726,说明因变量各实际值与估计值离差的97%以上已被回归方程解释,未被解释的只占不到3%。
d.t检验。
本例中t=30.4>t0.025(28)=2.084,模型通过了t检验。
e.D—W检验。
样本期间数n=30,自变量个数K’=1,显著性水平α=0.05的情况下,查D —W分布表得dL=1.35,du=1.49。
因为D—W=0.5492<dL=1.35,由判断标准可知,随机误差u i之间存在正的自相关问题。
也就是说,由于模型的随机误差存在正的自相关问题,用它进行预测可能会导致估计值过高。
为了纠正回归直线存在的系统偏差,一般采取缩短回归分析样本期间的方法,更多地让近期数据在分析中发挥影响。
分别采用1963~1979,1970~1985,1976~1990年份的数据预测如表3-9和图3-10。
用1976年~1990年数据确定的回归方程④为:
通过图3-10,可以看出,随着回归分析中样本期间向前滚动,近期数据影响的加大,
回归直线的位置在上移,但变得越来越平缓。