汉字信息在计算机中的处理
- 格式:doc
- 大小:485.05 KB
- 文档页数:4

有关计算机汉字处理的叙述
计算机汉字处理(CWP)是一种重要的语言处理技术,它用于在计
算机系统中建立汉字的数据存储、输入、输出和处理过程。
一、汉字存储
1. 字符集:汉字字符集可以采用码表或编码方式记录,例如GB2312,BIG5, Unicode 等,字符编码一般定义为八位或十六位。
2. 字体库:汉字字体库存储字形图像以及与之对应的编码,一般以二
进制文件方式存储在计算机中,常见的字体库文件格式有TTF、FOT、FNT 等。
二、汉字输入
1. 速记:对于不会拼音或五笔字型的字符,可以通过其他编码方式
(例如拼音、五笔)来编写汉字,字符串转换模块可以实现将输入的
汉字转化为码表表示的字符编码。
2. 屏幕手写输入:该方法通过鼠标或手写板,将手写的汉字字符输入,一般是通过一种识别软件来实现,将手写的信息识别为码表字符编码,以适应计算机处理。
三、汉字处理
1. 术语加工:对汉字信息进行分词、短语抽取以及关键字提取等操作,主要用于自然语言处理、信息检索和语义分析等应用领域。
2. 汉字统计分析:从某文章或一组文章中提取汉字的主题,按照出现
的次数进行统计,并进行分析处理,用于文本摘要等应用。
四、汉字输出
1. 文本输出:将汉字按照汉字字符集中的编号,以文本形式显示出来,可以被屏幕、打印机等设备正确识别。
2. 图形输出:将汉字字符以其字形图形输出到屏幕或打印机上,需根
据汉字的编码从字体库中读取相应的字形图像进行绘制。

对汉字进行传输,处理和存储时使用汉字的
在计算机中,对汉字进行传输、处理和存储时使用汉字的()。
A.字形码B.国标码C.输入码D.机内码
参考答案D解析:显示或打印汉字时使用汉字的字形码,在计算
机内部时使用汉字的机内码。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加20H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
汉字信息在系统内传送的过程就是汉字编码转换的过程。
汉字交换码:汉字信息处理系统之间或通信系统之间传输信息时,对每一个汉字所规定的统一编码,我国已指定汉字交换码的国家标准“信息交换用汉字编码字符集——基本集”,代号为GB2312—80,又称为“国标码”。
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以此标准为基础。
GB2312—80就是国标码。
该码规定:一个汉字用
两个字节表示,每个字节只有7位,与ASCII码相似。
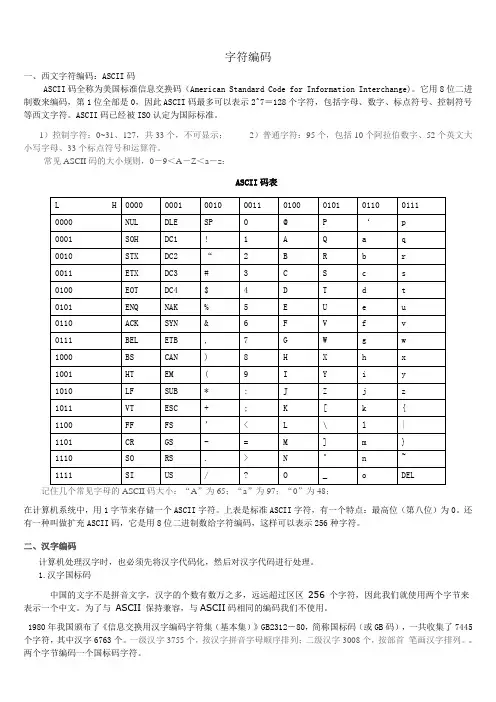
字符编码一、西文字符编码:ASCII码ASCII码全称为美国标准信息交换码(American Standard Code for Information Interchange)。
它用8位二进制数来编码,第1位全部是0,因此ASCII码最多可以表示2^7=128个字符,包括字母、数字、标点符号、控制符号等西文字符。
ASCII码已经被ISO认定为国际标准。
1)控制字符:0~31、127,共33个,不可显示;2)普通字符:95个,包括10个阿拉伯数字、52个英文大小写字母、33个标点符号和运算符。
常见ASCII码的大小规则,0-9<A-Z<a-z:ASCII码表记住几个常见字母的ASCII码大小:“A”为65;“a”为97;“0”为48;在计算机系统中,用1字节来存储一个ASCII字符。
上表是标准ASCII字符,有一个特点:最高位(第八位)为0。
还有一种叫做扩充ASCII码,它是用8位二进制数给字符编码,这样可以表示256种字符。
二、汉字编码计算机处理汉字时,也必须先将汉字代码化,然后对汉字代码进行处理。
1.汉字国标码中国的文字不是拼音文字,汉字的个数有数万之多,远远超过区区256 个字符,因此我们就使用两个字节来表示一个中文。
为了与ASCII 保持兼容,与ASCII码相同的编码我们不使用。
1980年我国颁布了《信息交换用汉字编码字符集(基本集)》GB2312-80,简称国标码(或GB码),一共收集了7445个字符,其中汉字6763个。
一级汉字3755个,按汉字拼音字母顺序排列;二级汉字3008个,按部首笔画汉字排列。
两个字节编码一个国标码字符。
2.汉字的机内表示:机内码:计算机在信息处理时表示汉字的编码,称作机内码。
现在我国都用国标码(GB2312)作为机内码。
中国的台湾省也在使用中文,但是由于历史的原因,那里没有使用大陆的简体中文,还在使用着繁体的中文,并且他们自己也制定了一套表示繁体中文的字符编码,称为BIG5,不幸的是,虽然他们的也使用两个字节来表示一个汉字,但他们没有象我们兼容ASCII 一样兼容大陆的简体中文,他们使用了大致相同的编码范围来表示繁体的汉字。


汉字计算机中的一、前言众所周知,英文是拼音文字,一个不超过128种字符的字符集,就可满足英文处理的需要。
汉字是平面结构,字数多,字形复杂、长期被认为不便于计算机存储和处理,因而常有一些知名人士主张用拼音文字来取代汉字。
经过我国科技工作者的不懈努力,这一问题已得到了较好的解决,我国已经具备了成熟的汉字信息处理方法,并且得到了广泛应用。
二、汉字在计算机中表示方法。
用计算机处理汉字,首先要解决汉字在计算机里如何表示的问题,即汉字编码问题。
根据统计,在人们日常生活交往中,包括社会生活、经济、科学技术交流等方面,经常使用的汉字约有四、五千个。
汉字字符集是一个很大的集合,至少需要用两个字节作为汉字编码的形式。
原则上,两个字节可以表示256×256=65536 种不同的符号,作为汉字编码表示的基础是可行的。
但考虑到汉字编码与其它国际通用编码,如ASCII 西文字符编码的关系,我国国家标准局采用了加以修正的两字节汉字编码方案,只用了两个字节的低7位。
这个方案可以容纳128×128=16384 种不同的汉字,但为了与标准ASCII码兼容,每个字节中都不能再用32个控制功能码和码值为32的空格以及127的操作码。
所以每个字节只能有94个编码。
这样,双七位实际能够表示的字数是:94×94=8836个。
国家根据汉字的常用程度定出了一级和二级汉字字符集,并规定了编码。
国家标准局于1981年公布了国家标准GB2312-80,即信息交换用汉字编码字符集基本集,其中共收录汉字和图形符号(682个)7445个。
每一个汉字或符号都用两个字节表示。
其中每一个字节的编码取值范围都是从20H 到7EH,即十进制写法的33到126,这与ASCII编码中可打印字符的取值范围一样,都是94个。
因为这样两个字节可以表示的不同字符总数为8 836个。
而国标码字符集共有7 445个字符,所以在上述编码范围中实际上还有一些空位。

汉字信息在计算机中的处理随着计算机技术的发展,计算机具有了中文信息处理的能力,那么汉字信息在计算机中是如何被存储、输入输出和显示的呢?一、汉字信息在计算机中的处理与存储计算机对每一个字符进行编码形成其对应的唯一一个内码就是汉字的存储,然而同一个字符(例如“中”字)不同编码对应的内码不一样。
计算机中汉字编码一般采用两个高位(左边第一位)为1 的ASCⅡ码表示一个汉字,即用两个字节表示一个汉字。
汉字在计算机内的编码很复杂,涉及汉字的各种代码,如汉字输入码,汉字机内码,汉字交换码,汉字字形码等。
1、汉字输入码汉字输入码也叫外码,是为了通过键盘字符把汉字输入计算机而设计的一种编码。
汉字的输入码种类繁多,大致有4种类型,即音码、形码、数字码和音形码。
2、汉字机内码汉字机内码又称内码或汉字存储码。
该编码的作用是统一了各种不同的汉字输入码在计算机内的表示。
汉字机内码是计算机内部存储、处理的代码。
3、汉字交换码:汉字交换码主要是用作汉字信息交换的。
4、汉字字形码汉字字形码是指确定一个汉字字形点阵的代码(汉字字形码)。
一般采用点阵字形表示字符。
目前普遍使用的汉字字型码是用点阵方式表示的,称为“点阵字模码”。
所谓“点阵字模码”,就是将汉字像图像一样置于网状方格上,每格是存储器中的一个位,16×16点阵是在纵向16点、横向16点的网状方格上写一个汉字,有笔画的格对应1,无笔画的格对应0。
这种用点阵形式存储的汉字字型信息的集合称为汉字字模库,简称汉字字库。
通常汉字显示使用16×16点阵,而汉字打印可选用24×24点阵、32×32点阵、64×64点阵等。
汉字字形点阵中的每个点对应一个二进制位,1字节又等于8个二进制位,所以16×16点阵字形的字要使用32个字节(16×16÷8字节=32字节)存储,64×64点阵的字形要使用512个字节。


汉字的计算机输入与处理技术中国汉字源远流长,是世界上最古老且使用最广泛的文字之一。
然而,由于汉字的数量多、结构复杂,对于计算机而言,如何实现高效的汉字输入与处理一直是一个具有挑战性的问题。
为满足人们对汉字输入与处理的需求,汉字计算机输入与处理技术应运而生。
本文将介绍汉字的计算机输入与处理技术的发展历程以及现阶段的应用情况。
一、汉字计算机输入技术1. 手写输入技术手写输入技术是最直接、最自然的汉字输入方式之一。
通过使用触摸屏、手写板等设备,用户可以直接书写汉字,然后由计算机进行识别和转换。
随着汉字识别算法的不断优化,手写输入技术越来越准确和便捷,成为许多人喜爱的输入方式之一。
2. 拼音输入技术拼音输入技术是基于汉字的发音,通过输入相应拼音来选取汉字的一种技术。
用户可以根据汉字的拼音首字母进行输入,并通过候选词列表选择所需的汉字。
拼音输入技术简单直观,基本适用于所有人群。
3. 五笔输入技术五笔输入技术是一种按照字形特点进行编码的输入方法。
通过使用五笔码表,用户可以通过输入五个基本笔画,按字形特点排列的编码来选取所需的汉字。
五笔输入技术需要一定的学习和记忆,但在熟练掌握后,输入速度比拼音输入更快。
二、汉字计算机处理技术1. 汉字编码技术汉字编码技术是将汉字用二进制数进行表示和存储的一种技术。
其中,比较有代表性的是GB2312、GBK、GB18030和Unicode等编码方式。
GB2312是最早用于表示简体中文字符的编码方式,GBK对GB2312的扩展,包含了更多的汉字字符;GB18030则是目前国内使用的最新的字符编码标准,支持简体中文、繁体中文以及少数民族文字的表示;Unicode是国际标准字符集,涵盖了全球几乎所有的字符。
2. 汉字处理算法在计算机中,对汉字进行处理需要运用到一系列的算法。
包括汉字的分词算法、拼音转换算法、汉字输入法等。
这些算法能够将输入的汉字进行处理和转换,以满足用户的各种需求。

计算机内处理汉字信息时所用的代码文章标题:探索计算机内处理汉字信息时所用的代码一、引言在计算机科学领域中,汉字信息的处理一直是一个重要而复杂的问题。
在计算机内部,汉字是如何被表示和处理的?这背后涉及到的编码方式、存储方式以及处理方式都是我们需要探索的内容。
二、初识汉字编码1. 汉字的基本表示:在计算机内部,汉字通常需要通过一定的编码方式来表示。
最常见的汉字编码包括ASCII、Unicode和GB2312等。
这些编码方式各有特点,对汉字信息的处理都起着重要作用。
2. ASCII编码的局限性:ASCII编码只能表示128个字符,无法满足汉字信息处理的需求。
随着汉字在计算机中的普及,Unicode编码应运而生,它可以表示世界上几乎所有的文字。
3. Unicode编码的发展:Unicode编码是一种全球性的字符编码标准,它为世界上几乎所有的字符规定了唯一的二进制编码。
而在Unicode的基础上,又衍生出了UTF-8、UTF-16等不同的存储方式,以适应不同场景下的需求。
三、汉字信息的存储和传输1. 汉字信息的存储方式:在计算机内部,汉字信息可以通过不同的存储方式进行表示,包括大端序和小端序的存储方式。
这两种方式对于汉字信息的存储具有重要的影响。
2. 汉字信息的传输方式:在网络传输等场景下,汉字信息的传输也需要考虑编码方式和传输协议,以确保信息的完整和准确性。
四、汉字信息的处理1. 文本处理:在文本处理中,汉字的分词、识别和索引等是极为重要的任务。
各种文本处理算法和工具都会涉及到汉字编码的处理。
2. 数据库处理:在数据库中存储和查询汉字信息也需要考虑编码方式和索引方式,以提高查询效率和准确性。
3. 图像处理:在汉字图像识别中,计算机需要对汉字进行识别和处理,这同样离不开对汉字编码的理解和运用。
五、个人观点和总结通过对计算机内处理汉字信息所用的代码进行深入地探讨,我们可以看到汉字编码在计算机科学中的重要性和复杂性。

《计算机内处理汉字信息时所用的代码》1. 概述在计算机领域中,处理汉字信息所用的代码是至关重要的。
汉字作为中文的基本符号,它的编码方式直接影响着文字的存储、传输和显示。
本文将从多个角度全面评估计算机内处理汉字信息时所用的代码,为读者深入了解这一主题提供指导。
2. ASCII码我们需要了解ASCII码。
ASCII码是计算机系统内部用来存储和交换文本信息的标准编码系统,它使用7位或8位二进制数字来表示128或256种不同的符号。
然而,ASCII码只能表示基本的拉丁字母、数字和少量符号,对于汉字来说显然是不够的。
3. GB2312为了解决汉字编码的问题,我国在上世纪80年代提出了GB2312编码方案。
GB2312采用了双字节编码,能够表示6763个常用汉字和非汉字字符。
这一编码方式大大提高了汉字在计算机中的表示能力,为中文信息的数字化处理带来了重要的进步。
4. GBK随着信息技术的发展,GB2312编码方式逐渐暴露出一些不足之处。
为了更充分地表示汉字,GBK编码应运而生。
GBK在GB2312基础上进行了扩充,加入了21003个新的汉字和符号。
这一编码方式成为了我国大陆和台湾地区的标准编码,极大地丰富了汉字的表示范围。
5. Unicode然而,随着全球化的推进和计算机技术的不断发展,单一的汉字编码方式已经无法满足需求。
Unicode作为一种强大的字符编码方案,被广泛应用于各种操作系统、软件和互联网标准中。
Unicode的出现使得世界上几乎所有的文字都有了统一的编码,为不同语言文字的处理提供了标准化的解决方案。
6. UTF-8在Unicode的基础上又衍生出了多种不同的编码方式,其中最为常见的是UTF-8。
UTF-8是一种可变长的编码方式,能够表示Unicode标准中的所有字符。
它不仅兼容ASCII码,而且能够表示任意文字,同时还具有很高的存储利用率,是当前互联网上最常用的字符编码方式之一。
7. 总结通过对计算机处理汉字信息所用的代码的深入探讨,我们可以得出结论:随着技术的不断发展,汉字编码方式逐渐从简到繁,由GB2312到GBK再到Unicode和UTF-8,每一种编码方式都在不断拓展汉字的表示范围和存储能力,使得汉字信息能够更好地融入到数字化的世界中。

汉字信息处理过程一、引言汉字是中国文字的重要组成部分,具有悠久的历史和丰富的文化内涵。
如何高效地处理汉字信息,一直是信息技术领域的研究热点之一。
本文将介绍汉字信息处理的基本过程,并探讨其中涉及的关键技术和应用领域。
二、汉字信息的表示与编码在计算机中,汉字需要通过编码方式进行表示,以便于存储和处理。
目前常用的汉字编码方式有GBK、Unicode等。
其中,GBK编码是国家标准,采用双字节表示一个汉字,能够表示常用汉字和少量生僻字;而Unicode编码则是国际标准,采用四字节表示一个汉字,能够表示全球范围内的所有字符。
三、汉字信息的输入与识别汉字信息的输入方式多种多样,包括手写输入、拼音输入、笔画输入等。
其中,手写输入是最接近人类书写习惯的方式,通过触控屏或数位板识别用户的手写输入,并将其转化为计算机能够理解的字符流。
拼音输入则是通过输入拼音来自动推测用户的意图,并给出相应的候选字词。
而笔画输入则是通过用户输入汉字的笔画顺序来识别用户的输入。
四、汉字信息的处理与分析汉字信息处理的方法有很多,其中常见的包括汉字分词、词性标注、命名实体识别等。
汉字分词是将连续的汉字序列切分成有意义的词语,是文本理解和信息检索的基础。
词性标注是给每个汉字或词语标注其词性,以便于进行句法分析和语义理解。
命名实体识别是识别文本中的人名、地名、组织机构名等具有特定意义的词语。
五、汉字信息的存储与检索汉字信息的存储方式多种多样,常见的有关系数据库、非关系数据库、文本文件等。
关系数据库以表的形式存储数据,可以通过结构化查询语言(SQL)进行检索。
非关系数据库则以键值对的方式存储数据,适用于半结构化和非结构化数据的存储与检索。
文本文件则以纯文本的形式存储数据,适用于小规模数据的存储和共享。
六、汉字信息的应用领域汉字信息处理广泛应用于文本挖掘、自然语言处理、机器翻译、信息检索等领域。
在文本挖掘中,通过对大规模文本数据进行分析和挖掘,可以发现隐藏在文本中的有价值的信息。
汉字在计算机中的处理过程
汉字是中国的独特符号体系之一,它在计算机中的处理过程也与其他字符、符号有所不同。
下面将介绍汉字在计算机中的处理过程及其相关技术。
1. 汉字的编码
汉字在计算机中的处理需要对其进行编码,将其转化成计算机可以识别和处理的数字序列。
目前广泛应用的汉字编码有GB2312、GBK、GB18030和Unicode等。
其中GB2312编码是中国国家标准,用于存储简体中文;GBK编码是GB2312的扩展,用于存储繁体中文、日语和韩语等;GB18030是国际标准,包含了GB2312和GBK的所有字符,并支持其他语种的字符;而Unicode是一种国际标准,用于表示各种文字系统的字符,包括汉字、英文字母、数字及标点符号等。
2. 汉字的输入和输出
在计算机中,汉字的输入和输出需要借助特定的输入法和字体。
输入法是将拼音等输入方式转换成相应汉字的工具,常见的输入法有微软拼音、搜狗拼音、百度输入法等。
而字体则是展示汉字形状的工具,不同的字体库包含了不同的汉字字形,因此需要选择合适的字体库才能正常显示汉字。
3. 汉字的处理和存储
汉字在计算机中的处理和存储也需要特定的技术支持。
由于汉字编码长度较长,因此存储时需要更多的空间。
同时,因为汉字的连续性比较强,因此在处理时需要考虑字节对齐以提高效率。
另外,汉字的排序和搜索也需要特殊的算法和数据结构来实现,如汉字拼音排序和汉字树等。
总体来说,汉字在计算机中的处理需要借助特定的编码、输入法、字体、算法和数据结构等技术支持。
这些技术正不断发展和完善,为汉字的应用和普及提供了更多的可能性和机会。
计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
汉字信息在系统内传送的过程就是汉字编码转换的过程。
汉字交换码:汉字信息处理系统之间或通信系统之间传输信息时,对每一个汉字所规定的统一编码,我国已指定汉字交换码的国家标准“信息交换用汉字编码字符集——基本集”,代号为GB2312—80,又称为“国标码”。
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以此标准为基础。
GB 2312—80就是国标码。
该码规定:一个汉字用两个字节表示,每个字节只有7位,与ASCII码相似。
区位码:将GB 2312—80的全部字符集组成一个94×94的方阵,每一行称为一个“区”,编号为0l~94;每一列称为一个“位”,编号为0l~94,这样得到GB 2312—80的区位图,用区位图的位置来表示的汉字编码,称为区位码。
机内码:为了避免AS CII码和国标码同时使用时产生二义性问题,大部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。
这样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码与国标码具有极简单的对应关系。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加20H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
GB2312编码包括符号、数字、字母、日文、制表符等,当然最主要的部分还是中文,它采用16位编码方式,简体中文的编码范围从B0A1一直到F7FE,完整编码表可以参考http://ash.jp/code/cn/gb2312tbl.htm。
汉字信息在计算机中的处理
陌陌:琪琪,随着计算机技术的发展,计算机具有了中文信息处理的能力,在上次课中,我们已经学习了第一节的文字及其处理技术,那么我想问你,汉字信息在计算机中是如何进行处理呢?
琪琪:陌陌,这你可要认真听了哦,汉字首先要被计算机先存储,计算机只能识别二进制数0和1任何信息在计算机中都是以二进制形式存放的,汉字也不例外,这就需要对汉字进行编码。
陌陌:那琪琪你能说说计算机在处理汉字时是如何机进行编码的吗?
琪琪:汉字在计算机内的编码很复杂,涉及汉字的各种代码,目前计算机上使用的汉字编码主要有三种1、汉字输入码2汉字机内码3汉字输出码。
陌陌:那琪琪你能告诉我汉字信息在计算机中是如何通过编码进行输入输出和显示的吗?琪琪:这个有点复杂,陌陌你要仔细听,在前面我所提到的汉字编码中,汉字输入码也叫外码,是为了通过键盘字符把汉字输入计算机而设计的一种编码。
汉字的输入码种类繁多,大致有4种类型,即音码、形码、数字码和音形码。
陌陌:那第二个汉字机内码是什么呢?
琪琪:第二个是汉字机内码,它又称为内码或汉字存储码。
汉字机内码是供计算机系统内部进行存储、加工处理、传输而统一使用的代码。
陌陌:那汉字输出码又应该怎么理解呢?
琪琪:汉字输出码,它也叫汉字的字型码,由汉字的字模信息组成的。
目前普遍使用的汉字字型码是用点阵方式表示的,称为“点阵字模码”。
所谓“点阵字模码”,就是将汉字像图像一样置于网状方格上,每格是存储器中的一个位,16×16点阵是在纵向16点、横向16点
的网状方格上写一个汉字,有笔画的格对应1,无笔画的格对应0。
这种用点阵形式存储的汉字字型信息的合称为汉字字模库,简称汉字字库。
通常汉字显示使用16×16点阵,而汉字打印可选用24×24点阵、32×32点阵、64×64点阵等。
例如以下几幅图都是用点阵来显示汉字:
陌陌:琪琪我了解了三种汉字编码了,那我还想知道这三种编码是如何处理才得出了汉字的呢?
琪琪:好,我现在就告诉你汉字信息的到底是如何输入输出的,汉字输入就是将汉字符号输入到计算机中,目前简便易行的方式是键盘输入。
有了汉字的机内码和输入码,计算机就可以处理汉字了,下面的工作就是将处理后的汉字信息输出了。
汉字是一个特殊的图形符号,输出主要是指在显示器上或打印机上输出汉字的字形,将它用点阵的方式描述。
在汉字输出时,计算机根据汉字机内码从汉字库中取出相应的汉字字型码。
通过汉字处理系统的专门处理程序自动把要输出的汉字的内码转换成对应的汉字字形后输出。
陌陌:琪琪,你好聪明,我要向你多学习点新知识。
琪琪:为了给你更加理解,我给你举个例子吧。
其处理过程如图所示
我以汉字“春”为例其处理过程为: 键盘 输入 输入码 编码转换
机内码 编辑与输出 字型码
1用拼音输入法通过键盘输入外码“chun”2从外码表找出与之对应的汉字机内码3按照汉字机内码找到存放字型码的地址4取出“字型码”在屏幕上显示出来。
陌陌,你明白了吗?陌陌:琪琪,谢谢你,我明白了。
我会记住的。