MySQL和PostgreSQL两数据库的对决
- 格式:docx
- 大小:12.87 KB
- 文档页数:2

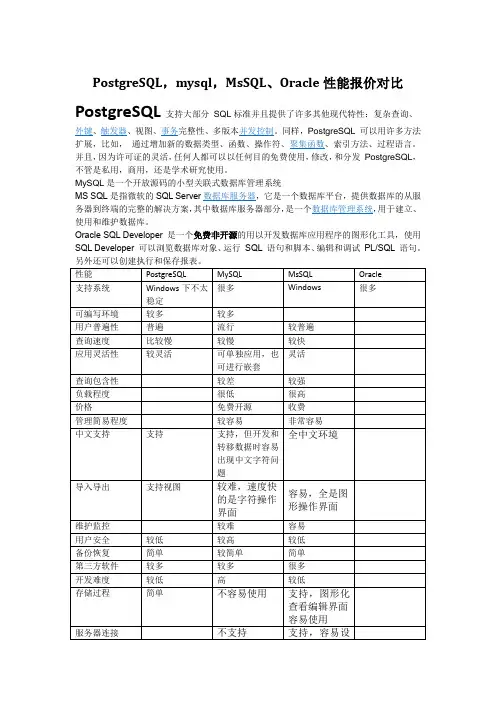
选择pgsql还是mysqlpgsql又称PostgresSQL,出现在1986年,官方标榜自己是世界上最先进最高级的开源关系型数据库。
pgsql和mysql简介:pgsql的一些粉丝说可以跟oracle相媲美,可靠性是pgsql的最高优先级,数据一致性与完整性也是pgsql的高优先级特性;mysql和pgsql都出现在一些高流量的web站点上,都能用在大型分布式系统上,都支持事务,都支持全文索引;mysql现在已经支持嵌入式应用,而pgsql依然坚守在传统B/S 架构上;mysql能够进行快速地读取和大量的查询操作,不过在复杂特性与数据完整性检查方面不太尽如人意;pgsql是针对事务性企业级应用严肃、功能完善的数据库,支持强ACID特性,会做很多数据完整性检查;mysql上myISAM存储引擎因为执行很少的数据完整性检查,所以速度快,对于敏感数据,对读写要求高的数据,支持ACID特性的InnoDB则是个更好的选择,相反pgsql是个只有单一存储引擎完全集成的数据库;mysql与pgsql都是高可配置的,通过参数调整性能,也可以调整查询与事务特性,他们都支持通过扩展添加额外的功能;pgsql可靠性更好,稳定性很强,在保护数据安全方面更擅长,并且是社区项目,不会陷入商业厂商牢笼之中;mysql的普及更广一些,学习资料更多,熟练使用的人更多,所以选择mysql的企业很多。
pgsql相比mysql的优势:pgsql存储过程的功能支持要比mysql好,具备本地缓存执行计划的能力;pgsql对表连接支持更完整,优化器的功能更完整,支持的索引类型很多,复杂查询能力较强;pgsql主备复制属于物理复制,支持异步、同步、半同步复制,mysql基于binlog的逻辑复制,是异步复制,pgsql数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小;pgsql支持json数据类型,而mysql不支持,mysql字符型有长度限制,而pgsql的text类型无限长,可以使用xml xpath,用pgsql 的话,mongodb这样文档数据库就省了;pgsql是完全免费开源的,而mysql归属oracle后,开源程度大不如以前;pgsql在GIS领域多年来处于优势地位,有丰富的几何类型,支持极其丰富的空间函数,可以建立R树、GIST树等空间索引,instagram就是因为pgsql的空间数据库扩展postgis远远强于mysql 的my spatial而采用的pgsql;pgsql有极其强悍的sql编程能力,有非常丰富的统计函数和统计语法支持,可用多种语言写存储过程,对R支持也非常好,这一点mysql就差的很远,腾讯内部数据存储主要用mysql,但是数据分析主要是hadoop pgsql;pgsql有多种集群架构可选择,plproxy可以支持语句级的镜像或分片,slony可以进行字段级的同步设置,standby可以构建WAL文件级或流式的读写分离集群,同步频率和集群策略调整方便,操作非常简单;pgsql支持topology、pgrouting等功能强大、方便使用的GIS 扩展,例如可以用pgrouting计算路径规划;pgsql数据库方便QGIS等GIS工具连接和图层展示等操作;下图是用QGIS从pgsql读取数据并展示图层:mysql相比pgsql的优势:mysql采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束;mysql的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;mysql分区表的实现要优于pgsql的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大;mysql的存储引擎插件化机制,使得它的应用场景更加广泛,比如除了Innodb适合事务处理场景外,Myisam适合静态数据的查询场景;mysql也支持空间索引,是用R树实现的空间索引,但空间函数等功能不如pgsql丰富,空间查询比pgsql慢;pgsql更适合严格的企业应用场景,比如金融、电信、ERP、CRM等,mysql更适用业务逻辑相对简单、数据可靠性要求更低的互联网场景,比如google、facebook、淘宝等。

MySQL和PostgreSQL两数据库的对决在这篇文章中,我们选用MySQL4.0.2-alpha与PostgreSQL7.2进行比较,因为MySQL4.0.2-alpha开始支持事务的概念,因此这样的比较对于MySQL应该较为有利。
我们这样的比较不想仅仅成为一份性能测试报告,因为至少从我个人来看,对于一个数据库,稳定性和速度并不能代表一切。
对于一个成熟的数据库,稳定性肯定会日益提供。
而随着硬件性能的飞速提高,速度也不再是什么太大的问题。
一、前言前一段时间,我曾经翻译过一篇将你的网站从MySQL改为PostgreSQL,其实当初我更感兴趣的是一个应用程序的后台数据库从MySQL转为PostgreSQL的具体操作,并没有关心MySQL和PostgreSQL的优劣,没想到反应出乎意料的大,因此我也就觉得有写这篇文章的必要了。
在这篇文章中,我们选用MySQL4.0.2-alpha与PostgreSQL7.2进行比较,因为MySQL4.0.2-alpha开始支持事务的概念,因此这样的比较对于MySQL应该较为有利。
我们这样的比较不想仅仅成为一份性能测试报告,因为至少从我个人来看,对于一个数据库,稳定性和速度并不能代表一切。
对于一个成熟的数据库,稳定性肯定会日益提供。
而随着硬件性能的飞速提高,速度也不再是什么太大的问题。
二、两者的共同优势这两个产品都属于开放源码的一员,性能和功能都在高速地提高和增强。
MySQLAB的人们和PostgreSQL的开发者们都在尽可能地把各自的数据库改得越来越好,所以对于任何商业数据库使用其中的任何一个都不能算是错误的选择。
三、两者不同的背景MySQL的背后是一个成熟的商业公司,而PostgreSQL的背后是一个庞大的志愿开发组。
这使得MySQL的开发过程更为慎重,而PostgreSQL的反应更为迅速。
这样的两种背景直接导致了各自固有的优点和缺点。
四、MySQL的主要优点1、首先是速度,MySQL通常要比PostgreSQL快得多。

数据库管理系统:PostgreSQL和MySQL的差异PostgreSQL和MySQL是两种常用的关系型数据库管理系统(RDBMS),它们在很多方面都有相似之处,比如都是开源的、可以在多个平台上运行、支持SQL等等。
但是,它们之间也有不同点,这篇文章将简要介绍这些不同点,以便读者可以更好地选择适合自己需求的数据库管理系统。
1.数据类型PostgreSQL和MySQL在数据类型方面有些区别,例如PostgreSQL 支持数组类型、范围类型和JSON类型,而MySQL不支持。
此外,PostgreSQL还支持网络地址和CIDR类型,以及各种几何数据类型,而MySQL则不支持这些类型。
这些不同可能对于需要使用这些数据类型的应用程序有影响。
2.存储引擎MySQL具有多种存储引擎,其中包括InnoDB、MyISAM等。
InnoDB 是MySQL的默认存储引擎,它支持事务和外键。
而MyISAM不支持事务和外键,但比较适合于只读的应用程序。
PostgreSQL则只有一个存储引擎,即MVCC。
MVCC是多版本并发控制的缩写,它是PostgreSQL实现隔离级别的方式。
它允许多个用户同时访问数据库,每个用户看到的数据都是根据他们所在的事务版本而定的。
这些版本是通过创建快照来实现的,这个快照包括所有已提交的数据。
MVCC的优点是可以确保并发访问的同时,还能提供高可靠性和数据完整性,但是,它的缺点是需要更多的存储空间来存储快照,因此可能导致性能下降。
3.复杂操作PostgreSQL在处理复杂操作和大型数据集时更为出色。
例如PostgreSQL支持CTE(公共表表达式)和窗口函数,这些函数可以让用户更轻松地进行复杂的分析操作。
此外,PostgreSQL还支持全文搜索,这使得用户可以更轻松地搜索包含关键字的文本。
MySQL则在处理事务时更为出色。
MySQL支持更严格的事务隔离级别,因此在多个用户执行写操作时,MySQL可以保证数据的一致性和完整性。

Mysql和Postgresql(PGSQL)对⽐PostgreSQL与MySQL⽐较使⽤太⼴泛了,以⾄于我不得不将⼀些应⽤从mysql 迁移到postgresql, 很多开源软件都是以Mysql 作为标准,并且以Mysql 作为抽象基础的,但是具体使⽤过程中,发现Mysql 有很多问题,所以都迁移到postgresql上了,转⼀个Mysql 和Postgresql 对⽐的⽂章:PostgreSQL由于是类似Oracle的多进程框架,所以能⽀持⾼并发的应⽤场景,这点与Oracle数据库很像,所以把Oracle DBA转到PostgreSQL数据库上是⽐较容易的,毕竟PostgreSQL数据库与Oracle数据库很相似。
同时,PostgreSQL数据库的源代码要⽐MySQL数据库的源代码更容易读懂,如果团队的C语⾔能⼒⽐较强的知,就能在PostgreSQL数据库上做开发,⽐⽅说实现类似greenplum的系统,这样也能与现在的分布式趋势接轨。
为了说明PostgreSQL的功能,我下⾯简要对⽐⼀下PostgreSQL数据库与MySQL数据库之间的差异:我们先借助Jametong翻译的"从Oracle迁移到Mysql之前必须知道的50件事",看⼀看如何把Oracle转到MySQL中的困难:50 things to know before migrating Oracle to MySQLby Baron Schwartz,Translated by Jametong1. 对⼦查询的优化表现不佳.2. 对复杂查询的处理较弱3. 查询优化器不够成熟4. 性能优化⼯具与度量信息不⾜5. 审计功能相对较弱6. 安全功能不成熟,甚⾄可以说很粗糙.没有⽤户组与⾓⾊的概念,没有回收权限的功能(仅仅可以授予权限).当⼀个⽤户从不同的主机/⽹络以同样地⽤户名/密码登录之后,可能被当作完全不同的⽤户来处理.没有类似于Oracle的内置的加密功能.7. ⾝份验证功能是完全内置的.不⽀持LDAP,Active Directory以及其它类似的外部⾝份验证功能.8. Mysql Cluster可能与你的想象有较⼤差异.9. 存储过程与触发器的功能有限.10. 垂直扩展性较弱.11. 不⽀持MPP(⼤规模并⾏处理).12. ⽀持SMP(对称多处理器),但是如果每个处理器超过4或8个核(core)时,Mysql的扩展性表现较差.13. 对于时间、⽇期、间隔等时间类型没有秒以下级别的存储类型.14. 可⽤来编写存储过程、触发器、计划事件以及存储函数的语⾔功能较弱.15. 没有基于回滚(roll-back)的恢复功能,只有前滚(roll-forward)的恢复功能.16. 不⽀持快照功能.17. 不⽀持数据库链(database link).有⼀种叫做Federated的存储引擎可以作为⼀个中转将查询语句传递到远程服务器的⼀个表上,不过,它功能很粗糙并且漏洞很多.18. 数据完整性检查⾮常薄弱,即使是基本的完整性约束,也往往不能执⾏。

MySQL和其他数据库的对比及选择指南引言:在当今信息化时代,数据已经成为企业和组织中最重要的资产之一。
数据库技术的发展和应用已经成为大数据时代的关键驱动力之一。
在众多数据库中,MySQL以其开源、免费、易用等特点受到了广泛的青睐。
然而,随着技术的不断进步和需求的增长,其他数据库也不断崭露头角。
本文将比较MySQL和其他数据库,旨在帮助读者在众多选择中做出明智的决策。
一、性能对比性能是评估数据库的一个重要指标,直接关系着系统的效率和响应速度。
下面我们将MySQL与其他数据库进行性能对比。
1. MySQL vs. OracleOracle数据库是关系数据库的代表,它具有较高的性能和可靠性。
然而,Oracle的高昂的许可费用使其在中小型企业中的应用受到了限制,相比之下,MySQL是一个开源数据库,免费并且易于安装和维护。
针对小规模项目,MySQL 的性能已经完全能够满足需求。
2. MySQL vs. MongoDBMongoDB是一种面向文档的数据库,它以其高性能和水平扩展能力而闻名。
与MySQL相比,MongoDB具有更好的读取和写入性能,尤其适用于处理大量非结构化数据。
然而,MySQL在事务处理和数据一致性方面表现更加出色。
综上所述,根据具体的需求,选择合适的数据库是至关重要的。
如果注重可靠性和事务处理,可以选择MySQL或Oracle;如果注重大数据和高性能,可以选择MongoDB。
二、功能对比数据库的功能也是衡量其优劣的重要标准之一。
不同的数据库在功能方面存在一些差异,下面我们将来比较MySQL和其他数据库的功能。
1. MySQL vs. PostgreSQLPostgreSQL是另一种常见的开源关系型数据库,与MySQL相比,PostgreSQL 在功能方面更加强大。
例如,PostgreSQL支持更多的数据类型、索引和查询优化器,并且具有更好的事务支持和并发控制能力。
2. MySQL vs. Amazon AuroraAmazon Aurora是亚马逊推出的一种兼容MySQL和PostgreSQL的云数据库服务。
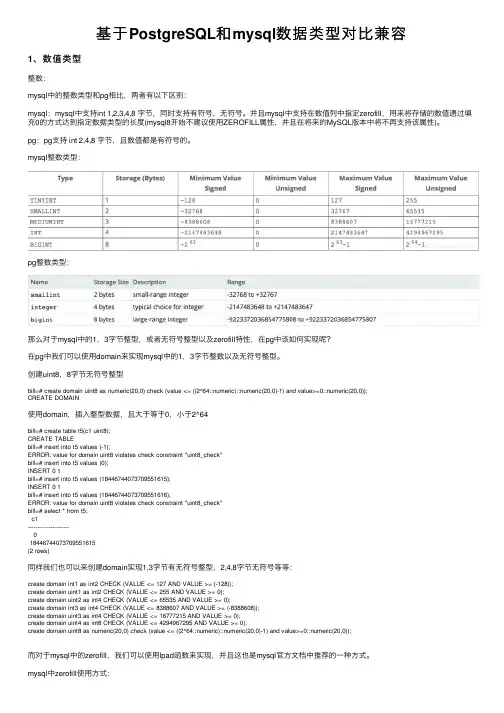
基于PostgreSQL和mysql数据类型对⽐兼容1、数值类型整数:mysql中的整数类型和pg相⽐,两者有以下区别:mysql:mysql中⽀持int 1,2,3,4,8 字节,同时⽀持有符号,⽆符号。
并且mysql中⽀持在数值列中指定zerofill,⽤来将存储的数值通过填充0的⽅式达到指定数据类型的长度(mysql8开始不建议使⽤ZEROFILL属性,并且在将来的MySQL版本中将不再⽀持该属性)。
pg:pg⽀持 int 2,4,8 字节,且数值都是有符号的。
mysql整数类型:pg整数类型:那么对于mysql中的1,3字节整型,或者⽆符号整型以及zerofill特性,在pg中该如何实现呢?在pg中我们可以使⽤domain来实现mysql中的1,3字节整数以及⽆符号整型。
创建uint8,8字节⽆符号整型bill=# create domain uint8 as numeric(20,0) check (value <= ((2^64::numeric)::numeric(20,0)-1) and value>=0::numeric(20,0));CREATE DOMAIN使⽤domain,插⼊整型数据,且⼤于等于0,⼩于2^64bill=# create table t5(c1 uint8);CREATE TABLEbill=# insert into t5 values (-1);ERROR: value for domain uint8 violates check constraint "uint8_check"bill=# insert into t5 values (0);INSERT 0 1bill=# insert into t5 values (18446744073709551615);INSERT 0 1bill=# insert into t5 values (18446744073709551616);ERROR: value for domain uint8 violates check constraint "uint8_check"bill=# select * from t5;c1----------------------18446744073709551615(2 rows)同样我们也可以来创建domain实现1,3字节有⽆符号整型,2,4,8字节⽆符号等等:create domain int1 as int2 CHECK (VALUE <= 127 AND VALUE >= (-128));create domain uint1 as int2 CHECK (VALUE <= 255 AND VALUE >= 0);create domain uint2 as int4 CHECK (VALUE <= 65535 AND VALUE >= 0);create domain int3 as int4 CHECK (VALUE <= 8388607 AND VALUE >= (-8388608));create domain uint3 as int4 CHECK (VALUE <= 16777215 AND VALUE >= 0);create domain uint4 as int8 CHECK (VALUE <= 4294967295 AND VALUE >= 0);create domain uint8 as numeric(20,0) check (value <= ((2^64::numeric)::numeric(20,0)-1) and value>=0::numeric(20,0));⽽对于mysql中的zerofill,我们可以使⽤lpad函数来实现,并且这也是mysql官⽅⽂档中推荐的⼀种⽅式。

MySQL与其他数据库系统的比较在当今信息化时代,数据库是各个企业和组织不可或缺的组成部分。
它能够帮助组织存储、管理和检索数据,促进业务的发展和决策的制定。
MySQL作为最热门的开源关系型数据库管理系统之一,在数据库市场中占有重要的地位。
然而,与MySQL类似的其他数据库系统也在企业中得到了广泛的应用。
本文将从性能、可扩展性、安全性和生态系统等方面,对MySQL与其他数据库系统进行比较。
一、性能比较数据库系统的性能是企业选择的关键因素之一。
MySQL作为一个经过优化的数据库系统,在基准测试中呈现出良好的性能。
然而,与之相比,其他数据库系统也有各自的优势。
1.1 OracleOracle作为全球领先的关系型数据库系统,以其强大的性能而闻名。
Oracle的查询优化器能够根据查询的复杂性和数据分布情况,选择最佳的执行计划来提高查询速度。
此外,Oracle还使用多线程架构来充分利用多核处理器的性能优势。
1.2 PostgreSQLPostgreSQL是另一个强大的开源关系型数据库系统,它在性能方面与MySQL 相媲美。
PostgreSQL具有高度可配置的查询优化器,可以根据数据库管理员的需求进行调整。
此外,PostgreSQL还支持并行查询和复制,进一步提高了系统的处理能力。
1.3 MongoDBMongoDB是一个非常受欢迎的NoSQL数据库系统,其性能优势主要在于其基于文档的数据模型和存储引擎。
相比于关系型数据库系统,MongoDB的插入和查询速度更快,特别适用于大规模数据的存储和实时数据处理。
二、可扩展性比较随着企业业务的增长,数据库系统的可扩展性变得越来越重要。
MySQL与其他数据库系统在可扩展性方面的差异主要体现在以下几个方面。
2.1 MySQLMySQL通过复制和分片来实现横向扩展。
复制是指将数据复制到多台机器上,提高读取性能和冗余容错能力。
而分片是指将数据分散到多个MySQL实例中,通过分布式计算来提高写入性能和存储能力。
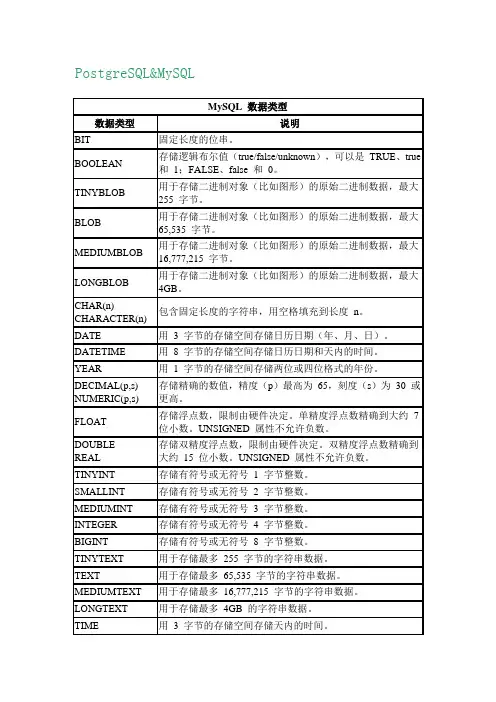

PostgreSQL与MySQL对⽐(转载)所有数据库对⽐可以参考:原⽂地址:⽐较版本:PostgreSQL 11 VS MySQL5.7(innodb引擎) Oracle官⽅社区版版权情况:PostgreSQL 11(免费开源)、MySQL5.7 Oracle官⽅社区版(免费开源)1. CPU限制PGSQL没有CPU核⼼数限制,有多少CPU核就⽤多少MySQL能⽤128核CPU,超过128核⽤不上2. 配置⽂件参数PGSQL⼀共有255个参数,⽤到的⼤概是80个,参数⽐较稳定,⽤上个⼤版本配置⽂件也可以启动当前⼤版本数据库MySQL⼀共有707个参数,⽤到的⼤概是180个,参数不断增加,就算⼩版本也会增加参数,⼤版本之间会有部分参数不兼容情况3. 第三⽅⼯具依赖情况PGSQL只有⾼可⽤集群需要依靠第三⽅中间件,例如:patroni+etcd、repmgrMySQL⼤部分操作都要依靠percona公司的第三⽅⼯具(percona-toolkit,XtraBackup),⼯具命令太多,学习成本⾼,⾼可⽤集群也需要第三⽅中间件,官⽅MGR集群还没成熟4. ⾼可⽤主从复制底层原理PGSQL物理流复制,属于物理复制,跟SQL Server镜像/AlwaysOn⼀样,严格⼀致,没有任何可能导致不⼀致,性能和可靠性上,物理复制完胜逻辑复制,维护简单MySQL主从复制,属于逻辑复制,(sql_log_bin、binlog_format等参数设置不正确都会导致主从不⼀致)⼤事务并⾏复制效率低,对于重要业务,需要依赖 percona-toolkit的pt-table-checksum和pt-table-sync⼯具定期⽐较和修复主从⼀致主从复制出错严重时候需要重搭主从MySQL的逻辑复制并不阻⽌两个不⼀致的数据库建⽴复制关系5. 从库只读状态PGSQL系统⾃动设置从库默认只读,不需要⼈⼯介⼊,维护简单MySQL从库需要⼿动设置参数super_read_only=on,让从库设置为只读,super_read_only参数有bug,链接:6. 版本分⽀PGSQL只有社区版,没有其他任何分⽀版本,PGSQL官⽅统⼀开发,统⼀维护,社区版有所有功能,不像SQL Server和MySQL有标准版、企业版、经典版、社区版、开发版、web版之分国内外还有⼀些基于PGSQL做⼆次开发的数据库⼚商,例如:Enterprise DB、瀚⾼数据库等等,当然这些只是⼆次开发并不算独⽴分⽀MySQL由于历史原因,分裂为三个分⽀版本,MariaDB分⽀、Percona分⽀、Oracle官⽅分⽀,发展到⽬前为⽌各个分⽀基本互相不兼容Oracle官⽅分⽀还有版本之分,分为标准版、企业版、经典版、社区版7. SQL特性⽀持PGSQLSQL特性⽀持情况⽀持94种,SQL语法⽀持最完善,例如:⽀持公⽤表表达式(WITH查询)MySQLSQL特性⽀持情况⽀持36种,SQL语法⽀持⽐较弱,例如:不⽀持公⽤表表达式(WITH查询)关于SQL特性⽀持情况的对⽐,可以参考:8. 主从复制安全性PGSQL同步流复制、强同步(remote apply)、⾼安全,不会丢数据PGSQL同步流复制:所有从库宕机,主库会罢⼯,主库⽆法⾃动切换为异步流复制(异步模式),需要通过增加从库数量来解决,⼀般⽣产环境⾄少有两个从库⼿动解决:在PG主库修改参数synchronous_standby_names ='',并执⾏命令: pgctl reload ,把主库切换为异步模式主从数据完全⼀致是⾼可⽤切换的第⼀前提,所以PGSQL选择主库罢⼯也是可以理解MySQL增强半同步复制,mysql5.7版本增强半同步才能保证主从复制时候不丢数据mysql5.7半同步复制相关参数:参数rpl_semi_sync_master_wait_for_slave_count 等待⾄少多少个从库接收到binlog,主库才提交事务,⼀般设置为1,性能最⾼参数rpl_semi_sync_master_timeout 等待多少毫秒,从库⽆回应⾃动切换为异步模式,⼀般设置为⽆限⼤,不让主库⾃动切换为异步模式所有从库宕机,主库会罢⼯,因为⽆法收到任何从库的应答包⼿动解决:在MySQL主库修改参数rpl_semi_sync_master_wait_for_slave_count=09. 多字段统计信息PGSQL⽀持多字段统计信息MySQL不⽀持多字段统计信息10. 索引类型PGSQL多种索引类型(btree , hash , gin , gist , sp-gist , brin , bloom , rum , zombodb , bitmap,部分索引,表达式索引)MySQLbtree 索引,全⽂索引(低效),表达式索引(需要建虚拟列),hash 索引只在内存表11. 物理表连接算法PGSQL⽀持 nested-loop join 、hash join 、merge joinMySQL只⽀持 nested-loop join12. ⼦查询和视图性能PGSQL⼦查询,视图优化,性能⽐较⾼MySQL视图谓词条件下推限制多,⼦查询上拉限制多13. 执⾏计划即时编译PGSQL⽀持 JIT 执⾏计划即时编译,使⽤LLVM编译器MySQL不⽀持执⾏计划即时编译14. 并⾏查询PGSQL并⾏查询(多种并⾏查询优化⽅法),并⾏查询⼀般多见于商业数据库,是重量级功能MySQL有限,只⽀持主键并⾏查询15. 物化视图PGSQL⽀持物化视图MySQL不⽀持物化视图16. 插件功能PGSQL⽀持插件功能,可以丰富PGSQL的功能,GIS地理插件,时序数据库插件,向量化执⾏插件等等MySQL不⽀持插件功能17. check约束PGSQL⽀持check约束MySQL不⽀持check约束,可以写check约束,但存储引擎会忽略它的作⽤,因此check约束并不起作⽤(mariadb ⽀持)18. gpu 加速SQLPGSQL可以使⽤gpu 加速SQL的执⾏速度MySQL不⽀持gpu 加速SQL 的执⾏速度19. 数据类型PGSQL数据类型丰富,如 ltree,hstore,数组类型,ip类型,text类型,有了text类型不再需要varchar,text类型字段最⼤存储1GBMySQL数据类型不够丰富20. 跨库查询PGSQL不⽀持跨库查询,这个跟Oracle 12C以前⼀样MySQL可以跨库查询21. 备份还原PGSQL备份还原⾮常简单,时点还原操作⽐SQL Server还要简单,完整备份+wal归档备份(增量)假如有⼀个三节点的PGSQL主从集群,可以随便在其中⼀个节点做完整备份和wal归档备份MySQL备份还原相对不太简单,完整备份+binlog备份(增量)完整备份需要percona的XtraBackup⼯具做物理备份,MySQL本⾝不⽀持物理备份时点还原操作步骤繁琐复杂22. 性能视图PGSQL需要安装pg_stat_statements插件,pg_stat_statements插件提供了丰富的性能视图:如:等待事件,系统统计信息等不好的地⽅是,安装插件需要重启数据库,并且需要收集性能信息的数据库需要执⾏⼀个命令:create extension pg_stat_statements命令否则不会收集任何性能信息,⽐较⿇烦MySQL⾃带PS库,默认很多功能没有打开,⽽且打开PS库的性能视图功能对性能有影响(如:内存占⽤导致OOM bug)23. 安装⽅式PGSQL有各个平台的包rpm包,deb包等等,相⽐MySQL缺少了⼆进制包,⼀般⽤源码编译安装,安装时间会长⼀些,执⾏命令多⼀些MySQL有各个平台的包rpm包,deb包等等,源码编译安装、⼆进制包安装,⼀般⽤⼆进制包安装,⽅便快捷24. DDL操作PGSQL加字段、可变长字段类型长度改⼤不会锁表,所有的DDL操作都不需要借助第三⽅⼯具,并且跟商业数据库⼀样,DDL操作可以回滚,保证事务⼀致性MySQL由于⼤部分DDL操作都会锁表,例如加字段、可变长字段类型长度改⼤,所以需要借助percona-toolkit⾥⾯的pt-online-schema-change⼯具去完成操作将影响减少到最低,特别是对⼤表进⾏DDL操作DDL操作不能回滚25. ⼤版本发布速度PGSQLPGSQL每年⼀个⼤版本发布,⼤版本发布的第⼆年就可以上⽣产环境,版本迭代速度很快PGSQL 9.6正式版推出时间:2016年PGSQL 10 正式版推出时间:2017年PGSQL 11 正式版推出时间:2018年PGSQL 12 正式版推出时间:2019年MySQLMySQL的⼤版本发布⼀般是2年~3年,⼀般⼤版本发布后的第⼆年才可以上⽣产环境,避免有坑,版本发布速度⽐较慢MySQL5.5正式版推出时间:2010年MySQL5.6正式版推出时间:2013年MySQL5.7正式版推出时间:2015年MySQL8.0正式版推出时间:2018年26. returning语法PGSQL⽀持returning语法,returning clause ⽀持 DML 返回 Resultset,减少⼀次 Client <-> DB Server 交互MySQL不⽀持returning语法27. 内部架构PGSQL多进程架构,并发连接数不能太多,跟Oracle⼀样,既然跟Oracle⼀样,那么很多优化⽅法也是相通的,例如:开启⼤页内存MySQL多线程架构,虽然多线程架构,但是官⽅有限制连接数,原因是系统的并发度是有限的,线程数太多,反⽽系统的处理能⼒下降,随着连接数上升,反⽽性能下降⼀般同时只能处理200 ~300个数据库连接28. 聚集索引PGSQL不⽀持聚集索引,PGSQL本⾝的MVCC的实现机制所导致MySQL⽀持聚集索引29. 空闲事务终结功能PGSQL通过设置 idle_in_transaction_session_timeout 参数来终⽌空闲事务,⽐如:应⽤代码中忘记关闭已开启的事务,PGSQL会⾃动查杀这种类型的会话事务MySQL不⽀持终⽌空闲事务功能30. 应付超⼤数据量PGSQL不能应付超⼤数据量,由于PGSQL本⾝的MVCC设计问题,需要垃圾回收,只能期待后⾯的⼤版本做优化MySQL不能应付超⼤数据量,MySQL⾃⾝架构的问题31. 分布式演进PGSQLHTAP数据库:cockroachDB、腾讯Tbase分⽚集群: Postgres-XC、Postgres-XLMySQLHTAP数据库:TiDB分⽚集群:各种各样的中间件,不⼀⼀列举32. 数据库的⽂件名和命名规律PGSQLPGSQL在这⽅⾯做的⽐较不好,DBA不能在操作系统层⾯(停库状态下)看清楚数据库的⽂件名和命名规律,⽂件的数量,⽂件的⼤⼩⼀旦操作系统发⽣⽂件丢失或硬盘损坏,⾮常不利于恢复,因为连名字都不知道PGSQL表数据物理⽂件的命名/存放规律是:在⼀个表空间下⾯,如果没有建表空间默认在默认表空间也就是base⽂件夹下,例如:/data/base/16454/3599base:默认表空间pg_default所在的物理⽂件夹16454:表所在数据库的oid3599:就是表对象的oid,当然,⼀个表的⼤⼩超出1GB之后会再⽣成多个物理⽂件,还有表的fsm⽂件和vm⽂件,所以⼀个⼤表实际会有多个物理⽂件由于PGSQL的数据⽂件布局内容太多,⼤家可以查阅相关资料当然这也不能全怪PGSQL,作为⼀个DBA,时刻做好数据库备份和容灾才是正道,做介质恢复⼀般是万不得已的情况下才会做MySQL数据库名就是⽂件夹名,数据库⽂件夹下就是表数据⽂件,每个表都有对应的frm⽂件和ibd⽂件,存储元数据和表/索引数据,清晰明了,做介质恢复或者表空间传输都很⽅便33. 权限设计PGSQLPGSQL在权限设计这块是⽐较坑爹,抛开实例权限和表空间权限,PGSQL的权限层次有点像SQL Server,db=》schema=》object要说权限,这⾥要说⼀下Oracle,⽤Oracle来类⽐在ORACLE 12C之前,实例与数据库是⼀对⼀,也就是说⼀个实例只能有⼀个数据库,不像MySQL和SQL Server⼀个实例可以有多个数据库,并且可以随意跨库查询⽽PGSQL不能跨库查询的原因也是这样,PGSQL允许建多个数据库,跟ORACLE类⽐就是有多个实例(之前说的实例与数据库是⼀对⼀)⼀个数据库相当于⼀个实例,因为PGSQL允许有多个实例,所以PGSQL单实例不叫⼀个实例,叫集簇(cluster),集簇这个概念可以查阅PGSQL的相关资料PGSQL⾥⾯⼀个实例/数据库下⾯的schema相当于数据库,所以这个schema的概念对应MySQL的database注意点:正因为是⼀个数据库相当于⼀个实例,PGSQL允许有多个实例/数据库,所以数据库之间是互相逻辑隔离的,导致的问题是,不能⼀次对⼀个PGSQL集簇下⾯的所有数据库做操作必须要逐个逐个数据库去操作,例如上⾯说到的安装pg_stat_statements插件,如果您需要在PGSQL集簇下⾯的所有数据库都做性能收集的话,需要逐个数据库去执⾏加载命令⼜例如跨库查询需要dblink插件或fdw插件,两个数据库之间做查询相当于两个实例之间做查询,已经跨越了实例了,所以需要dblink插件或fdw插件,所以道理⾮常简单权限操作也是⼀样逐个数据库去操作,还有⼀个就是PGSQL虽然像SQL Server的权限层次结构db=》schema=》object,但是实际会⽐SQL Server要复杂⼀些,还有就是新建的表还要另外授权在PGSQL⾥⾯,⾓⾊和⽤户是⼀样的,对新⼿⽤户来说有时候会傻傻分不清,也不知道怎么去⽤⾓⾊,所以PGSQL在权限设计这⼀块确实⽐较坑爹MySQL使⽤mysql库下⾯的5个权限表去做权限映射,简单清晰,唯⼀问题是缺少权限⾓⾊user表db表host表tables_priv表columns_priv表34. 发展历史PGSQL在1995年,开发⼈员Andrew Yu和Jolly Chen在Postgres中添加了⼀个SQL(Structured Query Language,结构化查询语⾔)翻译程序,该版本叫做Postgres95,在开放源代码社区发放。
MySQL与PostgreSQL相⽐哪个更好?⽹上已经有很多拿PostgreSQL与MySQL⽐较的⽂章了,这篇⽂章只是对⼀些重要的信息进⾏下梳理。
在开始分析前,先来看下这两张图:MySQLMySQL声称⾃⼰是最流⾏的开源数据库。
LAMP中的M指的就是MySQL。
构建在LAMP上的应⽤都会使⽤MySQL,如WordPress、Drupal等⼤多数php开源程序。
MySQL最初是由MySQL AB开发的,然后在2008年以10亿美⾦的价格卖给了Sun公司,Sun公司⼜在2010年被Oracle 收购。
Oracle⽀持MySQL的多个版本:Standard、Enterprise、Classic、Cluster、Embedded与Community。
其中有⼀些是免费下载的,另外⼀些则是收费的。
其核⼼代码基于GPL许可,由于MySQL被控制在Oracle,社区担⼼会对MySQL的开源会有影响,所以开发了⼀些分⽀,⽐如: MariaDB和Percona。
PostgreSQLPostgreSQL标榜⾃⼰是世界上最先进的开源数据库。
PostgreSQL的⼀些粉丝说它能与Oracle相媲美,⽽且没有那么昂贵的价格和傲慢的客服。
最初是1985年在加利福尼亚⼤学伯克利分校开发的,作为Ingres数据库的后继。
PostgreSQL是完全由社区驱动的开源项⽬。
它提供了单个完整功能的版本,⽽不像MySQL那样提供了多个不同的社区版、商业版与企业版。
PostgreSQL基于⾃由的BSD/MIT许可,组织可以使⽤、复制、修改和重新分发代码,只需要提供⼀个版权声明即可。
MySQL与PostgreSQL的对⽐MySQL的背后是⼀个成熟的商业公司,⽽PostgreSQL的背后是⼀个庞⼤的志愿开发组。
这使得MySQL的开发过程更为慎重,⽽PostgreSQL的反应更为迅速。
这样的两种背景直接导致了各⾃固有的优点和缺点。
PostgreSQL相对于MySQL的优势1)不仅仅是关系型数据库除了存储正常的数据类型外,还⽀持存储:array,不管是⼀位数组还是多为数组均⽀持json(hStore)和jsonb,相⽐使⽤text存储接送要⾼效很多json和jsonb之间的区别jsonb和json在更⾼的层⾯上看起来⼏乎是⼀样的,但在存储实现上是不同的。
SQL OperationMySQL 5.0.51MySQL 5.1.30with InnoDB 1.0.3PostgreSQLsecondssecondssecondssel_1_cl()00.020.04join_3_cl()0.060.050.02sel_100_ncl()0.010.010.03table_scan()10.54 4.130.64oin_2()1.78 1.620.89sel_variable_select_low()0.030.020sel_variable_select_high()12.527.8249.51oin_4_cl()000proj_100()7.137.35149.97join_4_ncl()0.0300proj_10pct()9.132.6820.06table_scan()select * from uniques where col_int = 1sel_1_cl()select col_key, col_int, col_signed, col_code, col_double, col_name from updates where col_key = 1000sel_1_ncl()select col_key, col_int, col_signed, col_code, col_double, col_name from updates where col_code = ‘BENCHMARKS’sel_100_cl()select col_key, col_int, col_signed, col_code, col_double, col_name from updates where col_key <= 100sel_100_ncl()select col_key, col_int, col_signed, col_code, col_double, col_name from updates where col_int <= 100sel_variable_select_high()select col_key, col_int, col_signed, col_code, col_double, col_name from tenpct where col_signed <:prog_var;sel_variable_select_low()select col_key, col_int, col_signed, col_code, col_double, col_name from tenpct where col_signed <:prog_var;join_4_cl()select uniques.col_date, hundred.col_date, tenpct.col_date, updates.col_date from uniques, hundred, tenpct, updates whereuniques.col_key = hundred.col_key and uniques.col_key = tenpct.col_key and uniques.col_key = updates.col_key andmysql 和postgresql 性能对⽐测试今天突然想知道mysql 和postgresql 的性能哪个好些搜索看了⼀些⽂章,然后看到⼀篇专业的测试⽂章对⽐测试的环境如下电脑配置Hardware ResourcesCPU: Intel(R) Pentium(R) D CPU 3.00GHz Dual Core RAM: 3G RamHDD: WDC WD3200AAJS-0测试安装的软件Software ResourcesDebian Lenny 5.0 64 bit archLinux painkiller 2.6.26-2-amd64 #1 SMP Wed May 13 15:37:46 UTC 2009 x86_64 GNU/Linux MySQL 5.0.51a-24+lenny1MySQL 5.1.30 Sun compiledInnoDB 1.0.3 Plugin compiled by ORACLE for MySQL 5.1.30PostgreSQL 8.3.72.1 – Opensource Database benchmark.使⽤osdb ⽣成了1024m 的数据来测试The test was made on a 1024MB of data and the multiple users test was made with 100 users simultaneously on the same database.截取⼀部分测试结果⼤家看uniques.col_key = 1000join_4_ncl()select uniques.col_date, hundred.col_date, tenpct.col_date, updates.col_date from uniques, hundred, tenpct, updates whereuniques.col_code = hundred.col_code and uniques.col_code = tenpct.col_code and uniques.col_code = updates.col_code anduniques.col_code = ‘BENCHMARKS’sel_variable_select_high()select col_key, col_int, col_signed, col_code, col_double, col_name from tenpct where col_signed < :prog_var;sel_variable_select_low()select col_key, col_int, col_signed, col_code, col_double, col_name from tenpct where col_signed < :prog_var;sel_1_cl()select col_key, col_int, col_signed, col_code, col_double, col_name from updates where col_key = 1000table_scan()select * from uniques where col_int = 1---------------------------------------------------------------------------------------------------------------------------------------------------------- 在⼀些常规的根据表的键查询MySQL 5.1.30 with InnoDB 1.0.3居然还快过postgresql但是表扫描就要慢了可见mysql 也不是被postgresql ⽐的⼀⽆是处⼤家可以再研究下对⽐结果。
特性MySQL PostgreSQL实例通过执行MySQL 命令(mysqld)启动实例。
一个实例可以管理一个或多个数据库。
一台服务器可以运行多个mysqld实例。
一个实例管理器可以监视mysqld的各个实例。
通过执行Postmaster 进程(pg_ctl)启动实例。
一个实例可以管理一个或多个数据库,这些数据库组成一个集群。
集群是磁盘上的一个区域,这个区域在安装时初始化并由一个目录组成,所有数据都存储在这个目录中。
使用initdb创建第一个数据库。
一台机器上可以启动多个实例。
数据库数据库是命名的对象集合,是与实例中的其他数据库分离的实体。
一个MySQL 实例中的所有数据库共享同一个系统编目。
数据库是命名的对象集合,每个数据库是与其他数据库分离的实体。
每个数据库有自己的系统编目,但是所有数据库共享pg_databases。
数据缓冲区通过innodb_buffer_pool_size配置参数设置数据缓冲区。
这个参数是内存缓冲区的字节数,InnoDB使用这个缓冲区来缓存表的数据和索引。
在专用的数据库服务器上,这个参数最高可以设置为机器物理内存量的80%。
Shared_buffers缓存。
在默认情况下分配64 个缓冲区。
默认的块大小是8K。
可以通过设置postgresql.conf文件中的shared_buffers参数来更新缓冲区缓存。
数据库连接客户机使用CONNECT 或USE 语句连接数据库,这时要指定数据库名,还可以指定用户id 和密码。
使用角色管理数据库中的用户和用户组。
客户机使用connect 语句连接数据库,这时要指定数据库名,还可以指定用户id 和密码。
使用角色管理数据库中的用户和用户组。
身份验证MySQL 在数据库级管理身份验证。
基本只支持密码认证。
PostgreSQL支持丰富的认证方法:信任认证、口令认证、Kerberos 认证、基于Ident的认证、LDAP 认证、PAM 认证加密可以在表级指定密码来对数据进行加密。
PostgreSQL与MySQL相⽐,优势何在?⼀、 PostgreSQL 的稳定性极强, Innodb 等引擎在崩溃、断电之类的灾难场景下抗打击能⼒有了长⾜进步,然⽽很多 MySQL ⽤户都遇到过Server级的数据库丢失的场景——mysql系统库是MyISAM的,相⽐之下,PG数据库这⽅⾯要好⼀些。
⼆、任何系统都有它的性能极限,在⾼并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚⾄对数曲线,到顶峰之后不再下降,⽽ MySQL 明显出现⼀个波峰后下滑(5.5版本之后,在企业级版本中有个插件可以改善很多,不过需要付费)。
三、PG 多年来在 GIS 领域处于优势地位,因为它有丰富的⼏何类型,实际上不⽌⼏何类型,PG有⼤量字典、数组、bitmap 等数据类型,相⽐之下mysql就差很多,instagram就是因为PG的空间数据库扩展POSTGIS远远强于MYSQL的my spatial⽽采⽤PGSQL的。
四、PG 的“⽆锁定”特性⾮常突出,甚⾄包括 vacuum 这样的整理数据空间的操作,这个和PGSQL的MVCC实现有关系。
五、PG 的可以使⽤函数和条件索引,这使得PG数据库的调优⾮常灵活,mysql就没有这个功能,条件索引在web应⽤中很重要。
六、PG有极其强悍的 SQL 编程能⼒(9.x 图灵完备,⽀持递归!),有⾮常丰富的统计函数和统计语法⽀持,⽐如分析函数(ORACLE的叫法,PG⾥叫window函数),还可以⽤多种语⾔来写存储过程,对于R的⽀持也很好。
这⼀点上MYSQL就差的很远,很多分析功能都不⽀持,腾讯内部数据存储主要是MYSQL,但是数据分析主要是HADOOP+PGSQL。
七、PG 的有多种集群架构可以选择,plproxy 可以⽀持语句级的镜像或分⽚,slony 可以进⾏字段级的同步设置,standby 可以构建WAL⽂件级或流式的读写分离集群,同步频率和集群策略调整⽅便,操作⾮常简单。
数据库选择指南MySQLvsPostgreSQLvsMongoDB 数据库选择指南:MySQL vs PostgreSQL vs MongoDB在当今信息时代,数据的重要性不言而喻。
对于企业和个人而言,选择合适的数据库管理系统(DBMS)至关重要。
在众多的DBMS中,MySQL、PostgreSQL和MongoDB因其性能和功能的出色表现而备受关注。
本文将对这三种流行的数据库进行比较和评估,为读者在选择适合自己需求的DBMS时提供一些建议。
一、MySQL:经典而稳定MySQL是一种开源的关系型数据库管理系统。
作为Web应用中最常用的数据库之一,它具有以下优点:1. 易于使用:MySQL拥有直观且用户友好的用户界面,允许用户轻松管理和操作数据库。
2. 良好的性能:由于其简洁的架构和高效的索引机制,MySQL在大多数场景下都能提供稳定且高效的性能。
3. 成熟的生态系统:MySQL拥有庞大的用户群体和活跃的社区,用户能够获得大量的优质支持和文档。
4. 简单的扩展性:MySQL提供了易于扩展的机制,可以根据需求进行水平或垂直扩展,以满足不断增长的数据存储需求。
5. 可靠性和稳定性:MySQL经过多年的发展和测试,已经被广泛应用于各种场景,并获得了良好的稳定性和可靠性。
尽管MySQL具有众多的优点,但也存在一些限制。
例如,对于复杂的关系查询和大数据存储,MySQL的性能可能无法满足需求。
此外,MySQL对于非结构化数据的存储和处理能力相对较弱。
二、PostgreSQL:功能强大的开源选择PostgreSQL是一种功能强大的开源关系型数据库管理系统。
相较于MySQL,它具有以下优点:1. 丰富的功能:PostgreSQL支持许多高级功能,如自定义数据类型、触发器和复杂查询等,使其成为处理复杂数据需求的理想选择。
2. 可扩展性:PostgreSQL提供了强大的扩展性机制,使用户能够根据需要添加自定义插件和功能,适应不断增长的数据处理需求。
MySQL和PostgreSQL两数据库的对决
在这篇文章中,我们选用MySQL4.0.2-alpha与PostgreSQL7.2进行比较,因为MySQL4.0.2-alpha开始支持事务的概念,因此这样的比较对于MySQL应该较为有利。
我们这样的比较不想仅仅成为一份性能测试报告,因为至少从我个人来看,对于一个数据库,稳定性和速度并不能代表一切。
对于一个成熟的数据库,稳定性肯定会日益提供。
而随着硬件性能的飞速提高,速度也不再是什么太大的问题。
一、前言
前一段时间,我曾经翻译过一篇将你的网站从MySQL改为PostgreSQL,其实当初我更感兴趣的是一个应用程序的后台数据库从MySQL转为PostgreSQL的具体操作,并没有关心MySQL和PostgreSQL的优劣,没想到反应出乎意料的大,因此我也就觉得有写这篇文章的必要了。
在这篇文章中,我们选用MySQL4.0.2-alpha与PostgreSQL7.2进行比较,因为MySQL4.0.2-alpha开始支持事务的概念,因此这样的比较对于MySQL应该较为有利。
我们这样的比较不想仅仅成为一份性能测试报告,因为至少从我个人来看,对于一个数据库,稳定性和速度并不能代表一切。
对于一个成熟的数据库,稳定性肯定会日益提供。
而随着硬件性能的飞速提高,速度也不再是什么太大的问题。
二、两者的共同优势
这两个产品都属于开放源码的一员,性能和功能都在高速地提高和增强。
MySQLAB的人们和PostgreSQL的开发者们都在尽可能地把各自的数据库改得越来越好,所以对于任何商业数据库使用其中的任何一个都不能算是错误的选择。
三、两者不同的背景
MySQL的背后是一个成熟的商业公司,而PostgreSQL的背后是一个庞大的志愿开发组。
这使得MySQL的开发过程更为慎重,而PostgreSQL的反应更为迅速。
这样的两种背景直接导致了各自固有的优点和缺点。
四、MySQL的主要优点
1、首先是速度,MySQL通常要比PostgreSQL快得多。
MySQL自已也宣称速度是他们追求的主要目标之一,基于这个原因,MySQL在以前的文档中也曾经说过并不准备支持事务和触发器。
但是在最新的文档中,我们看到MySQL4.0.2-alpha已经开始支持事务,而且在MySQL的TODO中,对触发器、约束这样的注定会降低速度的功能也列入了日程。
但是,我们仍然有理由相信,
MySQL将有可能一直保持速度的优势。
2、MySQL比PostgreSQL更流行,流行对于一个商业软件来说,也是一个很重要的指标,流行意味着更多的用户,意味着经受了更多的考验,意味着更好的商业支持、意味着更多、更完善的文档资料。