Distributed database design overview
- 格式:pdf
- 大小:108.71 KB
- 文档页数:3


巨链数据库:一个可扩展的区块链型摘要:巨链数据库(BigchainDB )其功能上可以达到每秒百万次写入,源于去中心化数据库(DB),并且加入免疫攻击,以及创建和转移数字资产随节点数量线性扩展吞吐量,完全特数据库基于已有的分布式DB ,因此大具法律约束力的合同及证书都可储存块链数据库以及公开公众的区块链数太坊,分布式文档存储系统如IPFS 传统区块链,分布式数据库,以及这是向分布式DB 导入类区块链特性时延迟的分析还有初步的实验结果。
(本文仅翻译摘要部分,欢迎大家块链型数据库(草稿)填补了去中化生态系统中一个空白:即去中心化数据写入,数据存储量以P 计算,次秒延迟。
BigchainDB 设加入了一系列的创新功能:区块链特性;去中心化控字资产。
BigchainDB 具有目前流行的去中心化数据库的特完全特性的NoSQL 查询语言,高效查询及权限控制。
因此大多数源码也经过企业级别的测试。
容量可扩展意在区块链数据库上。
权限控制系统意味着私人企业块链数据库都可共存。
BigchainDB 是对分布式处理平台PFS 的一种补充。
本文描述了BigchainDB 设计的技术角以及DNS 的案例分析。
我们引入了“区块链输送管道”特性,可扩展性的关键。
本文还详细描述了Bigchai 果文末是一些应用案例。
(本文仅翻译摘要部分,欢迎大家指正或到巴比特论坛分享读后感miner@化数据库。
的设计起心化控制;库的特点:。
由于本扩展意味着人企业的区理平台如以技术角度:”的概念,gchainDB ,.com )BigchainDB:A Scalable Blockchain Database(DRAFT)McConaghy,Trent Marques,Rodolphe M¨u ller,Andreas De Jonghe,Dimitri McConaghy,Troy McMullen,Greg Henderson,Ryan Bellemare,Sylvain Granzotto,AlbertoFebruary12,2016ascribe GmbH,Berlin,GermanyThis paper describes BigchainDB.BigchainDBfills a gap in the decentral-ization ecosystem:a decentralized database,at scale.It points to perfor-mance of1million writes per second throughput,storing petabytes of data, and sub-second latency.The BigchainDB design starts with a distributed database(DB),and through a set of innovations adds blockchain characteris-tics:decentralized control,immutability,and creation&movement of digital assets.BigchainDB inherits characteristics of modern distributed databases: linear scaling in throughput and capacity with the number of nodes,a full-featured NoSQL query language,efficient querying,and permissioning.Being built on an existing distributed DB,it also inherits enterprise-hardened code for most of its codebase.Scalable capacity means that legally binding con-tracts and certificates may be stored directly on the blockchain database.The permissioning system enables configurations ranging from private enterprise blockchain databases to open,public blockchain databases.BigchainDB is complementary to decentralized processing platforms like Ethereum,and de-centralizedfile systems like InterPlanetary File System(IPFS).This paper describes technology perspectives that led to the BigchainDB design:tra-ditional blockchains,distributed databases,and a case study of the domain name system(DNS).We introduce a concept called blockchain pipelining, which is key to scalability when adding blockchainlike characteristics to the distributed DB.We present a thorough description of BigchainDB,an anal-ysis of latency,and preliminary experimental results.The paper concludes with a description of use cases.11.Introduction1.1.Towards a Decentralized Application StackThe introduction of Bitcoin[1]has triggered a new wave of decentralization in computing. Bitcoin illustrated a novel set of benefits:decentralized control,where“no one”owns or controls the network;immutability,where written data is tamper-resistant(“forever”); and the ability to create&transfer assets on the network,without reliance on a central entity.The initial excitement surrounding Bitcoin stemmed from its use as a token of value, for example as an alternative to government-issued currencies.As people learned more about the underlying blockchain technology,they extended the scope of the technology itself(e.g.smart contracts),as well as applications(e.g.intellectual property).With this increase in scope,single monolithic“blockchain”technologies are being re-framed and refactored into building blocks at four levels of the stack:1.Applications2.Decentralized computing platforms(“blockchain platforms”)3.Decentralized processing(“smart contracts”)and decentralized storage(file sys-tems,databases),and decentralized communication4.Cryptographic primitives,consensus protocols,and other algorithms1.2.Blockchains and DatabasesWe can frame a traditional blockchain as a database(DB),in the sense that it provides a storage mechanism.If we measure the Bitcoin blockchain by traditional DB criteria,it’s terrible:throughput is just a few transactions per second(tps),latency before a single confirmed write is10minutes,and capacity is a few dozen GB.Furthermore,adding nodes causes more problems:with a doubling of nodes,network traffic quadruples with no improvement in throughput,latency,or capacity.It also has essentially no querying abilities:a NoQL1database.In contrast,a modern distributed DB can have throughput exceeding1million tps, capacity of Petabytes and beyond,latency of a fraction of a second,and throughput and capacity that increases as nodes get added.Modern DBs also have rich abilities for insertion,queries,and access control in SQL or NoSQLflavors;in fact SQL is an international ANSI and ISO standard.1.3.The Need for ScaleDecentralized technologies hold great promise to rewire modernfinancial systems,supply chains,creative industries,and even the Internet itself.But these ambitious goals need1We are introducing the term NoQL to describe a database with essentially no query abilities.This term is not to be confused with the database company noql().2scale:the storage technology needs throughput of up to millions of transactions per second(or higher),sub-second latency2,and capacity of petabytes or more.These needs exceed the performance of the Bitcoin blockchain by many orders of magnitude.1.4.BigchainDB:Blockchains Meet Big DataThis paper introduces BigchainDB,which is for database-style decentralized storage:a blockchain database.BigchainDB combines the key benefits of distributed DBs and traditional blockchains,with an emphasis on scale,as Table1summarizes.Table1:BigchainDB compared to traditional blockchains,and traditional distributed DBsWe built BigchainDB on top of an enterprise-grade distributed DB,from which BigchainDB inherits high throughput,high capacity,low latency,a full-featured efficient NoSQL query language,and permissioning.Nodes can be added to increase throughput and capacity.BigchainDB has the traditional blockchain benefits of decentralized control,immutabil-ity,and creation&transfer of assets.The decentralized control is via a federation of nodes with voting permissions,that is,a super-peer P2P network[2].The voting oper-ates at a layer above the DB’s built in consensus.Immutability/tamper-resistance isvia an ordered sequence of blocks where each block holds an ordered sequence of trans-actions;and a block’s hash is over its transactions and related data,and the previous block’s hash;that is,a block chain.Any entity with asset-issuance permissions can is-sue an asset;any entity with asset-transfer permissions and the asset’s private key may2It takes light140ms to make one trip around the world,or70ms halfway around.Somefinancial applications need30-100ms latency,though due to speed-of-light constraints those necessarily need to be more locally constrained.Section6explores this in detail.3Centralized Decentralized Figure 1:From a base context of a centralized cloud computing ecosystem (left),BigchainDB can be added as another database to gain some decentraliza-tion benefits (middle).It also fits into a full-blown decentralization ecosystem (right).transfer the asset.This means hackers or compromised system admins cannot arbitrarily change data,and there is no single-point-of-failure risk.Scalable capacity means that legally binding contracts and certificates may be stored directly on the blockchain DB.The permissioning system enables configurations ranging from private enterprise blockchain DBs to open,public blockchain DBs.As we deploy BigchainDB,we are also deploying a public version.1.5.BigchainDB in the Decentralization Ecosystem Figure 1illustrates how BigchainDB can be used in a fully decentralized setting,or as a mild extension from a traditional centralized computing context.BigchainDB is complementary to decentralized processing /smart contracts (e.g.Ethereum VM [3][4]or Enigma [5][6]),decentralized file systems (e.g.IPFS [7]),and communication building blocks (e.g.email).It can be included in higher-level decen-tralized computing platforms (e.g.Eris/Tendermint [8][9]).It can be used side-by-side with identity protocols,financial asset protocols (e.g.Bitcoin [1]),intellectual property asset protocols (e.g.SPOOL [10]),and glue protocols (e.g.pegged sidechains [11],In-terledger [12]).Scalability improvements to smart contracts blockchains will help fully decentralized applications to better exploit the scalability properties of BigchainDB.BigchainDB works in compliance with more centralized computing blocks too.One use case is where decentralizing just storage brings the majority of benefit.Another use case is where scalability needs are greater than the capabilities of existing decentralized processing technologies;in this case BigchainDB provides a bridge to an eventual fully-decentralized system.41.6.ContentsThis paperfirst gives background on related building blocks,with an eye to scale:•Section2-traditional blockchain scalability,•Section3-distributed DBs,andThen,this paper describes BigchainDB as follows:•Section4-BigchainDB description,•Section5-BigchainDB implementation,including capacity vs.nodes(Figure10),•Section6-BigchainDB latency analysis,•Section7-private vs.public BigchainDBs in a permissioning context,•Section8-BigchainDB benchmarks,including throughput vs.nodes(Figure14),•Section9-BigchainDB deployment,including use cases and timeline,and•Section10-conclusion.The appendices contain:•Appendix A-a glossary,e.g.clarifying“distributed”vs.“decentralized”,•Appendix B-blockchain scalability proposals,and•Appendix C-the Domain Name System(DNS).•Appendix D–further BigchainDB benchmarks.2.Background:Traditional Blockchain ScalabilityThis section discusses how traditional blockchains perform with respect to scalability, with an emphasis on Bitcoin.2.1.Technical Problem DescriptionTechnically speaking,a traditional blockchain is a distributed database(DB)that solves the“Strong Byzantine Generals”(SBG)problem[13],the name given to a combination of the Byzantine Generals problem and the Sybil Attack problem.In the Byzantine Generals problem[14],nodes need to agree on some value for a DB entry,under the con-straint that the nodes may fail in arbitrary(malicious)ways.The Sybil Attack problem [15]arises when one or more nodesfigure out how to get unfairly disproportionate influ-ence in the process of agreeing on a value for an entry.It’s an“attack of the clones”—an army of seemingly independent voters actually working together to game the system.52.2.Bitcoin Scalability IssuesBitcoin has scalability issues in terms of throughput,latency,capacity,and network bandwidth.Throughput.The Bitcoin network processes just1transaction per second(tps)on average,with a theoretical maximum of7tps[16].It could handle higher throughput if each block was bigger,though right now making blocks bigger would lead to size is-sues(see Capacity and network bandwidth,below).This throughput is unacceptably low when compared to the number of transactions processed by Visa(2,000tps typical, 10,000tps peak)[17],Twitter(5,000tps typical,15,000tps peak),advertising net-works(500,000tps typical),trading networks,or email networks(global email volume is183billion emails/day or2,100,000tps[18]).An ideal global blockchain,or set of blockchains,would support all of these multiple high-throughput uses.Latency.Each block on the Bitcoin blockchain takes10minutes to process.For suffi-cient security,it is better to wait for about an hour,giving more nodes time to confirm the transaction.By comparison,a transaction on the Visa network is approved in sec-onds at most.Manyfinancial applications need latency of30to100ms.Capacity and network bandwidth.The Bitcoin blockchain is about50GB;it grew by24GB in2015[19].It already takes nearly a day to download the entire blockchain.If throughput increased by2,000x to Visa levels,the additional transactions would result in database growth of3.9GB/day or1.42PB/year.At150,000tps,the blockchain would grow by214PB/year(yes,petabytes).If throughput were1M tps,it would completely overwhelm the bandwidth of any node’s connection,which is counterproductive to the democratic goals of Bitcoin.2.3.Technology Choices Affecting ScalabilityThe Bitcoin blockchain has taken three technology choices,which hurt scaling:1.Consensus Algorithm:POW.Bitcoin’s mining rewards actually incentivizesnodes to increase computational resource usage,without any additional gains in throughput,latency,or capacity.A single confirmation from a node takes10 minutes on average,and six confirmations take an hour.In Bitcoin this is by design;Litecoin and other altcoins reduce the latency,but compromise security.2.Replication:Full.That is,each node stores a copy of all the data;a“full node”.This copy is typically kept on a single hard drive(or in memory).Ironically,this causes centralization:as amount of data grows,only those with the resources to hold all the data will be able to participate.munication Protocol:Broadcast.Bitcoin uses a simple broadcast net-work to propagate transactions,meaning that bandwidth use increases as a square of the number of nodes in terms of bandwidth overhead.For example,10x more nodes uses100x more network traffic.Right now there are approximately6,500 nodes,so every new node has6,500nodes worth of communication to deal with.6Any one of these characteristics prevents Bitcoin blockchain from scaling up.2.4.Blockchain Scalability EffortsThe Bitcoin/blockchain community has spent considerable effort to scale performance of blockchains.The Appendix gives reviews these proposals in more detail.Most effort has been on improving one characteristic:the consensus algorithm,for example via proof of stake(POS).To our knowledge,no previous work has addressed all three issues.So,a necessary but not sufficient constraint in BigchainDB design is to avoid these three technology choices.What previous approaches share in common is that they are all starting with a blockchain design,then trying to increase its performance.There’s another way:start with a“big data”distributed database,then give it blockchain-like characteristics. 3.Background:Distributed Databases&Big Data3.1.IntroductionWe ask:does the world have any precedents for distributed databases at massive scale? The answer is yes.All large Internet companies,and many small ones,run“big data”distributed databases(DBs),including Facebook,Google,Amazon and Netflix.For example,at any given time Netflix might be serving up content making up35%of the bandwidth of the entire Internet[20].Distributed DBs regularly store petabytes(1,000,000GB)or more worth of content. In contrast,the Bitcoin blockchain currently stores50GB,the capacity of a modern thumb drive.There are initiatives to prevent“blockchain bloat”caused by“dust”or “junk”transactions that“pollute”Bitcoin’s50GB database[21].In light of petabyte-capacity DBs,it is ironic that a50GB database would be con-cerned by“bloat”.But let’s look at it another way:perhaps distributed DB technology has lessons for blockchain DB design.Let’s explore distributed DB scalability further.Figure2illustrates the throughput properties of Cassandra,a distributed DB technol-ogy used by Netflix.At the bottom left of the plot,we see that50distributed Cassandra nodes handle174,000tps.Increasing to300nodes gives1.1million transactions per sec-ond(tps)[22].A follow-up study three years later showed a throughput of1million tps with just a few dozen nodes[23].To emphasize:the throughput of this DB increased as the number of nodes increased.The scaling is linear:10×more nodes means(10c)×more throughput,where0<c≤1.Each node also stores data.Critically,a node only stores a subset of all data,that is,it has partial replication.In the Netflix example[23],each piece of data has three copies in the system,i.e.a replication factor of three.Partial replication enables an increase in the number of nodes to increase storage capacity.Most modern distributed DBs have a linear increase in capacity with the number of nodes,an excellent property.7Figure2:Netflix experimental data on throughput of its Cassandra database(Client writes/s by node count-Replication Factor=3).The x-axis is number ofnodes;the y-axis is transactions per second.From[22].Additionally,as the number of nodes increases,Cassandra’s latency and network usage does not worsen.Cassandra can be distributed at scale not only throughout a region, but around the globe.Contrast this to the Bitcoin blockchain,where capacity does not change as the number of nodes increases.The scalability properties of distributed DBs like Cassandra make an excellent refer-ence target.3.2.Consensus Algorithms in Distributed Databases3.2.1.IntroductionCassandra achieves its scale because it avoids scalability-killing decisions like making a full copy of all the data at every node,the baggage of mining,coins,and the like. What Cassandra does have is a consensus algorithm that uses2f+1processes to tolerate f benign processes[24],which is used to get the distributed data to synchronize. Synchronizing distributed data was in fact the original motivation for the BG problem. The problem wasfirst documented in1980by Leslie Lamport and colleagues[25],and solved two years later,also by Lamport and colleagues.The solution is the Paxos protocol[14]with versions that can tolerate f Byzantine faults using3f+1processes [26,27]3.3Benign faults are system crashes,lost messages,and the like.In systems with benign faults,all nodes are assumed to follow the same protocol.Byzantine faults include benign faults,but also deviations from the protocol,including lying,collusion,selective non-participation,and other arbitrary behavior.83.2.2.Paxos Consensus AlgorithmThis section describes the origins of Paxos.In1980,Lamport challenged colleagues with the following question:Can you implement a distributed database that can tolerate the failure ofany number of its processes(possibly all of them)without losing consistency,and that will resume normal behavior when more than half the processes areagain working properly?[28]It was generally assumed at the time that a three-processor system couldtolerate one faulty mport’s paper introduced the problem ofhandling“Byzantine”faults,in which a faulty processor sends inconsistentinformation to the other processors,which can defeat any traditional three-processor algorithm.In general,3f+1processors are needed to tolerate ffaults.However,if digital signatures are used,2f+1processors are enough.This was thefirst precise statement of the consensus problem[14].Lamport then set out to prove the problem was impossible to solve[28].Instead,in a happy accident,he discovered the Paxos algorithm[24].At the heart of Paxos is a three-phase consensus mport wrote,“to my knowledge,Paxos contains thefirst three-phase commit algorithmthat is a real algorithm,with a clearly stated correctness condition and aproof of correctness”[28].Paxos overcame the impossibility result of Fischeret al.[29]by using clocks to ensure liveness.3.3.Extensions to Paxos ConsensusThe original Paxos could handle arbitrary benign(non-Byzantine)failuressuch as network delays,packet loss,system crashes and so on.Several Byzantine fault tolerant systems were designed in the1980s[30],including Draper’s FTMP[31],Honeywell’s MMFCS[32],and SRI’s SIFT[33].However,those early systems were slow when it came to m-port’s“Fast Paxos”[34]and Castro’s“Practical Byzantine Fault Tolerance”(PBFT)[27]improved upon speed under malicious conditions.Aardvark[35]and RBFT[36]are examples of continued research in speed and reliability.Paxos is notoriously difficult to understand,and risky to implement.Toaddress this,Raft[37]was designed specifically for ease of understanding,and consequent lower implementation risk.It has a robust variant[38].The recent Stellar protocol allows each node to choose which other nodes totrust for validation[39].9age/EcosystemMike Burrows of Google(co-inventor of Google’s Chubby,BigTable,andDapper)has said“There is only one consensus protocol,and that’s Paxos,”[40]and“all working protocols for asynchronous consensus we have so farencountered have Paxos at their core”[41].Henry Robinson of Cloudera hassaid“all other approaches are just broken versions of Paxo”and“it’s clearthat a good consensus protocol is surprisingly hard tofind.”[40]4.Paxos and its lineage is used at Google,IBM,Microsoft,OpenReplica,VMWare, XtreemFS,Heroku,Ceph,Clustrix,Neo4j,and certainly many more[42].3.5.Replication factor&blockchain“full nodes”A modern distributed DB is designed to appear like a single monolithic DB,but under the hood it distributes storage across a network holding manycheap storage devices.Each data record is stored redundantly on multipledrives,so if a drive fails the data can still be easily recovered.If only onedisk fails at a time,there only needs to be one backup drive for that data.The risk can be made arbitrarily small,based on assumptions of how manydisks might fail at once.Modern distributed DBs typically have3backupsper data object,a replication factor of3[43].In contrast,Bitcoin has about6,500full nodes[44]—a replication factorof6,500.The chance of all nodes going down at once in any given hour(assuming complete independence)is(1/8760)6500,or10−25626.The chanceof all nodes going down would occur once every3,000billion years.To saythis is overkill is to put it mildly.Of course,hardware failure is not the only reason for lost data.Attacksagainst the nodes of the network have a much higher probability of destroy-ing data.A well-targeted attack to2or3mining pools could just remove50%of the computing power from the current Bitcoin network,making the net-work unusable until the next adjustment to POW complexity,which happensabout every two weeks.3.6.Strengths and WeaknessesLet’s review the strengths and weaknesses of DBs that use Paxos-style dis-tributed consensus algorithms.Strengths.As discussed above,Paxos is a proven consensus algorithm thattolerates benign faults and extensions for Byzantine tolerance have been re-ported.It is used by“big data”distributed DBs with the well-documented4An especially interesting statement in light of efforts the Bitcoin community is spending on consensus algorithms.10ability to handle high throughput,low latency,high capacity,efficient net-work utilization,and any shape of data,including table-like SQL interfaces, object structures of NoSQL DBs,and graph DBs,and they handle replication in a sane fashion.Derivatives like Raft make distributed consensus systems easier to design and deploy.Weaknesses.While their technical attributes and performance are impres-sive,traditional“big data”distributed DBs are not perfect:they are cen-tralized.They are deployed by a single authority with central control,rather than decentralized control as in blockchains.This creates a number of fail-ings.Centralized DBs are:•Susceptible to a single point of failure,where a single node being hacked can be disastrous.Thisflaw is what lead to hacks at Target, Sony,the U.S.Office of Personnel Management(OPM),and many others [45,46].•Mutable.A hacker could change a5-year-old record without anyone noticing(assuming no additional safeguards in place).For example,this would have prevented police from doctoring evidence in the India exam scandal[47].Such tampering is not possible in blockchains because past transactions cannot be changed or deleted,as each new block contains a“hash”digest of all previous blocks.•Not usable by participants with divergent interests in situations where they do not want to cede control to a single administrator.For example,the risk of losing control of the management of information is one reason that copyright rightsholders in the music industry do not share a single DB.•Not designed to stop Sybil attacks,where one errant node can swamp all the votes in the system.•Traditionally without support for the creation and transfer of digital assets where only the owner of the digital asset,not the administrator of the DB,can transfer the asset.•Not typically open to the public to even read,let alone write.Public openness is important for public utilities.A notable exception is WikiData[48].3.7.Fault Tolerance in the BigchainDB SystemSimultaneously preserving the scalability and trustless decentralization of both large-scale databases and decentralized blockchains is the main objec-tive of the BigchainDB system.The following were considered when design-ing BigchainDB’s security measures:11•Benign faults:In the BigchainDB setup,nodes communicate througha database which uses a fault-tolerant consensus protocol such as Raftor Paxos.Hence we can assume that if there are2f+1nodes,f benign-faulty nodes can be tolerated(at any point in time)and each node seesthe same order of writes to the database.•Byzantine faults:In order to operate in a trustless network,BigchainDBincorporates measures against malicious or unpredictable behavior ofnodes in the system.These include mechanisms for voting upon trans-action and block validation.Efforts to achieve full Byzantine toleranceare on the roadmap and will be tested with regular security audits.•Sybil Attack:Deploying BigchainDB in a federation with a high bar-rier of entry based on trust and reputation discourages the participantsfrom performing an attack of the clones.The DNS system,for example,is living proof of an Internet-scale distributed federation.Appendix Cdescribes how the DNS has successfully run a decentralized Internet-scale database for decades.4.BigchainDB Description4.1.PrinciplesRather than trying to scale up blockchain technology,BigchainDB startswith a“big data”distributed database,and adds blockchain characteristics.It avoids the technology choices that plague Bitcoin,such as full replicationand broadcast communication.We built BigchainDB on top of an enterprise-grade distributed DB,fromwhich BigchainDB inherits high throughput,high capacity,a full-featuredNoSQL query language,efficient querying,and permissioning.Nodes can beadded to increase throughput and capacity.Since the big data DB has its own built-in consensus algorithm to toleratebenign faults,we exploit that solution directly.We“get out of the way”of the algorithm to let it decide which transactions to write,and what theblock order is.We disallow private,peer-to-peer communication betweenthe nodes except via the DB’s built-in communication,for great savings incomplexity and for reduced security risk5.This means that malicious nodescannot transmit one message to part of the network and different messageto other part of the network.Everytime a node“speaks”all the others canlisten.5Though we must vigilantly exercise restraint in design,as intuition is to just get the nodes talking directly!124.2.High-Level DescriptionWe focused on the adding the following blockchain features to the DB:1.Decentralized control,where“no one”owns or controls a network;2.Immutability,where written data is tamper-resistant(“forever”);and3.The ability to create&transfer assets on the network,withoutreliance on a central entity.Decentralized control is achieved via a DNS-like federation of nodes with vot-ing permissions.Other nodes can connect to read,and propose transactions;this makes it a super-peer P2P network[2].The voting operates at a layerabove the DB’s built in consensus.Quorum is a majority of votes.For speed,all transactions are written independent of their validity;votes are done aposteriori.A network with2f+1voting nodes that communicate openly(ie.through the database)can tolerate f malicious nodes6[14].Immutability is via an ordered sequence of blocks where each block holds anordered sequence of transactions;and a block’s hash is over its transactionsand related data;that is,a block chain.Blocks are written,then voted upon.Chainification actually happens at voting time.A block doesn’t have a top-level link to the previous block.Instead,it has a list of votes,and each votehas a“previous block”attribute pointing to the id of the block coming beforeit.Any entity with asset-issuance permissions can issue an asset;any entitywith asset-transfer permissions and the asset’s private key may transfer theasset.This means hackers or compromised system admins cannot arbitrarilychange data,and there is no single-point-of-failure risk.4.3.ArchitectureFigure3illustrates the architecture of the BigchainDB system.The BigchainDB system presents its API to clients as if it was a single blockchain database.Under the hood,there are actually two distributed databases7,S(transactionset or“backlog”)and C(block chain),connected by the BigchainDB Con-sensus Algorithm(BCA).The BCA runs on each signing node.Non-signingclients may connect to BigchainDB;depending on permissions they may beable to read,issue assets,transfer assets,and more;section7explores thismore.Each of the distributed DBs,S and C,is an off-the-shelf big data DB.Wedo not interfere with the internal workings of each DB;in this way,we get6It is2f+1and not3f+1because digital signatures are employed.Section3.2.2has details.7This can be implemented as two databases,or as two tables in the same database.While there is no practical difference,for the sake of clarity we describe it as two separate databases.13。
1、数据仓库基本概念1.1、主题(Subject)主题就是指我们所要分析的具体方面。
例如:某年某月某地区某机型某款App的安装情况。
主题有两个元素:一是各个分析角度(维度),如时间位置;二是要分析的具体量度,该量度一般通过数值体现,如App安装量。
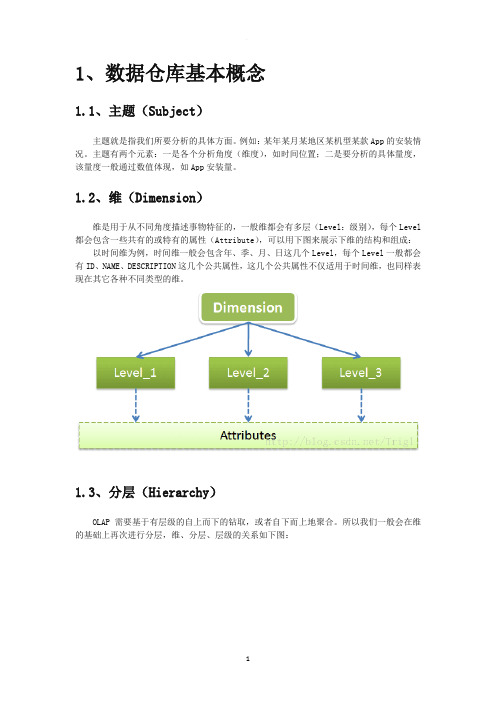
1.2、维(Dimension)维是用于从不同角度描述事物特征的,一般维都会有多层(Level:级别),每个Level 都会包含一些共有的或特有的属性(Attribute),可以用下图来展示下维的结构和组成:以时间维为例,时间维一般会包含年、季、月、日这几个Level,每个Level一般都会有ID、NAME、DESCRIPTION这几个公共属性,这几个公共属性不仅适用于时间维,也同样表现在其它各种不同类型的维。
1.3、分层(Hierarchy)OLAP需要基于有层级的自上而下的钻取,或者自下而上地聚合。
所以我们一般会在维的基础上再次进行分层,维、分层、层级的关系如下图:每一级之间可能是附属关系(如市属于省、省属于国家),也可能是顺序关系(如天周年),如下图所示:1.4、量度量度就是我们要分析的具体的技术指标,诸如年销售额之类。
它们一般为数值型数据。
我们或者将该数据汇总,或者将该数据取次数、独立次数或取最大最小值等,这样的数据称为量度。
1.5、粒度数据的细分层度,例如按天分按小时分。
1.6、事实表和维表事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发生的事情。
事实表中存储数字型ID以及度量信息。
维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。
事实表和维表通过ID相关联,如图所示:1.7、星形/雪花形/事实星座这三者就是数据仓库多维数据模型建模的模式上图所示就是一个标准的星形模型。
雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。
雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。


As an applicant to your University's Graduate program in Computer Science, I am very glad to have an opportunity in introducing my study objectives to you.I majored in Computer Science and Technology. During my undergraduate studies, I acquired a comprehensive knowledge of computer hardware in all its complexity. I also learnt of diverse software and their applications. The courses were as follows: Operating Systems, Data Structures, Compilers, Software Engineering, Programming Languages and Practice, DBMS, System Programming and Practice, Data Communication, Digital Logic Design , C or JAVA programming, object oriented programming as well as programming using different tools and so on.作为贵校的计算机科学研究生课程的申请人,我很高兴有一个机会介绍我的研究目标。
我的专业是计算机科学与技术。
在我的本科学习,我获得了计算机硬件的相应复杂全面的知识,我也学到了不同的软件及其应用。
这些课程如下:操作系统,数据结构,编译器,软件工程,编程语言和应用,数据库管理系统,系统编程与实践,数据通信,数字逻辑设计,C和java语言编程,面向对象编程等。

What is PMS?什么是电力系统建模套件?Power Modeler Studio (PMS) is a next-generation power system modeling tool designed to address the 21st century modeling requirements in power industry. It provides an integrated environment for power system modeling and information sharing within or among electric utility organizations.电力系统建模套件(Power Modeler Studio PMS)是新一代电力系统建模工具,为满足21世纪电力行业的建模需求而设计。
它提供了一个集成的环境用于建立电力系统模型和促进电力公司组织内部或之间的信息共享。
PMS has been designed as a distributed metadata-driven enterprise application. The design put the user, rather than the system, at the center of the process, incorporating user concerns and advocacy from the beginning of the process. In addition, PMS delivers rich user experience targeted to address a variety of common power system modeling requirements.PMS是一分布式电力企业应用软件系统, 其特点是由元数据驱动,这个设计置用户而非系统在过程的中心, 从一开始就兼顾用户利益,并贯彻于整个设计过程。
数据库系统概论参考文献参考文献是论述、研究或评价某一主题时所引用的相关文献资料。
在数据库系统概论中,参考文献起到了支撑和证明论述观点的重要作用。
以下是一些相关的参考文献,供您作为学习和研究数据库系统概论的参考。
1. Date, C.J. An Introduction to Database Systems. Pearson 2003.这本经典教材是数据库系统概论领域的权威之作,全面介绍了数据库系统的基本概念、结构和应用。
2. Ramakrishnan, R., Gehrke, J. Database Management Systems. McGraw-Hill Education 2016.本书系统地介绍了数据库管理系统的核心原理和技术,包括关系数据库、SQL查询语言、并发控制和恢复等重要内容。
3. Elmasri, R., Navathe, S.B. Fundamentals of Database Systems. Pearson 2016.这本经典教材深入浅出地介绍了数据库系统的基本概念和理论基础,包括数据模型、数据库设计与规范化、查询处理和优化等内容。
4. Silberschatz, A., Korth, H.F., Sudarshan, S. Database System Concepts. McGraw-Hill Education 2019.这本教材是数据库系统的权威教材之一,详细阐述了数据库系统的各个要素,包括数据模型、事务处理、并发控制和数据安全等内容。
5. Garcia-Molina, H., Ullman, J.D., Widom, J. Database Systems: The Complete Book. Pearson 2013.这本全面介绍数据库系统的书籍,包含了关系数据库、分布式数据库、数据挖掘和数据仓库等领域的内容,是数据库系统学习和研究的重要参考资料。
分布式数据库如何工作Distributed Database Howdoes it workHow does Distributed Database work?A distributed database is considered as a database in which two or more files are located in two different places. However, they are either connected through the same network or lies in a completely different network. It is a single huge database in which portions of the data are stored in multiple physical locations and processing system is done by distributing the data among various nodes of the database. It is a system in which a huge database is settled down in a distributed manner in several physicallocations to avoid any kind of confusions while dealing with that database.The distributed database system is managed in a centralized manner by connecting the data logically. This helps in managing the bulk data in a manner as if it was all stored in one single place. In such a centralized database it is seen that the data are synchronized in such a manner that deletes or updates done in one location is automatically upgraded in other parts of the data. This is the concept of a distributed database in making the management of bulk data easy. Now we will tell you more with the help of an infographic.How Does Distributed Database Work?Definition of NetworkThe network is defined as a system that helps in connecting multiple devices together that helps them to communicate effectively. Networks can be small or it can consist of billions of devices that are connected to each other. Networking is of various types and each has some role or the other to perform. Two major types of networks are LAN and WAN. The first type is a local area network that allows for forming a network to a specific and personalized area such as home, office and campus.Within this also there is single or large network depending on the space of the area. On the other hand, WAN is a wide area network that is not limited to a single area and spread over multiple locations. WAN is seen to consist of multiple LAN system and these LANs are connected with the help of internet. Moreover,WAN allows limiting the access to the network with the help of authentication, firewalls and other security systems.The network is also defined according to characteristics that help in categorizing different types of networks such as typology, protocol and architecture and forms an integral part in the distributed database system.The typology is the geometric arrangement of the network in a system in the form of a ring, star, bus and others.The protocol is another characteristic that defines a set of rules and signals that help the networks use to communicate with each other. For example, the protocol for LAN is Ethernet.Architecture is another network characteristics that show the design or form of the network such as peer to peer or server architecture.The characteristics of the networks play an important role in a distributed database because it helps in connecting data in different location effectively and in a secured manner.Features of Distributed DatabaseIn a collection or group, it is seen that a distributed database is logically connected to each other and is often described under a single database. This means that a distributed database is not kept in a spread manner and is represented in a collaborative form.This interdependency of the database on each other from a different location is done with the help of a processor. The processors in a site connect with another site with the help of the network and do not have any kind of multiprocessing configuration. However, there are misconceptions that the distributed database system is loosely connected to each other in a file.In reality, it is not so because the entire process of a distributed database system is a complicated one. Based on these facts, the distributed database has various types of features that help defines them clearly, such as:Location independentDistributed query processingReliability of safety and reduction in data lossThe internal and external security systemCost-effective by reducing the bandwidth pricesEase of access to the data even if a failure occurs in umbrella networkEasy integration of more nodes to the databaseThe efficiency of speed and resourcesThere are some concerns connected to a distributed database system such as it should be kept up-to-date and there should be consistency while using the data that is remotely stored.Advantages of Distributed Database systemA distributed database is capable of offering various types of advantages to the business in the maintenance of large size data in a simpler and systematic form. This type of database is able to make modular development which means that a system can easily be expanded by connected new computers or local data to a site. Then the site is connected to the distributed system without much interruption.The distributed database also offers advantages over a centralized database system by preventing the system to stop working completely. In a time of failure, it is seen that a centralized database system stops completely, while in a distributed database in case of failure the system becomes slow and continue to perform until the error is fixed completely. Thisallows the user of the database from stopping their work completed in a time of failure.In addition to the above benefits, it is also seen that the distributed database system helps in offering lower communication costs to the admin. The admin can access the data effectively if is located close to where it is extracted the most. This facility helps in reducing the cost of the database admins. This is because communication becomes easier in this system by locating the data closer to the point of use.The response rate for the extraction of particular information or data is done at a faster rate with the help of the distributed database system. This is because the data is distributed in such a manner that it is kept close to the users in a particular site and they can use the data anytimethey want from the site. These are some of the advantages that the distributed database offers to the user for handling large and complex data.The environment in which Distributed Database WorksThe ability to create a distributed version of a database has been existing since the 1980s. This is done based on various types of distributed database environment that are widely categorized as homogenous and heterogeneous database.This shows that the process of distributed database system does not work in a single type of system and is spread over sites. This means that multiple computers and networks are involved in the process. This has led to thecategorization of the environment of the database in two different categories.Homogenous database–environment helps the sites to store the database identically. This type of environment works in a way in which the structures are the same in all the sites such as operating system, database management system and data structures. This environment further works under two environment that is autonomous and non-autonomous.Autonomous–in this each DBMS works in an independent manner by passing messages back and forth and helps in sharing data updates.Non-autonomous–in this environment the central database management system worksand coordinates database access across sites and update other nodes.Heterogeneous Database–in this environment different sites use different types of software to reach the problems of query processing and transactions. In such type of environment, the distributed database is stored in different sites in such a way that one site is unaware of what is having in another site. In such a process, the company uses different data models for storing the database and hence translation has to be done to connect from one model to another.In a heterogeneous environment, it is seen that a distributed database system works in a much complex manner and involves various steps, unlike the homogeneous database. There are two broad categories of nodes such as systemsand gateway. The system helps in supporting one or all the functionality of the logical database. Gateway, on the other hand, helps in creating paths for other databases without creating many benefits for one single logical database.Options for Distributing a DatabaseDistribution of a database in a site in a number of forms depending on the characteristics of the data. There are four basic strategies adopted by the Distribution Database system to distribute the data across multiples sites.The types of strategies that distributed database can use in its process are data replication, horizontal partitioning, vertical partitioning and combination of the above. The characteristicsand the processes involved in each of these options can be explained with the help of relational databases. Now we will tell you about the Data replication.Data ReplicationIn this type of option, it is seen that the entire data relation is stored in two or more number of sites. In this type of processes, it is seen that the database is distributed or stored in copies in different systems entirely. This is a way distributed database system will allow for fault tolerance capacity by storing a copy of all data in a number of sites.Such type of processes in common in an information system organization in which the database is removed from a centralized positionand moved to location specific server so that it is kept close to the user. This type of method help in using either synchronous or asynchronous distributed database technologies. Thus, replication is a copied version of the entire database stored in every site that the organization use to access.Advantages of replication are huge due to the ease of usage and highly secured process. Some of the advantages of using the replication process of the distributed database are:Reliability- this means that one site containing the relation database fails then another site can be approached easily to get a copy of the database. The available copies can then be uploaded after the transaction takes place andfailed nodes can be updated once they are repaired and return to service.Fast response- this process allows for fast response of the database in case of need because the data is stored near to the user to be processed quickly.Node decoupling- is another benefit of the replication process for distributing database because in this each transaction may move without coordinating with another network as each site has access to the entire database.Data Replication process also faces various kinds of disadvantages such as space for storage requirement as the database is huge and also complexities and cost attached toupdating the database because each site has to be updated about any new relation.Horizontal PartitioningThis is yet another process that is used in a distributed database in which some of the rows in a relation are put in one site and other rows are put under a base relation in another site. It is done in a horizontal or base form as the name suggests and the rows of the database are distributed in a number of sites.This can be seen with the help of an example that is customer relations in which the rows are located in home branches. In this system in case the transaction is made in the home branch then the transaction is processed locally and response time is reduced. In case the customermakes a transaction in another branch then the data is sent to the home branch for processing and then send back to the initiating branch.This process of distributed database system also has various types of advantages and disadvantages from the efficiency it adds to data management. The advantages of using horizontal partitioning are:Efficiency- this means that the data in this system is stored close to the user and separated from other data that is used by some other users. This reduces the chances of confusion and improved efficiencies to a great extent.Local optimization- data is stored in such a way that it can help in improving the performance of local access.Security- it is the biggest advantage of using this process because all types of data are not available in one place and data that is not relevant is kept separately without any kind of distraction.The use of horizontal partitioning also has various kinds of disadvantages attached to it such as inconsistent access speed, which means that the data is required from various points and this increases the access time. Moreover, there is a backup vulnerability, which means that due to lack of replication of similar kinds of data when one type of data become damaged in one site then it is completely lost and cannot be updated.Vertical PartitioningVertical partitioning is yet another form of distributed database process in which the data is partitioned column-wise. Some of the columns of the data or relations are projected in one site and other columns are projected under a base relation in another site.In this type of process, the distributed database system works in a separate manner as it works in horizontal partitioning system. The data or relations that are shared in each of the sites are connected to each other with the help of a common domain so that it can be extracted easily.Vertical partition of the database also has some advantages and disadvantages to being used and getting destroyed. The advantages of vertical partitioning are similar to that of thehorizontal partition system because in this process as well data are kept separately without much replication. The only exception that in vertical partition the combination of the data is many complications difficult to make compared to horizontal partitions.。
TRANSPARENCY IN ITS PLACE -- The Case Against Transparent Access to Geographically Distributed DataJim GrayTandem Computers Inc.19333 Vallco ParkwayCupertino CaTandem Technical Report TR89.1Tandem Part Number PN 21667TRANSPARENCY IN ITS PLACE --The Case Against Transparent Access toGeographically Distributed DataJim GrayTandem Computers Inc.19333 Vallco ParkwayCupertino CaMay 1987+Revised Feb. 1989Abstract: Distributed database software offers transparent access to data -- no matter where in the network the data is located, an authorized program can access the data as though it is local. This article argues that transparency in a geographically distributed system is unmanageable and has technical drawbacks. The real virtue of transparency is its ability to support geographically centralized clusters of computers.+ This paper originally appeared in UNIX Review, V.5, N.2, May 1987, pp. 42-50.D istributed database software offers transparent access to data -- no matter where in the network the data is located, an authorized program can access the data as though it is local. Transparency has been the goal of distributed database systems for over a decade -- it is at the core of next-generation distributed database systems.Both IBM's CICS/ISC [1] and Tandem's Encompass [2] have offered transparency since 1976. Although these two distributed systems are very popular, their ability to transparently access remote data is not used much. In fact, design experts of both vendors recommend against transparent remote access to data [3]; instead, they recommend a requester-server design (sometimes called remote procedure call) in which requests for remote data are sent to a server which accesses its local data to service the request (see figure 1). Ironically, CICS and Encompass initially offered only transparent distributed data. Both added a requester-server model about three years later (1979).Why are newcomers enthusiastic about the transparency they will deliver next year, while old-timers who have had these facilities for a decade are skeptical about using transparency for geographically distributed applications? Manageability is at the crux of this paradox. Geographically distributed system are a nightmare to operate. By definition, they are a large and complex system involving hundreds if not thousands of people. Communication among computers, administrators and operators in such a system is slow, unreliable, and expensive (SUE for short). When confronted with a "real" distributed system, one with SUE communication, successful application designers fall back on the requester-server model. Such designs minimize communication among sites and maximize modularity and local autonomy for each site.Distributed database systems do have an important application: they allow modular growth -- the ability to grow a system by adding hardware modules to a cluster instead of growing by trading up to a bigger, more expensive box (see Figure 2). It is not enough to have a "cluster" hardware architecture -- distributed system software is needed to allow modular growth. Clusters avoid all the hard problems of geographic distribution:• Clusters have high-bandwidth, low-latency, reliable and cheap communication among all processors in the cluster. All data in the cluster is "close" since access times are dominated by disk access time. Geographically distributed systems must deal with slow, unreliable, expensive communications via public networks. In geographically distributed systems message delays dominate access times.• A cluster can be administered and operated by a single group with face-to-face contact and with similar organizational goals. "Real" distributed systems involve multiple sites, each site having its own administration. Personal communication and relations among sites are via slow, unreliable, expensive mail and telephones -- SUE again.This analysis is controversial. But, if it's correct, computer vendors should overhaul their hardware and software to add support for clusters. On the other hand, there is little need for computer users to worry about geographically distributed or heterogeneous databases -- rather a standard requester-server model is needed so that application designers can build geographically distributed systems in standard ways. I believe that IBM's SNA LU6.2 will emerge as that standard [4]. In addition, standard data interchange protocols are needed. Facilities being built atop LU6.2 are likely to become those standards.The rest of this article attempts to justify this analysis and its conclusions.FIGURE 2.a: The classic VonNeumann machine with a Central Processing Unit (CPU) that handles both computation and IO. Virtually no one builds such a computer today.Figure 2.b: The first evolutionary step away from the VonNeumann model: multiple processors share memory. Some of the processors are functionally specialized to do IO while others execute programs. The processors communicate via shared memory and signal wires.Figure 2.c: The next evolutionary step was to couple multiple independent processors on a high speed local network to form a cluster. The nodes of the cluster do not share memory, rather they communicate via messages. This architecture allows tens or hundreds of processors to be applied to one application. It is the thesis of this article that clusters require a distributed database system to be effective and distributed database transparency should only be used within a cluster.Figure 2.d: A true distributed system in which geographically distributed clusters are connected via long-haul networks. As with a cluster, the nodes do not share memory, rather they communicate via messages. But in this case messages are Slow, Unreliable and Expensive (SUE). This architecture allows geographically distributed applications and data. It is the thesis of this article that truly distributed systems require a requester-server mechanism to be effective -- distributed database transparency should not be used in a long-haul network.Figure 2: The evolution of computer architectures to clusters and networks.The Case Against Transparent Access to Distributed DataD istributed databases offer transparent access to data. Beyond the authorization mechanism, there is no control over what the program does to the data. It can delete all the data, zero it, or insert random new data. In addition, no comprehensible audit trail is kept telling who did what to the data. This interface is convenient for programmers, but it is a real problem for application designers and administrators.The simplest way to explain the negative aspects of a distributed database is to compare refrigerators to grocery stores. My refrigerator operates like a distributed database. Anyone with a key to my house is welcome to take things from the refrigerator or put them in. There is a rule that whoever takes the last beer should get more at the grocery store. I only give keys to people who follow this rule.A grocery store could operate like a distributed database. It could hand out keys to trusted customers who agree to pay for any groceries they take. This would be much cheaper than having a lot of clerks standing around collecting money from customers. Why don't any grocery stores operate in this way? Why are they different from refrigerators? Well, its because refrigerators are convenient for the users but are unmanageable. The clerks manage the access to the store inventory.Requester-server designs provide an administrative mechanism much like the store clerks. They provide defined, enforceable, auditable interfaces which control access to an organization's data. Rather than publishing its database design and providing transparent access to it, an organization publishes the CALL and RETURN messages of its server procedures. These servers perform requests according to the procedures specified by the site owner. They are the site's standard operating procedures. Requesters send messages to servers which in turn execute these procedures much as the clerks perform and enforce the store's operating procedures.Requester-server designs are more modular than distributed databases. A site can change its database design and operating procedures without impacting any requesters. This gives each site considerable local autonomy. The only things asite cannot easily change are the request and reply message formats. In the parlance of programming languages, distributed databases offer transparent types, servers offer opaque types, sometimes called abstract types or encapsulated types. Requester-server designs are more efficient. They send fewer and shorter messages. Consider the example of adding an invoice to a remote node's database. A distributed database implementation would send an update to the account file, insert a record in the invoice file, and then insert several records in the invoice-detail file. This would add up to a dozen or more messages. A requester-server design would send a single message to a server. The server would then perform the updates as local operations (see Figure 1). If the communication net is SUE then sending only a single message is a big savings over multi-message designs.To summarize the negatives, applications coded with transparent access to geographically distributed databases have:• Poor manageability,• Poor modularity and,• Poor message performance.when compared to a requester-server design.The lunatic fringe of distributed databases promise transparent access to heterogeneous databases (say an ASCII system accessing an EBCIDIC system). These folks promise to hide all the nasties of networking, security, performance, and semantics under the veil of transparency.This is a wonderful promise. But the prospect of getting people who cannot agree on how to represent the letter "A" to agree to share their raw data is far fetched. Heterogeneous systems are a very good argument for requesters and servers. The systems need only agree on a network protocol and a requester-server interface. Still a little far fetched unless a standard network and requester-server model emerges.Manageability of a Distributed DatabaseM anageability is the key problem in distributed systems. Lets suppose for the moment that some genius solved all the technical problems. Lets suppose that there is cheap, fast, reliable communications among all points of the globe. Suppose that everyone agrees to run the same hardware and same software. Suppose that everyone trusts everyone else completely and that there are no auditors insisting that we explain how our system works.Now suppose that we have to design and manage a distributed application in this ideal world. Will we use transparent access to geographically remote data? Probably not.Why not? Well, a distributed system is a big and complex thing. We will want to change and grow it over time. We may want to add nodes, move data about, redesign the database, change the format or meaning of certain data items, and do other things which are likely to invalidate some programs using the data.If everyone in the world knows what our database looks like, and we change the design, then their programs will stop working. Some changes may not break programs, but others certainly will. To install a change, we would have to change all the programs that use our data. This might be possible, but at some point, change control will consume all the system's resources.Modularity is the solution to this. If we only tell people about the interface to our servers, we can change a lot about our database without letting anyone else know. We can support "old" server interfaces when we go to a new design and gradually inform our users about the new interface. They can convert at their leisure. So, even in the programmer's ideal world, manageable distributed systems must be structured as modules communicating via messages rather than as programs transparently accessing an integrated distributed database.The Case For Transparent Access to Cluster DataW hat is the proper place for transparent access to distributed databases? Transparent access is very convenient for programmers -- it makes it easy to bring up distributed applications. Coding requesters-servers and making an application modular is extra work. Unfortunately, system administrators control the security of their data and generally do everything in their power to prevent ad hoc queries from running on it. If I want to run an ad hoc query on someone else's data, I have to get permission. This turns out to be not very ad hoc after all.Clustering is the real application of transparent access to distributed data. To appreciate clusters, you have to appreciate the quandary of computer vendors. Almost all vendors have standardized on a single architecture. IBM wishes it had only System 360, DEC wishes it had only VAX and so on. The vendors then build 1, 2, 3, 4, 5,... MIP engines for that architecture. Most vendors are limited to15MIP s per processor right now. To go beyond that they must combine several processors and convince the customer that the resulting price/performance adds to more than 15MIPS.Clusters offer an approach to this problem. The vendor builds a slow-cheap cpu (say 1MIP), and a fast-expensive cpu (say 10MIPS). The vendor does the same for disks and communication controllers -- making a cheap box and a high-performance box. He then offers software that lets the customer use between 1 and 100 processors clustered as a single system. This gives the customer a 1MIP to 100MIP range with the cheap engines and a 10MIP to 1000MIP range for the expensive boxes (see figure 3).Clustering offers both the customer and the vendor significant advantages. The customer can buy just what he needs and grow in small increments as he needs more. The vendor has two advantages. First it need design and support only a very few module types (discs, cpus, communications,....). In addition, it can build systems which far exceed the power of the non-clustered vendors. Apollo, DEC, Teradata, Tandem, and Sun have each taken this approach. Of course if the vendor or customer programs in a bottleneck, then the clusters cannot grow beyond the bottleneck. Successful vendors and customers have avoided such bottlenecks -- it is possible but the many failures indicate that it is not easy.1101001000paths and so on for fault tolerance -- other vendors have been reluctant to sacrifice a factor of two. And yet, Tandem and Teradata systems are competitive with those of other vendors and they are the only vendors building functional 100MIP clusters.ConclusionsT o summarize, the benefits of transparent access to clustered databases are undersold within computer vendors; and the benefits of transparent access to geographically distributed databases are oversold to customers. Customers wanting to implement geographically distributed applications need a standard and powerful requester-server mechanism.It is fine to distribute data geographically close to the data users. But when access to the data crosses geographic or organizational lines, then the access is best structured as a requester-server interaction with a remote server which in turn accesses and updates its local data.We hear relatively little about the requester-server idea -- there are no conferences or journals dedicated to it. Nonetheless, there is considerable activity in this area. Remote procedure call protocols typified by Courier from Xerox [5] and RPC from SUN [6] are being promoted. Tandem continues to extend its Pathway system [2]. IBM is implementing SNA LU6.2 which is the Esperanto of the IBM data processing world [6].SNA LU6.2, also known as Advanced Program to Program Communication (APPC), is the de facto standard requester-server mechanism. All the major vendors have announced their intention to support it. In addition, IBM is building an edifice of software atop LU6.2 including transaction processing (CICS), name servers (SNADS), distributed database (DDM and CICS), forms flow and electronic mail (DISOS), document interchange (DIA/DCA), and so on. These extensions are servers defined by the server's message formats and English specifications of the server's semantics.LU6.2 is a set of protocols to:• Establish an authorized and authenticated conversation between a requester and a server which allows multi-message exchanges (calls) and informs the endpoints if the conversation or other endpoint fails.• Exchange requests and replies between requesters and servers.• Package a set of requests to a set of servers as a single atomic transaction so that all servers within the transaction will commit or all will undo their operations. • Deal with errors along the way.So LU6.2 is merely a remote procedure call mechanism combined with a transaction mechanism (a transaction commit/abort protocol) and an authorization mechanism. It gains it's significance from the 35,000 CICS systems (which all support it), the IBM System 38 which supports it nicely, the many applications that are being built on top of it, and the many non-IBM systems which have varying degrees of support.It is likely that particular industries will evolve standard servers based either on LU6.2 or on higher level functions such as SNADS and DISOS. The universal support of LU6.2 and the support of industry-specific extensions are likely to solvemany of the heterogeneous systems problems currently plaguing designers of distributed applications.References[1] CICS/OS/VS Intercommunication Facilities Guide, International BusinessMachines, White Plains, N.Y, Form SC33-0230, 1986.[2] An Introduction to Pathway, Tandem Computers Inc. Cupertino, CA.,Part: T82339, 1985.[3] Anderton, M., Gray, J., "Four Case Studies of Distributed Systems",Tandem Computers Inc., Cupertino, CA. TR. 86.5 (1986).[4] SNA Transaction Programmer's Reference Manual for LU Type 6.2,International Business Machines, White Plains, N.Y, Form GC30-3084,1986.[5] "The Remote Procedure Call Protocol", Xerox Corp., Rochester NY, TRXSIS 038112, (1981).[6] "Remote Procedure Call Specification", Sun Microsystems Inc.,Sunnyvale, CA., (1985).。