weblogic日常维护总结与故障诊断
- 格式:doc
- 大小:2.40 MB
- 文档页数:20

运维常见问题和解决方案
《运维常见问题和解决方案》
运维(运维技术)是指运营和维护的缩写,主要是指企业的
IT基础设施和应用服务的管理。
在进行运维工作的过程中,
经常会遇到一些常见问题,这些问题需要及时解决,以保证系统的正常运行。
以下是一些运维常见问题和解决方案:
1. 网络故障
网络故障是最常见的问题之一。
当出现网络故障时,首先需要检查网络设备和连接是否正常。
如果网络设备无故障,可能是网络配置问题,可以尝试重新配置网络设置或重启设备。
2. 硬件故障
硬件故障包括服务器、存储设备、交换机等硬件设备的故障。
当出现硬件故障时,需要及时更换故障设备,并重新配置系统,以保证系统的正常运行。
3. 软件升级问题
在进行软件升级时,可能会出现兼容性问题或安装失败的情况。
为了避免这些问题,需要提前备份系统数据并进行充分的测试,确保升级过程顺利。
4. 安全漏洞
安全漏洞可能导致系统遭受黑客攻击或数据泄露。
为了避免安全漏洞,需要及时更新系统补丁,并加强系统安全配置,定期进行安全检查,保证系统的安全性。
5. 性能问题
系统性能问题可能导致应用服务的延迟或崩溃。
为了解决性能问题,可以通过优化系统配置、增加硬件资源或使用性能监控工具定位问题,并进行相应的调整和优化。
综上所述,运维工作中常见的问题有很多,解决这些问题需要运维人员具备丰富的经验和技能。
通过及时的故障排除和系统优化,可以确保企业的IT基础设施和应用服务的正常运行。

中间件故障诊断总结一、步骤:1、准确描述现象:客户说的和自己查看到的:平台、版本、操作、信息等。
特别是,故障前是否有做过什么操作:网络调整、设备调整、主机参数调整、配置文件修改……反正将这一切都列入排查的对象。
2、使用工具收集数据,收集配置文件、日志、dump文件等等。
3、使用分析数据,根据问题或收集的数据,使用适当的工具分析数据,当然包括了在网上和在官方支持站点搜索类似的问题的解决办法。
4、尝试解决问题,根据找到的问题点,尝试解决。
如修改错的,复原正确的;运行有问题的,适当调整运行的环境和运行的参数等等。
5、给出最佳解决方案,一般就是继续观察了。
6、总结经验并加以重用,知识积累。
二、通过前台收集基本的信息:1、重点是故障前做过的操作2、比对运行平台是否在官方的兼容性列表中,一般就是关注各个版本,特别是一些比较怪异的问题3、检查环境和参数,如能打开控制台,就在控制台中初步观察,一般进入控制台的格式是如:。
常用的留意点如下:A、域运行状态(域-监视-健康状况);一般为running状态,如果不是running,那这些界面就没有了。
B、服务器运行状态(域-环境-服务器),正常的为running。
C、各个server性能(JVM)状态(域-环境-服务器,点击具体的serve后进入,监视-健康状况);留意JVM堆中当前可用的内存量。
不同的JVM,所显示的内容可能不一样,以下为sun的:D、各个server线程状态(域-环境-服务器,点击具体的serve后进入,监视-线程);一般来说,空闲线程要多;健康状况为ok如下图health状态为:Warning,这个是有线程阻塞的。
阻塞线程的内容为:####<2011-8-13上午02时42分35秒GMT+08:00><Error><WebLogicServer><dataweb1><dc_admin1><[ACTIVE]ExecuteThre ad:'15'forqueue:(self-tuning)'><<WLSKernel>><><><BEA-000337><[STUCK]Execut eThread:'19'forqueue:(self-tuning)'hasbeenbusyfor"2,492"secondsworkingonth erequestwhichismorethantheconfiguredtime(StuckThreadMaxTime)of"2,400"secon ds.Stacktrace:Method)Source)E、JDBC(域-环境-服务器,点击具体的serve后进入,监视-JDBC);活动连接数合理。

关于Weblogic应用集群服务启动慢的缺陷分析及处理办法一、缺陷现象江苏公司电网GIS部分服务部署在Linux Redhat5.5操作系统的服务器上,使用的中间件版本为Weblogic 9,在电网GIS运行过程中,如果遇到因为应用服务器原因或者检修计划安排,重启Weblogic程序,需要花费10分钟以上的等待时间。
在日常检修中,重启Weblogic程序集群服务的耗时都在30分钟左右,在7*24小时的在线运行系统,中断业务服务时间,严重影响系统的运行及检修工作。
国家电网公司核心系统的应用架构,均采用Weblogic集群服务,此缺陷为系统日常检修的通病,造成很多省公司检修系统停机时间过长,甚至不敢停机维护系统,属于中间件的重大缺陷问题,已经存在很久。
二、缺陷分析对于一个简单部署的Weblogic而言,一般情况下,启动Weblogic最长一般需要2~3分钟时间,同时在启动时,Weblogic的日志内容是滚动的,不会在日志的某个地方静止到5分钟以上,所以这是极不正常的现象。
Weblogic启动慢的原因,在Weblogic启动时,通过对线程堆的监控,线程挂在security相关的随机数生成上面。
这个由于JDK的配置(JDK从/dev/random读取‘randomness’经常耗费10分钟或者更长的时间)导致的。
三、缺陷处理针对该问题,有三种解决方案,分别如下:在Weblogic启动参数里添加“-Djava.security.egd=file:/dev/./urandom”(/dev/urandom 无法启动)执行命令mv /dev/random /dev/random.ORIG ; ln /dev/urandom /dev/random将/dev/random 指向/dev/urandom修改Linux上Weblogic使用的jdk $JAVA_HOME/jre/lib/security/java.security 文件将securerandom.source=file:/dev/urandom 修改为securerandom.source=file:/dev/./urandom这样可以解决任何一个域Weblogic启动慢的问题。

《装备维修技术》2024年第1期(总199期)I-Nodal V1节点采集单元电源板故障分析与维修瞿婉洁(中石化石油工程地球物理有限公司物资装备中心,江苏南京)摘要:I-Nodal V1节点仪器是中石化地球物理公司自主研制的节点采集系统,自2019年产业化后该仪器已应用于40多个野外项目。
随着野外生产应用使用年限增加,节点采集单元故障数量逐渐上升。
据此,主要从I-Nodal V1节点采集单元电源板电路组成入手,结合电源板测试结果,对I-Nodal V1节点采集单元电源板几种常见的故障进行分析总结,并提出解决方法,为该设备的维修提供技术参考。
关键词:I-Nodal节点仪器;故障分析与维修;节点采集单元Analysis and Maintenance of Power Board Faults in I-Nodal V1Node Acquisition UnitQu Wanjie(Sinopec Geophysical Corporation Purchasing&Equipment Center,Nanjing211100,China)Abstract:The I-Nodal V1node instrument is a node acquisition system independently developed by Sinopec geophysical company.Since its industrialization in2019,the I-Nodal V1node instrumenthas been applied to more than40field projects.As the service life of field production applications increases,the number of node acquisition unit failures gradually increases.This article mainly startswith the composition of the power board circuit of the I-Nodal V1node acquisition unit,and com-bined with the test results of the power board,analyzes and summarizes several common faults ofthe power board of the I-Nodal V1node acquisition unit,and proposes solutions,providing technical reference for the maintenance of the equipment.Keyword:I-Nodal node instrument;Fault analysis and maintenance;Node acquisitionunit引言国内各探区勘探程度的逐步提高,且勘探目标日趋复杂,对地下小、碎、薄等复杂地质体的描述精度和分辨率要求越来越高[1]。


设备故障分析总结在生产和运营过程中,设备故障是不可避免的问题。
及时、准确地分析设备故障的原因,并采取有效的措施进行解决和预防,对于保障生产的正常运行、提高设备的可靠性和使用寿命、降低维修成本等方面都具有重要的意义。
本文将对近期发生的设备故障进行详细的分析和总结。
一、故障设备基本信息本次故障的设备是设备名称,该设备主要用于设备的主要用途。
设备的型号为具体型号,生产日期为生产日期,投入使用时间为投入使用时间。
二、故障现象描述在故障发生时间,操作人员发现设备出现了以下故障现象:1、设备无法正常启动,按下启动按钮后没有任何反应。
2、设备运行过程中突然停止,且控制面板上显示故障代码具体代码。
3、设备的输出功率明显下降,达不到正常的工作要求。
三、故障排查过程1、电气系统检查首先检查了电源线路,发现电源线连接正常,没有松动和短路的情况。
对控制电路进行了检测,发现控制板上的一个继电器损坏,导致启动信号无法传递。
2、机械系统检查检查了设备的传动部件,发现皮带出现了严重的磨损和松弛现象,影响了设备的动力传递。
对设备的轴承进行了检查,发现其中一个轴承出现了卡死的情况,导致设备无法正常运转。
3、液压系统检查检查了液压油箱的油位,发现油位过低,导致液压系统无法正常工作。
对液压泵和液压阀进行了检测,发现液压泵的内部磨损严重,液压阀也出现了堵塞的情况。
四、故障原因分析1、电气系统故障继电器损坏是由于长期频繁的开合导致的触点烧蚀,属于正常的老化现象。
控制板上的一些电子元件也出现了性能下降的情况,可能是由于工作环境温度过高或者湿度较大导致的。
2、机械系统故障皮带磨损和松弛是由于长期使用没有及时进行调整和更换,导致皮带受力不均。
轴承卡死是由于润滑不良和灰尘进入导致的,这也反映了设备的日常维护保养工作不到位。
3、液压系统故障油位过低是由于操作人员没有及时检查和添加液压油,导致液压系统吸空。
液压泵内部磨损和液压阀堵塞是由于液压油污染严重,没有按照规定的周期进行更换和过滤。
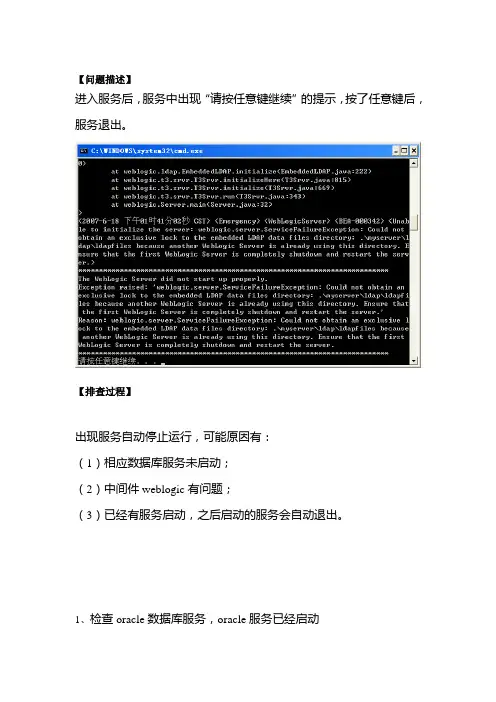
【问题描述】
进入服务后,服务中出现“请按任意键继续”的提示,按了任意键后,服务退出。
【排查过程】
出现服务自动停止运行,可能原因有:
(1)相应数据库服务未启动;
(2)中间件weblogic有问题;
(3)已经有服务启动,之后启动的服务会自动退出。
1、检查oracle数据库服务,oracle服务已经启动
2、检查weblogic服务是否有问题,我们可以查看到重启服务时提示
有另一个服务正在运行。
3、查看任务管理器中,确实有CMD.EXE的进程,并且我们注意到,
同时有计划任务在运行,因此怀疑在任务计划中启动了服务。
查看计划任务,果然是已经启动了weblogic服务,
【解决方案】
因服务在计划任务中设置成了自动启动,因此不需要手动打开服务。

运维常见故障及处理一、编码器故障故障原因:1)、连接导线断掉1)、编码器本体损坏处理方法:1)更换连接导线,紧固连接插头2)如本体坏掉,更换编码器二、通讯中断或者无通讯故障原因:1)环网有断点2)SCADA系统处理方法:1)查找断电的机组送电,或是UPS断电送电。
2)RIU 复位,交换机的水晶头从插3)SCADA从新启动三、振动传感器动作,安全链断开故障原因:1)由于风速过大,导致塔筒摇晃太大2)程序错误处理方法:1)如果因为振动大使安全链断开,在现场将UPS从新启动(机舱PLC断电)2)如有振动报警而安全链没有断开,在安全情况可以将振动等级增大一级以使风机组运行(厂家允许情况下)3)从新导入程序四、变桨通讯故障故障原因:1)滑环内部接触不好2)变桨通讯模块出错3)NOP插头接触不良4)主控柜内部程序出错处理方法:1)更换连接导线,NOP插头紧固2)更换变桨通讯模块,或从新上电变桨通讯模块,紧固CAN1连接插头3)从新导入主控程序四、发电机温度高故障原因:1)传感器坏掉2)散热器风扇不正常工作,或换气风扇不工作3)外界温度处理方法:1)检查传感器,更换传感器或换连接线。
2)检查散热器的空开,若跳掉,从新投入。
3)外界温度高,使机舱温度升高,应及时散热降温五.齿轮油温低故障原因:1)环境温度低且齿轮箱加热装置没有工作;2)环境温度过低且齿轮箱加热装置功率不足;3)温度传感器故障处理方法:1)检查加热器线路。
2)功率不足是,等待加热到正常温度3)若传感器损坏,断线及时更换。
六、变桨轴承密封圈漏油故障原因:密封圈出厂质量问题。
处理方法:厂家更换变桨轴承密封圈(仅供参考,欢迎大家补充)。

Weblogic宕机事件定位分析段常飞Weblogic宕机,是很多运维人员的噩梦,时不时的系统挂了,而且总是找不到源头,开发说程序没有大的变动,一直很平稳呀,客户反馈,系统硬件配置已经相当高了,足以支持系统运行呀。
又把问题抛给了运维人员,必须得找出原因了。
可是怎么下手呢下面我以郑州为例来演示如何定位程序问题。
郑州市、宕机事件日志错误类型:<2016-5-9 上午11时22分13秒CST> <Error> <WebLogicServer> <BEA-000337><[STUCK] ExecuteThread: '1' for queue: ' (self-tuning)' has been busy for "3,708" seconds working on the request "Workmanager: default, Version: 0, Scheduled=true, Started=true, Started time: 3708125 ms[Cookie:JSESSIONID=yGn2XvYC6yV3nDLJHCQFyxVQLSBcpL1WmRxkhQl78nyZTpq13J8v!-8; BIGipServerPool-zhongxinduan=", which is more than the configured time (StuckThreadMaxTime) of "3,600" seconds. Stack trace:>> INFO >> Timer-3 >> >> 检查内存更新...<2016-5-9 上午11时24分21秒CST> <Warning> <Socket> <BEA-000449> <Closing socket as no data read from it on during the configured idle timeout of 5 secs><2016-5-9 上午11时26分28秒CST> <Warning> <Socket> <BEA-000449> <Closing socket as no data read from it on during the configured idle timeout of 5 secs><2016-5-9 上午11时26分28秒CST> <Warning> <Socket> <BEA-000449> <Closing socket as nodata read from it on during the configured idle timeout of 5 secs>分析原因:weblogic的线程阻塞,进而导致批量等待阻塞,最纵引起weblogic挂起现象Weblogic 线程处理的默认时间为3600s,StuckThreadMaxTime:3600。

系统运维与故障排除的工作总结在当今数字化的时代,系统的稳定运行对于企业和组织的正常运转至关重要。
作为一名系统运维人员,我肩负着保障系统稳定、高效运行以及及时排除故障的重要职责。
在过去的一段时间里,我经历了各种挑战和机遇,也积累了不少宝贵的经验。
以下是我对这段时间系统运维与故障排除工作的详细总结。
一、工作内容概述系统运维工作涵盖了多个方面,包括服务器的监控与管理、网络设备的维护、应用系统的部署与更新、数据备份与恢复,以及日常的系统巡检等。
而故障排除则是在系统出现异常时,迅速定位问题并采取有效的解决措施,以减少业务中断的时间和影响。
在服务器监控方面,我使用专业的监控工具对服务器的性能指标进行实时监测,如 CPU 使用率、内存利用率、磁盘 I/O 等。
一旦发现指标异常,立即进行深入分析并采取相应的优化措施。
例如,当服务器的 CPU 使用率持续过高时,通过查看进程列表,找出占用资源较多的进程,并对其进行优化或终止。
网络设备的维护也是工作的重点之一。
我定期检查路由器、交换机等设备的运行状态,确保网络的畅通。
当出现网络故障时,通过排查线路连接、设备配置等方面,迅速恢复网络的正常运行。
应用系统的部署与更新是保障业务功能不断完善和优化的关键环节。
在进行部署和更新前,我会仔细测试新的版本,确保其稳定性和兼容性。
在更新过程中,严格按照操作流程进行,避免出现意外情况。
数据备份与恢复是保障数据安全的重要措施。
我制定了完善的数据备份策略,定期对重要数据进行备份,并定期进行恢复测试,以确保备份数据的可用性。
二、常见故障类型及处理方法在系统运维过程中,遇到了各种各样的故障。
以下是一些常见的故障类型及处理方法:1、硬件故障硬件故障是较为常见的问题之一,如服务器硬盘损坏、内存故障等。
当发现硬件故障时,首先要迅速定位故障硬件,并及时更换。
同时,要对数据进行恢复,以减少数据丢失的风险。
2、软件故障软件故障包括操作系统崩溃、应用程序出错等。

第9章GoldenGate错误分析与处理在维护GoldenGate过程中,由于各种意外情况,难免还是会遇到各种各样的问题。
掌握一些常见的GoldenGate故障诊断和错误分析的方法是非常有必要的,而且掌握这些错误分析工具也进一步加深对GoldenGate产品的认识与对GoldenGate原理的理解。
9.1 GoldenGate常见异常处理GoldenGate运行起来后,随着时间的推移可能会碰到各种各样的问题,下面就来介绍常见的异常现象以及常见的异常处理方法。
9.1.1 异常处理的一般步骤首先确定是GoldenGate的哪类进程有故障(是抽取,投递还是复制进程有问题),解决故障的一般思路如下。
(1)通过GGSCI>view report命令查找ERROR字样,确定错误原因并根据其信息进行排除。
(2)通过GGSCI>view ggsevt查看告警日志信息。
(3)检查两端数据库是否正常运行,网络是否连通。
(4)通过logdump工具对队列文件进行分析。
9.1.2 RAC单节点失败在RAC环境下,GoldenGate软件安装在共享目录下,可以通过任一个节点连接到共享目录,启动GoldenGate运行界面。
如果其中一个节点失败,导致GoldenGate进程中止,可直接切换到另外一个节点继续运行。
操作步骤如下。
(1)以Oracle用户登录源系统(使用另外一个正常的节点)。
(2)确认将GoldenGate安装的所在文件系统装载到另一节点相同目录。
(3)确认GoldenGate安装目录属于Oracle用户及其所在组。
(4)确认Oracle用户及其所在组对GoldenGate安装目录拥有读写权限。
(5)进入GoldenGate安装目录。
(6)执行./ggsci进入命令行界面。
(7)执行start mgr启动MGR。
(8)执行start er *启动所有进程。
检查各进程是否正常启动,即可进入正常复制。
9.1.3 Extract常见异常以下为列举的一些常见错误信息作参考用。
设备维护与故障处理工作总结工作总结:设备维护与故障处理在过去一年的工作中,作为设备维护与故障处理团队的一员,我深入参与了日常设备的维护工作,并及时响应和解决了各类设备故障。
在工作中,我体验到了工作的挑战以及通过解决问题所带来的成就感。
以下是我对这一年工作的总结与反思。
一、工作概述设备维护与故障处理工作是一个充满挑战的领域,要求我们具备扎实的专业知识和良好的沟通协调能力。
在过去的一年里,我所负责的设备维护工作主要包括:1. 定期设备巡检与保养。
按照工作计划,定期对设备进行巡检和保养,确保其良好的运行状态,并及时记录和汇报设备的运行情况。
2. 设备故障处理。
出现设备故障时,及时响应并开始排除故障,与相关部门密切合作,确保设备能够迅速恢复正常运行。
3. 设备维修与替换。
如果设备故障无法修复或超出修复范围,则需要进行设备维修或替换。
在此过程中,我需要与供应商和其他团队进行有效的协调合作。
此外,我还参与了一些设备的改进项目,通过优化设备的运行流程和维护计划,提高了设备的稳定性和效率。
二、工作收获与成就在过去一年的工作中,我积累了大量的专业知识和实践经验。
通过不断的学习与实践,我对各类设备的工作原理和故障排除方法有了更深入的理解,能够更迅速地判断和解决设备故障。
同时,由于工作的不确定性和复杂性,我也锻炼了自己的问题解决能力和应变能力。
在面对各种设备故障时,我能够冷静地分析问题、快速作出决策,并通过团队协作解决故障,取得了显著的成果。
三、工作中的不足与反思尽管在工作中取得了一些成绩,但我也意识到自己还存在一些不足之处。
首先,在一些重要设备的维护工作中,我可能没有及时发现潜在的问题,造成了一些不必要的故障。
这一点需要我改进,提高自己的观察力和敏感度。
其次,我在团队沟通和协作方面还有一定的欠缺。
有时候在处理复杂的故障时,我会过于独立思考,没有及时与其他团队成员进行沟通和协调。
这种情况下,我可能会浪费一些时间和资源,对工作效率产生一定的影响。
Weblogic常见报错以及解决⽅法[转载]Weblogic常见报错以及解决⽅法[转载]2020-09-13 09:55:22 4109 收藏 11⽂章标签:前⾔:Oracle WebLogic中间件在⽹站部署过程中经常会使⽤到。
该产品系列的核⼼是Oracle WebLogic服务器,它是⼀个功能强⼤和可扩展的Java EE服务器。
今天整理了在运维过程中经常会遇到的各种报错以及解决⽅法,纯技术⼲货,希望能够对正在学习weblogic过程中的您提供帮助。
weblogic有两种部署⽅式,单点模式和集群模式,单点模式直接创建⼀个域,在控制台进⾏程序部署即可;⽽集群模式分为admin(管理)节点和Managed(被管理)节点,管理节点通过控制台对被管节点进⾏管理,程序部署在被管节点的集群上。
不论是单点模式,还是集群模式,常见的报错基本⼀致。
基本概念Domain :域是作为单元进⾏管理的⼀组相关的 WebLogic Server 资源。
⼀个域包含⼀个或多个 WebLogic Server 实例,这些实例可以是集群实例、⾮群集实例,或者是集群与⾮群集实例的组合。
⼀个域可以包含多个集群。
域还包含部署在域中的应⽤程序组件、此域中的这些应⽤程序组件和服务器实例所需的资源和服务。
应⽤程序和服务器实例使⽤的资源和服务⽰例包括计算机定义、可选⽹络通道、连接器和启动类。
Domain 中包含⼀个特殊的 WebLogic 服务器实例,叫做 Administration Server,这是我们配置管理Domain中所有资源的核⼼。
通常,我们称加⼊Domain中的其他实例为 Managed Server,所有的Web应⽤、EJB、Web Services和其他资源都部署在这些服务器上。
Administration Server :管理服务器是控制整个域配置的中⼼操作节点,管理服务器维护着整个域的配置并将配置分配到每个被管理服务器 Managed Server 中。
数据中心设备维护与故障排除经验总结数据中心是现代化企业核心运营的重要部分,它承载着海量数据和关键应用系统的存储和处理,因此数据中心设备的维护和故障排除显得尤为重要。
为了最大限度减少设备故障对业务运行的影响,数据中心管理员需要积累并总结经验,以帮助他们在设备维护和故障排除过程中更加高效地工作。
一、设备维护经验总结1. 定期巡检和维护设备定期巡检是数据中心设备维护的基本工作,可以帮助管理员发现潜在的问题并采取相应的措施预防故障的发生。
巡检内容包括检查设备的供电线路、散热系统、存储设备和网络连接等。
同时,还应注意设备的清洁工作,使用合适的清洁工具和方法,定期清理设备表面和内部的灰尘和杂物,以保证设备的正常运行。
2. 注意设备的温度和湿度温度和湿度是设备正常运行的关键因素,过高或过低的温度都会影响设备的性能和寿命。
因此,数据中心管理员需要通过监控设备的温度和湿度,及时调整空调和湿度控制设备,保持适宜的工作环境。
此外,还可以采取合适的散热措施,如安装风扇或使用散热片等,以进一步提高设备的散热效果。
3. 做好设备的备份和升级数据中心设备的备份和升级是设备维护工作中重要的部分。
定期对设备进行备份,可以确保数据的安全性,一旦设备出现故障,可以及时恢复数据。
而设备的升级可以帮助解决潜在的性能问题和漏洞,提高设备的稳定性和安全性。
但在进行设备升级时,需要做好充分的准备工作,确保升级过程的顺利进行,避免升级失败导致数据丢失或设备无法正常工作的情况发生。
二、故障排除经验总结1. 建立故障管理流程对于数据中心设备的故障排除,建立一个清晰的故障管理流程非常重要。
首先,应及时响应用户报告的故障,并记录故障的具体信息,如出现故障的设备、故障的现象以及故障的发生时间等。
然后,根据故障的性质和紧急程度,指派合适的人员进行故障排查和修复。
在排查和修复的过程中,要注意记录排查的步骤和修复的方法,以便于日后的参考和总结。
2. 注意设备的日志监控设备的日志是故障排除和问题诊断的重要参考依据,因此需要定期检查和监控设备的日志信息。
weblogic运维时经常遇到的问题和常⽤的配置希望这篇能把weblogic运维时经常遇到的问题、常⽤的配置汇总到⼀起。
1、配置jvm参数:⼀般在domain启动过程中会看到以下启动的⽇志信息,如下图所⽰:图中红⾊⽅框部分为启动weblogic domain的命令。
其中包括了jvm参数以及classpath信息。
【注意】java -client是由于之前建⽴的domain是开发模式的。
⽣产模式的话,这⾥执⾏的是java -server。
⾄于-client与-server的区别,⼤家去google下吧,这⾥不介绍了。
那如何修改这个配置呢?找到setDomainEnv.cmd⽂件(linux下⾯就是setDomainEnv.sh了),位置为:weblogic11\user_projects\domains\example\bin\setDomainEnv.cmd修改⽂件中的MEM_ARGS部分,相关参数配置如下:Java代码1. call "%WL_HOME%\common\bin\commEnv.cmd"2.3. set WLS_HOME=%WL_HOME%\server4.5. if "%JAVA_VENDOR%"=="Sun" (6. set WLS_MEM_ARGS_64BIT=-Xms256m -Xmx512m7. set WLS_MEM_ARGS_32BIT=-Xms256m -Xmx512m8. ) else (9. set WLS_MEM_ARGS_64BIT=-Xms512m -Xmx512m10. set WLS_MEM_ARGS_32BIT=-Xms512m -Xmx512m11. )12.13. set MEM_ARGS_64BIT=%WLS_MEM_ARGS_64BIT%14.15. set MEM_ARGS_32BIT=%WLS_MEM_ARGS_32BIT%16.17. if "%JAVA_USE_64BIT%"=="true" (18. set MEM_ARGS=%MEM_ARGS_64BIT%19. ) else (20. set MEM_ARGS=%MEM_ARGS_32BIT%21. )22.23. set MEM_PERM_SIZE_64BIT=-XX:PermSize=128m24.25. set MEM_PERM_SIZE_32BIT=-XX:PermSize=48m26.27. if "%JAVA_USE_64BIT%"=="true" (28. set MEM_PERM_SIZE=%MEM_PERM_SIZE_64BIT%29. ) else (30. set MEM_PERM_SIZE=%MEM_PERM_SIZE_32BIT%31. )32.33. set MEM_MAX_PERM_SIZE_64BIT=-XX:MaxPermSize=256m34.35. set MEM_MAX_PERM_SIZE_32BIT=-XX:MaxPermSize=128m36.37. if "%JAVA_USE_64BIT%"=="true" (38. set MEM_MAX_PERM_SIZE=%MEM_MAX_PERM_SIZE_64BIT%39. ) else (40. set MEM_MAX_PERM_SIZE=%MEM_MAX_PERM_SIZE_32BIT%41. )42. if "%JAVA_VENDOR%"=="Sun" (43. if "%PRODUCTION_MODE%"=="" (44. set MEM_DEV_ARGS=-XX:CompileThreshold=8000 %MEM_PERM_SIZE%45. )46. )47.48. @REM Had to have a separate test here BECAUSE of immediate variable expansion on windows49.50. if "%JAVA_VENDOR%"=="Sun" (51. set MEM_ARGS=%MEM_ARGS% %MEM_DEV_ARGS% %MEM_MAX_PERM_SIZE%52. )53.54. if "%JAVA_VENDOR%"=="HP" (55. set MEM_ARGS=%MEM_ARGS% %MEM_MAX_PERM_SIZE%56. )57.58. if "%JAVA_VENDOR%"=="Apple" (59. set MEM_ARGS=%MEM_ARGS% %MEM_MAX_PERM_SIZE%60. )61.62. @REM IF USER_MEM_ARGS the environment variable is set, use it to override ALL MEM_ARGS values63.64. if NOT "%USER_MEM_ARGS%"=="" (65. set MEM_ARGS=%USER_MEM_ARGS%66. )主要就是修改-Xms、-Xmx、-XX:PermSize、-XX:MaxPermSize的参数(视具体硬件、JVM负载情况进⾏修改)。
运维常见故障问题及处理的重新总结标题:运维常见故障问题及处理的重新总结导言:运维人员负责保持系统的稳定和正常运行,然而在实际工作中常常会面临各种故障问题。
本文将重新总结一些常见的运维故障问题,并提供相应的处理方法和建议,帮助运维人员更好地处理和解决这些问题。
1. 网络故障1.1 连接问题在现代IT环境中,网络连接是运维的基础。
常见的网络故障包括:物理线路故障、交换机故障、路由器故障等。
处理网络故障时,运维人员应遵循以下步骤:- 检查物理连接,确认线路是否完好;- 检查网络设备的状态,确认交换机和路由器是否正常工作;- 使用网络诊断工具进行故障定位,比如Ping命令、Traceroute命令等。
1.2 带宽问题运维人员常常需要应对带宽瓶颈导致的网络故障。
以下是一些建议:- 监控网络流量并及时发现异常;- 分析流量模式并进行合理的调整,比如负载均衡、流量控制等;- 考虑升级网络设备以提升带宽。
2. 服务器故障2.1 硬件故障硬件故障是服务器故障中最常见的问题之一。
以下是处理服务器硬件故障的一些建议:- 定期检查硬件设备的状态,包括磁盘、内存、CPU等;- 及时更换老化硬件设备,避免因为硬件故障导致系统崩溃;- 对于关键服务器,使用冗余配置以实现容错和高可用性。
2.2 软件故障软件故障也是常见的服务器故障问题。
以下是一些处理方法:- 及时安装系统补丁和更新,以提高系统的安全性和稳定性;- 配置合适的监控工具,对服务器性能进行实时监控;- 错误日志的分析和归纳,及时排查问题的根本原因。
3. 数据库故障数据库是许多应用系统关键的组成部分,它的稳定性和可靠性对整个系统都至关重要。
以下是一些建议:- 定期备份和恢复数据库,确保数据的安全性和可恢复性;- 对数据库进行性能优化,包括索引优化、查询优化等;- 提高数据库的容错和冗余机制,保证系统的高可用性。
4. 安全问题安全问题是运维过程中另一个需要高度关注的领域。
中间件故障诊断总结一、步骤:1、准确描述现象:客户说的和自己查看到的:平台、版本、操作、信息等。
特别是,故障前是否有做过什么操作:网络调整、设备调整、主机参数调整、配置文件修改……反正将这一切都列入排查的对象。
2、使用工具收集数据,收集配置文件、日志、dump文件等等。
3、使用分析数据,根据问题或收集的数据,使用适当的工具分析数据,当然包括了在网上和在官方支持站点搜索类似的问题的解决办法。
4、尝试解决问题,根据找到的问题点,尝试解决。
如修改错的,复原正确的;运行有问题的,适当调整运行的环境和运行的参数等等。
5、给出最佳解决方案,一般就是继续观察了。
6、总结经验并加以重用,知识积累。
二、通过前台收集基本的信息:1、重点是故障前做过的操作2、比对运行平台是否在官方的兼容性列表中,一般就是关注各个版本,特别是一些比较怪异的问题3、检查环境和参数,如能打开控制台,就在控制台中初步观察,一般进入控制台的格式是http://ip地址:端口/console如:http://192.168.0.89:7001/console/。
常用的留意点如下:A、域运行状态(域-监视-健康状况);一般为running状态,如果不是running,那这些界面就没有了。
B、服务器运行状态(域-环境-服务器),正常的为running。
C、各个server性能(JVM)状态(域-环境-服务器,点击具体的serve后进入,监视-健康状况);留意JVM 堆中当前可用的内存量。
不同的JVM,所显示的内容可能不一样,以下为sun的:D、各个server线程状态(域-环境-服务器,点击具体的serve后进入,监视-线程);一般来说,空闲线程要多;健康状况为ok如下图health状态为:Warning,这个是有线程阻塞的。
阻塞线程的内容为:####<2011-8-13 上午02时42分35秒 GMT+08:00> <Error> <WebLogicServer> <dataweb1> <dc_admin1> <[ACTIVE] ExecuteThread: '15' for queue:'weblogic.kernel.Default (self-tuning)'> <<WLS Kernel>> <> <><1313174555613> <BEA-000337> <[STUCK] ExecuteThread: '19' for queue: 'weblogic.kernel.Default (self-tuning)' has been busy for "2,492" seconds working on the request"weblogic.work.SelfTuningWorkManagerImpl$WorkAdapterImpl@12035ed", which is more than the configured time (StuckThreadMaxTime) of "2,400" seconds. Stack trace:.SocketOutputStream.socketWrite0(Native Method) .SocketOutputStream.socketWrite(SocketOutputStream.java:97).SocketOutputStream.write(SocketOutputStream.java:141).ns.DataPacket.send(Unknown Source)E、JDBC(域-环境-服务器,点击具体的serve后进入,监视-JDBC);活动连接数合理。
F、程序EJB/Web Module(域-部署);状态为活动,健康状况为ok。
其目标关联正确G、JMS(域-服务-消息传送-JMS服务器);健康状态为ok。
4、在控制台生成dump;生成Dump Thread Stacks内容;查找queryList等关键字符,即可快速定位问题代码。
5、如果控制台打不开或无法进入,就要先看进程有没有在跑,如果进程有,但控制台或程序无法进入,一般就是有故障了,此时,可以通过相关日志进行后台分析分析。
三、后台日志分析:一般来说,新建立的环境,配置的问题多一点;已经运行的生成系统错误或bug 的可能性大点。
当出现故障时,就可以调取系统日志、中间件的日志,根据相关关键字(BEA-)网上搜索,或到官方网站对相关问题的描述进行查找。
WebLogic在启动及运行过程中会记录各种LOG信息,以帮助系统治理员对整个应用系统进行治理及维护。
1、log默认位置..\user_projects\domains\your_domain\servers\AdminServer\logs下面的AdminServer.log;access.log;domain_name.log新版的如:C:\Oracle\Middleware\user_projects\domains\base_domain\servers\Adm inServer\logs如果是重定向输出的,就看重定向输出的文件。
2、日志文件说明WebLogic SERVER运行日志假如WebLogic SERVER在启动或运行过程中有错误发生,错误信息会显示在屏幕上,并且会记录在一个LOG文件中,该文件默认名为AdminServer.log。
该文件也记录WebLogic的启动及关闭等其他运行信息。
可在Gernal属性页中设置该文件的路径及名字,错误的输出的等级等。
HTTP访问日志在WebLogic中可以对用HTTP,HTTPS协议访问的服务器上的文件都做记录,该LOG文件默认的名字为Access.log,内容如下,该文件具体记录在某个时间,某个IP地址的客户端访问了服务器上的那个文件。
127.0.0.1 - - [25/Feb/2002:11:35:58 +0800] "GET /weather HTTP/1.1" 302 0127.0.0.1 - - [25/Feb/2002:11:35:58 +0800] "GET /weather/index.Html HTTP/1.1" 200 176HTTP访问日志的属性可在HTTP属性页中进行设置。
DOMAIN运行日志记录一个DOMIAN的运行情况,一个DOMAIN中的各个WebLogic SERVER可以把它们的一些运行信息(比如:很严重的错误)发送给一个DOMAIN的ADMINISTRATOR SERVER上,ADMINISTRATOR SERVER把这些信息些到DOMAIN 日志中。
默认名为:domain_name.log 。
一般就看这个最多。
3、通过控制台查看或修改系统日志路径登录weblogic后台左侧菜单:Environment->Servers右侧菜单:AdminServer(admin)->logging只找到examplesServer.log、access.log配置如图:4、其他如果日志太少,里面没有记载相关信息,可参照日志文件的回滚设置。
在“滚动类型:”属性页中可以设置这些日志文件的回滚方式,当日志文件到一定得大小或过了设定的时间后,把日志信息保存到一个新的文件中。
WebLogic提供按文件大小和时间两种方式。
如下面的设置种,选择Rotation Type 为BY SIZE。
也就是当日志文件的大小达到500K时,重新写一个新的文件。
假如Rotation Type 为BY TIME,那么是每隔一段时间重新写一个新的文件。
并且对这些文件编号设置日志文件名如:_%yyyy%_%MM%_%dd%_%hh%_%mm%5、日志的处理:查看日志中输出的具体内容,再进行处理。
如:BEA-下面是一个线程阻塞的一个信息####<2011-8-13 上午03时51分46秒 GMT+08:00> <Error> <WebLogicServer> <dataweb1> <dc_admin1> <[ACTIVE] ExecuteThread: '11' for queue:'weblogic.kernel.Default (self-tuning)'> <<WLS Kernel>> <> <><1313178706712> <BEA-000337> <[STUCK] ExecuteThread: '1' for queue: 'weblogic.kernel.Default (self-tuning)' has been busy for "2,503" seconds working on the request"weblogic.work.SelfTuningWorkManagerImpl$WorkAdapterImpl@deab5f", which is more than the configured time (StuckThreadMaxTime) of "2,400" seconds. Stack trace:四、产生hread Dump来分析问题hread Dump是非常有用的诊断Java应用问题的工具,每一个Java虚拟机都有及时生成显示所有线程在某一点状态的thread-dump的能力。
虽然各个Java虚拟机thread dump打印输出格式上略微有一些不同,但是Thread dumps出来的信息包含线程;线程的运行状态、标识和调用的堆栈;调用的堆栈包含完整的类名,所执行的方法,如果可能的话还有源代码的行数。
Thread Dump特点:•能在各种操作系统下使用•能在各种Java应用服务器下使用•可以在生产环境下使用而不影响系统的性能•可以将问题直接定位到应用程序的代码行上Thread Dump能诊断的问题包括:•查找内存泄露,常见的是程序里load大量的数据到缓存•发现死锁线程•收集 Thread Dump进行 Thread Dump 的方法取决于安装挂起服务器实例的操作系统。