实验5多元统计分析spss
- 格式:docx
- 大小:54.01 KB
- 文档页数:6
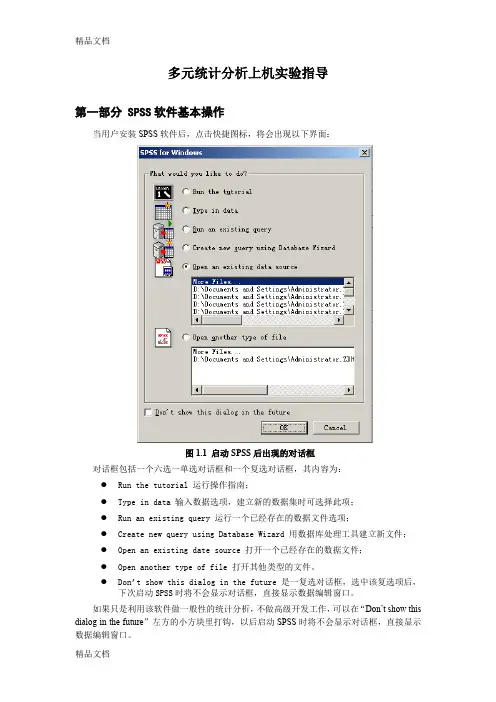
多元统计分析上机实验指导第一部分 SPSS软件基本操作当用户安装SPSS软件后,点击快捷图标,将会出现以下界面:图1.1 启动SPSS后出现的对话框对话框包括一个六选一单选对话框和一个复选对话框,其内容为:●Run the tutorial 运行操作指南;●Type in data 输入数据选项,建立新的数据集时可选择此项;●Run an existing query 运行一个已经存在的数据文件选项;●Create new query using Database Wizard 用数据库处理工具建立新文件;●Open an existing date source 打开一个已经存在的数据文件;●Open another type of file 打开其他类型的文件。
●Don’t show this dialog in the future 是一复选对话框,选中该复选项后,下次启动SPSS时将不会显示对话框,直接显示数据编辑窗口。
如果只是利用该软件做一般性的统计分析,不做高级开发工作,可以在“Don’t show this dialog in the future”左方的小方块里打钩,以后启动SPSS时将不会显示对话框,直接显示数据编辑窗口。
§1.1 数据文件的建立SPSS 软件包的数据编辑主窗口类似于EXCEL ,数据文件的建立就是在数据编辑窗口中完成的。
数据编辑窗口可以显示两张表,分别是Data View (见图1.2)和Variable View (见图1.3),通过点击下端的2个同名窗口标签按钮实现相互切换。
数据编辑区是SPSS 的主要操作窗口,是一个二维平面表格,用于对数据进行各种编辑;标尺栏由纵向标尺栏和横向标尺栏,横向标尺栏显示数据变量,纵向标尺栏显示数据顺序(如时间顺序)。
Data View 表可以直接输入观测数据值或存放数据,表的左端列边框显示观测个体的序号,最上端行边框显示变量名。

根据实验结果,进行多元方差分析SPSS操作步骤多元方差分析(MANOVA)是一种统计方法,用于比较两个以上组之间在多个连续因变量上的差异。
SPSS是一款功能强大的统计分析软件,可以用于进行多元方差分析。
下面是进行多元方差分析的SPSS操作步骤:1. 打开SPSS软件,并导入实验数据。
2. 在菜单栏选择“分析”(Analyze),然后选择“一元方差分析”(General Linear Model)。
3. 在弹出的对话框中,将多个连续因变量添加到“因变量”(Dependent Variables)框中。
点击“添加”按钮,然后选择需要分析的连续因变量。
4. 将一个或多个离散自变量添加到“因子”(Factors)框中。
点击“添加”按钮,然后选择需要分析的离散自变量。
5. 点击“选项”(Options)按钮,可以进行一些附加的设置。
例如,可以选择是否计算效应大小、调整误差项或进行共同协方差矩阵的检验等。
6. 点击“确定”按钮,开始进行多元方差分析。
7. 分析结果会显示在SPSS的输出窗口中。
可以查看因变量之间的差异是否显著,以及不同组之间是否存在显著差异。
8. 为了更好地理解结果,可以进一步进行后续分析。
例如,可以进行事后比较(Post hoc tests)来确定具体哪些组之间存在显著差异。
请注意,进行多元方差分析前,需要确保数据满足一些假设条件,如正态性、方差齐性和无多重共线性等。
另外,为了减少假阳性结果,应谨慎解释显著性水平。
以上是根据实验结果进行多元方差分析SPSS操作的步骤。
希望对您有所帮助!如有需要,请随时与我联系。


【精品】多元统计分析--判别分析SPSS实验报告一、实验目的1.掌握判别分析的基本原理和应用方法;2.掌握SPSS软件进行判别分析的具体操作;3.通过一个实例,学习如何运用判别分析对指标进行判别。
二、实验内容三、实验原理1.判别分析基本原理:判别分析(Discriminant Analysis),是一种统计学中的分类技术,它是对变量进行归类的技术。
判别分析是用来确定一个对象或自变量集合属于哪一个预设类型或者组别的过程。
判别分析能够生成一个函数,将数据点映射到特定的类型上。
判别分析的应用领域非常广泛,主要应用于以下领域:(1)股票市场(预测股价的涨跌与时间、公司发展情况等因素的关系);(2)医学(区分疾病、患者状态等);(3)市场调查(确定客户类型、产品或服务喜好);(4)产业分析(区分有助于产品销售的市场决策因素);(5)经济学(预测月度或季度的经济指标)。
3.判别分析的主要应用步骤:(1)建立模型:首先选择和收集数据,将收集的数据分为训练集和测试集;(2)训练模型:使用训练数据建立模型;(3)评估模型:通过模型诊断来评估建立的模型的好坏;(4)应用模型:对新的数据建立模型并进行预测。
四、实验过程1. 上机操作:1)打开SPSS软件,加载数据文件;2)选择分类变量和连续变量;3)选择训练数据集;4)建立模型;5)预测实验数据集。
2. 操作步骤:SPSS分析的步骤如下:1)将数据输入SPSS软件,确保数据格式正确;2)选择Analyse- Classify- Discriminant;3)有两种不同的分类变量,单分类或多分类,如果你要解释一个特定的分类变量,选择单分类。
如果你不确定哪个分类变量最适合,请尝试不同的选项;4)选择两个或更个你认为与指定分类变量相关的连续变量;5)选择要用于判别分析的数据集;6)确定分类变量分类比率。
这可以在设置选项中完成;7)点击OK,开始进行分析;8)评估结果,包括汇总、判别函数、方差-方差贡献、判别矩阵;五、实验结果选取鸢尾花数据,经过训练,得到如下表所示的结果。

多元统计分析SPSS操作步骤方差分析:Analyze—general linear model—univariate1、结果选入dependent variable,自变量选入fixed factors2、Options(display:descriptive statistics)主成分分析:Analyze→Dataredution---factor1、自变量:放入Variables2、Descriprives: (statistics默认)(correlation matrix:coefficients,KMO,)3、Extiaction :( method默认)(analyze:correlation)(display:全选)(extract:默认)4、Rotation:(method:none) (display:loading plot)5、Scores:(save as variables)(Display factor)因子分析Analyze→Dataredution---factor6、自变量:放入Variables7、Descriprives: (statistics默认)(correlation matrix:coefficients,KMO,anti-image)8、Extiaction :( method默认)(analyze:correlation)(display:全选)(extract:默认)9、Rotation:(method:quartimax) (display:rotated solution)10、Scores:(save as variables)(Display factor)11、Options:(默认)Logistic回归加权处理:data-weight cases-频数放入FVAnalyze—regression—binary logistic (二分类)1、因变量(y)放入dependent;自变量放入covariates;metord:forward(一般forward wald)2、Save:(predictde values:probabilities)3、Options:(statistics and plots: Hosmer;CI for exp(B))生存分析之life tables加权Analyze—survival—life table(未完成)1、生存时间选入time,Display time intervals:0 through(?)by(?),结局进入Status框,Define失效事件,变量进入Factor框,点击Define Range...钮,定义分组的范围,在Mininum 框中输入小的,在Maxinum框中输入大的2、 Options.(Plot:Survival)(Compare Levels of First Factor:Overall)生存分析之kaplan-meireAnalyze—survival—kaplan-meire1、生存时间选入time,结局入status,define 失效事件,2、Compare factor:(log rank)3、Save:(survival,standard)4、Options:(statistics:survival table;mean and median survival),(plot:survival)生存分析之COX生存时间处理transform—computeAnalyze—survival—cox1、生存时间入time,结局入status,define 失效事件,自变量选入covariaes,strate:对子数2、Plots(plot type:survival)3、Save(survival:function,standard error)4、Options(model statistics:CI for exp(B))。



多元统计学上机实验项目一(撰写实验报告)实验项目名称:练习运用SPSS软件进行聚类分析一、实验目的与要求:通过上机实验,熟练掌握运用SPSS软件进行Q型系统聚类和K-MEANS聚类,能对聚类分析软件输出结果进行分析。
二、实验环境硬件环境:微机软件环境:SPSS软件三、实验内容与步骤(一)实验内容一:运用SPSS软件进行系统聚类1. 实验内容为了研究亚洲国家的经济发展水平和文化教育水平,以便于对亚洲国家进行分类研究,对SPSS软件自带的数据文件World95.sav中的亚洲国家和地区进行系统聚类分析。
2. 实验步骤⑴打开数据。
使用菜单中File→Open命令,然后选中要分析的数据World95.sav。
在World95.sav数据中筛选出亚洲国家,使用Data→Select Cases →If condition is satisfied中选入region=3;⑵在菜单中的选项中选择Analyze→Classify命令,Classify命令下有两个聚类分析命令,一是K-means cluster(K-均值聚类),二是Hierarchical cluster(系统聚类法)。
这里我们选择系统聚类法。
⑶在系统聚类法中,我们看到Cluster下有两个选项,Cases(样品聚类或Q 型聚类)和Variables (变量聚类或R型聚类)。
这里我们选择对样品进行聚类。
⑷Display下面有两个选项,分别是Statistics (统计量)、Plots(输出图形),我们可以选择所需要输出的统计量和图形。
⑸在系统聚类法中底下有四个按纽,分别是Statistics、Plots、Method、Save。
(a)在Statistics中,有Agglomeration schedule(每一阶段聚类的结果),Proximity matrix(样品间的相似性矩阵)。
由Cluster membership可以指定聚类的个数,none选项不指定聚类个数,Single solution指定一个确定类的个数,Range of solution指定类的个数的范围(如从分3类到分5类)。

多元统计分析与SPSS多元统计分析是指通过应用多个统计方法和技术对多个变量之间的关系进行分析的一种统计分析方法。
SPSS(Statistical Package for the Social Sciences)是一个常用的统计分析软件,可以对大规模的数据集进行多元统计分析。
多元统计分析包括多个方法和技术,如多元方差分析、主成分分析、因子分析、聚类分析、判别分析等。
这些方法和技术可以帮助我们理解变量之间的关系,预测和解释数据,并支持决策制定。
通过使用SPSS软件,可以更轻松地进行这些分析。
在多元方差分析中,可以通过比较组别间的平均差异来检验因素对变量的影响;在主成分分析中,可以通过降低变量维度来提取主要的变化模式;在因子分析中,可以通过识别潜在的构念来简化变量之间的关系;在聚类分析中,可以通过将观测值划分为不同的群组来发现变量之间的模式;在判别分析中,可以根据已知组别来预测新观测值的组别。
SPSS软件提供了各种功能和工具,以便于使用者进行多元统计分析。
用户可以使用SPSS进行数据导入和数据清理,选择适当的多元统计方法和技术,设定分析的参数和条件,并生成相应的统计结果和图表。
此外,SPSS还提供了一些数据分析模板和指导,帮助用户更好地理解和使用多元统计分析方法。
在实际应用中,多元统计分析和SPSS广泛应用于社会科学、经济学、市场研究、医学和生物学等领域。
例如,研究者可以使用多元统计分析和SPSS来研究消费者行为模式、预测市场需求、评估治疗效果等。
企业可以使用多元统计分析和SPSS来进行市场细分、产品定位和品牌定位。
医生可以使用多元统计分析和SPSS来研究临床疗效、预测疾病发展等。
总而言之,多元统计分析是一种强大的统计方法,可以帮助我们理解和解释变量之间的复杂关系。
SPSS软件提供了方便易用的工具和功能,使得多元统计分析更加简单和高效。
同时,多元统计分析和SPSS广泛应用于各个领域,为研究者和决策者提供了有力的支持和指导。
《多元统计分析分析》实验报告2012 年月日学院经贸学院姓名学号实验实验成绩名称一、实验目的(一)利用SPSS对主成分回归进行计算机实现.(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.二、实验内容以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用三、实验步骤(以文字列出软件操作过程并附上操作截图)1、数据文件的输入或建立:(文件名以学号或姓名命名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”首先定义变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2、具体操作分析过程:(1)首先做因变量Y与自变量X1-X3的普通线性回归:在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)图5 图6图7图8图9回归分析输出结果:的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。

SPSS多元统计分析方法及应用课程设计引言多元统计分析是研究几个变量之间关系的一种统计学方法。
SPSS是一款常用的统计分析软件,可以用来进行多元统计分析。
本文将介绍如何使用SPSS进行多元统计分析,并结合具体案例,设计SPSS多元统计分析课程。
SPSS多元统计分析方法相关分析相关分析是研究两个变量之间的关系的统计方法。
可以使用SPSS进行相关分析,步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Correlate”选项,然后选择“Bivariate”。
3.将需要进行相关分析的变量添加到“Variables”框中。
4.点击“OK”按钮,SPSS会生成相关系数以及P值。
回归分析回归分析用来研究一个自变量和一个或多个因变量之间的关系。
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Regression”选项,然后选择“Linear”。
3.将自变量和因变量添加到“Dependent”和“Independent”框中。
4.点击“OK”按钮,SPSS会生成回归分析结果。
方差分析方差分析是一种用于比较两个或多个组之间差异的统计方法。
使用SPSS进行方差分析的步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Analyze of Variance”选项,然后选择“One-Way ANOVA”。
3.将需要进行方差分析的变量添加到“Dependent List”框中,将分组变量添加到“Factor”框中。
4.点击“OK”按钮,SPSS会生成方差分析结果。
SPSS多元统计分析课程设计为了帮助学生更好地掌握SPSS多元统计分析方法,我们可以设计以下课程:第一节课:相关分析1.介绍相关分析的概念和应用场景。
2.通过具体案例演示如何使用SPSS进行相关分析。
3.让学生自行导入数据文件,并进行相关分析,并展示分析结果。
如何使用SPSS进行多元统计分析第一章:SPSS简介SPSS(Statistical Package for the Social Sciences)是一种功能强大且广泛使用的统计分析软件。
它能够处理大量数据,进行各种统计分析和数据挖掘,是研究人员和数据分析师常用的工具。
第二章:设置数据在进行多元统计分析之前,首先需要设置数据。
SPSS支持导入外部数据文件,如Excel、CSV等格式。
用户可以在SPSS中创建新的数据集并录入数据,也可以导入已有数据集。
在设置数据时,需要注意数据的变量类型、缺失值处理以及数据的清洗与转换。
第三章:描述统计分析描述统计分析是理解数据的第一步。
SPSS提供了丰富的描述统计方法,包括平均数、标准差、最小值、最大值、频数分布等。
用户可以通过简单的命令或者界面操作来生成各种描述统计结果,并进一步进行数据的可视化展示。
第四章:相关性分析相关性分析是多元统计分析的常用方法之一。
SPSS提供了丰富的相关性分析工具,如Pearson相关系数、Spearman等。
用户可以通过相关分析来检测不同变量之间的关系,并进一步探索变量之间的线性或非线性关系。
第五章:线性回归分析线性回归分析是一种预测性分析方法,在多元统计分析中应用广泛。
SPSS可以进行简单线性回归分析和多元线性回归分析。
用户可以通过线性回归分析来建立模型,预测因变量与自变量之间的关系,并进行参数估计和显著性检验。
第六章:因子分析因子分析是一种常用的降维技术,用于发现隐藏在数据中的潜在变量。
SPSS提供了主成分分析、最大似然因子分析等方法。
用户可以通过因子分析来降低变量的维度,提取数据中的主要信息。
第七章:聚类分析聚类分析是一种用于将数据样本划分成相似组的方法。
SPSS支持多种聚类算法,如K均值聚类、层次聚类等。
用户可以通过聚类分析来识别数据中的固有模式和群体。
第八章:判别分析判别分析是一种用于将样本分类的方法,常用于研究预测变量对分类变量的影响。
多元统计分析原理与基于SPSS的应用1. 引言多元统计分析是统计学中的重要分支,用于研究多个变量之间的关系和模式。
在实际应用中,SPSS是一个流行的统计分析软件,提供了丰富的功能和工具,可以用于多元统计分析。
本文将介绍多元统计分析的原理,并探讨如何利用SPSS进行实际应用。
2. 多元统计分析概述多元统计分析是一种从多个维度考察数据的统计方法。
它可以帮助研究者发现多个变量之间的模式和关联,从而提供更深入的分析和理解。
常见的多元统计分析方法包括:主成分分析、因子分析、聚类分析、判别分析等。
2.1 主成分分析(PCA)主成分分析是一种减少数据集维度的方法,它可以将大量的变量转化为少数几个主成分。
通过主成分分析,可以发现数据中的主要模式和结构,从而简化数据集和分析过程。
2.2 因子分析因子分析是一种确定变量之间潜在关系的方法。
它可以帮助研究者发现共同的因素或维度,并解释变量之间的相关性。
因子分析可用于降维或构造新的变量,进而减少数据集的复杂性。
2.3 聚类分析聚类分析是一种将观测对象分组或分类的方法。
它可以通过计算对象之间的相似性或距离,将它们划分为不同的类别。
聚类分析可帮助研究者发现数据中的隐藏结构,并进行进一步的分析和解释。
2.4 判别分析判别分析是一种预测变量类别的方法。
它可以根据已知类别的样本数据,建立预测模型并进行分类。
判别分析可用于识别不同群体或类别之间的差异,并进行进一步的推断和预测。
3. 多元统计分析的应用场景多元统计分析可以应用于各种领域,如市场调研、社会科学、医学研究等。
以下是一些常见的应用场景:•市场调研:通过主成分分析和因子分析,可以帮助企业确定消费者需求和消费行为的主要影响因素。
•社会科学:聚类分析可用于对人群进行社会分类,从而提供对人群特征和行为的深入理解。
•医学研究:判别分析可以应用于医学诊断,预测患者是否患有某种疾病或疾病的严重程度。
4. 基于SPSS的多元统计分析应用示例SPSS是一款功能强大的统计分析软件,提供了多种多元统计分析方法和工具。
实验课程名称: __多元统计分析--判别分析___准则判别归类,则可写成:⎪⎩⎪⎨⎧=>∈<∈),(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。
对每种鸢尾有n1=n2=n3=50个观测值。
部分数据:第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。
判别分析:步骤:1、选择分析→分类→判别,打开判别分析子对话框。
2、选择变量“总体”,单击→,将其加入到分组变量栏中。
3、打开定义范围子对话框,最小值输入1,最大值输入3。
4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。
选择“一起输入自变量”的方法。
5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协方差、分组协方差及总体协方差,单击继续。
6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。
7、打开保存,选择所有的变量。
相关系数矩阵a总体萼片宽度X2 花瓣宽度X4合计萼片宽度X2 .190 -.122花瓣宽度X4 -.122 .581对数行列式总体秩对数行列式1 2 -6.4962 2 -6.1413 2 -5.189汇聚的组内 2 -5.583检验结果箱的M 52.832F 近似。
8.632df1 6df2 538562.769Sig. .000Wilks 的Lambda函数检验Wilks 的Lambda 卡方df Sig.1 到2 .038 477.868 4 .0002 .809 31.075 1 .000典型判别式函数系数函数1 2萼片宽度X2 -1.987 2.680花瓣宽度X4 5.477 .817(常量) -.494 -9.174非标准化系数组质心处的函数总体函数1 21 -5.958 .2152 1.265 -.6673 4.693 .452分类结果b,c总体预测组成员1 2 3 合计初始计数 1 50 0 0 502 0 49 1 503 04 46 50% 1 100.0 .0 .0 100.02 .0 98.0 2.0 100.03 .0 8.0 92.0 100.0 交叉验证a计数 1 50 0 0 502 0 48 2 503 04 46 50% 1 100.0 .0 .0 100.02 .0 96.0 4.0 100.03 .0 8.0 92.0 100.0。
青岛农业大学
多元统计分析实验报告
姓名:庞云杰
学号:20155653
班级:信计1502
指导老师:徐英
2017年11月28日
多元统计分析实验课:实验五
实验题目主成分分析
实验目的了解SPSS软件,掌握SPSS软件处理主成分分析的基本操
作
实验地点及时间信息楼127机房,周二8-9节
实验内容
1. 了解SPSS软件及常用功能;
2.了解主成分分析的原理;
3.掌握SPSS软件处理主成分分析的操作过程和技巧。
实验习题
1.题目简述:中国大陆31个省(市、区)2008年第三产业综合发展水平的主成分分析与评估。
选取了人均地区生产总值(元)、人均第三产业增加值(元)、第二产业占GDP的比重、第三产业占GDP的比重、第三产业就业人员比重、城镇化水平(%)、第三产业固定资产投资比重八项指标,具体数据见附件。
根据以上数据分析结果对全国31个地区的第三产业综合发展水平进行综合评价,并整理实验报告。
解答如下:
2.(1)首先对原始数据作标准化处理,然后计算标准化后的各指标之间的相关系数矩阵;
(标准化过程:点击分析—描述统计—描述;
相关系数矩阵过程:点击分析—相关—双变量然后确定。
)
相关性
Zscore: 人均地区生产总值/
元Zscore:
人均第三
产业增加
值/元
Zscore:
第二产业
占GDP的比
重/%
Zscore:
第三产业
占GDP的比
重/%
Zscore:
第三产业
就业人员
比重/%
Zscore:
城镇化水
平/%
Zscore:
第三产业固
定资产投资
比重/%
Zscore: 人均地区生产总值/元Pearson
相关性
1 .933**.037 .532**.760**.930**-.005
显著性
(双侧)
.000 .844 .002 .000 .000 .980 N 31 31 31 31 31 31 31
Zscore: 人均第三产业增加值/元Pearson
相关性
.933** 1 -.254 .768**.894**.874**.142
显著性
(双侧)
.000 .168 .000 .000 .000 .446 N 31 31 31 31 31 31 31
Zscore: 第二产业占GDP的比重/% Pearson
相关性
.037 -.254 1 -.734**-.378*.051 -.667**
显著性
(双侧)
.844 .168 .000 .036 .786 .000 N 31 31 31 31 31 31 31
Zscore: 第三产业占GDP的比重/% Pearson
相关性
.532**.768**-.734** 1 .802**.463**.505**
显著性
(双侧)
.002 .000 .000 .000 .009 .004 N 31 31 31 31 31 31 31
Zscore: 第三产业就业人员比重/% Pearson
相关性
.760**.894**-.378*.802** 1 .779**.270
显著性
(双侧)
.000 .000 .036 .000 .000 .142 N 31 31 31 31 31 31 31
Zscore: 城镇化水平/% Pearson
相关性
.930**.874**.051 .463**.779** 1 -.020
显著性
(双侧)
.000 .000 .786 .009 .000 .917 N 31 31 31 31 31 31 31
Zscore: 第三产业固定资产投资比重/% Pearson
相关性
-.005 .142 -.667**.505**.270 -.020 1
显著性
(双侧)
.980 .446 .000 .004 .142 .917
N 31 31 31 31 31 31 31
**. 在 .01 水平(双侧)上显著相关。
*. 在 0.05 水平(双侧)上显著相关。
(2)计算出相关系数矩阵的特征值,以及各主成分的贡献率和累计贡献率,并根据累计贡献率的结果选取合适的主成分;
解释的总方差
成份
初始特征值提取平方和载入
合计方差的 % 累积 % 合计方差的 % 累积 %
1 4.291 61.306 61.306 4.291 61.306 61.306
2 1.969 28.124 89.430 1.969 28.124 89.430
3 .426 6.091 95.522
4 .149 2.12
5 97.646
5 .115 1.649 99.295
6 .038 .548 99.844
7 .011 .156 100.000
提取方法:主成份分析。
(3)计算主成分载荷矩阵,并计算出相关主成分的系数向量,列出主成分的函数表示式;
成份矩阵a
成份
1 2
Zscore: 人均地区生产总值/
元
.862 .448
Zscore: 人均第三产业增加
值/元
.969 .192
Zscore: 第二产业占GDP的比
重/%
-.418 .847
Zscore: 第三产业占GDP的比
重/%
.857 -.421
Zscore: 第三产业就业人员
比重/%
.944 .009
Zscore: 城镇化水平/% .837 .470
Zscore: 第三产业固定资产
投资比重/%
.329 -.784
提取方法 :主成分分析法。
a. 已提取了 2 个成份。
设主成分1为,主成分2为
()
()
(4)计算选取的各个主成分得分,并以主成分的方差贡献率为权重计算出综合得分;
()
()
地区T1 T2 Z1 Z2 y1 y2 F
北京0.862 0.448 0.416 0.319 6.84 -1.1 3.88 上海 4.47 1.08 3.04 天津0.969 0.192 0.468 0.137 1.45 2 1.45 浙江0.75 1.3 0.83 广东0.86 0.83 0.76 江苏0.37 1.78 0.73 辽宁0.837 0.47 0.404 0.335 0.07 1.44 0.45 山东-0.46 1.33 0.09 内蒙古0.944 0.009 0.456 0.006 -0.37 1.13 0.09 福建0.06 0.02 0.04 吉林0.329 -0.784 0.159 -0.559 -0.16 0.41 0.02 湖北0.14 -0.88 -0.16 重庆-0.19 -0.4 -0.23 山西0.857 -0.421 0.414 -0.3 -0.97 1.21 -0.25 黑龙江-0.69 0.25 -0.35 新疆-0.64 0.14 -0.35 宁夏-0.91 0.66 -0.37 河北-0.418 0.847 -0.202 0.604 -1.06 0.99 -0.37 青海-0.9 0.06 -0.54 湖南-0.61 -0.7 -0.57 安徽-0.93 -0.12 -0.61 四川-0.79 -0.54 -0.64
江西-1.25 0.41 -0.65 河南-1.65 1.27 -0.66 甘肃-0.72 -0.83 -0.67 贵州-0.48 -1.46 -0.71 陕西-1.04 -0.36 -0.74 海南0.07 -2.92 -0.78 西藏0.73 -4.56 -0.83 广西-0.99 -1.03 -0.9 云南-1 -1.4 -1.01
(5)根据前两个主成分得分绘制散点图并标注出地区序号;
实验总结:由实验可以得出:北京、上海、天津第三产业发展水平最高,浙江、广东、江苏、辽宁、山东、内蒙古、福建、吉林第三产业发展水平其次,湖北、重庆、山西、黑龙江、新疆、宁夏、河北、青海、湖南、安徽、四川、江西、河南、甘肃、贵州、陕西、海南、西藏、广西、云南第三产业发展水平落后。
实验成绩评阅时间评阅教师。